
基于秘密分享和SWT的数字音频水印算法
2022-03-22 03:33马建芬张朝霞
计算机工程与设计 2022年3期
李 佳,马建芬+,张朝霞
(1.太原理工大学 信息与计算机学院,山西 晋中 030600; 2.太原理工大学 物理与光电工程学院,山西 晋中 030600)
0 引 言
数字音频水印技术可以解决音频的版权保护问题。根据在嵌入过程中对原始音频不同的处理方式,水印算法可分为时域和频域两大类[1]。基于时域的音频水印算法是在时间域修改信号样本达到嵌入水印的目的。基于频域的音频水印算法是利用人类的视觉和听觉特性,将音频信号在频域内进行处理,使用离散小波变换(DWT)[2,3]和DCT[3-7]居多,但是大多数变换不能保证信号的平移不变性。Aniruddha Kanhe等[5]提出一种基于DCT-SVD的音频水印技术,将所有低频高能帧的DCT系数以矩阵形式排列,并对这些矩阵进行奇异值分解(SVD),分解后得到奇异矩阵,将水印嵌入在这些奇异矩阵的非对角元素中。实验结果表明,该算法对常见攻击具有较强的鲁棒性,但并未给出对于同步攻击的效果。A R Elshazly等[6]提出一种基于同步攻击的DWT-SVD-QIM的音频水印技术。对每帧音频的DWT系数进行SVD处理,利用量化指数调制(QIM)将同步码和水印嵌入到奇异矩阵中。实验结果表明,该算法具有很强的鲁棒性,但导致了不可感知性,且有效载荷没有明显提高。有些算法[6,7]不会对原始图像(水印信息)进行加密处理,有些则是利用传统图像置乱技术[8,9]等对原始图像预处理,均是将原始图像的完整信息嵌入到原始音频中,很容易被篡改或伪造,安全性较差。
为了有效解决上诉问题,本文提出的算法利用了Shamir的秘密分享方案对水印信息进行处理;在频域内,利用SWT平移不变性,将水印嵌入根据水印特征产生的哈希码选定的浊音帧中。这样既可以实现水印信息的高安全性,也可以有效解决不可感知性,以及鲁棒性和有效载荷的权衡问题。
1 理论基础
1.1 Shamir的秘密分享方案
Shamir的(k,n)门限秘密分享方案[10]的基本思想是:首先将秘密信息R分解为n份无意义信息;然后,将n份无意义信息发放给n名参与者;最后,只要取其中任意k(k≤n) 份无意义信息就可以完全恢复秘密信息R。
定义一个k-1次多项式q(x),如式(1)所示。对输入值x1,x2,…,xn分别计算R1=q(x1),R2=q(x2),…,Rn=q(xn), 产生n份无意义信息 (x1,R1),(x2,R2),…,(xn,Rn), 任取k份无意义信息通过计算拉格朗日插值得到秘密信息R
q(x)=m0+m1x+m2x2+…+mk-1xk-1
(1)
式中:令m0=R。m1,m2,…,mk-1和n的取值范围为[0,p),p为素数。
令原始图像为秘密信息R,则Shamir的(k,n)门限秘密分享方案可描述为:将一张原始图像分解成n张无意义图像,任何其中一张均无法独自恢复出原始图像,只有把其中的任意k张联合起来才能恢复出原始图像。
1.2 区块链技术
区块链[11]是一种分布式数据库,通过去中心化,去信任的方式,集体维护的一个可靠数据库,区块链对数据进行管理时,具有不可伪造、全程留痕、可以追溯、公开透明和集体维护等特征,其安全性远高于中心化存储。
孟昭雄等[11]提出了一种基于数字水印及其信息的版权管理系统的设计方案,其中利用区块链技术安全存储水印信息,将区块链技术和数字水印技术结合起来,更有利于数字版权的保护。
所以在此启发下,本文首先利用1.1节所提及的Shamir的秘密分享方案对原始水印信息进行处理之后,得到的n份无意义信息可以进行分别存储,其中一份嵌入原始音频当中,剩余n-1份存储于区块链中,这样可以大大提高水印信息的安全性。
1.3 平稳小波变换
平稳小波变换(SWT)[12]又称小波多孔变换,是通过在滤波器各点间插入适当数目的零点再做卷积而得到的。SWT的分解如图1所示。

图1 SWT分解
其中:x(z)是序列 {xt} 的z变换,根据z变换的等效易位性质,h(z)是低通滤波器 {ht} 的z变换。g(z)是高通滤波器 {gt} 的z变换,j为分解级数。dj-1(z),dj-2(z),dj-3(z) 相当于将xj(z) 中各采样点处的小波变换全部计算出来。
和大家所熟知的DWT相比,SWT的优势在于对信号滤波后不进行下采样,能够保证信号的冗余性与平移不变性。SWT在图像水印技术中有广泛的应用[13,14],但在音频水印中应用极少[15]。由于DCT具有强大的能量压缩和去相关能力[5],而经过SD获得的正交矩阵的第一列向量的元素之间具有很强相关性,可以用来隐藏水印数据[7]。本文将SWT引入音频水印处理,并与DCT和SD相结合,这样在各种常规和同步攻击下能够具有很强的鲁棒性。
1.4 hashcode算法
hashcode一般指哈希码,是一种算法,在Java中,哈希码代表一类对象的特征。Java集合类[16]中的Set集合存储无序、不可重复的对象。将String类型的对象存入Set集合的实现类中,Set的实现类将hashCode()方法和equal()方法同时重写后,可以保证不同对象的特征产生的哈希码不重复且具有唯一性。
本文将利用Set集合存储信息的特性,产生的哈希码来选定被嵌入水印的浊音帧,在选定的浊音帧上嵌入水印不仅可以提高不可感知性,还能对同步攻击有良好的鲁棒性。
2 基于秘密分享和SWT的数字音频水印算法
本文利用Shamir的(k,n)门限秘密分享方案将原始水印信息分解成n份无意义信息后,将其分发给所有者(版权拥有者)和n-1名被指定的认证人,认证人持有无意义信息分别作为个人信息被安全存储在区块链中,将所有者拥有的无意义信息作为待嵌入图像;对音频信号中的语音信号进行分离得到整个浊音段后,在DCT-SWT-SD域中,待嵌入图像存入到根据原始水印信息特征产生出的哈希码[10]选定的浊音帧中。
本节包括4个主要的程序块:水印信息(原始图像)预处理块、语音信号分离块、嵌入块和提取块。
2.1 水印信息(原始图像)预处理块
采用Shamir的(k,n)门限秘密分享方案处理原始图像R,可表示为R={r(i,j),1≤i≤N1,1≤j≤N2},r(i,j) 代表W的第i行,第j列像素值。具体步骤如下:
步骤1 根据N1和N2生成随机索引值,在索引下随机选取的m0,m1,…,mn的值作为式(1)的系数,令m0=r(i,j)。
步骤2 选择R上n个不同的非零值x1,x2,…,xn, 分别计算r1(i,j)=q(x1),…,rn(i,j)=q(xn)。
步骤3 对R中所有像素值进行步骤1、步骤2的操作,从而得到n份影子图像,可表示为R1={r1(i,j)},…,Rn={rn(i,j)}。
步骤4 使用直方图和余弦距离结合的方法分别计算n张无意义图像与原始图像的相关性,相关性最小的无意义图像为待嵌入图像;利用区块链技术可以安全存储个人信息[18],其余n-1张无意义图像交给n-1名认证人分别作为个人信息安全存储在区块链中。任意k-1名认证人持有的无意义图像可作为Key1。
步骤5 Logistic混沌映射[9]是一种动力系统,其定义如式(2)所示。其中:μ为分支参数,Xk表示当前状态,Xk∈(0,1)。 当3.5699456≤μ≤4时,初始值X0在Logistic映射的作用下所产生的序列 {Xk,k=0,1,2…} 是非周期且不收敛的,即Logistic映射处于混沌状态
Xk=μXk(1-Xk)
(2)
将X0=0.2和μ=3.7联合作为Key2,所获得的混沌序列对待嵌入图像进行加密处理,得到加密图像W,可表示为W={w(i,j),1≤i≤N1,1≤j≤N2}。w(i,j) 代表W的第i行,第j列像素值。
步骤6 为了将W成功嵌入音频载体中,需要先对W进行降维处理。通过式(3)完成降维操作,最终得到一维序列Wd
Wd={wd(e,1)=w(i,j)}N=N1×N2,1≤e≤N
(3)
2.2 语音信号分离块
本文将原始音频中的语音提取出来,对语音进行清浊音分离处理获得浊音。浊音具有低频高能的特性,并且将水印只嵌入到浊音中能有效提高水印的不可感知性。本文采用短时能量(short-time energy,STE)与短时过零率(short-time zero crossing rate,ZCR)[17]两种参数相结合的方法将语音信号分离成3个部分,即清音、浊音与无声段。具体步骤如下:
步骤1 对语音信号x(t)进行加汉明窗处理,得到处理后的语音信号s(t)。
步骤2 利用式(4)和式(5)计算每帧语音的能量Et和过零率Zt, 计算参数EZ=Et.*Zt
(4)

(5)
其中

步骤3 经过大量实验统计得到的阈值T1和T2, 若EZ 在频域内,将水印嵌入到指定的浊音帧中,嵌入过程的结构如图2所示。具体步骤如下: 步骤1 将原始音频信号Yaudio经过处理提取到一维原始语音信号Yspeech, 可表示为Yspeech={y1,y2,…,yt}, 对Yspeech进行清浊音分离获到整个浊音段并分帧,每帧长为1024,帧总数为M。 步骤2 将原始图像R转换为字符串信息,随机分割为K份子字符串信息,K可以根据用户的需求进行取值。每一份子信息作为String对象存入Set的实现类的过程中,舍弃重复信息同时生成哈希码,挑选其中的N组哈希码H={H1,H2,…,HN}, 挑选规则为每个哈希码均小于浊音帧总数M。根据N组哈希码选择的浊音帧表示为V={VH1,VH2,…,VHN}, 要求K≥N,HN≤M, 每取两帧进行嵌入水印。 步骤3 两帧浊音分别表示为V1和V2。 分别进行DCT操作,获得变换系数D1和D2。 分别对D1和D2进行三层SWT操作,得到不同分量。取第三层子带的低频分量C1和C2, 利用式(6)计算所有嵌入位的数值之和Si (6) 步骤4C1和C2经过矩阵运算分别排列为矩阵A1和A2。 行数和列数为32。使用式(7)对A1和A2进行SD分解,得到正交矩阵U1和U2和上三角矩阵T1和T2, 由于U1和U2的第一列向量u1各自元素间的强相关性,本文采用嵌入规则8,9嵌入水印比特位。得到U′1和U′2 A=[u1u2…uv]×T×[u1u2…uv]-1=U×T×U-1 (7) (8) (9) 其中, 2 步骤5 将U′1和U′2与原来的T1和T2进行逆SD之后得到C′1和C′2, 利用式(6)计算所有嵌入位的数值之和S′i。 重复步骤4、步骤5。 步骤6 将最终的C′1和C′2, 经过SWT逆变换,得到D′1和D′2, 在经过DCT逆变换,得到V′1和V′2即含水印的两帧语音。依次每取两帧浊音,重复执行步骤3~步骤6。最终得到含水印浊音帧表示为V′={V′H1,V′H2,…,V′HN}, 然后与未选定的浊音帧进行帧合并处理得到含水印的整个浊音段V′。 步骤7 将整个含水印的浊音段和清音段合并得到含水印的语音信号Y′speech={y′1,y′2,…,y′t}。Y′speech经过处理恢复为含水印的音频信号Y′audio。 图2 嵌入过程的结构 提取过程的初始步骤与嵌入过程相同。提取过程的结构如图3所示。具体步骤如下: 步骤1 含水印的音频信号Y′audio经过处理提取到一维含水印的语音信号Y′speech, 可表示为Y′speech={y′1,y′2,…,y′t}, 对进行Y′speech分离获得整个含水印的浊音段V′并分帧,每帧长为1024,帧总数为M,选择嵌入过程中使用的N组哈希码确定含水印的N组浊音帧,表示为V′={V′H1,V′H2,…,V′HN}, 每取两帧进行提取水印。 步骤2 两帧浊音分别可表示为V′1和V′2。 分别进行DCT操作,获得变换系数D′1和D′2。 步骤3 分别对D′1和D′2进行三层SWT操作,得到不同分量。取第三层子带的低频分量C′1和C′2, 利用式(10)计算所有嵌入位的数值之和S′i (10) 步骤4 利用式(11)提取一维水印数据W′d (11) 步骤5 将W′d利用式(12)转换为N1×N2的二维数据W′, 使用Key2进行解密得到二维图像,在结合存储在区块链中的Key1,通过Shamir的(k,n)门限秘密分享方案获得提取的可视图像R′ W′={w′(i,j)=W′d(e,1)}, 1≤i≤N1, 1≤j≤N2, 1≤e≤N (12) 图3 提取过程的结构 在本节中将会介绍所使用的实验配置和性能测试。为了有效验证本算法的安全性、不可感知性、有效载荷和鲁棒性。原始图像选用了32×32的二值图像,采用的音频类型为音乐类型,在Mir-1K音乐数据库[5]上进行了测试。该数据库包含110首由男性和女性业余爱好者演唱的卡拉OK流行歌曲中的1000首歌曲音频,采样率为44.1 kHz。本文将其处理为100首音频,平均时长为90 s。利用了Adobe Audition软件工具从音乐信号中分离出演唱声音,将水印嵌入在歌唱声音(语音)当中。 本节测试水印信息(原始图像)经过Shamir的(3,6)门限秘密共享方案处理后的安全性,如图4所示。图4(a)为原始图像,图4(b)为获得的6张无意义图像,图4(c)为待嵌入图像使用Logistic混沌映射加密后得到的加密图像,图4(d)为通过错误密钥提取的图像,图4(e)为通过正确密钥提取的图像。 图4 原始图像处理 实验结果表明,用正确的密钥提取的图像与原始图像几乎没有变化,非常清晰,而用错误的密钥提取的图像非常模糊,根本无法获得图像的内容。可以看出该算法中水印信息具有很高的安全性。 不可感知性也被称为隐蔽性或透明性。添加数字水印不会改变音频的感知效果即无法感知数字水印的存在。为了测试嵌入水印对音频信号的影响,本文做了如下实验。 根据1.4节介绍的方法,首先在Eclipse集成开发环境中将图4(a)的原始图像转换为字符串数据后随机分割为2000份子字符串存入Set的实现类HashSet(自动消除重复子字符串)中,遍历得到表示A1035, 即A1035=[/9j/4,QT,…,f/Z], 产生并选出1024组哈希码(无序)表示为H1024=[1,67,…,471], 水印嵌入在相应位置的浊音帧V=[V1,V67,…,V147] 上。其次,使用MATLAB对原始音频进行了仿真。音频信号处理前后波形图如图5所示,图5(a)为原始音频信号波形图,图5(b)为原始语音信号波形图,图5(c)为整个浊点段波形图,图5(d)为加水印的音频信号波形图,图5(e)为含水印的音频信号和原始音频信号之间的误差信号波形图。 图5 音频信号处理前后波形图 可以看出嵌入水印后音频信号的波形没有明显变化。 经过听力测试发现,人耳无法感觉到水印的存在。为了避免主观因素的影响,我们使用式(13)计算信噪比(signal-noise ratio,SNR)[7]来测试该算法的不可感知性。SNR值越大,说明该算法的不可感知性越强 (13) 式中:Yaudio为原始音频信号,Y′audio为嵌入水印后的音频信号,t为音频信号长度。 其次,控制因素α的取值也非常重要。计算100首歌唱声音在α取不同值下的SNR平均值,如图6所示。 图6 α取不同值下的SNR平均值 从图6可以看出,SNR最大可以达到48 dB,最小可以超过43 dB,高于国际唱片业联合会(IFPI)设置的最低要求SNR≥20 dB[1]。高SNR值会增加失真,但会降低提取过程中的误码率。当α=0.11时,将本文提出算法与5种现有的算法进行比较,对比结果见表1。数据显示该算法具有很高的不可感知性。 表1 不同算法得到的SNR和有效载荷的统计结果 有效载荷表示嵌入原始音频信号1 s内的位数。本文实验采用的音频平均时长为90 s,采样率为44.1 kHz,帧时长23 ms,帧长1024,每1024个样本中嵌入一个32位秘密数据,即每23 ms浊音帧中嵌入32位水印数据。使用式(14)计算有效载荷(BPS)[7]为1.39 kbps (14) 式中:Nw b为嵌入水印的比特数,L0为原始音频信号的长度,单位为s。 为了测试本文提出的算法对常规攻击和同步攻击的鲁棒性,本文对含水印的音频信号进行了8种攻击,类型及其具体描述见表2。并使用了相关系数(normalized cross-correlation,NC)和误码率(bit error rate,BER)[8]作为评估标准,对鲁棒性进行了测试。NC和BER的计算公式分别如式(15)和式(16)所示 (15) 式中:N为嵌入和提取的水印序列长度,wd(i) 为原始水印信息;w′d(i) 为提取出的水印信息。BER值越小,则该算法的鲁棒性越好 (16) 式中:嵌入和提取出的水印图像大小为N1×N2,r(i,j) 表示原始水印信息;r′(i,j) 表示提取出的水印信息。如果NC(R,R′) 越接近1,则R和R′的相关度越高; NC(R,R′) 越接近0,则R和R′的相关度越低。 表2 攻击类型及其描述 含水印的音频信号经过以上8种攻击后,得到的平均NC值和提取的可视图像结果见表3。 表3 本文算法在8种攻击下NC的统计结果 从表3的结果可以看出,水印音频信号受到了攻击后,提取的可视图像非常清晰,很容易辨别出其中的内容。水印音频信号几乎不受这些攻击的影响,表明该算法具有很强的鲁棒性。 为了进一步测试该算法的鲁棒性,本文算法和现有的算法在受到8种攻击后得到的鲁棒性指标BER对照结果见表4。其中“-”表示未在本实验中讨论。 表4 不同算法在8种攻击下BER的统计结果 从表4的结果可以看出,未受到攻击时,表4中的算法均能没有错误地恢复出可视图像。本文算法在重采样攻击下的BER为0,因为水印嵌入到浊音的DCT系数中,浊音具有低频高能的特性,并且DCT具有保持形状的特性。表4的所有方法将水印都嵌入到DCT系数或低频DWT系数中,因为低频分量比高频分量具有较小的可感知失真。在受到低通滤波攻击时,因为水印没有嵌入到被滤除的高频分量中,所以BER值较低。文献[7]中,将水印嵌入到全部浊音帧中,而本文提出的算法是将水印嵌入选定的浊音帧中,实验结果表明在常规攻击下BER值比文献[7]低。在同步攻击中,文献[6]是可以通过同步码进一步降低BER,而本文提出算法在没有嵌入同步码的情况下,也能得到较低BER值,说明本文算法同步攻击也具有较强的鲁棒性。 本文从策略上着重探讨了Shamir的秘密共享方案和SWT的优点,利用浊音低频高能的特性和Set集合存储信息的特点,提出了一种可以有效解决不可感知性,有效载荷和鲁棒性之间的权衡问题的高安全性数字音频水印算法。利用Shamir秘密分享方案对原始图像进行处理后再分别存储,待嵌入图像存入根据原始图像特征得到的哈希码选择特定的浊音帧中,在DCT-SWT-SD域中,利用SD后得到的正交矩阵的第一列元素的相关性抵抗各种常规和同步攻击。该算法的有效载荷达到了1.39 kbps。实验结果表明,该方法具有较高的不可感知性。与其它水印算法比较表明,该方法对重采样、重量化、MP3压缩、随机裁剪和抖动等信号攻击具有很强的鲁棒性。 在下一步的研究学习中,可以探究不同类型音乐对该算法性能的影响。由于本文提出的算法只是处理语音部分,对伴奏部分并未修改,适用于除轻音乐以外所有类型的音乐(其中包含语音即歌唱声音),所以针对于适用范围内的音乐,算法的预期效果良好。2.3 嵌入块
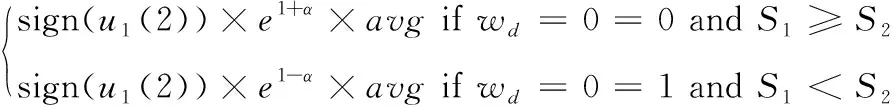

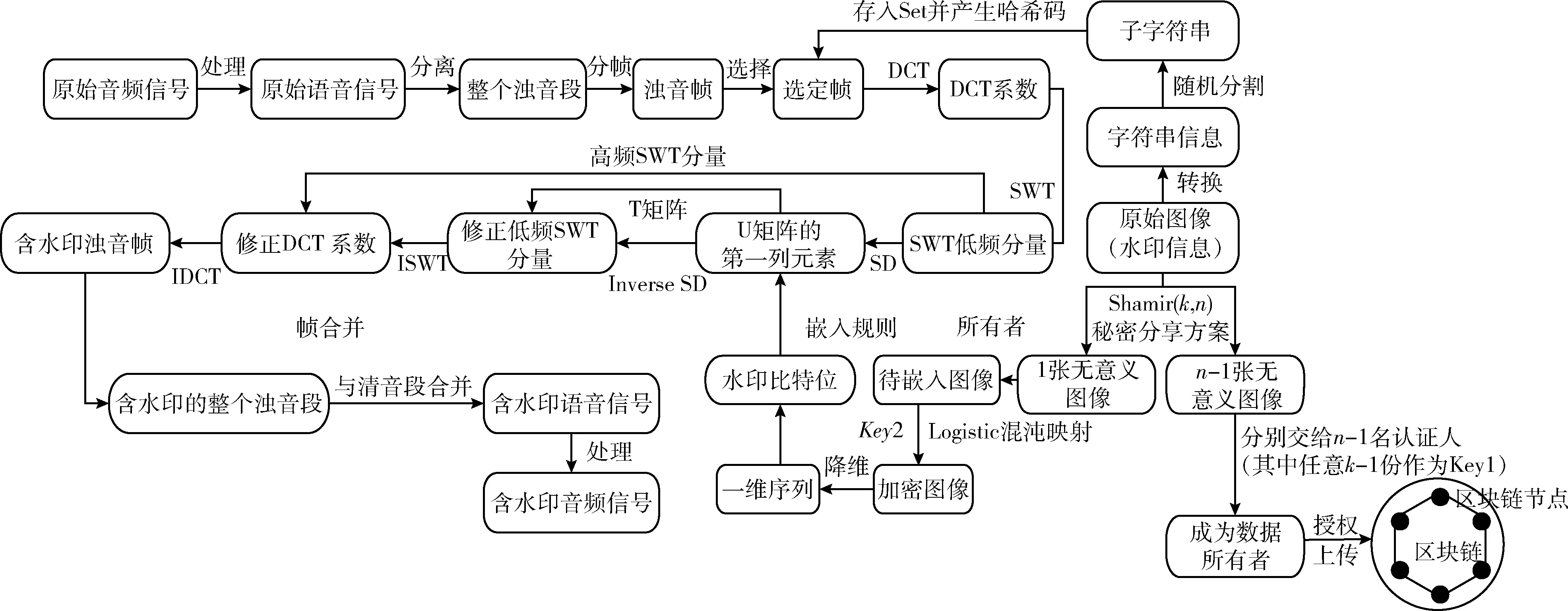
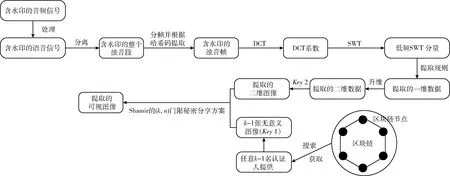
2.4 提取块
3 实 验
3.1 安全性分析

3.2 不可感知性分析
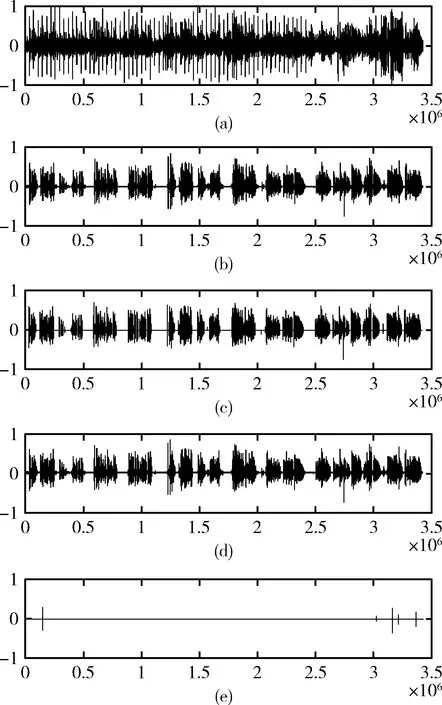

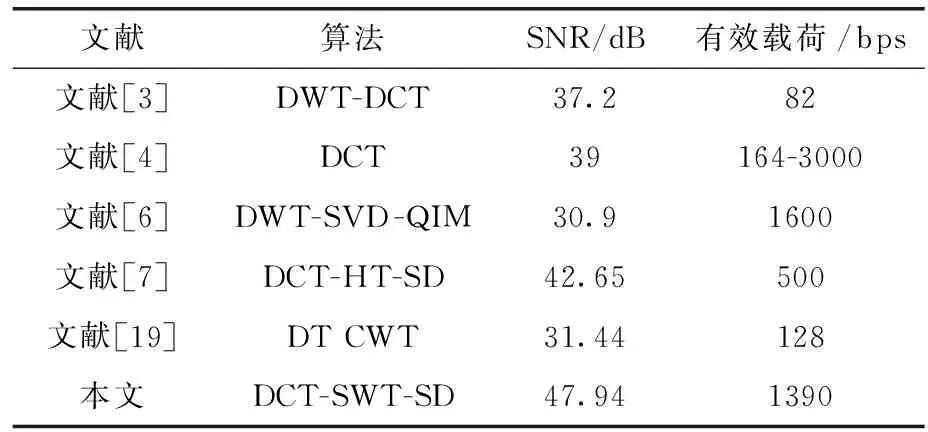
3.3 有效载荷
3.4 鲁棒性分析

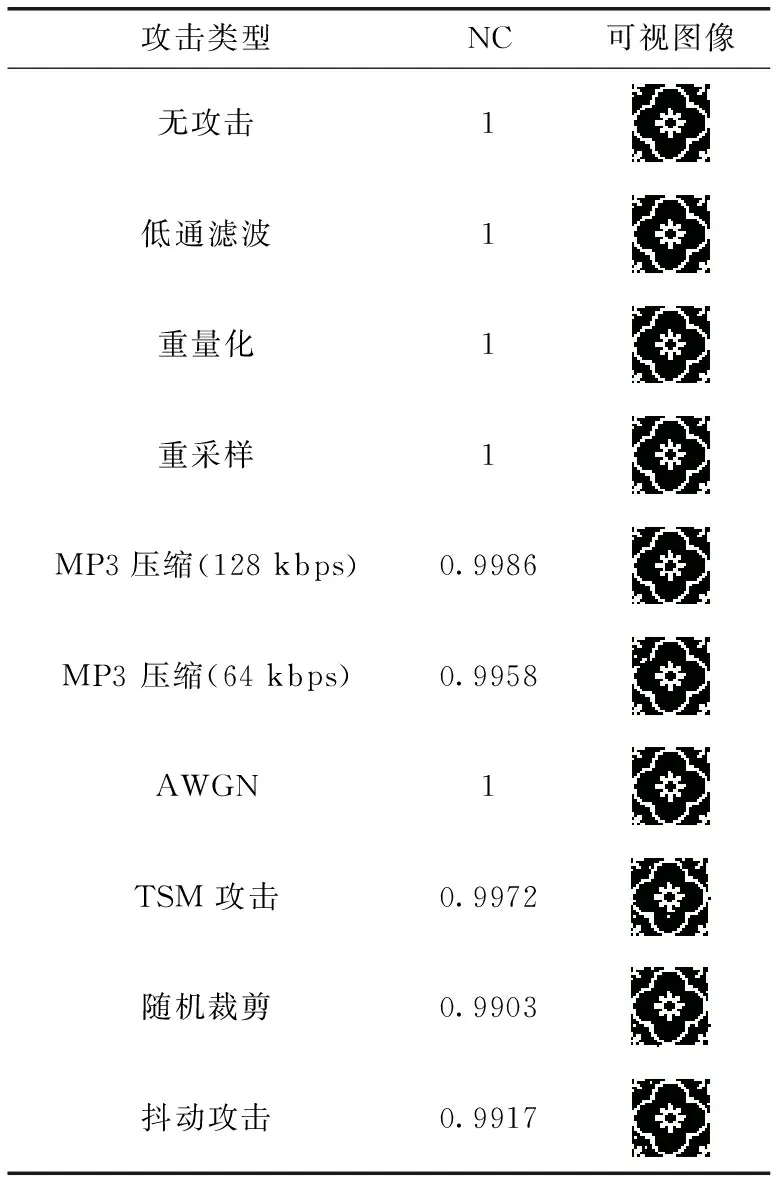

4 结束语
猜你喜欢
大数据(2021年6期)2021-11-22电脑爱好者(2021年8期)2021-04-21科技研究·理论版(2021年22期)2021-04-18电脑爱好者(2020年20期)2020-10-22农业机械学报(2020年2期)2020-03-09中华建设(2019年7期)2019-08-27家庭影院技术(2018年11期)2019-01-21电子制作(2018年19期)2018-11-14电子制作(2017年9期)2017-04-17电脑知识与技术(2016年28期)2016-12-21
