
基于循环神经网络的一种在线辅助CVT电压误差测量方法
2022-03-23 06:46陈文中陈俊杰张金丽
东华大学学报(自然科学版) 2022年1期
陈文中, 陈俊杰, 许 侃, 张金丽
(国家电网上海市电力公司电力科学研究院, 上海 200437)
随着科技水平的提高,我国配电网络的覆盖范围越来越广,电力用户的规模也越来越庞大,同时电能计价的细微变化会直接影响大量电力用户的日常生活,因此电能计价的公平性必须得到充分的保障,这对国计民生和国民经济的稳固发展都有着重要的影响。保证电能计价公平性的前提是对电力系统中的电压和电流大小进行精确测量。电容式电压互感器(capacitor voltage transformer,CVT)[1-2]常被广泛应用于100 kV及以上电压等级的电力系统中,以实现一次电压、电流的精确测量。CVT虽然具有绝缘性能好、经济性高等优点,但相比传统的电磁式电压传感器,CVT的电路结构较为复杂,容易受到周围自然环境、电场等外界因素的影响,使其测量稳定性降低。CVT的测量稳定性直接关系到电能计价的公平性。因此,如何准确地评估CVT的计量误差成了很多研究者的研究重点。昌云松等[3]提出一种基于滑动窗口原理和主成分分析的WMPCA(weighted multi-linear principal component analysis)误差评估方法,相比传统的CVT误差评估方法,该方法准确度更高且能够用于评估长期运行的CVT。李朝阳等[4]提出基于多元分析的互感器故障判别算法,该算法能够在不增加额外测量设备的情况下,正确识别出存在故障的互感器。张秋雁等[5]利用前馈神经网络建立数字电量计量系统的数字模型,从而达到正确评估系统误差的目的。但上述文献中提到的评估方法需要用到大量、多维度的离线数据,且需要花费大量的时间进行数据的预处理。
因此,本文提出一种基于RNN(recurrent neural network)[6]的在线辅助CVT电压测量方法,该方法通过收集电力系统中电压的历史数据,利用RNN对电压值的变化趋势进行拟合和建模。完成RNN模型训练之后,把当前时刻和过去几个时刻的电压值作为RNN的输入值,以在线预测未来某个时刻的电压值。将RNN的输出值作为标准值并与CVT的实际测量数值进行误差对比,对CVT的测量稳定性进行评估,从而帮助测量人员及时发现异常的测量值并更换CVT设备,保障电能计价的公平性。该方法不需要使用海量、多维度的离线数据,能够利用RNN对CVT的实际测试值进行误差评估。
1 模型与问题建立
基于RNN的在线辅助CVT电压测量方法的主要流程如图1所示。首先,需要收集以往电力系统中的电压序列作为数据集,将电压序列表示为V=(v1,v2, …,vn),n表示总的序列长度,然后使用数据集来训练RNN模型。简单来讲,训练RNN模型的过程,即利用反向传播算法和梯度下降算法来不断地迭代更新RNN网络中的权重系数,最终使得损失函数达到最小值。常用的梯度下降算法包括随机梯度下降算法(SGD)[7]和Adam梯度下降算法[8]等。最后,利用训练好的RNN模型来实时地预测下一时刻的电压值,并与CVT得到的实测数据进行对比。训练好的RNN模型如式(1)所示。

图1 基于RNN的在线辅助CVT电压误差测量方法的示意图
(1)

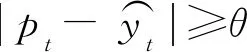
2 算法设计
2.1 RNN的网络结构
RNN是在神经网络的基础上进行拓展得到的。神经网络具有逼近任意一个函数的特点,因此该算法被广泛应用在生物、医疗、计算机、通信等多个领域[9-10]。神经网络的核心算法是向量乘法,并通过引入激活函数[11]来增加其拟合非线性函数的能力。
电力系统中的电压值随时间的变化趋势可以看作是一个时间序列[12],即当前时刻的电压值和前一时刻(或前几个时刻)的电压值存在着某种函数映射关系。因此,选择神经网络来逼近这一映射关系。但由于在传统的BP神经网络[13]或者卷积神经网络[14](convolutional neural network,CNN)中,当前时刻的输入值与上一时刻的输入值是相互独立的,因此这两者都不适合用来对时间序列进行建模。而RNN很好地弥补了BP神经网络和CNN没有“记忆能力”的缺点。
RNN简易的示意图如图2所示。由图2可知,RNN除了包含输入层、隐藏层和输出层以外,多了一个循环层,便于完成“记忆”的功能。

图2 RNN的结构示意图
其中:xt为RNN的输入向量(下标t表示当前时刻),其长度等于输入数据的维度;yt为RNN的输出向量;W1为输入层到隐藏层这两者之间的权重系数矩阵;st为隐藏层的值,其长度等于隐藏层神经元的个数;W2为隐藏层到输出层这两者之间的权重系数矩阵;W3为前一时刻的隐藏层st-1作为当前时刻的输入信息时,要相乘的权重系数矩阵;yt和st分别如式(3)和(4)所示。
yt=g(st·W2)
(3)
st=h(xt·W1+W3·st-1)
(4)
式中:g(·)和h(·)是激活函数,能够让RNN更好地拟合非线性函数。
从式(4)中可以看到,隐藏层st不仅与当前时刻的输入值xt有关,也取决于上一时刻的隐藏层st-1。接着,把式(4)不断地代入式(3)中,可得
yt=g(h(xt·W1+W3·st-1)·W2)
(5)
yt=g(h(xt·W1+W3·h(xt-1·W1+W3·st-2))·W2)
(6)
yt=g(h(xt·W1+W3·h(xt-1·W1+W3·h(xt-2·W1+…)))·W2)
(7)
输出层的值yt与当前时刻的输入值xt,以及过去时刻的输入值xt-1、xt-2、…都有一定的关系。式(5)非常直观地体现了RNN具有“记忆”功能这一特点。
2.2 训练RNN模型
首先,在使用电压序列训练RNN之前,需要对其进行数据清洗、归一化等预处理操作,对电压序列进行归一化的主要目的是为了让RNN模型更快地收敛。归一化的具体方式可由式(8)表示。
(8)
式中:vi为某一时刻的电压值;vmax为电压序列中的最大值;vmin为电压序列中的最小值;v′为归一化后的值。
接着,需要从经过归一化的电压序列中生成训练RNN所需的数据集。数据集中包含多行数据,每行数据由输入值和对应的标签两部分组成。把每3个连续的序列值作为一行数据,其中(vi-2,vi-1)作为输入值,vi则作为对应的标签,下标i满足2≤i≤n。得到的数据集需要进一步分成训练集和测试集:训练集用于训练RNN,测试集用于评估RNN的性能好坏。然后,把RNN输出层的预测值与标签值的均方误差作为损失函数来训练RNN。RNN损失函数如式(9)所示。
(9)
式中:L代表损失函数,w表示RNN中所有的权重参数;yi表示第i条数据经过RNN后得到的预测值;K表示训练集中样本的个数。随后,利用梯度下降算法不断更新RNN网络的权重系数以使损失函数L(w)的值最小化。权重系数的更新方式如式(10)所示:

(10)

当模型训练完成之后,需要使用测试集对模型的性能进行评估。当模型的性能较差时,则需要不断地调整学习率、神经元个数等超参数。
3 仿真试验
使用澳大利亚国家电力市场提供的2021年6月的电力负载数据集[16]进行仿真。原始的数据集中包含区域编号、采样时间点、总的电力负载值和当时的电价,本次仿真试验只使用其中的电力负载数据。该数据集包含了1 440个样本点,每间隔30 min进行一次采样。试验选择前400个样本点进行测试。该数据集的特征如图3所示。

图3 仿真数据集的特征图
仿真使用的RNN模型包含1个输入层、1个隐藏层(含32个神经元)、1个全连接层和1个输出层。其中输入层神经元的个数是2,包含t-1时刻和t-2时刻的负载值;输出层的神经元个数是1,即t时刻的负载值。学习率α设为0.01,并以7∶3的比例将数据集分成训练集和测试集两个部分。此外,选择Adam梯度下降算法来更新RNN模型中的权重系数。
3.1 不同的学习率对RNN收敛性能的影响
图4展示了不同大小的学习率对RNN收敛性能的影响。从图4可以看出,当学习率α的值越小时,均方误差下降得越慢,因此需要更多的迭代次数才能让RNN收敛。当迭代次数足够多时,RNN模型最终都能成功收敛。但当α过大时(α=0.900时),则损失函数达不到最低点,导致最终的均方误差过大。因此,要适当地调整学习率α的大小才能使RNN的性能达到最优,α过小则收敛速度较慢,α过大则均方误差较大,导致RNN最终的性能较差。

图4 均方误差与迭代次数之间的关系
在4种不同学习率下训练得到的RNN模型上,利用测试集来检验RNN的拟合效果,并与数据集中的原始数据进行比较。图5为不同学习率下的预测电压值。由图5可以看出:当学习率α为0.900时,得到的RNN性能非常差,几乎没有学习到电压序列的相关特征;当α为0.010时,RNN的性能最优,得到的预测值基本上与原始的电压序列相互重合。表1列出了在不同学习率下的测试集的均方误差。从表中能清楚地看到,当学习率α为0.900和0.001时,均方误差较大。前者是由于α偏大,导致权重系数在最优解的附近反复横跳,始终无法到达损失函数的最优解。而后者是由于α过小,学习速度较慢,经过600次迭代仍无法到达损失函数的最小值。图5和表1再次说明了学习率对RNN模型性能的重要性。

图5 不同学习率下的预测电压值

表1 不同学习率下的均方误差
3.2 神经元个数对RNN收敛性能的影响
图6为不同神经元个数下的均方误差和训练时长,总训练时间为RNN模型迭代600次所需要的时间。随着神经元个数的增加,最终得到的均方误差会逐渐减少。这是因为神经元个数越多,RNN的结构就更复杂,拟合非线性函数的能力就越强。此外,训练时长整体上也随着神经元个数的增加而增加。这是因为随着神经元个数的增加,RNN模型需要更新的权重系数的数量也会增加,导致训练时间变长。但通过仔细观察可以发现,当神经元的个数为32时,相比神经元个数为8这一情况,RNN模型训练所需的时间显著增长,但最终的均方误差并没有显著减少。这就说明在训练RNN模型的过程中,要综合考虑均方误差和训练时间这两方面的因素来选择合适的神经元个数。

图6 不同神经元个数下的均方误差和训练时间
3.3 RNN算法与ARIMA算法的比较
ARIMA(autoregressive integrated moving average)是一种常用的时间序列预测模型。该模型中需要确定3个参数的大小,即自回归项数p、差分次数d、滑动平均项数q。在本次仿真中,针对所使用的数据集,最终确定了一组比较合适的参数值(p=1,d=1,q=2)。RNN算法与传统的ARIMA算法[15]的性能比较如图7所示。从图7可以看出:RNN模型预测得到的电压值与原始数据几乎完全重合;但ARIMA算法的预测结果不太理想,与原始数据相差较大。这是因为ARIMA模型较为简单,只能够拟合线性函数,并不能很好地捕捉复杂时间序列的规律。此外,ARIMA要求预测的时间序列是稳定的,或者能够通过取对数和差分等手段使其变成稳定的,但大部分复杂的时间序列并不满足这一要求。RNN本身则可以拟合复杂的线性和非线性函数,也不要求时间序列具有稳定性,因此其预测的准确度远高于ARIMA算法,适用范围也比ARIMA算法广。

图7 RNN与ARIMA的性能比较
表2为RNN算法和ARIMA算法的均方误差。为了保证公平性,在计算RNN算法的均方误差时,使用测试集上的均方误差,并没有考虑训练集上的均方误差。从表2可以看出,RNN的预测效果远远优于ARIMA算法,其准确度比ARIMA算法高83%。

表2 RNN和ARIMA的均方误差
4 结 语
本文提出了一种基于RNN的在线辅助CVT电压测量方法,该方法不需要使用海量多维度的数据,只需要使用电力系统中过去的电压序列作为数据集。利用循环神经网络RNN对电压序列进行拟合和建模,把RNN的输出作为标准值来判断CVT的实际测量数据是否存在误差。通过实际的数据集进行仿真和对比试验,发现相比传统的时间序列算法ARIMA,本文方法的性能提升了83%,证实了该方法的有效性和准确性。
猜你喜欢
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
现代仪器与医疗(2021年1期)2021-06-09
电子产品世界(2021年8期)2021-01-16
中国计算机报(2019年49期)2019-02-07
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中国新闻周刊(2017年36期)2017-10-21
创新时代(2016年8期)2016-10-21
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
