
MetaCost 与重采样结合的不平衡分类算法
——RS-MetaCost
2022-03-25 04:44邹春安王嘉宝付光辉
软件导刊 2022年3期
邹春安,王嘉宝,付光辉
(昆明理工大学 理学院,云南昆明 650500)
0 引言
在互联网技术与人工智能技术快速发展的时代背景下,数据分类是机器学习、数据挖掘等领域的重要任务之一。传统的分类算法例如神经网络、逻辑回归、支持向量机、决策树等[1],旨在对样本进行精确分类,达到最高的整体分类精度。传统分类算法要取得好的分类效果,其中一个重要前提是数据集是平衡的,即分类器对数据集中所有类别都是公平的,任一样本被误分为其他类别时损失相同。然而,生活中大量数据往往是不平衡的,数据不平衡是指数据集中不同类别的样本数量差距很大。为达到最高精度,传统分类算法往往在处理不平衡数据集上会偏向多数类样本,导致少数类样本被错误分类的概率更高。对于不平衡数据研究而言,少数类样本往往携带更重要的信息,因此成为研究的重点对象。例如,在疾病诊断中,人们更关注如何尽可能精准识别出每一位病人,避免病人被误诊断为健康人,使病人不会因错过最佳治疗时期而导致病情恶化甚至死亡[2]。故而对于不平衡数据分类,总体正确分类率与少数类样本的正确分类率都很重要。
近年来,国内外众多专家学者对上述数据不平衡现象进行探索,提出很多解决不平衡问题的分类策略,主要从数据重采样与分类算法改进两方面展开研究。数据重采样是指通过改变原始数据集样本分布,降低或消除数据的不平衡程度,主要包括欠采样[3-6]、过采样[7-9]和混合采样[10-13];分类算法改进是指将原有分类算法在解决不平衡任务时存在的问题与不平衡数据的特点相结合,适当地改进算法或提出新算法以提高分类模型对少数类样本的分类性能,主要包括代价敏感学习[14]、单类别分类[15]和集成学习[16]。基于代价敏感的学习算法主要思想是对不同类别的样本设定不同误分代价,通常多数类误分代价较低,少数类误分代价较高。通过设置不同误分代价以尽可能降低分类器对多数类的偏好,提高少数类的分类精准率,从而降低误分类的总体代价。现有的代价敏感方法可分为数据前处理方法、直接的代价敏感学习方法与结果后处理方法3 类[17]。
数据前处理方法通过修改原始数据集分布,使得在新数据集上的分类结果等价于原始数据集采用代价敏感分类决策得到的结果。根据修改数据的不同策略,数据前处理方法可分为采样法和加权法。Elkan[18]提出Rebalanceing 方法,通过对正负类样本采样,实现对不平衡数据分布的修改;Zhou 等[19]提出Rescaling 方法,对训练集的不同样本赋予正比于其误分代价的比重,之后用样本训练分类器进行模型预测。代价敏感学习方法将代价信息直接嵌入经典算法的目标函数,以期望损失最小化,并建立相应的代价敏感模型,如代价敏感的神经网络、决策树和支持向量机等;结果后处理方法通过调整分类器决策阈值以解决代价敏感学习问题;经验阈值调整法采用交叉验证方法寻找分类器的最优决策阈值[20]。
MetaCost 算法是由Domingos[21]提出的一种典型的结果后处理方法。MetaCost 算法的核心思想是利用最小期望损失准则对训练样本进行重标记,然后在重标记的数据集上训练新的分类模型,使其代价敏感。但是,MetaCost 在划分子集过程中存在很强的随机性,当原始数据集中少数类样本很少时,可能导致训练子集中少数类样本很少甚至没有,因此预测的分类结果可能不是最优。目前国内外有很多学者将MetaCost 算法应用于不平衡分类问题,取得了很好的效果。例如,Michael 等[22]将基本分类模型与MetaCost算法相结合对点击付费广告的盈利情况进行预测;边婧等[23]将LDSP(Large Scale Dataset Stratified Pretreatment)算法与MetaCost 算法相结合以处理大规模不平衡数据集。
本文从代价敏感层面出发,将数据预处理的重采样技术引入其中,提出一种重采样与MetaCost 相结合的不平衡数据分类算法——Resampling MetaCost(RS-MetaCost)。该算法旨在先对原始不平衡数据集进行重采样,再利用Meta-Cost 算法修正样本类标签,通过m-estimation 修正少数类样本概率估计使其更平滑,并利用修改类标签的样本训练分类器得到最终分类模型。采用模拟数据集与实例数据集对RS-MetaCost 算法进行实验分析,结果表明,RS-Meta-Cost 相比于原始数据集、Adaboost 与MetaCost,在相关评价指标及平均代价上均有显著提高。
1 相关理论
1.1 MetaCost
MetaCost 方法采用Bagging 算法思想,以朴素贝叶斯风险理论为基础对训练样本进行重标记,之后在重标记的数据集上训练新的分类模型,使其代价敏感。设某分类问题包含J类,基本分类过程如下:
(1)在原数据集中多次进行随机重抽样获得N个新的训练子集(训练子集样本数小于原数据集),训练N个子分类器ft。
(2)使用N个子分类器分别对训练集样本进行分类,通过集成得到各样本实例x被分为第j类的概率P(j|x),定义如下:
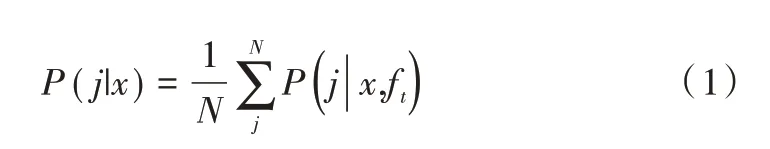
(3)计算每个样本实例x的误分代价R(i|x),然后依照最低代价对样本进行重标记,误分代价定义如下:

其中,i是样本的预测类标签,j是样本的实际类标签,R(i|x)是把第j类样本预测为第i类的损失。
(4)采用重新标记的训练集训练最终的预测模型,得到分类结果。
1.2 重采样
过采样是对少数类样本进行扩充以减少数据不平衡程度的一种重采样技术。如果原始数据集不平衡比率过高,少数类重复过多实例,会导致分类效果失真,模型过度拟合,从而使分类器学习的信息不够泛化。常见的过采样算法包括随机过采样、SMOTE[7]、Borderline-SMOTE[8]、ADASYN[9]等。
Chawla 等[7]提出合成少数类过采样技术(Synthetic Minority Over-sampling Technique,SMOTE),其基本思想是对少数类样本进行分析,并根据少数类样本人工合成新样本添加到数据集中。本文选取SMOTE 作为样本过采样方法,其算法流程如下:
(1)对于少数类中的每一个样本x,以欧氏距离计算该样本到少数类中k个近邻样本的距离。
(2)根据数据集的不平衡比例设定过采样比率n,从k近邻样本点随机选取n个样本xi(i=1,2,…,n)。
(3)代入少数类样本x与xi,得到新的少数类样本点xnew。
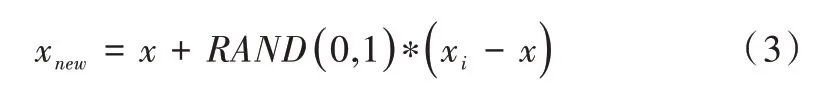
其中,RAND(0,1)表示在区间(0,1)内任取一个随机数。
与过采样方法相反,欠采样针对多数类,通过删除部分多数类样本达到平衡数据集的目的。最基础的欠采样方法为随机欠采样,该方法随机从多数类中取出部分样本进行欠采样。随机欠采样操作简单,但很可能造成重要的样本信息丢失,从而影响分类性能。因此,在随机欠采样基础上,又提出许多改进的欠采样方法,如ENN[4]、Tomek Links[5]、OSS[6]等。
xp与xq是属于不同类别的两个样本,定义d(xp,xq)为两个样本之间距离。如果没有其他样本xl使得d(xp,xl)<d(xq,xl)或d(xq,xl)<d(xp,xl),则d(xp,xq)被称为Tomek Links。如果两个样本点为Tomek Link 对,则其中某个样本为噪声(偏离正常分布太多),或者两个样本都在两类的边界上。如图1 所示,虚线圈出的即为Tomek Link 对。本文选取Tomek Links 作为欠采样方法,将Tomek Link 对中属于多数类的样本剔除。
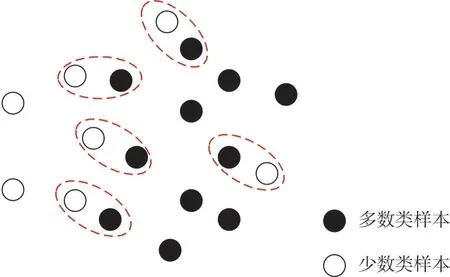
Fig.1 Schematic of Tomek Links图1 Tomek Links 示意图
2 RS-MetaCost
根据MetaCost 原理对原始数据集多次随机抽样获得训练子集的过程中,如果原始数据集中少数类样本个数很少,可能导致训练子集中不包含任何少数类样本。在这种情况下,子分类器对训练子集训练得到的分类模型预测分类效果可能会很差,最后集成得到的学习模型也不是最佳。为此,本文提出在划分训练子集前,先对原始不平衡数据集进行抽样,即过采样少数类样本或欠采样多数类样本,以降低或消除数据集的不平衡程度。
通过重采样可有效解决训练子集不包含任何少数类样本的问题,但当数据集不平衡比率过高时,认为增加过多少数类样本或减少过多多数类样本都可能导致模型失真,分类器学习到的信息不够泛化。因此,本文提出利用m-estimation 修正少数类样本的预测概率。
MetaCost 给出了概率估计的常用方法,即P(j|x)=为减少概率估计的极端性,本文通过m-estimation 对其进行修正,使这些估计更加平滑[24]。此时修正后的概率估计为:
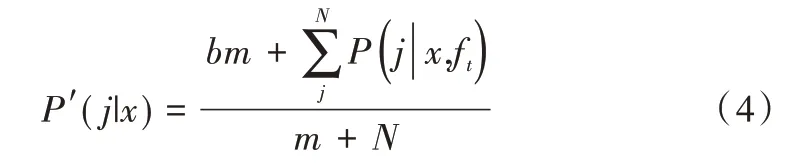
其中,b是少数类样本在数据集中所占比率,即b=P(j=1);m是控制分数向b移动距离的参数。之前的相关研究表明,m的选取并不是很重要,这里根据少数类基本比率b,使m的取值大约符合bm=10的要求。
本文通过m-estimation 进一步增大样本预测为少数类的概率,即P(j=1|x),当代价矩阵不变时证明这种方法的可行性。
以过采样少数类为例,首先假定M1为少数类样本个数,M2为多数类样本个数,则少数类的基本概率b=M1(M1+M2)。当过采样s个少数类样本时,此时少数类的基本概率为,因此可得到少数类的预测概率:
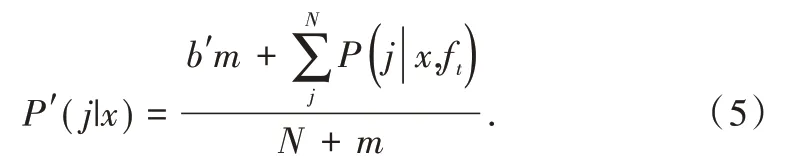
在二分类情况下,当且仅当预测少数类的预期代价小于或等于预测多数类的预期代价时,最优预测为少数类[18]。根据代价矩阵可得到下列不等式:
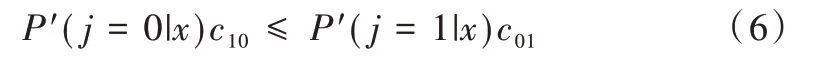
其中,c10为将多数类误分为少数类的代价,c01为将少数类误分为多数类的代价,此时正确分类的代价为0,即c00=c11=0。

求解得到b′的范围为:
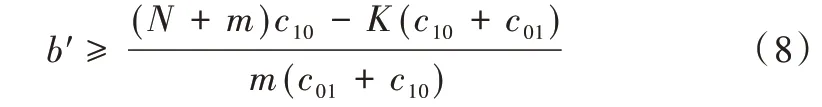
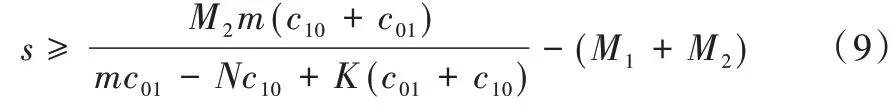
可看出该决策自由度为1,最优决策为:

当k=0时,s*取最大值这是s的一个下界。从理论上来讲,也即当出现这种极端情况时,所有样本都会被标为少数类。这本质上是一种通过过采样少数类和m-estimation 修正少数类概率估计以提高少数类预测概率,从而使分类器更容易将样本分为少数类的方法。本文通过该方法提升分类器对少数类样本的识别能力,并将其应用于不平衡学习中。
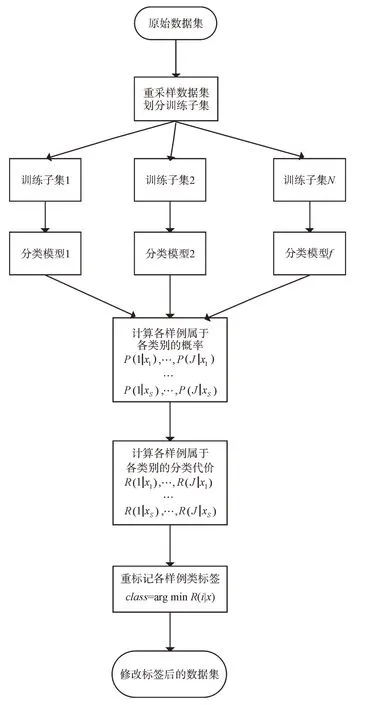
Fig.2 Flow of RS-MetaCost algorithm图2 RS-MetaCost 算法流程
RS-MetaCost 算法伪代码描述如下:
输入:多数类样本M2,少数类样本M1,重采样子集个数N,代价矩阵C,分类算法f
输出:修改标签后的数据集


3 实验设计与分析
3.1 实验设计
为验证本文算法的优越性与可行性,实验分为模拟实验与实例实验。其中,模拟实验数据集如表1 所示,实例实验数据集均来自于UCI 与KEEL 库,具体数据集描述如表2所示。
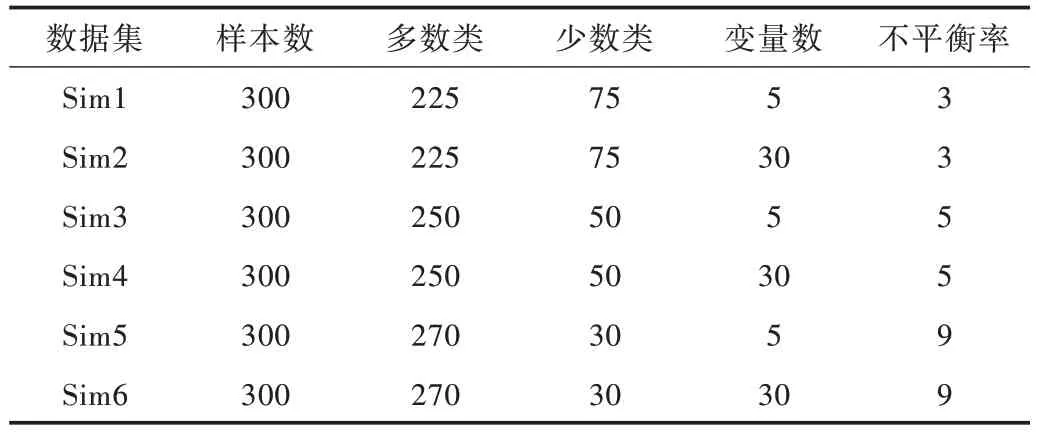
Table 1 Description of simulated datasets表1 模拟数据集描述

Table 2 Description of real datasets表2 实例数据集描述
实验对本文提出的RS-MetaCost 算法和Origin(原始数据集直接分类)、Adaboost 算法、MetaCost 算法在分类评价指标及平均误分代价方面的性能进行比较。为保证实验结果的可靠性,采用80%的数据作为训练集,剩下20%的数据作为测试集,实验结果为50 次分类评价结果的平均值。本文选用SMOTE 作为过采样方法,Tomek Links 作为欠采样方法。本文的代价矩阵设定为:少数类误判为多数类的代价为不平衡率,多数类误判为少数类的代价为1,正确分类的代价为0。
表1 为6 组模拟数据集,样本总数设定为300,变量数分为5 和30 两种情况,不平衡率分别设为3、5 和9。通过控制不同变量数及不同不平衡率的模拟数据集,以确保本文方法在处理不平衡问题上具有广泛的适用性。
3.2 模型评价准则
在不平衡数据分类问题中,少数类的分类精度比多数类的分类精度重要得多,因此在评价指标上,少数类的分类表现至关重要。下面引入混淆矩阵的概念,如表3 所示。其中,正类代表少数类,负类代表多数类。

Table 3 Confusion matrix表3 混淆矩阵
查准率(Precision)表示在类别预测结果为正类的样本中,样本预测结果正确的比率。计算公式如下:

召回率(Recall)表示在所有正类样本中被正确预测的样本所占比例,用来度量算法识别正类样本的能力。计算公式如下:
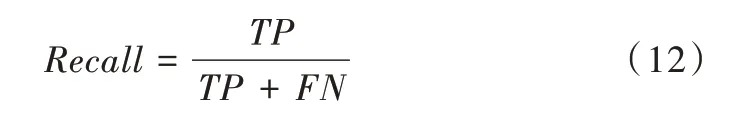
查准率与召回率是相互影响的。一般来说,查准率高时,召回率往往偏低;而召回率高时,查准率往往偏低。Fmeasure综合了两项评价指标,表示两者的加权调和平均值。F-measure值越大,意味着分类器性能越好。
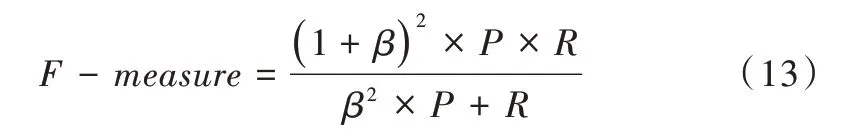
本文β的取值为1。
G-mean值也常用来衡量不平衡数据集的整体分类性能,计算公式如下:
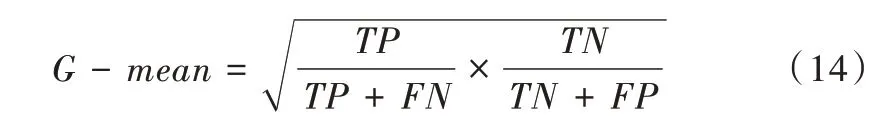
其中,TP/(TP+FN)反映分类器对少数类的识别能力,TN/(TN+FP)反映分类器对多数类的识别能力,G-mean会随着这两项数值的增大而提升。
全局的平均误分代价(AMC)是衡量代价敏感学习中的一个重要指标,该值越小,说明平均误分代价越小。计算公式如下:
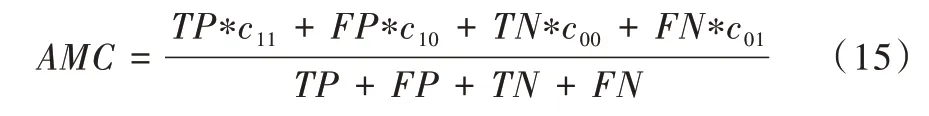
AUC 是接受者操作特征曲线(ROC)与坐标轴围成的面积,AUC 值越接近1,解决不平衡数据的模型越好。本文选取Precision、F1、G-mean、AUC 和AMC 作为评价指标。
3.3 实验结果与分析
3.3.1 模拟分析
表4 给出了模拟数据集在不同算法下的分类效果比较,其中OS-MetaCost 代表过采样下的RS-MetaCost,USMetaCost 代表欠采样下的RS-MetaCost。为便于观察与对比,用粗体标识各算法的最优结果。
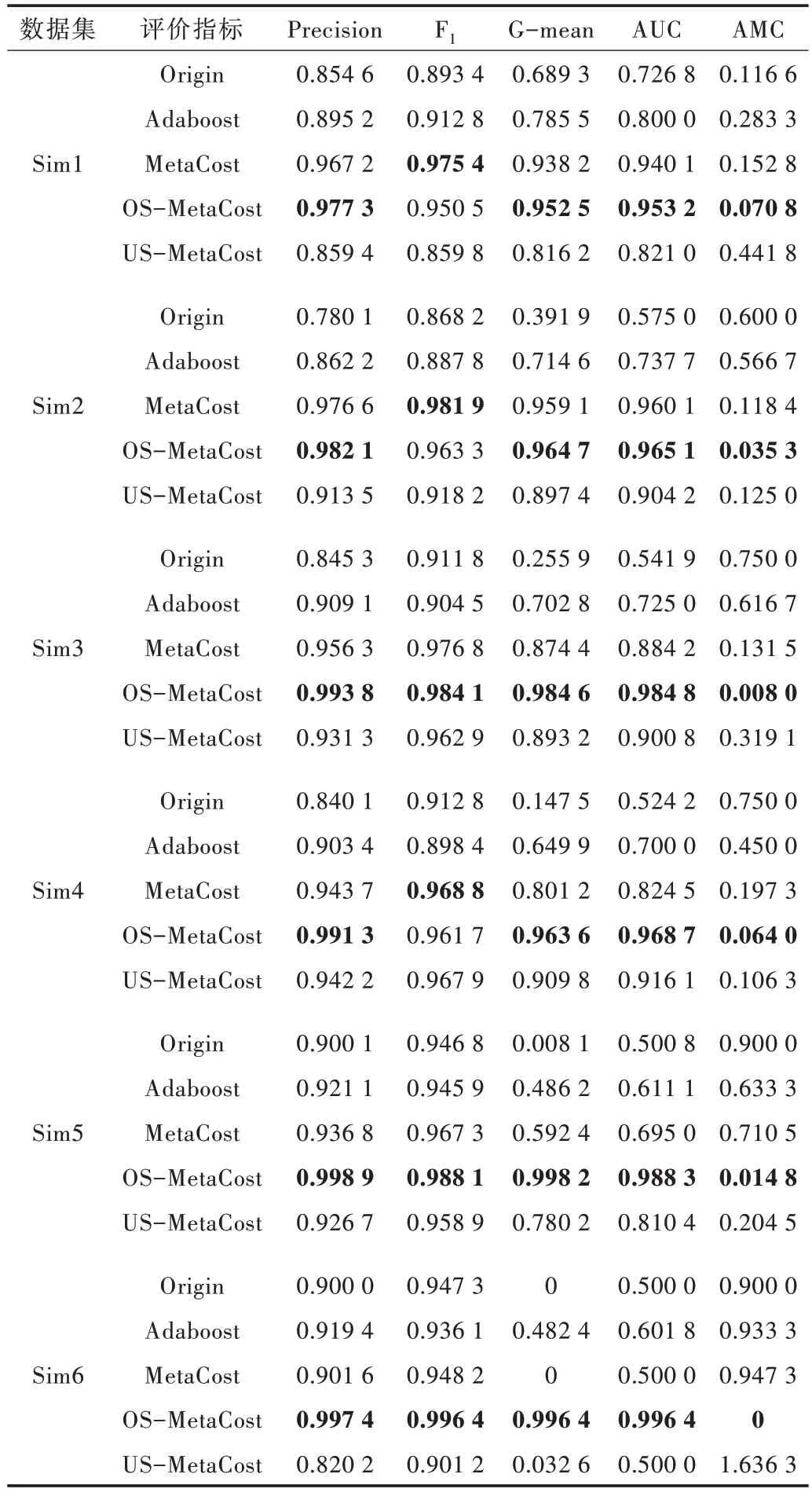
Table 4 Comparison of classification effect of simulated data sets with different algorithms表4 模拟数据集在不同算法下的分类效果比较
对于每个模拟数据集在不同评价指标上的表现,可看出OS-MetaCost 在大多情况下优于其他算法,证实了OSMetaCost 在解决不平衡分类问题上有所改进。OS-Meta-Cost的G-mean 值与AUC 值提升明显,说明本文方法通过对少数类进行过采样及修正少数类预测概率,提升了分类器对少数类的识别能力,进而提升了G-mean 值。同时,控制模型错误分类的概率很低,使得AUC 值提升显著。可看出在Sim1、Sim2 和Sim4 3 个模拟数据集中,MetaCost的F1值相较于OS-MetaCost 略胜一筹,说明重采样后可能存在少数类样本被误分为多数类的情况,导致假阴性率增大,进而导致F1值减小。MetaCost 和RS-MetaCost 都能有效降低全局的平均误分代价,当不平衡率较高时,效果更为显著,且OS-MetaCost 一直占据更大优势。
当不平衡率相同,变量数更大时,分类效果往往不尽如人意。可以看出,本文方法在各项评价指标上表现更好,能显著提高分类效果。同样地,若变量数相同,相较于不平衡比率较低时,当不平衡比率较高时,RS-MetaCost 能显著提升分类效果,其中OS-MetaCost 表现更好。综上所述,从模拟数据集实验分析结果来看,RS-MetaCost 有效提高了不平衡数据的分类性能,且OS-MetaCost 相较于USMetaCost 更具优越性。
3.3.2 实例分析
表5、表6 分别为各算法在10 组实例不平衡数据集上得出的Precision 与F1、G-mean、AUC的结果对比。针对每个数据集在不同算法下得到的评价指标结果,为便于观察与对比,用粗体标识各个算法下的最优结果。
从表5 可以看出,在多数数据集中,RS-MetaCost 算法在各项评价指标上均表现更好。针对原始数据集,采用Adaboost 算法和MetaCost 算法在Precision 值及F1值上虽然有一定提升,但RS-MetaCost 算法的提升效果更为显著,而且OS-MetaCost 比US-MetaCost的效果更好。实际上,对少数类样本进行过采样后,少数类样本数目增多,有利于调整原始数据集分布,扩大了少数类样本在分类时的决策空间,使得少数类样本被正确预测的数目增多,因此OSMetaCost的Precision 值优于其他算法的Precision 值,进而使得其F1值也优于其他算法。
G-mean 值代表正类准确率与负类准确率的几何平均数,该值越大,模型分类性能越好。从表6 可以看出,大多数数据集下RS-MetaCost 算法的G-mean 值大于其他分类算法,且在Speech Features、Musk2、Glass06vs5 等数据集上G-mean 值提高更多,因此认为RS-MetaCost 算法在保证负类准确率较高的情况下,提高了正类准确率。
RS-MetaCost 算法在AUC 值上仍具有优势,说明RSMetaCost 算法的分类效果很好,假阳性率和假阴率性很低。当不平衡率较低时,OS-MetaCost 与US-MetaCost的Gmean 值及AUC 值相差不大;当不平衡率较高时,OS-Meta-Cost的G-mean值与AUC值明显优于US-MetaCost。说 明过采样下的RS-MetaCost 算法在处理高度不平衡数据问题时效果显著,具有一定优越性与可行性。同时,当不平衡率较低时,相较于Origin、Adaboost 算法和MetaCost 算法,RS-MetaCost 算法的G-mean 值和AUC 值具有一定提升,但提升效果并不显著。然而,当不平衡率较高时,Adaboost 算法与MetaCost 算法的G-mean 值与AUC 值普遍较低,说明存在少数类样本很少导致训练子集的少数类实例很少,因而最后分类模型效果不好的情况,而RS-MetaCost 算法的G-mean 值与AUC 值提升显著,说明本文算法确实能有效解决上述问题。

Table 5 Comparison of Precision and F1 of different algorithms表5 Precision 与F1 在不同算法下比较
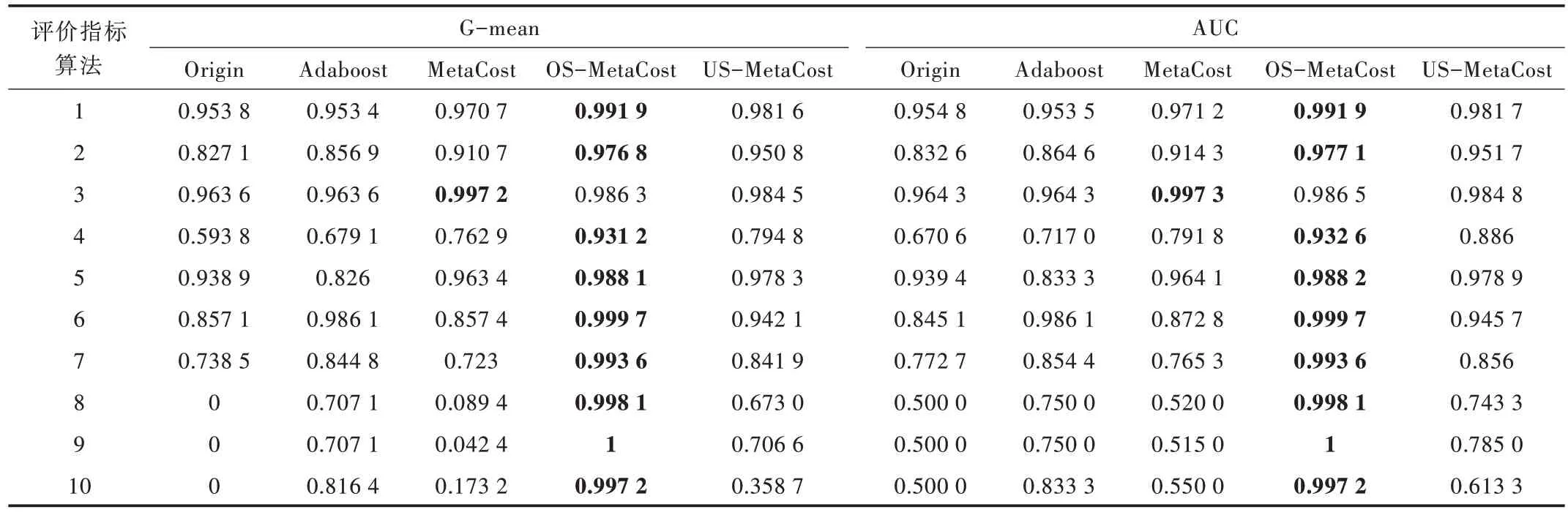
Table 6 Comparison of G-mean and AUC of different algorithms表6 G-mean与AUC 在不同算法下比较
为直观对比不同算法下的AMC 值,图3 展示了AMC 值在10 个数据集上的实验结果。可以看出,RS-MetaCost 算法在降低平均误分代价上具有很大优势。在多数数据集上,OS-MetaCost 取得了更小的AMC 值,主要因为对少数类进行过采样后,明显降低了假阳性率和假阴性率,使得平均误分代价更低,模型分类性能显著提高。此外,当不平衡率较低时,US-MetaCost 在多数数据集上取得更小的AMC 值,但当不平衡率较高时,OS-MetaCost的AMC 值相较于US-MetaCost 更小。因此,为降低全局误分代价,当不平衡率较低时,RS-MetaCost 算法可采用欠采样作为重采样方法;当不平衡率较高时,RS-MetaCost 算法可采用过采样作为重采样方法。
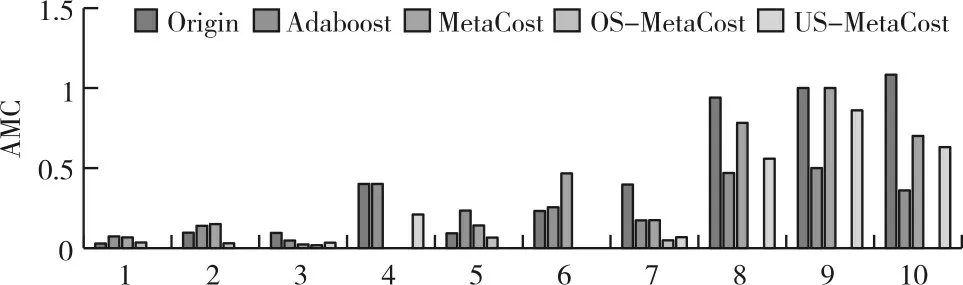
Fig.3 Comparison of AMC of different algorithms图3 不同算法下的AMC 值比较
为更直观地对比本文提出的RS-MetaCost 算法与其他算法在各项评价指标上的优劣,将10 个数据集的Adaboost、MetaCost 和RS-MetaCost 评价指标平均值减去原始数据集的评价指标平均值,得到不同算法下的平均评价指标提升值,如图4 所示。可进一步观察到,过采样下RS-Meta-Cost 算法的各项评价指标都有所提升,尤其是AMC 值和G-mean 值,说明过采样下RS-MetaCost 算法能够有效减少模型的平均误分代价,并提升了分类器对多数类与少数类的识别能力。欠采样下RS-MetaCost 算法的AMC 值与AUC 值仅次于OS-MetaCost,但G-mean 值、F1值和Precision值相较于Adaboost 算法与MetaCost 算法略逊一筹。
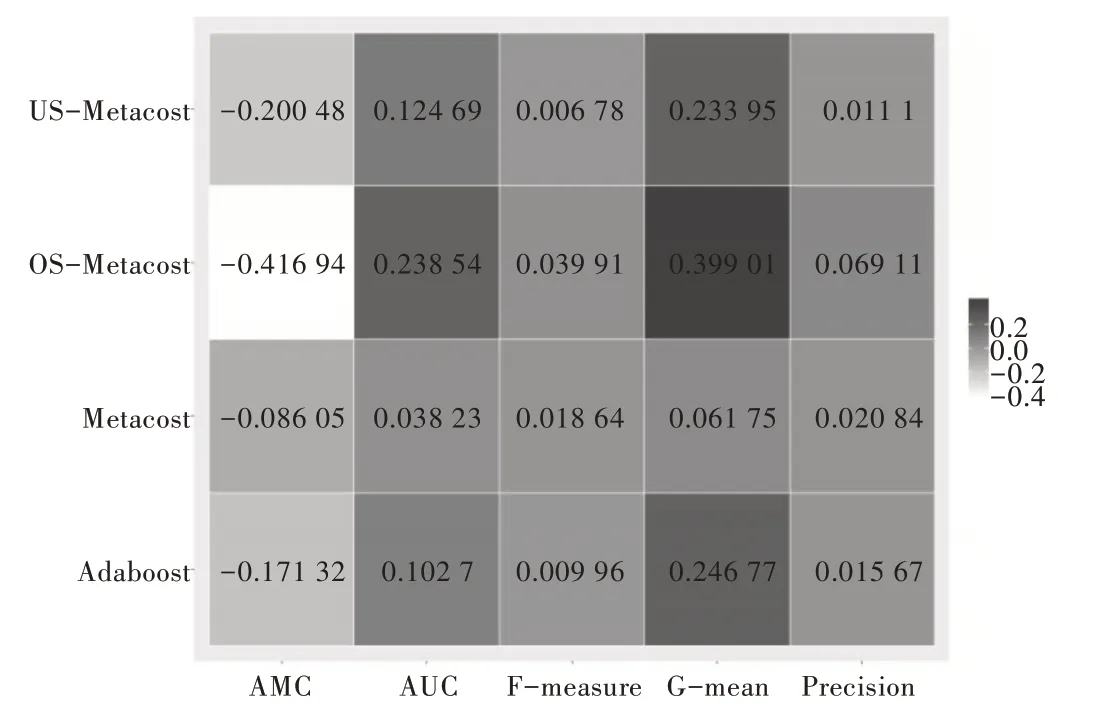
Fig.4 Mean measure improvement of different algorithms图4 不同算法下的平均评价指标提升值
采用Friedman 检验分别对各数据集的算法进行排序,以判断这些算法是否性能相同。最优算法的排序值为1,次优算法的排序值为2。当评价指标值相同时,指定平均排序。表7(左)为10 个数据集在5 个算法下评价指标的平均序值比较。可以看出,OS-MetaCost 相较于其他算法,在评价指标上具有明显优势,针对AUC、G-mean 与AMC,USMetaCost的平均序值仅次于OS-MetaCost,但针对F1与Precision,US-MetaCost的平均序值比较靠后。
通过Friedman 检验,说明实验中5 个算法的性能具有显著不同。此时利用Nemenyi 检验作为后续检验以进一步区分算法。利用Nemenyi 检验计算出平均序值差别的临界值域,计算公式如下:
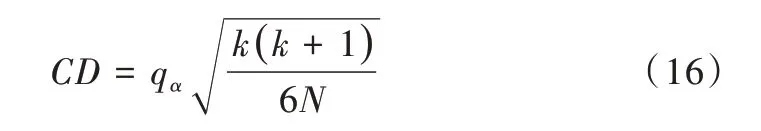
其中,k、N分别代表本文采用的算法与数据集个数。其中,k=5,N=10。当α=0.05 时,对应的qα=2.728,此时临界值域CD=1.928 9。
表7(右)展示了5 种评价指标的Nemenyi 检验值,可以看出,OS-MetaCost 与原始数据集、Adaboost 在各项评价指标的提升效果上存在显著差异,其差距值均大于临界值域。针对AUC、G-mean 和AMC 3 项评价指标,其相比于MetaCost 存在显著差异,但相比US-MetaCost 差异不显著,正好验证了US-MetaCost 在这3 项评价指标上具有一定提升,仅次于OS-MetaCost。同样地,针对F1和Precision,其相比MetaCost 差异不显著,但相比US-MetaCost 存在显著差异,也说明了其在这两项评价指标上的提升,MetaCost 仅次于OS-MetaCost,且优于其他算法。

Table 7 Mean ranks of performance measures and the test value of Nemenyi of different algorithms表7 不同算法下的评价指标平均序值及Nemenyi 检验值
4 结论与展望
本文对MetaCost 算法进行研究,在划分子集之前进行重采样,可避免出现训练子集中少数类样本实例很少的情况,并通过m-estimation 修正少数类的概率估计,使其更加平滑,以提高少数类样本的预测概率。实验结果表明,在大多数情况下,该算法相较于Adaboost 与MetaCost 算法,在评价指标(如Precision、F1等)及全局平均误分类代价上表现更好,且不平衡比率越高,分类性能提升越明显。过采样下的RS-MetaCost 算法在大多情况下,相较于欠采样下的RS-MetaCost 算法能取得更好的分类效果。
对于重采样方法,之后可采用混合采样作为重采样手段。通过对代价敏感的研究发现,分类代价类型还有很多,如属性检测代价、测试代价、干预代价等,因此在未来研究中还可以考虑其他代价。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
电子测试(2018年1期)2018-04-18
海峡姐妹(2017年12期)2018-01-31
初中生世界·七年级(2017年9期)2017-10-13
作文与考试·初中版(2017年12期)2017-04-19
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中学生(2015年12期)2015-03-01
