
多尺度聚合GAN的未标定光度立体视觉
2022-03-25 04:45孙晓明
软件导刊 2022年3期
任 磊,孙晓明
(浙江理工大学信息学院,浙江 杭州 310018)
0 引言
近年来随着计算机视觉技术的发展,许多基于图像的计算机应用技术应运而生,如:车牌识别、人脸识别、三维图像重建等,计算机处理数据图像的结果将直接影响到这些应用的精准度。非朗伯体三维信息的获取对于从图像恢复物体空间形状具有重要意义,一般采用两种方法进行相关信息的获取:多视角三维重建与光度立体视觉。前者利用摄影设备采集多张场景图像来恢复三维几何结构,该方法几何结构的重建精度高,但局部细节存在偏差;后者利用场景内的光度信息(光照方向/强度等)恢复场景表面的法向图,并通过法向图恢复三维几何结构。相比于多视角方法,光度立体视觉方法虽然重建精度略低,但可获得更详尽的局部细节。
非朗伯体的光度立体视觉技术大致可分为4 类,即基于离群值抑制、基于复杂反射率模型、基于参照物以及基于深度学习的光度立体视觉技术。基于离群值抑制的方法[1-2]假设非朗伯观测值是局部且稀疏的,可被视为离群值。异常值的剔除往往需要大量输入数据,并且在处理密集的非朗伯体对象时比较困难(如存在高光)。许多复杂的反射率模型被用于近似代替非朗伯体模型,包括Torrance-Sparrow 模型[3]、Ward 模型[4]等。这些方法不但需要解决复杂的优化问题,而且处理材料种类有限。基于参照物的光度立体法[5]通常需要额外的参考对象,该类方法虽然可在光线方向未知的情况下处理存在空间变化的BDRF对象,但由于对参照物形状和材料的要求,限制了其应用前景。近年来,随着深度学习在各个计算机视觉任务中取得了巨大成功,基于深度学习的方法也被引入到标定的光度立体视觉中[6-9]。其不是通过构造复杂的反射率模型,而是直接学习从给定方向的反射率观测结果到法向信息的映射。
传统的光度立体视觉方法大多假设一个简化的反射率模型(理想的朗伯模型或简易反射率模型),然而现实物体大多数都是非朗伯体,且一种特定的简易模型也只对一小部分材料有效。同时,光源信息的标定也是一个复杂且繁琐的过程。研究人员希望可仅通过固定视点下的多幅图像直接计算图像法向信息,这就是未标定的光度立体视觉技术[10-13]。Chen 等[6]引入UPS-FCN 网络,这是一个单级模型,可从已进行归一化处理且已知光照强度的图像中回归出物体表面法向信息,但全卷积网络在提取特征时感受野太小,无法获取全局信息,且计算效率低下,算法鲁棒性不强,其性能远落后于标定的PS-FCN 方法[6]。
近年来,生成对抗网络(GAN)在计算机视觉、图像处理等多个领域展现出良好性能[14-16]。本文旨在进一步提高未标定光度立体视觉技术法向估计的精确度,因此提出多尺度聚合的生成对抗网络,能够有效解决图像尺寸变化及输入数量变化的问题。多尺度聚合使每张图像局部特征与全局特征经过最大池化能更好地聚合在一起,生成的法向信息图比基于全卷积算法生成的图像更加准确。为进一步提高生成法向信息的精确性,本文采用微调模块使法向信息图在生成细节上更为精确,同时在处理局部细节较光滑的非朗伯体上展现出更好的训练效果。通过多项消融实验,证明了该设计结构的有效性与通用性。在公共数据集上的平均角度误差为14.1°,相比UPS-FCN的结果下降了1.92°,MSE 误差为9.15%,相比UPS-FCN 下降了1.43%,模型具有更强的鲁棒性,同时在处理局部细节比较光滑的非朗伯体上展现了最优的训练效果。
1 光度立体技术原理
光度立体视觉是一种在同一视点、不同光源方向下,通过拍摄同一物体的多幅图像恢复出物体表面法向信息的技术。在理想的朗伯体条件下,常用的求解过程为:①建立光照模型;②标定光源信息;③求解表面法向信息;④求解深度信息。然而,现实世界中绝大多数物体都是由漫反射与镜面反射材质组合而成的。
1980 年,Woodham[17]在假设场景反射为理想朗伯模型的情况下提出经典的光度立体视觉技术,该问题建立在平行光源的条件下,即光照方向为已知的标量,光源在各方向上辐射均匀。亮度公式可简化为:

其中,Ijk代表图像j上第k点的亮度值,ρk为对应k点的漫反射系数,nk为该点法向量方向,而对应的光照方向lj已知,因此k点亮度值只取决于ρk和nk。在一个拥有M 个光源的系统中,光照方向矩阵可记为L=(l1,l2,…,lM)∈R3×M,某点的亮度向量记为I=(i1,i2,…,iM)∈RM,可得到式(1)的矩阵形式:
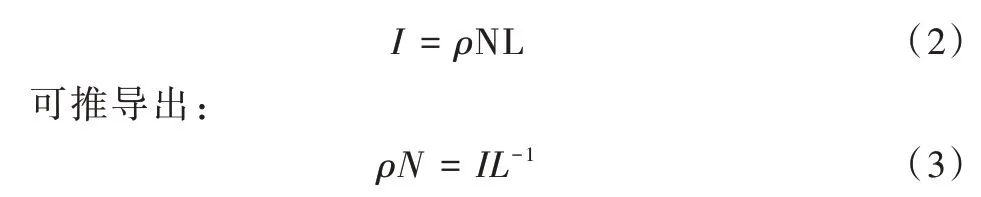
对于已进行归一化处理的法向信息N=(nx,ny,nz),其自由度为2,漫反射系数ρ未知。所以为求出最终法向,至少要求方向矩阵L的秩为3,即取3 处不共线的光照方向,才可以通过最小二乘得到未经过归一化处理的法向n^,如式(4)所示。
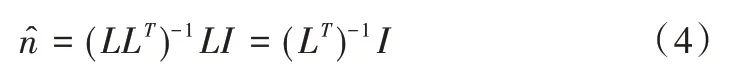
2 多尺度聚合生成对抗网络模型
2.1 网络结构
未标定光度立体的网络结构如图1 所示。为获得更精确的法向信息,生成器由两个分支组成:多尺度聚合网络(MUPS)与微调模块。多尺度聚合网络是从任意数量的输入图像中学习法向信息之间的映射,利用多尺度聚合使局部特征与全局特征更好地融合,通过最大池化结构对多个输入特征进行聚合,最后经过归一化层得到法向信息。
采用跳跃连接以达到多尺度特征聚合的目的在于,求解一个物体的表面法向信息是由多个因素决定的,单一观测的特征图中显然不能提供足够多的信息解决噪声模糊性等问题。对于每一个图像观测到的特征图,采用多尺度特征聚合以实现局部与全局特征更好地融合,从而在每张图中观测到更全面的信息。对于光度立体多输入的特性而言,最后利用最大池化方法对多个特征进行聚合,以解决传统卷积网络固定输入的问题。最大池化可以很自然地从不同光线方向捕捉到图像中的强特征(如对于一个表面存在高光的点,其法线靠近视点平分线与光照方向),此外最大池化在训练过程中可轻松忽略掉非激活的特性,使网络具有更强的鲁棒性。将池化后的特征进行L2 归一化处理,得到粗粒度的法向信息图。微调模块的作用是将粗精准度的法向图微调生成更高精度的结果图,其由4 个残差块组成。由于为提高网络性能而加深网络结构会导致网络优化困难与训练困难,因此本文采用残差结构。
(1)多尺度聚合网络基于U-Net 网络,并利用了卷积神经网络的属性(如平移不变性和参数共享)。网络由多个卷积模块与反卷积模块组成,最开始经过4 个卷积核大小为3×3、步长为1的卷积层,每一次卷积过后经过Leaky Re-LU 激活层并进行正则化处理,再通过步长为2的平均池化层,达到下采样目的。另一部分由3 个反卷积层与卷积层组成,通过卷积核大小为4×4、步长为2的反卷积层,再通过与对应下采样部分的特征图进行特征融合后,送入卷积层中。最后将得到的结果进行最大池化与归一化处理得到最终结果。
(2)微调模块网络由4 个残差块和1 个卷积层以及归一化层组成。理论上,网络模型越复杂,网络层数越深,意味着网络拟合能力越强,但在实际训练过程中常常会出现增加网络层后模型训练效果反而变差的情况。这是因为随着网络层级的增加,容易出现梯度消失现象。为此,He等[18]提出一种残差结构,通过跳跃连接的方式使该问题得到很好地解决。经过残差块后,特征图的宽度/高度恒定不变,最后经过卷积层与归一化层输出生成的法向信息图。
(3)针对判别器模型,本文借鉴PatchGAN[16],判别器D的输入为生成器G 生成的法向信息图与真实的法向信息图。经过多个卷积层提取输入特征后,最终输出16 组数值范围在[0,1]之间的评测值,求均值后得到该图为真实法向信息图的概率。
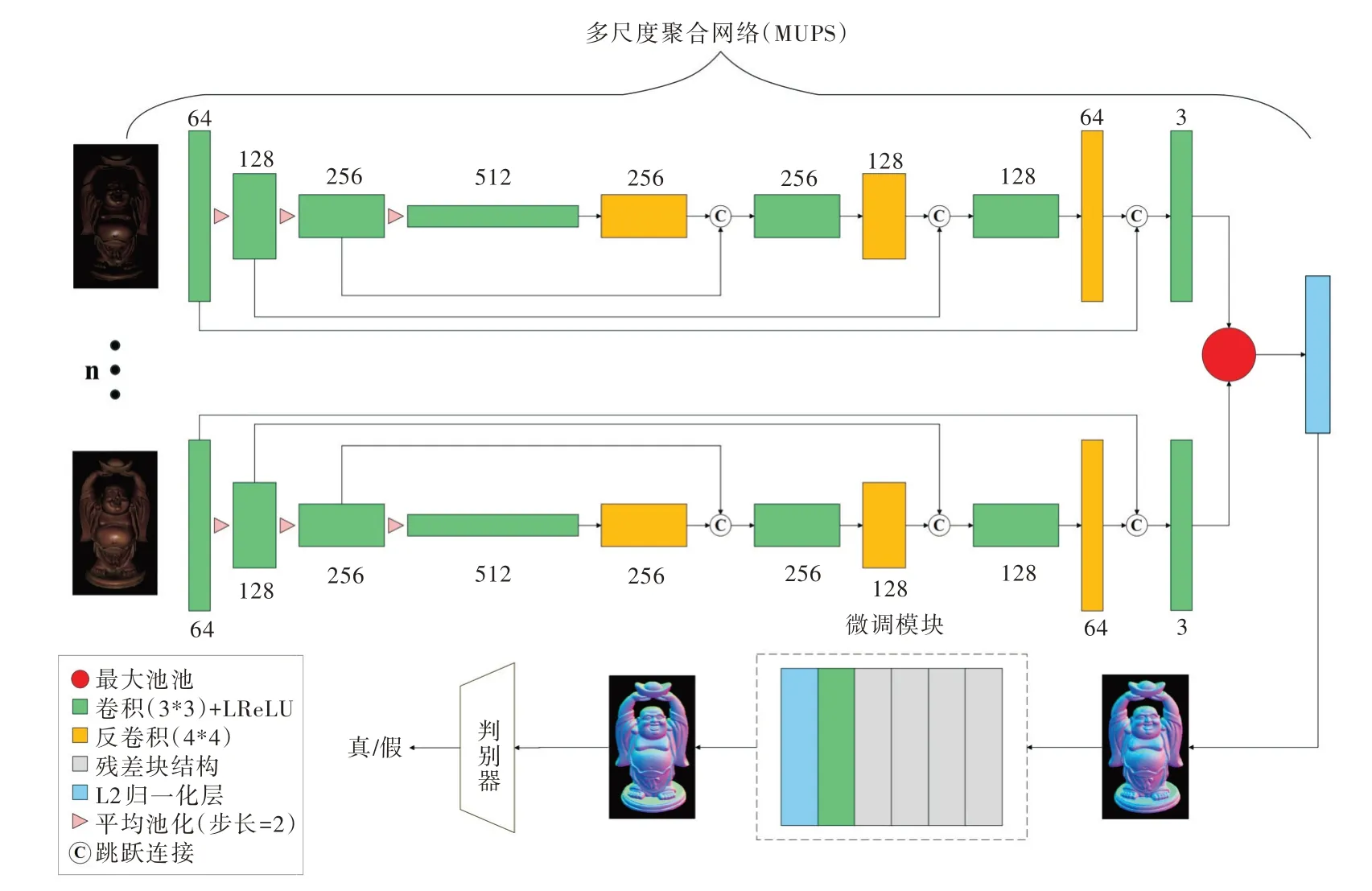
Fig.1 Network structure图1 网络结构
2.2 损失函数
生成器模型的损失函数LG由两部分组成,分别是对抗损失Lgen与法向量的余弦相似度损失Lnormal,如式(5)所示。其中λ1=1,λ2=0.01。

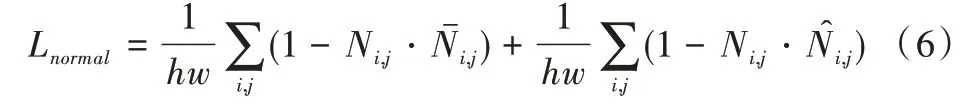
其中,Ni,j表示点(i,j)处的真实法向信息,如果真实的法向信息与预测的法向信息相差很小,则Ni,j与点乘值接近于1,Lnormal值会很小,反之亦然。本文对于生成器对抗损失定义如下:
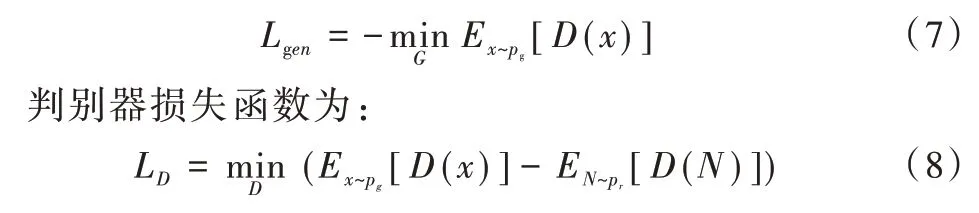
其中,x~pg表示输入数据x符合pg分布,N~pr表示真实法向信息N符合pr分布。
2.3 算法流程与训练细节
实验中,UPS-MRGAN 是在Pytroch的框架中实现的。在网络训练过程中,所有批处理归一化与Leaky ReLU 操作都使用共享的超参数,设置批归一化衰减率为0.9,以及Leaky ReLU 中的α为0.02。本文采用两个阶段进行训练,在第一阶段单独训练MUPS,使用Adam 优化器进行优化(β1=0.9,β2=0.99),设置初始学习率为10-5。MUPS 训练10 个批次后,被训练成可通过任意数量的输入图像得到粗粒度的法向信息图。在第二阶段,将MUPS 网络与微调模块作为生成器,同时训练生成器与判别器。生成器参数与第一阶段中的参数相同,共进行20 次迭代,在每一次迭代中对生成器与判别器网络交替进行优化。
UPS-MRGAN 模型具体训练方法如下:
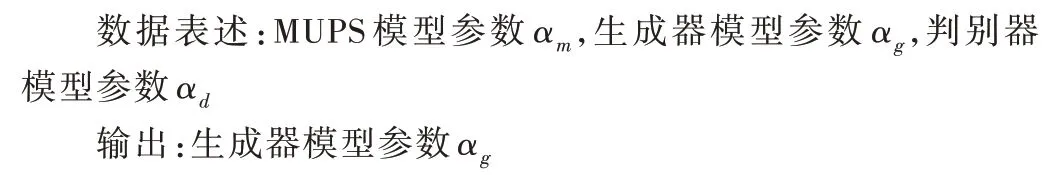

3 实验结果与分析
3.1 数据集
网络的数据集由Chen 等[6]提供,其中训练集和验证集包括合成数据集Blobby 与Sculptrue,而测试集采用DiLigent 数据集[19],其常被作为公共标准数据集使用。Blobby、Sculpture 共包含112 212 个样本数据,其中每个样本又包含64 张大小为128×128的光度图像及对应法向信息。DiLigent 数据集中包括多种非朗伯体,每个物体包括96 张光度图像与真实的法向信息。
将合成的两个数据集按照9∶1的比例分成训练集与验证集,为进一步提高网络拟合性能,在训练过程中进行实时的数据增强:随机将图像宽/高比缩放到[32,128]范围内,之后随机裁剪成大小为32 × 32的图像块进行训练。最后,本文以32 张图像作为一个批次进行训练与测试。
3.2 定性与定量比较
本文对于光度立体视觉技术生成的法向信息图采用的评价标准是平均角度误差(Mean Angular Error,MAE)与均方误差MSE。为验证本文算法的有效性及公平性,在DiLigent 数据集上与传统的未标定算法WT13[20]、LC18[13]、PF14[21]以及基于深度学习的UPS-FCN[6]进行比较,结果如图2 所示,其中本文方法为红线部分。
由图2 可知,本文算法的综合MAE 达到最低,比UPSFCN 降低了1.92%。本文算法处理的pot2、buddah、reading、cow 以及harvest 数据相比其他算法获得了更好的效果,而ball、cat、pot1、bear 以 及goblet数据得到的MAE结果都比UPS-FCN低1%~2%。同时,本文算法在处理局部细节比较光滑的非朗伯体pot2 时结果比之前的最优算法还低2%。本文算法优于UPS-FCN的原因在于:①多尺度聚合能更好地使多张图像的局部特征与全局特征融合;②微调模块通过残差网络可在生成的法向信息图基础上进一步改善生成细节;③生成对抗网络相较于卷积神经网络,在生成类任务上,其对抗损失有助于在训练网络时跳出局部最优解,从而实现新的最优解。
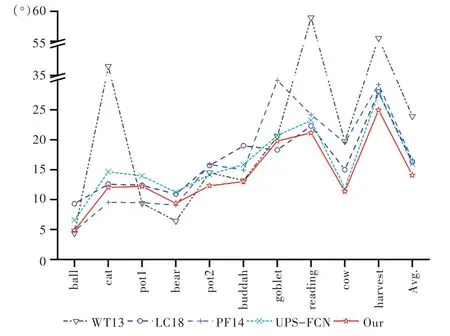
Fig.2 Comparison of MAE values of each method图2 各算法平均角度误差值比较
同时为进一步评估真实法向信息与估计法向信息之间的差异,同样在DiLigent 数据集上测算各种方法的MSE误差,如表1 所示。通过比较发现,本文算法在多个非朗伯体上的MSE 最小。相较于UPS-FCN 算法,MSE 下降了1.43%,其中pot2、buddah、goblet、reading、cow 以及harvest 都比最优算法下降了多个百分点,虽然在ball、cat、pot1、bear数据上没有达到最佳效果,但重建的法向信息误差也优于其他算法。通过两个定量实验数据对比可以发现,本文算法在非朗伯体材料的未标定光度立体视觉研究中取得了不错的效果。
最后,将本文算法与UPS-FCN 进行定性分析,结果如图3 所示。其中,GT Normal 列代表真实的法向信息,2、3 列分别为UPS-FCN 生成法向图与真实法向图之间的误差图,4、5 列为本文算法得到的法向图及其误差图。其中,低误差表现为蓝色,高误差表现为红色。定性与定量分析结果表明,本文算法使得未标定的光度立体求法向图的效果得到进一步改善。

Table 1 MSE error comparison of various methods on DiLigent dataset表1 在DiLigent 数据集上各种方法的MSE 误差比较

Fig.3 Comparison of error visualization of the proposed algorithm and UPS-FCN algorithm图3 本文算法与UPS-FCN 算法误差可视化比较
3.3 消融实验
为验证损失函数与网格结构的有效性,本文将UPSMRGAN 与其消融版本进行比较:
(1)w/o Res:代表移除微调模块。残差结构的移除将网络重新蜕变成单阶段的网络,相应损失函数Lnormal的结构也发生了变化。
(2)w/o MS:代表移除多尺度聚合。将结构中的跳跃连接移除,退化成简单的卷积神经网络。
(3)w/oLD:代表移除判别器,不采用生成对抗模式进行训练。
(4)w/oLnormal:代表移除余弦相似度损失函数。移除后,两阶段训练也变成了单阶段训练,生成器的损失函数仅为对抗损失。
本章对上述模型进行训练,最后针对DiLigent 数据集进行定量与定性分析。消融实验的定量实验结果如表2 所示。

Table 2 MAE value of ablation test results表2 消融实验结果的MAE 值
选取两个单独对象与整个数据集综合的MAE 值,定性结果选取其中一个对象,消融实验对比结果如图4 所示,其中上部分为生成的法向图,下部分为与真值(Groundtruth)进行比较的误差图。实验结果表明,完整的网络模型可获得最佳性能。如图4(a)所示,当移除了微调模块,法向信息图的狭缝区域会产生伪影,表明微调模块通过残差块从细节中微调了法向信息,使得结果更为精确。

Fig.4 Comparison results of ablation experiments图4 消融实验对比结果
为进一步验证其作用,本文重新训练了一个网络UPSFCN+Res,将本文训练的微调模块添加到UPS-FCN 网络中,如表3 所示。通过对比发现,微调模块同样可提高UPS-FCN 网络估计法向信息的精度值。当缺少对抗训练时,生成器由于尚未完全收敛,通常会产生一些较大的细节错误,这是因为对抗训练可加快生成器的收敛速度,使得模型性能更优。当缺少了多尺度融合时,相较于完整模型,MAE 值上升了1%,而且在处理具有明显凹陷区域的harvest 时效果最差,这是由于局部特征无法更全面地学习到法向信息。
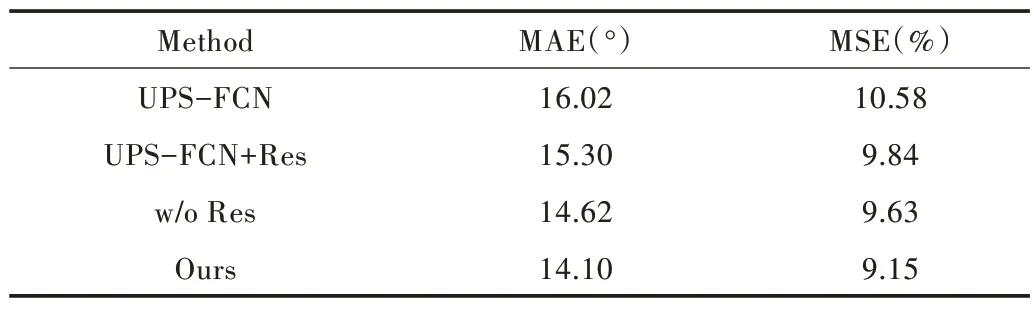
Table 3 Impact of Res module on the network表3 Res 模块对网络的影响
同时,本文的全损失函数也达到了最佳性能。如图4(d)与表2 所示,Lnormal可保持像素级别差异的最小化,缺省后物体的法向信息会产生较为模糊的效果。
4 结语
光度立体技术对于恢复非朗伯空间形状具有重要意义。本文基于生成对抗网络进行模型搭建,通过MUPS 网络、微调模块及生成对抗模块进行训练。实验结果证明,该方法可实现更高精度的法向信息图,在处理局部细节比较光滑的非朗伯体上也展现出良好的训练效果。但是,本文是从图像中直接提取特征学习法向信息图的映射,而忽略了光源信息的重要性。因此,下一阶段的工作是通过图像学习到光源信息的映射后,再学习其与法向信息图之间的映射。此外,未来还将充分考虑处理多种混合材质的问题,以进一步提升光度立体算法的泛化性能。
猜你喜欢
水文地质工程地质(2022年2期)2022-04-13
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
汽车电器(2019年1期)2019-03-21
北京航空航天大学学报(2018年1期)2018-04-20
光学精密工程(2016年1期)2016-11-07
光谱学与光谱分析(2016年5期)2016-07-12
中国铁道科学(2015年4期)2015-06-21
河南科技(2015年8期)2015-03-11
实验技术与管理(2014年12期)2014-03-11
