
人工智能结合大数据技术在材料拉伸性能教学中的应用1)
2022-03-12 07:45方棋洪
力学与实践 2022年1期
李 甲 方棋洪
(湖南大学机械与运载工程学院,长沙 410082)
材料力学是一门重要的专业基础课程,帮助机械、材料、力学、土木等专业学生初步认识材料在载荷作用下的应力、变形和破坏等。其中,低碳钢拉伸试验是本科学生动态观测塑性金属材料在单轴拉伸过程中经历弹性、屈服、强化、颈缩和断裂五个阶段的重要学习内容,为后续理解扭转和弯曲变形试验起到关键作用[1-2]。
拉伸试验能够有效地帮助学生理解金属材料的变形与力学性能,但是学生们发现测量得到的材料应力-应变曲线以及相对应的屈服强度、极限强度结果不一致。那么就会有这样的问题产生:“低碳钢关键性能指标应该怎么选取,所有试验结果的最小值、最大值还是平均值?”事实上,应该首先把不合理的结果剔除,再利用宏观统计结果预测才能得到合理的低碳钢拉伸试验应力-应变曲线。这主要是由于:(1)试验试件材料样本的成分分布和微观组织结构不均匀;(2) 材料样本内可能含微裂纹、孔洞和杂质颗粒等缺陷,产生应力集中,加速材料破坏,不能准确描述材料的力学性能。
针对这一问题,本文发展了基于人工智能与大数据的试验结果分析技术,通过读取拉伸试验数据并构建性能数据库,运用概率统计理论剔除不合理的结果,然后预测合理的应力-应变曲线,并结合人工智能方法评估试验结果准确性及可能失效原因,最后给出材料的关键性能指标值及偏差。这样不仅可以深入了解金属材料变形行为,而且能培养学生运用人工智能与大数据技术解决试验结果不确定性问题的能力,实现应用多学科知识解决实际问题,达到学以致用的目的。
1 大数据与人工智能简介
大数据通常指一种具有大规模数据容量、数据形式多样化、数据维度复杂、数据信息真实可靠、具有一定价值的数据集合。近年来,随着数据采集、存储、计算水平的迅速发展,大数据技术渐近成熟,相应理论体系也逐步完善,世界已正式踏入大数据时代[3]。然而,传统数据处理手段受到数据维度以及数据形式限制,无法实现对大数据的深入挖掘与分析。人工智能通常指使计算机获得一种能力,使计算机有效地执行原本需要人类智能才能完成的复杂任务。机器学习作为人工智能的一个非常重要的分支,能够捕捉到高度复杂的非线性输入输出关系,从而建立输入输出之间的精确联系。因而,机器学习已成为大数据分析的有效途径[4]。此外,大数据与人工智能之间并不是相互独立的,而是相互融合、促进与发展的(如图1(a) 所示)。大数据使人工智能可以得到有效地训练,同时,人工智能通过得到的“智慧”,更进一步地促进大数据的发展。如今,机器学习与大数据的结合已经在语音识别、肿瘤检测、人脸识别等领域有着广泛的应用[5]。本文在解决相关预测问题时,所使用的机器学习算法为人工神经网络算法,该算法的目的是人为地构建类生命体神经网络的结构,从而使得计算机通过训练而获得智能。如图1(b) 所示,人工神经网络通常由输入层、隐藏层以及输出层构成。输入层的主要功能是通过接收特定的数据或信号信息来感知外部世界。这些信息可以是实数、二进制值或者整数的形式。当信息通过隐藏层时,由神经元进行特征提取和处理,隐藏层承担了整个内部处理的大部分计算。输出层通过对前几层结果的综合,对输入信息做出最终决策。人工神经网络已经证实能够有效地解决分类或者回归问题[6]。

图1 大数据、人工智能与机器学习
2 数据收集和预处理
大数据是人工智能辅助教学的基础,高质量的数据能够使人工智能更加精准地判断及预测[3-4]。本文采用机器学习模型建立样本数据与力学性能之间的关系,实现批量判断试验数据的准确性及偏离原因分析[6]。在构建低碳钢的性能筛选模型之前,首先应该建立应力-应变的数据库,本文所收集的应力-应变数据来源于本科生试验测量数据,共456 组(如图2(a) 所示)。为降低预测结果的偏差,通过对比标准的试验数据结果,剔除了完全偏离标准试验结果的27 组数据。同时,根据样本1 数据绘制了相应的应力-应变曲线(如图2(b) 所示)。同时,选取几组有代表性的拉断试验样本,并给出了样本断裂形貌,如图3 所示。结果表明,材料本身的特性会影响最终的断裂位置及断口形貌。
图2 拉伸试验数据

图3 试验样本断裂形貌
3 计算分析与讨论
拉伸应力-应变曲线是学生直观理解低碳钢塑性变形过程,以及获得低碳钢弹性模量、屈服强度、极限强度等关键力学性能指标的重要基础[6-7]。但是,在试验过程中,学生得到的低碳钢的应力-应变曲线以及相对应的屈服强度、极限强度存在着随机性或不确定性问题。通过批量提取拉伸试验数据,并构建低碳钢应力-应变曲线数据库,对数据库中应力-应变曲线分析,发现部分拉伸应力-应变曲线是不合理的,可能是由于学生对试验设备、试验流程不熟悉或者操作不规范导致。因此,这些不合理试验结果应当被剔除。首先,批量提取了低碳钢在拉伸过程中同一应变下的应力值,并通过概率统计理论计算得到均值与方差。在此基础上,假设拉伸试验数据服从高斯正态分布,构建在同一应变下应力值的概率分布函数,运用正态分布中“3σ原理”,初步剔除了不合理的试验数据。同时,将剩余的数据取加权平均值,最终获得了基于大数据统计下的应力-应变曲线(如图4(d) 粗实线所示) 以及对应的关键力学性能指标的分布频率,概率密度拟合曲线及其数字特征(如图4(a)~图4(c) 以及表1 所示)。随后,取均值作为关键力学性能指标,在试验误差允许的范围内,定义关键力学性能指标值的15%为试验数据的合理偏差范围来进一步地剔除不合理试验数据。例如,图4 中的“样本1” 与“样本2” 的极限强度偏离合理偏差范围,因此,“样本1” 与“样本2” 需要被剔除。

图4 力学性能指标的分布频率及概率密度拟合曲线与大数据统计下拉伸应力-应变曲线

表1 力学性能指标
通过对数据库中应力-应变数据分析,结合概率统计获得的应力-应变曲线,定义低碳钢拉伸试验中关键力学性能指标值偏离大数据统计指标值5%以外为失效,并分析了可能失效的原因,如表2 所示。随后,在此定义的基础上,根据失效原因对数据库中的试验数据进行初步分类,构建了“应力-应变曲线-失效原因” 数据库,并以此作为初始数据集。运用机器学习算法评估了其他试验结果准确性及可能失效原因。图5 展现了机器学习算法的预测精度,并使用混淆矩阵来说明机器学习算法在不同失效原因上的预测结果。其中,绿色方框中的数字代表失效类别预测正确的样本数,红色方框中带数字代表预测错误的样本数。可以清晰地看出,机器学习算法在训练集、验证集以及测试集都表现出了十分优越的性能,达到了很高的精确度,且大部分数据样本落在失效类别5,说明弹性阶段应变未测准为主要失效原因,这与力学性能指标的分布频率统计结果一致。因此,机器学习算法能够准确地建立“应力-应变曲线-失效原因”模型、找到合理的分类标准,并以此预测试验结果的失效类别,这是传统的拉伸试验数据处理方法不能提供的新功能。在以后的拉伸性能教学课程中,学生可以根据已建立好的机器学习模型,快速地判别试验结果的合理性、找到试验结果不合理的原因。这不仅可以使学生深入理解金属材料变形行为,而且能够增强学生应用人工智能与大数据技术解决实际问题的能力,达到学以致用的目的。

图5 机器学习预测精度(续)

表2 失效类别及可能的原因
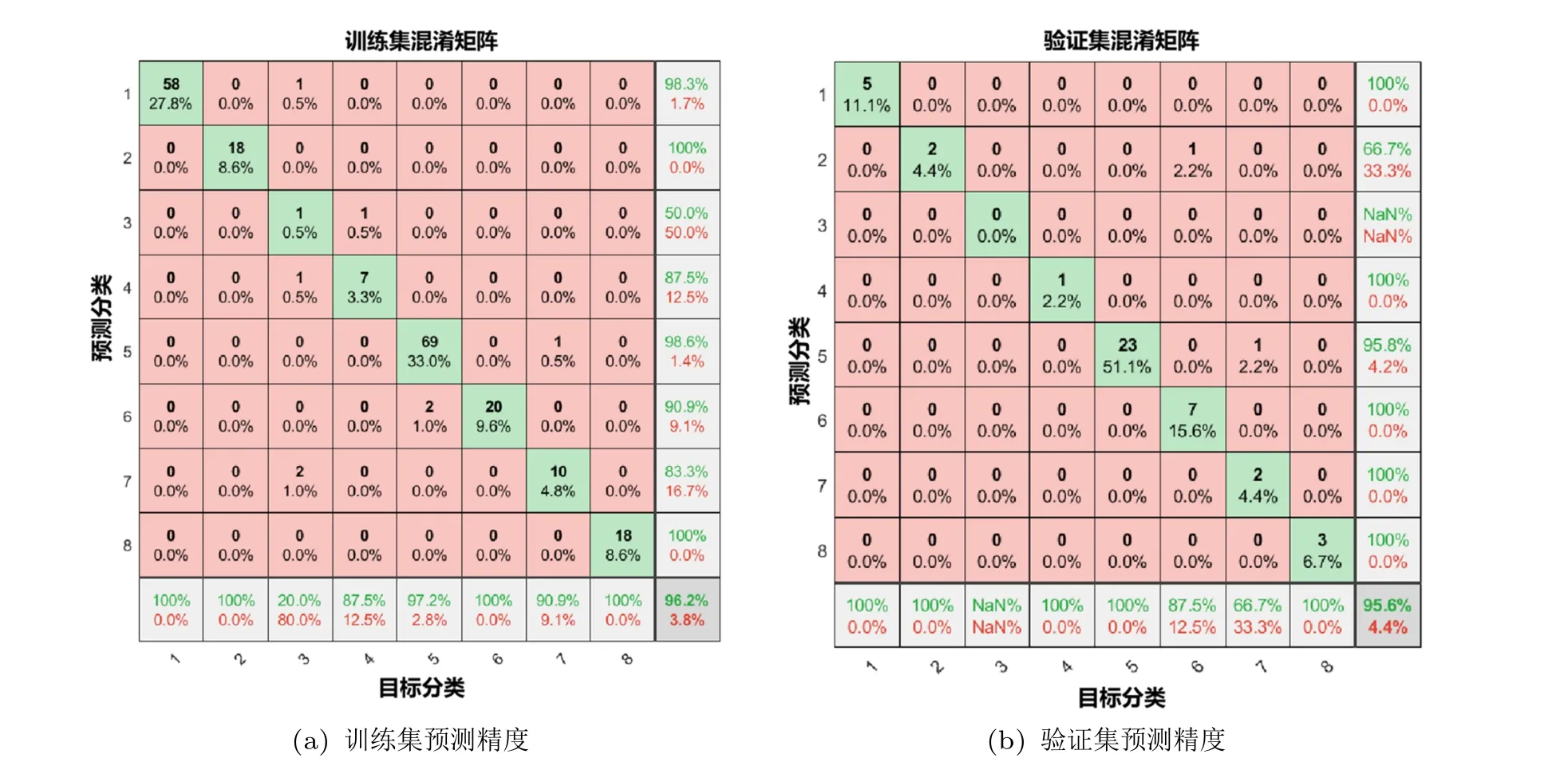
图5 机器学习预测精度
4 结论
材料力学教学中应用人工智能与大数据技术,学生能够认识和解决在拉伸试验因样本差异导致的拉伸性能关键参数不确定性问题。在以后的拉伸性能教学课程中,学生可以基于机器学习模型,快速地判别试验结果的合理性及了解试验结果偏离原因,加深对金属材料变形行为的理解。同时人工智能与大数据技术辅助的教学方法,能够激励学生主动发现问题,培养学生应用多学科知识解决问题的能力,实现学以致用的目的,并推动材料力学教学方式的创新。
猜你喜欢
出版人(2022年8期)2022-08-23
材料与冶金学报(2022年2期)2022-08-10
环球时报(2022-07-13)2022-07-13
交通科技与管理(2022年8期)2022-05-07
建材发展导向(2022年6期)2022-04-18
建材发展导向(2022年6期)2022-04-18
环球时报(2022-03-14)2022-03-14
英语文摘(2020年6期)2020-09-21
电影(2018年8期)2018-09-21
Coco薇(2015年10期)2015-10-19
