
基于AE-Tiny YOLOV3的小目标检测模型
2022-03-25 04:44张志坚
软件导刊 2022年3期
林 莉,姜 麟,张志坚
(昆明理工大学 理学院,云南昆明 650500)
0 引言
近些年,人工智能领域不断发展,涌现出一大批基于深度学习的目标检测算法。相较于传统目标检测算法,深度学习算法速度更快,精度更高。目前,深度学习领域对目标检测算法主要进行了两方面的研究:①以R-CNN[1]系列算法为代表的基于候选区域的二阶段目标检测算法,该类算法首先搜索边界框,生成一系列候选区域,然后利用卷积神经网络提取输入图像的特征,进行分类和定位;②以SSD[2]系列和YOLO[3]系列为代表的基于回归的一阶段目标检测算法,该类算法可将目标物体的检测定位和分类两个过程合二为一,直接预测物体的类别概率和所在位置坐标。
自2016 年YOLO 算法和SSD 算法被提出后,现有实时检测算法主要为一阶段目标检测优化算法。2017 年Lin等[4]提出焦点损失(Focal Loss)有效解决了一阶段算法中由于样本分布不均衡导致模型精度不高的问题。同年,Redmon 等[5]在YOLO 算法的基础上,引入高分辨率分类器(DarkNet-19)、Anchor Box、多尺度图像训练等方法,提出YOLOV2 算法,大幅度提升了算法的检测精度。随后2018年其对YOLOV2 算法进行再次改进,采用了更好的基础分类器网络(DarkNet-53)[6]和特征金字塔(Feature Pyramid Network,FPN),以预测3 种不同尺度的框,解决了一阶段目标检测算法在小目标检测上效果不佳的问题。2021 年5月,Chen 等[7]提出YOLOF 算法,仅检测一个层级的特征,并提出了一种替换FPN 复杂的特征金字塔的方案。随后,Ge等[8]提出YOLOX 算法,该算法在YOLOv3的基础上,引入了Anchor Free、SimOTA 样本匹配等方法,构建了一种anchor-free 端到端的目标检测框架,使其具备较高的检测能力。
YOLO 系列模型在现阶段目标检测领域应用最为广泛,该类模型具备良好的目标检测能力,但由于模型复杂,参数量多,对硬件的性能要求较高,难以适用于移动端、嵌入式平台等性能较低的设备。基于此,Redmon 等[6]提出了YOLOV3的轻量级版本Tiny YOLOV3 模型。Tiny YOLOV3模型对设备性能要求低,运行速度快,但检测精度较低,存在小目标漏检率较高的问题。针对这一问题,2020 年王玺坤等[9]在Tiny YOLOV3 模型的基础上增加了特征映射模块和残差分支,提高了算法的检测准确率。李文涛等[10]在Tiny YOLOV3 网络关键位置的特征图中使用挤压激励注意模块和卷积注意模块增强目标,提高抗干扰能力,从而增强模型的鲁棒性和提升模型的检测精度。马立等[11]对Tiny YOLOV3 目标检测模型中的主干网络和损失函数进行改进,有效提升了实时检测中行人等小目标的检测精度。这类改进模型对复杂实时环境具有良好的适应性,在检测速度上提升很大,但在检测精度上仍有较大的提升空间,在对多尺度检测尤其是小目标检测时,模型的鲁棒性不高、适应性不强。
针对Tiny YOLOV3 在小目标检测上存在检测精度低、漏检率高等问题,本文提出一种基于改进Tiny YOLOV3的小目标检测算法,在提高原网络检测精度的同时,进一步提高检测效率。首先,针对Tiny YOLOV3 算法特征提取网络层数少、结构简单、特征提取能力差等问题,使用轻量级高效卷积网络(EfficientNet-B0)中包含的图像输入处理模块和7 个MBconv 模块的图像特征提取网络,替换原特征提取网络,使模型在增加网络深度的同时,减少了参数量,便于提取更深层次的语义信息,为后续预测阶段作准备。其次,针对Tiny YOLOV3 算法中小目标漏检率高等问题,借鉴FPN 和注意力机制的工作原理,构建了基于注意力机制的3 尺度目标检测模型,使其能准确预测大、中、小不同尺度的目标,以解决小目标检测精度低、漏检率高等问题。最后,将改进的模型应用于检测架空输电线的绝缘子状态。通过实验数据表明,在海量无人机巡线所拍摄的图像中,该模型可快速、有效地检测绝缘子。
1 相关工作
1.1 Tiny YOLOV3
Tiny YOLOV3 是YOLOV3的简化版本,其主干网络由1个输入层、7 个卷积层和6 个下采样层构成,很大程度上缩减了Darknet53的网络层数,有效实现了模型压缩。其中,检测网络主要对13×13、26×26 两个尺度的特征图进行预测,网络结构如图1 所示。

Fig.1 Tiny YOLOV3 network structure图1 Tiny YOLOV3 网络结构
由图1 可见,Tiny YOLOV3 网络将416×416的图像经过5次Maxpooling下采样,分别得到208×208、104× 104、52×52、26×26、13×13 共5 个尺度的特征图。再将13×13、26×26 尺度的特征图输入检测网络中进行多尺度检测。此外,Tiny YOLOV3 将6 组锚框平均分配在检测网络上,每个尺度的锚点分配2 组锚框。具体操作如下:首先使用Adam优化器采用回归的方式对锚框进行类别和置信度预测;然后应用非极大值抑制算法(Non-Maximum Suppression,NMS)选出最终预测框;最后根据特征图与原图关系将预测框映射到原图上,完成目标定位。
1.2 EfficientNet
2019 年,Google 工程师Tan 等[12]通过神经网络架构搜索(NAS),设置与MobileNet V2 相同的搜索空间,使用ACC(m)*[FLOPS(m)/T]w作为优化目标,构建EfficientNet-B0 网络模型。该模型由7 个移动翻转瓶颈卷积(MBConv)模块构成,并在MBConv 模块中引入挤压和激发(Squeezeand-Excitation,SE)操作进行优化升级,使浅层网络同样能够通过全局感受野提取图像特征并对图像进行描述。此外,MBConv 模块中还包含深度可分离卷积、swish 激活函数、drop_connect 连接、批归一化等组件。EfficientNet-B0的网络结构及各层参数设置如表1 所示。
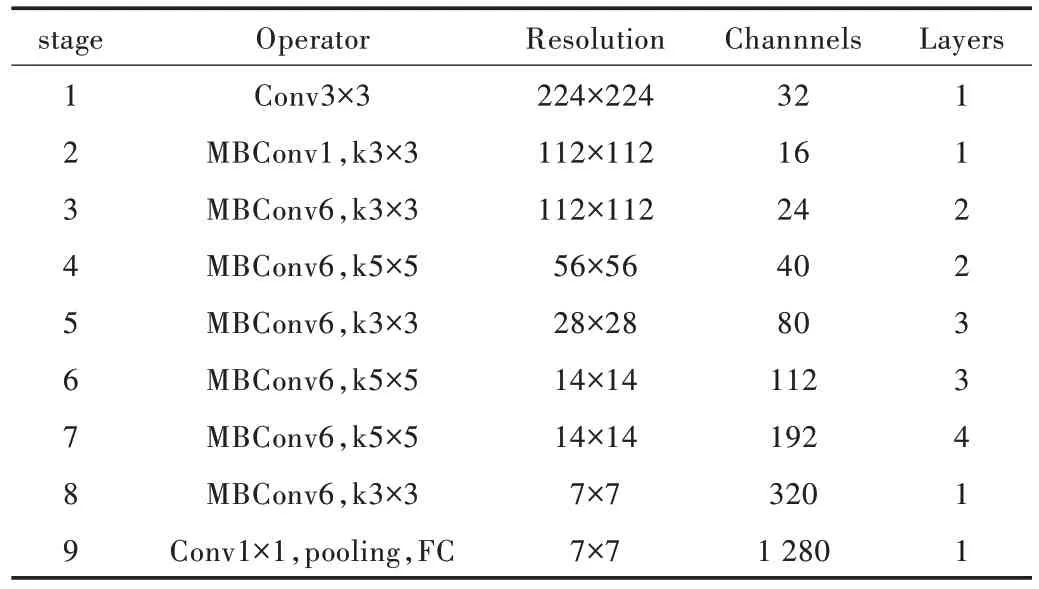
Table 1 EfficientNet-B0 network structure表1 EfficientNet-B0 网络结构
如图2 所示,MBConv 模块首先对输入图像进行1×1的二维卷积,目的是对输入数据进行维度整理;然后通过3×3的深度可分离卷积提取特征信息;再传入SE 模块中进行赋权,接下来将值输入到1×1的二维卷积进行维度整理;最后将输出值进行drop_connect 操作,随机舍弃一些信息与整个模块的原输入相加,得到MBConv 模块的最终输出。

Fig.2 MBConv block图2 MBConv 模块
2 AE-Tiny YOLOV3 小目标检测算法
2.1 基于注意力机制的多尺度检测
注意力机制源于人类视觉系统的研究,当人面对某一大型复杂场景时,往往会重点关注颜色突兀或风格突变的区域,而忽略其它区域。计算机视觉中的注意力机制正是借鉴于此,让网络根据当前任务从众多信息中聚焦重要信息[13]。
首先在原有两个检测分支的基础上,再增加一个检测分支,形成3尺度检测,使网络可有效检测大、中、小各尺度的目标。其次,将注意力机制应用于已经构建的3检测分支中,使网络在输出最终检测结果前,能够客观地分析各通道特征图之间的关系。并且可为含有重要特征的通道赋予更大的权重,使网络能自适应关注图像中的重要信息,从而提升模型检测精度。基于注意力机制的检测分支结构如图3所示。
由图3可见,DBL1模块中包含一个1×1的卷积层、Batch Normalization 标准归一化层和LeakyRelu 激活函数;DBL3 中包含一个3×3的卷积层、Batch Normalization 标准归一化层和LeakyRelu 激活函数。具体操作为:先对每一个检测分支经过DBL1的1×1 卷积整理上层输出特征通道的维度;然后使用DBL3的3×3 卷积分析、提取重要特征;最后将注意力机制得到的权重与DBL3 提取的特征相乘,使网络重点关注含特征信息较为丰富的通道。
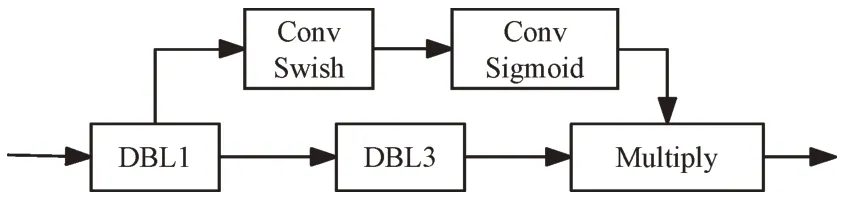
Fig.3 Detection branch structure based on attention mechanism图3 基于注意力机制的检测分支结构
2.2 改进网络结构
为解决现有Tiny YOLOV3 网络鲁棒性不高,尤其在针对小目标检测过程中存在的检测精度低、漏检误检率高的问题。将改进重点集中在特征提取主干网络和检测分支上,改进后的网络结构如图4 所示。

Fig.4 Improved Tiny YOLOV3 network structure图4 改进Tiny YOLOV3 网络结构
由图4 可见,该模型基于EfficientNet-B0 网络,舍弃了最后的全局平均池化层、dropout 层和全连接层,仅保留特征提取部分,以代替Tiny YOLOV3的7 层卷积骨干网络进行特征提取。替换后,新模型用于特征提取的网络层数明显增加,由原来7 层增加至36 层。随着卷积层数的增加,可有效提升特征提取网络的提取性能,从而可更好分析高层次的语义信息。
B0 网络中将传统的普通卷积更换为深度可分离卷积,并引入注意力机制和残差结构构建MBConv 模块。使用深度可分离卷积和注意力机制代替普通二维卷积,一方面在增加卷积层的同时可有效缩减网络的参数计算量;另一方面,通过引入注意力机制,可在网络在训练的过程中,赋予重要信息所在通道更大的权重。但随着卷积层的增加,模型会在训练中发生梯度消失的问题,而MBConv 模块通过引入残差结构可有效解决该问题。
EfficientNet-B0共有7个MBConv模块,取第3个MBConv模块的输出作为feat1 层,取第5 个MBConv 模块的输出作为feat2 层,取第7 个MBConv 模块的输出作为feat3 层,将语义信息丰富的深层特征通过上采样后与具有较多空间信息的浅层特征进行通道拼接,使用卷积操作融合不同通道。应用基于通道注意力机制的多尺度检测分支,构建feat1、feat2、feat3 之间特征融合后的3 种不同尺度检测层以检测大、中、小不同尺度的目标,以提升算法的准确性和鲁棒性。
3 实验结果与分析
3.1 实验环境与评价标准
本文实验环境:操作系统为Ubuntu18.04,GPU 型号为NVIDIA RTX 1660s,CUDA 版本为7.0,基于TensorFlow的Keras 深度学习框架,程序语言为Python 3.7。
由于目标检测结果由分类结果和定位结果两部分共同决定。因此,既可把目标检测看成一个分类问题,也可看成一个回归问题。本文使用单个类别的精确度(Average Precision,AP)和平均精确度(mean Average Precision,mAP)作为模型检测精度的评价标准,使用模型大小(model size)和每秒检测帧数(FPS)作为模型检测速度的评价标准[14]。计算公式如式(1)所示:

其中,AP定义为精确率(precision)/召回率(recall)曲线下的面积,TP表示实际为正样本,模型预测也为正样本的个数;FP表示实际为负样本,但是预测为正样本的个数;FN表示为实际为正样本,但是模型预测为负样本的个数。
对于多分类问题,需要求N个类别的AP均值,即平均精确率平均值以衡量分类器对所有类别的分类精度,这也是目标检测算法最为重要的指标之一。换言说,mAP就是不同类别的AP平均值,计算公式如式(2)所示:

实验过程中主要对mAP@0.3,mAP@0.5,mAP@0.7 进行对比,mAP@0.5 表示预测框与真实框的交并比(IoU)大于等于0.5的情况下可以准确预测的概率。IoU的计算公式如式(3)所示:
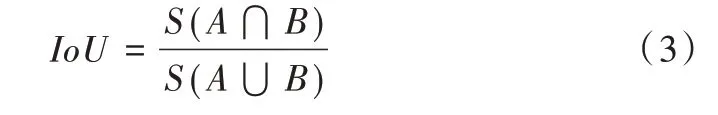
其中,S(A⋂B)表示区域A与区域B重叠部分的面积,S(A⋃B)表示区域A的面积与区域B的面积之和减去二者重叠部分的面积。
3.2 在VOC 数据集上的对比实验
实验使用的数据集为PASCAL VOC。该数据集是目标检测领域的通用数据集,共包含20 类已经标注好的对象,其中训练图像使用VOC2007 和V0C2012 综合数据集,共包含16 551 幅图像的40 025 个物体;测试集使用VOC2007的test 数据集,共包含4 952 幅图像的12 032 个物体。
实验过程中,输入图像尺寸为416×416,分两阶段进行。第一阶段:冻结特征提取骨干网络,加载已在ImageNet数据集上训练好的权重信息,仅对检测分支进行训练,从而获得一个稳定的损失,此阶段学习率设置为0.001,采用adam 优化器进行参数优化训练,batchsize 设为16,训练50epoch;第二阶段:将上一阶段冻结的骨干网络进行解冻,加载上一阶段的训练权重,对整个目标检测网络进行训练,设置学习率为0.000 1,batchsize 设为8,接着第一阶段的训练结果继续训练100epoch。
将AE-Tiny YOLOV3 算法与Tiny YOLOV3 算法在VOC2007+2012 数据集上进行检测效果对比,结果如表2 所示。

Table 2 Comparison of algorithm performance on the VOC data set表2 在VOC 数据集上的算法性能对比
表2 中模型A 保持Tiny YOLOV3 算法原有的检测框架不变,将其中包含7 层卷积的特征提取网络替换为EfficientNet-B0 网络的Tiny YOLOV3 模型;模型B 在模型A的基础上,引入FPN 思想,增加检测分支,构成3 尺度检测模型;AE-Tiny YOLOV3 在模型B的基础上融合注意力机制。
由表2 可见,模型A 使用基于神经网络架构的EfficientNet-B0 网络进行特征提取,相较于Tiny YOLOV3 模型的特征提取网络,网络层数从27 层增加到231 层,可有效提取深层次的语义特征,且模型参数量减少了12.3M,mAP@0.5 提高了8.93%。由此说明,EfficientNet-B0 相较于原特征提取网络更轻量高效。虽然FPS 有所降低,但依然满足实时检测的需求。模型B 结合多尺度训练,mAP@0.5相较模型A 提升了8.03%。
AE-Tiny YOLOV3 模型在多尺度训练的基础上,又在3个检测分支上添加了注意力机制,使模型可重点关注信息量最大的通道特征,自适应地抑制干扰因素对检测结果的影响,加强目标检测特征的表征能力。结果表明,该模型的mAP@0.5 由77.26% 提升至78.22%。表3 为Tiny YOLOV3 算法和AE-Tiny YOLOV3 算法在VOC2007测试集上,IoU为0.5 时,每一类的精确度AP。
根据表3 可知,AE-Tiny YOLOV3 算法在各类别的检测上均有提升,特别是在bird、bottle、cat 等小物体检测上尤为明显。其中,检测准确率提升幅度最大为bird,检测准确率提高了32.02%;检测幅度提升最小为car,仅提高了10.95%。由此可说明基于注意力机制的多尺度检测对于大、中、小不同尺寸的物体,尤其是小目标检测具有良好的检测效果。
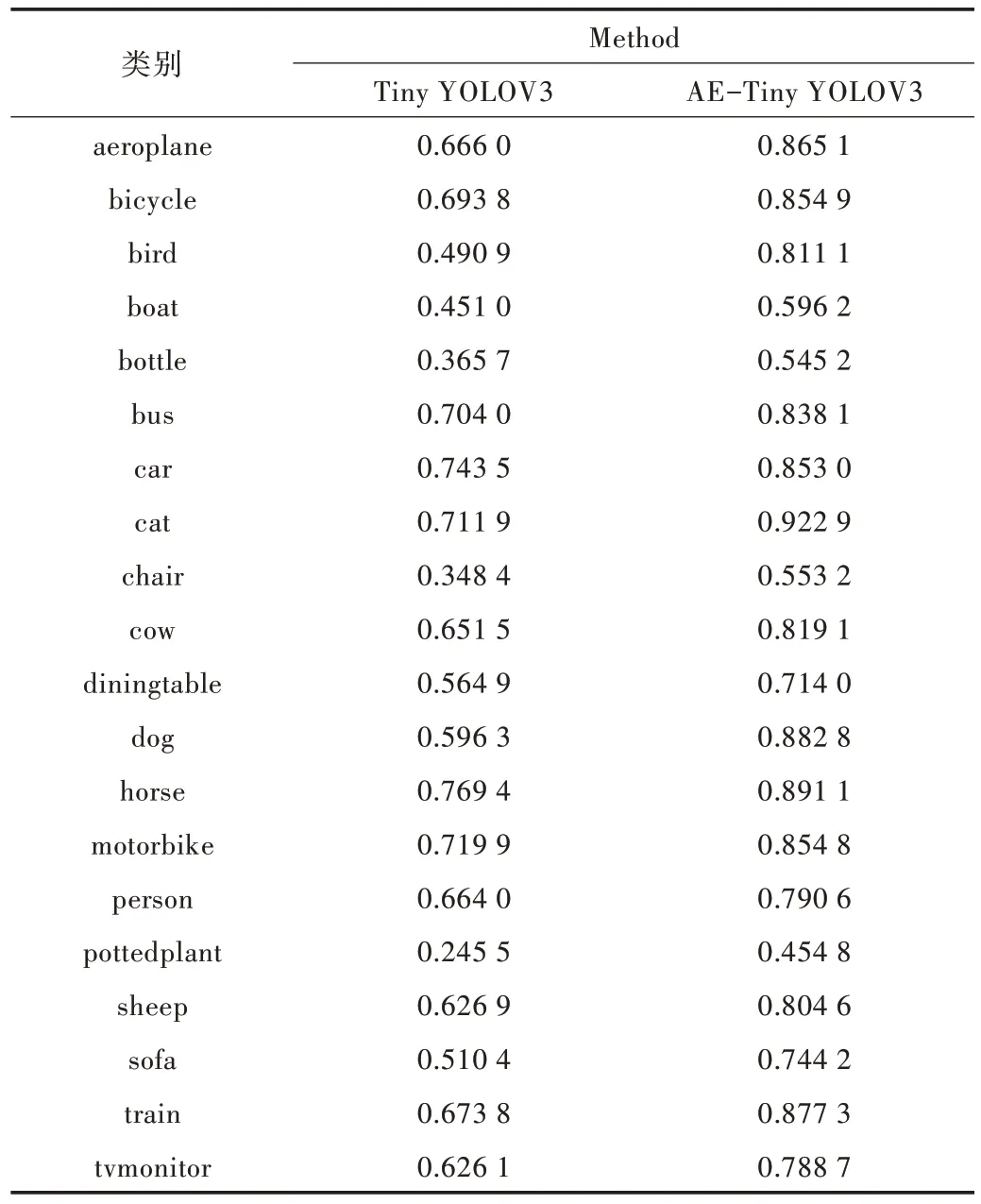
Table 3 Comparison results of various APs in the VOC data set表3 VOC 数据集各类AP 对比结果
如图5 所示,对添加注意力机制的检测分支和未添加的检测分支进行对比,本文选取feat1 层所在检测分支为例,比较输出最终检测结果的前一个卷积层的输出特征图。其中,(a)为未添加注意力机制的80 个通道对应的特征图,(b)为(a)图中80 个通道所叠加的特征图,(c)为添加注意力机制的80 个通道对应的特征图,(d)为(c)图中80 个通道叠加的特征图。
由图5 可见,(a)图中80 个通道对应的特征图之间区别度不高、特征相似;(b)图中图像高亮部分过多,且多数出现在背景部分,可用于分类的特征较少;(c)图中80 个特征图之间的区别度较高,可直观地看出某几个通道包含的特征信息较为重要;(d)图中图像高亮部分较少且集中于一个区域内,可通过此区域的高层次语义信息准确地区分物体。由此可见,本文改进的基于注意力机制的检测分支能够有效减少背景等无关信息的对检测的干扰。图6 为通过注意力分析后重新为80 个通道所赋权值的散点图。
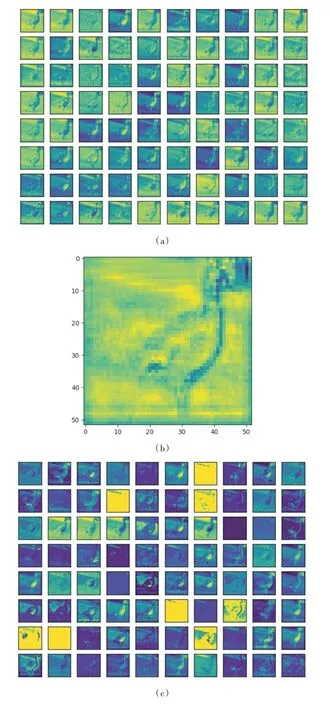
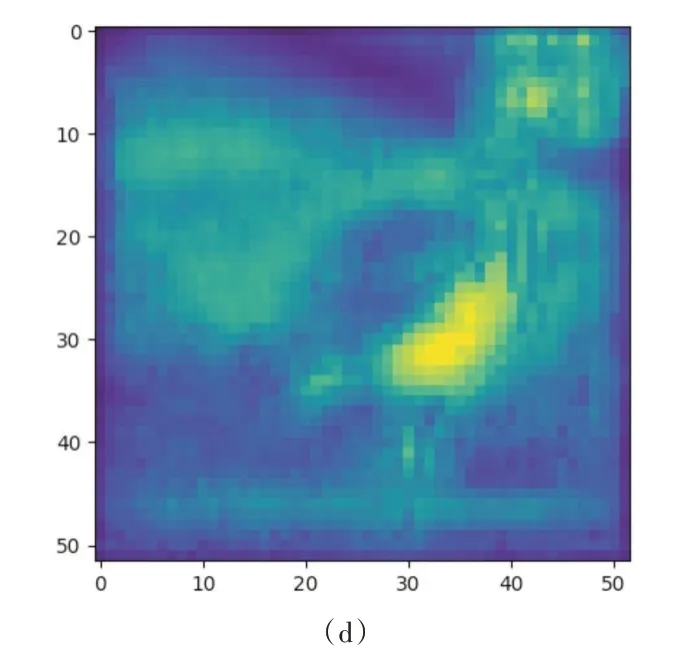
Fig.5 Feature map of the convolutional layer on the detection branch where the feat1 layer is located图5 feat1 层所在检测分支上的卷积层的特征图
由图6 可知,feat1 层的权值基本分布在0 周围,均值约为0.05。在经过注意力机制分析后,为多数通道赋予了一个很小的权重,即忽略一些次要信息。仅有少数权值分布较为分散,即为包含重要信息的通道赋予了一个较大的权重,突出显示其包含的特征信息。
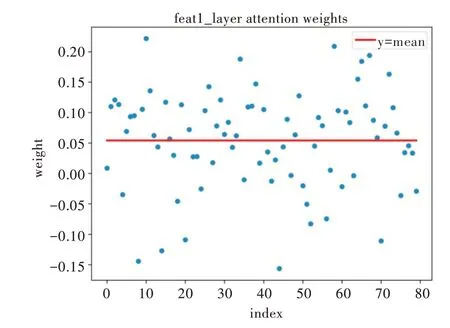
Fig.6 Scatter plot of weight distribution图6 权值分布散点
3.3 绝缘子状态检测
实验使用自制绝缘子数据集,图像来源于网络,分辨率均在800×600 以上,清晰度较高,能够满足目标检测需要。数据集主要包含正常绝缘子(normal)和“自爆”绝缘子(defective)两类,共1 000 张图像(正常绝缘子700 张,自爆绝缘子300 张)。图7 为样例图像。实验过程中,选取100张图像作为测试集,900 张作为训练集。数据集标注格式为VOC 格式,采用LabelImg 工具进行手工标记,得到相应的.xml 注释文件。
由于检测的绝缘子目标在单张图像中所占的比例较小,因此将绝缘子图像输入网络前需统一缩放至608×608大小。图8 为自制数据集中目标标注框所占图像尺寸的比例分布图,横坐标为目标框的面积占图像面积的比例,纵坐标为比例在每一区间上的对应目标数量。由此可见,占比小于10%目标有1 397 个,占所有目标的68.41%,表明数据集的大部分目标均为小目标。为此,本文提出基于AETiny YOLOV3 目标检测模型主要应用于检测小目标。

Fig.7 Sample image of self-made insulator data set图7 自制绝缘子数据集的样例图像
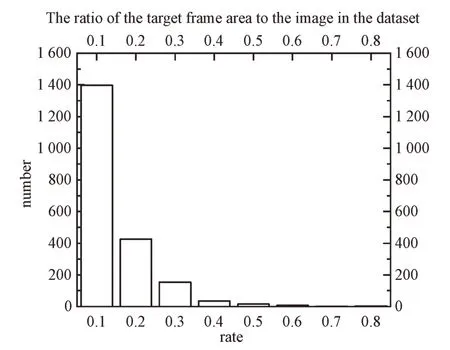
Fig.8 Proportion distribution of the label frame of self-made insulator data set in the original image size图8 自制绝缘子数据集标注框占原图像尺寸的比例分布
实验环境和实验设置除输入分辨率更改为608×608外,其余参数设置均与3.2 节中相同。表4 为本文改进模型与原模型在自制数据集上的对比结果。

Table 4 Performance comparison on the self-made insulator data set表4 在自制绝缘子数据集上的性能对比 (%)
表4 中实验结果为在IoU为0.5 时的测试结果。其中,normal-AP表示正常绝缘子的检测准确率,defective-AP表示“自爆”绝缘子的检测准确率,mAP为平均准确率。本文所改进的模型对正常绝缘子和自爆绝缘子的mAP相较于Tiny YOLOV3 算法提高了15.27%,正常绝缘子的识别率提升了16.74%,自爆绝缘子的检测准确率提升了13.79%。由此证明,本文模型较原算法提高了目标检测的准确率,且检测速度相当。图9 为本文模型与Tiny YOLOV3的检测结果的对比图。其中,图9(a)(b)为Tiny YOLOV3的目标检测结果,(c)(d)为相同图像在AE-Tiny YOLOV3 模型中的目标检测结果。
从图9的对比结果可见,AE-Tiny YOLOV3 模型可准确检测Tiny YOLOV3 模型中漏检的小目标。对比(a)和(c),Tiny YOLOV3 模型仅能检测到1 个正常绝缘子,漏检了2 个正常绝缘子和1 个“自爆”绝缘子;对比(b)和(d),二者均可准确检测到正常绝缘子,但由于“自爆”绝缘子的目标较小,原模型通常难以检测,而本文模型可准确检测并定位“自爆”绝缘子。

Fig.9 Comparison of insulator detection results图9 绝缘子检测结果对比
4 结语
本文提出的AE-Tiny YOLOV3 模型,不仅通过替换特征提取网络增加了模型的特征提取能力,降低了模型参数量,还保证了目标检测速度。同时,通过在预测网络中增加检测分支形成3 尺度预测,以更好预测自爆绝缘子等小目标。最后,通过注意力机制,使模型在预测时可自适应关注有效信息较多的通道特征,进一步提高了目标检测的准确率。通过在VOC07+12 数据集上的实验证明,AE-Tiny YOLOV3 模型目标检测的平均准确率为78.22%,相较于原模型提高了16.89%。在满足模型实时性的需求外,检测准确率更高。在自制绝缘子数据集上,本文所提出的模型目标检测的平均准确率为86.53%,相较于原模型提高了15.27%。虽然AE-Tiny YOLOV3 模型的目标检测精确度有所提高,但与大型检测网络相比仍有较大差距,需进一步改进。并且,如何让模型既满足嵌入式平台实时监测的需求,又能进一步提高准确率,将是下一步的研究重点。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
电力建设(2015年2期)2015-07-12
噪声与振动控制(2015年4期)2015-01-01
电测与仪表(2014年6期)2014-04-04
电气传动自动化(2014年6期)2014-03-20
电视技术(2014年19期)2014-03-11
