
端到端增强卷积网络的视频人脸表情识别研究
2022-03-25 04:44唐武宾曹雪虹
软件导刊 2022年3期
唐武宾,童 莹,曹雪虹
(1.南京邮电大学通信与信息工程学院,江苏南京 210003;2.南京工程学院 信息与通信工程学院,江苏 南京 211167)
0 引言
表情一直是人类情绪的直观体现,人们通过表情对事物作出回应。随着计算机技术的不断发展,表情识别作为人工智能领域重要的一环备受关注。表情识别主要分为机器学习和深度学习两种方法,而在机器学习中,特征提取是最重要的一步,该过程主要是对最终表情识别起作用的特征进行提取压缩,从而进行识别。传统的特征提取方法主要包括:局部二值模式(LBP)、Gabor 特征[1]、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[2],以及线性预测编码系数(LPC)等[3]。除特征提取会对最终表情识别起很大一部分作用外,分类器也会影响最后表情识别准确率。如今,分类算法常见的有SVM 分类算法[4]、K-NN分类算法[5]、Adaboost 分类算法[6]等。以上这些方法是使用较多也是较为成熟的一些技术。
深度学习比机器学习应用得更为普遍,这是因为其有着更好的特征加工能力且能够适应深层次特征提取网络,因此成为当前国内外学者研究的主流方向之一。对于表情识别研究,也由原先的传统机器学习方法转向了现在的深度学习技术,因为深度学习相比于传统机器学习有着诸多优点,如:①对特征的提取能力更强;②对于存在诸多干扰因素的场景表现出了更强的鲁棒性。深度学习主要有两种典型网络模型,分别为卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN),前者趋向于用于静态图像表情识别,而后者趋向于用动态视频表情识别。Baccouche 等[7]首次将卷积神经网络应用于特征提取。2015 年,Yao 等[8]采用深层次卷积级联进行特征提取从而将深层特征有效提取出来,最终建立特征与表情识别之间的相关性。由于卷积神经网络的优越性,Khorrami 等[9]使用深度学习对视频进行情感识别,但是卷积神经网络无法将相邻两帧之间的信息差异性关联起来,因此他们又采用循环神经网络,用来将相邻两帧之间的信息相关性提取出来,从而建立连续特征变换差异性,这一应用比单独使用卷积神经网络会产生更好的效果。
Zhang 等[10]提出用生成对抗网络(Generative Adversarial Network,GAN)自动生成具有表情的人脸图像,从而扩大训练集,这是在图像预处理部分进行特征丰富;Chen 等[11]提出标签分布学习(Label Distribution Learning,LDL)技术,从而将同一类别标签特征集中,减小类间间距;Wang 等[12]提出自愈网络(Self-Cure Network,SCN)以抑制表情判别不确定性,该网络主要运用自注意力机制对样本进行预处理从而加强样本的表情特点。这些方法都是从图像本身出发进行特征增强,而忽略了网络带来的特征丢失问题。
因此,Khor 等[13]提出一种丰富长期循环卷积网络(Enriched Long-term Recurrent Convolutional Network,ELRCN)用于细微表情识别,其主要通过通道级堆叠和特征级堆叠增强对于人脸面部情感特征的提取。对于ELRCN 网络,采用CNN+LSTM 进行特征提取及表情识别,从未考虑特征的相关性及侧重性,从而造成特征无区别度,同时还存在信息丢失问题。陈乐等[14]在ELRCN 网络基础上提出端到端增强特征神经网络,该网络从视频多帧角度出发,通过双LSTM 级联实现信息回溯进行相邻帧信息提取,但是忽略了视频单帧也存在信息丢失现象。Zhang 等[15]提出一种多信号卷积神经网络(Multi-Signal Convolutional Neural Network,MSCNN)从静止帧中提取“空间特征”,该网络主要在单帧上进行特征加强,其利用监督学习不同损失函数达到类内差异缩小、类间差异增大效果,但只是在反向传播更新参数时利用了多种损失函数,一开始的信息损失仍然存在,只不过是将没有损失的信息采用多种损失函数组合凸显出来,并没有做到信息保护,同时没有兼顾到视频多帧存在相关性的特点。
以上方法没有做到单帧和多帧信息的共同保护,而只是在某一方面进行了特征加强。为了解决这些问题,本文从单帧和多帧两个角度着手进行特征增强。单帧采用浅层特征与深层特征融合,浅层特征即在VGG 网络中间层外延卷积模块,从而提取浅层特征,深层特征即在VGG 网络最后融合空洞卷积[16](Dilated Convolution,DC)和通道间注意力机制[17](Squeeze-and-Excitation Networks,SENet);多帧采用帧间注意力机制提取帧与帧之间的相关性,从而将对于最终表情识别作用较大的帧凸显,将作用不大的帧加以抑制。该方法在AFEW 动态视频(Acted Facial Expressions in the Wild)[18]数据集、CK+[19]动态视频数据集、SFEW[20]静态图像数据集、FER2013 静态图像数据集上得到了有效验证。
1 增强卷积网络
本文设计的表情识别模型如图1 所示,共包括两个部分,分别为单帧特征增强网络和多帧特征增强网络。单帧特征增强网络,主要适用于静态图像数据集,同时也可以作为动态视频数据集的单帧特征提取;多帧特征增强网络由于要求相邻帧存在相关性,因此只能适应于动态视频数据集。其中,单帧特征增强网络分为深层特征增强和浅层特征增强,网络结构如图2 所示,多帧特征增强网络为帧间注意力机制。
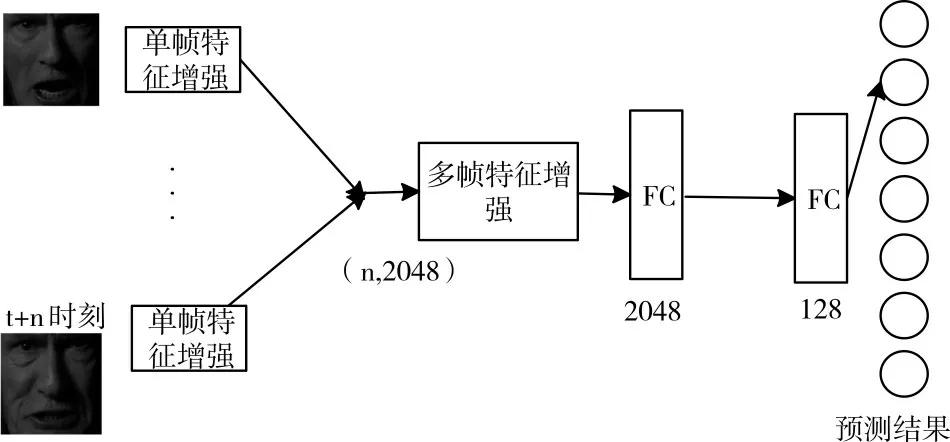
Fig.1 Expression recognition framework based on enhanced convolutional network图1 基于增强卷积网络的表情识别框架
1.1 单帧特征增强
在单帧特征增强部分,主要应用了3 种技术的融合,分别为空洞卷积(Dilated Convolution,DC)、基于通道间的注意力机制(Squeeze-and-Excitation Networks,SENet)及浅层特征提取模块。
空洞卷积(Dilated Convolution,DC)又称扩张卷积,最初是在算法“小波分解小波”中开发,其基本原理是在普通卷积的基础上,引入一个扩张率(Dilation Rate)的超参数,该超参数定义了相邻卷积核各值的间距。卷积核大小为3×3,扩张率为d的空洞卷积如图3 所示。从图3(a)可以看出,普通卷积是空洞卷积的一个特例,即为扩张率1的空洞卷积,以图3(b)为例,扩张率为2,让原本3×3的卷积核,在参数不变的前提下感受野增加到5×5。不仅如此,空洞卷积的应用也避免了polling 所带来的下采样问题,polling 每次操作都会造成一半信息丢失,这种无条件的一半信息丢失会直接导致重要特征丧失,而使用空洞卷积代替polling操作就能避免这种问题。以图3(c)为例,3 个相邻像素点保留1 个,一般而言,相邻像素点对于最终表情识别的作用是无差的,因此保留其一即可,从而可以保证强弱信息的结合。因此,空洞卷积的应用有效解决了标准卷积所带来的内部数据结构损失以及空间层级化信息丢失问题。本文对于空洞卷积的应用位置及扩张率的大小尝试过多种可能性,最终在VGG 网络最后一层应用扩张率为2的空洞卷积达到了最好的识别率。

Fig.2 Single frame feature enhancement network图2 单帧特征增强网络
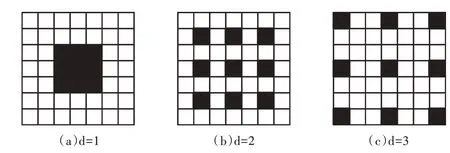
Fig.3 Empty convolution图3 空洞卷积
在实践过程中,卷积神经网络认为每一个像素点对于最终表情识别所起的作用都相同,然而从人眼角度看,有些像素点所起的作用更大,而不是平均分配,因此在CNN的基础上融合了基于通道间的注意力机制(Squeeze-and-Excitation Networks,SENet)。该模块通过网络自动训练学习从而获取到每个特征通道的重要程度,然后依照该重要程度去提升有用的深层特征并抑制对当前任务用处不大的深层特征。其结构如图4 所示,共通过3 个操作重新标定CNN 所输出的通道特征。首先是Squeeze 操作,将每一个特征通道里的像素点相加,然后除以特征通道大小,从而产生一个实数,该实数代表这一通道的全部信息,其公式如式(1)所示;其次是Excitation 操作,在该步骤采用网络自学习机制生成参数w,该值代表了每个通道对于最终表情识别所产生的影响因子,该值大小介于0 与1 之间,其公式如式(2)所示;最后是Reweight 操作,该操作就是将各通道的权重加权乘到相应特征通道上,从而每个特征通道对最终表情识别结果作出了不同的贡献,实现了通道特征的重标定,公式如式(3)所示。
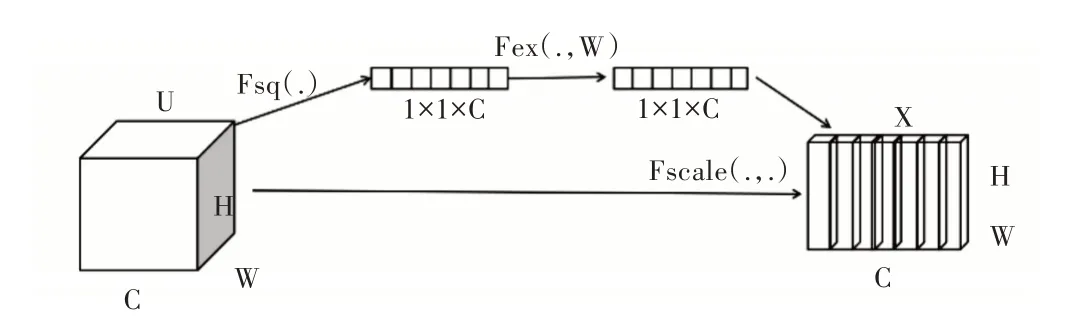
Fig.4 Inter channel based attention mechanism图4 基于通道间的注意力机制
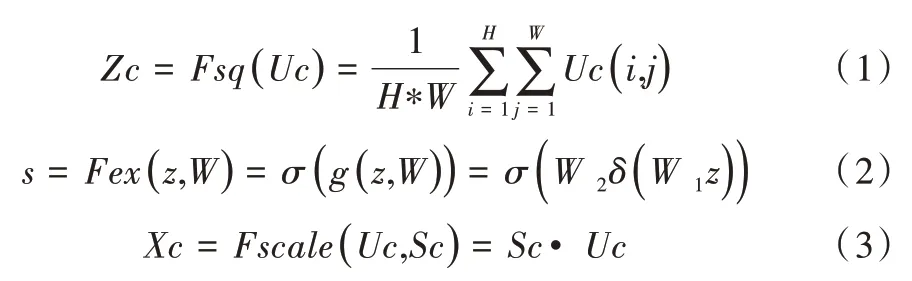
由于层数的提高必然会导致部分有用信息丢失,因此在注重深层特征的同时也需要关注浅层特征。在本文中,所采用的CNN 模块为VGG-16,此网络总共16 层,虽然层数并不很深,但在VGG-16 最后一层出来的其实就是深层特征,而一些浅层有用特征已经丢失。为了弥补这一缺陷,在VGG-16 中某一层外延支路进行浅层特征提取,在尝试多次之后,最终选取VGG-16 中间层外延支路。同时,在实验过程中进行了多种尝试,最终确定以两层卷积层的级联最佳,其结构如图5 所示。其第一层是一个7×7的卷积层,该卷积层在保留更多表情特征的同时也保证了网络的感受野。批量归一化层是为了防止梯度爆炸和梯度消失,激活层使用Relu 非线性函数。第二层为1×1的卷积层,主要是为了降维,同时提高网络表达能力,从而方便后续特征融合。该浅层特征增强与深层特征增强互相融合,从而促进特征进一步突出,提高识别率。

Fig.5 Shallow feature enhancement图5 浅层特征增强
1.2 多帧特征增强
CNN 对于处理单帧图片十分有效,但对于视频而言,相邻帧之间存在运动信息,同时由于表情是一个渐变过程,前一帧的表情将会直接影响到下一帧的表情,因此单独的CNN 将不适合处理这种关系,而循环神经网络(Recurrent Neural Networks,RNN)则更为有效。RNN 模型的循环特性可以使信息在网络中留存一段时间,从而可以建立相邻帧的表情变化关系。现阶段,应用最广的RNN 便是门限RNN(Gated RNN),而LSTM 就是其中最为经典的一种。但是由于其每个细胞中都有4 个全连接层(MLP),在LSTM 时间跨度很大的情况下,会导致运算时间呈几何级数上升。因此,本文提出采用帧间注意力机制代替LSTM,也能够将相邻帧的信息关联起来。该思想由Fajtl 等[21]首次提出,他指出使用自注意力机制处理相邻帧,并给每一帧赋予不同的权重,从而将对表情识别起关键作用的帧凸显出来,将对表情识别误导性极高的帧抑制起来,确保最终表情识别率的准确性,其操作性与基于通道间的注意力机制类似。
1.3 整体架构
本文深层特征增强网络框架如图6 所示。根据帧间注意力机制的结构特点,其要求CNN 网络需同时输出多张连续人脸特征,因此模型每次应输入n张人脸图像,每张人脸图像能够共享CNN 网络权重并进行特征提取。由于实验室条件有限,为了避免内存溢出问题,最终n值设置为10,一次传入10 张连续人脸图像。为了增加相邻帧的特征共享,因此在实验过程中同一个视频中的相邻子视频段存在5 帧的重合。
对于整体过程,首先以10 帧为一个单位依次传入人脸图像,带预训练权重的VGG-16 网络会初步提取人脸图像中的深度特征,在VGG-16 网络中间层会有一个旁支,该旁支的主要作用是浅层特征增强,也即提取浅层特征,从而弥补网络过深所带来的特征丢失问题。浅层特征增强出来的特征通道数为1 024,为了方便融合,在VGG-16 网络上做了优化,构造了两层卷积层:第一层卷积层卷积核为3×3,同时融入d=2的空洞卷积,该空洞卷积所起的作用是扩大感受野,同时促进强弱信息的结合;第二层卷积核为3×3,将输出通道扩充至1 024 维。该卷积层出来的特征会送入SENet 网络中,该网络以特征通道为切入点,显式建立它们之间的关联性,从而将对表情识别结果重要的特征通道凸显出来,而将对表情识别结果不重要的特征通道抑制起来,输出1 024 维带有权重的特征通道。最后将该输出特征通道与特征增强模块输出的1 024 维特征通道融合,从而达到浅层特征与深层特征的有效融合。

Fig.6 Deep feature enhancement图6 深层特征增强
2 实验分析
2.1 数据集
面部表情自20 世纪便受到研究者的关注,Ekman 等[22]结合前人经验对人脸表情识别进行开拓性的创新,将人类表情共分为6 类。之后他们又进行了分类完善,提出基于面部运动单元(44 个运动单元)的面部表情编码系统(Facial Action Coding System,FACS)[23]。
2.1.1 AFEW 数据集
数据集AFEW 为动态视频数据集,同时作为竞赛级数据集,相比于实验室录制的数据集,其增加了一些干扰因素,其中干扰因素主要包括遮挡、像素点过低、背景变化等,因为这些干扰因素的存在,其更具现实性。同时,该数据集已经将视频一帧一帧切割形成一张张图片,每个图片都有一个标签。其标签如图7 所示,由于某些表情不具有分辨性,因此特地加入中性标签。与此同时,作为竞赛级数据集,其测试集并不对大众开放,因此在实验中将验证集当作测试集使用。

Fig.7 7 kinds of emotion in AFEW dataset图7 AFEW 数据集的7 种情绪
2.1.2 CK+数据集
CK+数据集是表情识别常用的数据集之一,其为动态视频数据集,它通过对视频进行截帧操作形成图片数据集,因此该数据集也是动态视频数据集,同时每个图片皆有标签,但是该数据集没有区分训练集、验证集和测试集,需要实验者自行划分。
2.1.3 SFEW 数据集
SFEW 数据集由AFEW 数据集的静态帧图片组成,该数据集为静态图像数据集,其中分为3 个部分,分别为训练集、验证集、测试集,同时每张图片都具有标签,标签总共分为7 种。但是由于是竞赛级数据集,因此测试集不对外公开,在本实验中将验证集作为测试集。
2.1.4 FER2013 数据集
FER2013 数据集是由大量无关人脸图片组成的静态图像数据集,按照一定比例分为训练集、测试集、验证集,每个图片都具有标签,标签总共为7 类。该数据集为静态图像数据集。
本文主要为了测试网络框架的优越性,因此对于数据集并不采用任何处理,用官方给出的图片进行输入。同时在本文中,最具难度系数的是AFEW 数据集,该数据集来自于无约束条件现实场景,因此有一定的干扰因素,如遮挡、光照、背景多变等,这些干扰因素的存在给表情识别带来了一定的挑战性。不仅如此,由于测试集不对外公开,因此只能将验证集作为测试集,从而导致样本数量不足,因此这也是一种挑战。具体如图8 所示。

Fig.8 AFEW complexity图8 AFEW 复杂性
2.2 实验结果
2.2.1 评分标准
F1评分是一种常见的用来评判网络好坏的标准,经常用作竞赛排名。它是通过准确率(precision)和召回率(recall)的数学组合而形成的数学表达式,介于0 到1 之间。


其中,TP(True Positive)为正确预测的数目,FP(False Positive)为将其他预测产生错误的类预测为本类的数目,FN(False Negative)为本应预测正确但错误的本类数目,TN(True Negative)为将其他类预测为正确的数目。
准确率(Accuray):通常也作为网络好坏的评判标准。
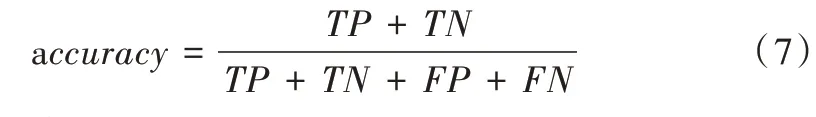
2.2.2 结果比较
实验中,VGG-16 采用预训练权重,加载VGG-16-FACE 模型权重,VGG-16 中间层引出旁支用以提取浅层特征,特征通道数为1 024。为了方便浅层特征与深层特征融合,在VGG-16 后延伸两层卷积层,同时在延伸的第一层卷积层融入扩张率为2的空洞卷积,该扩张率的选择以及空洞卷积应用的位置是经过实验而得出。为了凸显对预测起重要作用的特征通道,将其送入SENet 网络,该网络是为了凸显有用特征通道,抑制无用通道。其后浅层特征与深层特征融合为2 048 维并送入至帧间注意力机制,从而实现表情预测。考虑到样本之间的相关性,每10 帧作为一个单位,也即n设置为10,同时下一个输入的前5 帧为前一个输入的后5 帧。本网络所使用的优化算法为随机梯度下降法(Stochastic Gradient Descent,SGD),动量(Momentum)参数值设置为0.9。对于CNN 部分,采用预训练模型,其中初始学习率(Learning rate)为1e-4,并且在训练过程中一直迭代下降。对于输入,采用数据集自带的图片集,其中每张图片为224×224 像素。网络训练完毕,将测试集送入模型中,最后得出测试结果(见表1—表7)。
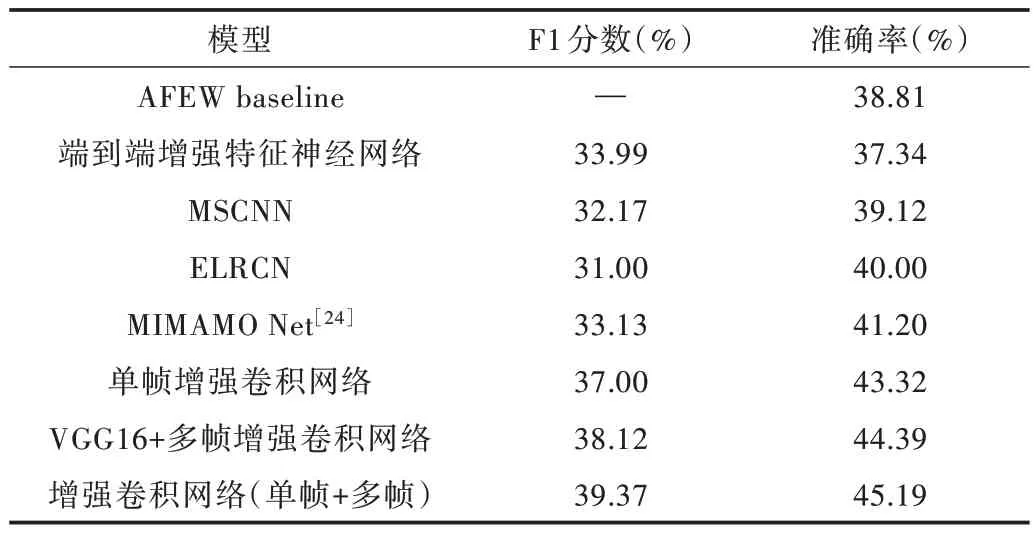
Table1 Test result comparison of AFEW dataset表1 AFEW 数据集测试结果比较

Table 2 Prediction result comparison of AFEW dataset(single frame enhanced convolutional network)表2 AFEW 数据集(单帧增强卷积网络)预测结果比较

Table 3 Prediction result comparison of AFEW dataset(multi-frame enhanced convolutional network)表3 AFEW 数据集(多帧增强卷积网络)预测结果比较

Table 4 Prediction result comparison of AFEW dataset(single frame+multi-frame enhanced convolutional network)表4 AFEW 数据集(单帧+多帧增强卷积网络)预测结果比较

Table 5 Prediction result comparison of CK+dataset表5 CK+数据集测试结果比较
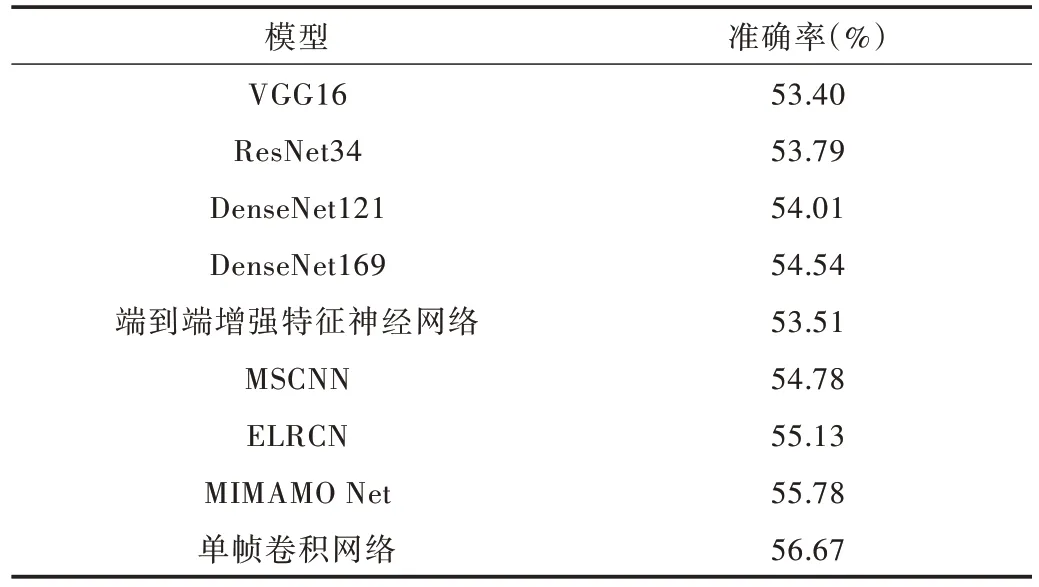
Table 6 Test result comparison of SFEW dataset表6 SFEW 数据集测试结果比较
2.2.3 结果分析
实验中所采用的数据集分为静态图像数据集和动态视频数据集。在静态图像数据集中,由于图像与图像之间没有相关性,因此不存在相邻帧上的信息关联,故主要在原有网络结构上提出了单帧特征增强模块。其中,单帧特征增强模块又分为3 个点的应用,分别为浅层特征增强、空洞卷积应用以及通道间注意力机制。首先是浅层特征增强,在VGG-16 中间层增加外延支路并进行浅层特征保护,避免卷积操作带来的特征丢失;其次,在CNN 部分pooling层采用空洞卷积进行替代,避免了pooling 操作带来的无差别一半信息丢失问题,同时空洞卷积选择性丢失作用相当的像素点以提高识别率;最后是注意力机制引入,在通道间采用注意力机制,给每个通道赋予不同的权重,突出重要通道,抑制不重要通道,即所提出的通道间注意力机制,这对于最终表情识别起到了一定作用。

Table 7 Test result comparison of FER2013 dataset表7 FER2013 数据集测试结果比较
在动态视频数据集中,首先在预处理部分将视频一帧一帧截取,形成具有相关性的视频帧,为了增加相邻帧的信息相关性,因此在单帧特征增强的基础上增加了多帧特征增强的应用,也即将相邻多帧关联起来。在这部分,还是采用注意力机制,将注意力机制应用到帧间,即帧间注意力机制,将对表情识别起关键作用的帧凸显,将对表情识别不起作用或者作用不大的帧进行抑制,基本操作类似通道间注意力机制。
3 结语
本文提出一种增强卷积网络模型,从单帧和多帧两个角度进行特征增强,将VGG、空洞卷积、通道间注意力机制和帧间注意力机制进行有效融合,并在AFEW 数据集、CK+数据集、SFEW 数据集和FER2013 数据集进行表情识别,比较其在测试集上的F1 分数和准确率,证明了该网络模型对于表情识别的优越性。由于AFEW 数据集来源于电影片段剪辑,存在诸多干扰因素,因此接下来将会在预处理部分继续优化模型,从而进一步提高模型实用性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
环境影响评价(2020年5期)2020-12-02
传媒评论(2017年3期)2017-06-13
故事作文·高年级(2017年2期)2017-03-01
水利规划与设计(2016年10期)2017-01-15
华北地质(2015年3期)2015-12-04
新闻传播(2015年20期)2015-07-18
世界科学(2013年11期)2013-03-11
