
面向知识图谱的语义有效性评价方法*
2022-04-07 03:42尚福华丁秋予蒋毅文杜睿山
计算机与数字工程 2022年3期
尚福华 丁秋予 胡 超 蒋毅文 杜睿山
(东北石油大学信息与信息技术学院 大庆 163318)
1 引言
知识图谱是目前被广泛使用的一种知识表示手段,知识图谱的图结构对知识实体及其之间的语义关系进行了形象的描述,从语义层面构建出完整的知识体系[1~2]。目前知识图谱的应用包括但不局限于知识问答[3]、语义检索[4]、个性化推荐[5],然而知识图谱能够在以上领域拥有卓越表现力的前提之一是能够进行合理的数据抽取,即本文所指的具有有效语义的数据。
业界关于数据语义评价的研究已有一定的成果,但是多为面向关系型数据库的语义评价[6~9]方向的研究,而知识图谱在存储方式、数据组织等方面,与传统的关系型数据库存在很大差异,故已有研究并不能完全适用于知识图谱的数据语义有效性评价。目前主流的知识图谱的数据层多以属性图模型为支撑存储在图数据库中[10],因此,对于知识图谱的数据语义有效性评估也应做出相应改变。
知识图谱中包含有大量的知识实体与关系[11],这为知识图谱的应用提供了有力支撑,然而也对面向众多的知识实体与错综复杂的关系进行数据语义有效性评价提出了更多的挑战:
1)Schema 层向数据层的映射问题,需要构建合理的映射机制实现Schema层向数据层的映射。
2)知识实体与关系数量庞大导致的知识检索问题。
3)面对知识图谱的语义有效性评价内容与评价方法。
综上,为了保证从知识图谱中获取到具有有效语义的数据,本文结合目前的研究成果,提出一种基于本体的知识图谱数据语义有效性评价方法,在从知识图谱中进行数据检索与抽取的阶段,于语义层面评价所获取数据的有效性,摒弃与目标内容关联度较低的知识实体,达到获得较高质量的数据的目的,从根本上降低由于数据质量问题而导致的后续工作误差。
2 相关工作
目前有关数据语义方面的研究大致分为语义正确性、语义约束和语义相似度计算三个方向,其中语义正确性方面的已有研究多聚焦于关系型数据库领域,如:文献[6]提出了一种名为SCORDA(Semantic Correctness Oriented Relational Data Acces)的面向语义正确性的关系型数据库访问方法;文献[7]基于本体实现对关系型数据库的语义约束;文献[8]应用本体技术实现关系型数据库的集成和语义正确性评价;文献[9]通过制定规则实现对审计领域数据库的语义正确性评价。
上述研究虽然面向关系型数据库,与知识图谱存在较大差异,但是对本文的研究工作提供了研究思路,有关本体在语义层面的相关研究工作如下:文献[12]基于本体构建了大规模分布式系统语义信任模型,提高了实体间交互行为的共享性和扩展性;文献[13]应用本体技术从语义层面实现数字媒体资源的管理;文献[14]基于本体实现医疗数据的语义相似度计算和数据转换;文献[15]基于本体进行VISEAGO 项目开发,在语义层面实现生物学领域的数据关联关系挖掘。通过对目前已有研究的总结,不难发现本体技术在知识表示与语义约束方面有着卓越的表现力,加之其能够良好支持规则制定与推理,能够较好地满足本文在面向知识图谱的数据语义有效性评估上的要求,因此本文利用本体在模式层对数据语义进行规范描述和管理,并提出一种面向知识图谱的数据语义评价算法。
目前面向知识图谱的语义层面的研究多关注语义约束和语义关联度计算两个方向,如:文献[16~17]通过构建JRL 和JKRL 模型计算知识间的语义关联;文献[18]利用上下文知识计算实体间语义关联度;文献[19]应用Microsoft Concept Graph技术实现查询的语义扩展。以上研究主要针对知识图谱的数据语义关联度与约束,有关知识图谱的数据语义有效性评价的相关研究较为缺乏。本文根据知识图谱的特点研究语义评价模型的构建,利用本体进行数据语义的管理和约束,制定语义有效性评价规则,通过对不同评价指标的评估实现对知识图谱的语义有效性评价。
综上,本文基于知识图谱的数据组织特点,考虑到元知识(属性、关系等)对知识实体的描述关联度不同,采用基于广度优先搜索的搜索算法进行数据遍历,在语义有效性评价中融入评价权重计算,降低较低相关度的关系可能造成的多余的时间开销和评价影响。
3 模型及规则构建
本文所提出的评价方法利用本体在模式层对数据语义进行规范描述和管理,使用标准元数据标识数据元素构建本体。因此在数据实例层(即知识图谱层)和本体层中间搭建Mapping 层进行模式与数据实例的映射,实现本体对知识图谱的语义管理。
知识图谱主要由语义类、实体、属性、关系等元素构成,通过{实体-关系-实体}和{实体-属性-属性值}这两种三元组的方式实现对语义的描述与表示,因此基于上述知识图谱的数据结构特点,构建知识图谱语义有效性评价模型。对该模型的定义如下:
定义1:评价模型SIRIA,SIRIA评价模型由五个元素组成,其表示为

其中S 表示待评估数据集,这里表示一个领域知识图谱;I 表示在评价中所设计的评价指标所构成的集合;R 表示在评价中所使用的规则集合;In 表示评估中数据实例,这里表示知识图谱中的一条实体-属性-值;A 表示在知识图谱语义评价中所用到的算法集合。
定义2:定义S={E,Re}为领域知识图谱。其中E为待评估的数据实体,Re为实体之间的关联关系。对E的描述为
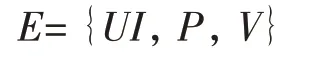
其中,UI 为唯一标识符,P 为实体包含的属性,V 为实体属性所对应的属性值。
定义3:定义I={D,SCR,SI}是在对领域知识图谱进行评价时所使用的评价指标集合。其中D为评价方向,SCR 为领域知识图谱的语义缺失率,SI为领域知识图谱的语义不当率。
定义4:定义R={Co,E,Re}是对领域知识图谱进行评价时所使用的规则集合,其中,Co 为对知识实体及关系的约束。
定义5:定义In={E,P,V}是对领域知识图谱进行评估时的数据实例,在本文中的表现形式为实体-属性-值。
定义6:定义A={E,I,S}是对领域知识图谱进行评价时所用到的算法集合,实现对数据的搜索和抽取。
3.1 语义评价模型
本文所提出的方法中,利用本体进行数据语义的管理和约束。构建语义评价本体则需要依赖上述模型中定义的关系,因此从上述数学模型出发,制定了从知识图谱语义数学模型向本体转换的映射规则,抽取模型中的概念及关系构建本体。
经典文献[20]将本体形式化为五元组本体=
映射1:S→C,实体类向本体类的映射,这里的实体类表示一类具有相同性质的实体集。
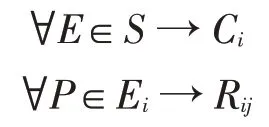
上式中P为实体属性。
映射2:I→C,评价指标集合向本体类的映射,即根据本文定义的评价指标对本体类进行评价。

D 为评价指标的评价方向,Co 为约束,每个评价方向映射到C中即为一个属性或约束。
映射3:R→A,评价规则向本体包含的公理集的映射,这里的评价规则表示在对领域知识图谱进行评价时使用的评价规则集合,每一条规则映射到本体中均为一个公理。
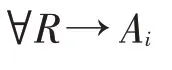
映射4:In→I,评价时使用的数据实例向本体实例的映射,本文在对知识图谱进行语义有效性评价时,抽取数据层的部分数据进行评估,这部分数据即为评价时使用的数据实例。
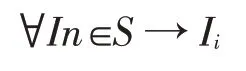
映射5:A→F,所有的算法映射到本体均为一个独立的函数。

3.2 规则构建
基于本体的推理由所定义的规则支持,本文使用Jena 推理引擎实现推理。根据上述制定的语义评价指标,构建的部分推理规则如下:
规 则1:[rule1:(?p rdfs:lessThan ?q)->print(‘Missing semantics’,?e)]
其中p=e.np,q=e.nkp,规则1 的解释如下:如果实体e 的属性数量小于实体e 的关键属性的数量,则视为e的语义缺乏;
规则2:[rule2:(?e rdfs:subPropertyOf?q),notEqual(? e,? q)-> print(‘Improper semantics’,?e)]
其中,q=e.p,规则2的解释如下:如果实体e的子属性p 与正常的属性值不符,则视为e 的语义不当;
规则3:[rule3:(?e rdfs:listLength ?len)->print(‘Missing semantics’,?e)]
对规则3 的解释如下:如果实体e 的字符串长度小于规定长度len,则视为e的语义缺乏;
规 则4:[rule4:(?e rdfs:listNotContains ?p)->print(‘Missing semantics’,?e)]
对规则4 的解释如下:如果实体e 中没有包含属性p,则视为e的语义缺乏;
规则5:[rule5:(?p rdfs:more ?k)-> print(‘Improper semantics’,?e)]
对规则5的解释如下:如果实体e的属性p超过了规定的属性k,则视为实体e的语义不当。
4 评价算法
4.1 实体关系搜索算法
在进行知识图谱语义有效性评价时,需要对知识图谱中的所有实体进行评价,包括实体拥有的关系和属性,而知识图谱通过G=
算法1剪枝实体关系搜索算法
自某一节点出发使用广度优先搜索算法对此节点的边进行遍历,并根据边的权重进行剪枝操作。
输入:节点vi;
输出:高权重关系(e)集合Ri;
初始化Ri=ø,vi
while(ejbelong to v)i
add ejinto Ri
end
//为Ri中的关系进行赋权,Poi为vi的语义权值
Poi=function pow(R)i
while(ekin R)i
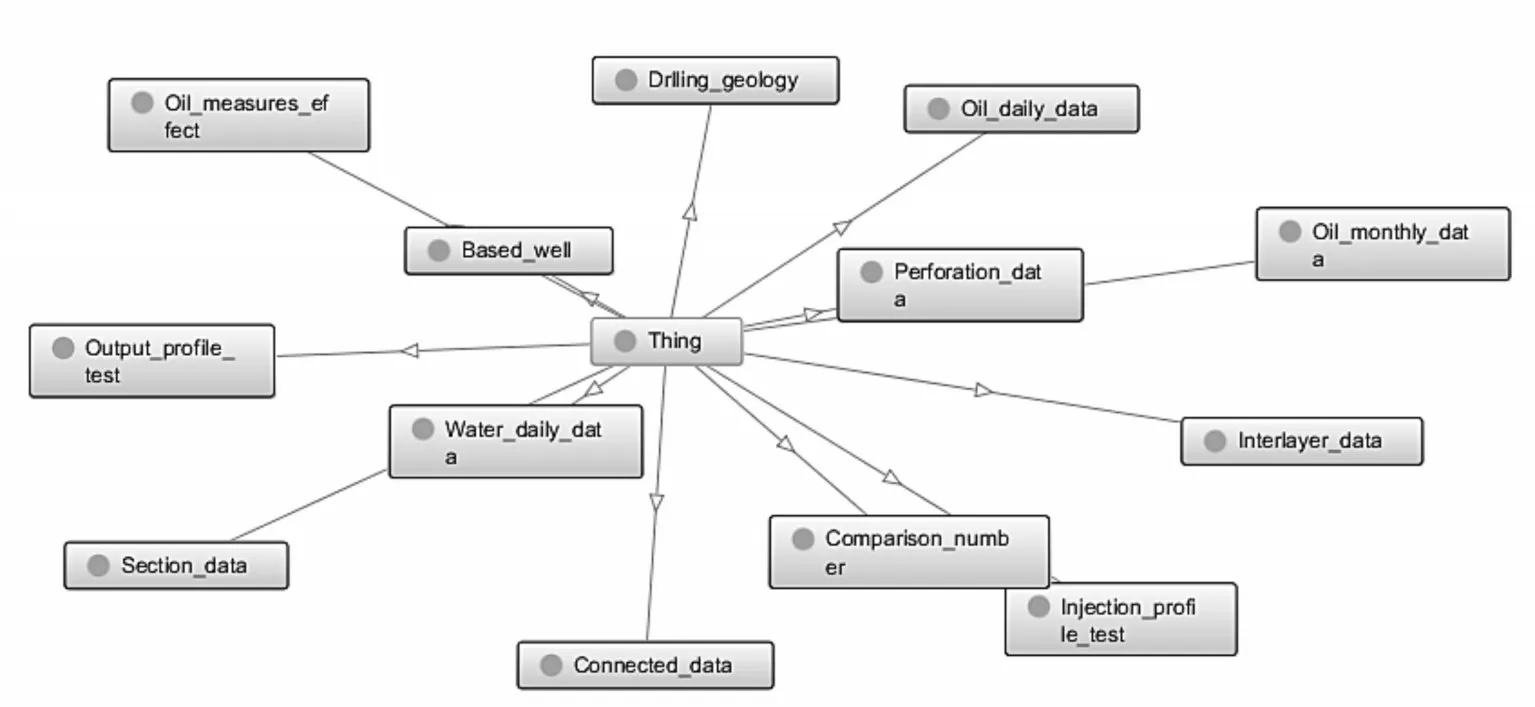
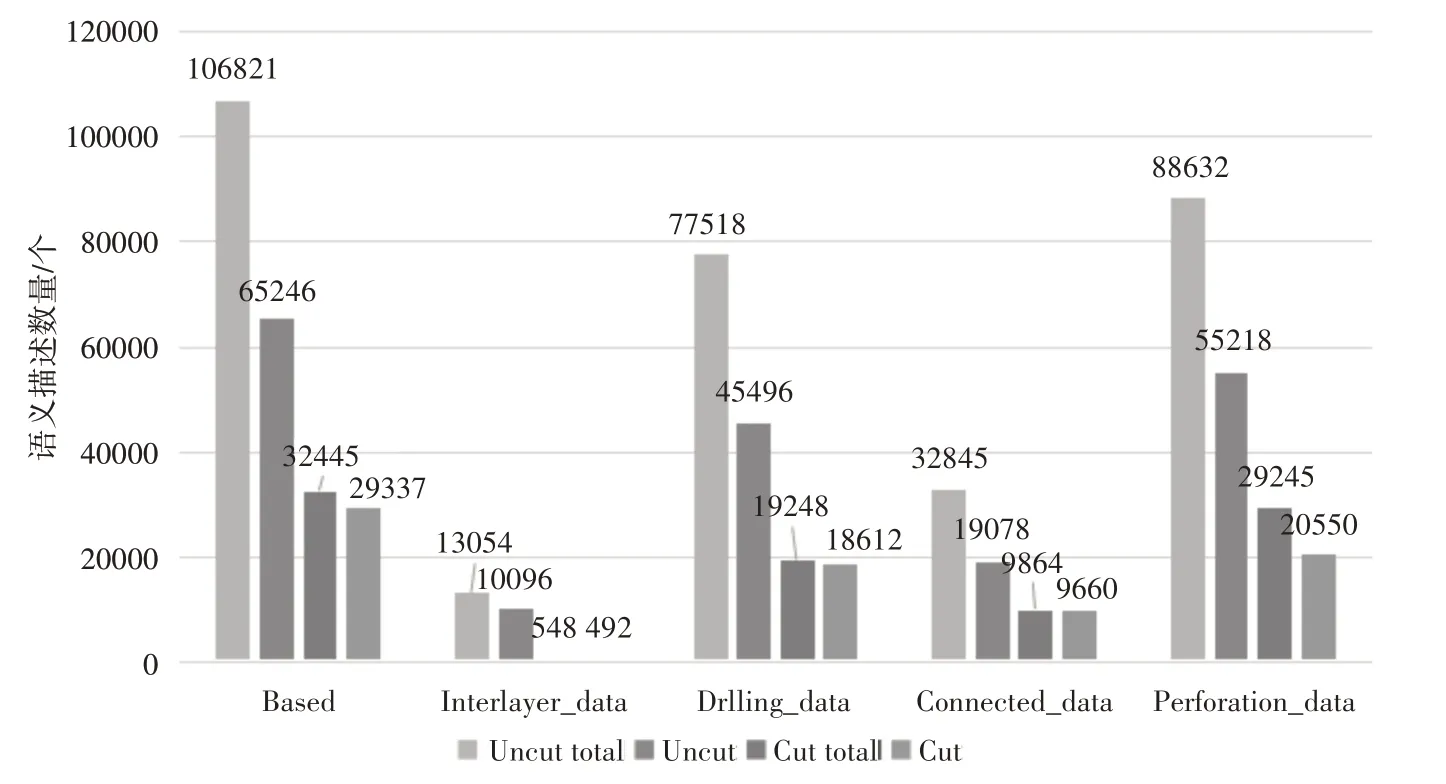
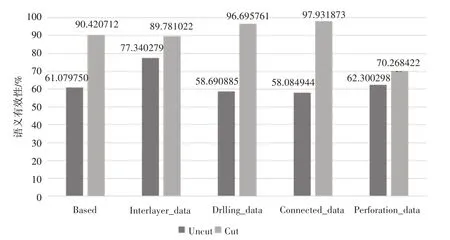
i(fek.pow remove ekfrom Ri end end return Ri 算法对每个实体节点vi关系进行遍历,检验每个实体的每个有效关系e∈Ri,针对节点vi,我们对语义有效性不同指标进行评价,如果vi某个关系ej语义有误,我们会根据语义权重对节点vi的语义有效性进行评价调整。 对于知识节点有效性的评价过程如式(1)所示: 上式中,SV 为知识节点的语义有效性,Ri为节点i的语义有效性,Poi为该知识节点的语义权值。 算法2语义有效性评价算法 输入:知识图谱G,本体O,评价规则R。其中G 为待评价知识图谱,其数据组织方式为图结构,即顶点VV 和边EE 组成一个庞大而复杂的{(E)i-[Relation]-(E)j,(E)-[Relation]-(V)}的集合。O 为待评价本体,可以理解为知识图谱的Schema 层,其为语义评价提供清晰地语义关系描述,为语义推理和约束提供有力支撑。R 为评价时使用的规则文件,其中包含大量的基于本体构建的语义评价规则和约束。 输出:知识图谱G 的语义评估结果β(G),即语义有效率; Count_Error=0,Count_Num=0; Initialize O,G,Rule; for vi in G; for ej in Ri Semij=Ru(O(ej)); //如果ej 与Ri 之间的语义关系评价结果小于1,则将ej视为语义不当或语义缺失 if(Semij<1) //对语义不当或语义缺失的语义描述数量进行累加 Count_Error++; WriteIn(file); end //对vi 的语义有效性评价通过对其拥有的关系进行加权计算的评价过程得到 SVi=SVi+Semij*Poj; Count_Num++; end end β(G)=(Count_Num-Count_Error)/Count_Num; 为了验证本文所提出模型和方法有效性,我们使用所提方法对5 个规模大小不同的知识图谱进行语义有效性评价,并对试验结果进行分析,验证所提方法和模型的可靠性。 实验中用到的知识图谱是测井领域的相关数据,能够满足本文实验对不同数据量的需求。对知识节点的语义权值设置如下:对重要的关系属性赋权值为2,其余关系权值为1,各数据集中重要的关系在图1中已给出。 图1 为本文所用的数据集合之间的关联关系在Neo4j 中的可视化展示,图2 为本文所用的数据集合在本体构建工具Protégé中的展示。 图1 Neo4j中的实验数据集之间的关系 图2 本体中的实验数据集 在本次实验中,主要对语义有效性维度下的语义缺失和语义不当两个指标进行评价。 语义缺失是指在知识图谱中,正常的实体节点拥有众多关系,这些关系对实体节点进行语义描述,不同类别的实体节点所拥护的关系不尽相同,不同关系对实体节点的描述重要程度也不同,对于个别的关系在实体描述中是不允许缺失的,如:在“人”这个概念类下,针对某个实例来说,姓名关系对于个人实体来说原则上是不允许缺失的,所以当某实体节点中缺少此类描述关系,则判定该实体此语义缺失。 语义不当主要是指在实体描述中关系节点与关系描述的不对称性。即通过关系连接的两个节点并不适配,如针对某个人来说,通过身高关系连接的实体为某人,而另一端的节点值为20m,这样的节点间关系语义描述是不当的。 因此本次实验主要针对上述两个指标对知识图谱进行语义有效性评价,以此验证所提模型和方法的有效性。 在实验中使用试验环境为:一台主频为3.2GHz 的计算机、内存大小为12GB、处理器为Intel Core I3-2130,使用Java 语言于64 位的Windows 7系统下进行编译运行。 在实验中针对5 个不同的领域知识图谱进行评价结果如图3、图4所示。 图3 语义描述数量对比图 图4 语义有效性评估结果对比图 我们对知识图谱进行基于剪枝和不剪枝两种方法都进行了验证,图3 为语义有效数量的对比图,图4为语义有效性的对比图。 由实验结果可见,知识图谱中的语义缺失和语义不当等问题会影响知识图谱的语义有效性,本文所提的模型和方法能够有效对知识图谱进行语义有效性评价,经过剪枝操作后,能够更好地对语义描述进行评价,提高语义评价的准确性。 本文研究了一种面向垂直领域知识图谱的数据语义有效性评价方法,并且详细地描述了整个评价过程,通过实例展示了本文提出的评价方法的有效性,旨在为知识图谱的应用提供数据质量的保障,提高数据的准确率与数据评价过程的评估效率。4.2 语义有效性评价算法
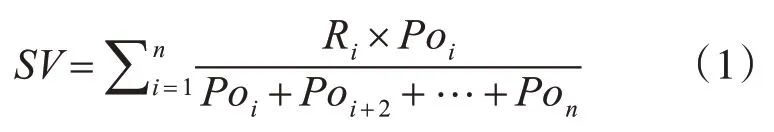
5 实验分析
5.1 实验对象
5.2 实验指标
5.3 实验结果分析
6 结语
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
齐鲁艺苑(2022年1期)2022-04-19
哈哈画报(2021年10期)2021-02-28
新城乡(2018年6期)2018-07-09
长江学术(2015年1期)2015-02-27
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
中国报道(2009年12期)2009-01-15
