
基于Spark 平台的微震信号鉴别方法
2022-04-16 03:50张忠政卢晓辉王卫东
露天采矿技术 2022年2期
杨 勇,张忠政,卢晓辉,杨 震,王卫东
(1.鞍钢集团矿业公司弓长岭有限公司 露采分公司,辽宁 辽阳 111008;2.东北大学 岩石破裂与失稳研究所,辽宁 沈阳 110819)
钻爆法施工技术和微震监测技术广泛应用于地下矿山、露天矿山、水电站和隧道等岩石工程的建设。凿岩爆破作为岩石工程施工中必不可少的关键环节,必然会对基于微震监测信号的岩体损伤过程分析产生干扰,严重影响分析结果的准确性。因此,在寻找爆破与岩体损伤分别产生的微震信号的区别的基础上,对爆破扰动引起的微震信号进行剔除,是准确分析工程岩体损伤过程的基础和关键[1-6]。
在以前研究中,诸多学者基于爆破产生的微震信号或者声发射信号特性,对爆破与岩石损伤产生的微震信号或者声发射信号进行了区分。例如:赵国彦等[7]采用频率切片小波变换技术对典型的矿山岩体微震信号和爆破振动信号的区别进行了研究;姜鹏等[8]利用S 变换分析地下厂房岩石破裂、爆破振动信号的频率特征,建立基于遗传算法优化的BP 神经网络模型,实现信号的准确分类;李贤等[9]对Allen算法进行改进,提出适用于工程尺度的微震信号及P 波初至自动识别的AB(Allen coupled with Bear algorithm)算法;陈炳瑞等[10]对大量微震信号进行分析,发现STA/LTA 算法在信号实时触发后能大致表征波形振幅和频率的变化,岩石破裂信号和非岩石破裂信号在延迟位置处R 值具有差异性;张法全等[11]针对微震信号难以精确识别的问题,提出一种基于RST-NMF 微震信号时频分析和分类方法;Liu 等[12]根据爆破产生的声发射信号的衰减特征和参数特征对爆破干扰信号进行了准确剔除。上述信号分析方法,能够准确区分岩体损伤与爆破扰动产生的微震或者声发射信号;然而岩体失稳具有突发性,这就要求信号鉴别方法能够对海量的微震信号或者声发射信号进行快速、准确区分。
Spark 平台作为Apache 项目的顶尖大数据处理平台,具有处理速度快、程序编写简单等特点,特别是对于海量数据的处理具有一定的优势。另一方面,在数据分类算法方面有朴素贝叶斯分类器、基于AdaBoost 分类器、SVM 分类器和基于K 邻近算法的分类器等。为此,采用识别微震爆破常用的Fisher 分类算法,通过采用Spark RDD 的方式进行实现,并将分类结果用于后续的风险预报预警。
1 Fisher 线性判别法
1.1 Fisher 算法的基本思想
Fisher 线性判别方法由Fisher 于1936 年提出,该算法主要用于数据分类。Fisher 线性判别方法的本质是将数据点按照离散程度,寻找在最大程度上能够区分数据点类别的投影方向,从而将高维度的数据转换为低维度的数据,由于判别式是线性的,因此,Fisher 算法是一种线性判别方法。Fisher 分类算法示意图如图1。

图1 Fisher 分类算法示意图
Fisher 判别式的一般形式为:

式中:L 为判别指标;Y1、Y2、Y3、…、Yn为判别参数;b1、b2、b3、…、bn为权重系数。
1.2 Fisher 算法步骤
以2 个样本集ω1、ω2的分类为例,介绍Fisher算法的计算过程。
计算各类样本的均值向量Mi(i=1,2):

式中:Ni为样本集ωi的样本个数;X 为样本集ωi中的元素数值。
类内离散度表示各类数据内部点之间的离散程度,总类内离散度表示各类类内离散度的线性代数和,类内离散度Si和总类内离散度矩阵SW的计算公式如下:

类间离散度矩阵Sb衡量了各类别之间的离散程度相关性,该值越大,说明各类之间的离散程度越大,类间离散度矩阵Sb的计算公式如下:

若各类内部的聚集程度越小,而类间的离散程度越大,则说明此时的区分效果是最佳的,反映到表达式上则是类间离散度和类内离散度的比值JF(w)越大,区分效果越好:
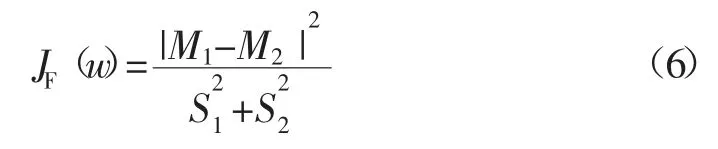
使JF(w)取最大值的解w*是为最佳的权系数,即Fisher 判别系数。最终可求得w*的表达式为:

最终的Fisher 判别式为:

对于阈值y0,这里采用一种简单的计算方式:

式中:m1、m2为一维空间样本均值。
2 基于Spark RDD 的微震爆破智能识别算法
通过搭建Spark 平台,借助Scala 语言和RDD算子编写Spark RDD 程序,将Fisher 算法迁移到Spark 平台下。
在程序的设计过程中,除了核心Fisher 代码,最重要的2 个过程分别是借助数据分析平台从云端数据库远程读取微震信号数据和向云端数据库远程写入处理结果数据,并且在读写的过程中着重考虑程序的I/O 效率。
通过Spark 中的JdbcRDD 方法可以对操作范围、操作方式等进行设定,返回值为JdbcRDD(String,String,Double,Double,……,Double)类型,JdbcRDD 存储类型与从数据库选择读取数据有关。
计算过程将每一条数据转换成LabeledPoint,其中label 为事件类型,feature 为事件特征参数。由于Scala 是一种函数式编程语言,因此可以将求1 组向量的均值向量(meanVector)、计算向量之和(vectorAdd)、计算向量之差(vectorSub)、计算向量点乘积(vectorMulti)、计算矩阵之和(matrixAdd)、矩阵求逆(matrixInverse)等过程封装成函数,然后利用Spark 基本的RDD 算子将各个过程组合起来完成整个过程的计算。由于数据分布式并行在每台机器上,因此为了使处理过程更加高效,对meanVector 的计算结果采用了广播变量(broadcast)的方式,通过这种方式可以将所求得的均值向量以节点为单位共享到每个计算任务中。广播变量如图2。

图2 广播变量
经过Spark 平台下Fisher 算法处理后,需要将数据库写回云平台数据库。按照普通的方式,每传输1 次数据建立1 次Connection,然后关闭Connection,这样会给网络及计算配置造成很大的压力。为了能够高效对数据进行高效、并发处理,采用每个分区建立1 个Connection 的方式,在Connection 量级及操作上会大大改善。
具体而言,RDD 本身是众多机器的数据分区(Partition)代理,1 个RDD 对应集群上所有数据的分区,工程上使用的机群数量有限,Partition 数目也远远不可能达到数据Connection 的数目,在这种情况下,借助Partition 与MySQL 建立Connection,当数据写入时,完成终止连接。Spark RDD 向MySQL 中写入数据如图3。

图3 Spark RDD 向MySQL 中写入数据
通过以上程序处理,可以实现从云端数据库读取数据到Spark 平台下的微震信号分类,再将结果写入云平台数据库的过程,此过程集成了云计算平台与大数据平台的统一调用,可以在工程数据传输和处理上提供一定的借鉴意义。算法识别效果图如图4。

图4 算法识别效果图
为了更加直观地对识别效果进行展示,以Fisher 识别阈值为基本参数,对每个微震和爆破事件求出对应的Y 值。由图4 可以看出Spark 平台下的Fisher 算法判别效果,其中标线为判别阈值Y0=-0.003 321 339,位于阈值线以下的微震数据点为正确识别的岩石损伤事件,反之为误判的微震信号。位于阈值线以上的爆破数据点为正确识别的爆破微震信号,反之为误判的微震信号。
实际工程中数据是海量的,为了验证算法在数据扩展情况下的有效性,这里分别采用(微震,爆破)数据量分别为(10,10)、(20,20)、(30,30)、(40、40)、(50、50)为实例,分别对算法的正确率进行计算,识别正确率结果如图5。

图5 识别正确率结果
将上述方法应用到弓长岭露天矿微震信号与爆破信号识别中,事件判别正确率虽然有所下降,但一直稳定在83 %左右,预测效果较为可靠。
3 结语
将微震信号识别算法迁移到Spark 平台下,实现了岩石损伤与爆破扰动引起的微震信号自动区分。在弓长岭露天矿微震信号与爆破信号的识别中,分类算法识别的正确率稳定在83 %左右,效果良好,因此可大大减少对监测数据处理的工作。此外将Spark 平台与云端数据库的建立远程连接,成功实现了数据传输,为后期基于云计算的预警工作提供了技术基础。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
医学食疗与健康(2022年3期)2022-04-23
健康体检与管理(2021年6期)2021-11-17
汉语世界(The World of Chinese)(2021年4期)2021-09-05
小学科学(2021年7期)2021-08-18
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小福尔摩斯(2021年2期)2021-02-09
青少年科技博览(中学版)(2017年3期)2017-06-15
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
