
基于脑电信号的癫痫发作预测
2022-03-25 04:45魏海坤张侃健
软件导刊 2022年3期
朱 柠,魏海坤,张侃健
(东南大学 自动化学院,江苏南京 210096)
0 引言
癫痫是一种慢性非传染性脑病[1],被定义为一种持久性产生大脑紊乱的疾病,会导致严重的机体、认知、心理障碍和社会后果[2-3]。癫痫发作是由大脑中异常、过度的神经元活动导致的短暂症状[4]。癫痫的平均发病率为23~190/10 万,儿童的发病率可达25~840/10 万[5],且发展中国家的癫痫发病率明显高于发达国家[6]。传统的流行病学和卫生统计方法只考虑疾病死亡率而不考虑残疾率,导致神经系统疾病对人类健康的影响被严重低估。全球范围内应对神经系统疾病的资源分配不足,迫使人们寻求更有效的解决方案。
1 相关研究
癫痫发作时如果得不到及时救治,可能会对患者生命安全产生极大伤害,预测癫痫发作可有效规避健康风险。有临床经验的医生可通过患者的脑电波图像对其病情有大致了解,但可能会忽视细小波动,而采用机器预测癫痫发作往往需要处理海量数据。近年来,人工智能(Artificial Intelligence)和机器学习(Machine Learning)技术由于其强大的数据处理能力,在癫痫发作的预测中发挥了一定作用[7-8]。目前,研究人员已经建立了一套解决癫痫预测问题的框架,主要包括4 个步骤[9],具体为:
(1)原始脑电数据的采集与转换。获取数据的方法主要有侵入式脑电和非侵入式脑电(头皮脑电)两种。为实时获取数据,需要将患者脑电信息通过电极连线传输到设备中。
(2)数据预处理和特征提取。原始脑电数据的信噪比过低,且电极相邻通道间具有强统计学相关性(皮尔森相关系数高于80%),因此从原始数据中提取有效信息十分关键,一般选择在一个确定的时间窗口内对数据特征进行提取。综合现有研究结果,数据特征可分为时域特征、频域特征、时域—频域特征线长度、离散小波变换特征、连续小波变换特征和傅里叶变换特征。例如,王雅静等[10]采用预发作数据段选取方法,在MIT 公共头皮脑电数据库和宣武医院收集的数据集上进行测试,召回率分别为95.76%和97.80%。
(3)运用机器学习相应的分类器。常用的分类器,如支持向量机(SVM)、随机森林(RF)和神经网络(BP、CNN、RNN)被广泛用于癫痫发作模式的识别。例如,Cho 等[11]将神经信号的锁相值作为SVM 分类器的输入特征,得到召回率为82.44%的分类结果;Ahmad 等[12]将傅里叶变换后的数据作为特征,召回率达到94.8%;Zhang 等[13]将信号的绝对/相对功率谱作为SVM 分类器的输入,模型性能极大提升,召回率达到98.68%。RF 模型的拟合能力强于SVM,在癫痫预测模型上的分类结果更优。例如,Truong 等[14]选择时域特征,Tzimourta 等[15]选择傅里叶变换后的频域特征,Sharma 等[16]选择经验模态变换后的数据作为RF 输入,得到模型的召回率分别为96.94%、99.74%、98.6%。在神经网络方面,刘亚朋[17]、O’shea 等[18]和Zhou 等[19]采用的1DCNN模型召回率分别为93.53%、95.9%、95.7%;Cao 等[20]采用的2DCNN 模型召回率为96.2%;Tsiouris 等[21]将时域和频域特征作为简单3 层长短期记忆人工神经网络模型LSTM的输入,得到的召回率为99.28%。现有神经网络模型的召回率略低于RF,但其误报率一般在0.1/h 内,而RF的误报率一般为0.21~0.77/h。在实际应用中,往往需要根据具体情况选择输入特征和分类器。
(4)模型评价。通常采用精确率(Precision)、召回率(Recall)和误报率(False Discovery Rate)评价模型性能优劣。
本文基于南京某医院癫痫数据集,为医患提供较为先进的癫痫监测方案,一方面帮助医生全面了解患者病情,另一方面使患者对癫痫发作产生预警,以便及时采取医疗措施。本文的研究意义在于解决医院现有数据集的癫痫预测问题,是机器学习相关技术应用于国内癫痫预测的实例;亮点在于该数据集与现有公开数据集差异较大,主要体现在数据量和数据处理方式上,同时本文方法集成了现有框架的优势,具有一定泛用性。
2 数据采集与预处理
2.1 数据集
采用南京某医院收录的采用立体定向脑波技术(SEEG)诊断与治疗的癫痫患者脑电信号数据,该数据集尚未公开。SEEG 是一种侵入式癫痫诊断与治疗技术,其通过微创外科手术将直径为0.8mm的电极置入脑内以实时监测癫痫患者的脑电信号,确定发病脑部区域。患者通过SEEG 植入脑部电极后,需要住院24h 实时监测脑电信号,癫痫发作时,射频热凝发生器会与目标电极点接触,即可对脑部相应区域实施热凝固治疗,一般需要治疗3~6 次。基于人道主义原则,医院一般不会要求患者为医学研究提供额外的癫痫发作数据,因此该数据集是本文的核心内容。提取其中5 位患者的癫痫发作数据,采样频率为2kHz,患者间植入电极数及其分布情况差异较大。除SEEG 信号数据外,临床上通常辅以肌电图诊断癫痫,这些数据也被记录在文件中。5 位患者植入的电极数分别为117、127、84、81、110,电极空间分布为A~J 区,每位患者相同区域的采集信号通道数有一定差异,这是由医院硬件设备连接不稳定造成的。数据集中记录的癫痫发作次数分别为4 次、6 次、3 次、3 次、6 次。
2.2 数据预处理
信道采集的无效数据包括3 种情况:第一种是信道已被使用,但由于连接不稳定或硬件设备损坏而产生无效数据,该种数据的特征是在维持一段有效信息后振幅突然激增,并保持较长时间,具体如图1 所示;第二种是信道未在临床中被使用,该种数据有高振幅、周期性波动类型,也有高振幅、信号不连续类型,具体如图2 所示;第三种是临床用于辅助诊断的肌电信号数据,与脑电数据不同的是,肌电数据往往是通过振幅体现肌电信号变化,且周期远小于正常脑电数据,具体如图3 所示。在正式处理数据之前,需要将这3 类数据剔除,降低有效数据的提取难度。

Fig.1 Invalid data caused by unstable channel connection图1 信道连接不稳定造成的无效数据

Fig.2 Invalid data caused by the channel not being used in the clinic图2 信道未在临床中使用造成的无效数据

Fig.3 Invalid data caused by EMG data for auxiliary diagnosis图3 辅助诊断的肌电数据造成的无效数据
3 特征提取
3.1 同区域通道间数据相关性
统计学三大相关系数分别为Pearson、Spearman 和Kendall,反映的都是两个变量之间变化趋势的程度及方向,数值范围为-1~1,0 表示两个变量不相关,正值表示正相关,负值表示负相关,值越大表示相关性越强。
Pearson 相关系数有两个假设,一是两个变量服从正态分布,通常采用t检验确定相关系数的显著性,二是两个变量的标准差不为0。Pearson 相关系数的计算公式为:

式中,cov(X,Y)表示X、Y的协方差,σX σY表示X、Y标准差的乘积。
Spearman 和Kendall 相关系数适用于数据秩序相关的情况,本文研究的是相邻通道间数据的相关性分布,更适合使用判断两个变量是否线性相关的Pearson 相关系数。将原始数据通道间的Pearson 系数值转换成热力学图(heatmap),可以更加明显地观察到相邻通道间具有统计学强相关性,具体如图4(彩图扫OSID 码可见)所示。由于数据集的采样频率为2kHz,通道数均值为103.8,需要处理的数据量远高于现有公开数据集。为降低模型后续计算量,可将具有统计学强相关性的通道数据融合。此外,相关性的验证对于患者脑部电极接入位置和数量的确定具有一定参考价值。

Fig.4 Heatmap of Pearson coefficient between channels图4 通道间Pearson 系数热力学图
3.2 时域与频域特征提取
特征提取的目的是从海量数据中提取有效信息,减少模型对无效信息的拟合,降低模型结构维度,提升模型拟合速度,使医院的硬件设备能够满足模型运行需要。现有特征提取方法多基于信道中一段时间的数据进行,称为时间窗口,通常为5s,移动步长为1s,以提前15min 预测癫痫发作为目标,也即本文采用的时间窗口和移动步长大小。这两个值实际上基于癫痫预测的准确性和实时性作出的平衡性选择,并不一定是最优解。常用特征提取方法及相关特征如表1 所示。

Table 1 Time domain and frequency domain feature extraction methods and their characteristics表1 时域、频域特征提取方法及其特征
3.3 样本正负样本比例
二分类模型的损失函数一般选择交叉熵损失函数(binary_crossentropy),计算公式为:
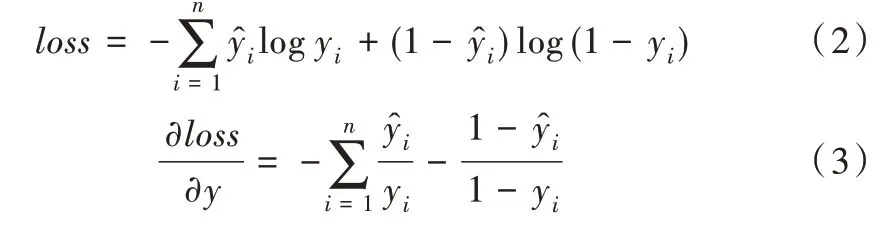
由上式可知,如果样本类型不平衡,如正样本数过少,模型便会默认将所有样本识别为负样本,拟合结果的loss值就会很低,这样显然不符合实际应用需求。因此,在对样本进行分类时需将正负样本的比例设置为1,最大程度地发挥模型的拟合性能。癫痫发作是一个短暂过程,一般患者住院7 天能监测到的癫痫发作次数为3~6 次,每次发作时间为30~75s,样本数极低。因此,本文采用欠采样的方式,以保证正样本/负样本=10。这个比值是综合考虑模型性能得出的一个较优解,该值过大可能会导致模型拟合失败,过小会导致拟合程度不够。
4 LightGBM 分类器及其结果评估
4.1 XGBoost 与LightGBM
XGBoost 采用泰勒二阶展开近似代价函数,使其能够自定义损失函数,拟合能力更强,其还采用L2 范式和列采样抑制过拟合。LightGBM 相较于XGBoost 具有训练速度快、内存占用率低的特点,可视为XGBoost的优化解,优化了模型运算量、内存消耗等,这是由于LightGBM 采用了直方图算法和带深度限制的Leaf-wise的叶子生长策略。然而,内存消耗的降低和计算效率的提升带来了一定程度的准确率降低,这是由于特征被离散化,但在梯度提升(Gradient Boosting)的框架下没有太大影响。
XGBoost 和LightGBM 是目前机器学习领域泛用性最强、应用最多、效果最好的分类器。癫痫数据集的数据量较大,因此选择LightGBM 作为分类器。
4.2 算法流程
本文建立的算法流程如图5 所示,分为数据处理、模型训练和预测结果输出3 个阶段。数据处理阶段将无效信息筛出,通过特征提取提升样本有效信息比例,减少计算量并对正负样本比进行平衡;模型训练采用五折交叉验证法,最后采用投票法输出模型预测结果。
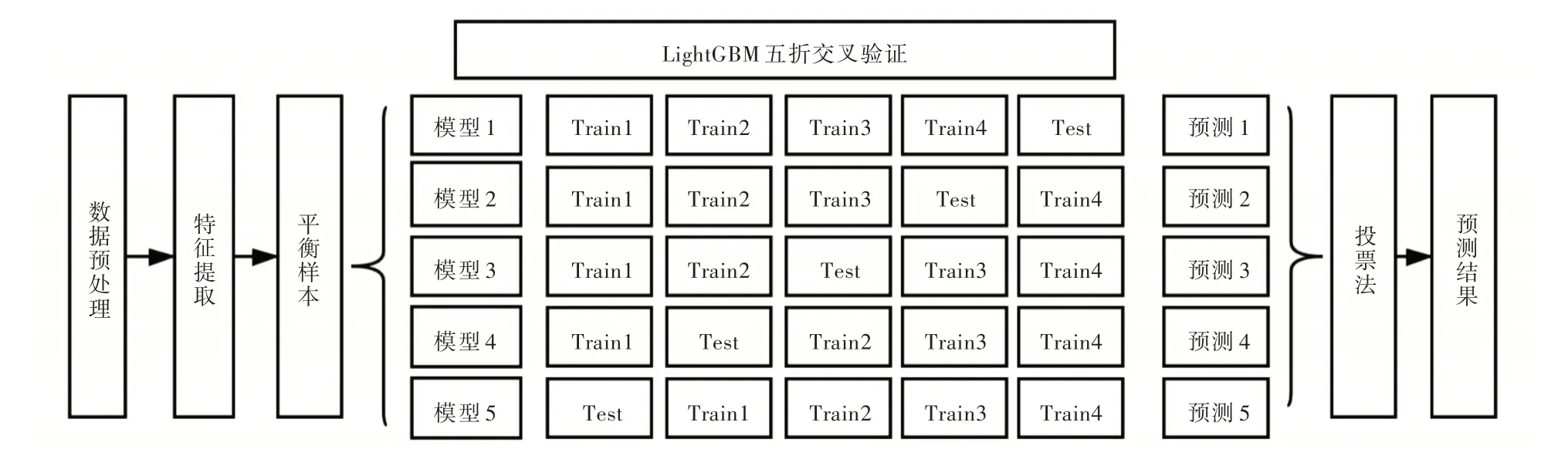
Fig.5 LightGBM five-fold cross-validation algorithm flow图5 LightGBM 五折交叉验证算法流程
4.3 分类结果评估
对每位患者的数据单独进行五折交叉训练,得到基模型的准确率如表2 所示。投票法结果表明,5 位患者的数据均达到召回率100%,误报率为0h-1的效果。测试集的选取是在单独某次发作或样本数量不足的情况下,加入某段相对独立的发作信息而来,即测试集的样本即使和某次发作出自同一时间段,样本内所含时间步长也未经过模型训练。

Table 2 Accuracy of LightGBM-based model training set表2 LightGBM 基模型训练集准确率 单位:%
模型在测试集得到的结果如表3 所示,测试集的平均召回率为84.18%,误报率为0.57/h。以上结果是基于每秒进行一次模型输出得出,在实际应用中,往往可以通过一定时间段内的模型输出结果综合确定癫痫是否发作。模型的误报主要集中在发作前15~25min 内,可能是由于类别间的划分间隙不够明确,位于类别边缘的点容易造成分类的误报和漏报,可通过更加准确地选取分类标签来改善。

Table 3 LightGBM test set results表3 LightGBM 测试集结果
5 结语
结合现有癫痫发作预测的研究成果,本文选择癫痫数据集的时域和频域特征,融合强统计学相关的通道间数据,以LightGBM 作为分类器,得到测试集的平均召回率为84.18%,误报率为0.57/h,说明本文方法能较好地解决现有癫痫数据集的分类问题。然而,本文仅针对每个患者单独进行建模且要求其至少有1~2 次有记录的癫痫发作,距离医院实际应用,即找到患者统一的癫痫发作模式仍有许多工作要做。
猜你喜欢
电子制作(2018年19期)2018-11-14
电子测试(2018年1期)2018-04-18
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代电生理学杂志(2016年3期)2016-07-10
现代电生理学杂志(2016年4期)2016-07-10
现代电生理学杂志(2016年1期)2016-07-10
现代电生理学杂志(2015年1期)2015-07-18
噪声与振动控制(2015年4期)2015-01-01
