
PET-MRI医学图像融合与混合神经胶质瘤分类模型
2022-03-25 04:45庞宏林高靖哲李雄飞
软件导刊 2022年3期
林 海,乔 雅,庞宏林,高靖哲,李雄飞
(1.吉林大学 软件学院;2.吉林大学计算机科学与技术学院,吉林 长春 130012)
0 引言
近年来,随着深度神经网络的出现及快速发展,特征提取能力越来越强,基于深度学习的放射学应运而生。卷积神经网络(Convolutional Neural Network,CNN)由于其在大规模图像处理上的稳定性能,在组织病理学图像分析领域引起了广泛关注[1]。Song 等[2]使用ImageNet 上预训练的VGG-VD 模型提取图像本地特征,并使用FV(Fisher Vector)编码表示图像特征;Murthy 等[3]将预先提取的VGG 功能注入(连接)到半监督CNN的中间层,使CNN 聚焦于图像中心;Li 等[4]使用改进的CNN 分割肿瘤,代替常规放射学方法对分割的图像特征进行计算,获得编码为FV 向量的高质量MRI 特征;Lao 等[5]先将医学图像进行分割,再通过转移学习方法,使用预训练的CNN 提取图像的几何、强度、纹理及其他深层特征。然而,随着深度的增加,存在CNN 输入及梯度消失问题,ResNet 通过身份连接将信号跃层输出,有效解决了该问题。但是ResNet 每层都有权重,导致参数量大,且研究表明许多层的贡献非常小[6-7]。
为增强特征提取能力,降低脑肿瘤错误分类的概率,本文设计的模型基于Huang 等[8]提出的DenseNet 将所有层直接相连,每一层都从前几层获得额外的输入,可直接访问来自损耗函数与原始输入信号的梯度,减缓了梯度消失并加强了特征传播。同时,DenseNet 层特征图数量固定,狭窄的DenseNet 层只向网络的“集体知识”中添加一小部分特征图,并保持剩余特征图不变,鼓励了特征重用,减少了网络参数。
医学上存在许多脑部成像诊断方法,最常见的是放射学方法,通过对高通量图像特征进行定量分析,从医学图像中获得预测信息。常见的放射学医学图像有计算机断层扫描(CT)、磁共振成像(MRI)、正电子发射计算机断层扫描(FDG-PET)等,针对这些医学图像的放射学研究与分析已十分普遍。如Vallières 等[9]采用放疗模型评估软组织肉瘤(STS),建立联合PET 与MRI 纹理的模型,通过复合纹理很好地识别侵袭性肿瘤,并提供了良好的转移评估指标;Aerts 等[10]使用一种基于计算机断层扫描(CT)数据的放射学方法解码肺癌与头颈癌的肿瘤表型。
PET 与MRI 具有不同的优缺点。MRI 图像是一种能够呈现人体解剖信息的结构型图像,空间分辨率高,包含丰富的软组织结构信息,但缺乏反映人体新陈代谢功能的颜色信息;PET 虽然可提供反映人体不同组织新陈代谢情况的颜色信息,但在分辨率和结构信息上有明显缺点。
通过影像融合技术可将PET 与MRI 图像各自的优势进行有效结合。Chen 等[11]使用IHS 对PET 图像进行分解,由Gabor 滤波器对数变换组成的LogGabor 变换分解MRI 与PET 图像的强度分量,获得高频子带和低频子带,高频子带的融合伴随着最大选择,低频子带的融合伴随着一种基于能见度测量与加权平均准则两级融合的新方法;Haddadpour 等[12]提出一种将该IHS 与二维希尔伯特变换相结合的融合方法,在合并高频与低频子带时引入双向经验模态分解(BEMD),并通过经验模态分解进行扩展;Yan 等[13]使用基于稀疏表示(SR)的融合方法,求出PET 与MRI 图像各自的稀疏表示系数,然后将二者的稀疏系数采用某种融合规则进行融合,再利用融合稀疏系数及用于重构的过完备字典重构出最终的融合图像;Li 等[14]使用基于多分辨率分析(Multi-Resolution Analysis,MRA)的方法将PET 与MRI 图像进行多尺度分解(分解成系数和变换基),根据某种融合规则对分解后的系数进行融合,最后对融合后的系数与变换基进行反变换;Arash 等[15]使用基于光谱与空间的自适应滤波PET-MRI 图像融合方法,设计自适应滤波器组件以优化融合图像的相对平均光谱误差;Easley 等[16]提出非下采样剪切波变换(Non-Subsampled Shearlet Transform,NSST),利用非下采样金字塔滤波器(NSPF)对图像进行多尺度分解,然后通过剪切波滤波器(SF)对图像进行多方向分解,得到低频与高频子带,融合后的图像效果好、颜色失真小,且结构信息丰富。因此,本文采用基于NSST的自适应融合方法。
考虑到融合算法需要具有对应的PET 与MRI 图像,本文采用已在基于脑放射学的分类研究中广泛使用的哈佛大学全脑图谱数据集和TCIA。将数据集分为3 部分,分别用于训练、验证与测试模型。实验结果表明,自适应NSST融合方法有效减少了颜色失真,相比于单一PET 图像,融合后的图像在保留PET 图像颜色信息的同时,具有MRI 图像明显的空间结构信息。融合后的图像将更有助于临床对疾病的诊断与治疗,且分类准确率达到97.6%和98.2%,取得了较好的分类效果。
1 相关工作
1.1 DenseNet
密集卷积网络由多个密集块组成,每个密集块中含有多个卷积层,每个卷积层的输入由前面所有卷积层的输出与原始输入拼接而成,即:

每个密集块结构如图1 所示。每层由BN -ReLU -Conv(1× 1)和BN -ReLU -Conv(3 × 3)组成,其中每个卷积层之前是批归一化[17]与修正线性单元[18]的组合。1×1卷积层作为瓶颈层,用于减少输入特征图数量,提升运算效率;3×3 卷积层使用1 个像素的全零填充,保证在一个密集块中特征图大小固定,每个密集块输出k 个数量固定的特征图。DenseNet 密集连接的方式类似于ResNet 残差连接,但不同的是,当前层的输入不是前层输入的简单相加,而是特征图拼接,以促进层与层之间的信息流动及特征重用。
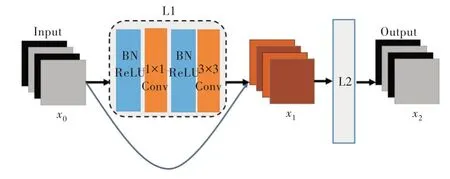
Fig.1 Dense block structure图1 密集块结构
1.2 多尺度特征图提取
本文在密集卷积网络中提取多尺度特征图的构想是受到尺度空间(scale space)思想的启发,其最早由Iijima[17]于1962 年提出。为获得多尺度的信息表示序列,设计了多个连续变化的尺度参数,之后将从序列中提取到的主轮廓作为一种特征向量,用于对不同分辨率图像的特征提取、边缘检测等。文献[18]提出一种多尺度卷积网络(MCNN),为捕获结节异质性,设计交替堆叠的层以提取判别特征,并利用多尺度结节补丁充分量化结节特征;文献[19]利用双树复数小波变换(DTCWT)从结构MRI 数据中提取不同空间尺度上的信息,根据多尺度信息区分样例是否患有多发性硬化症。多尺度特征提取如今已广泛应用于基于神经影像数据的神经系统疾病诊断研究中。
SMSDNet 中应用了多尺度特征提取,本文使用下采样方法,在4 个密集块之间加上平均池化层对特征图尺度进行变换。网络中前两个密集块输出的特征图具有较大尺寸,感受野较小,包含图像粗粒度信息;后两个密集块经过多层池化操作后,输出的特征图包含丰富的细节信息。本文对特征图进行跨层融合,对上层尺度大的特征图进行卷积操作,将其大小调整为与下层特征图尺度一致后,将两者相加。不同尺度特征图的结合有效提升了特征提取效果及分类精度。
1.3 Self-Attention
自注意力机制(Self-Attention)已广泛应用于循环神经网络(RNN)与长短期记忆(LSTM),用来完成具有顺序关系或前后具有因果关系的决策任务[20-22]。在此基础上,文献[23]、[24]在transformer 框架(编码器—解码器)中加入注意力机制,通过考虑文本当前词与上下文的关系来学习文本表达方式,相比于RNN,其对长期依赖关系有着更强的捕捉能力。深度玻尔兹曼机(DBM)在训练阶段使用重构过程,以包含自上而下的注意力。自上而下的注意力机制还被广泛应用于图像分类。与本文工作类似,Wang 等[25]设计一种软注意力结构,将自下而上与自上而下的前馈结构作为注意力模块的一部分,并在特征上添加软权重;Yuan 等[26]提出一种混合通道感知注意力(wise-attention)与时序注意力(time-attention)的自注意力机制深度学习框架HybridAtt,其中通道感知注意力层用来推断PSG 通道的重要性,时序注意力用来捕捉不同时间戳之间的动态相关性。
SMSDNet 为适应DenseNet 密集连接的性质,其自注意机制有所不同:①每个密集块单独注入自注意机制,块间不引入时序注意力机制,因为DenseNet 提取特征是一个顺序处理流程,不存在时间上的关联性;②每层都计算特征图像素矩阵W 和索引矩阵Q,通过卷积、矩阵相乘与全局池化为每个输出分配贡献权重;③为减少计算量与模型复杂度,之前的研究[27-28]设定了权重阈值,低于该阈值的层不作为后面某一层的输入。本文工作为保证密集块中卷积层结构的固定,对每个输入都按照权重系数进行拼接,不作删除。
1.4 NSST
非下采样是基于频域的,非下采样剪切波变换(NSST)[16]是在非下采样轮廓波变换(NSCT)[29]基础上提出的。NSCT的核心是轮廓波变换(Contourlet)[30],也称为塔型方向滤波器组(Pyramidal Directional Filter Bank,PDFB),但在拉普拉斯金字塔和方向滤波器组(DFB)中,轮廓波变换存在上采样与下采样操作,不具有平移不变性。NSCT 中将拉普拉斯金字塔替换为非下采样金字塔结构(NSP)以保留多尺度属性,并将方向滤波器组替换为非下采样方向滤波器(NSDFB)组。NSCT 从源图像中获取更多信息,其不仅具有小波变换的多分辨率和时频局部特征,而且具有多方向性和各向异性,但是NSCT 计算时间复杂度高、计算效率低。NSST 在此基础上进行改进,通过将图像分解为不同比例的有向子带以弥补采样步骤中信息丢失的缺陷,同时可准确获得图像的多角度信息。其能获得比小波变换(Wavelet)与轮廓波变换更稀疏的表达结果,工作效率更高,且融合后的图像不会产生伪像。图2 描述了NSST 低频与高频子带分解流程。
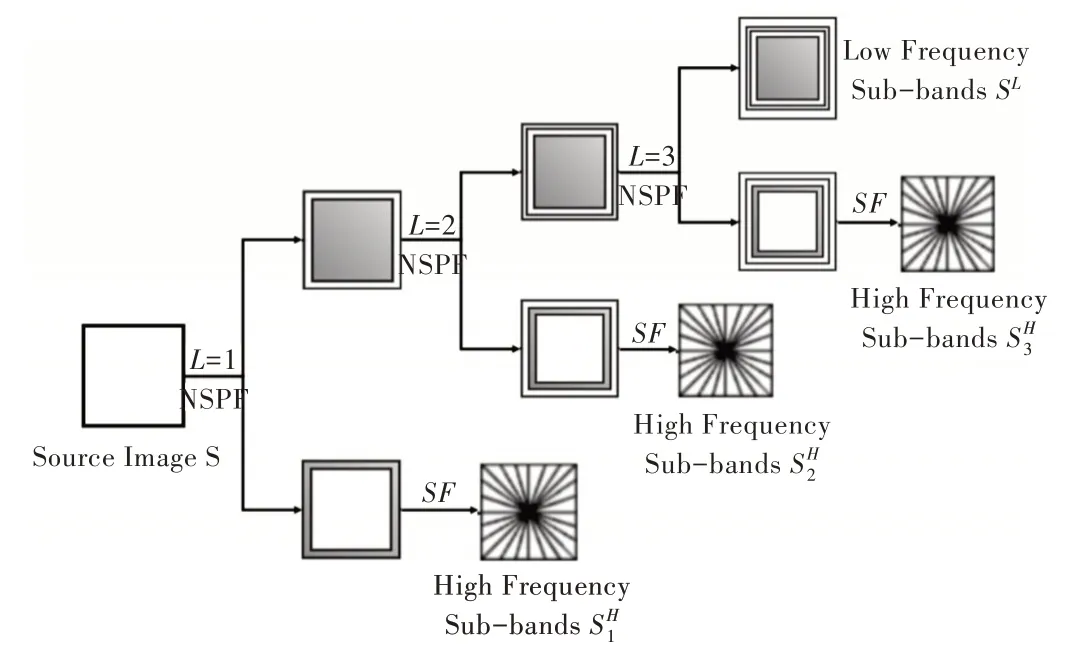
Fig.2 NSST low frequency and high frequency subband decomposition flow图2 NSST 低频与高频子带分解流程
2 系统架构
本文在NSST 基础上提出一个融合算法框架,对于PET和MRI 图像,首先使用NSST 进行高频与低频子带分解,然后分别设计低频系数与高频系数融合策略。与文献[31]的融合策略不同,本文的低频系数不采用简单的加权平均与基于最大值的策略,因为这些策略会损失图像能量,融合后图像的整体亮度及对比度差。本文采用基于稀疏表示(SR)的融合规则,可完整保留低频子带中的轮廓信息。如今对于高频子带融合规则的研究已十分广泛,包括脉冲耦合神经网络(PCNN)[32]、区域能量、稀疏表示等。与本文工作类似,文献[33]设计一种基于感兴趣信息(IOI)的融合方法,将图像分为感兴趣和非感兴趣部分,分别采用空间频率算法(SF)与取平均的方法进行融合;文献[34]对CT 与MRI 图像进行融合时,根据结构相似度SSIM(structure similarity)的不同,将高频子带分为低相似与高相似子带图像,对低相似子带系数与高相似子带系数都采用视觉敏感度系数VSC(Visual Sensitivity Coefficient)策略。为进一步提升融合效果,其分别在低相似子带系数与高相似子带系数融合中结合了梯度能量和区域能量。本文方法与文献[35]的方法类似,从源图像中提取权重图,再通过NSST 分解出高频权重系数。由于权重图为网络多次迭代训练后的输出,因此采用Adam 优化器进行反向传播,从而很好地拟合PET 与MRI 对融合图像的贡献度。但与文献[35]不同的是,本文设计了不同的权重图提取方法:①考虑到随着网络深度的增加,损失的权重图信息也越多,为减小权重图信息深度比的下降幅度,采用残差网络(ResNet)对PET 与MRI的贡献权重进行分配,该方法相比于CNN 之外的其他方法具有绝对优势;②PET 与MRI 各自维持权重图及高频权重系数,融合计算公式为两者高频系数加权和。
之后本文设计一个分类模型,考虑到融合后的图像具有丰富的特征信息,而密集连接在提取不同层次图像的纹理信息方面已取得了较多成果,因此本文采用DenseNet 对PET-MRI 进行特征提取。自注意力机制常被用来考虑当前位置与全局信息的关系,其符合DenseNet 输入拼接的性质,因此本文尝试将该机制应用于本文的分类模型。与传统只使用单尺度图像进行特征提取的方法相比,多尺度的特征图能够结合图像的高级和低级纹理特征。由于PETMRI 图像中包含PET 丰富的颜色特征(低级纹理)以及MRI的结构特征(高级纹理),因此多尺度特征图可更好地描述融合图像。最后本文试图恢复一些丢失的细节信息,通过上采样操作结合局部特征信息进行重构,可很好地胜任这项工作。同时设计后处理模块,通过亚像素卷积层上采样特征图,经过全连接层与softmax 分类器得到最终结果。
3 PET 与MRI 医学图像融合算法
3.1 算法框架
(1)采用残差网络(ResNet)对PET 与MRI 图像{IP,IM}进行权重系数提取,得到权重系数矩阵{WIP,WIM}及特征矩阵{FIP,FIM}。
(2)利用NSST 对PET 图像与MRI 特征矩阵{FIP,FIM}进行分解,分别获得PET 图像的低频子带和高频子带,以及MRI 图像的低频子带和高频子带利 用NSST 对权重系数矩阵{WIP,WIM}进行分解,得到PET 与MRI 各自的高频与低频权重系数矩阵
(4)对于低频子带融合,本文利用稀疏表示(SR)对低频子带进行融合,融合过程分为4 个阶段:联合字典构建、稀疏编码、稀疏系数融合、系数重构,最终得到融合结果。
图3 描述了本文的融合算法框架。
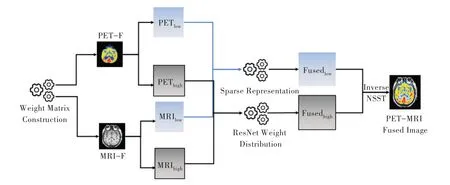
Fig.3 Fusion algorithm framework图3 本文融合算法框架
3.2 残差网络权重系数提取
本文设计一个二通道残差网络,分别对PET 与MRI 提取权重系数矩阵和特征矩阵,如图4 所示。
网络第一层存在4 个分支,其中两个分支使用单一的卷积层以提取PET 与MRI的特征矩阵{FIP},FIM,剩下两个分支类似于自动编码器,采用对称网络结构,以一层最大池化层和3 × 3 卷积层(该卷积层不改变通道数量)为中心,左右两边分别使用三层卷积层提取PET 与MRI的权重系数矩阵{WIP,WIM}。为提高权重分配的准确性,本文在层与层之间引入残差连接。具体方法如下:
(1)特征图提取。将图片初始大小调整为256 × 256 ×3,3 个通道分别代表HSV 颜色空间。先将图像经过一个卷积核大小为3 × 64 × 3 × 3的卷积层,采用1 个像素的全零填充,保证图片宽度与高度不变。为保证特征矩阵和权重矩阵尺寸与通道数的一致性,方便后续高频子带融合时进行权重分配,接下来对权重图进行步长为2、卷积核大小为64 × 128 × 3 × 3的卷积操作,最终得到PET 与MRI 各自的特征图{FIP,FIM}。

Fig.4 Residual network for weight coefficient extraction图4 用于权重系数提取的残差网络
(2)权重系数矩阵提取。卷积层采用标准的BN-ReLU-Conv结构,滤波器权重形成一个O×I×W×H的四维张量,分别代表输入通道数、输出通道数以及卷积核宽度与高度。为了在每次卷积操作后方便处理图像,采用1 个像素的全零填充,并设置W=H=3,则第k层卷积层卷积核大小为3 × 3 × 2k+2× 2k+3,且经过每次卷积后图像尺寸固定,权重图以两倍速率扩充,第k层输出后可得到2k+3个权重图。卷积操作计算过程如下:
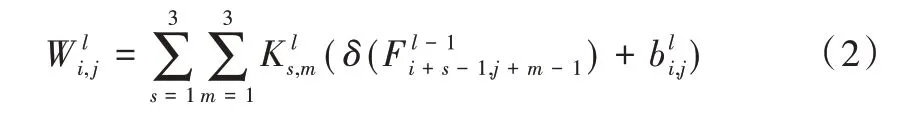
为突出图像区域峰值,降低之后权重矩阵计算的复杂度,在三层卷积层之后对图像进行下采样,采用步长为2的2 × 2 最大池化层来缩小图像,突出图像区域权重中的最大值。最后网络分别输出权重提取后的结果{WIP,WIM}。
(3)残差连接优化。不添加残差连接时,第l层输出Fl=Wl,输入只经过简单的激活与卷积操作。考虑到随着层数增加,权重提取效果可能会变差,本文添加了两种残差连接:
当输入与输出维度相同时,在卷积输出结果上添加原始权重图的恒等映射。计算第l层卷积层输出Fl的公式如下:
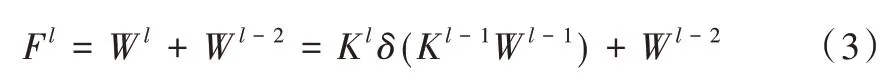
其中,Wl是纯卷积操作第l层输出的权重图,Kl是第l卷积层的3 × 3 卷积核,δ是ReLU 激活函数,可用于非线性变换。
本文设计的网络中,由于经过每个3 × 3 卷积层之后通道数量发生了改变,因此在作恒等映射时需要作一个线性变换。此时,计算第l层卷积层输出Fl的公式如下:

其中,Ds是1×1 卷积,用来将Wl-2权重图的通道数转换为与Wl通道数一致。
3.3 高频子带融合规则
上文从残差网络中提取到特征矩阵{FIP,FIM}与权重矩阵{WIP,WIM},接下来使用NSST 对特征矩阵进行分解,得到对应的高频子带,之后对权重矩阵进行分解,得到高频权重系数矩阵相比于其他高频融合方法,如基于感兴趣信息(IOI)的方法[33],通过局部极值算法(LES)和剪切滤波器(SF)简单区分MRI 与PET-FDG的感兴趣及非感兴趣部分,且感兴趣部分融合时仅根据局部能量进行取舍,非感兴趣部分采用简单的取平均方法进行融合,两者都不是按照比例进行融合。本文方法在残差网络中经过了epoch=20 次迭代训练,得到的高频权重系数矩阵已能很好地反映融合图像中PET 与MRI 特征矩阵各像素点的权重比例。本文高频子带融合计算公式如下:
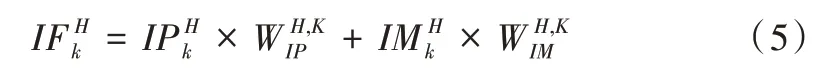
3.4 低频子带融合规则
低频子带包含了大量能量信息,但其稀疏性较差,因此本文采用稀疏表示(SR)提高其稀疏度,并提升融合效果。如图5 所示,基于稀疏表示的融合算法分为以下9 个步骤:
(1)设源图像(PET 与MRI)大小为M × N,利用大小为n×n的滑动窗口对PET 与MRI低频子图IPL和IML进行分块,以(i,j)为中心得到分块c 表示提取的第c(c=1,2,…n × n) 个图像块。基于稀疏表示的低频子带融合流程如图5 所示。
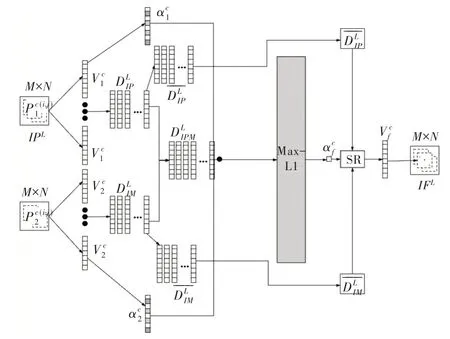
Fig.5 Low-frequency subband fusion process based on sparse representation图5 基于稀疏表示的低频子带融合流程
(3)将每个图像块转换成列向量形式V1c和V2c,各自组合构建局部字典
(4)考虑到源图像的能量信息,计算局部字典的均值矩阵
(6)使用联合字典对向量V1c、V2c分别进行稀疏 编码,得到各自的稀疏系数
(7)利用L1 范数最大规则对进行融合,得到稀疏表示系数,与Kang 等[37]提出的融合方法不同,本文使用的计算公式如下:
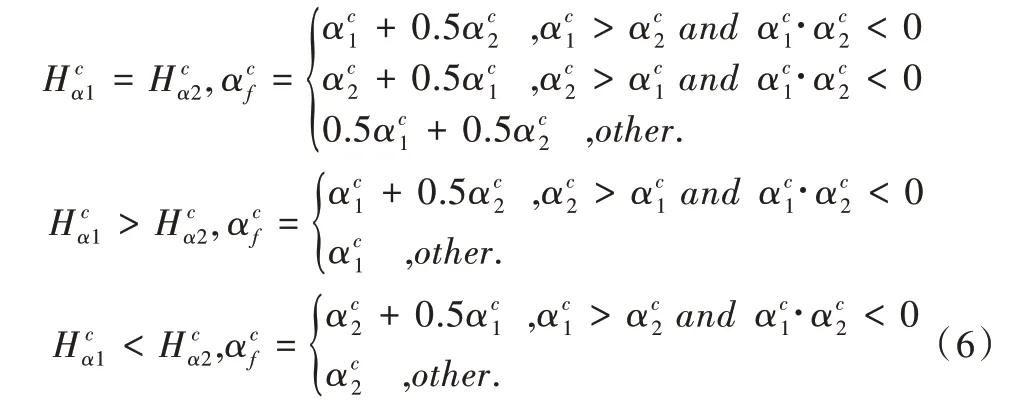
(8)稀疏重建时使用联合字典与稀疏表示系数,记重建后的向量为,其计算公式如下:
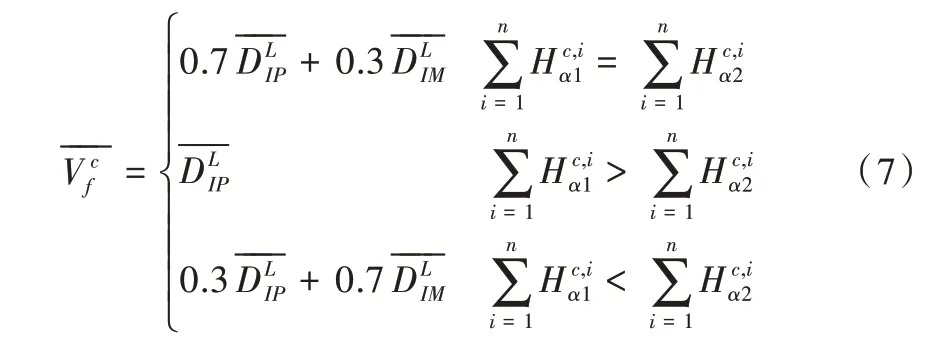

(9)最后将每个列向量V fc重新变换成块Pfc,其对应融合图像IFL的位置为(i,j)。
反复执行步骤(1)-(9),总共处理低频子带的M×N对像素点。
4 基于自注意机制的多尺度DenseNet分类模型
4.1 模型架构
基于自注意机制的多尺度DenseNet 分类模型SMSDNet 在融合PET-MRI 图像基础上进行特征提取与神经胶质瘤分类。该模型具体架构如图6 所示。
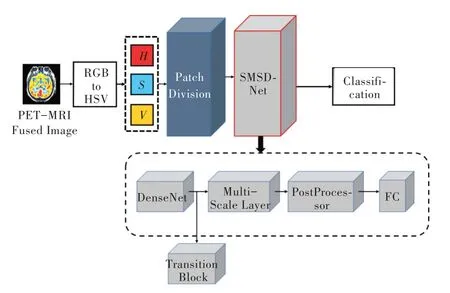
Fig.6 SMSDNet model architecture图6 SMSDNet 模型架构
该模型分为4 个模块:
式中:为0-1变量,k=1时,一定需要对刀,则时,若k子批量与k-1子批量在机床Mm加工的工序Ojils、所选刀具集相同时,机床Mm加工第k子批量前不需要对刀,即否则
(1)颜色空间转换模块。RGB 颜色模型适用于显示器等发光体显示,所有颜色信息由不同亮度的三基色混合而成。HSV 模型是针对用户观感的一种颜色模型,H 通道代表色彩,S 代表深浅,V 代表明暗,相比于RGB 模型,其在图像分割中作用较大。在RGB 模型中通过3 个通道表现出的图像比真实图像更亮,而在HSV 中仅用一个明暗分量V 即能表现亮度。此外,HSV 可直接表现图像之间色调与颜色的深浅差异。通过以下公式将RGB 转换成HSV:
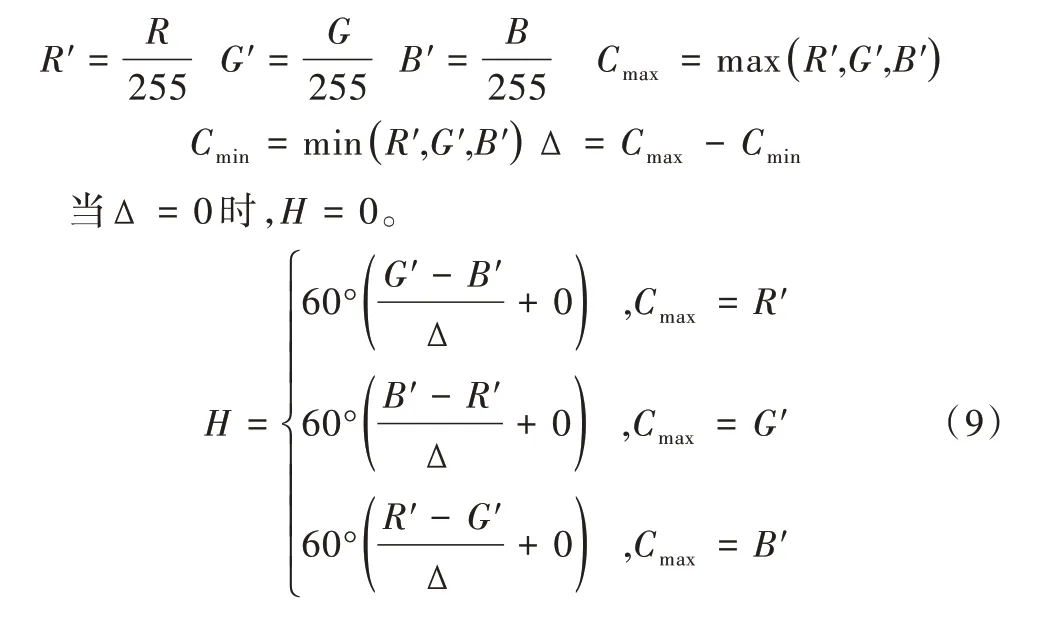
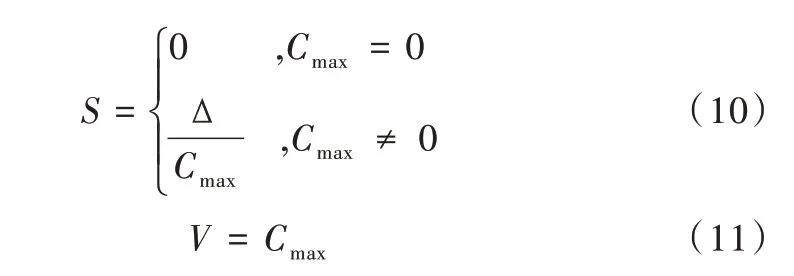
(2)基于自注意力机制的密集卷积网络模块。考虑到DenseNet 密集连接的性质,每层的输入是前层所有输入的拼接,且在每个密集块中设计5 层密集层作为特征提取器。采用自注意机制对每层输入的各组成部分进行权重分配,得到各自的贡献比例。
(3)多尺度特征图信息融合模块。融合图像初始输入尺寸为256×256×3,在经过每个密集网络块后,图像宽高不变。文献[36]、[37]的研究表明,图像多尺度信息能够提升特征提取效果。在每个密集网络块之后引入转换层,其由一层1×1的Conv 和一层最大池化层组成。最大池化层将密集块输出图像尺寸的宽与高变为原来的1/2,且保持通道数不变。SMSDNet 中有4 个密集网络块,对应输出4 个宽度与高度不同、通道数为16的特征图,记为Fl1、Fl2、Fl3、Fl4。其中前两层密集块输出的Fl1、Fl2尺寸较大,感受野范围也较大,具有融合图像的粗粒度信息,后两层输出的Fl3、Fl4多次经过最大池化层后,图像尺寸变为32×32 和16×16,且因经过了多次特征提取,细节信息比较丰富。基于以上事实,本文对4 个输出的特征图先进行一次跨层融合,再对结果进行融合,得到包含多尺度信息的特征图。
(4)后处理模块。融合图像从输入到输出经过4 层最大池化层,这些下采样操作丢失了图像大量细节信息。为尽可能恢复融合图像的低级特征(如颜色特征、形状特征等),后处理模块以多尺度信息特征图与最后一个密集块输出的特征图为输入,通过上采样与same 卷积操作以恢复一些细节信息。最后将输出的特征图经过2 个神经元的全连接层与softmax 分类器,得到图像属于神经胶质瘤的概率。
4.2 自注意机制的密集块
SMSDNet 中每个密集块有5 层密集层,每层密集层的输入是前层所有输入的拼接。考虑到连接的前后关系,引入自注意力机制,该机制的核心是为前层每一个输出进行权重分配后再进行拼接。自注意力机制的密集块如图7 所示。
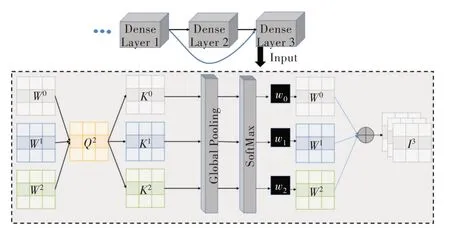
Fig.7 Self-attention dense block图7 自注意力机制的密集块
自注意机制分成以下3 个步骤:
(1)每个输入对应一张特征图Fl(l=0,1,…,4),尺寸大小为n×n。对于每层计算两个矩阵,分别为键矩阵Wl与查询矩阵Ql,初始化时Fl=Wl=Ql。计算第l层密集层的输入时,将第l-1 层的查询矩阵Ql与前面所有层(包括自己)的键矩阵Wl分别作矩阵乘法运算,得到权重矩阵Kl。
(2)由于每个权重矩阵Kl的尺寸为n×n,为进一步提炼权重系数,使用全局池化层对Kl作进一步处理。每个Kl共享一个池化矩阵Pn×n,计算Kl中每个像素点的加权和。经过全局池化操作后,每层都会得到一个反映权重的数值,之后使用softmax 将这些值约束到[0,1]范围内,得到权重系数wl。
(3)文献[38]、[39]的研究与本文研究类似,也是计算权重比例并设置权重阈值。当权重低于该阈值时,不作为输入的一部分以减少参数数量。但以上方法有一个缺点,每层输入由前层的部分输出而非全部输出组成,因而模型是不固定的,每层密集层卷积使用的卷积核通道数量会有很大变化。同时基于权重系数低的层经过权重分配后特征贡献将会很少的事实,对于权重系数低的前层输出不作删除。第l层密集层的输入计算公式如下:

这里将原始输入作为第0 层。
4.3 多尺度特征提取
在SMSDNet 中,为获得图像的多尺度信息,在密集块输出后加上变换层。SMSDNet 中多尺度特征图提取与融合过程如图8 所示。
每个过渡层使用2×2×2的最大池化层对特征图尺寸进行变换,li层得到的特征图为Fli(i=1,2,3,4),具体尺寸如表1 所示。
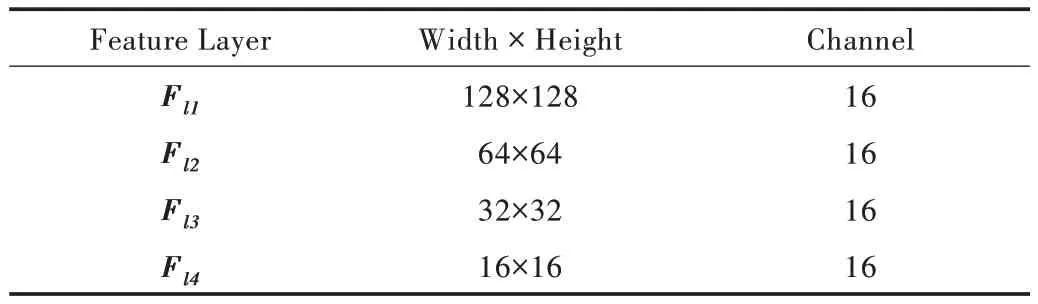
Table 1 Size of the feature map output for each transform layer表1 每个变换层输出的特征图尺寸
(1)跨层融合。对Fl1、Fl3进行二次卷积操作,其中Fl1、Fl3都使用1×1×16×64的卷积核。由于尺寸大小不一致,将Fl1卷积核的步长设置为2。1×1 卷积核在深度学习中已得到广泛应用,如GoogleNet[40-41]中的Inception、ResNet[6]中的残差模块等,其优点是使用最少的参数拓宽通道数量,可在卷积层之后配合激活函数很好地实现network in network 结构。原来融合后的16 个通道特征图经过跨通道信息交互实现了通道变换,相当于卷积操作只在channel 维度上进行变换,W 和H 上具有共享的滑动窗口。经过一次卷积后,Fl1尺寸大小为64×64×64,因此对Fl1的 尺寸进行调整。使用步长为2、1×1×64×64 卷积层代替平均/最大池化层,在将图像尺寸调整为32×32的同时,不改变通道数且尽可能减小图像提取的细节损失。最后将结果矩阵的像素点相加,得到融合后的结果F′l13,尺寸为32×32×64。Fl2与Fl4的融合步骤类似,最终得到融合结果Fl24,尺寸为16×16×64。
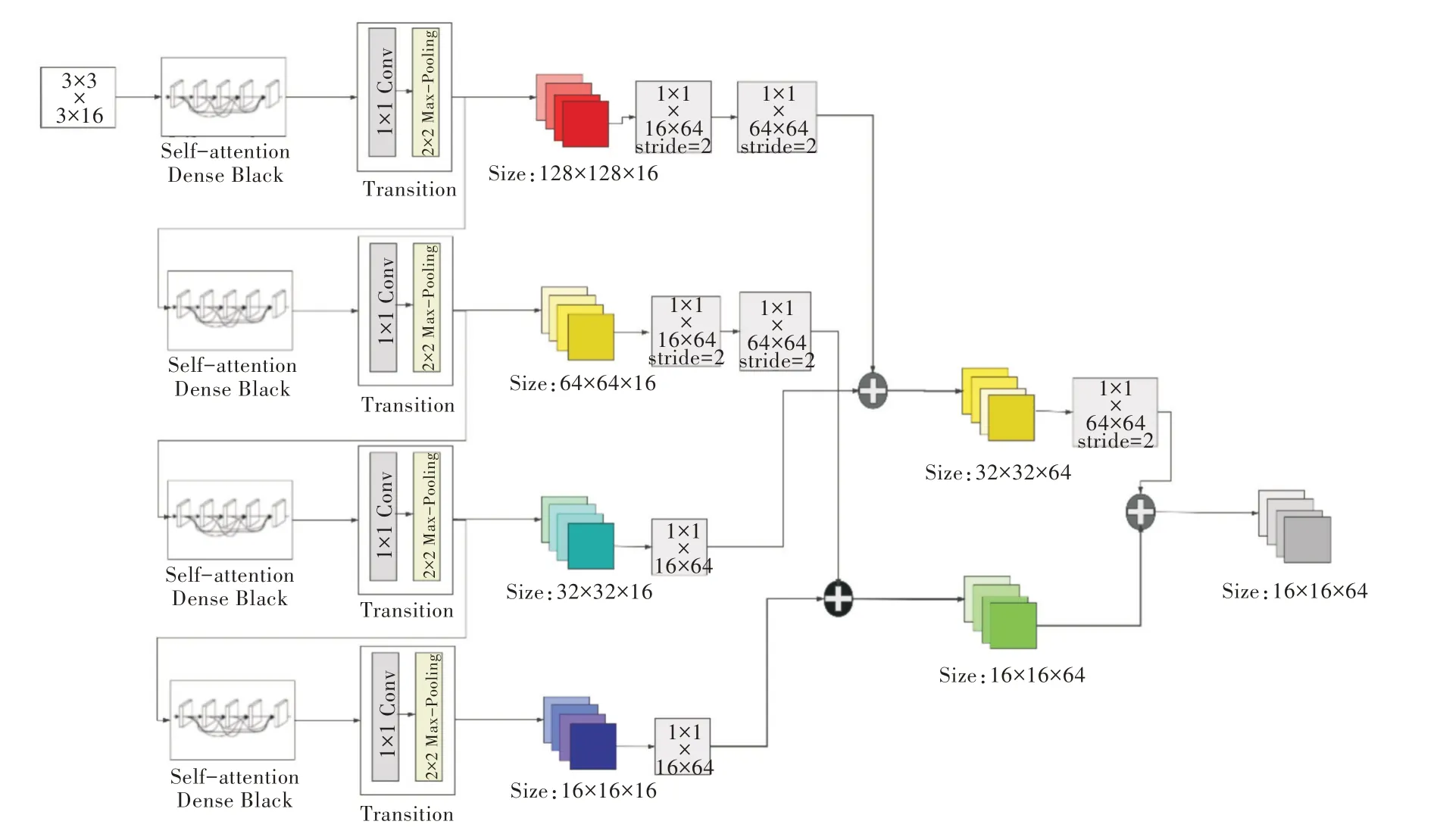
Fig.8 Multi-scale feature map extraction and fusion process in SMSDNet图8 SMSDNet 中多尺度特征图提取与融合过程
(2)二次融合。将得到的融合结果F′l13与Fl24进行融合,为使F′l13与Fl24的尺寸大小一致,与跨层融合方法类似,本文使用步长为2、1×1×64×64 卷积层对特征图Fl13进行卷积操作。但与跨层融合操作不同,考虑到之后会通过后处理操作对后层密集块输出Fl4再一次进行特征提取,因此在二次融合中降低Fl24的贡献比例。本文使用参数优化器对贡献比例进行微调,具体数据在实验部分展示。最终的二次融合计算公式如下:

其中,每个权重与特征矩阵中的每个元素作乘积操作。
4.4 PostProcessor
为了结合密集块前部提取到的低级纹理特征(颜色特征、形状特征)与后部提取到的高级纹理特征,同时恢复因转换层下采样操作而丢失的细节信息,在全连接层之前加入后处理模块。具体模块框架如图9 所示。
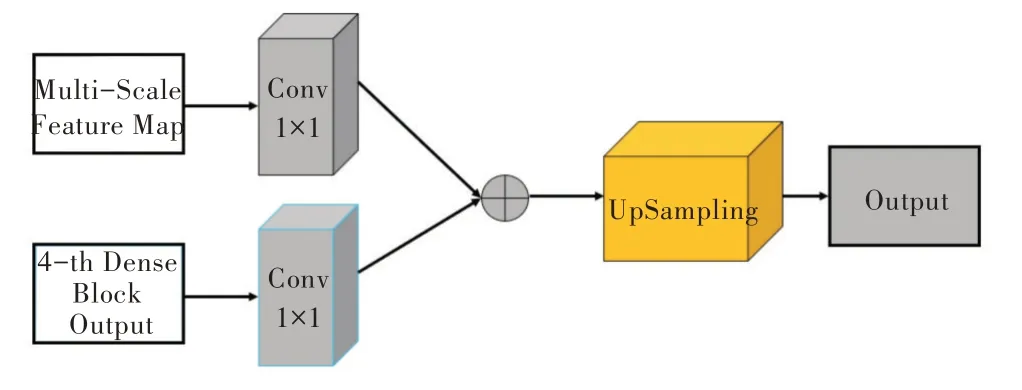
Fig.9 Post processing module framework图9 后处理模块框架
在后处理模块中,首先将第4 层密集块输出Fl4与上文得到的多尺度特征图FMS作为输入,由于两者通道数不一致,因此使用1×1×16×64的卷积核对Fl4进行升维,得到通道数为64的特征图。对于FMS使用1×1×64×64的卷积核,以保持通道数固定。之后对得到的结果作矩阵加法运算,得到融合后的结果FP1,尺寸为16×16×64。接下来进行卷积后上采样操作,常见的对图像进行上采样线性插值的方法有最近邻插值[42]、双线性插值[43]、双三次插值等。近年来基于深度学习的上采样方法得到了广泛研究,如Tian等[44]提出Dupsampling,通过卷积学习亚像素(sub-pixel),并通过重组以获得更大的图像。但与线性插值相比,该方法因为通道数改变,对于不同放大倍数的图像需要训练不同网络,且不容易连续进行放大。Wang 等[45]提出CAPAFE,其中核预测模块可生成用于重组计算的核上权重,之后在内容感知重组模块中将权重通道变形为一个kxk的矩阵。将该矩阵与原本输入特征图上的对应点一一进行匹配,并与以其为中心的kxk区域作卷积计算。本步骤中的上采样处理流程则是借鉴文献[46]提出的Pixel Shuffle,如图10 所示。
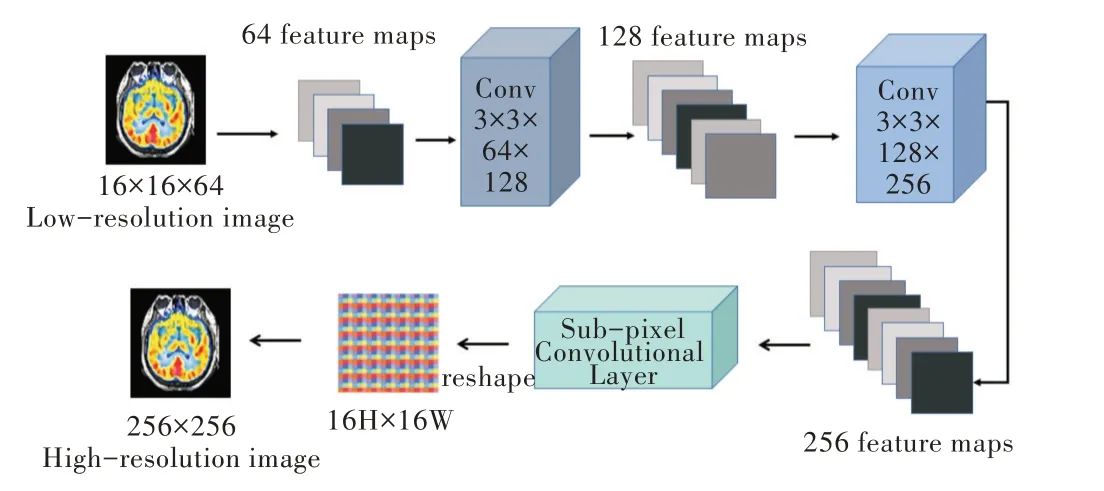
Fig.10 Upsampling process in postprocessor module图10 后处理模块中上采样处理流程
将FP1低分辨率图像经过两层卷积,卷积核分别为3×3×64×128 和3×3×128×256,且每次卷积采用1 像素的全0填充固定图像大小,两次卷积操作后得到与原图像尺寸相同的特征图FP2,尺寸为16×16×256;之后经过一层亚像素卷积层,该层采用reshape 方法将H×W×r2(r=16)的特征图转换成rH×rW的输出图,得到输出特征图FPET-MRI;最后将FPET-MRI放到2 个神经元的全连接层和softmax 分类器中,得到分类概率[P1,P2],且P1+P2=1。
5 实验与分析
本文实验部分的源代码可通过https://github.com/colinLH/SMSDNet 获取。
5.1 数据集
本文在两个基准数据集上验证SMSDNet的有效性。
(1)TCIA。因为需要同一患者的PET 与MRI 放射学图像,挑选出其中一个数据集ACRIN-FMISO-Brain(ACRIN 6684),数据集中包含45组尺寸为256×256的PET 和MRI图像。由于图像数据量较小,本文采用标准的数据增强方案,即对每张PET 与MRI 图像进行镜像与移位操作,最终得到135 组数据。训练集与测试集分别包含110 张和25 张图像,本文选择20 张训练图像作为验证集。在图像预处理方面,将PET 与MRI 分别在统计参量图(SPM)中进行头动校正、配准与归一化处理。其中包含两个样本种类:正常人群和神经胶质母细胞瘤患者。
(2)哈佛大学全脑图谱数据集(ANNILB)。该数据集中包含各种彩色脑部放射图像,尺寸为256×256。先从Normal Anatomy in 3-D with MRI/PET中选择120张PET与MRI 横截面图像作为正常数据集,再从Neoplastic Disease Glioma 中选择40 张PET-FDG 与MRI 图像作为患病数据集。训练集与测试集分别包含130 张和30 张图像,本文选择30 张训练图像作为验证集。在图像预处理方面,由于每个病例中含有多张切片,无法找到具体患病位置的切片,因此将mhd 格式的源数据通过二值化与形态学滤波的膨胀及闭运算等操作,生成脑部图像。由于图像不是RGB 三通道的,将图像更改为24 色位图bmp 格式的图像。
5.2 PET 与MRI融合结果
实验配置如下:平台为MATLAB2018a,操作系统为Windows10,硬件配置为Intel i7 8750 2.20GHz 8GB RAM。
首先将本文设计的方法与拉普拉斯变换(LP)[47]、曲线波变换(CVT)[48]、NSCT-PCNN[49]、NSST-PAPCNN[50]、ShearLab3D[51]5 种先进的融合方法进行比较。LP 是较为经典的融合算法,在医学图像融合方面具有较好效果;CVT变换是基于傅里叶变换与小波变换的一种改进,能够很好地表达图像边缘信息,在恢复边缘结构与减小局部范围噪声方面取得了良好效果;NSCT-PCNN 将轮廓波与脉冲耦合神经网络相结合,能够从复杂背景中提取出有效信息;NSST-PAPCNN 则是最近提出的一种杰出的基于MST的融合策略。其次,本文使用互信息(MI)、信息熵(IE)、边缘强度(EI)、空间频率(SF)、平均梯度(AG)、平均结构相似度(MSSIM)共6 个指标评价融合效果。
(1)互信息(MI)。衡量两组数据之间的相关性,MI 越大,像素灰度越丰富,且灰度分布越均匀。
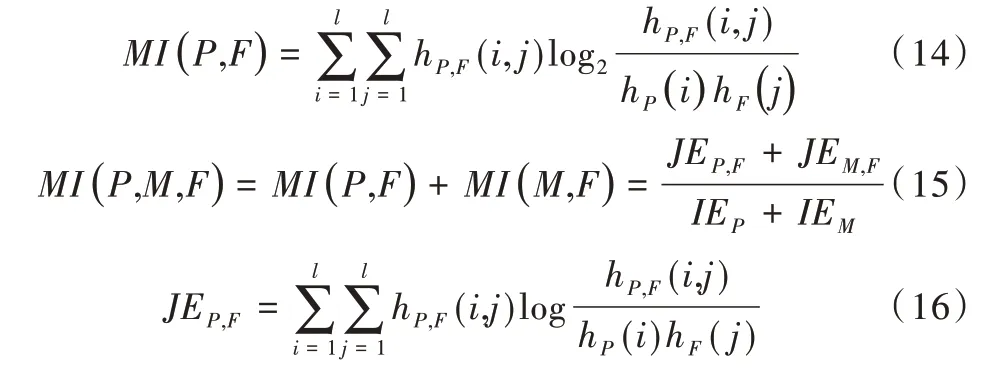
其中,P、M、F分别代表原始PET 图像、原始MRI 图像以及融合后的图像。hP,M(i,j)是P与M归一化联合灰度直方图,hP(i)和hF(j)是边缘直方图,l是灰度数量,JEP,F是PET与融合图像之间的联合熵,IE是单幅图的信息熵。
(2)信息熵(IE)。反映图像中信息的丰富度,IE 越大,图像包含的平均信息量则越大。

其中,f(i,j)是图像像素灰度与图像邻域灰度均值组成的特征组,N为图像尺度。
(3)边缘强度(EI)。反映边缘点梯度的幅值,EI 越大,图像包含的边缘信息越丰富。最终融合图像的边缘强度计算公式如下:
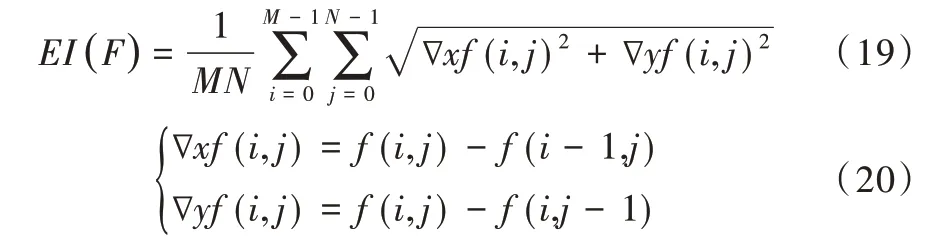
其中,∇xf(i,j)和∇yf(i,j)是图像第i行第j列x、y方向的一阶差,这里定义融合图像F的边缘强度是每个像素点边缘强度和的平均值。
(4)空间频率(SF)。反映图像灰度变换率,SF 越大,图像越清晰。
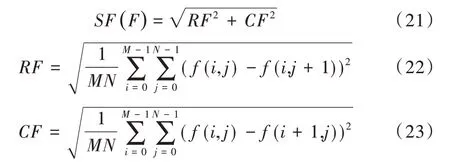
其中,RF、CF分别为图像的行频率和列频率,f(i,j)是每个像素点的值。
(5)平均梯度(AG)。反映图像比较细节的能力,AG 值越大,图像层次越多,且图像越清晰。反之,图像越模糊。
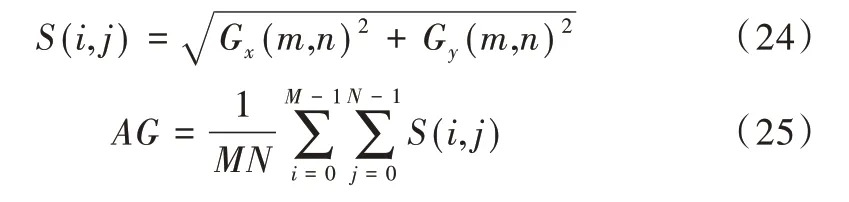
其中,Gx、Gy分别代表使用Sobel梯度算子求得x与y方向的图像梯度。
(6)平均结构相似度(MSSIM)。反映源图像与融合后图像结构上的相似度,MSSIM 越大,融合后图像的结构信息与源图像越相似。
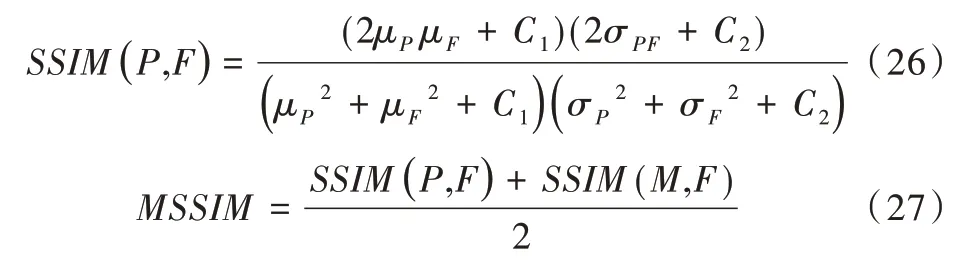
其中,μP、σP、σPF分别是图像均值、标准差与关联性,C1、C2是常数。
图11、图12 是采用本文方法融合后的PET-MRI 图像与LP、CVT、NSCT-PCNN、NSST-PAPCNN、ShearLab3D 融合结果的对比。前3 种方法使用PET 与MRI 灰度解剖图像,后3 种方法使用PET RGB 三通道的彩色功能图像与MRI 灰度解剖图像进行融合,融合图像属于RGB 颜色空间。结果表明,LP 与NSCT-PCNN 融合后色彩与亮度缺失较多,且清晰度不及CVT,原因可能是NCST-PCNN 低频与高频融合规则皆采用PCNN,相比于CVT 低频规则采用取平均值、高频规则采用取区域能量的方法,可能丢失图像部分灰度。但PCNN 处理图像后可有效抽取背景信号,其因数中包含了横向及纵向梯度等许多信息,因此EI 值较高。相较于NSST-PAPCNN 与ShearLab3D的融合图像,本文方法虽然图像灰度的丰富度没有显著提高,但是整体结构层次更多,清晰度有一定程度提升。

Fig.11 Fusion images using LP,CVT and NSCT-PCNN图11 使用LP、CVT、NSCT-PCNN 得到的融合图像

Fig.12 Fusion images using NSST-PAPCNN,ShearLab3D and the proposed SP-ResNet图12 使用NSST-PAPCNN、ShearLab3D 及本文SP-ResNet 得到的融合图像
图13 是本文方法与其他5 种融合方法在6 个评价指标上的对比。CVT 相较于传统的LP 与PCNN 融合方法,其MI数值较大,包含了丰富的图像信息。但在其他指标上,前4种融合算法差异不大。文献[51]提出的ShearLab3D 与本文提出的融合算法在EI、SF 和AG 指标上有大幅提升。虽然本文提出的算法在空间频率(SF)上不及ShearLab3D,但在其他指标上都有小幅提升。其中,在平均梯度(AG)和边缘强度(EI)上,本文算法相较于ShearLab3D 分别提升了0.177 8 与1.368 6,包含了更丰富的边缘信息,且融合图像更清晰,可提升后续神经胶质瘤判别的准确度。各种融合方法6 个评价指标值的比较如表2 所示。
5.3 SMSDNet 训练
本文使用随机梯度下降(SGD)方法进行网络训练。在TCIA 数据集上,设置批量大小为64 进行100 个epoch的训练。设置初始学习率为0.01。在训练epoch 达到50%和75%时,将学习率调整为1/10。在ANNILB 数据集上,同样设置批量大小为64,并进行2 000 个epoch的训练。设置4个不同的学习率λ,分别为1、0.1、0.01 和0.001,观察模型的损失变化趋势。本文借鉴Huang 等[8]训练DenseNet-161 时选择的方法,使用10-4的权重系数与0.9的Nesterov 动量。不同的是,SMSDNet 密集网络中只有29 层,因此本文不使用dropout 丢弃部分卷积层,以保证模型结构的固定性。为防止过拟合,只进行一次SMSDNet 训练与测试误差评估。同时在ResNet-152[6]、ResNet-200[53]、Wide ResNet[52]、ResNet-101[54]、Network in Network[55]、All-CNN[56]及DenseNet-161[8]上评估分类的误差率,并与SMSDNet 进行比较实验。
5.4 TCIA 与ANNLIB 分类结果
(1)精度。在TCIA 与ANNLLIB的所有数据集上,SMSDNet的分类错误率都低于其他分类网络。在TCIA 上的错误率为5.07%,在ANNLIB 上的错误率为4.39%,明显低于各种深度的基本ResNet 架构,但Wide ResNet 分类错误率反而小幅上升。在TCIA 上,本文结果相较于CNN 和Network in Network 有显著提高,错误率分别降低了40% 和45%左右。表3 显示了本文实验结果在TCIA ANNLIB 数据集上的错误率,其中采用增长率为48%的DenseNet-161,Wide ResNet 不采用DropOut 和pre-activation。结果表明,随着ResNet 网络层次的增加,错误率并没有明显降低,且200 层的ResNet 错误率仍低于161 层的DenseNet,性能也没有显著提高,很可能是因为本文工作局限于简单的图像二分类。
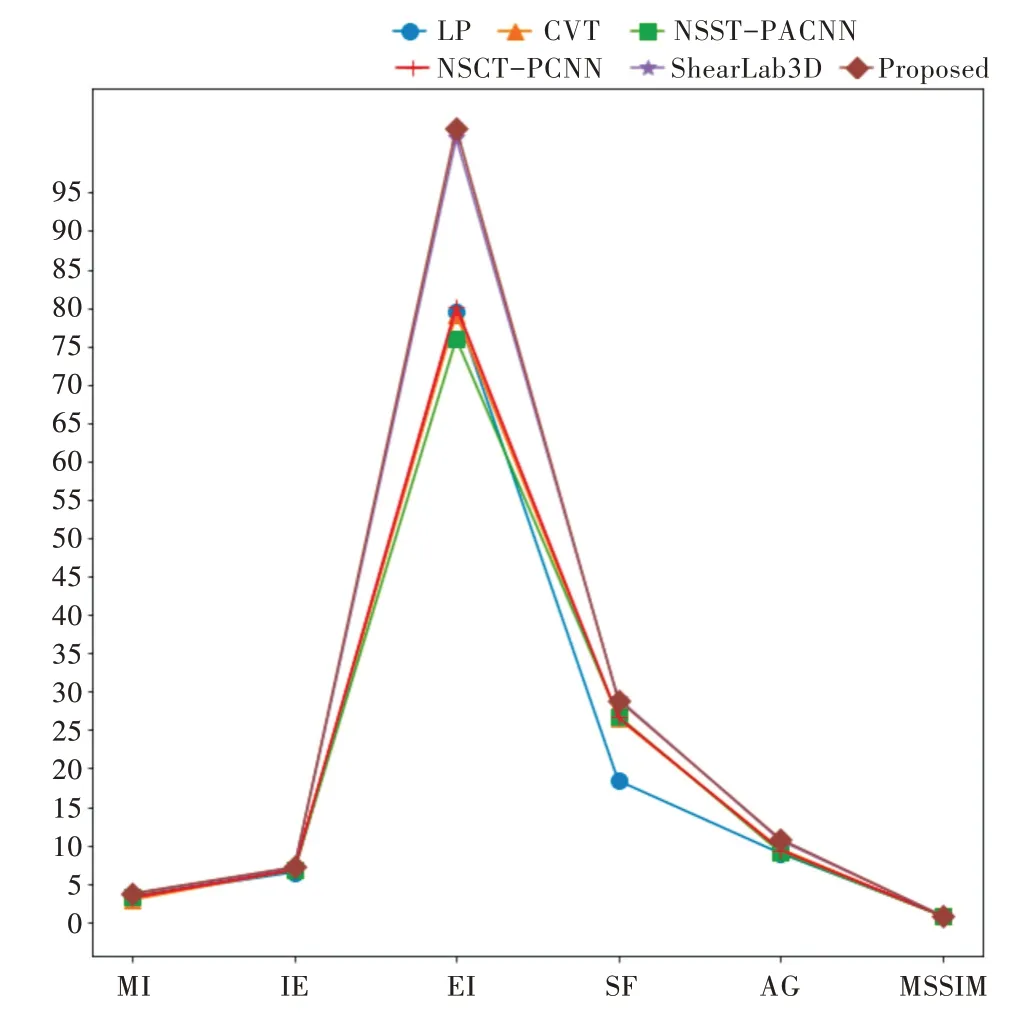
Fig.13 The value of each metrics for six fusion methods图13 6 种融合方法各个评价指标值

Table 2 Comparison of six metrics for six fusion methods表2 6种融合方法的6 种评价指标比较
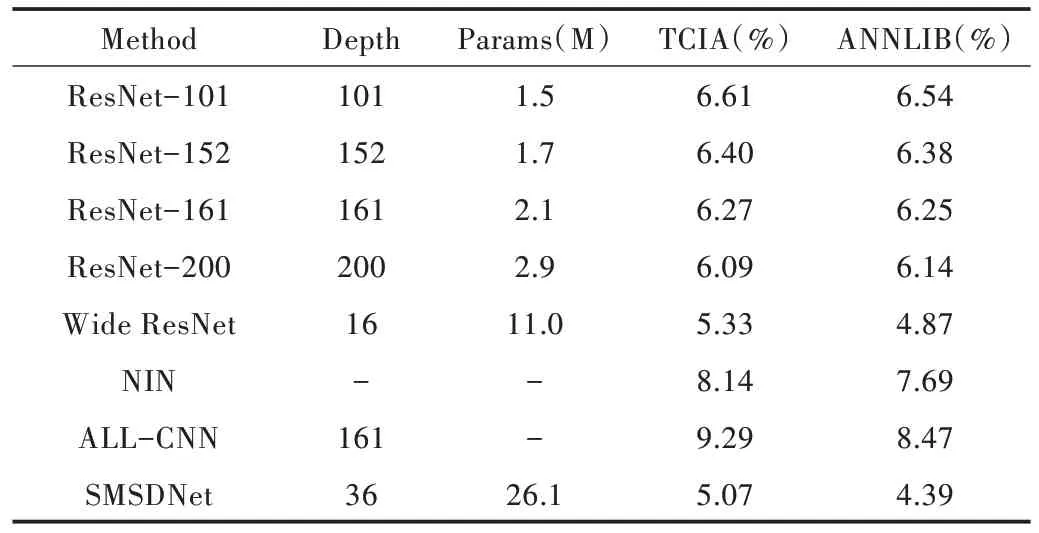
Table 3 Error rate of TCIA ANNLIB dataset表3 TCIA ANNLIB 数据集错误率
(2)训练效率。SMSDNet 相比于基本的ResNet 架构与DenseNet,深度只有36 层,且效果更优。因为本文没有使用Dropout,且增加了自注意力机制,引入了索引矩阵,所以参数量偏大。本文网络不适合增加深度,但相比于其他网络,SMSDNet 仅使用较少的卷积层即大幅提升了分类准确率,因此也没必要过分增加深度。相比于DenseNet,本文参数量降低了27%,但测试误差接近,且有小幅提升。为减少模型参数,通过增加池化层数量来减少参数的方法已被广泛应用于DenseNet。本文在密集块之间引入瓶颈层,每层瓶颈层中仅有一层最大池化层,因此本文参数量仍无法显著减少,这也是本文模型的缺点。但是SMSDNet 计算效率高,较低的深度即可达到较好的分类效果。
SMSDNet 模型在ANNLIB 上的训练损失如图14 所示,其中横坐标表示训练epoch,λ 表示学习率。对TCIA、ANNLIB 分别用数量为25 与30 个样本的测试集进行评估,得到正确与错误分类的样本数。两个数据集上测试集的混淆矩阵如图15 所示(彩图扫OSID 码可见)。
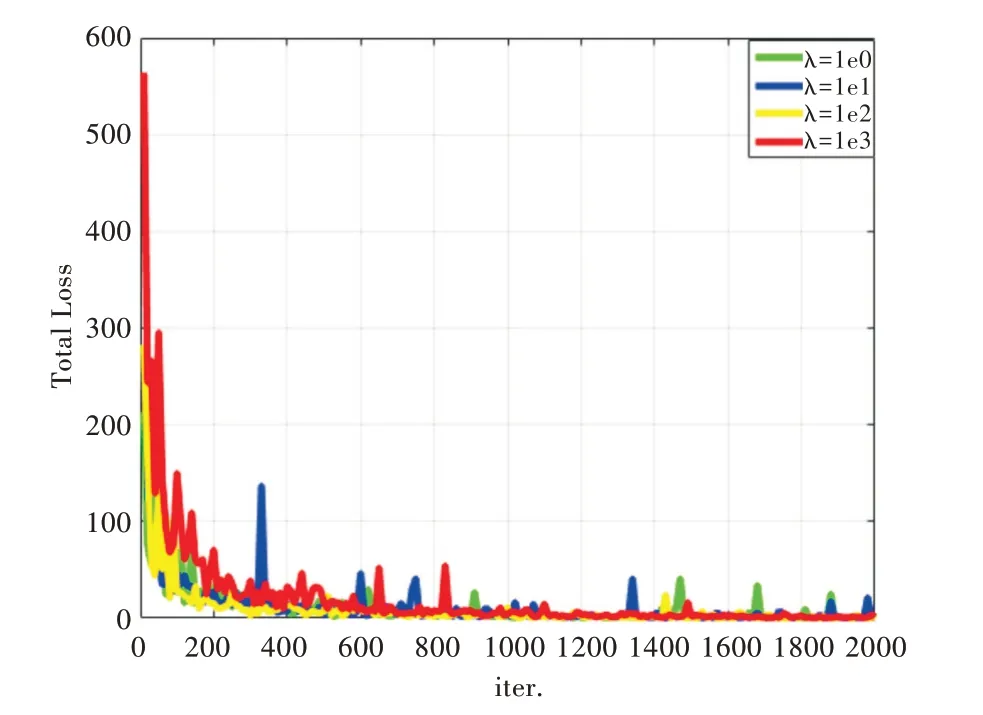
Fig.14 Training loss of SMSDNet model on ANNLIB图14 SMSDNet 模型在ANNLIB 上训练损失
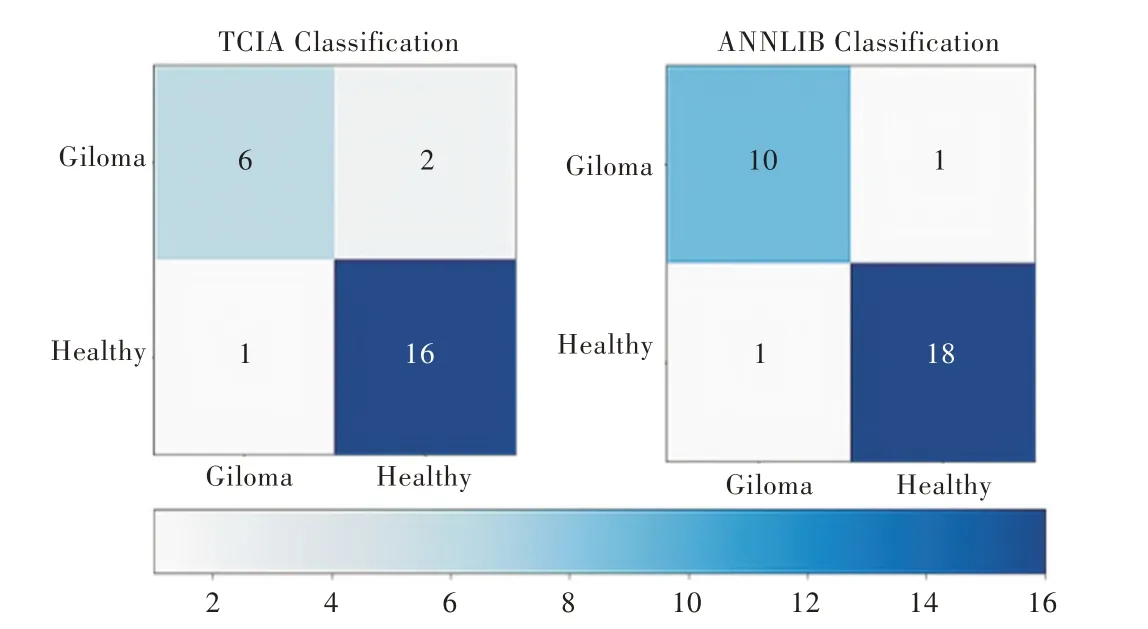
Fig.15 Confusion matrix for neuroglioma dichotomization on TCIA and ANNLIB图15 TCIA 与ANNLIB 上神经胶质瘤二分类混淆矩阵
对于每个数据集,根据以下公式计算召回率、精确率及F1分数:

在TCIA 与TEBA的测试集上,本文定义健康的样本为正样本,患有神经胶质瘤的样本为负样本,得到回归率分别为0.941 和0.947。其中,各自误判为负样本的仅有一例,表明SMSDNet 很好地判断出了健康样本,精确率分别为0.889 和0.947。但其在单独的健康样本中精确率较低,猜测可能是测试样本基数小的缘故,对整体样本进行8 次5折交叉验证,得到平均精确率分别为0.952 和0.983,验证了之前的猜想。为综合考虑回归率和精确率两个指标,实验同时计算了F1分数。其F1分数分别为0.978 和0.965,表明SMSDNet 对于小样本数据也有很高的训练精度。此外,SMSDNet 只有36 层密集卷积层,由于密集连接的性质,随着层数的增加,效果不会变差,因此推断SMSDNet 在数据量更大与密集网络层数更深的情况下,分类精度将进一步提升。
6 结语
本文首先提出基于NSST的图像融合方法,其中低频子带采用稀疏表示的方法进行融合,高频子带采用残差连接网络对PET 与MRI 分解出的高频部分进行权重分配后再进行融合。低频融合方法充分结合了NSST的平移不变性,可避免伪吉布斯现象出现,且SR 能更好地表示图像非线性边缘和曲面。高频融合方法通过神经网络得到权重系数,相比于其他融合方法具有绝对优势,融合后的图像结合了PET 图像的色彩丰富度及MRI 图像的结构信息。之后提出基于DenseNet的带有自注意力机制与多尺度变化机制的分类框架SMSDNet,针对病理样本分类任务取得了优异的成绩,相比最新模型的平均准确率提升了4.7%,可准确判断出患有神经胶质瘤的样本,具有临床辅助诊断的应用价值。
猜你喜欢
今日农业(2021年9期)2021-11-26
空间电子技术(2021年4期)2021-11-10
北京航空航天大学学报(2021年9期)2021-11-02
英语文摘(2021年2期)2021-07-22
电子制作(2019年22期)2020-01-14
电子制作(2019年11期)2019-07-04
电子测试(2018年4期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
系统工程与电子技术(2016年2期)2016-04-16
中国质量与标准导报(2015年2期)2015-02-28
