
基于动态ID跳变的CAN总线安全调度算法
2022-04-01 11:36臧仕义曹殿明佘黎煌
东北大学学报(自然科学版) 2022年3期
丁 山, 臧仕义, 曹殿明, 佘黎煌
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
近年,车载网络安全研究员和网络黑客们开发了大量对CAN(controller area network)的攻击方法,攻击数量显著增加,这暴露出CAN总线的弱访问控制和缺乏网络安全防御机制问题,攻击者可以轻易地入侵CAN总线实施伪造攻击、重放攻击和拒绝服务等攻击.随着智能网联汽车的快速发展以及5G时代的万物互联,类似于自动驾驶等先进技术正广泛应用于汽车中,因此网联汽车的智能化和一体化管理背后的安全问题至关重要.
在CAN网络攻击方式多样化的同时,其防御手段也相继提出.Wolf等[1]提出在相互通信的ECU之间进行验证,同时对传输的数据进行加密以保证安全性.吴尚则[2]提出动态身份认证方法,使用动态口令完成消息认证.Groza等[3]提出物理特性身份认证.由于CAN总线的资源是有限的,添加消息认证码将消耗有限的有效负载.Larson等[4]提出基于CANopen协议的异常检测,通过对象字典检测非法ECU.Humayed等[5]提出基于非周期的NAS机制的ID跳变方法.Lukasiewycz等[6]提出一种优先级混淆方法.Wu等[7]提出使用基于ID跳变表的周期性ID跳变算法,即IDHCC(ID Hopping CAN controller).但是上述ID跳变机制必须保持相对优先级顺序,通过收集大量消息,攻击者可以轻易知道消息在系统中的优先级分布情况从而实施攻击.
针对上述情况,本文提出使用优先级跳变和一次性ID的方法.通过遗传算法计算固定优先级决定算法保证系统的实时性.将数据帧的ID段进行重构,利用可调度性分析计算结果,进行分组优先级的循环ID跳变(PID与UID),使用单向散列函数SHA-256对ID段的后部DID进行动态跳变,通过优先级跳变和动态ID 跳变算法保证系统的网络安全性.
1 理论准备、攻击模型与解决方案
1.1 CAN帧格式
局域网控制器CAN是一种串行通信协议,是当今现场总线中具有国际标准的现场总线,传统的CAN帧只能支持0到8字节的数据长度.不过CAN 2.0规范又分为CAN 2.0A和CAN 2.0B,其中,CAN 2.0A 的报文格式继承了CAN 1.2标识符11位的标准帧;CAN 2.0B对CAN 2.0A进行了扩展,同时支持标识符为29位的扩展帧.图1为CAN标准帧格式.

图1 CAN标准帧格式
1.2 攻击模型
在本文的攻击模型中,由于当前CAN总线中没有安全策略,认为攻击者可以访问CAN总线并通过发起嗅探、重放、伪造和特定拒绝服务(denial of service,DoS)攻击进行CAN总线攻击.构建的攻击模型如图2所示,其中特定DoS攻击是指攻击者以某一个ECU或某一组ECU为目标,插入大量优先级ID大于正常数据帧ID的恶意帧,从而破坏正常的CAN总线工作;重放攻击指攻击者通过大量嗅探以往的数据帧,在某个关键时刻向总线上重放嗅探到的数据帧,以达到破坏CAN总线或执行攻击者预想的效果,也被称为“中间人攻击”.
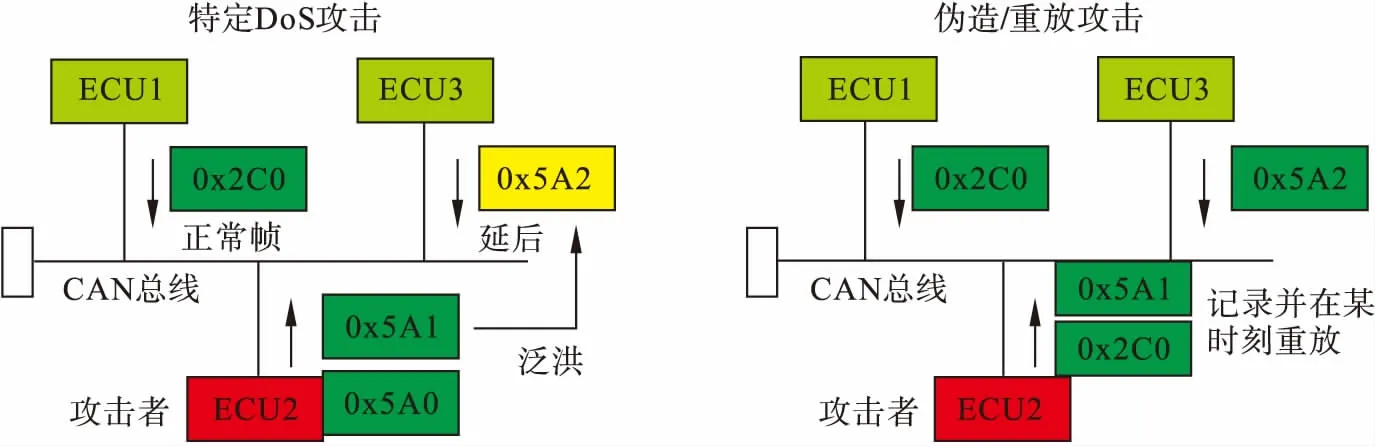
图2 攻击模型
1.3 解决方案
本文针对现存问题所提出的解决方案概述如图3所示,其中包含5个步骤,步骤1和2是跳变前的数据准备阶段,步骤3和4是循环跳变的设计阶段,步骤5是利用重构后的ID段进行ID Hopping的应用阶段.
步骤1 数据帧的固定优先级与优先级可妥协范围,即通过遗传算法得到CAN总线数据帧的最佳固定优先级并尽可能扩大每个优先级的上下限的绑定范围,且满足所有实时约束.
步骤2 优先级分组集合,本文提出一种“优先级决定算法(priority decision algorithm,PBD)”,通过优先级可妥协范围计算出优先级分组集合,将优先级分组集合作为后续的优先级跳变的依据.
步骤3 重构ID段,如图4所示,将ID段分为用于区分优先级的部分和进行混淆跳变的部分,定义标识符的前部分为优先级ID(priority ID,PID)、中间部分为唯一ID(unique ID,UID)和后部分为动态ID(dynamical ID,DID).
步骤4 循环跳变,利用可调度性分析计算的结果进行分组优先级的循环ID跳变,即重构后的PID段与UID段,使用单向散列函数SHA-256对ID段的后部DID进行动态跳变.
步骤5 应用阶段,当在CAN总线上发送数据帧时,可以结合重构后的ID段进行数据帧ID的选择与跳变.
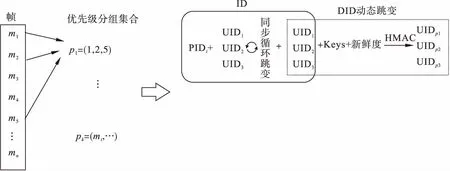
图3 动态ID Hopping机制

图4 ID段重构
2 固定优先级与优先级决定算法
2.1 最坏情况响应时间(worst case response time,WCRT)和可调度性分析
一个消息mi,属于一个消息集合M={m1,m2,…,mn},共计n个消息帧.这些帧可以使用一个三元组来表示:mi={Ti,tci,tdi},其中Ti是帧的周期,tci是帧的传输时间,tdi是帧的截止时间.一般情况下,Ti=tdi,在本文中,为了计算方便,同样认为Ti=tdi.那么,帧mi的WCRT[8]由三部分组成,分别是抖动时间Ji、队列延迟Wi和传输时间tci(队列抖动,指的是事件开始到帧mi就绪并准备在总线上进行传输需要的最长时间;队列延迟,指的是帧mi成功在总线上开始传输之前,一直被保存在CAN设备驱动队列里的最长时间).
Ri=Ji+tci+Wi,∀mi.
(1)
队列延迟Wi是一个单调非递减函数,具体值的计算只能通过以下递推公式来求解:
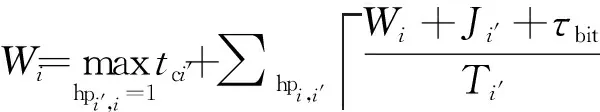
(2)
其中:hpi,i′=1是一个二进制变量,用来表示帧mi的优先级高于帧mi′;τbit是CAN总线的速率,这里设为1.
最后,tci的计算公式如下:
(3)
其中:Si是CAN总线数据场中数据的字节数;g是CAN总线的一个常量,这里等于34.
关于实时性的约束,即WCRT要小于等于截止时间,使得消息可以在规定时间内被接收,其约束如下:
Ri≤tdi,∀mi,
(4)
tdi=Ti,∀mi.
(5)
其中,Ri是mi的最坏响应时间,通常对于任意的周期消息来说,其截止时间就是周期,即每个消息都需要在其周期内响应,否则该消息响应失败.
本文在优先级约束中引入RM调度[9]约束,即周期小的帧的优先级高于周期大的帧的优先级,该约束定义如下:
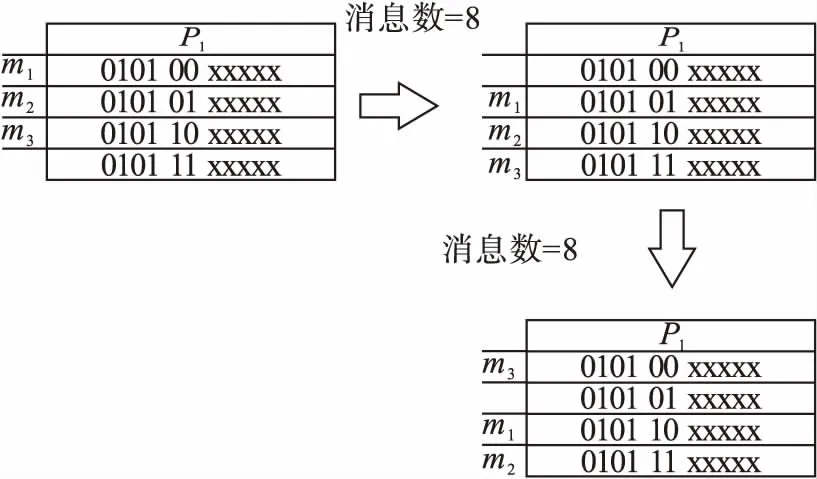
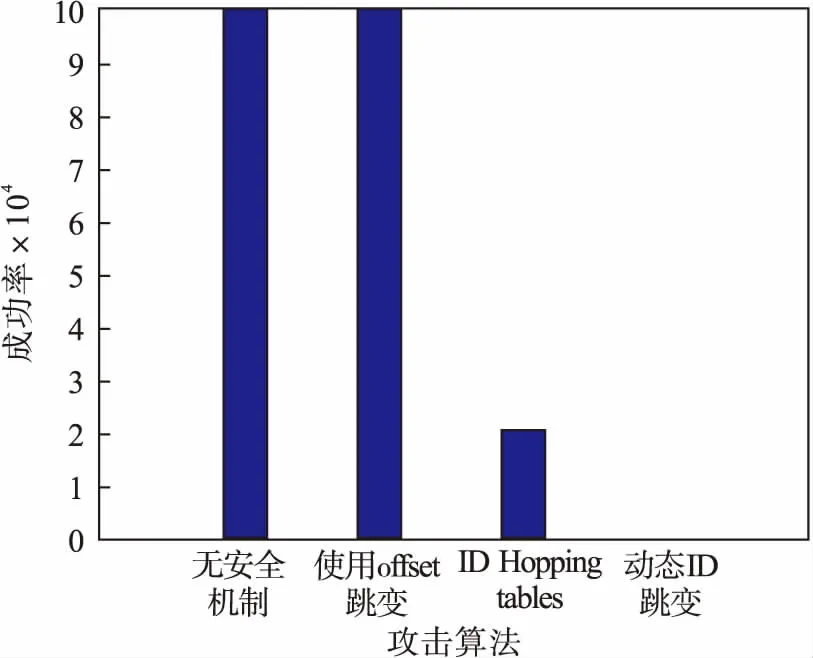
Ti (6) 其中,对于帧mi,mi′,如果有Ti>Ti′,则有pi hpi,i′+hpi′,i=1,∀mi,mi′,i≠i′; (7) hpi,i′+hpi′,i″-1≤hpi,i″,∀mi,mi′,mi″,i≠i′,i′≠i″. (8) 对于可调度系统,调度性能的指标主要是系统的冗余度,其最坏响应时间越小,冗余的时间越多,则系统的调度性能越好,即系统具有更好的鲁棒性,目标是最优调度策略,即系统的冗余时间越多说明调度性越好,并通过最坏情况响应率WCRR[10](worst case response rate)进行说明,这样就可以得到如下目标函数: (9) 其中:Ri代表消息mi在本周期的最坏响应时间;Ti是消息mi的周期.可调度的系统每个消息都满足WCRRi<1,若有任一消息WCRRi>1,则该消息不满足实时性,即不可调度. 2.2.1 初始化种群 本文采用实数形式构建染色体编码,每个染色体编码代表一个排序方案,染色体上每个基因位置代表任务的优先级.每个实数编码只能取一次不能重复,即一个染色体内不能出现两个相同的实数.实数编码的取值范围为1到N(N为数据集内帧的个数).据RM调度可知周期越小的帧的优先级越高,即代表优先级的实数p越小.初始化个体实例如图5所示,假设有12个帧进行固定优先级的计算,其中{m9,m11}的周期都为T1,m8的周期为T2,m10的周期为T3,{m1,m2,m3,m4,m7,m12}的周期都为T4,m5的周期为T5,m6的周期为T6,并且T1 2.2.2 适应度函数 适应度函数用以评价固定优先级顺序的优劣,由截止时间和最坏响应时间的差值来体现,差值越大,代表冗余度越多,即调度性能越好;另一种表现调度性能的形式是最坏情况响应率WCRR(式(9)).由于初始化和交叉后的种群也是根据周期大小的顺序进行优先级排序的,所以只要数据集是满足可调度的,那么每一个帧的截止时间一定是小于其周期的,否则输入的数据集就是不可调度的,计算会没有意义. 图5 个体实例 2.2.3 选择运算 遗传算法的选择方式有很多种,一个合适的选择方式可以直接影响到算法的性能,如果选择后导致个体的多样性降低会导致算法过早收敛到局部最优解,而选择后个体的多样化程度过高可能导致算法不容易收敛.本文选择的方式是在种群中通过轮盘赌的方式选N/2组个体,每组包含2个个体,然后保留适应度更好的个体,适应度较差的个体则淘汰. 2.2.4 交叉运算 本文采用实数编码方式,根据要求设计了一种基于周期分类的多点交叉方式,如图6所示.交叉的过程是在每个周期内选择随机的一个交叉点,将2个父代染色体每个周期的交叉点的后部分进行交换,由于编码中不允许有重复的基因码,所以子代还需依次把父代的剩余编码按顺序保留. 图6 交叉示意图 2.2.5 变异运算 本文采取的变异方法是在一个染色体上每个周期范围内任取两点,然后通过交叉概率判断是否进行交叉,如果进行交叉,将这两点之间的基因互换得到新的染色体. 2.2.6 终止条件 本文采用的是设置最大迭代次数来终止算法,当算法运行结束后就可以得到一个全局最优解. 2.3.1 优先级可妥协范围 每个帧的优先级可妥协范围用FB(fb_high,fb_low)表示,fb_high表示每个帧的可妥协优先级的上界,fb_low表示每个帧的可妥协优先级的下界.每个帧在其妥协范围内选择任意1个优先级发送,不会影响整体的可调度性. 求各帧在最优调度情况下的可妥协范围,将式(2)替换为 Wi=maxmax{PG(j)}≥min{PG(i)}tcj+ (10) 这表示一个帧mi会被另外一个帧mj所延迟,而帧mj的可妥协上界必须要大于帧mi的可妥协下界.需添加如下约束: pi (11) 表示帧mi′的优先级可妥协范围可以在i与i″之间滑动. 2.3.2 优先级分组 根据优先级可妥协范围,帧的优先级可以改变,不会造成系统不可调度.根据每个帧的优先级可妥协范围把妥协范围相近的帧合并到一组集合内,在这个集合内很多的帧的优先级范围可以相互覆盖,在发送时,该集合内的帧以集合范围内的任一优先级发送不影响系统的可调度性,则称集合为优先级分组集合(priority grouping,PG).每一个PG内的所有帧拥有相同优先级上下界PG(pg_high,pg_low).满足以下约束: fb_highi≤pg_highk,fb_lowi≥pg_lowk,∀mi∈PGk, (12) pg_highk-pg_lowk+1=num(PGk) ,∀PGk, (13) PG(mi)≠PG(mj),∀mi∈PG,mj∈PG . (14) 即每个优先级分组集合的范围都满足该集合内每个帧的优先级可妥协范围,而每个帧的优先级可妥协范围满足可调度性.不同组的优先级互相没有交集,每一个帧只属于一个优先级分组.每个分组内帧的数量与优先级的数量必然相等. 表1是优先级分组算法的具体过程,本算法的核心是不停地在一个组中寻找覆盖最大帧的集合. 表1 算法1 优先级仲裁在标识符的前部分,将ID段分为用于区分优先级的部分和进行混淆跳变的部分,其中包括以下三部分: 1) PID:用以区分优先级分组集合的优先级,分组内的所有数据帧共用同一个PID,PID位数是由优先级分组集合的个数所确定: 2n-1≤α≤2n-1 . (15) 其中:α代表优先级分组的数量;n为PID所需的位数. 2) UID:优先级分组帧集合内每个数据帧分配独一的ID, UID不同代表优先级不同,同一分组集合内的帧进行UID跳变,即实现优先级跳变,使用同步循环机制进行跳变.UID位数由式(15)确定. 3) DID:通过对称加密算法进行动态跳变混淆,每发送一次数据帧,该数据帧的收发双方的DID同时使用相同的密钥进行跳变,且保证优先级不改变,实时性不改变. 3.2.1 优先级跳变 前文提到数据帧在妥协范围内以任意优先级进行发送不会破坏系统的可调度性,而后形成一个优先级分组集合PG,分组范围具有上下限,组内数据帧都满足范围的上下限,范围内的帧进行优先级跳变.以表2所示的5个数据帧解释优先级跳变. RM调度规定周期越小的帧优先级越高,由于帧的数量较少,可以轻易计算出固定优先级和优先级分组集合.如表3所示,帧m1,m2,m3可以形成一个PG集合P1={m1,m2,m3},帧m4,m5可以形成一个PG集合P2={m4,m5},其中P1内所有数据帧的优先级高于P2内所有数据帧的优先级. 表2 帧的参数 表3 帧优先级可妥协范围 对于表2的数据,由式(15)可知2个优先级分组只需要1位PID就可以决定,但是实际上总线上数据帧最后形成的分组大约在12个,用4位的PID决定分组优先级,优先级分组集合内的数据帧的最大数量必小于UID位数可决定的数量,这里分组集合内数据帧的数量的最大值是3,所以用2位ID区分,ID段剩余5位用作DID进行动态跳变. 优先级跳变流程如图7所示,计算每个帧的固定优先级,根据WCRT判断可妥协范围,得到优先级分组集合.为每个优先级分组分配PID与UID,图7中PID分为两个优先级分组集合P1={m1,m2,m3}和P2={m4,m5},集合P1的PID1为0101,集合P2的PID2为1010,PID1的值小于PID2的值,集合P1的帧仲裁一定胜过P2,满足实时性. 为节点分配初始标识符后,需要同步控制器控制优先级跳变,即UID的改变.本文的优先级跳变机制将通过改变每个帧的UID,使UID表在规定时间向下移,即UID+1,如图8所示,当m3的UID移动到11时,此m3的优先级是低于m1和m2的,当优先级再次移动时,由于m3的UID为11加1后变为00,这样m3的优先级就高于m1和m2了,即m3的优先级覆盖了m1的优先级,进行了优先级的跳变. 图7 UID跳变策略 优先级跳变(UID跳变)的时间由消息计数器(message counter)确定,本文使用ACK应答信号作为优先级跳变标志,当发送了8个ACK信号,UID表自动向下跳变. 图8 优先级转换 当帧的优先级发生改变时,攻击者无法区分每个帧的具体优先级,攻击者不能将某一个优先级判定为具体的功能,增加破解系统的复杂程度. 3.2.2 DID验证算法 本文使用对称加密进行DID的动态跳变,一个会话的接收方和发送方都有着相同的会话密钥(group session key,GSK),用作DID的加密生成.输入DID,生成的密文作为新的DID,不需要解密,保证收发双方同时加密,生成的密文一致,满足收发双方同步.具有会话密钥的ECU每次发送数据帧都会生成一个新的一次性密钥(one-time key,OTK),DID通过一次性密钥生成新的DID作为下次发送数据的ID,本文使用HMAC[11]生成DID. 3.2节使用UID进行优先级跳变,但跳变只在一段时间发生一次,跳变后还将维持到静态配置,攻击者可以通过这段时间破解系统.本文在此基础上进一步增强系统防御性,使用NAS方案,即最高频率的更改ID. 3.3.1 数据帧发送与接收 发送数据帧时,使用DID进行一次性动态跳变混淆攻击者,呈现无规律状态,DID改变频率为1,用后即改变频率(如图9所示),使用单向散列函数和对称密钥进行DID的跳变,攻击者无法通过计算得到. 发送数据帧:发送ECU通过前一次生成的会话密钥(GSK)和帧计数器生成新的一次性密钥(OTK),每次更新DID后其一次性密钥发生改变,根据OTK生成新的会话DID,发送时使用新生成的DID,当发送成功后,再次通过散列函数计算新的DID作为下次发送的ID. 图9 接收方和发送方DID跳变 根据GSK生成新的一次性密钥[12]: HGSKk(OTKi-k||CTRe-j)=OTK(i+1)-k; (16) 根据OTK生成新的DID: HOTK(i+1)-k(DIDi-k||CTRe-j)=DID(i+1)-k. (17) 接收数据帧:接收方在接收数据之前,通过已经接收到的 DIDi、新鲜度CTRe和会话密钥生成的一次性密钥OTKi+1生成新的DIDi+1,会话发送方的DID和接收方的DID通过散列函数保持一致,从而数据可被接收,此时接收方的帧计数器加1,改变新鲜度. 3.3.2 身份认证与密钥分发 DID动态跳变进行通信的发送方和接收方都保存着相同的密钥,由网关ECU分发(如图10所示),支持密钥更新.密钥导出通过HKDF(HMAC-based extract-and-expand key derivation function)[13]实现,HKDF是一种基于HMAC的密钥衍生函数,其主要规范如下: GSKk=HKDF(Seed,t,P). (18) 输入一个随机的种子Seed,一个迭代次数t,一个口令p,函数成功终止后可以得到一个密钥K. 图10 密钥分发流程 3.3.3 同步机制 如图11所示,本文在DID跳变过程中可能造成发送方与接收方ID不同步,接收方若长时间没有接收到发送方的消息,则判断ID失去同步,接收方向发送方发送Auth Fail信号请求同步,当发送方读取到Auth Fail信号后,发送方向接收方广播当前的经过加密的计数器与会话密钥,接收方接收到发送方的数据后根据自己的数据进行MAC认证,如果不一致则向发送方请求同步数据. 图11 密钥同步 实验所用数据集参数由标准数据集SAE benchmark产生,本次实验收集了带宽利用率从10%到76%的多组测试数据(见表4).默认周期和截止时间相等,数据长度从0到8 B,抖动时间范围从0.1 ms到1.7 ms. 表4 数据集大小 实验主要测试数据为带宽利用率76%的数据集,周期分布如表5所示,其中比例指当前周期的测试数据数量占总测试数据数量的百分比. 表5 周期分布 本次实验进行了多组数据结果的分析,从10%带宽利用率的数据集到76%带宽利用率的数据集,经过不同数据集对比WCRR,如图12所示.当数据量较小时,遗传算法和RM调度算法计算固定优先级得到的目标值相差较小,输入信号的带宽利用率越大时,即信号更多,经过基于遗传算法的固定优先级调度的优化后,其效果越明显,这表明遗传算法在大规模数据计算中可以得到优秀的全局最优解. 图12 优化效果对比 4.2.1 安全参数 优先级分组算法输出安全参数N_aver,含义是一个帧可以选择的优先级的平均数,用以计算算法对伪造攻击与重放攻击的防御能力,N_aver表示为 (19) 其中:pgi表示第i个优先级分组集合内帧的数量;N为数据集内帧的数量. 如图13所示,通过对不同数据集的多次实验结果分析可知,帧的数量越多,平均每个帧可以分配的优先级数量越多. 图13 N_aver结果 4.2.2 安全性分析 使用ID Hopping方法防御攻击关键在于ID的接收原理,即攻击者需要猜测出正确的ID,使得攻击者的帧可以被接收节点所接受.没有ID Hopping机制的CAN总线破解的概率为 (20) 使用offset进行ID Hopping破解的概率为 (21) 使用ID跳变表的IDHCC的概率为 (22) 本文所提算法被破解的概率由DID的长度lDID决定,lDID越大则系统的安全性越强. (23) 实际总线传输的数据帧的个数Num_IDs为120个左右,P_offset由当前系统使用的ID最大值决定,因为ID跳变后不能超过CAN总线ID的范围.Table_nums为16,这是因为CAN数据帧的ID为11位,其范围是0x000~0x7FF,对于总线上的120个帧可以分为16份,lDID代表DID的长度,经多次计算,如果使用11位ID,PID长度为4,UID长度为3,DID长度为4,N_aver为同一优先级分组集合内帧的数量,这个值就是安全参数N_aver. 图14展示几种算法的被攻击成功率的对比情况,其被攻击成功的概率越小,安全性越高.可以看出,本文中提出的动态ID跳变安全调度算法具有较高的安全性,其效果远远好于其他ID跳变机制,可以有效地抵御伪造攻击与重放攻击. 图14 不同算法被攻击成功率对比 本文结合了CAN总线固定优先级调度,设计了一种优先级跳变机制,改变了传统的静态跳变方式,将通过散列函数进行一次性标识符动态跳变的方式引入到实时调度算法中.实验结果和安全性分析表明,该机制能在不增加负载开销的情况下,有效防御伪造和重放攻击等多种攻击手段,安全性能优于现有方法.在未来的工作中,将通过改进算法,使其UID数量减少,增加DID数量,从而进一步提高安全性能,例如切割数量较多的优先级分组集合.2.2 基于遗传算法的最佳固定优先级


2.3 优先级决定算法(PBD)
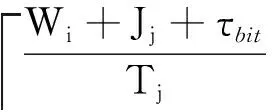

3 ID段重构与动态ID Hopping
3.1 重构ID段
3.2 优先级跳变与验证算法



3.3 动态ID生成



4 实验对比与安全性分析
4.1 遗传算法实验评估



4.2 安全性分析




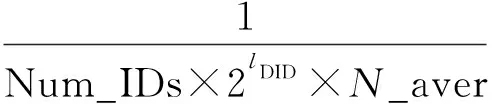
5 结 语
猜你喜欢
现代电子技术(2022年11期)2022-06-14故事作文·低年级(2022年2期)2022-02-23故事作文·低年级(2022年1期)2022-02-03汽车工程(2021年12期)2021-03-08北京电子科技学院学报(2020年2期)2020-11-20电子制作(2019年16期)2019-09-27电子制作(2019年24期)2019-02-23小型微型计算机系统(2018年9期)2018-10-26爱你·心灵读本(2018年6期)2018-09-10爱你(2018年16期)2018-06-21
