
伪装目标检测与分割研究进展
2022-03-25 04:45何淋艳王安志任春洪杨元英欧卫华
软件导刊 2022年3期
何淋艳,王安志,任春洪,杨元英,欧卫华
(贵州师范大学大数据与计算机科学学院,贵州贵阳 550025)
0 引言
伪装检测/分割是利用计算机视觉和机器学习等技术对图像或视频进行特征表示,从而将隐藏在图像背景环境中的目标对象检测出来[1]。由于伪装目标的外观特征与背景很接近,导致对伪装目标进行特征表示比较困难。图1给出了自然伪装和人为伪装的示例图,第1-2 行是自然伪装图像,3-4 行是人为伪装图像。早期,研究人员利用颜色、纹理等手工设计特征检测伪装目标,这些方法将前景信息看作是伪装目标,对图像中的前景和背景进行分离,但当伪装目标对象的颜色纹理与背景非常相似时,该类方法性能表现不佳,甚至失效。近期,人们采用深度卷积网络检测伪装目标,其结果优于基于手工特征的方法,但这类方法设计复杂,需要借助高性能设备进行计算,还需精心标注的大量数据才能训练。

Fig.1 Some samples of natural and artificial camouflage objects图1 自然伪装与人为伪装实例
本文首先对颜色、纹理、运动等传统基于手工特征的COD 方法进行分析,重点阐述基于深度学习的伪装检测方法;然后对COD 领域的重要数据集和性能度量指标进行介绍,并作详细的定性和定量分析;最后探讨COD的应用,并进行总结和展望。
1 基于手工特征的伪装目标检测
基于手工设计特征的伪装目标检测方法主要利用颜色、纹理、运动等特征区分前景和背景从而检测出伪装目标。文献[2]综述了传统伪装目标检测与追踪的方法。
1.1 基于颜色和纹理特征的方法
Galun 等[3]提出一种自底向上聚合框架检测伪装目标的技术,该技术结合纹理特征和滤波器响应自适应地识别纹理元素的形状,并通过其大小、纵横比、亮度等表示图像中的纹理信息以发现伪装目标,该方法只适用于包含目标和背景纹理不同的图像;Bhajantri 等[4]提出利用共生矩阵[5]和边缘检测器[6]的多重去伪装技术,将从共生矩阵中分析出的纹理和边缘检测器中检测出的边缘合成背景图像,但该方法不适用于真实生活中的数据;Kavitha 等[7]利用局部HSV(色调、饱和度、值)颜色模型和灰度共生矩阵纹理特征识别图像中的伪装目标;鲜晓东等[8]提出利用高斯混合模型拟合背景颜色信息和局部二值模式提取图像纹理信息的方法,将颜色和纹理信息进行线性融合以检测伪装部分。简言之,基于颜色的方法只能解决物体与背景有颜色差异的情况。然而,基于纹理特征的方法在颜色非常接近背景时检测效果较好,却在伪装目标的纹理与背景相似时性能较差。
1.2 基于运动特征的方法
Wang 等[9]设计了视觉运动图像滤波的计算模型,该方法会随着光照变化、环境条件变化等因素产生更多虚警;Yin 等[10]提出基于光流的运动伪装检测方法,其准确性取决于光流结果,且容易受到噪声影响;周静等[11]也提出基于光流场分割的伪装运动目标检测方法,首先计算视频序列运动光流场,再利用K-means 算法完成运动目标背景分割。基于运动的检测方法依赖于运动信息,其根据运动形成的背景颜色和纹理之间的变化差异,定位出伪装目标。但该类方法受干扰因素影响较大,会因光照变化或背景移动而出现误检漏检等问题。
1.3 基于几何梯度特征的方法
梯度信息有助于从背景区域中提取到目标特征信息,Tankus 等[12-13]提出通过Darg 运算增强对应需要分离的凸(或凹)3D 对象(伪装目标)的阴影区域,该方法不适用于包含凹背景和深色对象的环境;潘玉欣等[14]也提出利用Darg算子对复杂背景下的伪装部分进行检测,该方法需要选择阈值以去除较复杂背景下Darg 算子产生的噪声;武国晶等[15]提出基于边缘检测的算法,引进经过空间域平滑滤波器对图像进行去噪处理的三维凸面检测算子,将其应用于迷彩伪装目标检测,解决了三维凸面检测算子对图像中噪声敏感的问题。
1.4 基于频域特征的方法
Losa 等[16]提出基于结构相似度量的粒子滤波器以追踪伪装目标,通过比较两帧之间的亮度、对比度和空间特征反映二者的距离;李帅等[17]提出纹理引导加权选择算法,采用平稳小波变换在一定的小波频带内捕获图像前景与背景区域之间的差异性;随后又提出一种小波域伪装运动前景检测融合框架,通过建立前景和背景模型估计小波频域,通过对不同小波频域段的似然度进行聚类以检测伪装目标[18];叶松等[19]提出一种基于图像融合的算法,先融合线偏振度和域偏振角两个特征图,后使用直方图均衡化算法进行增强,最后采用非下采样轮廓波变换将增强后的特征图像和光强度图像进行融合以检测伪装目标;Shah等[20]提出基于背景估计的视频小波融合算法,结合曲波和小波变换,将自适应权值和小波变换进行融合以检测伪装目标。基于频域特征的方法更有效地反映了图像细节,但不能突出表面光滑物体间的差异。
1.5 基于光学图像特征的方法
Zhou 等[21]提出一种基于剪切波变换的光谱—偏振图像融合算法,从背景中分离伪装目标;Kim[22]提出一种基于光谱和空间特征的超光谱图像伪装检测方法,利用统计距离度量候选特征和基于熵的空间分组特性减少无用的特征波段;Mangale 等[23]融合热红外成像和可见光谱成像模式以检测伪装目标;Liang 等[24]构建一个红外图像数据集,并提出一种利用红外特征信息的伪装检测方法,其采用“残缺窗口模块”优化数据集以解决目标信息残缺出现的漏检问题;Liu 等[25]提出一种通过综合图像的空间特征、自顶向下特征和光谱特征的方法,用期望最大化、框架普遍化描述如何处理伪装问题,但缺点是:当物体形状模糊时,会导致检测不准确。这类方法根据图像的光谱特征信息分析和鉴别伪装目标,但这类方法检测精度受光谱特征信息质量影响较大。
基于传统手工设计特征的伪装检测方法利用物体的视觉特征(如颜色、纹理、运动等)设计算法以发现伪装区域,依靠单一特征的检测方法检测效果差,而结合颜色、纹理、运动等多种特征的方法相较于单一特征的检测效果更好。并且,基于手工设计的算法不需要进行大量训练,也无需手工标注的数据。但检测效果易受到噪声、光照、运动等因素影响。
2 基于深度学习的伪装目标检测
近年来,随着深度学习在计算机视觉各领域的深入应用,部分学者利用卷积网络解决伪装目标检测任务,效果较传统的伪装检测方法有明显提升。Mondal 等[26]提出一种基于概率神经网络和模糊能量的伪装目标跟踪方法,从多线索(如颜色、形状和纹理等)中整合特征以表示伪装物体;Fang 等[27]提出强语义膨胀卷积神经网络检测框架,充分利用卷积神经网络的语义信息和扩大感受野检测伪装目标。近期,基于深度卷积算子的伪装检测方法取得了突破性进展,本文将对最新的几种代表性伪装检测方法进行深入阐述。
2.1 ANet
2019 年,Le 等[1]提出一个端到端的深度卷积网络——Anabranch Network(Anet)。该网络由一个卷积神经网络[28]和全卷积网络(FCN)[29]组成的分类流,以及一个基于端到端的FCN 分割流组成,两个支流网络的输出结果相乘得到伪装目标分割图。ANet 本质上是一个显著性目标检测网络,其核心思想是将伪装看作显著的反面,先提取伪装图像中的显著性特征,分割流将显著性特征分割出来,然后将从卷积层中提取到的特征经过其分类流进行分类过滤,最后将分割流的结果与分类流的结果进行乘操作,去掉显著性特征,得到伪装特征。实验表明,该方法检测效果优于传统的伪装检测方法,但检测结果存在部分伪影且边缘检测效果不佳。
2.2 Mirror Net
Yan 等[30]利用生物视觉特性提出一种镜像仿生对抗网络MirrorNe,利用实例分割和对抗网络分割图像中的伪装目标,该分割网络有两种分割流,分别是与原图像对应的主流及其翻转后图像对应的对抗流。该方法将图像进行翻转从而改变角度以打破原始图像带给人们的视觉迷惑,从一个新的视角发现伪装目标的位置从而将其分割出来。该方法通过计算对抗流中经过翻转得到的特征图与主流中原图像的距离发现二者之间的差异,该距离用欧几里德距离表示为:
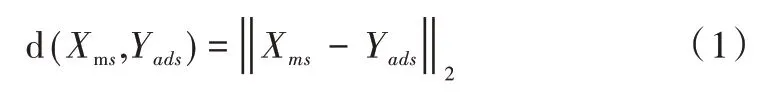
其中,d(Xms,Yads)表示主流与对抗流之间的距离,Xms、Yads分别表示主流和对抗流图像的特征点位置。对比图像间的视觉差发现伪装目标的轮廓,使用区域建议网络[31]对目标进行不同建议框选,得到多个建议区域包围盒,并使用RoIPool 将这些特征进行最大汇聚。本文还利用数据增广技术扩大训练数据集,再对这些数据进行翻转操作后将其作为网络对抗流的输入数据。实验表明,该方法的检测分割性能优于ANet。
2.3 SINet
Fan 等[32]提出一个简单的搜索识别模块(SINet)以解决伪装目标的检测与分割问题。根据文献[33]可知,浅层卷积能保留物体边缘空间信息的低级特征,而深层卷积则保留用于定位目标的语义信息,该方法采用稠密连接策略将低、中、高层的特征保存下来。在骨干网络中使用扩大的感受野[34]模块整合鉴别性特征,获得候选特征后,在识别模块使用局部解码组件PDC[35]对相邻元素进行乘操作保证相邻特征之间差距更小,PDC 模块整合了来自搜索模块的4 个特征层。此外,Fan 等[32]还收集制作了一个较CAMO 更加全面的伪装图像数据集COD10K[32],数据分布如表1 所示。
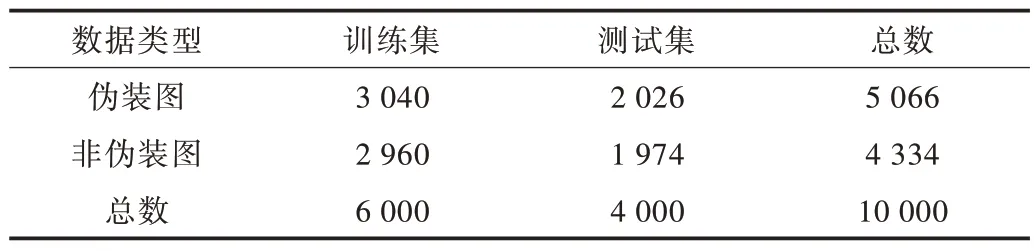
Table 1 Distribution of the COD10K Dataset表1 COD10K 数据集图像分布
2.4 MoCA——视频伪装分割方法
Lamdouar 等[36]提出由可微分配准模块和带有记忆的分割模块组成的一种新框架分割视频中的伪装物体。可微分配准模块用来校准连续帧背景并计算差分图像从而突出移动目标的细粒度细节,运动分割网络将从配准模块中获取的光流和差分图像作为输入,生成更精确的分割掩模。此外,他们还收集了一个大型的动物伪装视频数据集MoCA,并证明了该数据集的有效性。
2.5 基于改进版的RetinaNet 伪装检测
邓小桐等[37]改进了轻量级目标检测网络框架RetinaNet[38]以检测伪装目标,嵌入了空间注意力和通道注意力(CBAM)[39],并基于置信得分构建预测框算法,对数据进行增广,提高了检测精度。本文将CBAM 注意力机制引入RetinaNet 模型,将其串联嵌入特征提取网络ResNet50的每个残差块之间,以期更好地抑制背景区域,提升模型对伪装目标的表示能力。模型通过特征金字塔网络中的上采样和按元素相加将图像深层语义信息融合到各特征层中,得到具有各种尺度的特征集合,使用FCN[38]并行分类和位置回归,实现对目标的预测。此外,模型还用focalloss解决训练中正负样本失衡的问题。
2.6 基于混合技术的语义相似度算法
Dong 等[40]提出一种由一个双分支融合卷积和一个交互融合模块的网络框架检测伪装目标,其中双分支融合卷积的作用是为了扩大感受野以获得更丰富的上下文特征信息,交互融合模块则结合了注意力机制对卷积层的特征进行有效融合,使得最终效果图更加全面。丰富的上下文信息能够获得更精确的图像特征,而此文利用多个不成对卷积和两个扩张卷积扩大感受野,提取更多的上下文信息,使网络在训练时能够检测到目标的主体特征,但该网络不能获取准确的边缘信息。图2 比较了该方法与SINet 在数据集CAMO[1]以及COD10K[32]上的预测图,其中左边图为在数据集CAMO 上的对比,右边图为在COD10K 上的对比,更直观地展示了该网络提取伪装目标主体信息的准确性。
基于深度学习的伪装目标检测网络一般设计为两部分,即用于定位或获取伪装目标特征的模块和将目标检测分割出来的模块。两个模块相互作用,进行特征融合得到最终伪装部分。最新研究表明,目前使用卷积神经网络和注意力机制结合的伪装检测方法表现出前所未有的性能优势。实验表明,这类方法明显优于传统检测方法,但依赖于大量标注的数据训练网络,且网络框架设计复杂、训练耗时。
表2 总结了典型基于传统手工设计特征的伪装目标检测和基于深度学习的伪装目标检测与分割方法的关键信息和设计要点。
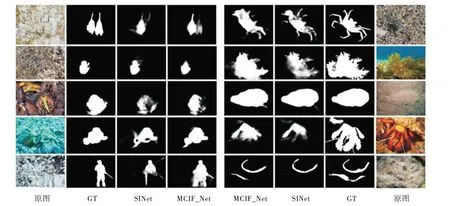
Fig.2 Comparison of MCIF_Net and SINet prediction results图2 MCIF_Net 与SINet方法比较
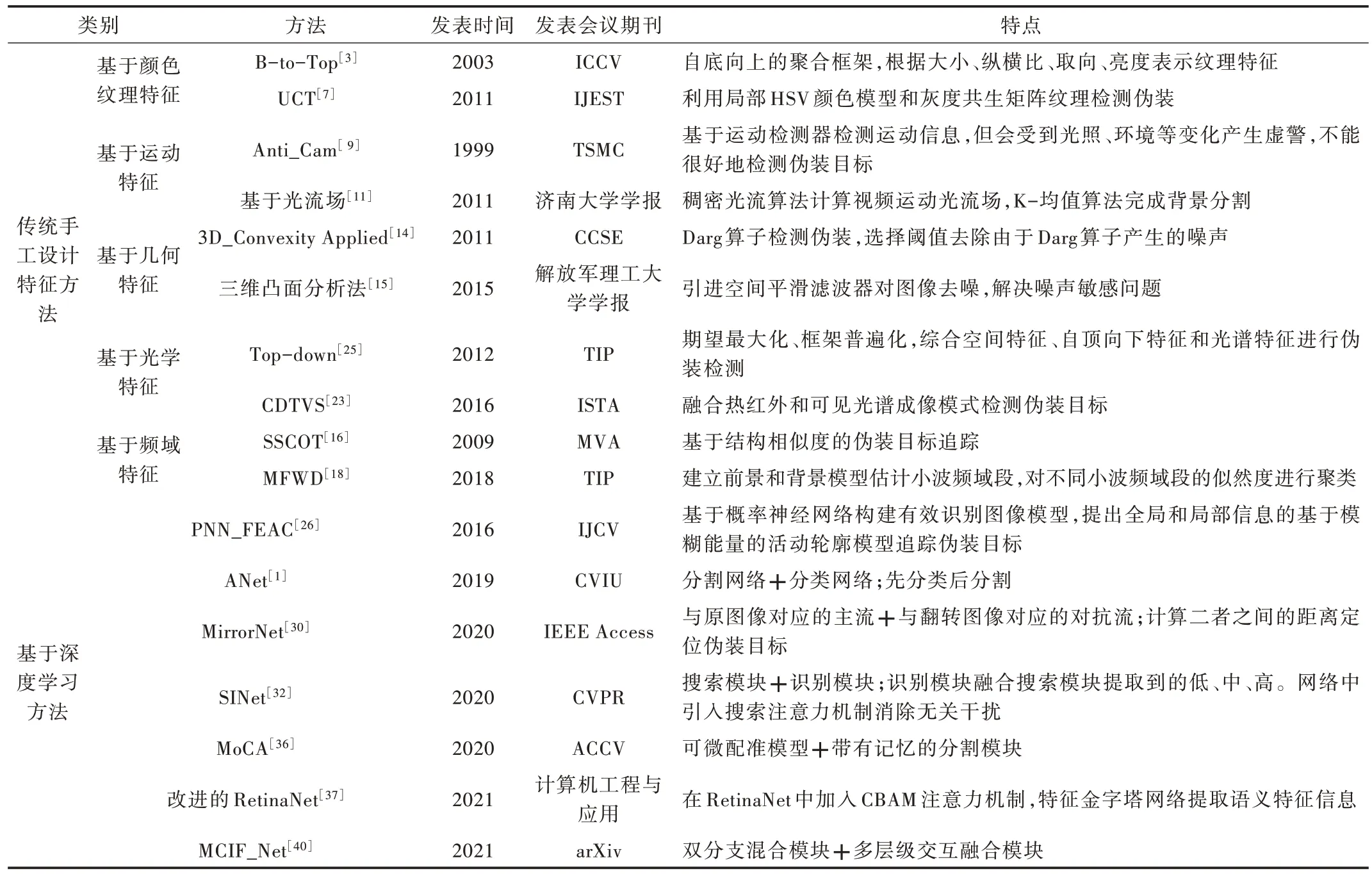
Table 2 Summary of traditional and deep learning-based camouflage detection methods表2 传统伪装检测和基于深度学习的伪装目标检测方法
3 实验
本文首先介绍伪装检测的几个公开测试数据集,然后介绍用于伪装目标检测的性能度量指标,并给出基于不同骨干网络的伪装检测算法定量评价指标值和多个先进检测算法的定性评价视觉效果对比。
3.1 数据集
数据集对算法模型的评估十分重要,通常可分为训练集、验证集和测试集。伪装目标检测领域主要数据集包含CHAMELEON、CAMO、COD10K 和MoCA 数据集,MoCA 数据集尚未公开。CHAMELEON 数据集由Skurowski[41]等提出,其中包含76 张伪装动物的图像,以及手工标注的对象级真值图和边界图。CAMO 数据集由Le 等[1]构建,包含1 250 张图像,其中每张图至少存在一个伪装物体,包含动物伪装、物体伪装、迷彩伪装和人体彩绘的伪装等。COD10K 数据集由Fan 等[32]于2020 年提出,包含10 000 张样本图像(5 066 张伪装图、3 000 张背景图、1 934 张非伪装图),涵盖各种自然场景的伪装目标,共78 个类别(包含69个伪装类、9 个非伪装类),MoCA 数据集包含了141 个视频片段,共37 250 帧,跨度26 分钟,包含67 种伪装动物在自然场景中的运动,但该数据集尚未公开。
这些数据集的构建为伪装目标检测提供了更完善、更多样的伪装数据,为算法研究提供了更好的评估和预测基准,使得网络模型有更可靠的训练数据。
3.2 性能评估度量方法
伪装目标检测与目标检测、显著性目标检测等任务存在一定的相似性,现主要采用这些相近领域中的评价度量指标进行评估,主要包括平均绝对误差[42](Mean absolute error,MAE)、准确率—召回率曲线(Precision-Recall Curve,PRC)、F-measure 值、S-measure 值和E-measure 值。MAE计算显著预测图和真值图之间的差值,计算公式如下:
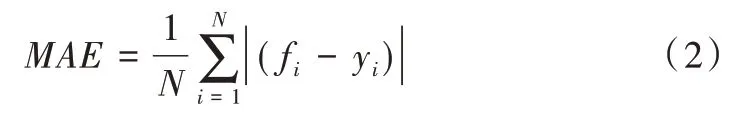
其中,fi表示预测图,yi表示真值图。PRC 是度量模型的查全率Precision 和查准率Recall,但查准率和查全率都不能很全面地对显著图像进行评估,因此提出了F 度量值[43](F-measure),即查全率和查准率在非负权重的加权调和平均值,计算公式表示如下:
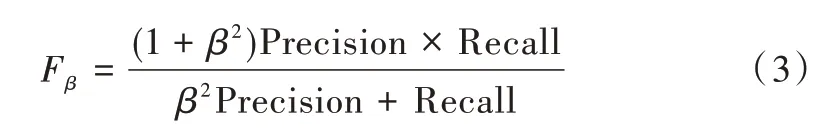
其中,β的取值根据显著性检测经验所得,β2默认取值0.3,增加了查准率的权重。结构相似度测量[44](S-measure)同时评估非二值显著图和真值图之间区域感知和对象感知的结构相似性,S-measure 可表示为:
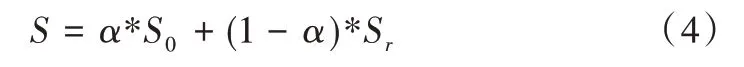
其中,S0是面向物体的结构性度量,Sr是面向区域的结构性度量,α是一个0~1 区间的概率值,默认取0.5。E-measure(Eφ)是一种基于人类视觉感知机制的增强—匹配评价指标[45],它同时考虑了像素级信息匹配和图像级信息统计。以上评价指标统称为定量评价。
3.3 实验比较分析
表3 比较了几种基于深度学习的伪装检测算法在CAMO 测试集上的评估结果。结果显示,采用改进的ResNeXt-152 为主网络的MirrorNet 各项指标均优于其他算法模型。图3 展示了近期几个最先进的伪装检测方法的定性评价,在数据集CAMO 测试集中随机选取8 张图像进行比较,结果最优的加粗标注。实验表明,MCIF_Net的伪装检测结果总体上优于其他算法,能够很好地检测到伪装目标的特征信息,但对边缘部分的细节检测效果不够理想。
4 结语
伪装目标检测可应用于物种保护、农业防治、军事和人体伪装等领域[30-32]。Song 等[48]将伪装检测技术用于区分伪装害虫和绿色植被;甘源滢等[49]将伪装技术应用于军事作战,以改进军队伪装技术,提高战场生存能力;项阳等[50]和张润生等[51]对人脸伪装识别进行探索,对佩戴眼镜、帽子、假发或化妆等形成的人脸伪装进行检测,对安防领域有极大的应用价值;Fan 等[32]提出伪装检测的两个潜在应用:一是医学图像病变区域检测与分割;二是搜索引擎。
本文对伪装目标检测与分割相关研究进行了系统总结,分析了传统的伪装检测和基于深度学习的伪装检测两大类方法。基于传统手工设计的检测方法只能检测简单理想的伪装情况,对于检测与背景环境非常相似的目标时,检测效果较差,甚至失效;基于深度学习的方法借助于卷积算子提取伪装目标的特征,各种高效卷积层和新型注意力机制可用来进一步提升检测性能。实验结果表明,基于深度学习的伪装检测方法效果更好,更适合于伪装目标检测与分割。
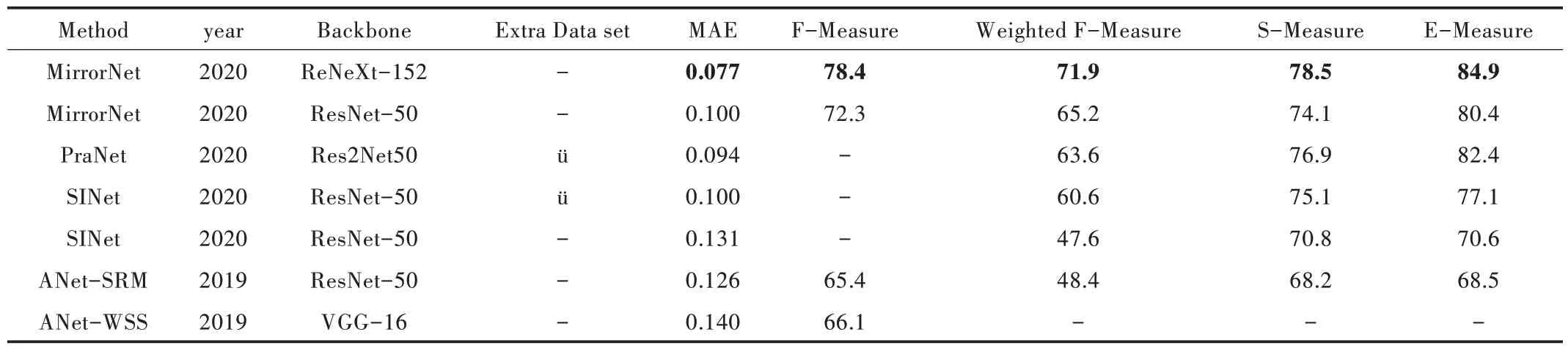
Table 3 Quantitative evaluation of CAMO test dataset based on different backbone networks表3 不同Backbone 网络在CAMO_test 数据集上的定量评价

Fig.3 Comparison of camouflage detection and prediction effects图3 伪装检测预测效果对比
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
摄影之友(影像视觉)(2018年12期)2019-01-28
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
电视技术(2014年19期)2014-03-11
