
一种视频防抖的车辆检测算法
2022-03-25 04:45薛余坤谈文蓉邢雪枫陈秋实
软件导刊 2022年3期
薛余坤,谈文蓉,邢雪枫,陈秋实
(西南民族大学计算机科学与技术学院计算机系统国家民委重点实验室,四川成都 610041)
0 引言
2020 年2 月24 日,国家发改委、中央网信办、工业和信息化部等11 个部委提出:到2025 年,中国标准智能汽车的技术创新、产业生态、基础设施、法规标准、产品监管和网络安全体系基本形成[1],标志着智能汽车成为国家未来发展战略的一部分,这也是世界汽车行业的发展趋势。
对周围车辆进行快速准确的识别是智能汽车在高级驾驶辅助(Advanced Driving Assistance System,ADAS)功能方面的重要内容。随着计算机视觉相关技术的快速发展,基于行车记录仪的前方车辆检测算法在定位准确度和识别速度方面有了很大提升。基于视觉的车辆检测算法一般使用阈值法、边缘检测法等对候选区域特征进行检测。例如,Viola 等[2]设计了基于AdaBoost的车辆检测方法;Harzallah 等[3]提出基于SVM的目标分类算法。近年来,基于深度学习的目标检测算法,如Faster R-CNN(Faster Region-Convolutional Neural Networks)[4]在识别准确率方面表现优异,但由于其采用“两步走”的方式,识别一张图片需要送入神经网络两次,分别进行目标预测框回归和目标种类确定,大大影响了图片检测速度,在高速行车过程中将产生巨大安全隐患[5]。为此,黎洲等[6]、Seo[7]提出了基于YOLOv2(You Only Look Once v2)框架的车辆检测算法,可同时进行车辆及其视角识别。
抖动对视频质量的影响较大。目前视频防抖技术一般包含特征点检测、运动估计、运动平滑和运动补偿4 个过程,传统的防抖方法包括基于特征匹配的视频防抖、基于滤波的视频防抖。例如,熊炜等[8]提出结合金字塔光流法和卡尔曼滤波的视频稳像算法;张培健等[9]使用级联卷积神经网络对轻量级视频进行插帧,但在提高检测精度的同时降低了计算速度。
本文采用最新的YOLOv4(You Only Look Once v4)[10]作为车辆检测算法,极大地提高了检测速度,但在对车载视频进行检测的过程中发现,道路颠簸、车辆自身抖动造成的视频帧模糊问题对识别准确率产生了较大影响。为解决上述问题,本文创新性地提出对进行车辆检测视频进行防抖预处理的方法,由于车辆行驶过程中对防抖算法的计算速度有很高要求,故使用光流跟踪算法[8]对行车记录仪采集到的模糊视频帧进行运动补偿,以提高基于车载视频进行车辆检测的识别准确率。
1 基于YOLOv4 算法的车辆检测算法
YOLO 系列算法[11]诞生于2016 年,在众多针对目标检测的深度学习算法中脱颖而出,其创新性地采用“一步走”策略[7],将目标检测任务划分为单一的回归任务,只需要将被识别图片输入网络中一次便能输出目标种类和目标框的准确位置[12]。
YOLOv4 作为YOLO 系列的第4 个版本,将最新科研成果融于一体,使用Mosaic 数据增强方式作为输入端数据处理方法,使用全新的CSPDarknet53 作为主干网络,广泛使用深度残差网络结构,将Mish 作为全新的激活函数,使其在检测速度和目标框的识别精度方面进一步提升。在COCO 数据集上,YOLOv4的平均精确度(Average Precision,AP)和每秒检测帧数(Frames Per Second,FPS)较上一代分别提高了10%和12%[10]。
1.1 YOLOv4 算法流程
YOLOv4 算法框架由输入层、基于深度残差网络的卷积层、池化层、FPN(Feature Pyramid Network)层、PAN(Path Aggregation Network)层和预测层组成,具体流程如图1 所示。
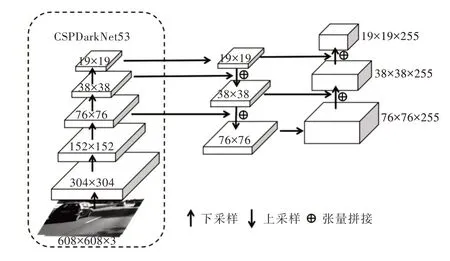
Fig.1 Flow of YOLOv4 algorithm图1 YOLOv4 算法流程
首先,输入的图片进行Mosaic 数据增强处理,对4 张图片进行随机缩放、旋转、裁剪等操作,最后再拼接合成为一张图片输入到CSPDarkNet53 主干网络中进行训练。CSPDarkNet53 网络采用3×3 大小的卷积核,采样步长为2,因此可以起到下采样的效果。然后,将输入图片大小统一调整为608×608,经过5 次下采样操作,分别得到304×304、152×152、76×76、38×38 和19×19 大小的特征图,并在池化层中引入Dropblock 算法,随机删除一部分神经元数量,使网络结构变得更加简单,运算速度得到明显提升。YOLOv4 使用FPN 算法,对经过数次下采样运算得到的19×19 大小的特征图再进行上采样操作,与38×38 大小的特征图进行融合,再对得到的特征值继续上采样,并与76×76 大小的特征图再次融合。最后,对FPN 层得到的3 种不同大小的特征图再进行下采样,分别与上一层相同大小的特征图进行融合,得到分类成功的3 种不同尺度的特征图,其中最大的特征图为76×76,对应最小预测框(Anchor Box);中等特征图为38×38,对应中等预测框;最小特征图为19×19,对应最大预测框。
1.2 模型训练
模型训练采用KITTI 数据集,其是目前世界上最大的针对自动驾驶的数据集[13]。为防止过拟合,采用Mosaic 数据增强的方式对数据进行预处理,具体如图2 所示。

Fig.2 Schematic diagram of Mosaic data enhancement algorithm图2 Mosaic 数据增强算法示意图
将KITTI 数据集的80%作为训练集,20%作为测试集。由于本文只针对车辆进行检测,故将目标识别的种类设为1,种类名称设为car,并设置模型训练的批大小(Batchsize)为924 个,迭代次数(Iteration)为32 000 次,训练周期(Epoch)为200 次。为保证模型对不同尺寸大小的图片具有良好的泛化性,在训练过程中使用大小尺度图片混合训练的方式,每隔几个训练周期就随机改变输入图片的尺寸大小,使模型对不同分辨率的图片都能取得较好的检测精度。
2 视频防抖算法
在车辆行驶过程中,行车记录仪拍摄的视频往往会由于道路颠簸、车身振动等原因产生视频帧模糊的问题,不利于检测算法准确识别出车辆目标。针对该问题,首先使用SURF(Speeded Up Robust Features)进行特征点检测;然后使用基于特征匹配的光流法跟踪特征点位置,计算其运动矢量,估计相机运动路径;最后使用卡尔曼滤波算法[14]对相机运动路径进行平滑操作,从而输出相对稳定的视频帧序列。防抖算法的流程如图3 所示。
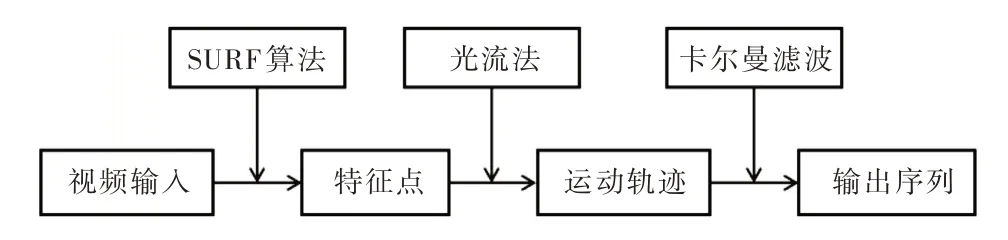
Fig.3 Flow of anti-shaking algorithm图3 防抖算法流程
2.1 SURF 算法
SURF 算法使用矩阵的形式侦测特征点,以Hessian 矩阵行列式值代表周围像素点的变化量,然后进行非极大值抑制。为实现尺度不变性,SURF 算法还使用尺度为σ的行列式值进行特征点检测。给定图像灰度函数为I(x,y),则Hessian 矩阵H(x,σ)在x处尺度为σ的定义可表示为:

式中,Lxx(x,σ)为高斯函数(如式2 所示)的二阶偏导数,g(σ)为图像I(x,y)在x处的卷积结果,Lxy(x,σ) 与Lyy(x,σ)的含义类似。
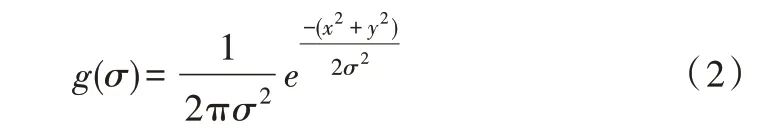
通过求解Hessian 矩阵行列式得到局部极值点,每个局部极值点与同一层其他8 个相邻点,以及上下两层的各9个点,形成一个3×3×3的立体区域,当局部极值点为这个立体区域的最大(或最小)点时,则为候选特征点。
2.2 基于特征点匹配的光流法
运用光流算法追踪SURF 算法采集到的特征点运动轨迹,不断对目标的主要特征进行定位和跟踪[15]。光流法假定同一目标在不同帧之间运动时亮度值不会发生改变[16],假设某一像素在第一帧的光强度为f(x,y,t),其中t为时间维度,其经历dt时间移动了(dx,dy)的距离,故可得:

使用泰勒展开式展开式(3)右端项,可得到:
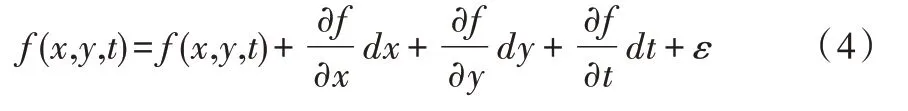
式中,ε表示二阶无穷小项,可忽略不计。将式(4)代入式(3)后同除以dt,可得:

3 实验结果与分析
使用移动PC 平台进行实验测试,具体配置为Windows10 操作系统、Inter CoreI5-7500 3.0GHz CPU、16GB 内存、NVIDIA GeForce GTX 1655 4G GPU。测试使用到的照片、视频均为真实行车记录仪在高速公路上采集的数据。
3.1 视频防抖结果与分析
选取一段长度为1 269 帧的真实道路拍摄视频,经过SURF 算法和光流法处理后,计算得到原视频序列相机的水平方向位移、垂直方向位移和旋转角度位移,具体如图4所示。
经过卡尔曼滤波算法处理后的位移结果如图5 所示。可以看出,经过防抖算法处理后的视频序列在水平方向、垂直方向和旋转角度的位移频率明显低于未经处理的原视频序列,稳定性得到了很大提高,证明本文算法能有效实现防抖。


Fig.4 Movement trajectory of unstabilized camera图4 未增稳的相机运动轨迹
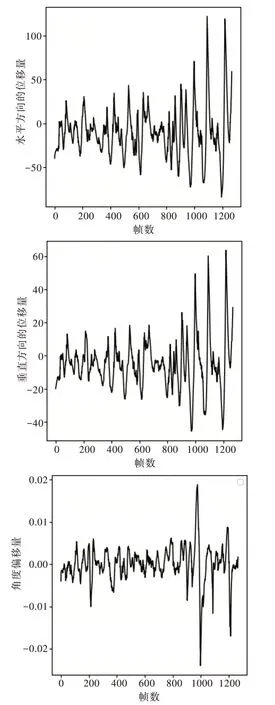
Fig.5 Camera movement trajectory after stabilization图5 稳定后相机运动轨迹
3.2 优化前后检测结果比较分析
使用KITTI 数据集对本文模型进行训练与测试,最终识别准确率达到96.51%。使用该训练权重对真实行车拍摄的视频进行防抖优化前后车辆检测的对比试验。对未经处理的原行车视频进行逐帧提取,抽取其中由于抖动造成图像模糊的视频帧,送入YOLOv4 框架进行检测,结果如图6 所示。再将经过防抖处理的视频帧送入YOLOv4 网络,检测结果如图7 所示。此外,该模型在其他模糊视频帧上也取得了类似效果,说明其可以提高整段视频的稳定性。测试结果表明,经过本文防抖方法处理的视频序列中的车辆识别准确率明显提高。

Fig.6 Original video detection result图6 原视频检测结果

Fig.7 Video detection result after anti-shaking process图7 防抖处理后视频检测结果
4 结语
本文设计了基于视频防抖的YOLOv4 车辆检测算法,解决了由于道路颠簸、车辆自身振动造成视频帧模糊而影响检测效果的问题。实验结果表明,该方法可有效提高基于视频序列的车辆检测准确度,并具有较好的实时性,在行车记录仪中具有一定潜在应用价值。但针对抖动情况较为严重的路况,该防抖算法仍存在不足,未来将对图像增稳算法进行优化和改进。
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
小太阳画报(2018年3期)2018-05-14
数学小灵通·3-4年级(2017年9期)2017-10-13
阅读与作文(小学低年级版)(2016年12期)2016-12-22
汽车与安全(2016年5期)2016-12-01
汽车文摘(2015年11期)2015-12-02
中国交通信息化(2014年4期)2014-06-05
河南科技(2014年23期)2014-02-27
