
一种基于YOLO的宠物图像识别方法*
2022-03-14 08:45宋广佳胡建华
科技与创新 2022年5期
汪 洋,宋广佳,胡建华
(浙江农林大学暨阳学院,浙江 绍兴311800)
早期的目标检测方法通常是通过提取图像的一些robust的特征(如Haar、SIFT、HOG等),使用DPM(Deformable Parts Model)模型,用滑动窗口(Silding Window)的方式来预测具有较高score的bounding box[1-2]。这种方式非常耗时,而且精度不高。近年来,随着人工智能的强势崛起,机器学习、大数据、各种生物识别技术发展迅速,其中就包括了宠物识别[3-5]。在大数据时代,它更加复杂且更加强大的深度学习模型更能深刻揭示海量数据里所承载的复杂而丰富的信息,有利于对未来或未知事件做更精准的预测。这使人们开始研究宠物识别,在机器识别代替真人工作的模式上有了重大突破[6-9]。
随着深度学习的开发和研究,越来越多的人认识到了机器识别带来的方便和快捷,计算机往往比人类自己本身更加准确和有效率。所以许多的识别框架被开发了出来,比如CNN、SSD、YOLO(You Only Look Once)等一系列优秀的智能识别算法。其中基于回归方法类的检测算法YOLOv3受到了大众的欢迎。YOLOv3是Redmon基于YOLOv2的改进算法,不同于YOLOv2的网络结构Darnet19,YOLOv3使用了新的结构,其中有大量的3×3、1×1的卷积层,一共为53个卷积层从而命名为Darnet53,并且YOLOv3使用多个独立逻辑回归分类器,可以对每个物体进行是否属于当前标签的判断,实现了多标签分类。本文则利用YOLOv3方法实现了对宠物图片的智能识别,新的宠物识别方法速度快、精度高,具有很高的理论和实践价值。
1 研究背景
20世纪80年代末期,人工神经网络的反向传播算法(Back Propagation算法或者BP算法)的出现给机器学习带来了希望,掀起了基于统计模型的机器学习热潮。人们发现,利用BP算法可以让一个人工神经网络模型从大量训练样本中学习出统计规律,从而对未知事件做预测。这种基于统计的机器学习方法比起过去基于人工规则的系统,在很多方面显示出优越性。这个时候的人工神经网络,虽然也被称作多层感知机(Multi-layer Perceptron),但实际上是一种只含有一层隐层节点的浅层模型。2006年,加拿大多伦多大学教授、机器学习领域专家GEOFFREY H和他的学生RUSLAN S在《Neural computation》上发表了一篇文章,开启了深度学习在学术界和工业界的浪潮。
随后Google、微软、百度等知名的拥有大数据的高科技公司争相投入资源,占领深度学习的技术制高点。在大数据时代,更加复杂且更加强大的深度模型更能深刻揭示海量数据里所承载的复杂而丰富的信息,并对未来或未知事件做更精准的预测。宠物图像处理是图像处理中与人脸检测同样重要的研究课题,其研究成果在人们生活的方方面面都有广泛应用。图像处理技术是在第三代计算机问世后才得到了迅速发展,它的快速发展使所有图像处理的问题都可以由数字信号来处理,这为接下来的各种由图像处理引伸出来的应用打下了基础。在国际上,图像处理的研究大概始于20世纪60年代,因为图像所含的信息量巨大,为了达到实验得处理要求,现在的图像处理系统都采用了高性能、高速度的处理器。
随着近些年来国内宠物市场的发展,一直滞后的宠物识别领域也受到了空前的重视,通过深度学习对图片中数据进行采集,然后进行机器学习式的卷积神经网络训练,计算机能轻易地识别各种宠物类别。由于宠物图像处理的数据量大、相关性高,机器识别方法突破了识别物体对于人的局限性,大大减轻了人类的工作量,系统运行成本低,实现简单,为产品的大众化提供了理论和技术支持。
最重要的是在众多深度学习的优秀算法中,SSD和CNN由于复杂度过高,在性能较好的GPU中也依旧运行比较缓慢,而YOLO系列就解决了此类问题,进一步增强了描述特征的能力,使它在即使很小的检测处理目标中也能脱颖而出,使人工智能更加的亲民化。此外YOLO还将预测层的softmax函数改为了logistic函数,大大提高了检测能力。YOLO的特点是可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。YOLO没有选择滑动窗口(Silding Window)或提取proposal的方式训练网络,而是直接选用整图训练模型,这样做的好处在于可以更好地区分目标和背景区域。
2 基于YOLOv3的宠物识别方法
YOLOv3是一种利用坐标的端点卷积神经网络,算法将检测的目标分为区域检测和类别检测,使用单个卷积神经网络来预测被选中目标类别的概率。YOLOv2的基础网络十分简单,且精准度不够,YOLOv3在YOLOv2的基础上利用深度残差网络提取图像特征,获得了很好的检测准确度和速度。YOLOv3采用多个scale融合的方式做预测,算法工作流程如图1所示。首先设计passthrough layer,假设最后提取的feature map的size是13×13,那么passthrough的作用就是将前面一层的26×26的feature map和本层的13×13的feature map进行连接。算法将图像划分为一个S×S的网格,当检测目标落在某个网格中,那么这个网格就是检测对应物体的标准,同时每个网格预测N个目标窗口,而每个窗口都有5个参数的运算,分别是目标的中心坐标(x,y)、目标的高度(height)、目标的宽度(width)和它的置信度概率(confidence),利用NMS算法进行迭代、遍历、消除的过程,最终输出置信度最高的目标。
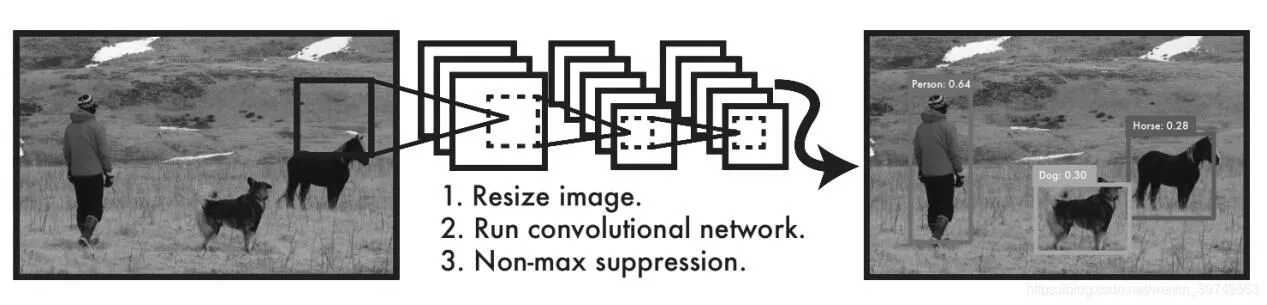
图1 YOLO检测流程图
YOLOv3使用了FPN(feature pyramid networks)的想法,在3种不同的规模上预测,13×13、26×26、52×52。网络结构(Darknet-53)一方面基本采用全卷积,另一方面引入了residual结构,克服了YOLOv2中类似VGG那样直筒型的网络结构,层数太多训起来会有梯度问题,得益于ResNet的residual结构,训深层网络难度大大减小,因此这里可以将网络做到53层,精度提升比较明显。
3 实验结果
实验环境为Windows10,Intel i9 10900x CPU,32G DDR 2600 Memory,IDE为Anaconda,代码库TensorFlow1.10、pillow6.2.0、keras2.2.4、matpkotlib3.1.1、opencv-python 4.1.1.26。
利用数据集,分别把猫、狗分成6类,每组3类,根据上述修改相应的配置数据后使用python train.py跑训练集,经过200次训练后,得到权重.h5文件,在Anaconda Prompt控制台运行python yolo_video.py--image,得到输出结果。因为本次实验设备有限,在训练次数不够多时,结果并不理想,在置信度高时无法选中被检测目标,所以修改置信度为0.000 01得到实验结果。
YOLOv3用于提取特征的最小特征图,尺寸大小仅为13×13,相对于SSD中的1×1仍然严重偏大。在使用了pycharm框架后,方便了自行设计参数,如类别、分类、置信度等,并且提供的是图形化界面,省去之前用命令行操作时间,大大简化了测试步骤,美化了测试界面,并且可直接将训练完成的数据集改成自己想要的几类检测对象,可轻易地实现对目标的检测效果,并且准确率较高。
实验中发现pycharm上检测并不完美,加上数据集和训练集训练次数的区别,如果2种动物的检测数据集外貌相近,提取的特征值相接近,无法十分准确地区分正确的宠物类别,使本实验中对于相近动物的区分检测效果差,产生误检、漏检等问题。采用一张3只羊的图片,1、2号框为检测到目标为羊,3号框为检测到目标为狗,此时置信度为0.6,检测效果如图2所示。

图2 误检图
当设置置信度为0.8时,左右两边的检测目标消失了,同时产生了漏检和误检的问题,结果如图3所示。这与训练次数有关,可以通过增加训练次数来提高检测正确率。
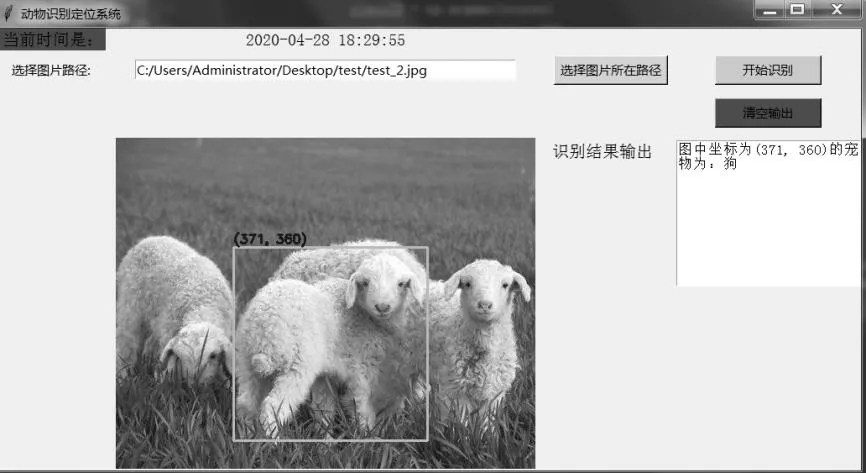
图3 漏检图
调整完参数后,放入检测图片,准确度可达到90%以上,结果如图4所示。
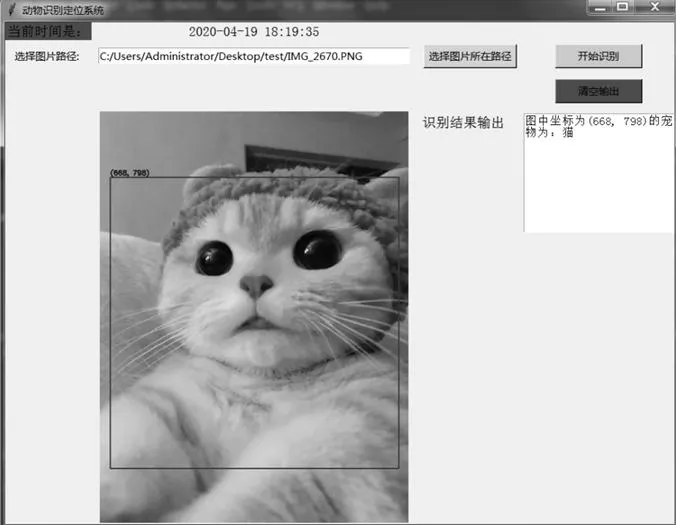
图4 检测结果图
4 结论
通过对本系统的测试,发现了依然存在着许多的问题,在Windows系统下的检测需要相应的配置,在GPU的训练环境下会比CPU快许多倍,并且在命令控制台运行时有诸多的不方便,使其难以得到推广。在Pycharm上则要方便许多,更容易进行错误排查与调试。YOLOv3的算法并不完美,在识别不同种类外形相近的宠物时,准确率还有待提高,但利用YOLO算法中的tiny-model可以减少CPU占用率而提升训练效率。batch_size是训练批次大小,数据集大的时候,batch_size越大跑得越快,但过大会显存不足,5G显存最好是16或者32。epochs是训练次数,数据集越大,需要的epochs越大,loss要降到5左右,如果没到,继续增大epochs。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年7期)2022-07-09
电脑知识与技术(2022年9期)2022-05-10
电脑知识与技术(2022年9期)2022-05-10
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
儿童故事画报·智力大王(2016年6期)2016-09-14
上海故事(2015年10期)2015-12-03
