
基于fast-Unet的补强胶胶体在线识别分割技术
2022-03-25 04:45薛金超赵德安李长峰
软件导刊 2022年3期
薛金超,赵德安,李长峰,张 军,陈 辉
(1.江苏大学电气信息工程学院,江苏 镇江 212013;2.常州铭赛机器人科技股份有限公司,江苏常州 213164)
0 引言
随着人们生活水平不断提高,手机等电子产品的消费日益俱增,对电子产品质量提出了新的要求。电子产品零部件通常都采用补强胶加固,因此对补强胶进行分割提取,便成为质量检测的关键。传统图像分割算法主要有阈值分割法[1]、边缘分割法[2]等。张启轩等[1]通过设定阈值,利用阈值分割算法将图像中的像素值进行分类。该算法简单、快速,但忽略了图像的空间信息,且易受光照等因素影响分割效果。唐闯[2]通过边缘分割法检测ROI的边界灰度变化,并以此作为分割依据。常用的边缘检测算子有:Roberts[3],Prewitt[4],Sobel[5],Laplace[6],Canny[7]等。Cherri[3]提出的Roberts 边缘检测算子,在处理陡峭的低噪声图像时效果较好,但只能提取图像的粗边缘,定位精度较低。安建尧等[4]使用Prewitt 算子处理灰度渐变和多噪声图像效果显著。Shen 等[5]利用Sobel 算子处理灰度渐变和多噪声的图像效果好,且定位准确。孟小华等[6]利用Laplace 算子可准确定位阶跃性边缘点,对噪声十分敏感,但容易丢失边缘方向信息,造成边缘不连续。Archana 等[7]使用Canny算子可支持同时利用两种不同阈值分别检测强边缘和弱边缘,但在实际检测过程中,仅通过边缘检测仍难以实现高精度分割。
通过以上算法可知,传统边缘检测算法可较为准确地定位边缘,但易受光照等客观因素影响,分割效果不佳。随着深度学习技术不断发展,Unet[8]在分割医学图像等细小等物体上优势明显,被广泛应用于生物医学图像方面,但Unet 和U2net[9]分割速度较慢。现有实时分割网络有ICnet[10]、Enet[11]、LEDnet[12]、CGnet[13]等。ICnet提出了级联特征融合单元可获取高质量的分割图像,同时包含多重分辨率分支的级联网络实现实时分割。LEDnet 使用了不对称“编码—编码”机制实现实时分割,并利用通道分割和融合技术提高分割效率。CGnet 主要由CG 块组成,通过学习局部和上下文特征实现实时语义分割。
上述分割网络算法相较于传统算法,鲁棒性更高,且支持实时分割,但相较于Unet 等网络,分割精度仍然较低。因此,本文提出了一种基于改进Unet 实时分割的fast-Unet语义分割网络模型。
1 网络改进
根据ICnet 设计原理及Unet 自身结构,提出了一种适合分割补强胶的fast-Unet 网络,该网络模型结构如图1 所示。
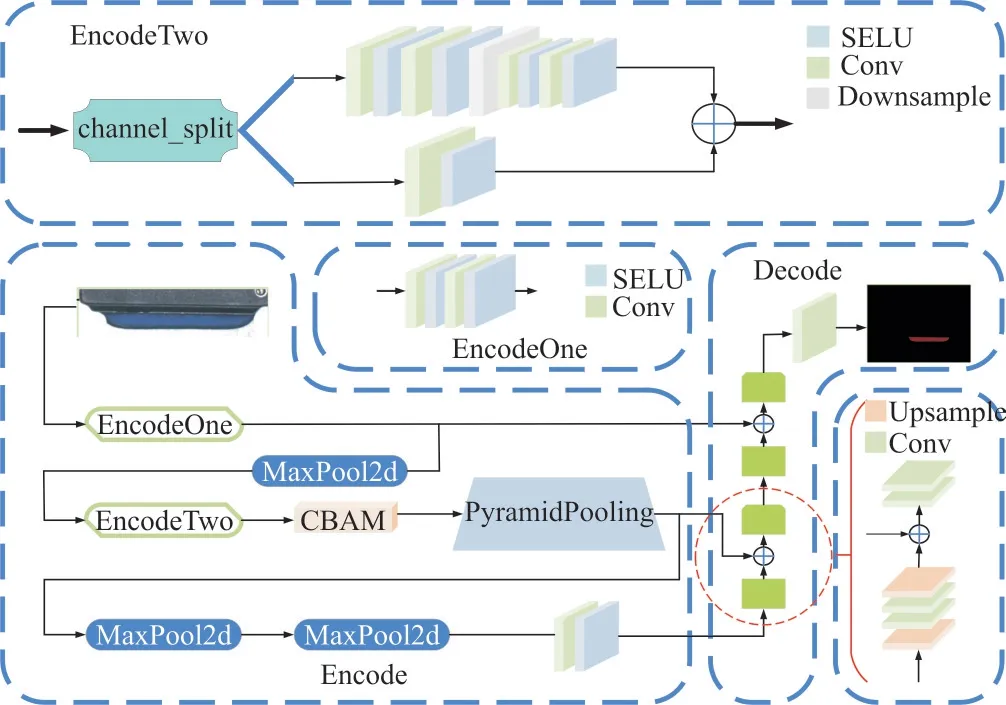
Fig.1 Fast-Unet structure图1 fast-Unet 结构
1.1 注意力模块
注意力模块[14](Convolutional Block Attention Module,CBAM)主要包含通道注意力模块(Channel Attention Module,CAM)和空 间注意力模块(Spatial Attention Module,SAM)。CBAM 依次通过CAM 和SAM 模块推算通道和空间两个不同维度的注意力特征图,再将输入特征图与不同维度的注意力特征图相乘,以细化特征。注意力模块结构图如图2 所示。

Fig.2 Attention module structure图2 注意力模块结构
图2 中所涉及计算公式如式(1)、式(2)所示:
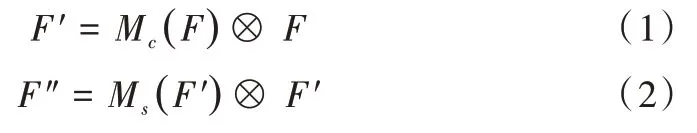
其中,F为输入特征图,Mc(F)为一维通道注意力图,Ms(F′) 为二维空间注意力图,F′为通过通道注意力模块得到的特征图,F″为最终细化输出。

Fig.3 Channel attention module structure图3 通道注意力模块结构
由图3 可见,通过CAM 获得通道注意力特征图时,可使用平均池化方法聚合空间信息,但需要压缩输入特征图的空间维度;或使用最大池化方法细化通道注意力。鉴于此,本文将两种方法相结合。具体为:首先分别得到平均池化特征Fcavg和最大池化特征Fcmax;然后将它们分别通过多层感知机MLP 组成的共享网络得到特征向量;接下来使用element-wise 进行合并;最后使用sigmoid 得到特征图F′,计算公式如公式(3)所示:

其中,σ为sigmoid 激活函数,w代表使用element-wise进行求和合并,M为由MLP 组成的共享网络。
SAM 主要对经过通道注意力后的特征图进行补充,以寻找最具代表特征信息的空间部分。计算公式如公式(4)所示:
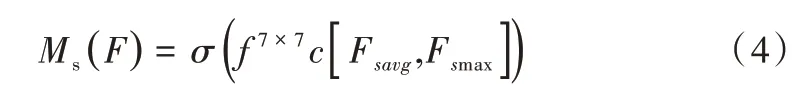
其中,σ为sigmoid 激活函数,f7×7c为7 × 7 卷积运算。
1.2 金字塔池化模块
金字塔池化模块(Pyramid Pooling Module,PPM)[15]分为1× 1、2 × 2、3 × 3、6 × 6 不同大小的4 层。先将输入池化为4 个不同大小的池化层;然后分别使用4 个1× 1的卷积将通道数减少3/4;接着使用双线性采样得到4 个与原特征图大小一致的特征图,并将其与原特征图按通道进行融合;最后使用1× 1 卷积改变通道数,使其与原特征图通道数保持一致。金字塔池化模块结构如图4 所示。
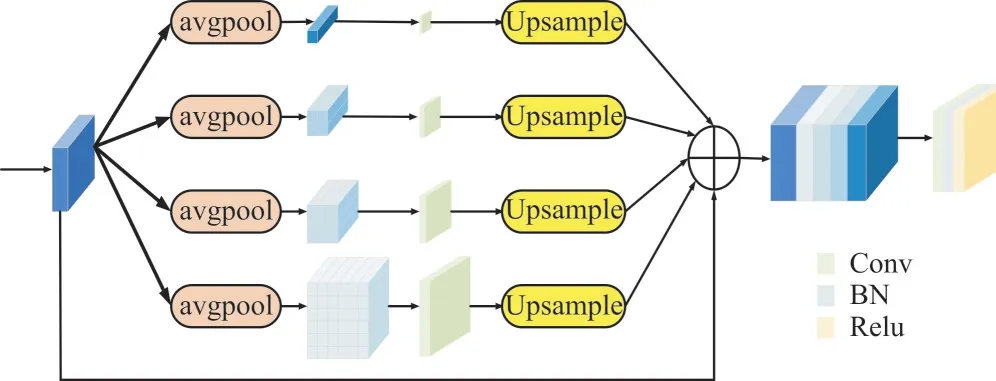
Fig.4 Pyramid pooling module structure图4 金字塔池化模块结构
由图4 可见,PPM 可充分利用全局信息,并保留全局上下文信息,以解决不匹配、类别混淆、易忽视类别等问题。
1.3 激活函数
常用的非线性激活函数有ReLU,该函数计算简单,不但可加快收敛速度,还能缓解梯度爆炸、梯度消失等问题。数学表达式如式(5)所示:

由式(5)可见,一旦激活函数输入值为负数时,激活函数输出值为0。则使神经元失活,并且之后所有的神经元节点都将无法再被激活。
ELU[16]相较于ReLU,负值部分仍有输出值,鲁棒性更高。此外,ELU 激活函数输出值的均值更逼近于0,收敛速度更快。然而为了有效去除噪声的影响,本文使用一种自归一化的激活函数SeLU[17],该激活函数具有自归一化特点,是对特征的高级抽象表示。数学表达式如公式(6)所示:
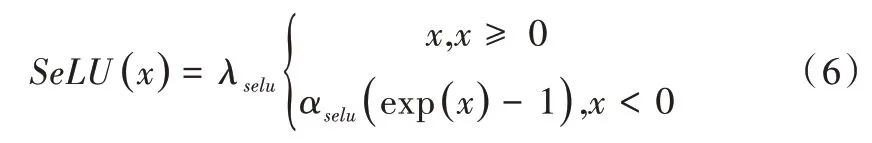
其中,通过实验验证当λselu≈1.673 263 242 354,αselu≈1.050 700 987 355 时,效果较好。
1.4 编码器
目前FCN[18]、Unet、DeepLab[19]等系列的主流语义分割网络,虽然分割性能较好,但无法实现实时快速分割。香港中文大学、腾讯优图及商汤科技联合开发的ICnet 语义分割模型则实现了实时快速分割。ICnet 使用低分辨率图像快速捕捉图像的语义信息,再使用高分辨率图像获取图像细节,并利用获取的主要特征信息优化调整低分辨率分割的语义信息,以提升分割速度和精度。
本文基于ICnet的3 分支输入模式和Unet的特殊结构,提出了一种由3 个特征提取分支组成的编码模块,如图5所示。
由图5 可见,本文提出的编码模块由3 个特征提取分支构成。其中,3 个特征提取分支都使用VGG16[20]作为特征提取主体。ICnet 中3 种输入分别是原图大小、原图1/2大小、原图1/4 大小。输出特征图则分别为原图1/8 大小、原图1/16 大小和原图1/32 大小。而本文编码模块的3 个特征提取分支的输入都为原图大小,仅共享一部分权重,输出特征图为原图大小、原图1/4 大小和原图1/16 大小。
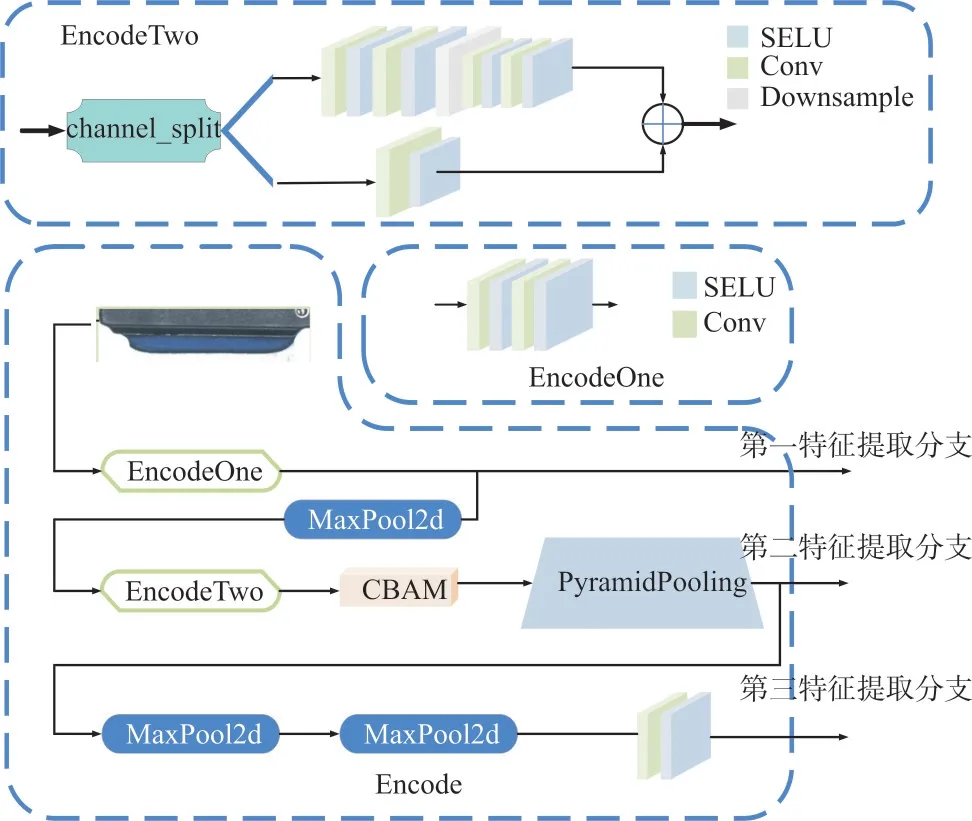
Fig.5 Fast-Unet coding module structure图5 Fast-Unet 编码模块结构
ICnet的加速策略是采用低分辨率特征图提取语义信息,从高分辨率特征图提取特征细节。本文基于ICnet 设计策略进行改进,加入中分辨率特征图,联系高、低分辨率的语义信息和特征细节。
1.4.1 第一特征提取分支
第一特征提取分支由EncodeOne 模块构成。Encode-One 模块改变了VGG16 第一次下采样前特征层结构的原始通道数,并使用SeLU 代替ReLU 激活函数,以提取原始图片大小的特征图。EncodeOne 模块结构卷积参数如表1所示。
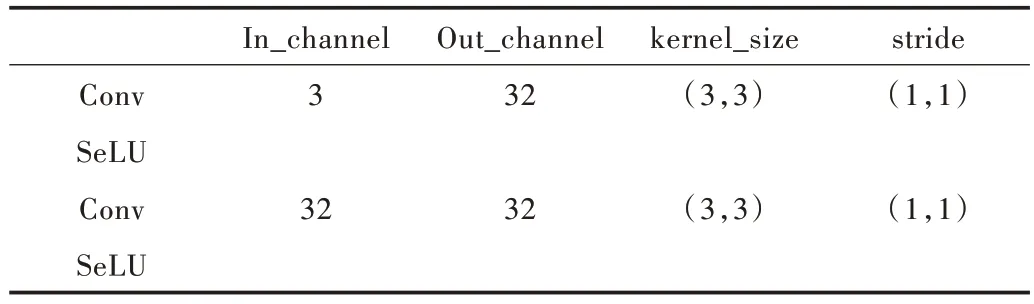
Table 1 EncodeOne module structure convolution parameters表1 EncodeOne 模块结构卷积参数
1.4.2 第二特征提取分支
第二特征提取分支共享第一特征提取分支的权重,并加入了EncodeTwo 模块、CBAM 和PPM。其中,EncodeTwo模块也是由VGG16 改进而来。同样先将通道数减半,再采用channl_split 操作进一步将输入通道数减半,以此提高检测速度。然而,由于EncodeTwo 使用了VGG16的基础结构,通道分割后进行融合时会发生特征图大小不一致的问题。为此,需要在另一个分支中引入一个卷积核为3 × 3、stride 为2的卷积层,使通道分割后的两个分支可进行融合。通过该方法虽然可以提高检测速度,但会导致特征提取能力下降。为此,本文引入SeLU 激活函数代替ReLU 函数,以提高检测效率。EncodeTwo 模块结构如图6 所示。
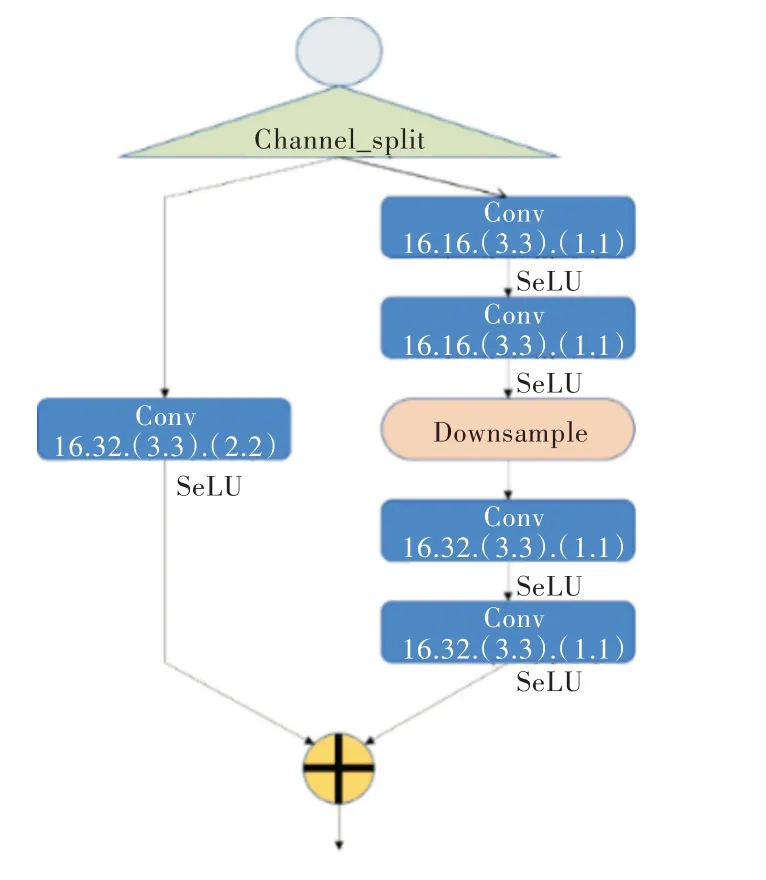
Fig.6 EncodeTwo module structure图6 EncodeTwo 模块结构
由图6 可见,由于第二特征提取分支得到的中分辨率特征图,起到联系高分辨率和中分辨率的语义信息和特征细节的作用。因此提高第二分辨率的特征提取能力至关重要,于是本文在EncodeTwo 模块后引入注意力和金字塔池化模块。
1.4.3 第三特征提取分支
第三特征提取分支主要为了快速获取低分辨率的特征语义信息。这一分支共享了第二分支的网络权重,并且经过两次下采样和一次3×3 卷积,得到原图1/16 大小的特征图,以获取语义信息。
1.5 解码器
解码器采用了Unet的原有结构,并且根据提出的编码器结构进行改进。解码器结构如图7 所示。

Fig.7 Decoder structure图7 解码器结构
由图7 可见,原有Unet 解码器是由一次上采样加两次卷积,堆叠4 次构成,将5 个不同大小的特征层进行融合。而本文将原本需进行4 次堆叠的解码模块进行改进,融合编码网络中的特征层,并将两个解码模块堆叠,构成新的解码器。
2 实验与分析
2.1 实验环境和参数
基于Pytorch 构建深度学习网络,并使用C++、OpenCV、ibtorch 将模型部署到工程上。
本文训练实验参数如表2 所示,检测参数如表3 所示。

Table 2 Training experiment parameter表2 训练参数
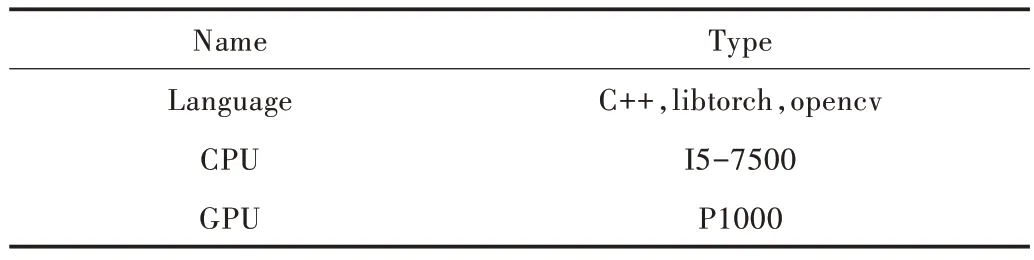
Table 3 Test experiment parameter表3 检测参数
2.2 实验结果与分析
实验评价指标采用平均像素精确度(Mean Pixel Accuracy,MPA)、平均交并比(Mean Intersection over Union,MIoU)、F1_score 及检测速率FPS(包含预处理,前向推理及预测输出)。其中,不同改进Unet 模型训练和验证过程的Train-F1-score如图8所示。
图8 中new_Unet 模型为未加入CBAM 和PPM 模块的fast-Unet;new_Unet_original 为通道数未减半及未加入channel-split的new_Unet模型;new_Unet+CBAM 为加入了CBAM 模块的fast-Unet 模型;new_Unet+PPM为加入了PPM模块的fast-Unet模型;new_Unet+P-PM+CBAM 为先加入PPM模块再加入CBAM 模块的fast-Unet 模型;new_Unet+CBAM +PPM 为先加入CBAM 模块,再加入了PPM 模块的fast-Unet 模型。各改进Unet 模型的Train-F1-score、Val-F1-score 和FPS 如表4 所示。
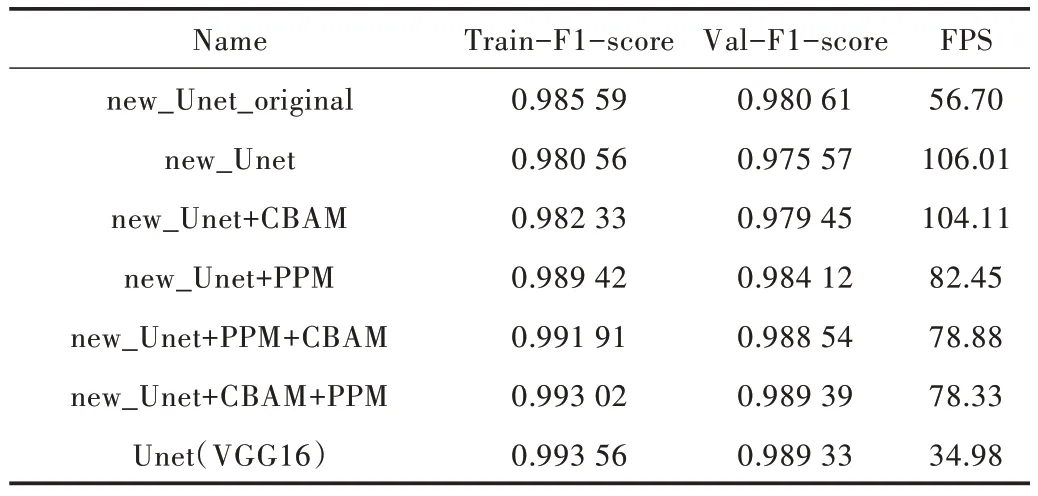
Table 4 Train-F1-score、Val-F1-score and FPS of each improved Unet model表4 各改进Unet 模型的Train-F1-score、Val-F1-score 和FPS

Fig.8 F1-score of different improved Unet model training and verification processes图8 不同改进Unet 模型训练和验证过程的F1-score
由图8 和表4 可见,当new_Unet_original 模型通道数减半并引入channel-split 后,new_Unet 相较于new_Unet_originalFPS 提高了近一倍,但Train-F1-score 下降了0.005;当new_Unet 模型引入CBAM 后,new_Unet+CBAM 相较于new_Unet FPS 和Train_F1-score 变化不明显,但Train-F1-score与Val-F1-score的差值从0.005降到了0.002 8;在new_Unet 基础上引入了PPM 后,虽 然new_Unet+PPM 模型的Train-F1-score相较于new_Unet 提升了0.009,但FPS从106.01下降到82.45,Train-F1-score和Val-F1-score的差值从0.005增加到0.0053;在new_Unet上加入CBAM和PPM后,new_Unet+PPM+CBAM、new_Unet+CBAM+PPM相较于new_Unet,Train-F1-score提高了0.013左右,并且Train-F1-score和Val-F1-score的差值仅为0.003 5 左右,由表4 可见,new_Unet+CBAM+PPM 效果更佳,相较于Unet(VGG16)Train-F1-score 几乎相同,但FPS 从34.98 提高到了78.33。各模型性能指标对比如图9所示,具体数据见表5。
由 图9和表5可见,new_Unet的MIoU和MPA分别为0.9495 和0.956 7,FPS 达到了106.01。fast-Unet(new_Unet+CBAM+PPM)的MIoU 和MPA 最高,相较于new_Unet 分别提高了0.021 1 与0.029 3,但FPS 从106.01 下降到78.33。接下来测试了不同激活函数对fast-Unet 模型性能的影响,结果如图10 所示。训练、验证集上不同激活函数的F1-score 最大值如图11 所示,具体数据见表6。
由图11 和表6 可见,在训练集和验证集上使用ReLU6、LeakRelu、HardSwish 等激活函数的Train-F1-score、Val-F1-score 最大值,相较于使用ReLU 有所下降;使用CELU和SELU 激活函数相较于ReLU 激活函数略有提升。其中,不同的激活函数在测试集上的性能指标如图12 所示,具体数据见表7。
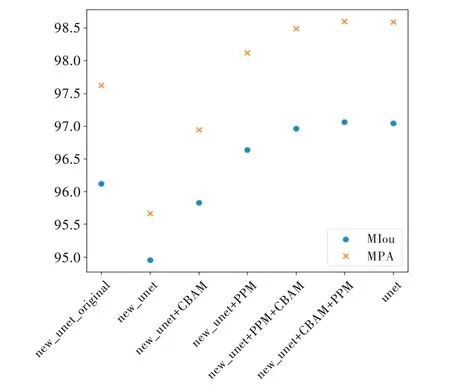
Fig.9 Comparison of performance indexes of each model图9 各模型性能指标对比

Table 5 Comparison data of performance indexes of each model表5 各模型性能指标对比数据

Fig.10 F1-score of fast-Unet under different activation functions图10 Fast-Unet 在不同激活函数下的F1-score

Fig.11 F1-score maximum values of different activation functions on training and validation sets图11 训练、验证集上不同激活函数的F1-score 最大值
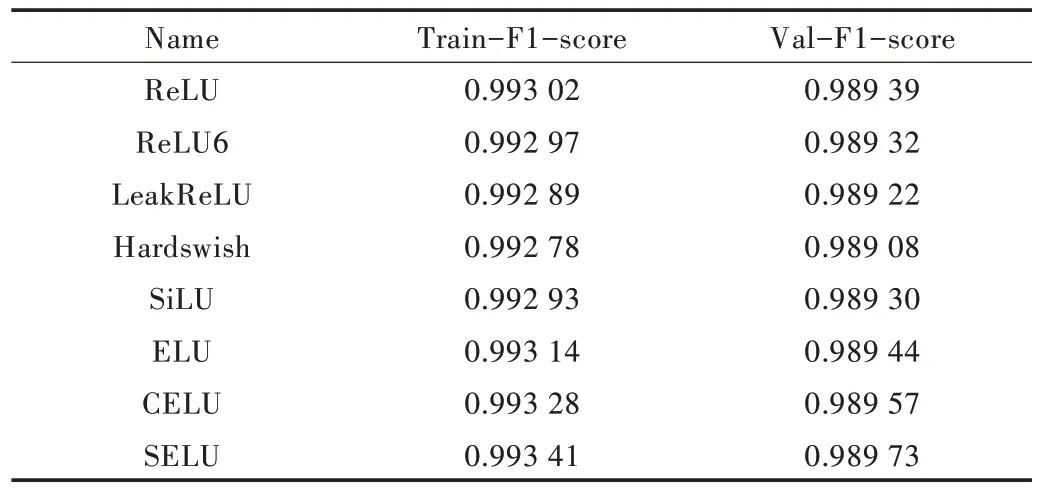
Table 6 F1-score maximum values of different activation functions on training and validation sets表6 训练、验证集上不同激活函数的F1-score 最大值
由图12 和表7 可见,使用SELU 激活函数相较于ReLU函数,MIoU 和MPA 分别从提升了0.000 5 和0.000 6,FPS 只下降了0.27。同时,本文比较了不同模型的性能指标,如表8 所示。

Fig.12 Comparison of performance indexes of different activation functions图12 不同激活函数的性能指标比较
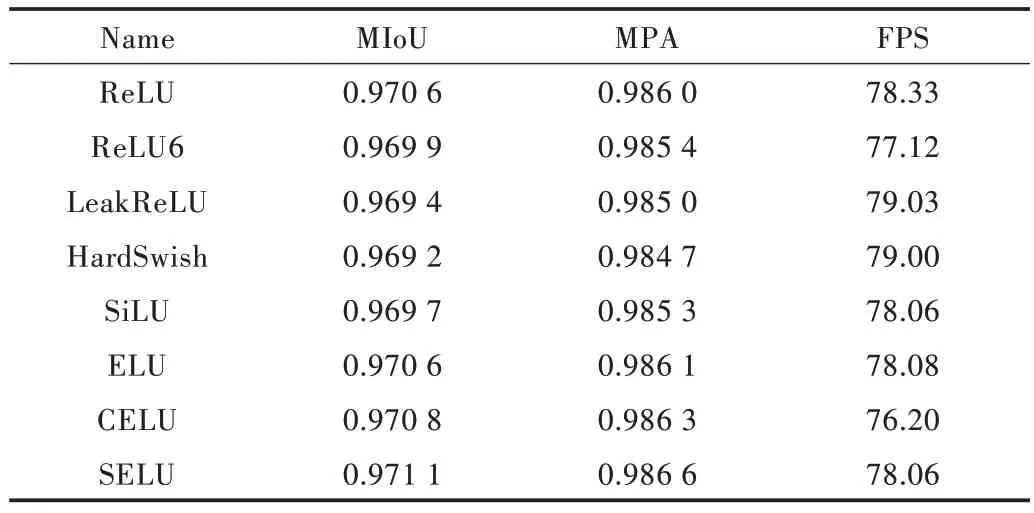
Table 7 Comparison of performance indexe data of different activation functions表7 不同激活函数的性能指标数据比较

Table 8 Comparison of performance index data of different models表8 不同模型性能指标数据比较
通过Pytorch 训练得到的fast-Unet 网络模型后,将其转为支持libtorch 调用的模型。经过实验证明,用P1000 显卡进行在线识别分割单个样本的耗时仅为25ms。实际测试界面如图13 所示。
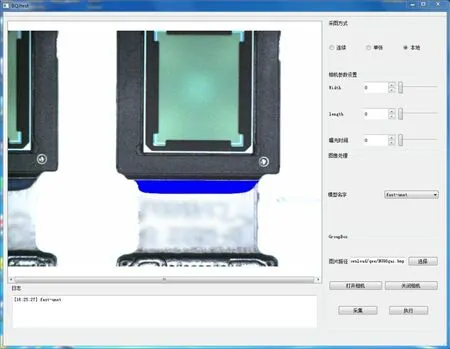
Fig.13 Reinforcing glue colloid on-line detection and segmentation experiment图13 补强胶胶体在线检测分割实验
3 总结
本文针对手机电子零部件上补强胶的识别分割,提出了一种改进Unet的实时分割网络fast-Unet,并引入CBAM和PPM 增强网络的鲁棒性。通过实验表明,该网络的识别精度和FPS 均高于Unet,取得了较好的识别分割效果,MIoU、MPA 和FPS 分别达到了0.971 1、0.986 6 和78.06。此外,当使用P1000 显卡进行测试时,单个样本识别分割耗时仅为25ms。但由于在识别分割后,仍需进行胶体测量,下一步将研究在识别分割后量化胶体长、宽等信息。
猜你喜欢
学生天地(2019年28期)2019-08-25
电子制作(2018年19期)2018-11-14
数学物理学报(2018年1期)2018-03-26
数位时尚(幼儿教育)(2017年12期)2018-01-05
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
测绘科学与工程(2014年6期)2014-02-27
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
疯狂英语·口语版(2013年1期)2013-01-31
电讯技术(2010年8期)2010-08-08
