
申威架构下的软件平滑嵌套页表
2022-04-06 06:58杜翰霖罗英伟汪小林王振林
计算机研究与发展 2022年4期
沙 赛 杜翰霖 罗英伟 汪小林 王振林
1(北京大学计算机科学技术系 北京 100871)
2(鹏城实验室 广东深圳 518000)
3(密歇根理工大学 美国密歇根州霍顿市 49931)
(ss_boom@pku.edu.cn)
申威处理器采用自主指令集,是我国具有完全自主知识产权的处理器系列[1].初代申威指令集是在Alpha指令集的基础上进行扩展的,但经过不断发展与完善,现在已经成为独立的自主可控的指令集.申威处理器最为典型的应用场景是我国自主研发的神威·太湖之光超级计算机.太湖之光超级计算机搭载了40 960个申威26010众核处理器,其性能十分优越,已蝉联多次全球超算冠军[2].申威架构的应用除众核超级计算机之外,还有多核服务器,如申威1621服务器.本文的研究工作主要针对1621型服务器展开,探讨申威处理器上高效的内存虚拟化解决方案.该解决方案依托申威架构特性,并适合在同一架构下的多种型号的服务器上进行推广.虚拟化技术是云服务产业的核心支持技术之一,可以有效提高物理资源的利用率和系统的安全性[3-4].申威架构下的虚拟化解决方案并不完善,仍处于发展阶段.经过近年来的不断发展,申威架构已经形成了基本的虚拟化框架.虚拟化技术分为3个主要方面:CPU虚拟化、内存虚拟化和I/O虚拟化[3].申威在CPU虚拟化和I/O虚拟化已经有了较为完善的解决方案.而内存虚拟化方面,当前申威虚拟机采用固定大小的预留段式内存进行直接映射,虚拟机使用固定的物理内存空间,虚拟机的数量及整个物理机内存的使用极其受限,并不是真正意义上的内存虚拟化[5].计算机系统中,CPU访问内存首先需要进行地址转换,即虚拟地址转换成物理地址.非虚拟化环境下只需要1维地址转换.当前申威虚拟机的内存访问和非虚拟化环境下相似,只是一种权宜的解决方案.
作为最为复杂的虚拟化技术,内存虚拟化需要完成2维(2D)地址转换,即客户机虚拟地址(guest virtual address, gVA)到客户机物理地址(guest physical address, gPA)再到宿主机物理地址(host physical address, hPA)的转换(gVA→gPA→hPA).现有的内存虚拟化解决方案主要包括3类:影子页表(shadow page table, sPT)模型、嵌套页表(nested page table, NPT)模型以及直接页表[3].前2种属于完全内存虚拟化,虚拟机操作系统无需做任何修改;第3种属于半虚拟化,需要修改虚拟机操作系统的源代码.
本文工作主要针对完全虚拟化解决方案.影子页表模型属于软件内存虚拟化,不需要硬件支持.该模型的主要思想是采用一个页表(即影子页表)来直接保存客户机虚拟地址到宿主机物理地址(gVA→hPA)的映射.在虚拟机进行地址转换过程中,内存管理单元(memory manage unit, MMU)直接加载当前进程的影子页表,加速2级地址转换.影子页表依赖写保护机制来同步客户机页表(guest page table, gPT)和影子页表(sPT),这种模式造成了严重的虚拟机退出(VMExit)开销.
嵌套页表模型属于硬件辅助内存虚拟化,需要有专门的硬件支持,其代表有Intel拓展页表(extended page table, EPT)和AMD嵌套页表,两者在原理和实现上基本一致[6].嵌套页表保存了虚拟机物理地址到宿主机物理地址的映射关系.嵌套页表模型的核心思想是MMU加载虚拟机进程页表,在页表查询(page walk)的过程中,从进程页表中获取虚拟机物理地址,然后立即访问嵌套页表,转换成宿主机物理地址,再进内存访问.嵌套页表模型实现了地址转换过程中的2维页表代换,避免了影子页表模型因同步产生的开销.然而64位机器在不开启大页机制的情况下,都具有4级页表结构.嵌套页表模型会导致1次地址转换中存在远超非虚拟化环境下的多次内存访问.若无硬件辅助支持,嵌套页表模型在1次2维页表查询过程中需要24次访存[7-8].因此,处理器采用必要的硬件进行辅助加速.硬件主要包括页表查询缓存(page walk cache, PWC)和嵌套旁路转换缓存(nested translation lookaside buffer, NTLB).PWC缓存了页表项(包括页表物理页帧号和页内偏移)为索引、次级页表页物理页帧号为值的映射.PWC可以减少页表查询产生的访存次数[9].NTLB通过缓存gPA到hPA的映射来优化4级嵌套页表的查询[6].虽然NTLB可以有效减少嵌套页表查询的访存次数,但是NTLB的大小十分有限,尤其是对于访存局部性较差的程序,系统就会产生较多的NTLB miss,2维4级页表的嵌套查询仍会造成显著的性能开销.
目前申威架构缺乏嵌套页表所需的硬件辅助,因此,难以实现传统意义上的嵌套页表模型.幸运的是,申威架构具有独特的特权程序可编程接口(hardware mode code, HMcode),提供了底层软件灵活性[10].在HMcode中,系统开发者可以通过软件实现丰富的类硬件支持,特别是虚拟化支持,如虚拟中断、虚拟机退出/陷入(VMExit/VMEntry)等.基于申威架构这一特性,本文实现了申威架构下的平滑嵌套页表模型(swFNPT).该模型通过纯软件的优化,弥补了申威架构硬件不足的缺点,实现了申威处理器上真正意义的内存虚拟化.
1 相关工作
申威处理器现有的内存虚拟化方案采用了预留内存的直接映射模型实现虚拟机的内存访问.该模型要求宿主机将物理内存进行预留,仅虚拟机可使用这部分内存.因为直接使用“基址+偏移”的方式进行1维地址转换,这种设计不存在额外的内存虚拟化开销.然而,这种实现既不符合内存虚拟化的理念,在资源使用上也存在着资源利用率低、灵活性差等问题.
Gandhi等人[7]也提出通过直接映射模型加速虚拟化环境下的地址转换,从而减少页表访问带来的开销.他们先是在非虚拟化环境下,针对大工作集程序实现了一种段式内存映射,然后将这种方案拓展到内存虚拟化当中.他们为1个虚拟机申请充足的连续物理内存,该虚拟机的地址转换就变成了简单的段基址加偏移,这样直接避免了4级页表的访问,提高了转换效率.但是,这种直接映射要求虚拟机的物理内存是连续的,这可能导致一些内存资源的损失,降低了内存利用率;另一方面,这种设计直接丧失内存虚拟化带来的灵活性,不能够根据应用的需要调节虚拟机的内存,也难以细粒度地进行内存管理.这种设计也难以和现有的一些虚拟机功能有效兼容,比如虚拟机热迁移.
Ahn等人[11]提出将4级嵌套页表改为1级嵌套页表,即平滑嵌套页表(flat nested page table).该设计将2维嵌套页表查询最坏情况下需要24次访存缩减到最多9次访存.该设计保留硬件辅助虚拟化支持,是通过全功能模拟器进行评估,由于进行了必要的硬件改造,无法在真机上实现.HMcode恰好为申威处理器实现这一设计提供了条件.本文吸收了该工作的思想,在申威架构下实现了平滑嵌套页表来缓解页表查询压力.
采用大页机制可以有效缓解嵌套页表查询压力.因为使用大页可以将4级页表缩短为3级甚至2级页表,加快了页表查询的速度.同时每个映射都具有更大的映射空间,TLB miss率也会显著下降.然而,大页机制存在着碎片化严重、资源浪费、灵活性差、不支持虚拟机热迁移等诸多问题.针对这些问题,研究者们提出了一系列的解决方案来缓解大页机制带来的弊端.Guo等人[12]在VMware上提出了主动积极拆分大页的技术方案来缓解大页导致的内存资源浪费问题;针对大页机制不适应于NUMA架构的问题,Gaud等人[13]提出了改良版的Carrefour算法来保障大页机制在NUMA架构上的性能;Pham等人[14]则提出了一种推测式大页机制来进行大页的轻量级管理.
研究者们在内存虚拟化领域进行诸多尝试与探索,取得了一系列丰富成果.然而一方面,一些方法需要依赖一定的硬件改造;另一方面,由于申威架构的特殊性,针对申威架构的内存虚拟化工作还存在很大的空白.本文借鉴吸收国内外先进的研究经验,提出了首个申威架构下的纯软件的嵌套页表内存虚拟化解决方案.
2 申威虚拟化框架
本节主要介绍申威架构虚拟化框架的相关实现,主要包括申威架构CPU特权级模型、虚拟化模型支持以及申威HMcode.
2.1 申威CPU模式
如图1所示,申威CPU具有4个特权模式,由高到低分别是硬件模式(L-0)、虚拟模式、核心模式(L-1)以及用户模式(L-2).特有的HMcode运行在最高权限的硬件模式.该接口主要用于代替部分硬件功能,这些功能用硬件实现过于复杂,而又无法用常规程序实现,例如页表代换、进程上下文切换、TLB刷新等;也用于实现一些原子操作和一些兼容不同平台的代码.虚拟模式暂未启用;核心模式类似于X86架构的内核模式,操作系统运行在该模式下;用户模式具有最低的特权级,用户程序在该模式下执行.其他非硬件模式都可以通过受限的系统调用(syscall)调用硬件模式下的特权指令实现一些底层支持.
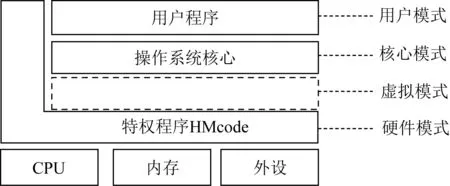
Fig. 1 The privilege modes of Sunway CPU图1 申威CPU特权模式
2.2 申威虚拟化模式
如图2所示,申威CPU具有和Intel X86 VT-X根/非根模式(root/non-root mode)类似的虚拟化模式.宿主机和客户机分别在根/非根模式下运行,但两者都具有核心模式和用户模式.宿主机操作系统及虚拟机管理器(virtual machine monitor, VMM,也称hypervisor)运行在根模式下的内核模式特权级.VMEntry实现根模式到非根模式的切换,VMExit实现非根模式到根模式的切换.例如,虚拟机触发时钟中断处理时,虚拟机触发1次VMExit.首先,系统保存客户机上下文信息,其中包括主要的CPU寄存器状态、栈指针、欲执行的指令地址(PC)等.然后系统恢复宿主机上下文信息,陷入VMM进行时钟同步处理;处理结束后,CPU触发VMEntry,恢复虚拟机上下文信息,进入虚拟机,继续执行指令.和X86不同的是,申威架构具有最高权限的硬件模式,该模式不受根/非根虚拟化模式的限制,任何模式都可以通过受限的系统调用陷入硬件模式.

Fig. 2 The virtualization mode of Sunway CPU图2 申威CPU虚拟化模式
2.3 申威特权程序可编程接口(HMcode)
HMcode运行在最高特权的硬件模式(如图1、图2所示),该接口处于内核和硬件之间,属于固件.代码保存在flash部件中,形式上类似于RAM BIOS.特权程序可以以物理地址直接访问全局地址空间,也可以直接访问寄存器.特别地,申威架构是软件管理的TLB,这为实现内存虚拟化提供了必要支持.TLB miss之后,特权入口TLB_MISS_ENTRY接管TLB miss处理,进行页表查询和TLB填充.我们在TLB_MISS_ENTRY中实现嵌套页表的相关逻辑,具体实现在第3节进行详细阐述.HMcode为上层应用提供丰富的系统调用接口,但不同CPU模式具有不同的调用权限,例如内核进程可使用如进程上下文切换、读寄存器、TLB刷新等功能的系统调用;而用户进程无法使用此类内核级调用.
3 申威架构下的软件平滑嵌套页表
3.1 传统内存虚拟化模型
现有的完全内存虚拟化模型包括影子页表模型和嵌套页表模型.图3展示了2种模型的工作原理.

Fig. 3 The principles of shadow page table model and nested page table model图3 影子页表模型和嵌套页表模型原理
图3(a)是影子页表模型的工作原理.VMM为每个虚拟机进程建立一套影子页表,用于保存客户机虚拟地址到宿主机物理地址之间的映射.在地址转换过程中,一旦发生TLB缺失,CPU触发页表查询过程.实际加载到页表基地址寄存器CR3中的是影子页表基地址,所以MMU对影子页表进行页表查询.影子页表模型的优点是通过1维页表缓存2维地址转换,提高了地址转换的效率.然而,VMM需要维护影子页表的正确性,一旦客户机操作系统修改了客户机进程页表,影子页表也需要进行相应的修正.这就是影子页表模型最大的开销所在,即如何同步客户机进程页表和影子页表.客户机修改进程页表不是系统级事件,VMM无法感知这一操作.传统的方式是写保护机制,VMM对所有的客户机进程页表页施加写保护,一旦进程页表页被修改,就会触发写保护错误,进而触发VMExit而陷入VMM.所以,影子页表模型的缺点就是不适应于高频页表修改的应用程序(如gcc).过度的页表修改会导致大量的VMExit,每一次VMExit/VMEntry都需要TLB清空、上下文切换等操作,开销十分显著.
图3(b)是嵌套页表模型的工作原理.嵌套页表模型的基本思想是通过嵌套页表保存gPA到hPA的映射,虚拟机在进程页表查询时获取gPA,然后访问嵌套页表进行第2维的地址转换(gPA→hPA).相较于影子页表模型,嵌套页表模型消除了因为影子页表同步造成的虚拟化开销,并且有效降低了内存虚拟化的复杂程度.然而,嵌套页表模型会导致更多的页表查询开销.64位系统具有4级页表,每一级进程页表查询都需要进行1次嵌套页表的查询,每一级嵌套页表的查询都需要1次访存操作.页表基地址寄存器(CR3)、4级进程页表及数据页地址各1次转换,因此在无硬件辅助支持的条件下共需24次访存[15].为了缓解这一开销,研究者们提出了NTLB的硬件部件,用于直接保存第2维的地址映射,其基本功能等同于CPU TLB.因为是硬件部件,因此具有极高的查询效率(数个CPU周期).NTLB可以显著提高嵌套页表的查询效率.
但是,目前的申威芯片仍处于不断发展与完善阶段,很多相关的硬件支持(比如DMA等)均未实现,嵌套页表所需的相关硬件同样也未提供.硬件支持的缺乏意味着如果在申威处理器上实现嵌套页表模型,每次地址转换都需要24次访存,相较于非虚拟化环境的4次访存,显然这一开销是难以接受的.因此,我们改进了传统的嵌套页表模型,基于申威架构的HMcode,在申威处理器上实现了首个平滑嵌套页表的内存虚拟化解决方案.一方面为申威虚拟机实现真正意义的内存虚拟化,另一方面我们也希望通过这一方案为新一代申威处理器的硬件辅助虚拟化设计提供相应的理论和实验支持.
3.2 平滑嵌套页表
申威架构缺少硬件上的内存虚拟化支持,因此在地址转换开销上难以接受.为了解决这一问题,我们采用平滑(1级)嵌套页表机制来缓解开销.图4展示了平滑嵌套页表基本原理.平滑嵌套页表由一段连续的物理内存存储,任何对于该页表的查询都只需要根据“基地址+偏移”的模式进行访问.平滑嵌套页表以客户机物理页帧号(guest-physical frame number, GFN)为索引,其中每个条目保存着对应的宿主机物理页帧号(physical frame number, PFN).宿主机物理页帧号和客户机物理地址的页内偏移组成宿主机物理地址.相较于4级嵌套页表,访问1次平滑嵌套页表仅需要1次访存,整个2维嵌套页表查询最多需要9次访存.然而平滑嵌套页表的设计需要重构查询嵌套页表的MMU,这在X86服务器上无法实现.而申威架构HMcode提供了底层支持的软件可编程性,我们可以在HMcode中软件编程实现嵌套页表所需的一些底层支持.

Fig. 4 The principle of flat nested page table图4 平滑嵌套页表原理
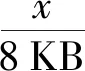
3.3 基于申威架构的平滑嵌套页表设计
平滑嵌套页表模型主要分为3部分:页表初始化、页表查询和页表缺页处理.当前的申威服务器以QEMU/KVM为基本虚拟化框架,底层的页表查询模块实现在HMcode中.平滑嵌套页表将依托于申威架构特性来设计,图5展示了申威架构下平滑嵌套页表的基本框架.

Fig. 5 The framework of flat nested page table under Sunway architecture图5 申威架构平滑嵌套页表框架
1) 平滑嵌套页表的初始化.VMM需要根据虚拟机的物理内存大小来申请相应的连续内存保存平滑嵌套页表.
2) 平滑嵌套页表的查询.查询平滑嵌套页表的MMU(FNPT MMU)应实现于HMcode.目前申威的MMU是以软件形式实现在HMcode中.Software MMU在访问每一级客户机进程页表时需要通过FNPT MMU访问平滑嵌套页表将gPA转换成hPA.
3) 平滑嵌套页表缺页处理.FNPT MMU查询页表时可能触发缺页中断,通过VMExit接口进入VMM中进行缺页处理.缺页处理结束之后,通过VMEntry接口重新进入客户机完成地址转换.
3.4 平滑嵌套页表在申威下的软件实现
我们在申威1621服务器上实现了平滑嵌套页表模型.在虚拟机运行过程中,CPU根据客户机虚拟地址查询TLB进行地址转换.系统发生TLB缺失,立刻陷入TLB缺失处理入口进行TLB缺失处理.MMU加载客户机进程页表开始进行2维页表查询,客户机进程页表保存了gVA到gPA的映射关系,每一级页表的页表项都保存了1个客户机物理页帧号和对应的权限位信息.首先,MMU访问FNPT MMU尝试将进程页表基地址(gPA)转换成hPA;然后,4级进程页表的每一轮查询都需要访问FNPT MMU将gPA转化成hPA;最后,MMU将gVA到hPA的映射使用软件填充TLB.至此,1次虚拟化环境下的地址转换完成.
在嵌套页表模型中,系统可能发生2种缺页中断:1)客户机进程页表不完整导致的缺页中断;2)嵌套页表不完整导致的嵌套页表缺页中断.当MMU查询客户机进程页表时,会检查页表项的权限位,若有效位为0,则触发1次客户机缺页异常处理,系统进入虚拟机内核缺页处理程序进行缺页处理,填充进程页表.缺页中断处理结束后,系统再次执行产生TLB miss重新开始地址转换.当FNPT MMU查询平滑嵌套页表时,有可能发生缺页中断,此时触发1次嵌套页表缺页处理.
系统通过VMExit接口进行上下文切换,CPU进入VMM进行嵌套页表缺页处理.首先根据传入的GFN调用_gfn_to_pfn_memslot()接口将GFN转化成对应的PFN.该接口首先将虚拟机物理页帧号转化成宿主机虚拟页号,因为虚拟机物理地址空间和虚拟机管理进程(QEMU进程)的虚拟地址空间都是连续的,因此两者之间通过“基地址+偏移”的方式直接转换;其次,该接口查询宿主机进程页表,将虚地址转化成物理地址;最后VMM以GFN为索引,将对应的PFN插入嵌套页表.至此,1次嵌套页表的缺页处理完成,VMM调用VMEntry接口切换上下文,重新陷入虚拟机,CPU再次执行产生TLB缺失的指令,重新进行地址转换.
4 实验与分析
4.1 实验环境
我们在真机环境下评估了申威架构下的平滑嵌套页表模型.实验组物理机是申威1621服务器,该服务器具有16个物理核心,主频约为1.6 GHz,搭载深度操作系统15.02.对照组物理机是基于X86架构的Intel服务器,主频约为2.1 GHz,搭载的是Ubuntu 16.04服务器版操作系统.具体参数如表1所示.
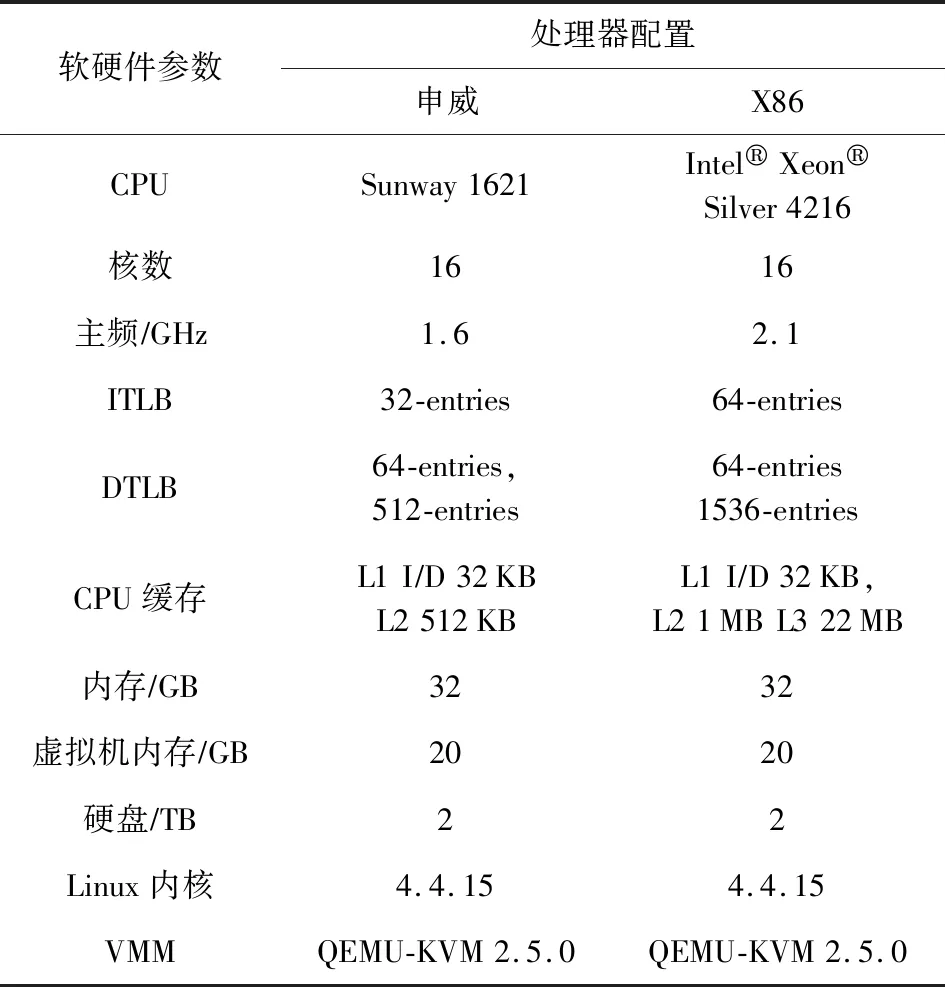
Table 1 Experimental Machine Configuration表1 实验机参数配置
4.2 实验设计
因为现有的申威服务器不具有真正意义的内存虚拟化功能,所以对照组机器选择相同软件配置的Intel X86服务器.在X86架构下,我们对影子页表模型(X86-SP)和拓展页表模型(X86-EPT)分别进行了测试.
嵌套页表模型需要预热处理(warm-up).在每轮测试程序运行前,需要首先运行一个较大工作集程序进行预热处理,保证嵌套页表完成缺页处理.若在虚拟机启动初期直接运行测试程序,系统会产生大量的嵌套页表缺页处理中断,降低程序性能.这种处理是考虑到云服务器的应用都具有较长工作周期,嵌套页表的缺页处理一般只发生在虚拟机启动前期,预热操作之后的实验结果更能体现虚拟机在一个长周期内的真实性能.
我们选择了SPEC CPU 2006,SPEC CPU 2017,Graph500,Memcached等应用作为测评程序.SPEC CPU 2006采用ref集进行测试.SPEC CPU 2006测试程序工作集普遍较小(均低于3 GB),为进一步验证模型的效果,我们从SPEC CPU 2017测试集中挑选了8个具有较大工作集的测试程序.表2展示了这8组程序的工作集信息.我们也选用了较为典型的云服务程序Memcached和Graph500测试swFNPT模型的性能.最后我们使用STREAM评估虚拟机系统内存带宽损失.
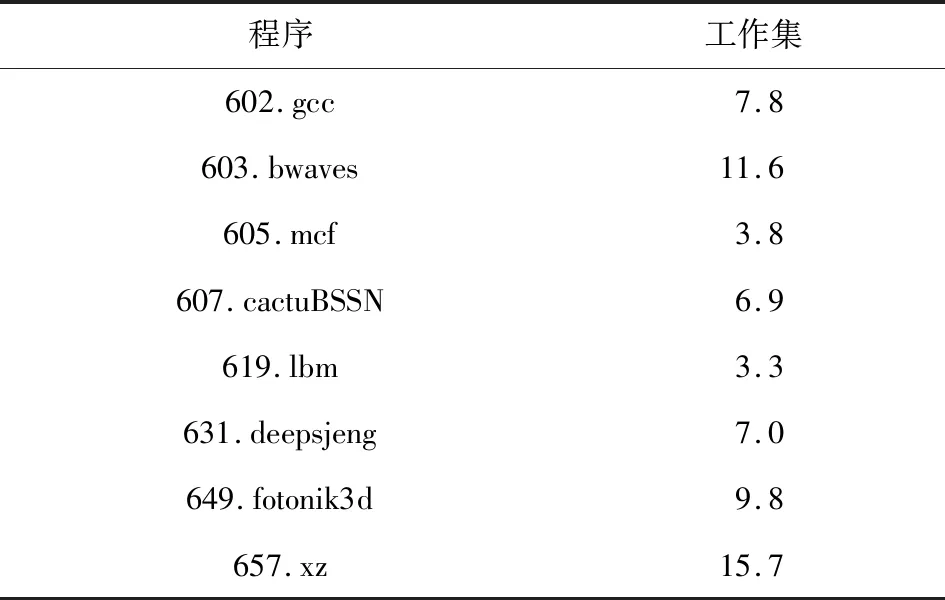
Table 2 Benchmarks of SPEC CPU 2017表2 SPEC CPU 2017测试程序 GB
4.3 实验结果及分析
4.3.1 内存虚拟化整体性能测试
SPEC CPU 2006测试集具有多个测试子程序,不同程序具有不同的访存特征,能够较为全面地反映系统访存性能.表3展示的是swFNPT,Intel X86-EPT,Intel X86-SP这3组模型使用SPEC CPU 2006测试集的实验结果.实验结果表明,适配swFNPT模型的申威虚拟机整体性能良好,SPEC CPU 2006全集平均性能开销仅为3.24%.申威服务器内存虚拟化与Intel X86下2组模型的平均性能开销基本相当.
如第3节所述,相较于传统的影子页表模型,嵌套页表的主要优点是消除了页表同步的开销.这一优点展现在具有频繁修改页表特性的测试程序(如403.gcc)上.如表3所示,基于嵌套页表的X86-EPT和swFNPT在403.gcc程序的开销均低于基于影子页表的X86-SP.
在SPEC CPU 2006的实验结果中429.mcf具有超过20%的性能开销.且X86架构下的Intel X86-EPT同样具有高达8.39%的虚拟化开销,但Intel X86-SP的开销低于5%,这是由该程序的访存特性所决定的.429.mcf是典型的局部性较差的程序,这导致该类程序的TLB缺失率高,MMU压力更大.在地址转换过程中,该类程序需要频繁进行页表查询操作.64位操作系统采用4级页表,基于影子页表模型的地址转换最多产生5次存储访问,考虑到PWC硬件支持,这一开销会更小[9].相反地,采用嵌套页表模型,无论是Intel EPT还是swFNPT都需要2维页表查询,这大大加剧了页表查询的开销.这一特性在之前的研究工作中也有明确体现.Pham等人[14]指出使用嵌套页表模型的虚拟化系统中运行429.mcf,地址转换在整个程序运行周期中占比高达40%.我们在Intel X86机器上通过硬件计数器统计地址转换开销并建模实验获得了近似的实验结果.此外,在非虚拟化环境下429.mcf仍有22%的执行时间用于地址转换.汪小林等人[16]的工作也明确指出429.mcf在使用嵌套页表模型时具有明显的内存虚拟化开销.

Table 3 Experimental Results of SPEC CPU 2006表3 SPEC CPU 2006测试结果 %
429.mcf实验结果表明,Intel X86-EPT比申威swFNPT内存虚拟化开销更小.这一差距主要原因分为2个方面:1)硬件支持(PWC,NTLB)和TLB;2)Cache容量.PWC和NTLB可以有效减少2维页表查询中的访存次数,申威服务器暂未实现这2个功能部件.尽管swFNPT将每次页表查询中的访存次数控制在9次,但是相较于具有硬件辅助的内存虚拟化实现,swFNPT平均的访存次数仍然较高.由表1可知,Intel服务器的1级TLB容量为申威服务器的2倍,2级TLB容量为申威服务器的3倍.Intel服务器的2级Cache容量为申威服务器的2倍,且Intel服务器具有第3级Cache.更大的TLB容量将大大降低程序的TLB缺失率,缓解MMU压力.更大的2级Cache容量将有助于提升地址转换中访存效率.
4.3.2 大工作集程序虚拟化性能测试
为进一步验证平滑嵌套页表模型的性能,我们在申威服务器上运行测试SPEC CPU 2017中8个内存用量较大的程序.实验结果如表4所示,平滑嵌套页表模型的平均开销仅为4.12%,最大开销不超过9.2%.这一实验结果说明该模型在较大内存压力的情况下仍有较好的性能.特别地,结合4.3.1节SPEC CPU 2006的实验结果,我们发现605.mcf程序虚拟化开销明显低于429.mcf程序的开销.这是因为后者局部性更差,这一特性也有相关研究给出[17].
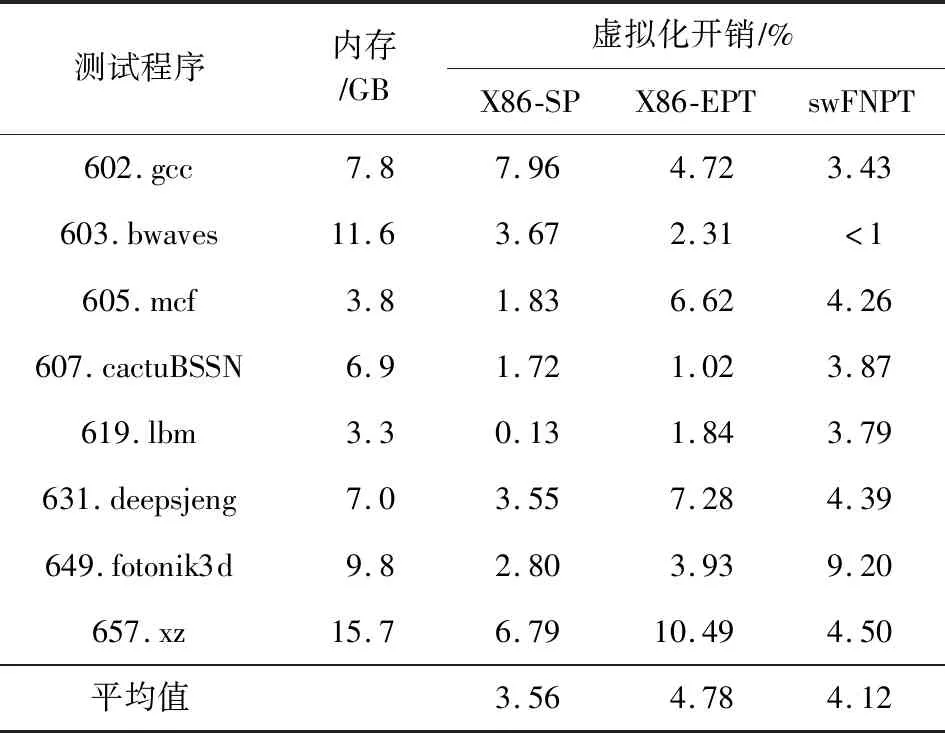
Table 4 Experimental Results of SPEC CPU 2017表4 SPEC CPU 2017测试结果
4.3.3 典型云服务应用内存虚拟化性能测试
表5展示了Memcached和Graph500的2组典型云服务应用的实验结果.Memcached使用memcslap脚本进行测试,其中并发参数为100;Graph500使用OpenMPI框架运行节点数为220.结果表明Memcached测试中,swFNPT和X86-EPT虚拟化开销均低于X86-SP.这是因为Memcached程序具有较为频繁的进程切换,而影子页表模型在进程切换时都需要产生VMExit进行页目录表寄存器的更新,开销较大.Graph500是较为典型的大规模并行程序,我们使用OpenMPI框架运行.该程序在Intel X86-EPT模型上的开销约为5%,在Intel X86-SP模型上开销约为6%,在swFNPT模型上开销低于8%.
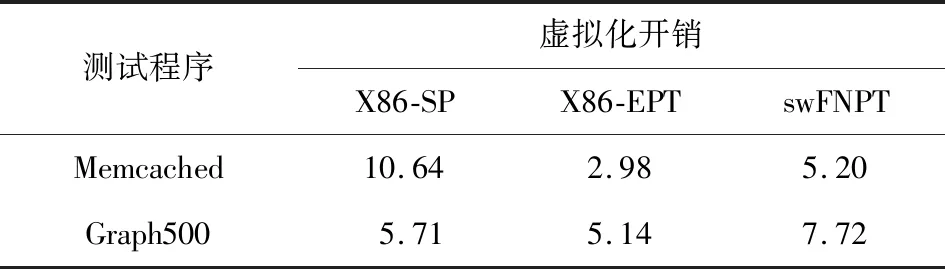
Table 5 Experimental Results of Memcached and Graph500表5 Memcached和Graph500测试结果 %
4.3.4 虚拟机内存带宽
STREAM是广泛使用的用于测试系统内存带宽的工具.我们使用STREAM 2.0测试了虚拟化系统中的内存带宽.试验结果表明,相较于非虚拟化环境,swFNPT产生的内存带宽损失低于3%.我们在相同的软件环境下分别进行了Intel X86-EPT和X86-SP的实验,带宽损失分别为2.88%和3.27%.
4.3.5 实验总结
4.3.1~4.3.4节的实验结果表明:swFNPT在大多数应用程序上表现良好,诸如400.perlbench等18个程序虚拟化开销均低于3%.特别地,401.bzip2,435.gromacs,603.bwaves等程序的虚拟化开销低于1%.SPEC CPU 2017的实验表明swFNPT模型在较大内存压力下也能表现出良好的性能.在内存带宽方面,STREAM测试结果表明swFNPT内存虚拟化造成的带宽损失不高于3%;Memcached和Graph500的实验结果表明,swFNPT在支持进程频繁切换和大规模并行方面表现良好.但是申威swFNPT在执行局部性较差的程序(如429.mcf)时虚拟化开销较大,这主要受限于申威服务器硬件支持上的不足,这一实验结果为申威服务器下一步的发展提供切实有效的实验支持.
5 总结与展望
本文在国产申威架构上设计实现了首个软件平滑嵌套页表模型swFNPT,在申威1621服务器上的实验结果表明,swFNPT整体性能良好.这一工作为国产申威架构的硬件辅助虚拟化下一步发展提供有价值的参考.一方面,申威架构处理器要不断完善MMU,NTLB,PWC等的硬件支持;另一方面,申威处理器要保留特权程序可编程接口以提供底层软件灵活性.结合NTLB等硬件支持,未来软硬件结合的swFNPT将更能充分发挥申威架构的独特优势.
作者贡献声明:沙赛进行了该论文相关的系统设计、代码编写、论文撰写等工作;杜翰霖进行了系统测试;罗英伟进行了论文结构设计和论文修改;汪小林制定了论文相关的实验方案;王振林参与进行了系统设计和论文修改.
猜你喜欢
电脑知识与技术·经验技巧(2018年2期)2018-05-21
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
大众理财顾问(2016年9期)2016-10-11
考试周刊(2016年72期)2016-09-20
网络与信息(2009年12期)2009-12-17
网络与信息(2009年12期)2009-12-17
计算机世界(2009年32期)2009-09-30
现代电子技术(2009年14期)2009-09-05
计算机世界(2009年21期)2009-07-30
