
基于知识图谱的心血管疾病智能问答系统
2022-03-25 04:45周作建
软件导刊 2022年3期
吴 丹,周作建
(南京中医药大学人工智能与信息技术学院,江苏南京 210023)
0 引言
随着社会经济不断发展,人们生活方式发生了巨大变化。由于运动量不足、饮食不健康、吸烟等因素导致我国患有冠心病、高血压、高血脂等心血管疾病的人群数量在不断增加,且心血管疾病的发病率和死亡率也在不断升高[1]。据调查发现,2018 年城乡居民心血管疾病的患病人数仍在不断增长[2-3]。由于我国医疗资分布不均,一直存在“看病难,挂号难”的问题[4]。随着互联网医疗发展,通过网络问诊的人数越来越多,市面上也出现了如好大夫[5]、寻医问药网等在线就医平台,但医生线上诊疗效率不高,导致患者等待时间较长。为了提高医疗资源利用率,本文提出建立基于知识图谱的心血管疾病自动问答系统,该系统可实时、智能解答心血管疾病患者的相关问题,在一定程度上节约了医疗资源。
1 研究现状
1.1 知识图谱
知识图谱[6]最先由Google 于2012 年正式提出,在语义搜索[7]、智能问答[8]、个性化推荐[9]等领域都具有重要的研究价值。它是一种由多个节点和边构成的数据结构,主要用于优化搜索结果。本质上是一种用于描述物理世界中的概念及其之间关系的语义网络,通过将数据粒度从document 级降到data 级别,以聚合大量的知识信息,从而实现知识的快速响应和推理。目前,知识图谱已被广泛应用于工业领域。例如:Google 搜索、百度搜索、领英经济图谱、天眼查企业图谱[10]、金融风控图谱[11]等。
1.2 医疗知识图谱
随着互联网+智慧医疗的发展,知识图谱在医学上的应用也愈发广泛。由于医疗数据的多样性与多量性,使用知识图谱管理医疗数据成为了一种便捷、高效的管理模式。目前,医学知识图谱主要应用于智能导诊、临床辅助诊疗、辅助健康管理及医疗知识问答4 个方面。刘道文等[12]将知识图谱与智能导诊算法相结合,提升了科室推荐精度。刘勘等[13]将知识图谱与深度神经网络、知识表示学习等方法相结合,构建了并发症辅助诊断模型,以诊断并发症的相关问题。严越等[14]在构建的脑卒中防治知识图谱的基础上,提出脑卒中风险预测模型,有助于加强对高危慢性病人群的健康管理。李贺等[15]将AC 多模式匹配算法引入疾病知识图谱中,提升了疾病自动问答系统的准确率。然而,现有知识图谱的研究主要集中在全科诊疗,对特定种类疾病的研究较少。为此,本文构建了心血管病知识图谱,并基于该图谱开发了一套自动问答系统。
2 心血管疾病知识图谱构建
2.1 模式层构建
模式层作为构建知识图谱的骨架部分,对知识图谱的数据模式起着决定性作用[16]。本文通过爬取39 健康网的数据构建模式层,采用自顶向下的方法构建心血管疾病知识图谱。模式层设计如图1 所示,其中包含心血管疾病的症状、并发症、挂号科室、检查项目和治疗药物共5 类实体,各实体之间的关系如表1 所示,实体属性如表2 所示。
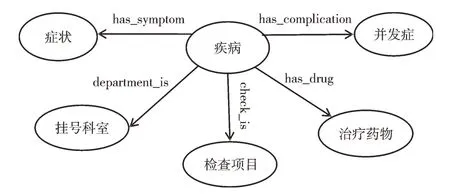
Fig.1 Schema layer design图1 模式层设计
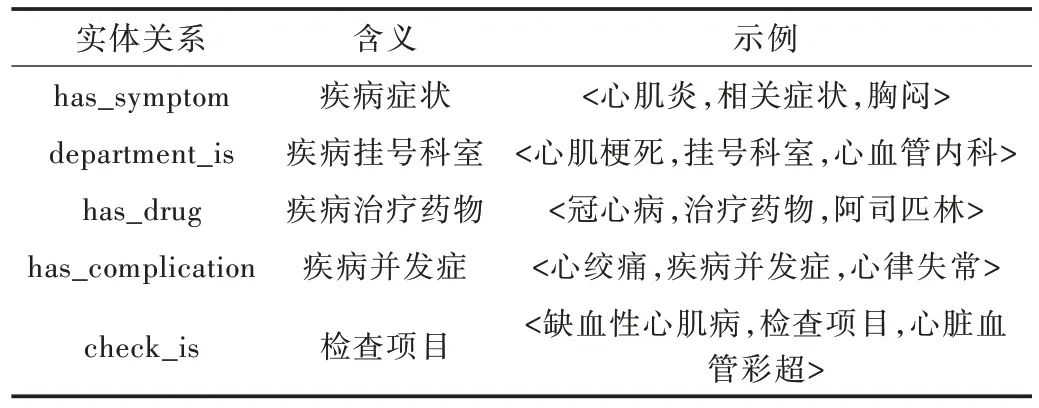
Table 1 Entity relationship表1 实体关系
2.2 数据来源
本文数据来源于39 健康网,其涵盖了大量医学疾病信息,支持疾病自测、在线问医、药物推荐及医生查询等功能。该平台收集了各类医学疾病的基本信息,包括疾病别名、发病部位、典型症状、相关并发症、挂号科室、治疗方法(药物、手术)等。由图2 可见,先通过爬虫技术爬取心血管疾病的相关数据,然后对爬取的数据进行清洗及预处理,最终获取392 个心血管疾病数据进行试验。

Table 2 Entity property表2 实体属性
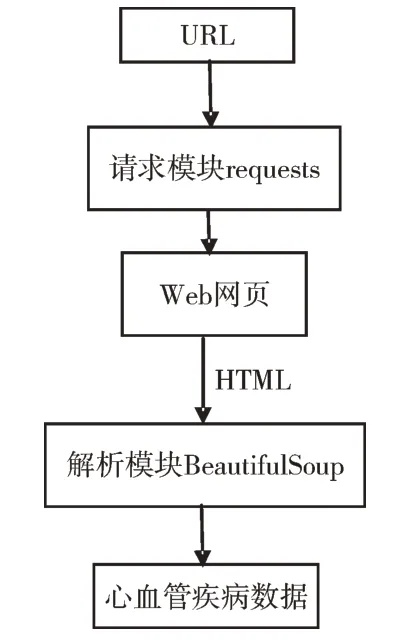
Fig.2 Crawler technology flow图2 爬虫技术流程
2.3 数据层构建
由于网页数据不规范,因此需要对爬取的数据进行知识融合。心血管病知识图谱的知识融合主要包括实体对齐与属性对齐。
2.3.1 实体对齐
为了消除多源异构数据导致的冲突、歧义等问题,需要对不同表达方式的同一实体进行统一规范。例如:“高血脂”和“高脂血症”是同一种疾病的不同表达方式,可统一表达为较为常见的“高血脂”。常见实体对齐方法主要通过相似度匹配方式实现,实体间相似度计算的函数定义为:

其中,simc(A,B)表示基于实体对间的属性相似函数,α为可调节参数,实体结构相似函数采用Jaccard 系数计算方法,具体计算方式如式(2)所示。
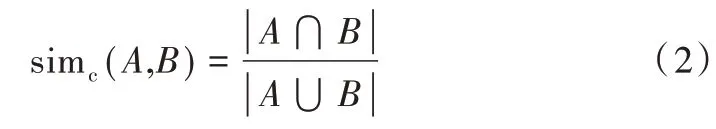
其中,|A⋂B|表示实体A与实体B的交集,|A⋃B|表示实体A与实体B的并集,属性相似函数采用余弦相似度计算方式,如式(3)所示。
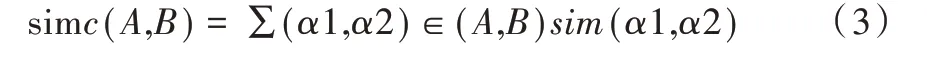
2.3.2 属性对齐
由于同一属性的属性值可能存在多种表达方式,例如一对多或多对一。可将属性值之间相隔一个空格键以解决一对多问题,而对于后者,则需要通过人工标注具有相同语义的属性值进行解决。具体标注样例如表3 所示。

Table 3 Annotation example表3 标注样例
2.4 知识存储及可视化展示
知识存储通常为RDF 和图数据库两种方式,图数据库属于NoSQL 数据库之一,目前最常用的图数据库为Neo4j。Neo4j 是一种基于Java的开源图数据库,可将数据存储于灵活的网络结构中,具备完整的ACID 特性,且具有高性能、高可靠性、高可扩展性等优势[17]。由图3 可见,Neo4j的基本组成单元为节点、边和属性。
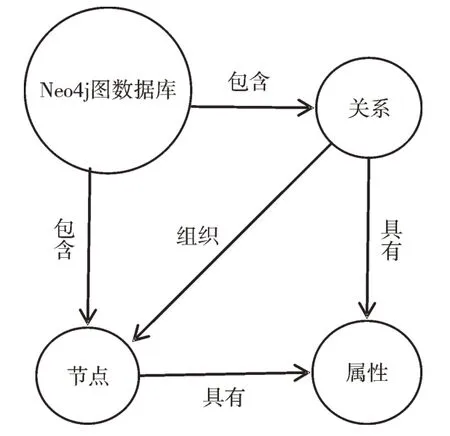
Fig.3 Neo4j graph database model图3 Neo4j 图数据库模型
心血管病知识图谱使用Neo4j 数据库中Cypher 语言的LOAD CSV 语句导入处理好的数据,实现知识图谱的存储及可视化。图4 展示了部分心血管病知识图谱。
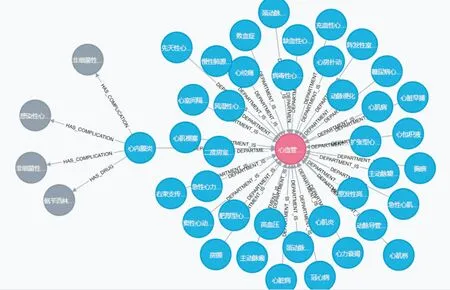
Fig.4 Part of the knowledge graph of cardiovascular diseases图4 部分心血管病知识图谱
3 基于心血管疾病知识图谱的问答系统
3.1 问答系统设计
由图5 可见,系统包括以下6 个流程:输入问题、分词处理、实体识别、问题模板匹配、基于Neo4j的图数据库查询及输出答案。
3.2 问答系统实现
3.2.1 问题输入
用户逐条输入心血管疾病的相关问题。例如:“治疗高血压吃什么药?”“治疗高血压要去哪个科室?”“高血压有哪些并发症?”等。
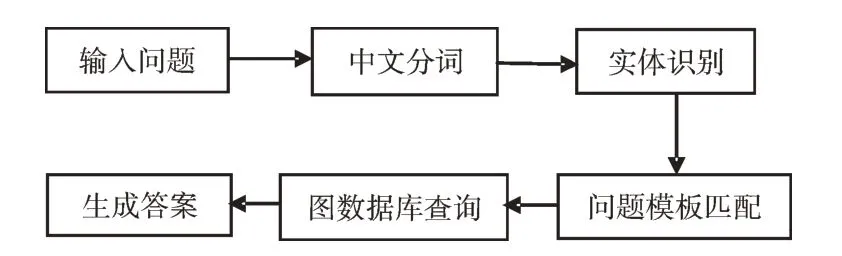
Fig.5 System design process图5 系统设计流程
3.2.2 问题预处理
由于中文的词和词组边界较模糊,如何让计算机精确识别一直是目前的研究难点。为此,本文使用Python 提供的第三方依赖包jieba 分词对完整的语句进行分词处理,将一句话分解为一个个符合逻辑的词语。
3.2.3 医学实体识别
常用的实体识别方法为卷积神经网络、支持向量机、条件随机场、递归神经网络等。由于医学领域的实体相对较多且复杂,大部分疾病目前仍未有统一的规范标准,极易发生误识别。传统方法多采用BiLSTM+CRF[18]模型进行医学实体识别,本文在此基础上进行改进提出了BERT+BiLSTM+CRF 模型。该模型包括:BERT 嵌入层、BiLSTM 特征提取层和CRF 序列标注层,具体做法是将问题中的字用BERT 模型转换成字向量,然后将字向量输入到BiLSTM 层进行训练,最后引入CRF 层修正结果,输出全局最优序列。将两种模型进行对比评估,以准确率、召回率和F1值作为评价指标,结果如表4 所示。

Table 4 Comparison of the results of two models表4 两种模型结果对比
由表4 可见,相比BiLSTM+CRF 模型,BERT+BiLSTM+CRF 模型在准确率和F1值上都提升了0.07,证明BERT+BiLSTM+CRF 模型可有效提升医学实体识别的性能。
3.2.4 问题模板匹配
常用的问题理解方法一般为模版匹配[19]、检索模型及基于深度学习方法。然而,基于检索模型需要从海量问答文本中检索类似问题,基于深度学习的方法需要人工标注大量语料库。鉴于此,本文选用模板匹配方法,将系统收集的问题与设计好的问题模板进行相似度匹配计算,得到的最高相似度即为问题模板。不同实体的问题模板如表5所示。

Table 5 Question templates of different entities表5 不同实体的问题模板
3.2.5 基于Neo4j 图数据库的查询
本文使用Cypher 语句对Neo4j 图数据库进行查询,查询语句为:Match(a)-[:关系]-(b)where b.name=”实体”return a.name.。例如:查询“治疗高血压吃什么药”,对应的Cypher 语句为:Match(a)-[:HAS_DRUG]-(b)where b.name=”高血压”return a.name.;查询“糖尿病有什么症状?”,对应的Cypher 语句为:Match(a)-[:HAS_SYMPTOM]-(b)where b.name=”糖尿病”return a.name。根据查询结果,系统会自动生成答案返回用户。例如:“治疗高血压可以用利尿药、β 受体阻滞剂、钙通道阻滞剂等”“糖尿病的症状有多尿、多食、疲乏无力等”。
3.3 系统性能分析
3.3.1 性能指标
本文选用精确率(P)、召回率(R)及F1值作为性能指标,具体公式如式(4)。
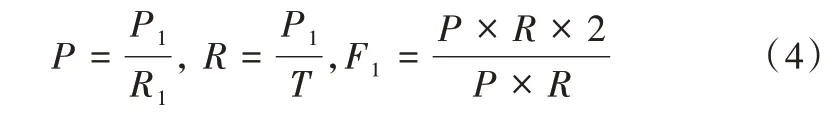
其中,R1表示问答系统返回答案的全部数量,P1表示问答系统中返回正确答案的数量,T表示实际问题正确答案的数量。
实验通过人工手动选取150 个与心血管疾病相关问题作为该问答系统的测试数据并将问题输入心血管疾病问答系统,以统计P1和R1的值。
3.3.2 实验分析
由表4 可见,问答系统的精确率为0.95,召回率为0.93,F1值为0.94。说明本文构建的心血管疾病知识图谱问答系统可为用户提供有效的问答服务。通过深入分析发现,无论是与表5的问题模板表达方式相同的问题,还是与问题模板的实体和语义相同但表达方式不同的问题都能给出正确答案,说明该系统在问句理解与语义搜索方面效果较好。分析回答错误的问题发现,系统可正常识别问题中的实体,但无法识别在表5 问题模板中未出现的语义信息。如“高血压会传染吗?”“糖尿病会遗传吗?”等,从而导致识别错误。
4 总结与展望
本文通过爬取39 健康网的数据信息,采用自顶向下的方法构建心血管疾病知识图谱,并开发了基于心血管疾病知识图谱的问答系统。该问答系统支持自动应答疾病—药物、疾病—症状等相关问题,实现了心血管病患者的初步自诊自查。通过实验证明,该系统的精确率和召回率分别为0.95 和0.93,F1值为0.94。但本文构建的心血管疾病知识图谱数据源较为单一,知识图谱信息不够完整;问答系统设计简单,仅支持基本的心血管疾病。下一步将扩充实验数据集,并寻找更好的方法提升系统精度。
猜你喜欢
心血管病防治知识(2022年23期)2022-11-10
现代临床医学(2022年3期)2022-06-06
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
医学研究杂志(2015年8期)2015-06-22
医学研究杂志(2015年11期)2015-06-10
