
医学图像处理中的注意力机制研究综述
2022-04-09 07:01陈朝一吴凯文
计算机工程与应用 2022年5期
陈朝一,许 波,吴 英,吴凯文
1.广东财经大学 信息学院,广州 510320
2.暨南大学附属第一医院 超声科,广州 510630
深度学习作为当下最热门的研究方向之一,与现有基于规则的算法或深度学习以外的机器学习算法相比,深度学习表现出卓越的特征提取能力和性能。因此,它被广泛应用于医学领域,包括自动诊断[1]、反应评估[2]和生存预测[3]。尤其是在医学图像处理领域,医学图像重建[4]、合成[5]、高分辨率图像恢复[6]以及图像去噪[7]等方面的研究成果显著。
随着为患者定制精准医疗的趋势越来越明显,医学图像分析的方式也从传统的定性分析转变为定量分析[8],通过从医学图像中提取特征来做出更复杂的预测。在这个过程中,除了基于机器学习的影像组学技术[9-10],最近正在积极研究使用深度学习的深度特征提取[11]、病变检测[12]和分割技术[13-14]。有研究表明,可以通过计算机辅助诊断系统来提高专家的诊断准确性[15],甚至有报道称这些人工智能算法可以为某些部门进行专家级的分析[16]和诊断[17]。
然而迄今为止开发的大多数深度学习模型最大的问题是很难从检测和分割结果中明确发现深度学习模型判断的依据,即无法深入理解深度学习模型在图像的哪个部分做出了这样的判断[18]。因此,深度学习模型通常被称为“黑盒”,因为人们无法完全解释它的内部机理[19]。
因此,通过注意力机制,不仅可以验证深度学习模型的判断依据,而且可以让深度学习模型更多地关注重要特征,而较少关注不重要的特征,以达到提升深度学习模型性能的目的。在这篇综述中,首先讲述注意力机制的基础知识,然后根据应用于医学图像处理的最新趋势来讨论未来前景和发展方向。
1 医学图像处理领域中注意力机制的种类
在医学图像处理领域中,注意力机制主要分为两种类型:(1)用于寻找深度学习模型作用区域的“显著性检测”(saliency detection),目的是生成热点图,该图以定量的方式表征了场景不同位置吸引“注意力”的强度。(2)与深度学习模型同时训练的“视觉注意力模型”(visual attention model),目的是为了让模型实现有针对性的“聚焦”,以提高模型的性能。注意力机制分类示意图如图1所示。
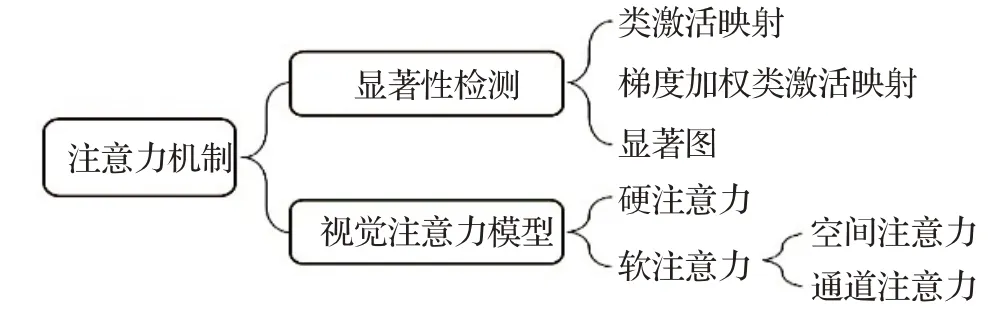
图1 医学图像中的注意力机制分类Fig.1 Classification of attention mechanism in medical image
显著性检测是一种用于图像读取和检测等的网络推理技术,应用于经过训练的网络,用于识别深度学习模型作用区域作为分类或检测的依据。类激活映射(class activation mapping,CAM)[20]、梯度加权类激活映射(gradient-weighted class activation mapping,Grad-CAM)[21]和显著图(saliency map,SM)[22]都属于显著性检测,经常被提及为可解释的人工智能技术。
视觉注意力模型是一种“确定图像的哪个区域要聚焦”的主动学习聚焦技术,它将注意力机制插入到深度学习模型中,使其本质上是跟深度学习模型一起训练,对根据相关性提取的特征赋予权重[23],而不是为了检测深度学习模型专注于哪个区域。通过聚焦关键区域,可以克服医学图像数据不足和偏差现象导致的性能下降问题[24]。视觉注意力模型根据所表达的注意力区域的特点,大致可以分为硬注意力和软注意力。
2 常用数据集和评价指标
2.1 常用数据集
目前,注意力机制在医学图像处理中得到了广泛的应用,以下介绍医学图像处理常用数据集。
(1)MURA[25]
这是一个大型肌肉骨骼放射图数据集,包含来自14 863项研究的40 561张图像,其中每项研究都被放射科医生手动标记为正常或异常。另外从斯坦福大学放射科医生处收集了额外的标签,其中包括207项肌肉骨骼研究。
(2)DeepLesion[26]
这是一个拥有多种病变类型的数据集,包含肺部结节、肝脏肿瘤、肿大的淋巴结等,来自4 427名独特病人的10 594项研究,一共32 735个病变,这些病变分布在32 120个CT图像上。
(3)NSCLC[27]
该数据集共收集了211名转诊手术治疗的受试者的临床和CT成像数据,并从切除的肿瘤中获得组织样本。同时还收集了临床数据,如:年龄、性别、体重、种族、吸烟状况、TNM分期、组织病理学等级。
(4)NIH[28]
这是一个新的胸部X射线数据库,它包含32 717名患者的108 948张正面X射线图像,文本挖掘了8个疾病图像标签(其中每个图像可以有多标签)和来自使用自然语言处理的相关放射学报告。
(5)OASIS[29]
OASIS汇编了1 098名参与者的MRI和PET成像以及相关的临床数据,这些数据是在华盛顿大学奈特阿尔茨海默病研究中心的几个正在进行的研究中收集的,时间长达15年,一共超过2 000个MR片段,包括多个结构和功能序列。
医学图像数据集相比自然图像数据集有很大区别。首先,医学图像数据集由于涉及到病患隐私,数据不公开是很常见的,导致收集难度较大。第二,医学图像数据集需要通过特殊设备生成,如X光、超声和核磁共振等,存在对比度低、噪声高、伪影等特点。第三,不同模态的图像反应的信息是不一样的,比如CT看骨头和出血的清晰度更高,而MRI显示软组织更好。第四,成像参数不一样也会带来巨大的区别,比如KV级和MV级的X光生成的图像具有很大的差异。因此,评价实验结果除了要考虑算法本身以外还要看数据集的好坏。
2.2 常用评价指标
本节介绍了医学图像处理中的常用评价指标,为下文的性能评价提供基础认识。
(1)Dice系数
集合相似度度量的函数,通常用于计算两个样本的相似度,范围为[0,1]。公式如下:

其中,X和Y分别代表金标准和预测结果,通常用于评价医学图像分割效果。
(2)Precision(精确率)
表示预测为正的样本中有多少是真正的正样本,公式如下:

其中,TP(true positive)表示把正样本预测为正样本,FP(false positive)表示把负样本预测为正样本。
(3)Recall(召回率)
表示样本中的正例有多少被预测正确了,公式如下:

其中,FN(false negative)表示把正样本预测为负样本。精确率越高越好,召回率也越高越好,但事实上这两者在某些情况下有矛盾。因此精确率和召回率指标有时候会出现矛盾的情况,这样就需要综合考虑它们,最常见的方法就是F1分数。
(4)F1分数
可以通过计算F1分数来评价性能,公式如下:

F1分数是精确率P和召回率R的加权调和平均,可知F1综合了精确率和召回率的结果,当F1较高时则能说明实验方法比较有效。
(5)AUC
AUC是ROC曲线下的面积,介于0.1和1之间。AUC作为数值可以直观地评价分类器的好坏,值越大越好。计算公式如下:
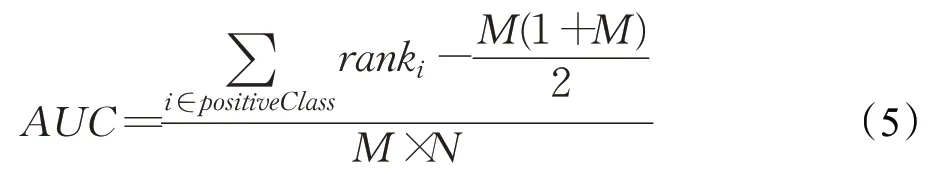
其中,rank为排名,M为正类样本,N为负类样本。AUC倾向于训练一个尽量不误报的模型,也就是知识外推的时候倾向保守估计,而F1倾向于训练一个不放过任何可能的模型,即知识外推的时候倾向激进。
3 显著性检测
为了提高深度学习性能,深度学习模型的复杂度呈指数级增长,使得很难直观地解释模型内部做了什么样的处理,这在医学图像处理领域是非常致命的[30]。为了解决这个问题,已经有研究人员开发出用于解释基于卷积神经网络模型的各种方法,其中主要介绍最新研究中使用的三种代表性方法。
3.1 类激活映射
几乎所有知名的基于卷积神经网络的深度学习模型,如U-Net[31]、ResNet[32]、DesenNet[33]和R-CNN[34]等层数都非常深,参数量很大,因此很难直观地理解模型内部的计算过程。CAM是一种旨在解释深度学习模型在计算每个类别的概率时主要关注图像的哪一部分的方法,主要应用于分类和判别任务中。
首先,CAM经过全局平均池化(global average pooling,GAP)过程,将最后的特征图fk压缩为卷积神经网络层之后的平均值。CAM的基本思想是,在特征图上应用GAP压缩值对相应级别的影响越高,越能形成较高的权重值。所以通过在特征图上显示权重值,可以显示出图像每个区域特定类被激活的程度。提取CAM的公式如下:
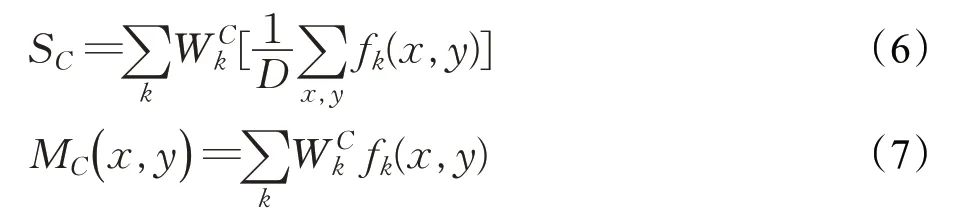
每个符号的含义如下:SC表示模型对于C类的输出值,fk表示模型卷积层末尾的第k个特征图,D表示图像中的总像素数,表示应用于C类权重的第k个fk,MC表示C类的CAM。每个特征图fk乘以其对应的权重并求和得到CAM,因此,它具有很好地定位模型关注的部分[35]。
作为CAM应用于医学图像分析的一个例子[35],该研究团队使用自主开发的用于膝关节MRI的深度学习模型MRNet,开发了三种类型(非特异性异常、前十字韧带撕裂、半月板撕裂),并通过CAM确诊为诊断依据。图2为膝关节MRI,其中每幅图像的描述如下:
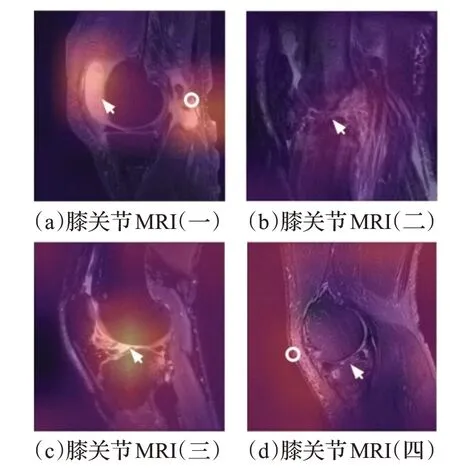
图2 CAM应用于膝关节MRIFig.2 CAM applied to knee MRI
图2(a)显示腓肠肌腱有大量渗出和破裂,MRNet将其归类为异常。模型的CAM渗出区(箭头)和腓肠肌腱断裂部位(白环)显示相对较好。这表明该模型即使只学习了疾病的分类,也可以检测到异常。
图2(b)由于患者的运动,在严重伪影中显示完整的前交叉韧带撕裂,模型诊断该图像为前交叉韧带撕裂(箭头),并且CAM也适当地激活了破裂部位。
图2(c)显示完整的前交叉韧带撕裂(箭头),可以确认CAM也能很好地检测到前交叉韧带撕裂。
图2(d)与图3中的其他图像不同,这是一个CAM激活错误部位的例子。从图像上看,可以外侧半月板后角撕裂,并且该模型也有膝关节异常。然而CAM激活的是前部软组织,而不是外侧半月板。这证实了虽然模型将患者归类为异常,但判断的依据是错误的。
从上面的结果可以看出,在大多数情况下,模型的判断标准和实际诊断的原因是一致的,但也有不一致的情况,这说明不能完全相信这个模型的结果[36]。除此之外,因为导致这种结果的因素可以在视觉上得到确认,所以它可以有效地用于实际的临床诊断,并且可以起到辅助图像医师的作用[37]。
然而,CAM也有一定的局限性。第一,CAM受模型结构约束,只适用于模型必须包含GAP的情况,但深度学习模型在输出阶段不一定都使用包含GAP的结构。第二,这是一种基于分类问题的可视化技术,用于回归问题可能效果不佳。第三,它有分辨率低的缺点,原因是当输入图像通过网络时,池化很难扩大接收区域并提取更多信息,到最后的特征图,尺寸变得比原图小。为了对应原图,在CAM的尺寸上采样的过程中将尺寸提高到与原图一样大。
3.2 梯度加权类激活映射
模型判断在解释基本原理,需要一种不受模型结构约束的灵活方法,梯度加权类激活映射(Grad-CAM)就是根据这种需要而设计的。模型中必须至少包含一个卷积神经网络层,但是在图像处理中使用深度学习模型的情况下,大多数情况下都会使用卷积神经网络层,因此这种限制实际上对模型的灵活性影响不大。
Grad-CAM和CAM一样,也使用与卷积神经网络层的特征图对特定类的影响相关的权重。通过反向传播得到图的每个像素的梯度值的全局平均值,并用作权重。对应的梯度值会很大,通过对它们求平均,可以量化特定类的特征图的权重。差分图可以通过反向传播对该类的特征图的导数得到,而大部分的深度学习模型中,一阶导数可以很容易地计算出来,所以不受模型结构的限制,可以更灵活地应用[21]。
作为应用于基于深度学习的医学图像分析的梯度加权激活图的示例,Cheng等人[38]利用该模型产生的Grad-CAM如图3所示。
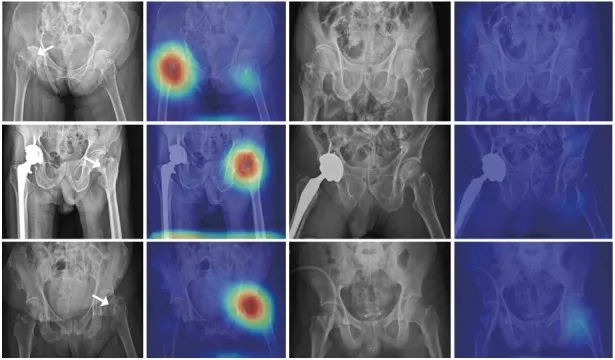
图3 Grad-CAM辅助解释髋部骨折Fig.3 Grad-CAM aids in interpretation of hip fractures
从图3第一列显示为骨盆骨折,第二列可以看出模型的Grad-CAM也激活了骨折部分。第三列显示没有骨盆骨折,从第四列可以看出Grad-CAM没有被专门激活。因此,Grad-CAM与CAM相比,以更局部化的形式成为可视化模型的判断依据,为高效安全的治疗提供帮助。
虽然Grad-CAM与单纯的CAM技术相比,对模型形式的限制较小,但依然未能克服分辨率问题,所以必须增大尺寸,像CAM一样降低分辨率[39-40]。
3.3 显著图
显著图是按输入图像的微分计算的,假设输入图像的特定像素值变化相对较大,则意味着该像素对输出值的贡献更大。
如果把显著图看成一个公式,它是这样的,即输入C类对应的模型,输出的微分值就成为显著图。如公式(8)所示:

显著图的特点是它的运算完全独立于模型的结构,这就是为什么它可以灵活地应用于两种模型。另外由于计算输出的是微分值,所以显著图可以和输入图像保持相同的分辨率。
在最近的一项研究中,深度学习被用于胸部X射线图像的结核病筛查。该研究使用显著图来理解模型并帮助放射科医生进行视觉诊断[41],如图4所示。
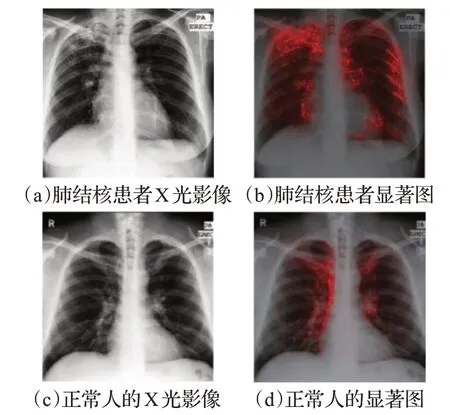
图4 肺结核患者和正常人的X光图像和生成的显著图Fig.4 X-ray images and saliency maps of tuberculosis patients and normal people
图4上面的两张图是肺结核患者的X光图像和显著图。深度学习模型诊断出肺结核患者,通过显著图可以理解模型的判断。右上叶因胸膜增厚呈混浊,右肺门向上偏移,在显著性图中,可以看出右上叶被强烈激活。反之,下面两张图是没有疾病的人的X光图像和显著图,深度学习模型误诊了这个病人为肺结核,从显著图可以看到注意力都集中在了右上叶,由于上叶的混浊是锁骨和肋骨重叠造成的,由此可见模型判断是错误的。
然而,显著图在将梯度传播到输入阶段的过程中,由于非线性激活函数等可能会出现梯度爆炸的问题,因此显示的热图中会出现噪声[42]。由于高维信息不使用压缩特征图,因此定位能力较差[41,43]。此外,如果出现数据集不足或者缺乏医生标注的标签时,可能无法达到理想效果。
综上,CAM是适用于包含GAP的情况,在灵活性上要比Grad-CAM和SM差,而Grad-CAM因为只需要包含卷积神经网络,而且得到每个特征图的权重,所以在灵活性和准确性要比CAM好。显著图的特点是它的运算完全独立于模型的结构,所以它的灵活性要比CAM好。另外显著图可以和输入图像保持相同的分辨率,而CAM和Grad-CAM都要降低分辨率。为了更直观表达每种显著性检测的优缺点,表1对每种显著性检测的优缺点进行了总结评价,其中+号表示正得分,-号表示负得分。表2总结了每种显著性检测在医学图像处理中的应用案例。
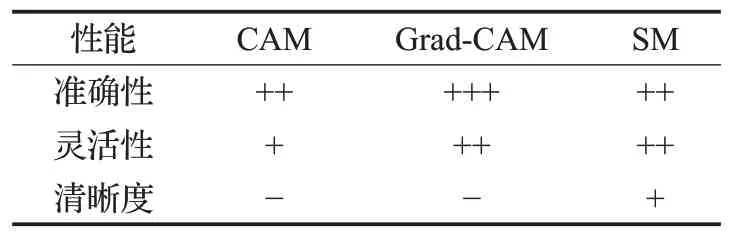
表1 显著性检测的优缺点评价Table 1 Evaluation of advantages and disadvantages of saliency detection
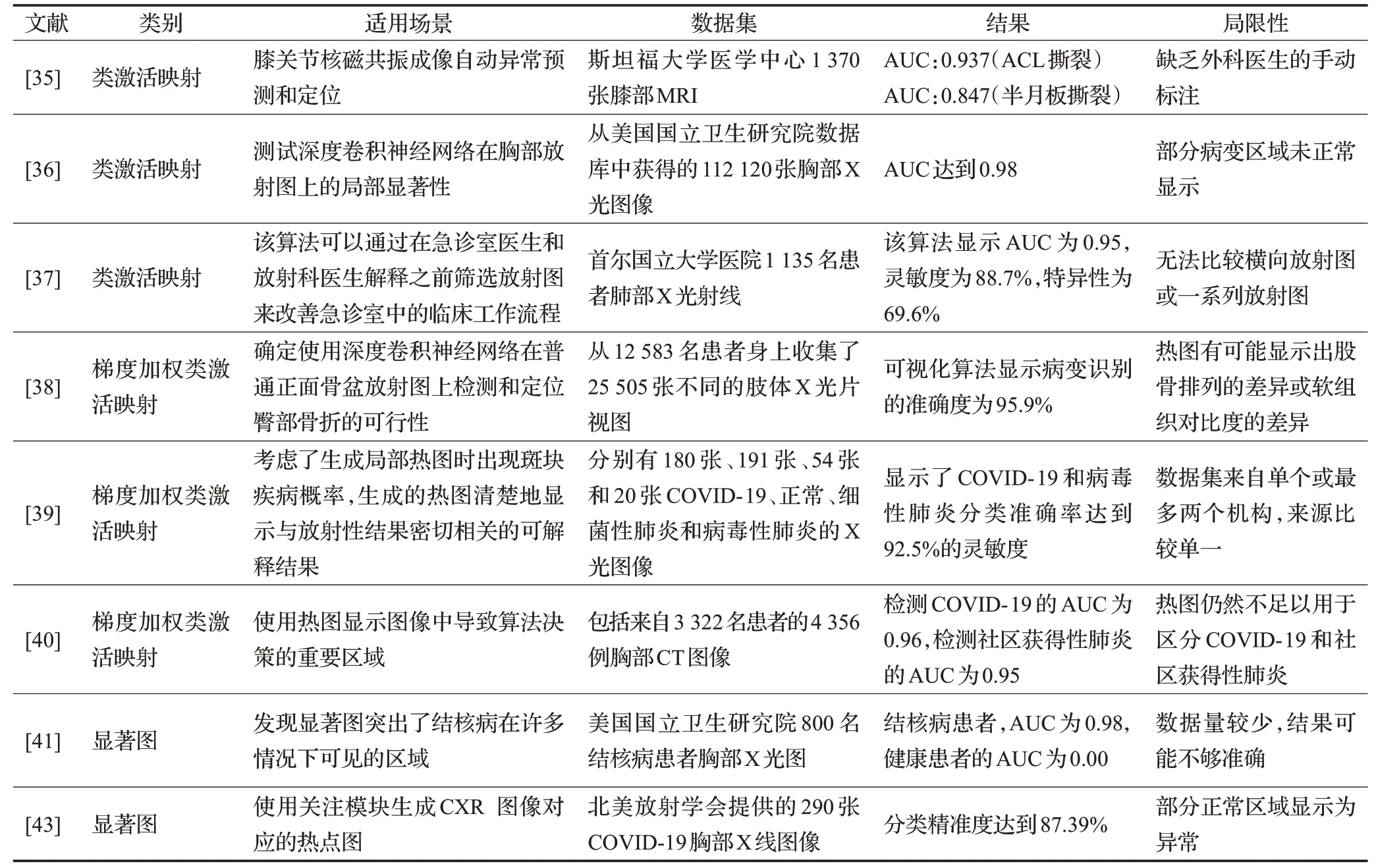
表2 显著性检测在医学图像处理中的应用案例Table 2 Application cases of saliency detectionin medical image processing
4 视觉注意力模型
前面介绍的显著性检测,是一种通过将其应用于已经学习过的模型来确认判断基础的技术,但对性能提升没有直接贡献。它不会直接对性能提升做出贡献,另一方面,视觉注意力模型可以让网络更多地关注重要特征,而较少关注不重要的特征。
视觉注意力模型主要分为硬注意力和软注意力,硬注意力和软注意力最大的区别在于创建的热点图的形式。在硬注意力的情况下,生成的热点图是一个二值掩码的形式,其中重要的特征区域为1,其余的为0,关注区域中只存在一个特定的区域,而不是整个图像。另一方面,由于裁剪的过程是非可微,它无法通过深度学习的反向传播算法训练,训练过程往往是通过强化学习(reinforcement learning)来完成的[44-45]。另一方面,软注意力通常比硬注意力需要更多的内存和算力,但它的创建过程是可微的,因此它的优点是可以轻松地使用反向传播算法以及一般深度学习进行端到端学习模型,所以比硬注意力更积极地被使用。
4.1 硬注意力
硬注意力单纯从技术本身来说它的复杂度比软注意力要高,因为使用反向传播算法很难进行端到端的学习,必须使用强化学习。在这篇综述中,介绍了硬注意力的相关研究,以帮助读者理解基础知识。使用循环注意力模型(recurrent attention model,RAM)是基于强化学习的硬注意力模型,它循环搜索包含核心信息的区域,并利用循环神经网络(recurrent neural network,RNN)和强化学习来训练。
第一次将这种方法应用于医学图像处理的是Guan等人[46],该方法与现有的基于卷积神经网络的方法相比,即使参数少得多,也表现出相对更好的性能。然而由于该方法是基于图像块的方法,提取的信息有限,因此可能需要非常大量的训练迭代才能访问到核心区域。这种方法与基于CAM的热点图提取略有不同,其中基于CAM的方法使RAM依据特定类别的权重来显示关注的区域,硬注意力不同之处在于该模型不使用权重,而是表现模型在计算过程中整体关注的部分。实验结果显示,使用全局和局部图像的融合模块的分类准确度高于每个全局模块和局部模块的准确度。然而对于病理范围较广的疾病,例如肺不张或心脏肥大,融合区域模块有时会导致性能下降,推测这是因为在大面积中存在的疾病的信息丢失,这对准确分类产生了不利影响。
因此,硬注意力机制可以分析模型关注的区域,并且可以让模型更多地关注核心区域来获得额外的性能改进。硬注意力等视觉注意力模型的优势在于,它通过允许网络自行创建焦点区域,而无需创建边界框来引导该区域聚焦,从而能够对区域进行更精确的分析[47]。
但是,硬注意力机制的缺点是实现起来不方便,因为它是不可微的,无法通过深度学习的反向传播算法训练,很难进行端到端的学习,必须像上面的案例那样针对网络的每个模块进行拆分,所以往往只能通过强化学习来训练[48],导致灵活性不足。而且硬注意力在其大部分区域中有许多突然的变化,会给网络模型的计算带来一定的误差[49]。
4.2 软注意力
软注意力与硬注意力不同,因为学习过程是可微的,所以它可以很容易地与深度学习模型结合。换句话说,在将软注意力模块与现有的深度学习模型(如UNet)结合后,注意力模块和神经网络使用反向传播算法共同进行端到端的学习。Attention U-Net[50]是最早将软注意力用于医学图像分析的研究案例之一,当软注意力机制与U-Net相结合时,在腹部CT图像分割方面,与一般U-Net相比,只添加非常少的参数,就能得出提高很多的分割结果。
引进注意力机制的深度学习模型在运算效率方面也非常高,因为网络本身主要通过对核心区域高度相关的特征赋予更大的权重来学习在核心区域激活,所以循环神经网络或前面的网络首先提取核心区域,就像上面介绍的硬注意力方法。换句话说,硬注意力的作用可以通过软注意力来有效替代,注意力机制的效果也体现在性能上。根据相关研究[51],虽然Attention U-Net比普通U-Net有更多的参数,但它即使在训练数据数量极少的情况下,Dice系数和召回率等定量值上表现出更高的分割性能。因此,在一般U-Net上仅增加1.6%左右的参数,Dice系数却有效提升约3.2%。
虽然目前引入的注意力机制主要针对在空间轴上选择集中区域,但有研究在通道方向而不是空间轴上应用了注意力机制[52]。即在深度学习网络生成的特征图中,有与滤波器数量一样多的通道,是一种重新校准过程来增加模型表示能力的方法。
所提出的方法非常简单,主要有两个阶段:压缩(squeeze)和激励(excitation),在压缩阶段,每个通道的重要全局信息通过GAP压缩成一个值。在随后的激励阶段,通过全连接层计算通道之间的相互依赖性,以生成通道中包含特征的重要性成比例的权重。之后,生成的权重乘以压缩前的特征图,并为每个通道赋予一个权重。
由于这种压缩和激励结构也对应于软注意力机制,因此可以应用于各种现有的深度学习网络。它的优点是相比参数增加量,模型的性能提升非常大。换句话说,可以在不显著增加模型复杂度的情况下获得出色的性能提升效果。在最近的研究中,通道注意力出现大量的应用,如在U-Net上结合压缩及刺激结构提高的性能及一般化能力[53]和应用于大脑MRI及全身CT图像的通道注意力[54]。
软注意力机制可以像显著性检测一样用于模型解释的目的,也就是说可以通过观察最终形成的注意力图来找出模型关注的区域。相比于硬注意力,它更被积极用于医学图像相关研究。特别是在MRI、CT以及X线等各种医学图像中,主要研究提高脑[54-56]、胸[57-58]和甲状腺[59]等各种器官和病变的分类和分割精度。它也被应用于皮肤病变分类[60]和手术图像中的手术机器分割[61]领域的研究。
然而,软注意力准确度受制于这样一个假设,即加权平均数能很好地代表关注的领域。另外,在计算上下文信息时,软注意力为编码器的每个时间步骤使用可训练的权重,如果编码器的输入图像很大,这可能是一个非常大的权重参数。在图像分割等这样的任务中,模型越大(就参数数量而言),训练的时间就越长[62]。
综上,视觉注意力模型可以让网络更多地关注重要特征,进而提高神经网络模型的性能。硬注意力相比软注意力要更节约性能和内存,但由于裁剪的过程是非可微,它无法通过深度学习的反向传播算法训练,往往只能通过强化学习来训练,在灵活性方面要比软注意力差许多。而软注意力与现有的深度学习模型(如U-Net)结合后,注意力模块和神经网络使用反向传播算法共同进行端到端的学习,不需要像硬注意力那样对每个模块进行强化学习,相对于硬注意力在灵活性上具有一定的优势,但同时也会花更多的内存和算力[63]。表3总结了每种视觉注意力模型在医学图像处理中的应用案例。
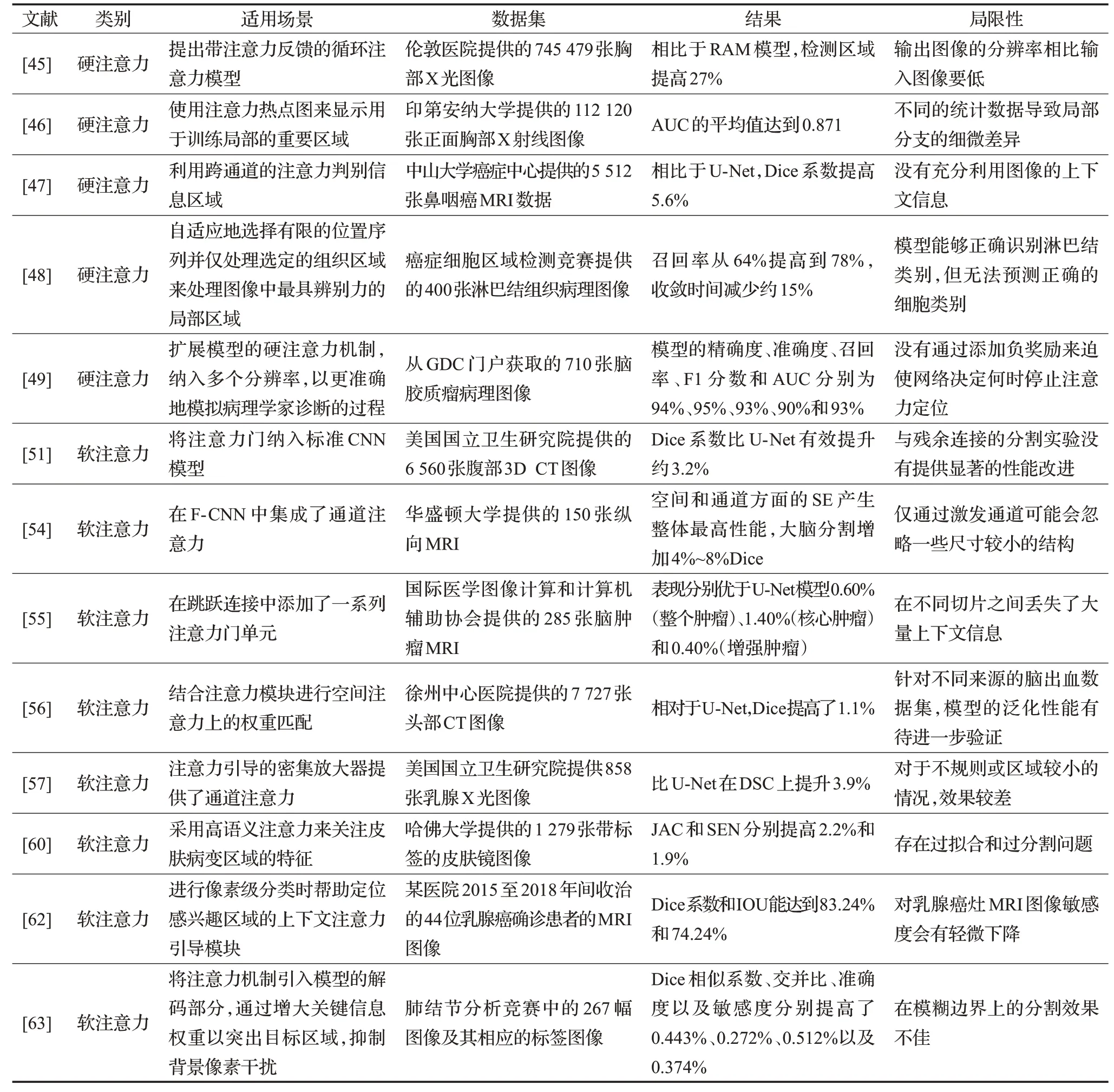
表3 视觉注意力模型在医学图像处理中的应用案例Table 3 Application cases of visual attention model in medical image processing
5 未来热点与趋势
深度学习正在逐步应用于医疗领域,但要安全地、系统地、全面地用于临床实践还为时过早。虽然深度学习还有很多问题仍需解决,但是注意力机制可以有效推动深度学习应用于临床实践。以下列出几个未来值得去研究的方向。
5.1 可解释性人工智能
在医学领域中,确认深度学习模型的判断依据是直接关系到患者生命健康的一个非常重要的问题。此外,医学图像由于其固有的不确定性以及升级困难的医院基础设施等,特别容易受到对抗性攻击。因为这些问题,深度学习模型要想在医疗领域安全使用,必须确认其判断依据的过程。最近提出的用于确认决策和判断过程的技术被称为可解释性人工智能(XAI),其中之一就是注意力机制。注意力机制通过对模型判断的可视化,有望成为将深度学习应用于临床实践的安全支撑[64]。
目前使用注意力机制的XAI已经不罕见。Jiang等人[65]提出了一种基于深度学习的多标签分类模型,该模型采用Grad-CAM,既能进行DR分类,又能自动定位不同病变的区域。减少了人工注释工作,提高了为图像打标签的效率。Cai等人[66]开发了一个基于深度神经网络的前列腺癌临床决策支持系统,以注意力机制视觉叠加的方式在图像上呈现其预测结果,提高模型的可解释性。了解模型预测对于医疗保健至关重要,有助于快速验证模型正确性,并防止使用利用混淆变量的模型。Draelos等人[67]提出了一种新型的特定标签关注机制,可以证明只突出模型用于进行每个预测的位置,推进了医学图像中多重异常建模的卷积神经网络解释方法和临床适用性。
在参考文献中,注意力机制在可解释性人工智能应用上的趋势十分明显。大多数论文使用了显著性检测,即解释是在已经训练好的模型上提供的,而不是在模型训练中纳入。此外,大多数文献都运用局部解释,而不是全局解释,也就是说,解释是针对每个病例,而不是针对所有病人。
大多数适合卷积神经网络的现成的可解释性人工智能方法是CAM,它通常提供训练后的、针对模型的和局部的解释。此外,因为显著性检测可以在神经网络训练完成后使用,这使得它们的结果比视觉注意力模型更容易获得。
5.2 计算机智能辅助诊断系统
许多人正在提出将基于人工智能的自动诊断系统引入医疗薄弱地区的想法。与普通图像相比,医学图像在每幅图像的特征(对比度、形状、直方图等)上非常相似。也就是说,因为医学图像是在患者每个身体部位的固定位置获取的,在要拍摄区域的方向和范围上,与一般图像相比偏差较小。换句话说,注意力机制使深度学习模型专注于哪个区域基本上是确定的,这可以辅助专业水平不高的医务人员逐渐获得重点查看哪些特征区域然后找到特定病变的能力,提高其诊断的速度、准确性和安全性,以解决医疗服务不平衡的问题。
另一方面,在医疗条件相对发达的地区,虽然医生普遍拥有较高的医学水平,但服务的病人多,工作压力大,难免会出现疲劳等情况,而注意力机制可为医生提供一层安全保障,减少发生医疗事故的风险。
Gotkowski等人[68]提出了一个用于生成基于CNN的PyTorch模型的注意力热图的代码库,提高了模型预测能力。该代码库支持2D和3D数据的分类任务以及分割。一个关键的特点是,在大多数情况下,只需要一行代码就可以为一个模型生成注意力热图,基本上是即插即用,可以提高临床医生对计算机智能辅助诊断系统的可接受性,增加了复杂AI系统采用的机会和新型计算机智能辅助诊断系统的临床可行性。此外,在基于注意力机制的计算机智能辅助诊断系统的临床实施方面还存在一些挑战。Cai等人[66]采访了病理学家,发现除了局部解释外,临床医生还需要对模型的整体特性进行深入的了解,例如,他们的能力、局限性、功能、医学视角、特征和设计目标。这些信息丰富了计算机智能辅助诊断系统的可行性,在常规实践中采用这些系统之前是有必要的。
在参考文献中,大多数文献在智能辅助诊断系统的应用上都是集中在视觉注意力模型方面。视觉注意力模型的聚焦区域集中在包含关键信息的病变区域而不是整个图像中存在的不必要的噪声,从而提高了性能。在肺结节等非常局部分布的病变的情况下,提取与整个图像相比占据非常小的区域的核心区域并执行特定分析使得性能显著提高。
5.3 发现潜在诊断方法
注意力机制似乎可以有效地用于发现医学上尚未明确研究的新诊断方法。通过结合注意力机制,深度学习模型可以更多地关注与目的相关的核心区域。这将有助于提高深度学习在分析医学图像时的多功能性,使得医学图像的图像质量和对比度可以根据成像设备而改变,达到兼容MRI、CT以及超声等医学图像的目的。此外,有研究将深度学习应用于胸部CT图像,以比较具有相似图像特征的社区获得性肺炎和新型冠状病毒(COVID-19)患者的图像,提出了通过热点图可视化为深度学习和注意力机制快速诊断新型冠状病毒做出贡献的可能性[68]。
Tosun等人[69]开发了一个初步的应用软件,用于乳腺核心活检。该软件自动预览乳腺核心全切片图像,并识别感兴趣的区域,以互动和可解释的方式快速呈现关键诊断区域。胡耿等人[70]受到注意力机制等最新研究启发,通过长短注意力机制,增加有效对抗扰动的同时减少冗余扰动,并探讨注意力引导机制与DNN对抗攻击的相互关系,将深度学习应用于新型冠状病毒肺炎CT智能识别。Chen等人[71]提出了一种新的半监督图像分割方法,重建目标使用一种注意机制,将不同类别的图像区域的重建分开,在未标记和少量标记图像上进行培训,优于接受过相同数量图像和CNN的受监督CNN,并应用于脑肿瘤图像分割。
将来,注意力机制可能会协助医护人员,结合大数据等技术,为单个患者最佳定制图像剂量。其中,视觉注意力模型可以在图像采集时结合深度学习运用,以提高图像质量。在图像评估的方面,显著性检测可用于生成感兴趣区域,然后由监督医生进行修改,这是提高效率的各种潜在步骤中的一步。或许通过运用注意力机制,人类利用人工智能发现新医学知识的时代即将展开。
6 结束语
本文首先讲述注意力机制的基础知识,然后介绍了注意力机制在医学图像处理中的类别,并且从不同类别介绍了注意力机制可以有效地用于医学图像分析、分类、分割以及诊断方面的例子,最后根据应用于医学图像处理的最新趋势来讨论未来前景和发展方向,为注意力机制在医学图像处理领域的进一步研究与应用提供参考和研究思路。
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
网络安全与数据管理(2022年2期)2022-05-23
现代临床医学(2022年2期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
中国人兽共患病学报(2020年11期)2020-12-08
甘肃教育(2020年22期)2020-04-13
电子制作(2019年15期)2019-08-27
电子制作(2019年24期)2019-02-23
电子制作(2018年18期)2018-11-14
第二课堂(课外活动版)(2016年2期)2016-10-21
