
自注意力机制的短文本分类方法
2022-03-22 03:34陈立潮陆望东潘理虎
计算机工程与设计 2022年3期
陈立潮,秦 杰,陆望东,潘理虎,张 睿
(1.太原科技大学 计算机科学与技术学院,山西 太原 030024; 2.太原政通云科技有限公司,山西 太原 030000)
0 引 言
目前对文本分类研究的方向大致有两个:一是对文本的句子特征和上下文语义信息进行扩展;二是对分类算法、分类模型的选择和创新。对文本句子特征和上下文语义进行拓展可以增加短文本特征的信息量,但也因此会增加许多不属于原有文本的语义信息,从而使最终文本分类的难度增加。而对分类算法和分类模型的创新则很好地避免了引入噪声后带来的对语义信息的干扰。长短时神经网络(long short-term memory,LSTM)[1]是在循环神经网络的基础上改造和发展的一种神经网络模型,可以解决传统人工分类效果不佳的问题,同时解决长期的依赖问题。Lee J Y等[2]提出将RNN、CNN相结合的神经网络分类模型,期望对文本语料分类结果不准确的问题提供新的解决思路和方法;龚千健[3]提出了在短文本分类问题上构建循环神经网络,利用神经网络模型以获取上下文语义进而弥补统计学方法的缺点。关于短文本的分类结果在智能推荐、即时通讯、搜索问答等方面的应用也越来越广阔,但因为上下文语义信息理解不充分,使分类效果不佳进而会导致用户体验变差。因此,研究一种可以充分获取上下文语义,对解决长期依赖关系的短文本分类模型具有重要意义。
为此,提出一种融合对抗训练自注意力多层双向长短期记忆网络模型对短文本进行分类识别,以期通过对抗训练对文本信息进行参数多样性的补充,提高模型的泛化能力并减少过拟合现象的发生,从而达到优化模型,提高分类性能的目的。
1 传统的Bi-LSTM网络
双向长短期记忆神经网络(bidirectional long and short term memory network,Bi-LSTM)的创新点在于弥补了LSTM无法准确解释文本脉络深层逻辑和深层上下文这一不足,运用双向结构可以对文本进行正反两次语义调整,并准确输出信息,使得机器编译训练后的语义更接近语句上下文环境的真实语义。董彦如等[4]提出基于双向长短期记忆网络和标签嵌入的文本分类模型,利用BERT模型提取句子特征,通过Bi-LSTM和注意力机制得到融合重要上、下文信息的文本表示,进行分类。张晓辉等[5]提出基于LSTM的表示学习-文本分类模型,首先对文本进行初始化文本表示,再对模型进行训练提升,提高模型面对复杂样本的准确分类能力,增强模型的泛化性能。陶永才等[6]利用平均池化方法以及最大池化的方法将文本特征做提取,加之注意力机制的不同权重配比,对中文新闻语料做分类。以上方法中,虽然都对单一的LSTM神经网络做了相关改进,在限定领域的部分范围内取得了一定的效果,但改进发展的相关模型都无法将文本信息中隐藏的部分关键联系进行捕获,对比较复杂的语义来说分类效果会有很大不确定性。
万齐斌等[7]提出基于BiLSTM-Attention-CNN混合神经网络的分类处理方法。在注意力机制层之后又进行卷积神经网络的训练,增强了模型特征的表达能力。李文慧等[8]提出Ad-Attention-BiLSTM模型,通过对嵌入层文本进行对抗训练来增加文本的训练过程中的参数更新,提高最终的文本分类准确率。姚苗等[9]提出Att-BiLSTMs模型,使用基于自注意力机制的堆叠双向长短时记忆网络模型。捕获上下文隐藏依赖关系,优化短文本特征稀疏的问题。上述方法中Ad-Attention-BiLSTM模型存在着扰动参数单一化,固定化,无法准确把握噪声大小的缺点;而Att-BiLSTMs模型则没有考虑到文本的健壮性和更深层次参数的重要性。
Bi-LSTM的网络结构如图1所示。图中h(t)代表前一层次的初始数值,w(t)代表词向量。
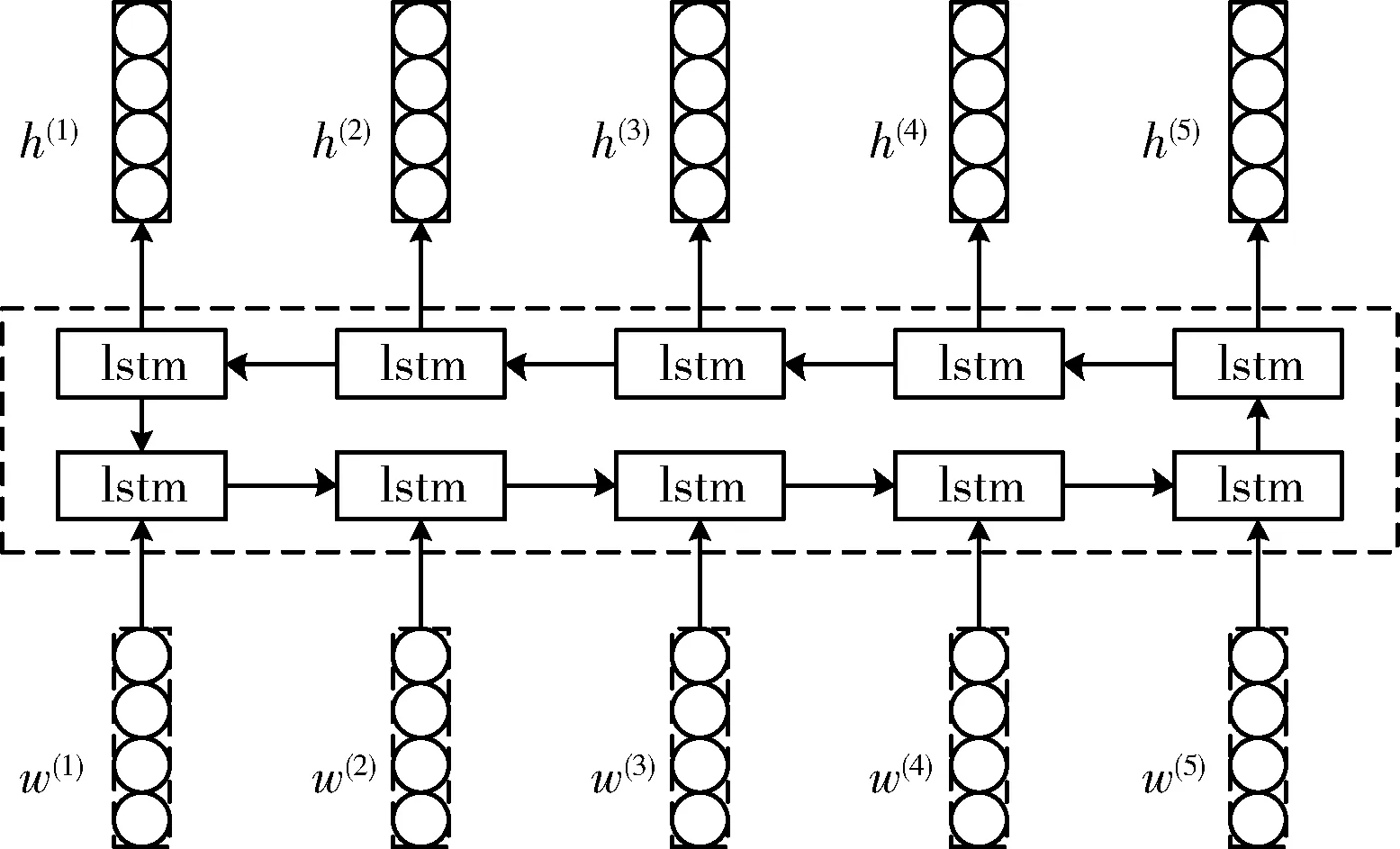
图1 Bi-LSTM网络
2 改进的Con-Att-BiLSTMs模型
考虑到短文本的语义特征较少,同时文本是高维的。故为了实现文本分类的准确率,在传统的Bi-LSTM网络结构上进行改进,提出融合对抗训练自注意力多层双向长短期记忆网络(Con-Att-BiLSTMs)模型,对文本信息进行充分挖掘,并运用了分类对抗训练的方式对模型进行训练。
2.1 文本分类整体架构
文本分类方法的整体架构如图2所示。整体架构包括词嵌入层、Bi-LSTM层、注意力机制层和softmax这4个过程,可分为文本依赖关系学习和局部关键信息学习两个阶段。首先,在文本的嵌入过程中使用对抗训练加Dropout等多种正则化方式结合,并应用自注意力动态调配扰动参数,更合理控制噪声大小,增强模型的健壮性和抗干扰能力;其次,使用双层双向长短期记忆网络交叉获取隐藏在文本深处的参数信息特征信息,挖掘文本中隐藏的深层次关键依赖关系特征,进而获取更深层次的隐含依赖关系。最后,通过注意力机制对短文本中关键信息进行加权,对重要的内容分配更多注意力,再利用softmax分类器进行文本分类。总的来说,所提方法以多层Bi-LSTM网络结构为核心,使用对抗训练是对Bi-LSTM网络健壮性和防止过拟合的保证,而注意力机制是对Bi-LSTM网络捕获信息的突出显示。
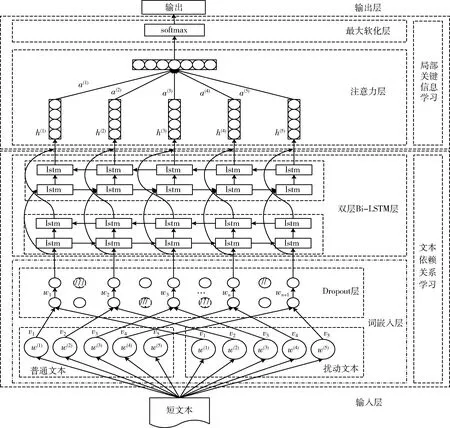
图2 Con-Att-BiLSTMs模型
2.2 噪声注入及对抗训练
深度学习模型在防止模型过拟合的处理以及准确对语义进行泛化方面通常有以下几种解决方法:①使用参数范数惩罚对模型进行简化,增强泛化能力,如L2正则化方法;②增加网络层级,提高抗干扰能力,如使用Dropout;③增加必要的扰动,避免模型过拟合等,如引入对抗训练。
参数范数惩罚、噪声注入及对抗训练都是深度学习的几种正则化的方法之一。使用参数范数惩罚常用的是L2正则化方法,通常将其形容为“正则化逼近”,即通常只惩罚权重,不惩罚偏置。噪声注入的正则化方式又包括:在输入数据中注入噪声(等价于权重的范数惩罚)、向隐藏单元添加噪声(如Dropout)、将噪声添加到权重。对抗训练则是通过产生错误分类模型样本并加入到训练集中,进而对模型的分类准确度进行提升,使之拥有更好的泛化能力。
噪声注入中向隐藏单元注入噪声,如Dropout,原理是让一些参数失效。在每一次的训练中,随机的选取一部分的点,将这些参数进行隐藏,值置为0。因为每一次训练,都隐藏了不同的权值,相当于多次不同新网络的复合叠加,得到各种情况的结果并复合输出,使得获取的信息特征更丰富。此时的网络相比于最初的较复杂的网络进行了简化,从而可以减少过拟合的发生。一般来讲,叠加而成的组合网络要优于单一网络,因为组合网络能够捕捉到更多的随机因素。同样的,采用了Dropout以后,网络的性能一般也比没有使用Dropout的网络要好。
对抗训练也是正则化方法之一。Miyato T等[10]在半监督状态的文本训练分类中加入了对抗训练扰动,并引入虚拟训练,有效避免了过拟合情况的发生。陈润琳等[11]提出将注意力机制与对抗多任务学习相结合,在数据初始时即将注意力机制引入并分出一部分原始文本做对抗集,进行对抗训练,得到多任务分类模型。为避免模型存在着扰动参数单一化、固定化、无法准确把握噪声大小的缺点,故采用对抗训练加Dropout正则化的方式,使用自注意力机制动态分配扰动参数进行输入,通过计算得到不同程度的对抗样本,从而提升模型的性能,防止过拟合。输入层对抗训练扰动模型结构如图3所示。
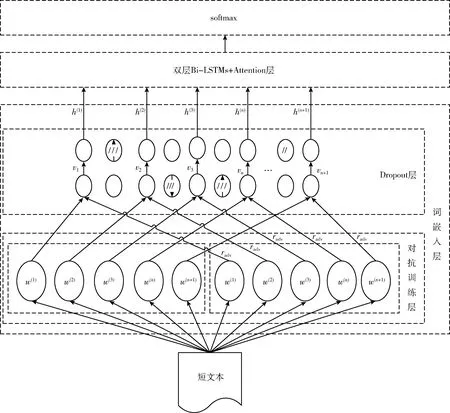
图3 输入层对抗训练扰动模型
2.3 多层Bi-LSTM网络
在Bi-LSTM网络中,不同层级的LSTM有不同的职责,每个LSTM又有输出门、记忆单元、输入门等对数据进行选择性丢弃、更新、输入。这3种机制的运算公式可简单概括为以下公式,激活函数如式(1)所示
sigmoidft=δ(Wf·X+bf)
(1)
输入门信息更新如式(2)所示
it=δ(Wi·X+bi)
(2)
输出门信息更新如式(3)所示
ot=δ(Wo·X+bo)
(3)
单元状态信息更新如式(4)所示
ct=ft⊙ct-1+it⊙tanh(Wc·X+bc)
(4)
t时刻隐层状态信息更新如式(5)所示
h(t)=ot⊙tanh(ct)
(5)

Bi-LSTM双层网络模型结构如图4所示。多重输入更新、多重丢弃、多重输入,使得模型的稳定性和可解释的上下文语义复杂性得到显著提升,有利于对上下文语义依赖关系的深度挖掘。
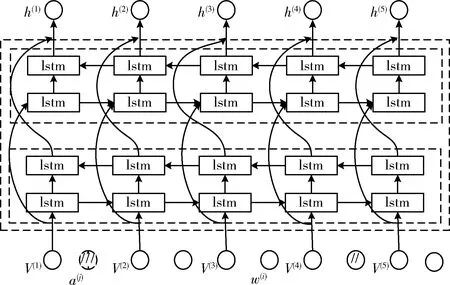
图4 双层Bi-LSTM结构
该模型是充分利用噪声集的优势,在词向量输入多层级的Bi-LSTM结构时加入噪声因素,改变一层不变的词向量特征,深层学习不同特征缺失的情况下语义的不同结果体现。首先,选择合适的数据集并划分噪声集、测试集及训练集;其次,对数据集进行去停用词等处理,加入噪声进行扰动对抗训练,利用多层级的Bi-LSTM结构做反复多轮的训练学习,利用Dropout层随机忽略部分特征的机制,深层学习上下文的语义信息,随之利用嵌入层可以做长远距离学习的特性,对不同时间序列中通过的文本做语义特征输出,转化为向量矩阵;最后利用注意力机制分配不同权重,增强关键词的权重比例,弱化冗余特征的影响。经过多次实验,因为两层Bi-LSTM结构相较于一层和三层等结构有迭代耗时短、训练耗时短、分类准确率较高的优点,且能更好挖掘潜在的上下文依赖关系,故采用两层Bi-LSTM。具体公式如下
e(ωi)=Wwordvi
(6)
(7)

2.4 注意力机制
注意力机制(Attention)是为了反映不同的特征词于整个文本所属类别分类时所贡献的程度而产生的。已在很多领域得到应用,如Kelvin Xu等[12]将注意力机制应用于图像标注,增加了特征属性。Zichao Yang等[13]在RNN中引入注意力机制来解决文本分类问题。自注意力机制(Self-attention)是注意力机制的一种,该机制只对同一层级的信息实现高效并行分析,不需要考虑下一层级的信息。注意力函数本质类似于非关系型数据库,可以将其看作是多个查询(Query)对多个键值对(key-value)的关系映射的集合,每一个键值对都是这个集合内的一个元素,存储时也是按照键值对的形式存入对应元素地址,当进行查询时,存储器就通过映射输出Value值,即Attention值。先使用相似性计算函数,如式(8)
(8)
再用softmax进行归一化处理得到概率分布,如式(9)
(9)
最后根据权重系数对Value进行加权求和,如式(10)
(10)
注意力机制就是对重要的内容分配更多注意力,对其它不太重要的内容分配较少的注意力。相较于直接把输出向量加权取平均,加入注意力机制的Bi-LSTM网络结构,避免了保留原文本大量冗余和噪声的结果再次通过取平均值被保留下来,导致分类精度不足。
3 实验结果与分析
处理器为Inter(R) Core(TM) i5-9300H CPU @2.40 GHz,RAM 16 G。开发环境为python 3.5,使用tensorflow框架,开发工具为JetBrains PyCharm。为验证提出方法的可行性设计了以下实验。
3.1 实验数据集
实验语料来自维基百科的DBpedia分类数据集,该数据集有训练集560 000条,测试集70 000条,总计类别14种。随机选取总训练集的7%(即39 200条)和8%(即44 800条)以及测试集的10%(即7000条)进行实验验证。文本内容由文本标题、文本内容、文本类别组成。
3.2 实验设计
为保证结果的普遍性,采用随机输入的方式进行实验验证。评价指标采用微平均F1值和宏平均F1值。
(1)模型参数设置
详细设置见表1。
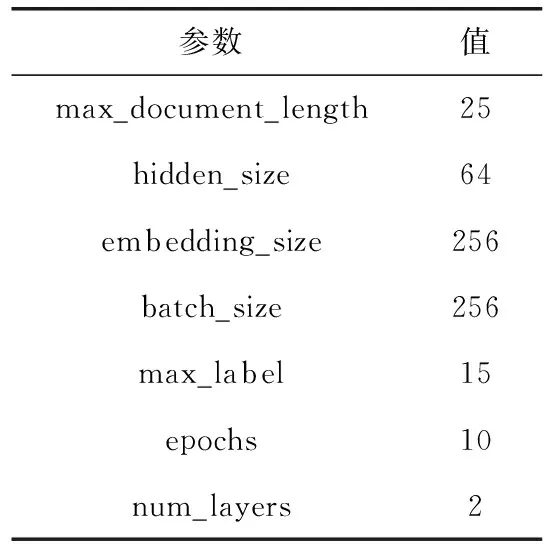
表1 模型参数
max_document_length为最大文档长度,hidden_size为双层Bi-LSTM的隐藏层节点数,embedding_size为词向量维度,batch_size为单次迭代训练批处理样本个数,max_label为最大标签数量,epochs为模型训练达最优的迭代次数,num_layers为Con-Att-BiLSTMs模型中Bi-LSTM的层数。
(2)embedding_size取值对实验结果的影响
在DBpedia数据集中选取39 200条训练集,7000条测试集,对词向量的维度分别取值为64、128、256、512维实验,结果见表2。
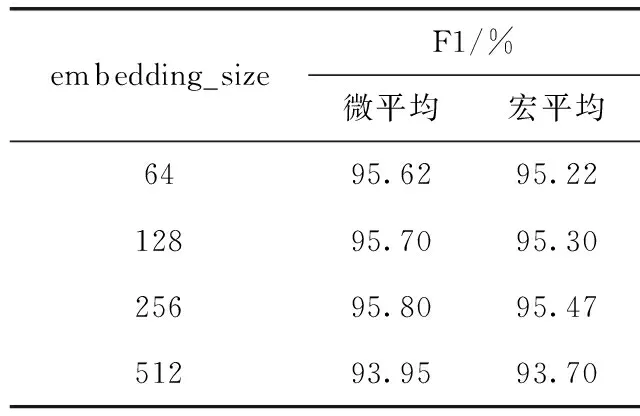
表2 embedding_size与模型性能的关系
从表2对比可以看出,模型的性能随着嵌入维度的变化而变化,但嵌入的维度不能无限制的扩大,否则会导致迭代耗时严重的问题。在选取的4个维度中,当维度到达256时,模型的性能开始达到峰值,微平均和宏平均的F1值都最高,当维度为512时,优于时间开销大大增加,且容易发生过拟合。
(3)num_layers取值对实验结果的影响
Con-Att-BiLSTMs模型中,Bi-LSTM的层数与模型的复杂度和模型的分类性能息息相关。在DBpedia数据集中选取39 200训练集,7000测试集,对num_layers分别取不同的值进行实验,实验结果见表3。
由表3中数据对比可知,Bi-LSTM取值的层数也会直接影响最终模型的性能。当num_layers取值为2时,模型

表3 num_layers与模型性能的关系
的微平均及宏平均都较取值为1和3时有不同程度的提高,这是因为层数少,模型无法深层挖掘潜在上下文关系,层数太多,容易出现过拟合且使得效率变慢。鉴于双层的双向长短期记忆神经网络比之一、三层结构有更明显的运行迭代用时少、效率高的优势,且能充分挖掘深层次依赖关系,所以最终采用两层Bi-LSTM。
3.3 模型对比实验
在DBpedia数据集上,将提出的Con-Att-BiLSTMs方法与短文本分类模型Attention-LSTM、Attention-BiLSTM、Ad-Attention-BiLSTM、CNN-LSTM、Att-BiLSTMs作对比来验证本文提出的方法优劣。结果见表4。
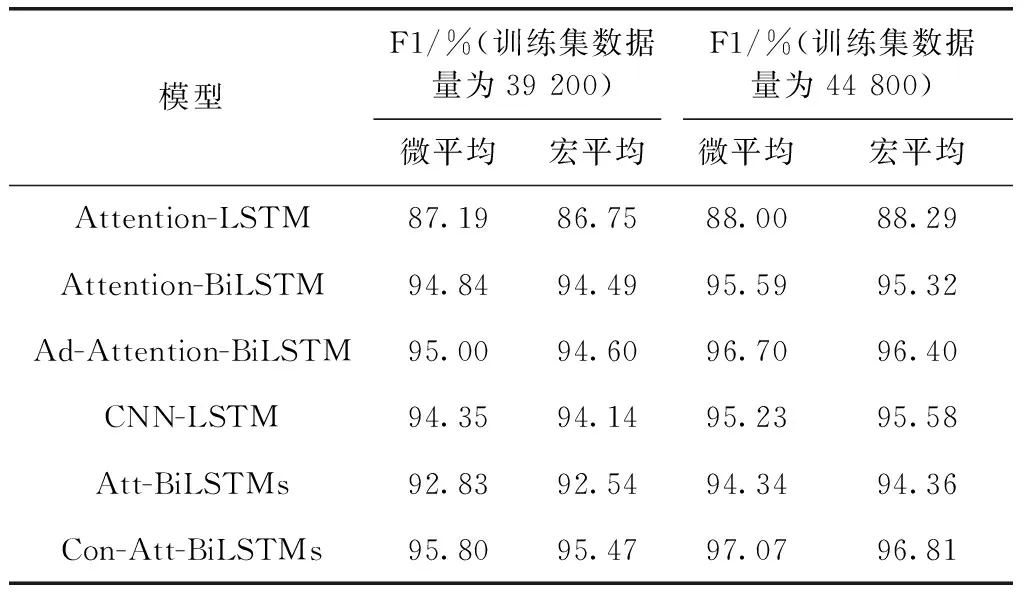
表4 Con-Att-BiLSTMs与其它模型对比
表4实验中的数据集数量占比按总数据集的7%(即39 200条数据)和8%(即44 800条数据)取值。考虑到选取的训练数据集单一时,可能会对模型的反映能力出现偏差,所以选择两组数据作对比参考。
当数据量为39 200条时,Attention-LSTM模型的准确率很低,对文本语义的理解偏差较大,微平均F1值相较于其它模型较低,仅为87.19%,宏平均F1值也较低,为86.75。这是因为Attention-LSTM模型中,单向的长短期记忆网络做不到将语义前文对后文进行反向反馈捕获,导致无法充分的挖掘上下文语义信息。当训练数据量较少时,深度学习模型很难准确学习并找到文本信息准确的语义,但将单向LSTM网络转变为Bi-LSTM网络时,模型对文本上下文信息的挖掘能力得到很大提高,故而Attention-BiLSTM模型的微平均F1和宏平均F1优于Attention-LSTM模型;而当数据集较少时,Attention-BiLSTM模型对文本的冗余特征和非冗余特征的容易发生误判,故会使得分类结果错误的情况发生,当加入噪声进行对抗练习后,模型的健壮性有了很大改观,所以Ad-Attention-BiLSTM模型的微平均F1值和宏平均F1值都略优于Attention-BiLSTM模型。CNN-LSTM模型对CNN网络做了改进并与LSTM进行了结合,但单向的LSTM缺乏对上下文语义信息深度挖掘能力,导致该模型性能较其它几种模型的性能较差。Con-Att-BiLSTMs模型和Att-BiLSTMs模型都使用了双层的Bi-LSTM网络结构,但Con-Att-BiLSTMs模型在对抗训练扰动结合Dropout的正则化方式对嵌入层数据进行增强的基础上,引入自注意力机制加强文本关键信息特征权重并使用双层Bi-LSTM网络对输入的信息进行提取,而且使得模型的微平均F1值和宏平均F1值皆高于其它5种模型,分别为95.80%、95.47%。当数据集为44 800条时,结论与数据量为39 200条时基本一致,因此Con-Att-BiLSTMs模型整体性能要优于其它5种模型。
4 结束语
在实验中,将多种正则化的方式相结合不仅能使模型在做文本分类任务时得到更高的准确率,还提高了词嵌入的质量和实验模型的抗噪声干扰能力,拥有更广泛的代表性和防过拟合能力。当数据集的数量相对较少时,对文本分类也有很高的准确率,但是仍然有不足之处。在对文本中的每个词进行遍历时,迭代过程比较缓慢,准确率得到提高的同时,数据集训练所需时间要略高于其它方法,后续研究考虑使用其它改进方法,缩短迭代的时间并在不同的数据集上进行验证。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
开放教育研究(2020年2期)2020-03-31
劳动保护(2019年3期)2019-05-16
第二课堂(课外活动版)(2016年2期)2016-10-21
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
客车技术与研究(2014年6期)2014-02-28
