
基于LDABPSO算法的烟叶复烤配方关联特征挖掘
2022-03-25 04:45杜清清侯开虎陈兴侯刘雅琴马显滔范振宇孙浩巍
软件导刊 2022年3期
杜清清,侯开虎,陈兴侯,刘雅琴,马显滔,范振宇,孙浩巍
(1.昆明理工大学机电工程学院,云南昆明 650500;2.云南烟叶复烤有限责任公司麒麟复烤厂,云南曲靖 655000;3.云南省烟草质量监督检测站,云南 昆明 650500)
0 引言
卷烟作为一种特殊的农业副食品,通常要求吸食口感长期保持稳定[1]。复烤企业作为烟草生产链的关键环节,实现对烟叶的初步加工及模块化配方打叶,对不同质量的烟叶进行协调搭配,为卷烟企业提供稳定的原材料。但在实际生产中,烟叶质量受气候、土质等因素的影响,导致复烤配方每年的波动性较大,如何维护复烤配方模块是目前亟待解决的问题。
近年来,已经有学者针对烟叶复烤配方维护展开研究。雒兴刚等[2]基于历史配方数据,运用关联规则Apriori算法挖掘配方中隐含的规则,得到单料烟的替换规则,对于卷烟配方维护具有积极意义。王萝萍等[3]在文献[2]的基础上对Apriori 算法进行改进,提出一种基于矩阵的多维关联规则算法并在烟叶复烤配方中成功实践。上述文献通过Apriori 算法可得到配方中隐藏的大量烟叶搭配协同信息进而提炼为规则,能在一定程度上实现配方维护。但采用Apriori 算法进行关联分析,需要人工设定规则提取阈值,挖掘结果受主观性影响大,造成海量冗余规则的出现且规则质量较低,如何解决上述问题是现阶段研究的方向。
关联分析属于离散域问题,而二进制粒子群算法(Binary Particle Swarm Optimization,BPSO)在离散优化方面具有较好的性能[4],近年来备受研究者关注。宋刚等[5]利用二进制粒子群算法优化LSTM 模型,并将其应用于股票预测研究,该模型提高了预测准确度,且具有普遍适用性;闫坤等[6]针对复杂网络问题,提出基于二进制粒子群算法的攻击策略,研究表明该策略具有高效性等优势;古良云等[7]提出一种改进二进制粒子群算法,并且在6 个高维数据集上进行关联规则挖掘验以证算法性能,通过与Apriori 算法作对比,表明该方法具有一定可行性;钟倩漪等[8]将一种多策略二进制粒子群算法用于关联规则挖掘,如此可得到更有效的规则。上述文献表明,二进制粒子群算法在离散域问题及关联规则挖掘中的有效性,但现有文献并未将该算法应用于复烤配方维护领域。
综上,提出一种改进二进制粒子群算法(Latin Hypercube Arcshaped Binary Particle Swarm Optimization,LDABPSO)用于烟叶复烤配方关联规则挖掘。首先对二进制粒子群算法从种群初始化、可行解的停滞、扰动机制等3 个方面提出改进策略;其次,将LDABPSO 算法在标准测试函数上与BPSO算法[9]、李浩君等[10]提出的ABPSO算法(Arcshaped Binary Particle Swarm Optimization,ABPSO)作对比。最后,以云南省麒麟复烤厂近年配方数据作为数据源,运用LDABPSO 算法进行配方关联规则挖掘。实验表明,当Apriori 算法最小支持度和最小置信度分别设置为0.18 和0.5 时,LDABPSO 算法挖掘到的烟叶规则数量相比Apriori算法减少90.23%,极大减少了冗余规则的产生,挖掘到的烟叶搭配规则质量更好,且算法运行时间减少8.4%。
1 改进二进制粒子群算法
基本粒子群算法(Particle Swarm Optimization,PSO)只能解决连续问题,为了解决离散空间问题,Kennedy 等[9]于1997 年在PSO 算法的基础上提出BPSO 算法。针对BPSO算法容易陷入局部最优且产生大量无用计算的缺陷,本文从全局及局部搜索方面进行算法改进,进而提出LDABPSO算法。
1.1 全局搜索
本文全局改进策略主要从种群初始化方面进行设计,BPSO 算法一般采用随机初始化策略,但种群的好坏同样影响算法的收敛速度和精度[11]。鉴于此,本文提出采用拉丁超立方抽样初始化种群,均匀划分搜索空间,保持初始种群的多样性[12],与随机初始化不同的是,拉丁超立方抽样可以保证变量覆盖整个分布空间。图1 和图2 分别为随机抽样分布图和拉丁超立方抽样图,在区间[0,1]随机抽取10 个点,可以看到拉丁超立方抽样基本可以分布到整个空间。
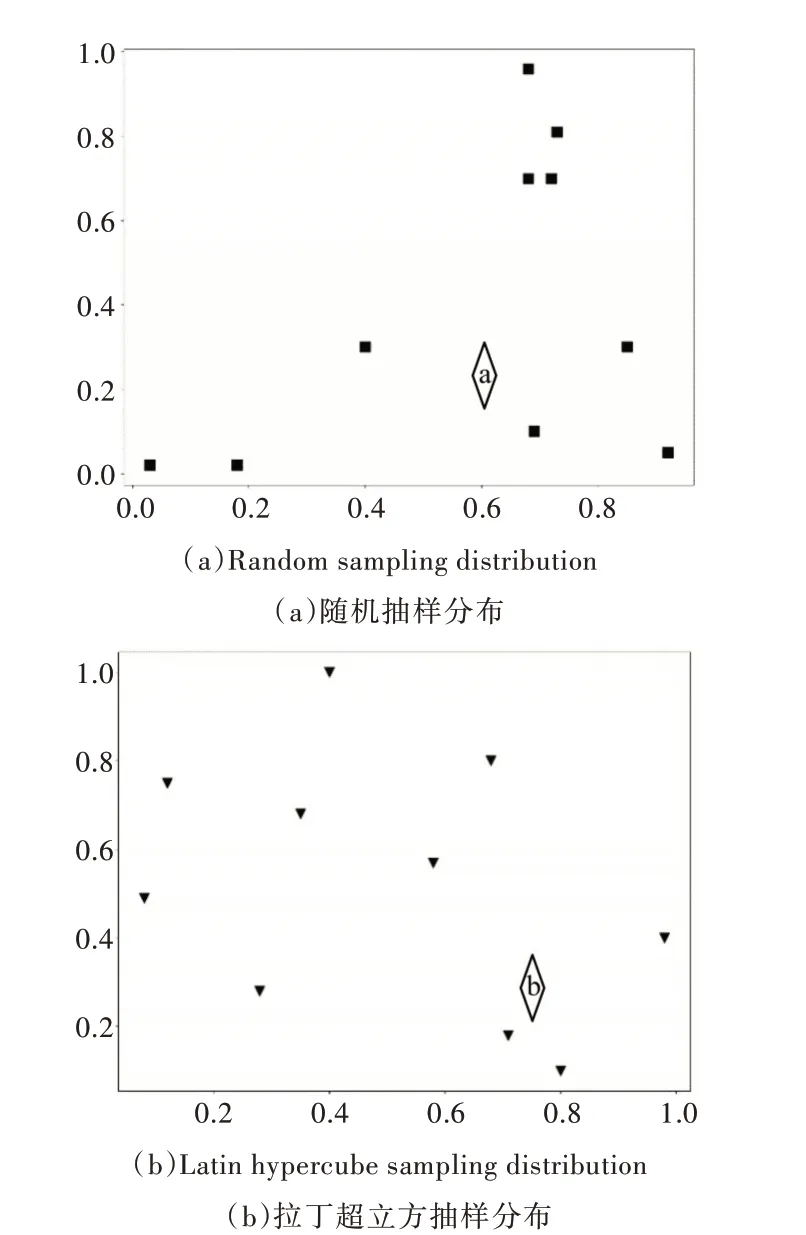
Fig.1 Comparison of the two sampling methods图1 两种抽样方式比较
1.2 局部搜索
1.2.1 limit 阈值
受文献[13]启发,本文引入蜂群算法在迭代过程中可行解的停滞次数limit 阈值。在BPSO 算法迭代过程中,算法后期全局搜索过强、局部搜索不足,容易陷入局部最优[14]。limit 阈值的引入在很大程度上能促使算法跳出局部最优,是对算法迭代过程的一种监控。在算法初始阶段,提前设置阈值的极大值limitmax。算法迭代时,观察每个粒子在阈值内的位置是否发生变化,若没有发生变化,则说明算法可能陷入了局部最优,此时需要调整陷入局部最优的粒子位置。本文采取的策略是:若某个粒子位置在limitmax 内的位置没有发生改变,则直接舍弃,生成新的粒子作为补充。文献[15]提到,阈值大小对算法寻优能力的影响较大,经过多次试验,本文将limitmax 阈值设置为80。
1.2.2 随机扰动

其中,是第k次迭代时第i个粒子的速度,w为惯性权重,C1、C2为学习因子,r1、r2来自于均匀分布(0,1),pi为粒子最佳适应值,g为全局最优适应值,xi是粒子当前位置,x′为粒子随机位置,类似地,r3来自于均匀分布(0,1)。由于BPSO 算法中粒子位置只能为0、1,因而粒子位置通过映射函数决定,rand()为[0,1] 区间的随机数,如式(3)所示。
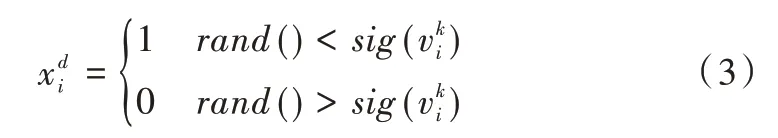
1.3 算法框架

Fig.2 LDABPSO algorithm flow图2 LDABPSO 算法流程
2 LDABPSO 算法测试
2.1 测试函数
为了测试LDABPSO 算法的性能,选择6 种基准函数进行测试,表1 为标准测试函数及参数说明,其中F1、F2、F3为单峰函数,适合测试算法收敛性,F4、F5、F6为多峰函数,用来测试函数跳出局部最优的能力,所有粒子的取值只有0和1。

Table 1 Standard test functions and parameters表1 标准测试函数及参数
2.2 比较算法
为了验证LDABPSO 算法的性能,选用以下算法进行仿真实验:①基本BPSO 算法[9];②文献[10]提出的ABPSO 算法;③本文提出的LDABPSO 算法。
2.3 关键参数确定
(1)学习因子。学习因子C1、C2的大小分别控制粒子向局部最优粒子和全局最优粒子靠近的步长,通常令C1=C2=1.449。
(2)惯性权重。BPSO 算法的惯性权值w 和文献[9]保持一致,采用固定惯性权重。ABPSO、LDABPSO 算法均采用文献[17]的线性递减式惯性权重,相应的最大和最小惯性权重值分别为0.9 和0.4。
(3)其他参数。在本次实验中,BPSO 算法、ABPSO 算法、LDABPSO 算法种群数量均设置为15,迭代次数设置为500 次。参考文献[10],BPSO、ABPSO 算法的最大速度值设为9,LDABPSO 算法的最大速度值设为4。
2.4 仿真结果
仿真实验数据通过10 次独立实验获取,图3 为3 种算法在F1-F6函数上的收敛曲线比较图(以种群数15、迭代次数500 次为例)。
为了更好地体现LDABPSO 算法的性能,表2 计算了BPSO 算法、ABPSO 算法、LDABPSO 算法在F1-F6函数上的均值及方差。


Fig.3 Function convergence curve图3 函数收敛曲线
由于单峰函数F1、F2、F3没有局部最小点,因此算法设置的维度较低,F4、F5、F6为多峰函数,函数随着维度的增加会出现更多局部最小解,所以将其维度设置为30。从表2可知,种群数为15、20、25,对应迭代次数分别为500、600、700。不同的参数设定下,LDABPSO 算法在6 个标准测试函数中具有最好的均值,除多峰函数F5 外,算法同样有最好的方差,说明算法具有较好的稳定性。通过对初始化种群、加入扰动、局部停滞解次数等多方面的改进后,LDABPSO的性能优于文献[10]提出的ABPSO 算法和基本BPSO算法,且LDABPSO 算法在单峰函数上的收敛速度和精度高于ABPSO 算法、BPSO 算法。
图3(d)—图3(f)为多峰函数收敛曲线图,曲线呈直线状态时,说明此时算法已经陷入局部最优,不可避免的是3条曲线都出现了这种情况。曲线状态由直线转为折线时,说明算法跳出了局部最优,从多峰函数收敛曲线图可以看出,相较于BPSO 算法、ABPSO 算法,LDABPSO 算法在多峰函数上的收敛曲线呈折线状态较多,这说明算法具有很好的跳出局部最优的能力。如图3(f)所示,在迭代300 次左右时,BPSO 算法、ABPSO 算法在局部已呈现直线状态,而LDABPSO 算法依然呈折线状态,说明算法在不断跳出局部最优,向质量更好的解迭代,因此本文所提的LDABPSO 算法在单峰、多峰测试函数上均表现良好。

Table 2 Experimental simulation results表2 实验仿真结果
3 LDABPSO 算法关联规则挖掘
本文将一种改进二进制粒子群算法(LDABPSO)用于历史复烤配方(2018-2020 年)的关联规则挖掘,课题及数据均来源于云南省麒麟复烤厂。
3.1 复烤配方关联特征挖掘设计
3.1.1 编码
关联规则就是从数据集中发现事务之间的关系,用形如{A}→{B}这样的规则表示[18]。首先发现频繁项集,频繁项集指满足最小支持度的集合,最终关联规则由频繁项集生成,用于描述两种事物间存在很强的关系,生成的关联规则必须同时满足最小支持度和置信度。
定义1支持度表示事务A 和B 在整个数据库中的占比,σ(D)代表整个事务数据库,数学表达如式(4)所示。

定义2置信度表示所有包含A的事务中又包含事务B的占比,数学表达如式(5)所示。

由上述可知,关联规则挖掘属于离散域问题,因此本文采用二进制编码,将原始数据转换为二进制数据,每条记录的属性为0 或1[19],在实际计算时便可很容易计算出相应的支持度和置信度,编码表示如图4 所示。
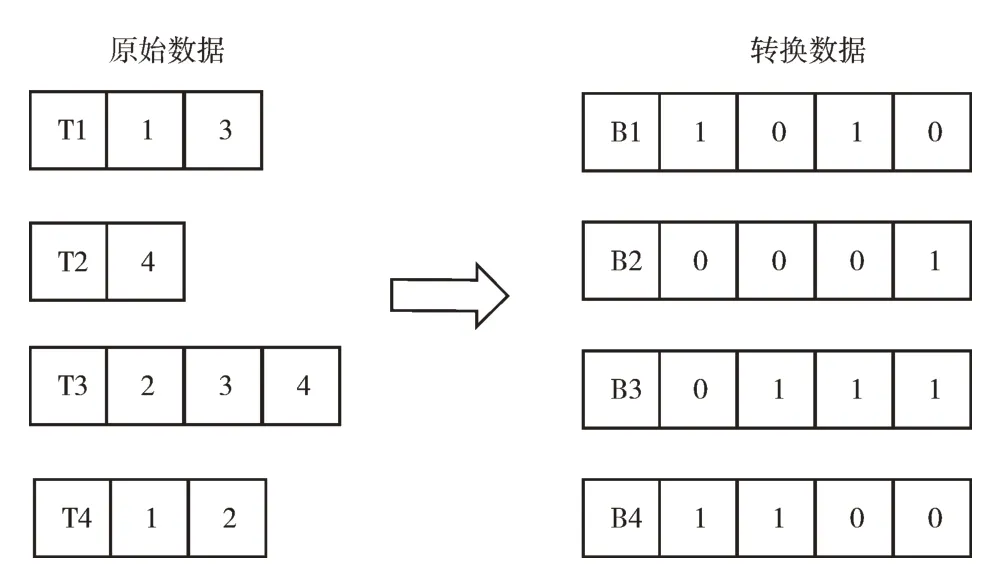
Fig.4 Coding图4 编码
3.1.2 解码
传统关联规则挖掘Apriori 算法通过逐层搜索进行迭代的方法发现频繁项集,进而直接得到关联规则。二进制粒子群算法用于关联规则挖掘则不同,在满足既定最大迭代次数M的前提下,最后得到的M 个全局最佳位置需以一定方式解码得到关联规则。如Gbest=(000110111000),采用Holland的密歇根方法[20],其按顺序两两组合得到S1=(0,0),S2=(0,1),S3=(1,0),S4=(1,1),S5=(1,0),S6=(0,0),Gbest=(S1,S2,S3,S4,S5,S6),S1…S6分别由两部分组成,第一部分若为1,则表示该事务出现在规则中,反之,规则中不存在该事务;第二部分表示该事务是规则的前项或后项,1为前项,0 为后项。综上,Gbest 所代表的规则表示为{ 3,5} →{ 4}。
3.1.3 适应度函数
在Apriori 算法中,适应度函数多以支持度或置信度为主。单独使用支持度为适应度函数,数据集中很少出现的项会被删减,尽管它们仍然会产生潜在有价值的规则;若单独使用置信度,根据置信度的定义,具有更高支持度的结果将自动产生更高的置信值,即使项目之间不存在关联。因此,本文采用文献[21]所提的使用支持度和置信度的乘积作为关联规则挖掘研究的适应度函数,如式(6)所示。

3.2 复烤配方关联规则挖掘实现
用拉丁超立方抽样初始化每个粒子,重复以下步骤,直到达到预先指定的迭代次数M。
Step1:使用式(6)计算所有粒子的适应度函数;
Step2:更新局部最佳值和全局最佳值;
Step3:使用式(2)更新粒子位置;
Step4:判断粒子的位置在limit 阈值内是否发生变化;
Step5:粒子的位置若没有发生变化,重新生成新的粒子保持种群不变,返回Step1;
Step6:若粒子位置发生变化,满足结束条件,挖掘停止。
这个过程将生成一个单一的规则,算法需运行M 次,以便从数据中获取前M 个规则,基于LDABPSO 算法的烟叶复烤配方关联规则挖掘过程如图5 所示。

Fig.5 LDABPSO algorithm-based association rule mining flow for redrying formula图5 基于LDABPSO 算法的复烤配方关联规则挖掘流程
3.3 数据预处理
现有历史复烤配方共计82 个,分为不同的配方模块,但是由于有些配方模块数较少,不适合关联规则挖掘,因此本文结合企业实际生产,对主要生产加工配方模块进行关联规则挖掘。通过对配方数据的筛选及整理,得到实验所用复烤配方数据,共计12 行、72 列。若对应行的配方中包含对应列的烟叶,则为1,反之为0,A 模块配方数据如表3 所示。

Table 3 Module A formula data表3 A模块配方数据
3.4 关联规则挖掘结果比较分析
从规则提取时间、提取数量、规则质量3 个方面分别对Apriori 算法、基于LDABPSO 算法的关联规则挖掘结果进行实验比较。
3.4.1 规则提取时间比较
使用Apriori 算法进行复烤配方挖掘时,将支持度设置为0.18,置信度设置为0.5。LDABPSO 算法中,算法总体规模保持在20 次,迭代次数保持在50 次,取20 次实验结果的平均值,两种算法的运行时间对比如表4 所示。

Table 4 Time comparison表4 时间比较 (s)
根据表4 可知,LDABPSO 算法相比于Apriori 算法运行时间减少8.4%。这主要是因为Apriori 算法在运行时,采用逐层搜索迭代策略,在实际计算时,需要多次扫描输入数据,而LDABPSO 算法不需要多次扫描数据,只需要将处理过后的数据按照既定的条件迭代,最后得到的全局最好值即为提取到的较佳规则,且随着数据集的增大,本文所提出的方法在运行时间方面将会有更突出的优势。
3.4.2 规则提取质量
因得到的规则数量较多,表5 所展示的只是部分规则。表5 中[0.21,0.52]代表支持度为0.21,置信度为0.52。以改进算法提取的规则5 为例,规则表示为{53,62} →{55,57},可以看出模块配方同时包含烟叶编号为53、62、55、57的概率为10%,置信度为1,表明在实际模块配方中,在含有烟叶编号53、62的前提下,有100%的概率包含编号为55 和57的烟叶,规则提取质量比较如表5 所示。
通过表5 可知,Apriori 算法提取出的规则{ 6} →{ 23}和{ 23} →{ 6} 为冗余规则,而LDABPSO 算法提取到的规则只有{ 6} →{ 23}。同样地,规则{17,18,23} →{6,13,16} 和规则{17,6} →{13,17,18,23} 也为冗余规则,可见在Apriori算法中,会出现大量的冗余规则,这造成两种不同算法提取到的规则数量出现很大差距。

Table 5 Comparison of rule extraction quality(partial)表5 规则提取质量比较(部分)
综上,Apriori 算法提取到的规则多为无效规则。此外,LDABPSO 算法还能挖掘出被忽略的低支持度而高置信度的关联规则,而往往这类规则具有重要价值,例如规则{6,20,35,37} →{17,32},这是Apriori 算法无法实现的。
3.4.3 规则提取数量
对于Apriori 算法,需要提前设定好最小支持度和最小置信度,最后得到的烟叶搭配规则数受上述两个参数的影响较大。将其最小支持度和最小置信度分别设置为0.18和0.5,提取规则共计4 073 条,将其分别设置为其他数值,如0.2 和0.5,得到的结果仅1 532 条,又如设定为0.1 和0.3,得到结果共8 956 条,由此可见,Apriori 算法受主观性影响很大。若最小支持度和最小置信度设定过小,结果集会出现海量规则;如果设定过大,又会丢失很多重要规则,LDABPSO 算法解决了从海量杂乱规则中人工盲目筛选规则的问题,两种算法得到的规则数量比较如表6 所示。

Table 6 Comparison of number of rules表6 规则数量比较
综上可知,运用LDABPSO 算法挖掘A 配方模块中烟叶之间的协同、搭配信息规则,经过比对真实配方数据,挖掘到的结果和真实配方数据保持一致,因而采用LDABPSO 算法挖掘到的烟叶搭配规则有效。
4 结语
本文将一种改进二进制粒子群算法(LDABPSO)用于复烤配方的关联规则挖掘,对BPSO 算法提出改进策略,将其应用于关联规则复烤配方挖掘,并通过实验对比验证所提算法的有效性。LDABPSO 算法避免了Apriori 算法预设最小支持度和最小置信度的缺陷及大量冗余规则的出现,且规则质量进一步提升。在实际生产中,使用LDABPSO 算法挖掘到的复烤配方中烟叶协同搭配信息可在一定程度上实现复烤配方维护。此外,各配方模块所使用的主要烟叶每年变动不大,对于复烤企业而言,可以根据挖掘到的烟叶协同规则为卷烟企业提前准备烟叶原料,缩短生产提前期。随着配方数的不断增多,未来可考虑从算法运行时间、规则质量提升方面作进一步优化。
猜你喜欢
核科学与工程(2021年4期)2022-01-12
中等数学(2021年8期)2021-11-22
数学大王·低年级(2019年10期)2019-11-25
活力(2019年15期)2019-09-25
中等数学(2019年4期)2019-08-30
计算机应用(2018年5期)2018-07-25
现代园艺(2017年23期)2018-01-18
轴承(2015年2期)2015-07-25
天津造纸(2015年2期)2015-01-04
作物研究(2014年6期)2014-03-01
