
基于机器学习算法的网络安全检测
2022-04-07 08:28何枢铭
水电站设计 2022年1期
何 枢 铭
(中国电建集团海外投资有限公司,北京 100048)
0 前 言
随着信息时代的发展,网络安全在我国电力行业的工业控制领域,有着举足轻重且不可撼动的地位。同时,随着信息化、数字化、自动化建设逐渐完善,数据成为了最重要的虚拟资产之一,做好网络安全防护也等同于阻断Web攻击者对机密信息窃取的主要渠道。另外,一旦攻击者入侵工业系统内网,取得了核心操作权限,就可以对软硬件设施、工业设备进一步控制或破坏,其后果不堪设想。因此,工业领域的网络安全是不惜一切代价也要严格把控的一大关口。
本文将详细介绍传统的网络攻击检测手段以及基于机器学习算法的Web攻击检测方案,并将两种方法进行比较,分析其优势与劣势,最终总结出一套低成本、低消耗、执行高效的网络安全检测方案。
1 传统检测方法
1.1 “黑白名单”
“黑白名单”可谓是网络安全领域中最传统且实用的防御手段之一,其操作简单有效,是Web防火墙WAF的重要配置选项。Web防火墙是信息安全的第一道防线,随着网络技术的飞速发展,新的黑客技术也层出不穷,采用“黑白名单”以及规则匹配方式的传统防火墙受到了极大的挑战。传统防火墙应对新黑客技术的缺陷主要表现在两方面:一是在灵活的黑客面前,硬性的规则匹配会被轻松绕过。程序员在编写防御规则时很难穷尽所有地罗列恶意攻击行为。二是传统防火墙是基于以往知识的规则集进行防御的,这种方式不仅维护成本高,而且在没有打补丁的情况下很难防范新鲜出炉的0Day漏洞,这就要求探索出一种低成本、动态且高效的方法来补足静态防御的短板。
1.2 正则匹配
正则表达式是一种由多个特殊字符组成的逻辑公式,其主要功能是用来匹配一类特定字符串,完成对文本的筛选与过滤。在网络安全应用中,正则匹配是一种常用的传统Web攻击检测手段,对于字符串形式的日志数据是一种强大的关键词捕捉工具。比如,服务器受到Webshell通信攻击时,Web日志中往往会出现类似”b374k”、“php”、“shell”的关键词,随后进一步查看响应代码为200,这表明攻击者大概率上传了一个Webshell文件并且成功访问了它。以上为Web服务器受到攻击时自动写入日志的数据,如果我们采用正则匹配的手段来自动捕捉这些与恶意攻击相关的关键词,便可及时发现可疑的攻击行为并采取相应的防御措施。
1.3 数值统计
在海量的日志数据中,单纯靠规则匹配、“黑白名单”、策略控制等传统方式是很难识别出变种攻击行为的,但是万变不离其宗,绝大多数攻击都会在Web日志中留下蛛丝马迹。倘若把Web攻击者视为一个对象,该对象在攻击时一定会发出某个网络动作,而这些动作会在Web日志中留下攻击者的“指纹”,包括用户行为、交互IP、访问次数等大量信息。作为防御者,我们通过这些信息背后的统计特征来推断出网络动作,并基于动作来判断该行为是否属于恶意的网络攻击行为。比如,在一段时间内多次检测到同一个IP访问目标网站说明有不良的网络扫描与嗅探行为,相同URL接收到不同参数的情况下出现相同值的次数表明有口令猜解或者密码爆破行为,不同域名下出现同一URL次数激增意味着有可疑用户在尝试猜测后台登录地址。总之,基于数值统计方法,通过不同的网络动作可以推测出用户意图,并及时动态更新黑白名单,采用新的WAF策略以加固防火墙。
2 机器学习检测方法
为了弥补传统规则集方法的不足,本文将基于机器学习算法的LSTM与SVM模型,针对大量Web日志数据进行自动化学习和训练,从而达到区分正常样本和攻击样本的目的,完成对海量日志数据的进一步筛查。下文将简单介绍该Web攻击检测方案的大致流程。
2.1 数据预处理
在获取完整的Web日志文件后,将对每一条日志数据进行关键字段提取。一般情况下,一条Web日志记录的结构如图1所示。
其中,115.28.44.151表示发出请求的源IP地址,[28/Mar/2014:00:26:10 +0800]表示用户发送请求的具体时间,“GET/manager/html HTTP/1.1”表示请求主体,404表示服务器响应码,162表示以字节为单位的请求报文长度,“Mozilla/3.0(compatible;Indy Library)”表示客户端信息[1]。若想对日志数据进行攻击意图识别,则需要将结构化数据根据字符串的空格分段,并将各个关键词存储到相应的变量中以准备下一步的特征提取。值得注意的一点是,Web攻击识别主要靠的是分析请求主体,需要提取主体的核心特征,才能准确判断出用户意图。
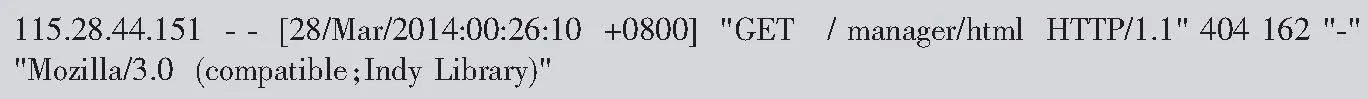
图1 Web日志数据样例
2.2 特征工程
运用机器学习算法的前提是构造好特征向量。就像人类识别车辆类型一样,短短一瞬间人的大脑会自动把一辆车拆解出多个特征,包括车的形状,颜色,材质,轮胎数量,排气管位置等等,只有当大脑收集到足够多的特征信息时才能做出合理判断。同理,源IP地址、时间戳、请求主体、客户端信息等关键词同样可以成为某个网络行为的特征,而且这些特征也有优劣或主次之分,应该重点关注源IP、请求主体、客户端这些信息,因为它们都是用户可控的。对于大多数Web攻击而言,攻击者往往会尝试修改以上这3个参数,比如注入Payload恶意攻击信息,这自然也成为了识别攻击意图的突破口。对于源IP、状态码这些包含纯数字的特征,只需合理分段并填入相应的特征槽便可完成特征向量的构筑,然而对于处理“/manager/html“这种字符串特征,就需要手动设计特征,比如根据被访问资源的敏感程度,量化给出不同的风险等级,如果manager属于极度敏感的信息,则赋予其特征值为9或10,反之若非核心的资源被访问,风险特征值则降为2或3,该特征的整个取值范围是0~10。
以上是仅从单条日志本身便可提取的特征,然而如果从全局的数据来看,或许会获得更加丰富且有用的信息。一方面,可以根据上文提到的数值统计构造新特征,包括访问的次数、深度、宽度统计、非200请求比、GET文件访问比等,每种统计结果可以表示不同的网络动作,从而判断源IP是否具有攻击意图。另一方面,一旦获取了全局数据,便可以进一步构造TF-IDF特征。词频-逆文档频率(TF-IDF)是一种从文本文档提取并构造每个单词特征的简单方法,它能够为每个单词计算出两个统计值,分别是词频(TF)和逆文档频率(IDF),词频是每个词在文档中出现的频率,逆文档频率表示在整个文档中出现的频繁程度[1]。就Web攻击的案例来说,将整个日志看作一个完整的文档或者语料库,倘若一个关键词在大多数正常流量的日志数据中均有出现,则表示可疑程度较低,相反如果该关键词在全局数据中出现频率很低,而偏偏在某个IP的网络行为中频频出现,则说明该用户有可疑的非常规操作。由此可见,TF-IDF以牺牲一些计算时间和内存空间为代价,提供了比较可靠的统计特征。
2.3 建模预测
构建拼接好特征之后,需要选择一个合适的模型来将特征值映射到非0即1的输出空间上,从而判断该网络行为是否可疑。文中采用了自然语言处理(NLP)领域的经典序列模型LSTM外加传统机器学习模型SVM来做分类预测,具体模型结构如图2所示。

图2 LSTM+SVM模型示意
该模型将某个时间段内来自同一IP地址的一连串网络行为特征作为输入,首先在“T1”的时间节点,将“特征1”传输到LSTM网络层中,随后经过网络层的线性变换提取出新特征后,生成新的离散向量“信息1”,在“T2”时间点,将“信息1”和“特征2”结合并传入LSTM网络层以生成“信息2”,以此循环往复直到该用户的网络行为终止。最后,将综合以上所有信息计算出信息和,并将其传入SVM模型做一个简单的二分类任务,输出为1则说明该IP具有可疑攻击行为,反之输出为0代表正常。本文只是从宏观角度提出机器学习版本的Web攻击检测方案,欲了解LSTM或SVM模型的底层原理请阅读参考文献[2-3]。
3 方法比较
上文主要介绍了两种Web攻击检测手段,包括传统方法和机器学习方法,蓝方至今没有舍弃传统防御手段是因为它们相较于新技术而言具有某种不可替代性,换言之传统方法和以机器学习为代表的新技术各有千秋,下文将深入讨论这两种方法的优与劣:
传统方式需要大量时间与人工成本来编写新的正则匹配规则,不断添加新的“黑白名单”,不停制定新的WAF策略,只要红方不愿休战,蓝方就需要持续消耗资源来做被动防御。然而,一旦完成琐碎的准备工作,传统的防御策略执行起来便会非常高效,并且对于已出现过的攻击行为防守成功率极高。
机器学习方式虽然智能,但同样少不了人工开销,建模前需要投入大量的时间来收集各种类型、各个时间段的Web日志数据,并且可能需要专业人士来制作标签以完成整个模型的训练或者学习过程。若想节省时间直接寻找开源的Web日志数据集,则会因正负样本比例严重失衡而导致模型在查准率方面表现极差,失去了Web防御工具自身的价值。不仅如此,一个泛化能力强的机器学习模型需要较长的时间周期训练,而且实践中的预测速度也远不及正则匹配等传统方式。但是,对于变种的攻击行为而言,机器学习模型有着得天独厚的优势,例如对于从未见过的请求主体,机器学习算法的效果远远凌驾于传统方式。
综合来看,传统方式的效果依赖于规则集的维护,而机器学习算法的效果依赖于训练数据集的质量。与其选择其中一种方式,不如将两者结合起来,先用传统方法过滤一部分确认安全的流量,再用机器学习算法进一步检测不确定的可疑流量,扬长避短之后效果可能会更好。
4 结 论
本文在网络安全与工控应用的背景下,针对Web日志的数据分析,提出了包括传统方法和机器学习方法两种Web攻击的检测手段。传统方法虽高效但耗费资源,机器学习算法依赖于训练数据,不过可以检测出新的攻击手段。未来,公司将在使用传统方法过滤流量的基础上,尝试采用无监督学习的方式,比如K-means聚类模型,为机器学习模型制造伪标签来自主增强训练数据集,从而平衡正负样本的比例,达到更好的模型训练与预测效果。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电影(2018年8期)2018-09-21
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
指挥与控制学报(2015年4期)2015-11-01
