
基于CGAN-LSTM的无监督网络异常流量检测算法
2022-03-25 04:45赵经宇杨义先朱洪亮
软件导刊 2022年3期
赵经宇,杨义先,辛 阳,朱洪亮
(北京邮电大学网络空间安全学院,北京 100876)
0 引言
信息技术的高速发展不仅给网络用户带来极大便捷,同时还带来了许多安全威胁[1]。端口扫描、SQL 注入、分布式拒绝服务、APT 等网络恶意攻击使得网络产生异常,计算机系统崩溃,最终无法对外提供正常服务。流量作为网络信息交互和传输的重要载体,对其异常情况进行检测是网络安全领域的研究热点之一[2]。
网络异常流量检测算法总体可分为有监督异常检测和无监督异常检测两种。有监督异常检测通过对有标签的网络流量样本进行特征学习,进而对测试样本进行判别[3-4],但该法有两个明显弊端,首先其需要大量有标签样本,即需要大量人工投入和资金支持,其次该法只能学习已有的攻击样本特征,无法检测未知攻击样本。现有无监督异常检测算法包括以K-means 为代表的聚类算法、基于多种自编码器的异常检测算法和基于生成对抗网络(Generative Adversarial Networks,GAN)的异常检测算法等。然而,上述算法仍具有一些局限性,如没有关注网络流量这类时间序列数据在时间上的依赖关系、没有从时间周期的角度对网络异常流量进行检测[5-6]。
针对上述局限性,本文提出基于条件生成对抗网络—长短时记忆网络(Conditional Generative Adversarial Networks-Long Short Term Memory,CGAN-LSTM)的网络异常流量检测模型。该模型使用LSTM 结构的生成器和判别器学习正常样本的数据特征,使用时间周期信息指导生成器G 生成样本,最后同时使用生成器的重构误差和判别器的判别结果判别测试样本。本文的主要贡献如下:①提出使用基于注意力(Attention)机制的多层LSTM 网络捕获时间上的依赖关系,并将其嵌入到CGAN 框架中,以保证模型充分学习到样本在时间上的依赖关系;②提出使用时间周期信息作为条件指导生成器生成数据,解决了误判问题,同时也解决了传统GAN 模型直接对先验分布进行随机采样以及中间模拟的方式过于自由而导致模型不可控的问题;③提出同时使用生成器的重构误差和判别器的判别结果进行网络异常流量检测。
1 相关研究
目前,网络异常流量检测已经得到许多学者的关注。无监督异常流量检测算法由于训练过程不需要有标签的网络流量数据而更适用于实际应用场景,是一种理想的流量异常检测算法,以下分类介绍。
1.1 基于聚类的无监督异常检测算法
该类算法的原理为距离聚簇中心较远的点更可能为异常点,聚类簇稀疏的点更可能为异常点[7]。例如,左进等[8]提出改进K-means 算法进行流量异常检测,对初始聚类中心选择问题进行优化,提高了聚类质量和异常检测率。该模型的不足之处为需要根据对数据的先验经验提前选择合适的k 值,缺乏理论支持;翟建丽等[9]提出一种基于模糊聚类的网络流量检测模型,该模型采用模糊C 均值聚类算法对网络流量进行向量量化分析,提取其高阶谱特征量,最终实现对网络流量的检测分类。该模型的不足之处为检测的实时性较低。
1.2 基于自编码器的无监督异常检测算法
自编码器是神经网络的一种,由编码器和解码器构成,前者能将输入的数据压缩成低维表示,后者能对低维表示进行重构,通过向自编码器中添加一些约束条件可以得到不同种类的自编码器[10]。例如,刘松洁[11]提出基于变分自编码器的网络异常流量检测算法,该算法只使用正常的网络流量数据训练变分自编码器,测试时,如果流量正常,重构误差应该在设定阈值范围内,如果重构误差超过阈值范围,则视为异常流量。该模型的不足之处为仍有部分异常样本的重构误差潜伏在正常误差水平中,导致模型准确率较低;Zong 等[12]提出DAGMM 模型用于网络异常流量检测,该模型的训练数据均为正常数据,其使用深度自编码器提取数据的低维表示,将自编码器的重构误差和低维表示连接后输入高斯混合模型,通过计算样本能量与异常数据的比例判定数据类型。该模型的不足之处为异常比例的设定需要依赖人工经验。
1.3 基于GAN的无监督异常检测算法
近年来,GAN 被广泛用于流量异常检测领域,其采用对抗训练的方式训练生成器G 和判别器D,训练后的判别器能从真实样本中检测出异常样本。例如,Jiang 等[13]提出使用编码器—解码器—编码器三层网络结构组成的生成器从正常样本中学习有效特征,然后同时使用判别器的判别损失和生成器的随机损失进行异常流量检测;Zenati等[14]提出基于双向生成对抗网络的网络异常流量检测算法,并在KDDCup99 数据集上进行了验证,实验结果表明该算法的F1 得分为0.92,不足之处为没有考虑网络流量这类时序在时间上的依赖关系。
2 网络模型
2.1 CGAN
GAN 由生成器和判别器构成[15]。生成器不断学习真实样本的分布,目标为将随机噪声z 转化为可以以假乱真的数据,而判别器的目标则为将生成器产生的样本与真实样本区分开。GAN 优化的目标函数为:
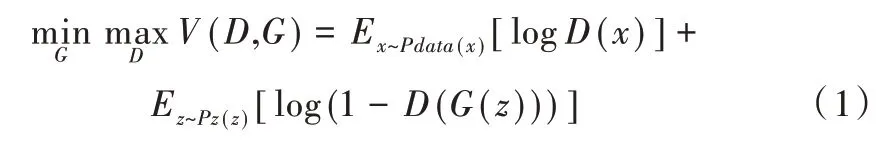
式中,x为真实样本,z为待输入生成器的随机噪声。从上述目标函数可知,在训练判别器参数时,当输入样本为真实样本x 时,期望的判别结果越接近1 越好;当输入样本为生成样本G(z)时,期望的判别结果越接近0 越好,因此需要最大化式(1)。在训练生成器参数时,生成样本期望的判别结果与上阶段期望的判别结果相反,即越接近1 越好,因此需要最小化式(1)。
然而,GAN 有一个显著的缺点,即模型不可控。该模型以一个随机噪声为输入,很难对输出结构进行控制。CGAN[16]很大程度上解决了这个问题,其在生成器和判别器中引入条件变量y,可指导性地生成数据,流程如图1 所示。CGAN 优化的目标函数为:
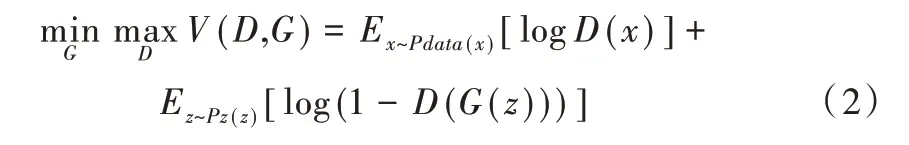

Fig.1 Conditional generative adversarial network flow图1 CGAN 流程
2.2 Attention-LSTM
LSTM 是一种特殊的循环神经网络[17],其在传统循环神经网络的基础上引入记忆单元和门机制,解决了传统循环神经网络训练长序列容易出现的梯度消失或爆炸问题。同时Attention 机制通过对神经元分配不同的概率,能将训练的注意力从全局转移到目标关注的局部重点上。LSTM加入Attention 机制的步骤如下:首先将LSTM 输出的隐藏状态hi通过点积计算出各部分隐藏状态得分,然后通过归一化操作得到权重矩阵,最后使用点乘得到模型输出,具体方法如式(3)-式(5)所示:


3 CGAN-LSTM 模型
3.1 CGAN-LSTM 模型架构
如图2 所示,CGAN-LSTM 模型分为训练和测试两个阶段,两阶段均使用额外的时间周期信息指导生成器G 生成数据,同时生成器G 采用基于Attention 机制的多层LSTM 捕获数据在时间上的依赖关系。

Fig.2 Network abnormal traffic detection model based on CGAN-LSTM图2 基于CGAN-LSTM的网络异常流量检测模型
在训练阶段,该模型选择的训练数据均为正常样本。首先从随机空间获得Z,将Z 与时间信息t 连接后输入到生成器G 中,通过生成器获得生成样本,将真实样本和生成样本同时输入到判别器D 中,判别器D 试图区分二者,根据D的输出反向更新D、G的参数。通过生成器G 与判别器D 不断对抗和训练,最终生成器G 完全学习到了正常样本的数据分布,判别器D 也完全无法区分真实样本与生成样本。
在测试阶段,生成器和判别器的参数均来自训练阶段的结果。将测试样本映射到随机空间中,首先通过梯度下降的方法在随机空间中寻找到输入生成器G 后生成的数据中最接近测试样本的Z,将Z 与时间信息t 连接后输入到生成器中生成重构样本,计算重构样本与测试样本的重构误差;然后将测试样本与时间信息t 连接后输入到判别器D 中计算判别结果;最后根据重构误差和判别结果综合判定测试样本是否异常。
3.2 使用时间周期信息指导生成器G 生成数据
大部分时序数据异常检测模型是以时间连续性为基础进行训练的,但时间连续性并不是时序数据异常检测的唯一考虑因素,如果只考虑连续性,那么很容易出现图3 中检测错误的情况。图3(彩图扫OSID 码可见)中蓝色部分的波峰和波谷分别代表网络访问量的高峰期和低谷期,如果仅从时间连续性的角度考虑很可能将其判别为异常数据,但如果加入时间周期信息训练模型,使模型学习到这种模式及其所处的时间,则能很好地纠正判别错误;图3 中的红色部分如果仅从时间连续性的角度考虑,很可能将其判别为正常数据,但如果加入时间周期信息训练模型,模型将会学习到该时间区间中正确的流量数据分布,则很容易纠正判别错误。
因此,针对上述判别错误的情况,本文提出使用时间周期信息t 作为条件指导生成器生成数据,可选择的时间周期包括周、天和小时,如此不仅避免了上述检测错误,还能解决传统GAN 模型不可控的问题。

Fig.3 Schematic diagram of network traffic data图3 网络流量数据示意图
3.3 训练阶段
3.3.1 生成器
在CGAN-LSTM 模型中,生成器的作用是模仿真实样本生成能欺骗判别器的生成样本。本实验在训练阶段仅使用正常样本作为训练数据,因此训练结束后,生成器学习到了正常样本的数据分布。考虑到网络流量为时间序列数据,因此要关注样本数据在时间上的依赖关系,采用循环神经网络作为生成器的基本结构。但传统的循环神经网络无法解决长距离依赖的问题,因此本文模型的生成器最终采用LSTM 结构提取样本数据的主要特征。
生成器的结构如图4 所示,包含两层LSTM 和一层Attention,其中多层LSTM 可解决单层LSTM 网络提取特征适应性弱的问题,Attention 机制能将训练的注意力从全局转移到目标关注的局部重点上。具体过程为:随机空间Z 先后通过含有64 个单元的第一层LSTM 和含有128 个单元的第二层LSTM,最后通过一层Attention 获取重点关注的部分。生成器的训练过程采用判别器的返回结果,损失函数为交叉熵函数,使用梯度下降的方法寻求模型参数最优解。
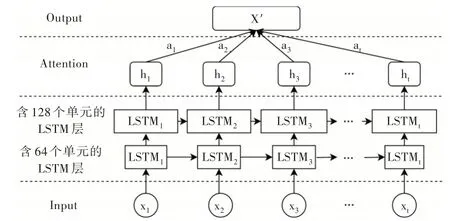
Fig.4 Generator based on Attention-LSTM图4 基于Attention-LSTM的生成器结构
3.3.2 判别器
在CGAN-LSTM 模型中,判别器的作用是将生成器产生的生成样本与真实样本区分开,其输出结果为0~1 之间的数值,当判别器认为是真实样本时则判定的值接近1,反之则判定的值接近0,然后根据输出结果更新判别器和生成器参数。该模型判别器的结构为一层含有100 个单元的LSTM 网络,并使用Sigmoid 函数将数值压缩到0~1 之间。判别器训练阶段的损失函数亦为交叉熵函数,同样使用梯度下降的方法寻求模型参数最优解。
3.4 测试阶段
基于GAN的异常检测大多仅使用训练好的判别器判定测试样本,但本文同时使用生成器的重构误差和判别器的判别结果综合判定测试样本。
3.4.1 生成器的重构误差
在训练阶段,生成器G 学习如何将随机空间Z 映射到真实样本X 上。为了进行异常流量检测,需要将测试样本Xtest映射到随机空间Z 上,然后观察通过随机空间Z 生成的生成样本G(Z|t)到测试样本Xtest的距离有多近,两者的距离越近代表Xtest越遵循用于训练生成器G的数据分布,即越接近正常样本。
为了在随机空间中找到一个最优的Z,使其通过生成器G 后能生成最接近测试样本Xtest的数据,首先随机生成一个Z,定义一个损失函数见式(6),利用梯度下降的方法更新Z,最终得到一个最优的Zk;然后使用Zk通过生成器G生成一个样本,计算生成样本与测试样本的重构损失,见式(7)。
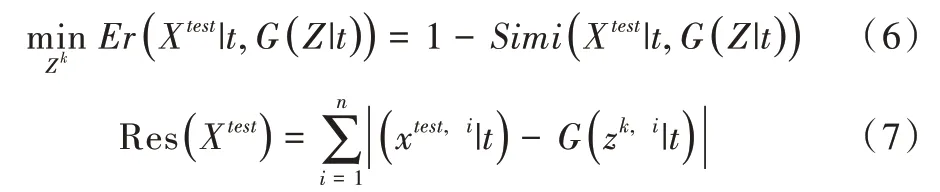
3.4.2 判别器判别结果
训练好的判别器能以较高的灵敏度将正常与异常数据区分开来,这是由于训练过程中判别器已经充分学习了正常样本的数据分布。如式(8)所示,当结果接近1 认为测试样本为正常样本,当结果接近0 时认为测试样本为异常样本。
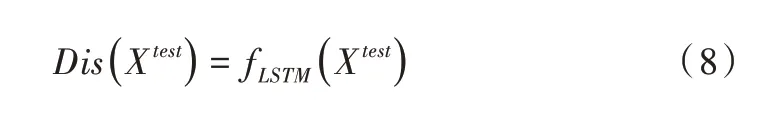
3.4.3 判定公式
综合生成器的重构误差和判别器的判别结果,其中判别器判定的准则是正常样本接近1,异常样本接近0,这与生成器重构误差越大越异常的原则相反,因此选用1-D(Xtest)的结果代入最终判别式(9),判别值Ltest越大表示测试样本Xtest越异常,反之则越正常。最终根据实验结果选取一个阈值,当判别值Ltest大于阈值时则认为是异常样本。

3.5 算法实现
训练阶段的算法实现步骤如下:

测试阶段的算法实现步骤如下:

4 实验方法与结果分析
4.1 实验数据
实验使用的数据集为:①ISCX2012 网络流量数据集。该数据集由加拿大新不伦瑞克大学于2012 年发布[18],共包含7 天24h的流量数据,数据特征包含应用名称、开始时间、结束时间、TCP 标志位、源IP 地址、目的IP 地址等。ISCX2012 网络流量数据集包含正常流量和4 种异常流量,分别为DDoS、HttpDos、Infiltrating、SSH 攻击。该数据集没有划分训练集和测试集,本文按照7∶3的比例进行随机划分。此外,该模型的训练阶段只需要正常流量,因此剔除掉训练集中的异常流量,最终统计结果如表1 所示;②CICIDS2017 网络流量数据集。该数据集由加拿大网络安全研究所于2017 年底发布,包含正常流量和12 种攻击流量,以pcap 文件的形式给出。CICIDS2017 数据集共包含5 天的流量数据,攻击行为分别发生于第2~5 天的上午和下午。该数据集没有划分训练集和测试集,本文采用7∶3的比例进行随机划分。此外,该模型的训练阶段只需要正常流量,因此剔除掉训练集中的异常流量,最终统计信息如表1所示。
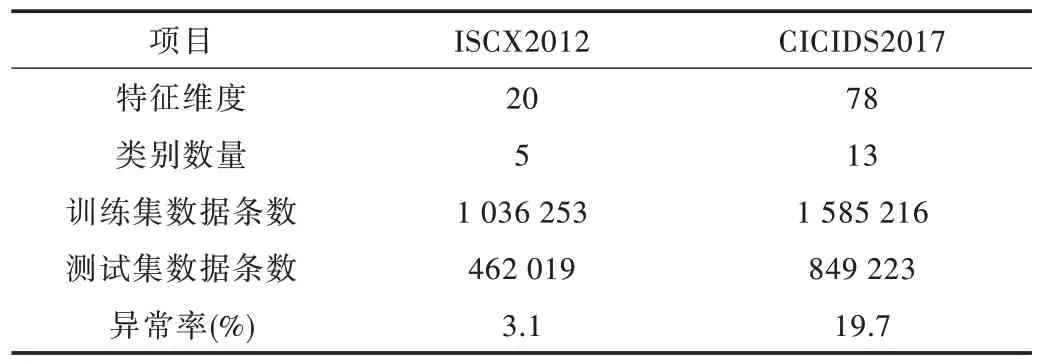
Table 1 Experimental data set information表1 实验数据集信息
4.2 评价指标
采用标准评价指标[19]精确度(Precision)、召回率(Recall)、F1值评估模型的异常流量检测性能。评估指标的计算公式表示为:

精确度是预测为异常且实际为异常的样本占所有预测为异常样本的概率,代表模型异常样本的查准率;召回率是预测为异常且实际为异常的样本占所有异常样本的概率,代表模型异常样本的查全率。单独使用这两个指标很难全面反映模型的实际检测能力,而F1值能同时兼顾查准率和查全率,因此本实验选择这3 个指标共同评估CGAN-LSTM 模型的异常流量检测性能。
4.3 实验设置
在上述两个数据集上分别对本文算法和对比算法进行实验。为保证实验结果的有效性,所有实验均在同一软硬件环境下进行。
在CGAN-LSTM 模型中,生成器由两个LSTM 层和一个Attention 模块组成,损失函数为交叉熵函数,使用梯度下降优化器寻求模型的最优解;判别器由一个LSTM 层构成,损失函数亦为交叉熵函数,使用Adam 优化器寻求模型最优解。训练阶段,生成器和判别器交叉训练;测试阶段,同时使用判别器的判别结果和生成器的重构误差进行判断,通过参数λ调节两部分计算权重并使用阈值判断是否异常。模型具体参数如表2 所示。

Table 2 Model parameters表2 模型参数
4.4 实验结果与分析
4.4.1 参数t的确定
使用时间周期信息t 指导生成器生成数据,可选择的时间周期有周、天和小时,那么时间周期信息t 分别为一周中的第几天(d)、一天中的第几小时(h)和一小时中的第几分钟(m)。分别使用以上3 种时间周期信息对时间数据t进行最大、最小归一化处理并分别进行实验。表3 结果表明,当t 使用一天中的第几小时(h)时检测结果为佳,因此本文模型的时间信息t 最终选择小时信息h。
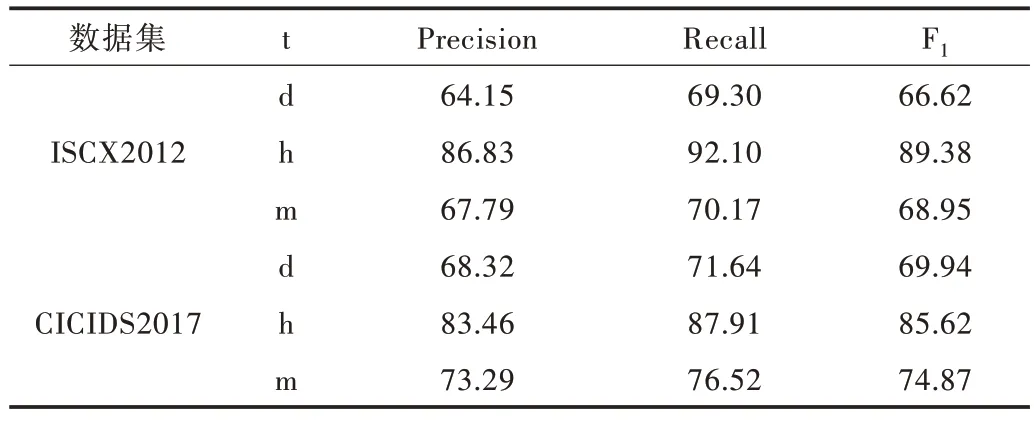
Table 3 Detection effect of different parameters t表3 不同参数t的检测效果 (%)
4.4.2 模型稳定性验证
模型在训练阶段进行了100 次epoch,每次epoch 后都对生成器和判别器的参数进行保存。图5 为CGAN-LSTM模型100 次迭代过程中的检测F1值。可以看到在迭代30次后模型进入稳定状态,F1值稳定在88%,并在迭代第37次时达到最大值89.38%,表明CGAN-LSTM 模型具有较高的稳定性。
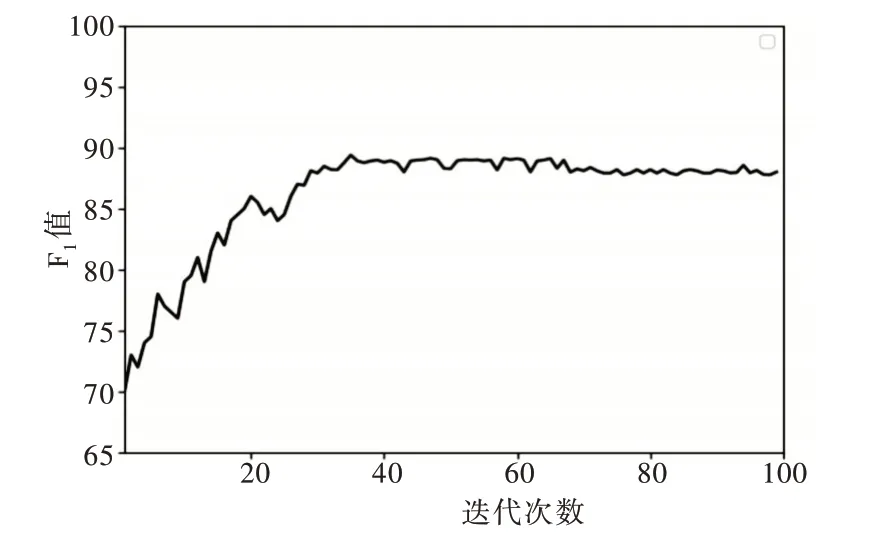
Fig.5 F1 value of 100 iterations of CGAN-LSTM model图5 CGAN-LSTM 模型100 次迭代过程的检测F1值
4.4.3 实验结果比较
为验证CGAN-LSTM 模型的流量异常检测性能,选择基于重构的AE、基于重构的VAE[9]、MAD-GAN[20]、仅通过判别器判别的CGAN-LSTM 4 个无监督异常流量检测模型与其进行比较,实验结果如表4 所示。其中,算法1 仅使用正常的网络流量训练自编码器,测试时如果流量的重构误差在阈值范围内,则将其判定为正常流量,否则判定为异常流量,该算法的不足之处是仍有一些异常样本的重构误差潜伏在正常误差水平中,导致模型检测结果较差;算法2利用VAE 引入了概率密度函数,使其不仅可以考虑重建数据与原始数据之间的差异,还可以根据分布函数的方差参数考虑重建数据的可变性,与算法1 相比具有一定优越性;算法3 考虑了时间序列数据之间的相关性,提出使用LSTM结构的GAN 进行多元数据异常检测,检测结果优于算法2;算法4 截取自本文算法,其不考虑生成器的重构误差,仅通过判别器的判别结果得出最终结论,不敌本文算法的检测结果。
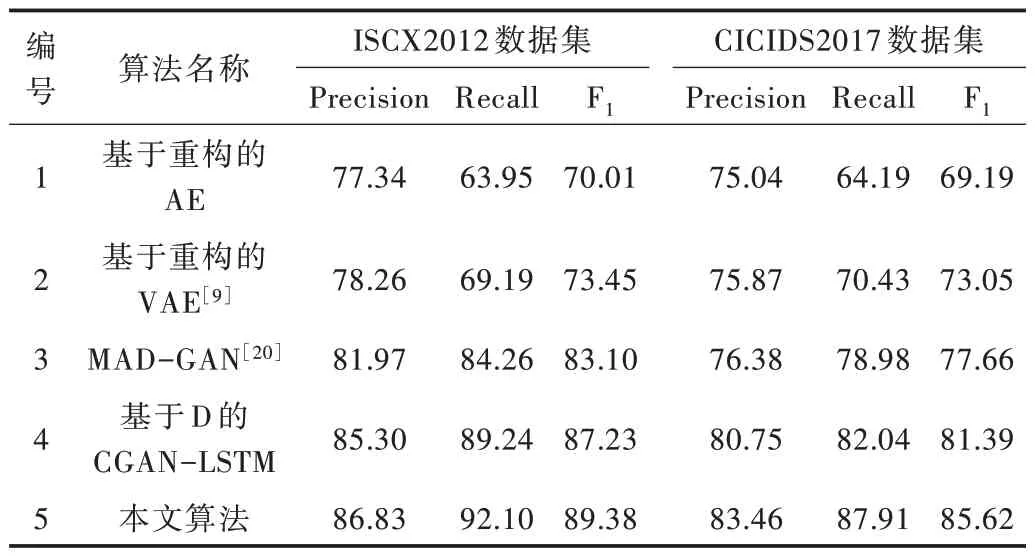
Table 4 Anomaly detection results of different algorithms表4 不同算法异常检测结果 (%)
本文提出的CGAN-LSTM 算法使用基于LSTM 结构的CGAN 模型判别网络流量异常,最后基于生成器的重构误差和判别器的判别结果判别测试样本。由于一些异常样本的重构误差潜伏在正常误差水平中,模型会存在漏检的情况;同时由于正常样本数量较大、占比过高,正常样本的情况较复杂,模型会存在误检的情况。最终,由于数据集正常样本占比过高,模型整体误检数量高于漏检数量,该模型在精确度达到86.83%的条件下召回率达到92.10%。
5 结语
无监督网络异常流量检测一直是网络空间安全领域的研究热点,无监督算法不需要有标签的数据,因此具有更好的应用前景。本文从网络流量的时序关系、时间周期信息的角度出发,提出一种基于CGAN-LSTM的无监督网络异常流量检测算法,使用Attention-LSTM 结构的生成器和判别器学习正常样本的数据分布,同时根据生成器的重构误差和判别器的判别结果判别测试样本,最后设置比较实验验证了本文模型的异常流量检测性能。实验结果显示,CGAN-LSTM 模型在精确度、召回率、F1值3 个指标上均实现了检测性能的提升。本文研究也存在一定的缺陷和不足,例如CGAN-LSTM 模型的时间周期信息是通过设置对比实验获得的,后续应考虑动态识别数据的周期性,从而在训练时能动态选择对应的t值以达到更好的判别效果。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
微型电脑应用(2021年3期)2021-03-31
知识经济·中国直销(2018年12期)2018-12-29
北京航空航天大学学报(2017年7期)2017-11-24
山东大学法律评论(2016年0期)2016-08-16
自动化博览(2014年12期)2014-02-28
河南科技(2014年23期)2014-02-27
