
知识图谱问答研究进展
2022-03-25 04:45王月春郝晓慧王会勇
软件导刊 2022年3期
论 兵,王月春,郝晓慧,2,谷 斌,王会勇
(1.石家庄邮电职业技术学院计算机系;2.中国邮政集团公司人才测评中心;3.河北科技大学信息科学与工程学院,河北石家庄 050000)
0 引言
问答系统(Question Answering System,QA)是利用自然语言处理技术对自然语言问句进行自动分析,并准确回复答案的智能系统。近年来,随着信息技术的飞速发展,现实世界中的信息量呈指数式增长,传统依赖大量规则或模板的问答系统已无法满足人们的实际需求。为了解决传统基于语义解析的方法中存在的问题,研究者们逐渐将研究兴趣从语义解析转移到信息检索中。基于信息检索的问答系统依靠关键词匹配和信息提取分析浅层语义,并从相关网页或文档中提取相关知识,从而实现自然语言问句回答。这种方法需要问答系统预先设置问题答案,因此无法实现开放领域的问答。
随着语义网(Semantic Web)、知识图谱(Knowledge Graph,KG)和信息检索技术的快速发展,一大批高质量的知识图谱被推出,如YAGO[1]、DBpedia[2]和Freebase[3]。知识图谱将现实世界中的知识以网状的形式进行存储,被广泛应用于医疗[4]、金融[5]、军事[6]等领域,并取得了较为显著的效果。基于知识图谱的问答系统(Knowledge Graph Question Answering,KGQA)根据知识图谱内部存在的大量实体间的直接关系,挖掘并推理隐藏关系[7]。与传统基于信息检索的问答系统相比,KGQA 可以在知识图谱的基础上争取理解用户问题的语义,并通过实体检索、关系推理,最终反馈最准确的答案。本文对近年来提出的知识图谱问答技术进行追踪和整理,为更多知识图谱问答研究者提供参考信息。
1 背景知识
1.1 问答系统
问答系统作为人工智能中的一个关键领域[8],其能够快速回答用户利用自然语句提出的问题,是信息检索和人工智能的交叉研究方向。早在人工智能出现早期,阿兰·图灵就提出了经典的图灵测试,以验证机器是否具有类人智能。在之后的数十年间,伴随着人工智能技术的兴衰,一大批具有代表性的问答系统不断涌现。1966 年,Weizenbaum 设计并实现了ELIZA 聊天机器人[9],其能够处理简单的问题语句。公认最早应用于现实生活的问答系统是Baseball 系统,仅能限定性地回答棒球领域的基础问题。随后Colby 设计的PARRY 聊天机器人[10]在利用ELIZA 规则的基础上,添加了自己的情感,成为第一个通过图灵测试的聊天系统。这些基于规则匹配的问答系统受限于当时匮乏的数据资源,不能得到大规模应用。
随着深度学习和自然语言处理技术的快速发展,问答系统逐渐从早期的规则匹配过渡到检索匹配[11]。其核心思想是通过提取自然语言问句中的核心词,之后根据问题核心词在文档或网页中搜索相关答案内容,并利用相关排序算法返回对应答案。Ma 等[12]基于文档自动检索的方法提出伪相关反馈算法,该方法利用文档中的上下文信息检索最相似的答案。基于检索的方法在提出之初取得了较好效果,但随着数据量激增、用户问题多样性及自然语言复杂性等问题的出现,基于检索匹配的问答系统从文档或网页中抽取的答案质量参差不齐,严重影响了系统的响应时间和答案的准确性。
直至知识图谱、知识库等概念的提出,问答系统利用知识图谱内存在的大量结构化知识和计算机强大的算力,从根本上解决了前两种问答系统的不足,实现了问答系统从文档形式的问答转变为基于知识图谱的问答,且越来越受到研究者的重点关注,成为自然语言处理领域的热点[13]。
1.2 知识图谱
2012 年,Google 首次提出知识图谱概念,并将其应用于改善传统搜索引擎的能力。知识图谱将现实世界中的知识以三元组(实体—关系—实体或概念—属性—值)的形式进行组织,形成了一个多边关系网络,其本质是一种语义网络,可揭示实体间的相互关系。图1 展示了一个简单的知识图谱示例,其中节点表示实体或概念,连接节点的边表示实体间的关系或概念的属性。根据知识覆盖领域不同,知识图谱可简单分为通用领域知识图谱(如:Wikidata[14]、DBpedia、CN-DBpedia[15]、Freebase 等)和特定领域知识图谱(如:阿里商品图谱[16]、美团美食图谱[17]、AMiner[18])。传统知识图谱构建方法包括实体识别[19]、实体消歧[20]、关系抽取[21]和知识存储等。

Fig.1 Simple example of knowledge graph图1 知识图谱简单示例
随着深度学习的出现和快速发展,知识图谱也逐渐由“符号”连接转变为“向量”表示。Boards 等[22]提出的TransE模型将知识图谱中的实体和关系嵌入到低维向量语义空间,把关系向量视为头实体向量到尾实体向量的一种翻译;Lin 等[23]提出的TransR/CTransR 为每个关系设置一个独有的关系矩阵空间Mr,并将实体和关系通过Mr矩阵嵌入到向量语义空间中进行翻译计算。基于知识表示学习的知识图谱构建方法从根本上解决了传统知识图谱构建方法带来的长尾效应,极大提高了知识图谱的可用性。
2 知识图谱问答主要方法
KGQA的关键问题是如何将自然语言问题转换为计算机可以理解的形式语言,并在构建好的KG 内通过查询、推理获得问题答案,其本质是自然语言处理的问题。现有KGQA的主要方法大致可以分为:基于语义解析的方法(Semantic Parsing-based Method)、基于信息检索的方法(Information Retrieval-based Method)、基于知识嵌入的方法(Knowledge Embedding-based Method)。图2 展示了上述3种方法的主要工作流程。其中,基于语义解析方法的核心思想是将自然问答语句解析为SPARQL 查询语句,并以此获取答案核心词实现问题的回答;基于信息检索方法的核心思想是将自然语言语句进行识别和抽取,构建知识图谱查询子图,并以此从知识图谱内获取最优结果;基于知识嵌入方法的核心思想是将知识图谱和自然问句嵌入到低维空间中进行向量计算以获取最优结果,从而实现知识问答。
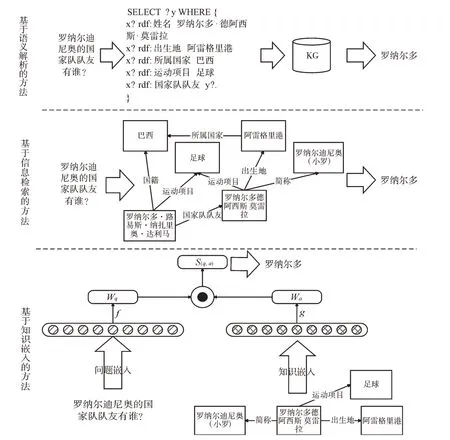
Fig.2 Main methods of knowledge graph question answering图2 知识图谱问答主要方法
2.1 基于语义解析的方法
基于语义解析方法的KGQA 主要是将非结构化的自然语言转换为一系列的逻辑表达式,并将拼接后的逻辑表达式放入知识图谱中,查询问题的最终答案。这种基于语义解析的方法对问题答案的可解释性较高,能够解释KGQA系统答案的来源。基于语义解析的方法主要包括直接映射和神经网络两种。
2.1.1 直接映射方法
直接映射方法主要采用语义解析语法工具完成逻辑表达式构建。Steedman[24]提出的组合范畴语法(Combinatory Categorial Grammar,CCG)使用词汇表完成问句到逻辑表达式的转化,并通过排序算法选择最佳逻辑表达式;Artizi 等[25]将CCG语义类型部分中的λ-算子替换为AMR(Abstract Meaning Representation),从而提升了语义解析效果;Berant 等[26]将CCG 语义解析直接融入KGQA 中,解决了传统语义解析器需要大量人工标注的词汇表问题。基于CCG 语法的语义解析方法具有很强的可解释性,同时结构也较为清晰,在特定领域取得了较为出色的效果,但面对大规模通用知识图谱时该方法使语义歧义问题更加凸显。
Reddy 等[27]对自然语言问题语句进行分析,将传统直接映射方法分析问句的依存解析树转为构建自然语言问句所对应的知识图谱子图,并将子图映射到知识图谱中,利用图匹配方法实现问题回答;Hao 等[28]将自然语句解析为复杂的知识图谱子图,从而实现复杂问题回答,且模型效果较为出色;孟明明等[29]设计一种语义查询拓展方法解决从数据源中难以获得理想答案的问题,该方法对问题三元组中的查询术语从3 个语义角度进行拓展,实现了对问题三元组的多语义拓展;Hu 等[30]认为基于语义解析方法的知识图谱问答大致分为问题理解和查询评分两个阶段,难点在于解决问题理解阶段中的歧义性问题,即解决短语链接问题和复合问题。为此,他们提出一种基于图匹配的方法,该方法将解决歧义问题与查询评分两个阶段进行融合,并提出关系优先(relation-first)和节点优先(node-first)的方法,relation-first 方法尽可能地抽取对应关系,并根据句法树中识别出的实体构建查询图,node-first 方法则从自然语言问句中抽取对应的实体,再对实体间的关系进行填充以构建查询图。这种方法不需要人工定义逻辑表达式模板,且对复杂问题解析非常有效。Dhandapani 等[31]认为直接将问题转化为三元组的方法无法获取问题中的语义信息,为此他们提出一种基于问题类型分类的模板匹配方法,该方法对问题类型进行分类,并为每种类型找到最合适的SPARQL 查询模板。该方法在QALD-8 数据集上表现出较好的优越性。
直接映射方法可以较为清晰地将自然语言问题语句转换为逻辑表达式,但该方法需要人工定义大量的逻辑表达规则,在特定领域内表现尚佳,而在面对大规模知识图谱时无法实现未定义规则的转化,造成通用性较差。
2.1.2 神经网络方法
为了解决直接映射方法无法处理未定义规则转化问题,研究者受到机器翻译中编码器—解码器结构网络(Sequence-to-Sequence,Seq2Seq)思想启发,提出神经网络方法。基于神经网络方法的语义解析模型将自然语言问句翻译成逻辑表达式,并将翻译后的逻辑表达式放入知识图谱中实现问题回答。
Dong 等[32]提出一种基于注意力增强机制的编码—解码(Encoder-Decoder)方法,从而将语义解析问题转换为翻译问题。具体而言,他们设计了Seq2Seq 模型和Seq2Tree模型。其中,Seq2Seq 模型将语义解析视为序列转换的一种任务,Seq2Tree 模型配备了分层树解码器,可以清晰地捕获用于翻译后的逻辑表达式。Dong 等[32]的方法主要关注的是解码器部分,而Xiao 等[33]认为编码器对语义解析非常重要。为此,他们将符号先验知识引入RNN 模型中,从而实现语义解析。在Xiao 等[33]的基础上,Xu 等[34]使用图编码器(Graph2Seq)对语义图进行编码,之后将注意力机制引入RNN 模型对编码结果进行解码,以获得逻辑表达式;Cao等[35]为了更好地对问题与知识图谱Schema 以及Schema 内部关系进行建模,提出一种结合线性有向图和普通有向图的Text2SQL 模型。该模型通过引入线性有向图,在简化问题子图的同时突出实体间的关系,同时该模型还设计了问题子图修剪的辅助任务,从而对局部图特征和非局部图特征进行区分。Cao 等[35]在Spider 数据集上测试了所提出的方法,结果表明其在Spider 上已超过所有基准模型,成为最优方法。Zhu 等[36]认为基于神经网络的方法主要关注了问题和关系之间的语义对应,忽视了问题的结构信息,为此他们提出了一种Tree2Seq的模型。该模型将问题的结构信息编码到其向量空间中,从而提升它与自然语言问句匹配的准确性。Zhang 等[37]提出一种Multi-point语义表示框架,其将每个属性拆分为细粒度的4 种因子(topic、predicate、objectcondition、query type)以此区分易混淆的属性,之后利用双向注意力compositional intent 模型(Compositional Intent Bi-Attention,CIBA)将粗粒度的属性信息和细粒度的因子与自然语言问句表示相结合,从而实现问句语义表示的增强。
相比于直接映射方法,神经网络方法不需要预先定义大量的逻辑表达式模板,但因神经网络存在黑盒效应,造成其可解释性较差,同时该方法还需大量的训练语料,导致训练时间过长。
综上所述,基于语义解析的方法旨在将自然语言问句通过直接映射或神经网络等方式转化为逻辑表达式,进而放入知识图谱中进行查询,最终生成最优答案。但无论是直接映射方法还是神经网络方法都有其优缺点,构建低成本、高可解释性的模型成为该类方法的主要研究方向之一。表1总结了基于语义解析的方法优缺点和主要适用范围。
2.2 基于信息检索的方法
基于信息检索的方法是将自然语言问句进行分析,提取其中包含的问题实体构建知识图谱子图,并在知识图谱内根据构建的子图选取多跳内的相关实体作为候选答案集合,之后根据问题及答案中的人工特征对候选答案进行排序,输出最优答案。基于信息检索的方法与基于语义解析的方法之间并没有直接关系,基于语义解析的方法是受到基于信息检索方法原理启发,并进行相应演变而得到。基于信息检索的方法主要分为特征匹配方法和神经网络方法。
2.2.1 特征信息匹配方法
Yao 等[38]最早提出特征信息匹配方法,其将开放知识图谱Freebase 作为信息检索数据集,并将特征信息分为问题特征信息和答案特征信息。
(1)问题特征信息。Yao 等[38]首先使用依存句法分析方法对自然语言问句进行分析,生成其对应的语法依存树(或称为问题图)。语法依存树中主要包含问题词(question word,qword)、问题焦点(question fucus,qfocus)、问题主题词(word topic,qtopic)和问题中心动词(question verb,qverb)4 个问题特征,其中问题词如when、who 等作为问题的明显特征;问题焦点主要表明答案的类型,如name、time、place 等;问题主题词表示问题的实体可用来寻找相关页面以帮助寻找答案,其中问题主题词使用实体识别方法(Named Entity Recognition,NER)确定;问题中心动词能够提供与真实答案相关的特征信息,如play、wear 等。总体而言,从自然语言问句到语法依存树之间的转换,实质就是对问题进行信息提取,抽取出对寻找答案有利的问题特征,并剔除掉无用信息的过程。

Table 1 Summary of the existing semantic parsing-based methods表1 基于语义解析的方法小结
(2)答案特征信息。Yao 等[38]在Freebase 内检索语法依存树中所有的Qtopic 多跳内的实体节点,将其组合成候选答案集,答案集中包含实体和实体间的关系。其中,候选答案集中最重要的特征是实体间的关系与问题直接的关联度,这一特征值主要是通过检索关系表ReverbMapping获得。并且,将属性或者实体之间的有向关系也作为节点的特征类别。
将分析得到的语法依存图中的所有特征与答案特征图中所有节点的特征进行组合,形成候选答案特征集,捕获问题与答案的关联关系和其对应的权重。在候选答案特征集找到最优答案,其本质是一个二分类问题,Yao 等[38]将WebQuestion 作为数据集利用L1 正则化的逻辑回归模型训练一个分类器以寻找最优答案。
图3 展示了Yao 等[38]提出的基于特征匹配问答方法的基本思想,总体而言该方法将自然语言问句转化为问题特征子图,将知识图谱内的答案特征作为检索元,且聚焦在权重较高的答案特征节点上,从而减少搜索空间,获取最优答案。该方法优化了答案生成过程,且在大规模通用知识图谱中表现出较好的适用性和优越性,但面对复杂问题或复杂关系时仍然存在一定缺点。Vakulenko 等[39]为了解决传统特征匹配方法存在的问题,提出一个新的基于特征匹配的复杂KGQA 方法。该方法使用无监督方法通过解析文本并将知识图谱中属于匹配到一组可能的答案而获得相应置信度,并对置信度进行排名以获取最优答案。
2.2.2 神经网络模型
随着机器学习和神经网络技术的快速发展,研究人员将神经网络模型引入信息检索过程中,以实现候选答案排序和关系匹配。Dong 等[40]提出一个基于Freebase的自动问答模型,该模型在不使用任何手工特征和词汇表的基础上,利用多列卷积神经网络(Multi-column Convolutional Neural Networks,MCCNNs)从答案路径、答案背景信息,以及答案类型方面理解问题,从而实现问题特征的提取和分类,并将答案的嵌入向量和前者同时作为评分函数,获取评分最高的候选答案。Dong 等[40]在WebQuestion 数据集上测试了MCCNNs 模型的效果,其结果在各项性能上均表现出了优越性。随着注意力机制逐渐成为解决KGQA 问题的关键技术,Golub 等[41]将注意力机制引入信息检索过程中,并将原来的词级别嵌入替换为字符级嵌入,提出一个引入注意力机制的字符级编码器和解码器模型,有效地改进了问答系统中词表外问题的回答效果;Hao 等[42]将交叉注意力机制引入问题表示和候选答案生成环节,其结果优于MCCNNs 模型。
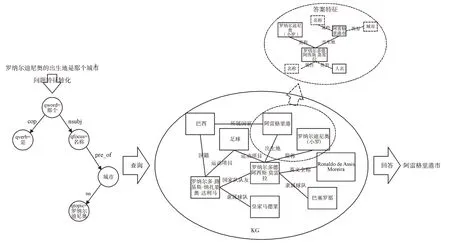
Fig.3 Example of feature matching method图3 特征匹配方法示例
此外,Yu 等[43]提出关系检测的HR-BiLSTM 模型,该模型使用残差双向长短期记忆网络(BiLSTM)在不同层面上对问句和关系进行对比,从而根据给定的问句识别出其对应关系,该方法在KGQA 数据集SimpleQuestions[44]和Web-QuestionsSP[45]上获得了最佳结果;Qiu 等[46]提出一个基于强化学习的神经网络模型(Stepwise Reasoning Network,SRN),SRN 模型将问题形式化为一个顺序策略问题,并使用注意力机制决定获取问题中的独特信息,极大程度上提升了基于信息检索方法的问答效果;Xu 等[47]认为虽然KG中包含丰富的结构信息,但缺乏上下文以提供更精确的概念理解。为此,他们设计一个使用外部实体描述来提供知识理解的模型以辅助完成知识问答。该方法在CommonsenseQA 数据集上实现了最优效果,且在OpenBookQA的非生成模型中获得了最好结果。
神经网络方法是基于信息检索方法中较为理想的方法,其对简单问题和复杂问题具有较优的适用性,但在缩小搜索空间方面仍有不足。
综上所述,基于信息检索的方法是将自然语言问句中的实体和关系进行识别和抽取,从而构建知识子图。利用子图在知识图谱中搜索查询候选答案实体集,并根据问题及答案中的人工特征对候选结果进行排序,输出最优答案。基于信息检索的方法不需要大量的人工标准逻辑表达式规则和庞大的词汇表,但仍然面临着时间复杂度过高、语义信息太复杂等问题的挑战。基于信息检索的方法优缺点和主要适用范围如表2 所示。

Table 2 Summary of information retrieval-based methods表2 基于信息检索的方法小结
2.3 基于知识嵌入的方法
知识嵌入方法是将知识图谱中的实体和关系嵌入到低维稠密的向量语义空间中,并对其进行特定的向量计算。这种针对知识三元组进行嵌入的方法不同于传统词嵌入方法,知识嵌入能够直接表示实体与关系间的语义相关性,能够保存知识图谱中原有的信息量。Boards 等[22]受word2vec 中词向量迁移语义不变现象的启发提出翻译模型TransE。如图4 所示,TransE 模型将知识三元组嵌入到低维稠密向量语义空间中,并在空间内构建h+r≈t的向量表示,其中h表示头实体向量,r表示关系向量,t表示尾实体向量。TransE 模型的提出极大程度上解决了传统知识图谱中存在的计算量大、长尾效应等问题。随着研究的不断深入,研究人员提出了多种知识嵌入模型及其应用,如TransH[48]、TransR、ConvE[49]、ITMEA[50]等。
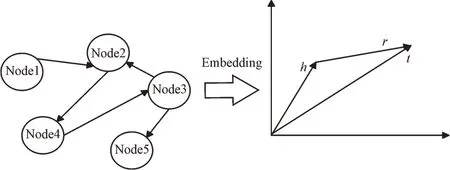
Fig.4 Example of TransE model图4 TransE 示例
Wang 等[51]基于知识嵌入模型提出一种解决SPARQL未匹配到答案的方法。该方法专门为SPARQL 查询语句设计了一个知识嵌入模型,使得答案实体在向量空间中与问题实体建立特定的关联关系,从而更高效地生成高质量的近似答案;Huang 等[52]提出一种基于知识嵌入的问答系统,其设计了一个谓词与头实体学习模型,将问题视为输入,返回与问题谓词/实体更接近的嵌入向量,进而确定头实体和关系,并利用实体链接方法找到尾实体,从而实现问题回答;Saxena 等[53]提出一种利用知识嵌入改进多跳KGQA的方法EmbedKGQA,该方法包含知识嵌入模块、问题嵌入模块和答案选择模块。其中,知识嵌入模块将知识图谱中的所有实体进行嵌入,得到实体对应的嵌入向量;问题嵌入模块将问题视为输入,获得其对应的问题向量;答案选择模块则将所有可能的答案实体向量与问题向量进行关联评分,选择得分最高的实体。此外,为了解决大规模知识图谱造成搜索空间过大的问题,设计了一个候选实体修剪方法,极大改善了EmbedKGQA的性能。EmbedKGQA 方法在MetaQA KG-50 和WebQSP KG-50 数据集上表现出了较好的效果,超过了所有的基准模型,成为最优模型(State-Of-The-Art,SOTA)。Niu 等[54]认为前期引入知识嵌入的知识图谱问答方法只考虑了三元组信息,忽视了路径与多关系问题间的语义。为此,他们提出了一个路径和知识嵌入增强的多关系问答模型PKEEQA,该模型利用KG中实体间的多条路径评估路径嵌入和多关系问题嵌入间的相关性,并制定了一套路径表示机制。通过实验对比,PKEEQA 模型提升了多关系问答性能,同时一定程度上从路径信息方面得到了答案的可解释性。
综上所述,知识嵌入方法是将知识图谱中的知识三元组根据一定关联关系嵌入到低维向量语义空间,这种做法能够最大程度上表示头、尾实体与关系间的联系,从而保留知识图谱中的重要信息。基于知识嵌入的问答方法对未知问题具有较高的处理效果,同时其对大规模通用知识图谱具有较优的鲁棒性和适应性。然而,如何将新知识引入到已构建好的知识嵌入模型中成为知识嵌入方法亟待解决的问题,也成为基于知识嵌入问答能否回答新知识的关键所在。表3 展示了基于知识嵌入的方法优缺点和主要适用范围。

Table 3 Summary of knowledge embedding based methods表3 基于知识嵌入的方法小结
3 知识图谱问答数据集
随着知识图谱问答技术的快速发展,知识图谱问答数据集不断被提出。现有知识图谱问答数据集可大致分为通用领域知识图谱问答数据集和特定领域知识图谱问答数据集,详细的知识图谱问答数据集比较如表4 所示。
3.1 通用领域知识图谱问答数据集
WebQuestions 是2013 年 由Berant 等[26]利 用Google Suggest 生成,数据集为每个答案都提供了其对应的主题节点。WebQuestions 数据集采用先提问后解答的构建思路,同时数据集的问题独立于Freebase 知识库外,从而比Free917[55]数据集更加自然,更偏向于自然语言,但该数据集仅提供了答案而没有给出对应的查询语句,从而造成逻辑表达式的生成变得极为困难,此外数据集中只包含少量的复杂问句。
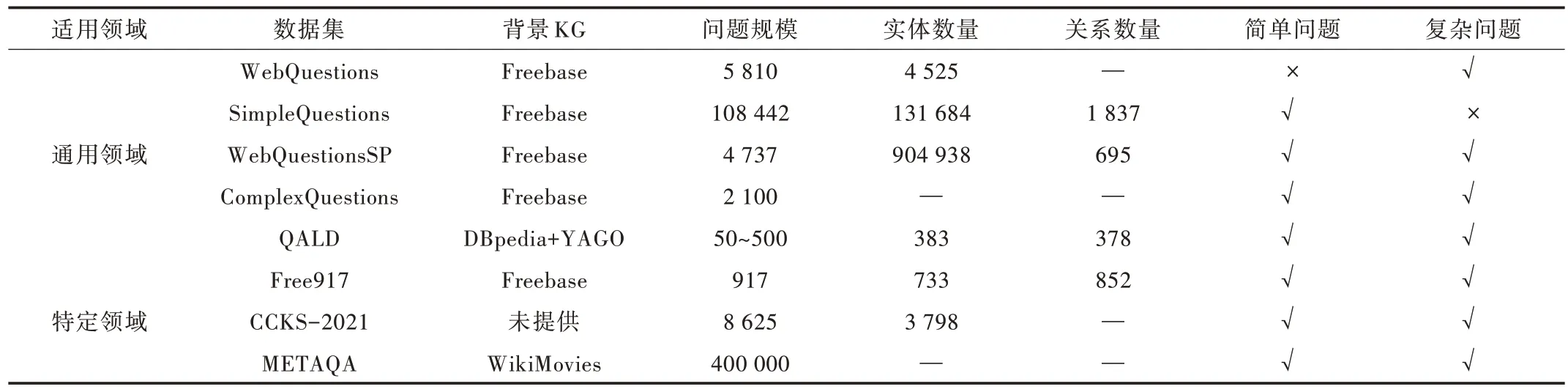
Table 4 Datasets of knowledge graph question answering表4 知识图谱问答数据集
SimpleQuestions 是Bordes 等[44]提出的一个大规模问答数据集。该数据集以问答系统处理覆盖面为主要研究内容,数据集内包含了大量的简单问答语句,这些问答语句可以用知识三元组进行回答,同时数据集中包含了问题对应的查询语句。
WebQuestionsSP 是Yih 等[45]对WebQuestion 数据集进行改进,补全了问题所对应的查询语句,可以简单地将其视为WebQuestions 数据集的子集。
ComplexQuestions 是Bao 等[56]为了测试KGQA对复杂问题的处理能力所提出的一个多限制问答数据集。Bao等[56]从WebQuestions 训练集和测试集中分别抽取了596 个和326 个问题,从搜索引擎中爬取了878 个问题,并从其他数据集中抽取了300 个问题从而构建ComplexQuestions 数据集。然而,ComplexQuestions 数据集内未提供问题所对应的查询语句。
QALD[57-61]是一种通用领域的大规模数据集,相比于其他知识问答数据集更加生活化、复杂化。QALD 数据集不仅包含问题和答案,还为每个问句设置了关键词和对应的查询语句。
3.2 特定领域知识图谱问答数据集
Free917 是2013 年由Yahya 等[55]提出,数据集以房地产领域数据为主,并将数据形式化表示为“问题-λ 微积分表达式”。数据集中问题的答案为Freebase 知识库中的某个属性,同时通过人工定义的方式提出与其相关的自然语言问句。然而,Free917 并未对问题类型进行限制。
CCKS 问答数据集是CCKS 全国知识图谱与语义计算大会提出的一项知识图谱问题评测任务所使用的数据集。CCKS 每年提出一个全新的知识图谱评测任务和数据集,包含保险领域问答、医疗领域问答等。数据集中包含了大量真实且复杂的问答语句,但未给出其对应的查询语句。
METAQA 是由Zhang 等[62]构建的电影领域知识图谱问答数据集,数据集中包含了近29 000 个多跳测试查询数据。
4 知识图谱问答测评指标
4.1 功能性测评指标
功能性测评指标主要反映知识图谱问答方法(系统)返回答案的正确性和完备性,当返回的答案与正确答案无关时评定其为错误答案,相关但不完备时也将其评定为错误答案。通常功能性测评指标指精确率、召回率、准确率、F1 值。
(1)精确率。精确率(Precision)指问答方法对每个自然语言问句给出的黄金标准答案(问题对应的一个标准答案)占所有返回答案总数的比例。精确率计算公式可以形式化表示:

(2)召回率。一个自然语言问句可能存在多个标准答案,如:问题“杭州有那些景点?”就有多个标准答案,因此需要评测知识图谱问答方法召回完整答案的能力。召回率(Recall)表示知识图谱问答方法返回的正确答案数占返回的黄金标准答案的比例。召回率计算公式可以形式化表示为:

(3)准确率。准确率(Accuracy)表示知识图谱问答方法回答正确的问题数占所有问题的比例。准确率计算公式可以形式化表示为:

通常使用准确率定义指标Hits@K,即将答案列表按照特定值进行排序,如果前K 个答案中有一个正确的则为1hit,否则为0hit,并最终计算整个问题集的平均值。
(4)F1 值。通常知识图谱问答方法(系统)的总体性能使用F1 值对精确率和召回率进行整体测评。测试集中的每个问题都有其对应的F1 值,其计算公式可以形式化表示为:

4.2 性能测评指标
除上述功能性测评指标外,还可以从性能指标角度对知识图谱问答方法(系统)进行测评。具体而言,知识图谱问答方法(系统)的性能测评指标分为方法响应时间和方法故障率两方面。
(1)知识图谱问答方法(系统)响应时间。通常,智能问答系统需要实时响应用户的文本或语音输入,因此知识图谱问答方法(系统)的响应时长(Response Time)成为测评方法性能的一个重要指标。如果响应时间过长,知识图谱问答方法的可用性就会大大降低。一般而言,知识图谱问答方法的响应时长应缩短到1s 以内。
(2)知识图谱问答方法(系统)故障率。知识图谱问答方法(系统)出现故障的概率,即统计方法在回答自然语言问句时发生系统错误或故障的比率,通常采用压力测试检验知识图谱问答方法(系统)的故障率。
5 知识图谱问答研究挑战与机遇
5.1 面临的挑战
(1)语义歧义。无论是利用语义解析方法还是信息检索方法,都需要将自然语言问句映射到知识图谱中,因此实体链接和关系抽取成为关键过程。然而,现有实体链接方法的质量并不高,使得错误实体信息被不断传递到关系提取阶段,造成自然语言问句无法与知识图谱进行匹配或无法避免增大搜索空间。虽然现有许多语义表示方法在不断地改进实体链接和关系抽取的效果,但如何从自然语言问句中精确完整地获取语义信息成为KGQA 面临的一大挑战。
(2)复杂问题。复杂问题中常常包含多个问题实体和关系,需要KGQA 系统具有推理和判断的功能。例如:“2020 年东京奥运会男子乒乓球比赛项目单打冠军分别战胜了那些对手?”然而,现有的KGQA 对于简单问题(仅有一个问题实体和关系)的处理能力已较为优秀,但对于真实应用场景中复杂问题的处理能力尚且不足。虽然,研究人员尝试解决平行的复杂问题,但仍然无法解决大多数复杂问题。因此,对于复杂问题的处理与研究成为学术界和工业界亟待解决的重大挑战。
(3)长尾问题。长尾问题包括知识图谱长尾问题和问句长尾问题。知识图谱长尾问题指现有大规模知识图谱中存在着大量的实体和关系,这些实体和关系中只有部分实体间存在大量的关系连接,但其他实体仅有单一或少量关系,从而造成答案实体的搜索空间和计算量剧增。问句长尾问题指少量表示相似含义的问句频繁出现在问答数据集中,造成KGQA 系统对于该类问题有较强的回答能力,而对于大量出现频率较低的问句处理能力较弱。因此,知识图谱长尾问题和问句长尾问题成为阻碍KGQA 性能进一步提升的关键因素。
5.2 未来研究方向
(1)知识图谱推理机制。现有的知识图谱推理机制常常根据知识嵌入后的知识三元组对实体或关系进行推理,但使用该机制预测缺失实体或关系的能力尚不足以支撑复杂问题的知识推理,尤其是对长尾关系的知识三元组的推理。目前,除利用知识嵌入方法外,还可以使用统计关系学习和GNN 等方法进行知识推理。如何将高效的推理机制引入知识图谱内,充分利用图谱中高质量的三元组信息实现复杂问题的回答,成为未来研究的热点问题。
(2)预训练模型有效利用。随着预训练模型的出现,包括智能问答在内的多项自然语言处理任务的性能不断被突破,许多研究人员致力于将预训练模型与知识图谱相结合,使得在KGQA 训练数据较少的情况下,仍然能够取得相比于传统KGQA 方法更优的问答效果[63]。但如何将预训练模型更加充分地与KGQA 相结合,利用好预训练模型和知识图谱中的先验知识,同样成为提升KGQA 性能的热点研究方向。
(3)多模态知识问答。随着多模态数据(如图像、视频、文本描述数据等)越来越多地被用来提升知识图谱的表示能力[50,64-66]。多模态知识图谱能够有效提升知识的多样性、丰富知识的隐藏信息,能更加完整地组织知识图谱内的知识。因此,为了满足用户日益增长的知识和认知服务需求,利用多模态知识图谱进行知识问答成为未来主要研究方法。
综上所述,知识图谱问答方法在处理简单、开放领域问题方面已经取得较为突出的进展,但仍然面临着语义歧义、复杂问题理解、知识图谱长尾和自然语言问句长尾等多因素的挑战。这些挑战成为阻碍知识图谱问答系统大规模应用于实际生产环境的重要因素。同时,随着自然语言和深度学习技术的快速发展,如何将多模态信息和预训练模型等新思想引入知识图谱问答方法中也成为未来主要研究方向,如利用预训练模型获取结构化知识、文本、图像等模态数据特征,并引入注意力机制将多模态信息进行融合从而实现多模态知识图谱问答。
6 结语
随着智能时代的到来,能够理解和回答自然语言问题的智能问答系统得到了广泛应用。作为智能问答系统主要方法的知识图谱问答成为国内外学者的主要研究方向,且取得了突出进展。本文对现有知识图谱问答研究进展进行追踪,介绍了3 种主要的知识图谱问答方法和两类知识图谱问答数据集,并针对知识图谱问答面临的主要挑战和未来研究方向进行了讨论,期望可以为未来KGQA 研究者提供帮助,以开拓不同领域知识图谱问答的应用场景。
猜你喜欢
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
杂草学报(2012年1期)2012-11-06
