
支持数据隐私保护的恶意加密流量检测确认方法
2022-03-10 09:25何高峰魏千峰肖咸财朱海婷徐丙凤
通信学报 2022年2期
何高峰,魏千峰,肖咸财,朱海婷,徐丙凤
(1.南京邮电大学物联网学院,江苏 南京 210003;2.南京林业大学信息科学技术学院,江苏 南京 210042)
0 引言
在互联网、物联网以及工业互联网的发展和演化中,网络流量加密日益被广泛接受和采用,成为一项重要的网络通信安全保护机制[1-2]。但网络流量加密技术是一把双刃剑,在保护正常用户网络通信安全的同时,也可以被攻击者所利用以隐藏攻击特征,从而躲避检测。为此,现有研究提出多种基于机器学习的恶意加密流量检测方法。基于机器学习的检测方法可以仅使用报文方向、报文长度和报文时间间隔等基本元素特征,不需要查看流量内容,因而被视为一种自然的恶意加密流量检测手段[3]。Anderson 等[4]分析了18 个恶意软件家族产生的上万条恶意传输层安全协议(TLS,transport layer security)加密流量,并利用逻辑回归模型进行分类。实验结果表明,分类的准确率超过98%。除了使用逻辑回归等基本机器学习算法外,研究人员还结合最新的深度学习算法进行恶意加密流量检测。Wang 等[5]首先将网络流量字节转变为图像,然后使用卷积神经网络进行建模分类,平均准确率超过99%。
在实际应用中,基于机器学习的恶意加密流量检测易产生大量误报[6]。以科罗拉多大学博尔德分校校园网络为例[7],该网络中共包含33 000 余名学生和7 000 余名教职工,每小时产生大约1 000 万条TLS 流量。若检测系统的误报率为0.01%(文献[4]中的典型结果),则每小时产生1 000 条误报,一天则多达24 000 条误报。这些误报若均由人工分析排除,将是非常艰难的工作。同时,主流的深度学习方法大多为黑箱运作模式,难以解释说明一条加密网络流量由于存在何种特征而被判断为恶意流量,从而无法为网络管理人员提供可靠的分析依据。这进一步增大了以人工方式排除误报的困难性。
为解决上述难题,一种可能的思路是将特征匹配和机器学习相结合,从而实现误报的自动排除。如文献[8]中所述,在长达16 个月的实际测试中,基于特征匹配的入侵检测系统共产生1 800 余条误报。其中,85%的误报与网络管理策略相关,如对等网络(P2P,peer to peer)流量识别等,仅有270 余条误报与实际网络攻击相关。因此,可通过设置合适的入侵检测特征对机器学习算法的判别结果进行确认,从而减少误报数量,且匹配的特征能够作为网络管理人员的分析依据。为此,一种直观的实现方法可描述为针对加密网络流量,检测节点(如网络中部署的入侵检测系统)首先利用机器学习算法进行恶意性判别,若判断为恶意流量,通知用户终端如电脑、智能手机等将本地保存的会话密钥发送至检测节点;然后进一步利用该密钥对流量进行解密,获得明文内容;最后在流量明文内容上开展入侵检测特征匹配,若匹配成功,则确认当前流量为恶意流量,否则为误报。
上述特征匹配和机器学习的简单结合又将引发新的网络安全问题。例如,检测节点可宣称任意的加密网络流量为恶意流量,要求用户终端提供对应会话密钥,进而获得明文通信内容,威胁用户的网络通信隐私安全。或者由用户终端解密网络流量,检测节点将入侵检测特征发送至用户终端处进行匹配。但同样地,该方法无法保护检测节点的数据隐私(商用入侵检测特征一般需要付费购买)。同时,恶意用户终端可以任意宣称匹配结果,进而躲避检测。
本文提出一种安全的恶意加密流量检测确认方法,旨在保护数据隐私的前提下,通过对机器学习方法产生的检测结果进行自动确认,减少误报并产生具体的检测判断依据。为保护数据隐私,由用户终端解密网络流量内容,用户终端和检测节点通过运行安全两方计算协议[9]完成网络流量内容和入侵检测特征间的精准匹配。在此过程中,用户终端和检测节点仅交互加密后的数据,且数据不需要解密处理,实现了用户终端和检测节点的双向隐私保护。特别是,本文考虑并解决恶意用户终端任意输入问题,即恶意用户终端以任意数据作为安全两方计算协议的输入,从而躲避特征匹配过程。本文的主要贡献如下。
1) 提出恶意加密流量检测确认方法。基于安全两方计算协议,在不泄露数据内容的前提下,实现入侵检测字符串关键词、正则表达式关键词以及关键词位置信息的精准匹配,并解决了安全两方计算协议在实际应用中存在的任意输入问题[10]。
2) 对方法的安全性和运行时所消耗的系统资源进行理论分析。给出恶意用户终端成功躲避检测的概率计算式,并指出影响用户终端计算量、所占内存大小和网络带宽消耗的关键因素。
3) 原型系统实现与验证。通过真实系统部署和仿真实验相结合的方式,验证方法功能和性能。实验结果表明,所提方法能显著减少误报,且对网络和系统性能影响小。
1 相关工作
本节对恶意加密流量的现有检测方法进行总结梳理。整体上,现有检测方法可以归纳为基于密文解密、基于密文匹配以及基于机器学习这三类。
1) 基于密文解密的检测方法。此方法是现阶段一种常用的恶意加密流量检测方法,其基本思路简洁明了,首先对加密流量进行解密得到明文内容,然后利用入侵检测特征匹配明文内容。若匹配成功,则判断当前加密流量为恶意流量。TLS 透明代理[11]是这类方法的典型实现。透明代理通常充当中间人(MITM,man-in-the-middle)代理,将加密的网络连接分为两部分:客户端到代理和代理到应用服务器。代理首先将其根证书导入客户的受信任证书存储区。当客户端应用程序建立TLS 连接到应用服务器时,代理代替应用服务器完成TLS 握手过程。同时,代理与应用服务器建立第二个TLS 连接。此后,代理可以任意解密通信内容,并判断2 个连接之间的消息内容是否为恶意。透明代理易于实施和部署,但也破坏了端到端的加密防护。研究人员已经发现多起TLS 透明代理有意窃取用户隐私信息的恶意攻击事件[12]。
为克服透明代理的弊端(安装完成后,用户对代理的运行情况一无所知),研究人员设计出非透明代理,如mcTLS[13]、PlainBox[14]等。mcTLS 是第一个针对TLS的非透明代理设计,能提供基于证书的身份认证机制,使用户和应用服务器能够对中间人代理进行身份确认。为实现此功能,mcTLS需要设计新的握手协议,并需改写现有用户端和服务器端的代码实现,因而在现阶段难以推广使用。与mcTLS 不同,PlainBox 使用带外方式进行身份认证和密钥共享,不需要对现有TLS的协议设计和代码实现进行改动。但与透明代理类似,PlainBox 等非透明代理依然可以读取用户和应用服务器之间的所有通信内容,给用户的隐私保护带来巨大威胁。
2) 基于密文匹配的检测方法。为在检测恶意加密流量的同时实现用户隐私信息保护,研究人员设计了一种新的检测思路:对入侵检测特征进行加密,再将加密后的检测特征与加密流量内容进行直接匹配。该思路在文献[15]中首次被提出。文献[15]实现了一种BlindBox 系统,该系统由用户终端、应用服务器以及检测节点组成。首先,用户终端与应用服务器建立正常TLS 连接。在传输数据时,用户终端需要对数据进行2 次处理。一是通过正常TLS连接,将数据发送至应用服务器端。二是对数据进行分割处理,比如将数据分割为多个长度为5 B的片段,称之为token。接着,用户终端利用对称加密算法,如AES 和密钥k对所有的token 进行加密,并将加密后的token 和加密算法对应的混淆电路发送至检测节点。检测节点对入侵检测特征进行同样的处理,如分割为长度为5 B的token,然后利用混淆电路形式的AES 算法和密钥k对规则token 进行加密。最后,检测节点对加密后的流量内容token和检测特征token 进行比对匹配。若匹配成功,则表明对应的加密流量含有恶意内容,为恶意流量。在此过程中,用户的所有数据都为密文形式,检测节点无法得知其具体内容(同规则token 匹配的内容除外),因而有效保护了用户隐私。但其弊端是给用户终端性能带来严重影响[15],如分析处理20条网络流量,需要消耗1 003.38 GB 网络带宽,其中包括加密token的发送和携带密钥k的AES 加密算法的不经意传输。
在文献[15]的启发下,研究人员设计出多种改进的密文匹配检测方法,如PrivDPI[16]、SHVE+[17]等。PrivDPI 对BlindBox 中的规则加密进行优化,使加密后的规则可以多次重复使用,减少了系统初始化配置所花费的时间。但PrivDPI 生成密文形式的流量内容token 时,速度是BlindBox的,且同样需要对数据进行2 次处理,严重降低了终端的运行性能。SHVE+对隐藏向量加密(HVE,hidden vector encryption)方案[18]进行改进,使其支持特征匹配功能。在使用时,用户端不需要对数据进行多次处理,只需要在传输至应用服务器时进行HVE 即可。但HVE 方案目前并不被典型的网络安全协议如TLS 等支持,无法部署于实际的网络应用中。
3) 基于机器学习的检测方法。机器学习被视为恶意加密流量检测的一种自然手段[3,19]。这是由于网络流量加密仅改变了报文内容的形式(由明文变为随机字段),并没有显著改变报文方向、报文长度以及报文时间间隔等特征,而这些特征将能有效区分恶意与正常流量。文献[4]针对TLS 流量,以报文长度序列、报文长度间隔序列、报文字节分布等为特征值,利用逻辑回归算法分类识别恶意TLS流量,识别准确率超过98%。文献[20]针对加密的安全外壳(SSH,secure shell)协议流量,以网络流中的报文数量、访问记录数为特征,实现SSH 协议流量的入侵检测。文献[21]针对数据的加密窃取,以网络协议、应用层协议以及时间等为特征值建立网络用户行为模型,并使用多项式朴素贝叶斯分类算法实现加密数据泄露的检测。文献[22]利用聚类算法,从TLS 流量中提取报文数量、流总字节数、流时长、报文时间间隔均值与方差等作为特征值,实现恶意Android 应用的在线检测。
为提高检测的准确率以及克服需要人工选择检测特征的难题,文献[5]将恶意软件产生的网络流量转变为图像,然后使用图像处理中成熟的深度学习卷积神经网络进行建模分类,平均准确率超过99%。类似地,文献[23]使用树形深度神经网络对恶意流量进行分类检测,实验结果表明,检测的准确率为99.63%,且能较好检测未知的恶意流量。文献[24]给出了基于深度学习的恶意加密流量检测研究综述。在上述工作中,均需要事先采集大量标注的恶意加密流量样本作为训练数据集,且标注正确与否直接影响最终的检测准确性[25]。为此,文献[26]利用生成对抗网络,从少量标注的恶意流量样本中自动合成新的样本,进而提高机器学习算法的分类准确性。
综上所述,基于密文解密的检测方法易于实现和部署,但其本质上破坏了网络应用端到端的加密防护,严重威胁用户数据隐私安全。基于密文匹配的检测方法能较好保护用户的通信隐私,但其性能较低,目前仍处于前期理论研究和探索阶段。基于机器学习的检测方法具有高检测率,且最新的深度学习方法能够从网络流量中自动提取检测特征和自动合成训练数据,无疑增加了此类检测方法的实用性。但基于机器学习的检测方法易产生大量误报,限制了其在实际网络中的部署应用。为此,本文提出一种检测结果再确认方法。在本文提出的方法中,组合使用机器学习和特征匹配功能来实现恶意加密流量检测的可解释和低误报特性,并通过安全两方计算协议确保双方数据的隐私保护。本文工作为恶意加密流量检测提供了一种新的实现思路。
2 方法概述与攻击者模型
2.1 方法概述
方法的典型部署应用如图1 所示。用户终端位于网络内侧,通过加密网络连接访问远程应用服务器。对于加密网络连接,用户终端记录网络五元组信息<源IP 地址、目的IP 地址、源端口、目的端口、安全协议>以及对应的会话安全参数。其中,安全协议为具体使用的网络通信安全协议,如TLS、SSH协议等。会话安全参数为当前网络连接使用的随机数和密钥,如TLS 中的客户端随机数和预备主密钥。值得注意的是,目前主流的杀毒软件已具备上述功能,因而可以对现有杀毒软件功能进行扩充以支持方法的运行。
为保护网络安全,网络管理员部署检测节点,对网络发出或接收的所有加密流量进行分析,判断是否为恶意流量。检测节点可以为独立硬件设备部署于网络出口处(图1(a)),或采用外包形式[27]部署于云平台中(图1(b))。检测节点所采用的分析方法可以为任意机器学习方法,如逻辑回归[4]、深度学习[5]等,同时配备入侵检测特征库用于检测结果确认。

图1 方法的典型部署应用
为对检测结果进行确认,检测节点需与用户终端建立网络连接。在图1(a)中,用户终端与检测节点位于同一网络中,易于满足该要求。在图1(b)中,网络管理员可将检测节点所在IP 地址统一配置于用户终端中,用户终端启动时便与检测节点建立相应网络连接。在后文中,均假定用户终端和检测节点间已存在安全的加密网络连接,所有用户终端构成集合U。恶意加密流量检测确认流程如图2所示。
在图2 中,检测节点利用机器学习算法对加密网络流量进行恶意性判别。对于识别出的恶意加密流量,将流量报文发送至对应用户终端(用户终端不需要事先保存流量,从而减轻用户终端处负载),用户终端验证该流量的真实性和隐私性。具体地,用户终端使用<源IP 地址、目的IP 地址、源端口、目的端口、安全协议>确定对应的会话安全参数,并解密流量。解密成功,则验证了流量真实性。随后,用户终端验证流量内容中是否含有与自身隐私信息相关内容,如“简历投递”“疾病”等。若无相关信息,则验证通过;否则验证失败。若真实性或隐私性验证失败,用户终端终止确认流程,并记录出错信息便于后续人工分析。
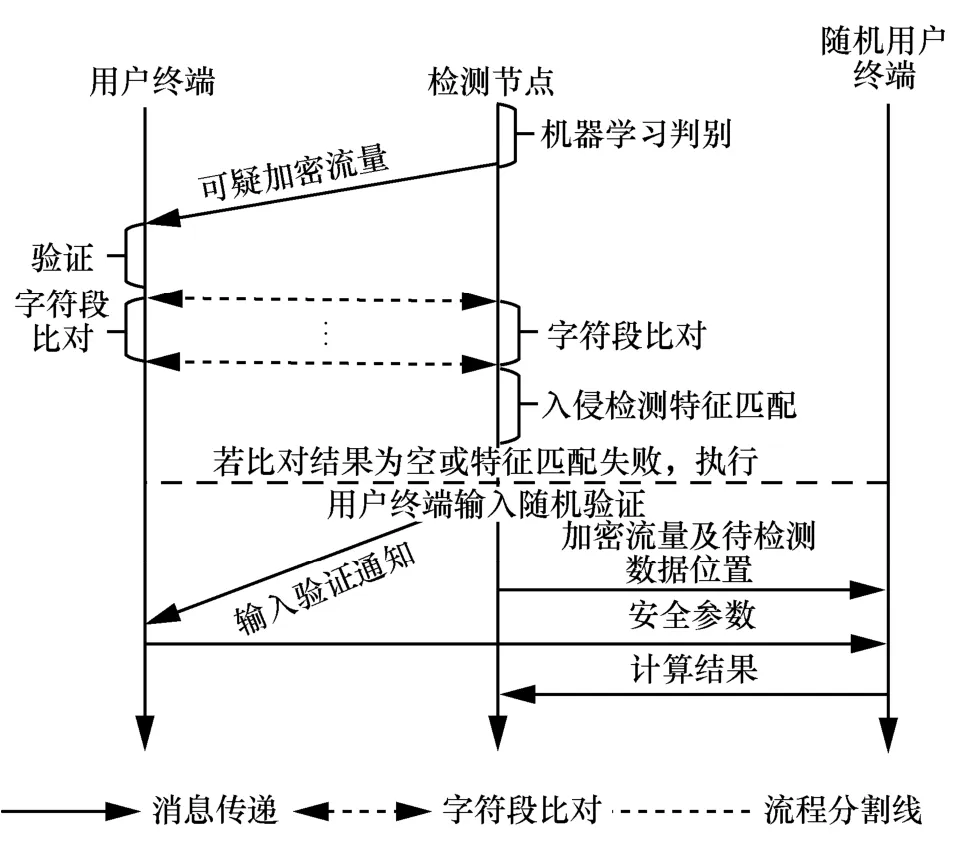
图2 恶意加密流量检测确认流程
验证通过后,用户终端和检测节点运行安全两方计算协议进行数据安全匹配。具体地,本文采用隐私保护集合求交(PSI,private set intersection)协议[9],判断网络流量内容和入侵检测特征之间是否存在相同字符片段。检测节点依据求出的交集还原匹配出具体的入侵检测特征。若匹配成功,则确认当前流量为恶意流量;若匹配失败(如交集为空),则启动用户终端输入验证流程,由随机选择的其他用户终端对PSI 协议数据和流量内容进行随机比对验证。若验证结果正常,表明当前流量为正常加密流量,机器学习检测算法的判别结果为误报;否则,表明用户终端实施了输入替换,存在恶意行为。用户终端输入随机验证使恶意用户终端难以使用其他数据代替真正的流量内容参与PSI 协议以躲避检测确认。
2.2 攻击者模型
如2.1 节所述,方法执行主要涉及用户终端和检测节点。考虑实际情形,本文做出如下攻击者模型假定。
检测节点为半诚实模型[15,28],其严格按照既定流程执行,但可能在运行过程中试图获取用户隐私信息。如图1 所示,检测节点为网络管理员部署,实现网络安全防护是其核心目标,执行既定流程有利于其实现该功能。但与此同时,检测节点可通过方法的执行窃取用户隐私信息,如推断流量内容中是否含有“工作查询”“简历投递”“疾病”等信息,进而调查、解雇对应员工[29]。因而在检测结果确认过程中,应保护用户的隐私信息不被泄露。
用户终端区分为恶意用户终端和正常用户终端。恶意用户终端为网络入侵者所占据的终端,而正常用户终端为其他合法终端。合理假定网络入侵者已拥有所占据终端的管理员权限,在终端中可执行一切操作,因而此类用户终端为恶意模型,即恶意用户终端能以任意偏离方法的执行流程来躲避检测确认或窃取有用信息。恶意用户终端之间可以相互合谋以完成特定攻击目标。正常用户终端为半诚实模型[15],在流程执行过程中可以试图获取入侵检测特征的具体内容。用户终端与检测节点间相互独立,检测节点无法控制用户终端以执行恶意行为,如数据窃取等。
3 方法实现
在本文所提方法中,机器学习判别可以由任意机器学习算法完成,并非本文的研究重点。本节将详细阐述字符段比对、入侵检测特征匹配和用户终端输入随机验证的具体实现流程。论文涉及的主要参数符号如表1 所示。

表1 参数符号
3.1 字符段比对
本文提出利用入侵检测特征对机器学习算法的判别结果进行进一步确认。入侵检测特征可以利用现有的ET Pro Ruleset、Snort Talos Rules 等入侵检测规则。这些规则中包括的字符串关键词(如“ -J-jar -J ”)、正则表达式关键词(如“/(launchx28.+-J-jar -J|-J-jar -J.+launchx28)/i”)以及关键词在流量内容中的位置信息即为入侵检测特征。实用的入侵检测系统一般以字符串关键词为先导[30],即首先匹配字符串关键词,若匹配成功,再匹配对应的正则表达式关键词,从而提高运行效率。本文方法遵循同样思路实现。
为实现在特征匹配过程中同时满足用户终端和检测节点的数据隐私保护要求,首先使用PSI 协议[9]实现数据内容的字符段比对。将网络流量内容和入侵检测关键词分割为多个长度为l的字符片段,分别构成集合C和S。针对集合C和S,用户终端和检测节点执行隐私保护集合求交协议得出交集C∩S。在此过程中,除了交集C∩S以外,用户终端和检测节点并不能获得对方的其他任何数据内容信息,从而实现了隐私保护。根据交集C∩S,检测节点将从多个字符段中还原出对应的数据内容,从而完成入侵检测特征匹配。本节主要阐述字符段比对的具体技术实现,入侵检测特征匹配将在3.2 节中描述。
1) 用户终端预处理。用户终端利用保存的会话密钥对可疑的加密网络流量进行解密(会话密钥保存以及加密网络流量获取等内容见2.1 节),从而获得网络流量明文内容(十六进制形式)。考虑到商用的入侵检测关键词中大多含有十六进制内容,因而在预处理步骤中,将网络流量内容和入侵检测关键词统一转变为十六进制形式,以便后续的集合求交运算。对流量明文内容进行滑动窗口分割,形成集合C。具体步骤如下。
步骤1设定大小为l(l≥1)的滑动窗口。
步骤2从流内容的起始处读取窗口内所有内容,按序加入集合C。
步骤3将窗口后移一位,读取窗口内所有内容,按序加入集合C。
步骤4重复步骤3,直至窗口内容长度小于l。
2) 检测节点预处理。检测节点读取入侵检测特征库中的所有字符串形式关键词,将关键词内容转变为十六进制形式并进行滑动窗口分割,形成集合S。具体步骤如下。
步骤1设定大小为l的滑动窗口。
步骤2读取当前关键词。
步骤3从关键词的起始处读取窗口内所有内容,加入集合S。
步骤4将窗口后移一个字符,读取窗口内所有内容,加入集合S(重复内容删除,不需要保持元素顺序)。
步骤5重复步骤4 直至窗口内容长度小于l。
步骤6跳转至步骤2,直至所有字符串形式关键词读取完毕。
3) 检测节点加密集合S。完成预处理后,检测节点加密集合S={s1,s2,…,sS}中每一项元素,并发送至用户终端,即针对sj(1 ≤j≤),进行式(1)~式(3)的Hash 和模幂运算。

计算完成后,检测节点将集合{Mj}发送至用户终端。
4) 用户终端加密集合C。用户终端接收集合{Mj}后,对Mj和集合C=进行密码学处理,计算过程如式(4)~式(8)所示。其中,式(4)产生随机数Rc,式(5)和式(6)利用Rc进行对应的模幂运算,式(7)利用离散对数难题和Hash 计算生成Rc的零知识证明,式(8)对集合C中的每一项元素进行模幂运算。


5) 检测节点比对数据。检测节点验证零知识证明π的值,如果验证失败,流程终止;如果验证通过,进行式(9)计算。式(9)对集合S中每一项元素进行模幂和Hash 处理。
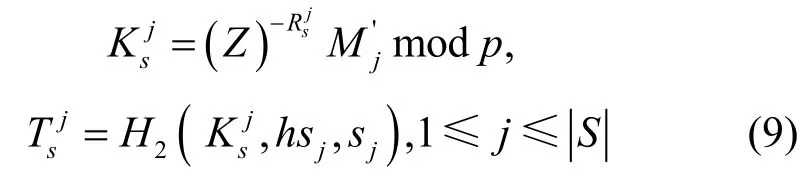
集合C和S的交集元素计算式为

式(7)中π值的验证参见文献[9,31]。上述过程为文献[9]中PSI 协议的优化,主要区别在于检测节点加密集合S时不需要提供零知识证明。这是由于本文假定检测节点为半诚实模型(2.2 节),其严格执行协议流程,因此不需要额外证明。
3.2 入侵检测特征匹配
检测节点依据集合{<s j∈C∩S,i>}匹配具体的入侵检测特征。若集合{<s j∈C∩S,i>}不为空,字符串形式关键词匹配算法如算法1 所示。
算法1字符串形式关键词匹配算法


在算法1 中,若sj匹配成功且对应的入侵检测规则中含有正则表达式关键词,则继续执行算法2。
算法2正则表达式关键词匹配算法

入侵检测特征中的关键词位置信息可由更新后的集合{<s j∈C∩S,i>}中i和sj的长度直接推算出。如ET Pro rules 中的offset字段,表示关键词在流内容的起始位置,因而(i-1)l的值等于offset 字段的值即匹配成功。其余表示位置信息的字段,如distance、within 等均可做类似计算和匹配。
在算法 1 中,只需要遍历交集集合{<s j∈C∩S,i>}一次,因而时间复杂度为O(n)。在算法2 中,步骤1)~步骤3)可离线完成(如系统启动时完成),从而加快算法执行速度;步骤4)~步骤7)的时间复杂度与正则表达式关键词中适配符数量等因素相关。设共有x个正则表达式关键词,每个关键词中含有a个适配符,适配符的取值范围为b,关键词实例长度为LI,则集合S的大小为=(LI-l+1)xab。在式(10)中,利用Hash 表求解集合交集[32],此时算法遍历S集合两次、C集合一次以及交集C∩S一次,故时间复杂度为O(2(LI-l+1)xa b+v+n)。算法2的时间复杂度随适配符数量呈多项式增长。
3.3 用户终端输入随机验证
当式(10)中的交集C∩S为空,或特征匹配失败时,检测节点执行用户终端输入随机验证流程。这是由于在式(8)中,恶意用户终端可以使用任意数据代替流量内容ci的值进行计算,从而规避检测确认。用户终端输入随机验证流程表述如下。
检测节点从Zq中选择随机数Rd,计算参数Pd为

检测节点将参数Pd和“输入验证通知”发送至目标用户终端。记目标用户终端为ut,即U集合中第t个用户。ut接收相关信息后,从Zq中选择随机数Rt,计算参数Pt为
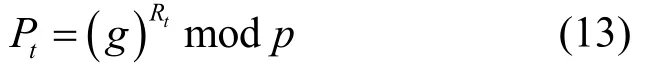
用户终端ut将参数Pt发送至检测节点。检测节点和用户终端ut分别进行式(14)和式(15)计算,求出共同参数k,并计算式(16),求得参数z(z应不等于t)。式(12)~式(15)本质上为DH 密钥交换[33],H1(k)为随机数,因而uz为随机选择的用户终端。
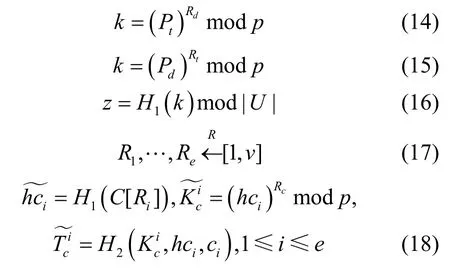
如式(17)所示,检测节点从[1,v]中随机选择e个数字R1,…,Re,并将R1,…,Re和加密流量f发送至用户终端uz。用户终端ut发送会话密钥kf和式(4)中的Rc至uz。用户终端uz接收R1,…,Re、f、kf和Rc后,利用kf解密流f。接着,对于解密后的流内容,执行用户终端预处理的步骤1~步骤4,得出集合C。从C中选择第R1,…,Re个元素,利用Rc计算式(18)。最后,uz将(1≤i≤e)发送至检测节点。
检测节点将˜i cT(1≤i≤e)同用户终端ut发送的即式(8)的计算结果)中的对应数值进行比较。若比较结果不一致,则表明ut实施了恶意输入代替,为恶意用户终端。在此过程中,恶意用户终端成功通过验证的概率分析见第4 节。
4 方法分析
本节对所提方法进行理论分析,包括方法的安全性分析以及性能分析。在安全性分析中,重点分析数据隐私保护特征以及恶意用户终端成功通过验证的概率。性能分析主要针对用户终端进行,分析用户终端需要执行的计算量、使用的内存大小以及消耗的网络通信带宽。类似的性能分析方法同样适用于检测节点,且检测节点一般由专用服务器实现,故本节省略检测节点的资源消耗分析过程。
4.1 安全性分析
1) 数据隐私保护特征分析
本文提出的方法能提供良好的双向数据隐私保护功能:①用户终端无法获得检测节点的入侵检测特征内容;②除交集C∩S的内容外,检测节点无法获知用户终端其他数据内容。方法的隐私保护功能以离散对数问题[34]为理论基础。在式(3)中,由于离散对数的难解性,用户终端无法在多项式时间内从Mj反推出hsj的值,进而无法获知式(1)中sj的值,从而实现了检测节点的入侵检测特征隐私保护。类似地,针对式(8),检测节点无法反推出ci的值,因而除了交集C∩S内容以外,检测节点无法获知流f中其他字段内容。上述结论的严格证明详见文献[9]。
在2.2 节攻击者模型中,设定检测节点为半诚实模型,即检测节点严格执行协议步骤,但试图窃取用户隐私信息。为此,检测节点可采取一种隐蔽攻击方式,将试图获取的信息作为入侵检测特征同加密流量内容进行比对。如检测节点可将“简历投递”“薪酬期望”等作为入侵检测特征。若在加密流量中匹配出此类关键词,检测节点在无法获知流量其他内容的前提下,也能推断出该流量的主要信息,威胁用户个人隐私。为抵御此类攻击,如2.1 节中所述,用户终端在解密流量内容后,将判断流量内容中是否涉及用户敏感信息。通过用户终端的主动检查,能够发现检测节点的上述攻击行为,从而使此类攻击失效。
2) 恶意用户终端成功通过验证的概率分析
为解决恶意用户终端的任意输入问题,在3.3 节中提出随机验证策略。随机选取e个流量内容片段,计算对应的值,并同用户终端ut发送的值进行比较。若存在不一致,则表明用户终端ut在执行PSI协议时存在输入替代,如将可能的恶意特征替换为正常字符,或直接使用随机数据替代流量内容等。由于为随机验证,恶意用户终端能以一定的概率通过输入验证。具体的概率Pr 计算如下。
情形1uz为恶意用户终端。设集合U中恶意用户终端总数为m,m< |C|。如2.2 节攻击者模型中所设定,恶意用户终端可以相互合谋以完成特定攻击目标。此时,uz不需要计算˜i cT的值,可直接发送对应的值至检测节点。检测节点通过比对,无法发现uz实施了输入替代,uz成功通过输入验证。由于uz为随机选择,情形1 发生的概率为

情形2uz为正常用户终端。假定恶意用户终端uz对流量内容中r(r≥1)个连续字符进行了修改。在3.1 节用户终端预处理步骤中,修改的r个字符将平均出现r+l-1 次。在随机选择e个字符段时,选择的字符段均不包含r个修改字符的概率为。此时,恶意用户终端成功通过输入验证的概率为

当e=|C|时,Pr2=0。最终的Pr 为

Pr 值递减。具体参数值的选取和验证将于第5 节中阐述。值得注意的是,式(21)为在随机选择一个用户终端作为验证方时,恶意用户终端通过输入验证的概率值。若随机选择n(n≥1)个用户终端作为验证方,则。因而可通过增加n的值使Pr 快速趋向于0。
4.2 性能分析
由于检测节点一般由专用服务器实现,且检测节点的性能分析过程与用户终端类似,本节重点分析用户终端的运行性能。在方法的运行过程中,用户终端需要进行数据预处理以及计算式(5)~式(8)。其中,数据预处理仅需遍历加密网络流量f的内容一次、式(7)中的零知识证明只需要计算Hash 一次,产生的性能消耗极低。因此,对用户终端性能产生主要影响的是式(6)和式(8)中的模幂运算和Hash 计算。令模幂运算的计算资源开销(如CPU 执行时间)为λ1,Hash 函数的计算资源开销为λ2,字符串关键词对应的集合S1的大小为,正则表达式关键词对应的集合S2的大小为,则用户终端所需的计算资源开销λc为
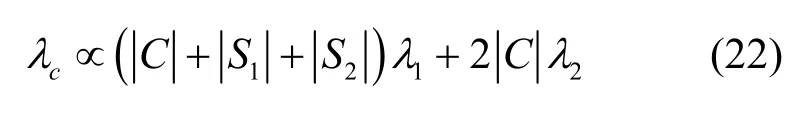
由式(22)可知,用户终端所需的计算资源开销与集合C和集合S的大小呈线性相关。
在计算过程中,用户终端需遍历集合{Mj}和集合C一次,计算和存储结果。集合C的大小为,集合{Mj}的大小为,计算结果所占比特数与模数p长度相同(如512 bit)。因此,用户终端的内存消耗λm可表示为
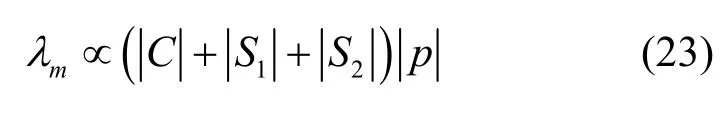
同样地,存储资源消耗与集合C和集合S的大小呈线性相关。
用户终端的网络通信带宽消耗分析如下。如3.1 节中所述,检测节点需将集合{Mj}发送至用户终端,用户终端需将集合{}和{}发送至检测节点。因而消耗的网络带宽正比于集合中元素个数和字符段长度l,如式(24)所示。

设未分割前的流量内容字符串长度为Lf,入侵检测特征关键词字符串长度为LI,字符段的长度为l,入侵检测特征关键词总数量为h,则有

将式(25)、式(26)分别代入式(22)~式(24),可得

由式(27)和式(28)知,在总数据量(Lf、LI以及h)一定的情形下,随着l值递增,用户终端的计算和存储资源开销递减。以l为自变量,对式(29)求一阶导数,可得当时,所消耗的网络带宽最大。因此,当时,随着l值的递增,用户终端的计算和存储资源开销递减,但消耗的网络带宽递增;当时,随着l值的递增,用户终端的计算和存储资源开销递减,消耗的网络带宽也递减。考虑到l≤LI这个约束条件,在实际应用中,可通过设置较长的入侵检测关键词来减少用户终端的资源消耗。具体实验验证见5.2 节。
5 实验验证
本节主要验证方法对恶意加密流量检测确认的准确性和对用户终端的性能影响程度。实验中运行Windows XP 虚拟机作为用户终端,检测节点为Dell PowerEdge R730 服务器。虚拟机配置为运行单个CPU,内存为2 GB,模拟较低性能终端设备。检测节点服务器与用户终端位于同一局域网,并配备路由转发功能。检测节点能够捕获用户终端所产生的所有流量。
在用户终端中,正常应用(如浏览器的密钥提取)通过配置SSLKEYLOGFILE 系统变量实现。对于恶意软件,其加密网络流量的密钥提取通过mitmproxy 实现,提取的密钥存储同样存于SSLKEYLOGFILE 文件中。加密流量的解密和十六进制内容导出由tshark 工具完成。入侵检测规则为开源的ET Suricata 规则,包括attack_response、malware、shellcode、Web 等规则文件。入侵检测规则和网络流量内容的分割由Python 代码完成。机器学习算法选定为随机森林算法,分类特征包括TLS证书、报文长度分布等。
PSI 代码由Python 代码实现。其中,在用户终端处运行Flask Python Web 框架,监听5000 端口。用户终端同检测节点采用HTTP 进行数据的接收和发送。在数据处理时,流量内容和关键词首先以十六进制字符形式存于文件,PSI 代码从文件中读取字符段并转换为对应数字进行模幂运算和Hash 计算。Hash 计算利用SHA256 完成,模幂运算则由高精度运算库gmpy2 实现。此外,在PSI 代码中额外增加CPU 执行时间(利用perf_counter 函数实现)和内存消耗(利用psutil 库实现)统计功能,便于计算方法的系统资源开销。鉴于TLS 已成为互联网安全传输的事实标准[35],实验中主要针对TLS 加密流量进行测试。
5.1 功能验证
功能验证主要包含3 个方面的内容:1) 验证对恶意加密流量检测的误报消除效果,由减少的误报数量衡量;2) 验证对检测召回率(Recall)的影响,由漏报数量衡量;3) 恶意用户终端成功通过输入验证的可能性,由Pr 衡量。实际上,恶意加密流量的检测召回率主要由机器学习算法决定,但对检测结果进行进一步确认可能增加漏报,从而降低召回率。实验中,设定l的值,即字符段长度为5。这是由于选用的ET Suricata 规则中最短的关键词长度为5。
为验证对误报的消除效果,在虚拟机中使用Firefox 浏览器访问Alexa Top 100 网站。依据文献[36],可认为Alexa Top 100 网站为合法网站,产生的流量为正常流量。实验中使用Shell 编程和iMacros 插件实现Firefox 浏览器的自动访问和自动链接点击,对每个网址的访问时间设定为1 min,共捕获15 887 条TLS 流量。实验结果如表2 所示。检测端使用随机森林算法进行判断,检测出13 条TLS 流量为恶意流量。经过特征安全匹配后,有12 条TLS流量被确认为正常流量,即消除误报流量12 条,误报数量减少了92.3%。对最终的误报流量进行人工分析发现,流量中含有“/perl”字段,从而触发了入侵检测规则。

表2 误报消除实验结果
为验证对恶意加密流量检测召回率的影响,从互联网中下载EXE 类型病毒样本1 047 例。将下载的病毒样本逐一运行于虚拟机中,并使用tshark 软件进行网络流量捕获。为避免干扰,完成一例病毒样本测试后,将虚拟机还原至初始状态,然后运行另一例病毒样本。实验结果如表3 所示。由于部分样本无法正常运行,实验中共捕获278 条恶意TLS流量。在检测端运行随机森林算法,共检测出269 条。但如表3 所示,经过特征安全匹配后,有2 条恶意TLS 流量被判断为正常流量,从而产生了漏报。对这2 条恶意TLS 流量进行人工分析发现,其数据内容为压缩或可执行文件,从而导致规则匹配失效。

表3 检测漏报实验结果
综合表2 和表3的实验结果可知,本文提出的方法能够有效减少误报,但同时也增加了一些漏报数量。误报和漏报产生的原因是规则的精确度有限,如将“/perl”字段判断为恶意攻击、无法匹配压缩和可执行文件内容等。因此,在实际使用中,可采用或制定更精确的入侵检测特征,提升方法的准确性和实用性。为验证上述思路,购买了商用版Snort Ruleset 对表2 中判断为恶意流量的13 条正常TLS 流量和表3中检测出的269 条恶意TLS 流量进行再次确认。实验结果表明,最新规则能够排除所有误报,且能确认所有恶意TLS 流量。
如4.1 节中所述,恶意用户终端能以一定概率通过输入验证。为验证式(21)的正确性,首先随机产生长度为1 000的随机十六进制字符串,并随机选择r个连续字符进行修改。对修改后的字符串进行滑动分割,分割长度为l,形成集合C。接着,产生0~1的随机数R。若的值为设定的实验参数),则直接判定恶意用户通过输入验证。否则,从集合C中随机选择e个字符段,若选出的e个字符段均不包含修改后的字符,则直接判定恶意用户通过输入验证。最后,重复实验10 000 次,统计通过验证的次数并除以10 000,即实验求出的Pr的值。不同参数条件下的实验结果如图3~图6 所示。

图3 设定r=3,l=10,e=300 时,随恶意用户终端所占比例不同的取值所对应的Pr 值

图4 设定=0.01,l=10,e=300 时,修改的字符数量不同的取值所对应的Pr 值

图5 设定=0.01,r=3,e=300 时,字符段长度不同的取值所对应的Pr 值

图6 设定=0.01,r=3,l=10 时,字符段数量不同的取值所对应的Pr 值
在图3~图6 中,理论值为式(21)的计算结果,理论值与实验值基本一致。实验结果表明,随着恶意用户终端所占比例的递增,恶意用户终端成功通过输入验证的概率Pr 递增;随着修改的字符数量、字符串长度以及检测节点随机选择的字符段数量的递增,Pr 值递减。特别地,当随机选择的字符段数量超过总字符段数量的一半时,Pr 值趋近于0。在实际应用中,可选择较大的l和e值,减少恶意用户终端成功通过输入验证的可能性。实验中还验证了其他多组参数,如r=4,l=11,e=200 和=0.02,l=10,e=400 等。实验结果均与理论计算结果一致,因此不再叙述。
5.2 性能验证
本节给出不同参数条件下,用户终端的资源消耗程度。具体地,在总数据量一定的前提下,通过设置不同的字符串长度,统计用户终端的计算性能开销、内存占用量和网络带宽消耗。在实验中,计算性能开销由CPU 执行时间来衡量,内存占用量由使用的内存字节数表示,网络带宽消耗由发送和接收的数据分组字节数表示。
首先,验证式(27)和式(28)的正确性。在式(27)中,区分模幂运算和Hash 计算的代价为λ1和λ2。在实验中,利用CPU 执行时间统一衡量模幂运算和Hash 计算的所需代价。为此,在隐私保护集合交集代码中使用perf_counter 函数统计式(4)~式(8)所需的计算时间。设定网络流内容共有10 000 个字符,入侵检测特征长度为20,入侵检测特征数量为1 000,字符段长度为1~9。对于相同数据,CPU 执行时间统计结果会略有差别。因此,对于同一参数运行10 次,取CPU 执行时间的平均值为最后实验结果,如图7 所示。实验结果表明,随着字符段长度的递增,CPU 执行时间递减,同式(27)的分析结果一致。

图7 不同字符段长度所对应的CPU 执行时间
程序所占用的内存字节由psutil 库统计。同样地,设定网络流内容共有10 000 个字符,入侵检测特征长度为20,入侵检测特征数量为1 000。为反映内存占用的变化趋势,字符段长度l值设定为1、4、7、10、13、16 和19。对于同一参数,运行10 次,取内存占用的平均值为最后实验结果,如图8 所示。实验结果表明,随着字符段长度的递增,所占用的内存大小递减,与式(28)的分析结果一致。
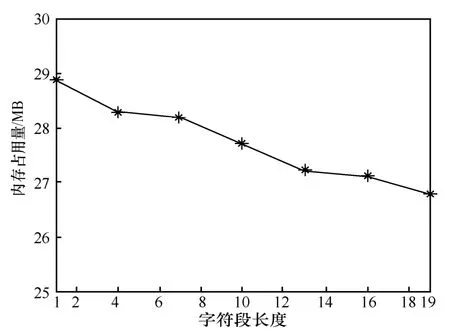
图8 不同字符段长度所对应的内存占用量
其次,验证式(29)的正确性。式(29)表明,在总数量一定的前提下,当时,随着l值的递增,网络带宽消耗递增;当时,随着l值的递增,网络带宽消耗递减。设定网络流内容共有10 000 个字符,入侵检测特征长度为20,入侵检测特征数量为1 000。依据上述分析,当l=15 时,网络带宽消耗最多。实验中调节l的值从12 递增至19,在用户终端处使用tshark 工具捕获端口5000的网络流量,并统计流中数据字节数(不包括报文头部字段)。不同字符段长度所对应的网络带宽消耗如图9 所示。实验结果同理论分析相一致。实验中还测试了其他不同参数,结果趋势均一致,故不再赘述。
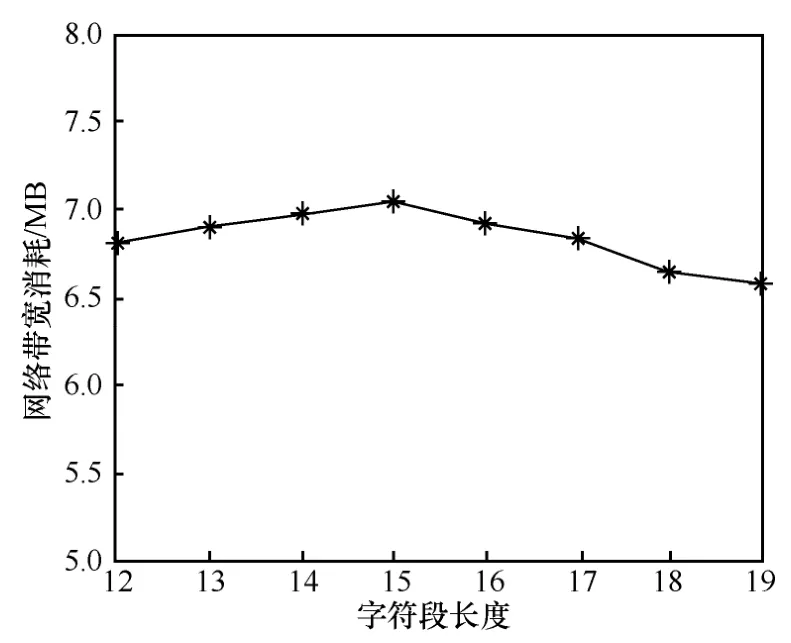
图9 不同字符段长度所对应的网络带宽消耗
综上所述,当l≥15 时,随着l值的增大,CPU执行时间、内存占用量、网络带宽消耗以及恶意用户终端成功通过输入验证的概率均呈下降趋势。因此在实际应用中可设置较长的入侵检测特征关键词,并通过增加l的值以提升方法性能。
最后,给出实际运行时的资源消耗统计。如5.1 节中所述,通过访问Alexa Top 100 网站和实际运行1 047 例恶意样本,共捕获16 165 条TLS 流量。其中有282(即13+269)条TLS 流量被随机森林算法判别为恶意流量。在对这282 条TLS 流量进行实际确认时,分别统计用户终端的CPU 执行时间、CPU 占用率、网络带宽消耗以及内存占用量,并对统计结果取均值作为最后数值,如表4 所示。

表4 实际确认时用户终端的性能消耗
实验结果表明,在执行确认过程中,用户终端需要进行1 min 左右的频繁计算(约25%的CPU 使用率),平均占用52.1 MB的内存,消耗的网络带宽平均为11.6 MB,可适用于普通PC 和智能手机。需要注意的是,对于正常用户终端,其仅在检测节点产生误报时才参与检测确认过程。若误报率为0.01%,正常用户终端平均产生10 000 条加密流量才参与一次确认。在其他情形时,检测节点与用户终端间无网络交互,用户终端也不需要进行模幂和Hash 计算,本文提出的方法的运行仅需极少的系统资源。因此本文提出的恶意加密流量检测确认方法对用户终端系统的实际运行影响较小。
将本文提出的方法同目前实用的基于密文解密的恶意加密流量检测方法[11,13]进行对比。本文提出的方法只需对可疑的加密网络流量进行解密,而文献[11,13]中的方法需对所有加密网络流量进行解密。本文提出的方法运用PSI 协议进行特征匹配,除求出的交集外,检测节点无法获知网络流量中其他内容,而文献[11,13]中检测节点能够获得用户终端的所有网络流量内容。因此,本文提出的方法具有更好的隐私保护特征,且如表4 所示,本文提出的方法运行仅需极少的系统资源。本文提出的方法可以与基于机器学习的恶意加密流量检测方法相配合,以一种新方式实现恶意加密流量的安全、有效监管。
6 结束语
本文提出并实现了一种支持隐私保护的恶意加密流量检测确认方法。在提出的方法中,可以使用任意机器学习算法进行恶意加密流量的检测判断,并支持字符串关键词、正则表达式关键词以及关键词位置信息判断,因而具有良好的适用性和可扩展性。在确认过程中,用户终端无法获得检测节点的入侵检测特征内容,检测节点无法获知交集以外的用户终端其他通信内容,从而实现了双方的数据隐私保护。利用真实加密网络流量进行测试,实验结果表明,本文提出的方法能减少92.3%的误报。在进行检测确认时,CPU 占用率接近25%,但此过程持续时间短,平均为58.3 s,且发生的频率低,因而对用户终端的系统性能影响有限。未来工作包括将用户终端功能同ClamWin 等开源杀毒软件相结合,优化程序实现提升系统性能,并在校园网等实际网络中部署使用。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
北京航空航天大学学报(2021年9期)2021-11-02
现代装饰(2020年8期)2020-08-24
微型电脑应用(2019年8期)2019-08-22
太原科技大学学报(2019年3期)2019-08-05
电子制作(2018年23期)2018-12-26
北京航空航天大学学报(2017年7期)2017-11-24
课堂内外(小学版)(2017年5期)2017-06-07
