
基于CUDA编程接口的GPU Trace模块设计
2022-04-20 10:57刘士谦
无线互联科技 2022年2期
刘士谦
(广州海格通信集团股份有限公司,广东 广州 510663)
0 引言
随着5G技术的日益成熟和广泛应用,人们正高速地迈入一个手机、可穿戴设备乃至智能家用电器等设备都能够实现彼此互联,并产生海量信息交互数据的数字化世界。面对海量信息数据的大量涌现,图形处理器GPU凭借其极强的并行计算处理能力,代替数字信号处理器DSP组成GPU+CPU架构的平台。该架构平台为现代无线接入网设备的信号处理提供了一种理想的技术手段。在GPU+CPU平台架构中,如何有效地跟踪调试GPU的运行信息,成为GPU程序开发中必须解决的一个问题。
1 GPU软硬件概述
1.1 硬件架构概述
当前计算机处理器主要分为中央处理器CPU和图形处理器GPU两大类。在传统的计算机架构中,GPU只负责图形渲染,大部分的处理都交由CPU完成。
由于图形渲染的高度并行性,使得GPU可以通过增加并行处理单元和存储器控制单元的方式来提高运算处理能力和存储器带宽。相对于CPU而言,它将更多的晶体管用作执行单元,从而大大地提高了计算能力。从而令GPU在处理能力和存储带宽上相对CPU有着非常明显的优势,在成本和功耗上也不需要付出太大的代价,为提升计算速度、计算能力提供了新的解决方案[1]。
1.2 CUDA编程接口概述
为了推广GPU的应用,英伟达公司于2007年推出了统一计算设备架构(Compute Unified Device Architecture,CUDA)这一易用编程接口。CUDA是C语言的一种扩展,集成了一些CUDA的内置应用编程接口,它允许使用标准的C语言来进行GPU代码编程。编写的代码既适用于CPU,也适用于GPU[2]。
CUDA编程模型将CPU作为主机(Host),GPU作为设备处理器(Device)。Host和若干个Device协同工作,Host负责执行控制部分以及串行运算;Device则专注于执行高度线程化的并行处理部分。一旦确定了程序中的并行部分,就可以考虑把这部分的计算任务分配给Device来执行,运行在Device上的CUDA并行计算函数称为核函数(kernel),一个完整的CUDA程序由一系列的设备端kernel函数和主机端的串行处理部分共同组成。由于CUDA的易用性,已经得到了很多硬件厂商的支持,正逐渐成为首个有可能发展成为GPU开发的候选编程语言[3]。
2 GPU Trace模块设计
在GPU+CPU平台架构中,跟踪记录GPU运行信息最恰当的时间点是在CPU将相关数据交予GPU侧进行运算处理时,对输入及输出的指令和数据进行实时的跟踪记录。为此,在设备CPU侧的系统软件中设计添加一个名为GPU Trace的功能模块,用于记录相关的GPU数据信息。由于在CPU侧调用GPU进行运算处理的软件功能模块数量众多,本GPU Trace模块被设计划分为server和client两部分。其中server部分在设备启动过程中,与其他的各个软件功能模块一同由启动脚本先后创建运行;client部分则以动态库的形式,提供用于跟踪记录GPU运行信息的接口。各个调用GPU进行运算处理的软件功能模块,通过调用client部分提供的函数接口,将需要记录的GPU运行信息数据交由server部分进行统一的存储记录。
GPU Trace模块server部分程序运行流程如图1所示。当GPU Trace模块中server部分在被创建,并完成对设备当前GPU Trace记录的检索后,阻塞等待由client发所送过来的带有Trace数据句柄的消息。当server接收到带有Trace数据句柄的消息,并通过句柄获取到所需要的GPU Trace数据后,记录Trace数据信息并更新相关的Trace信息描述记录。
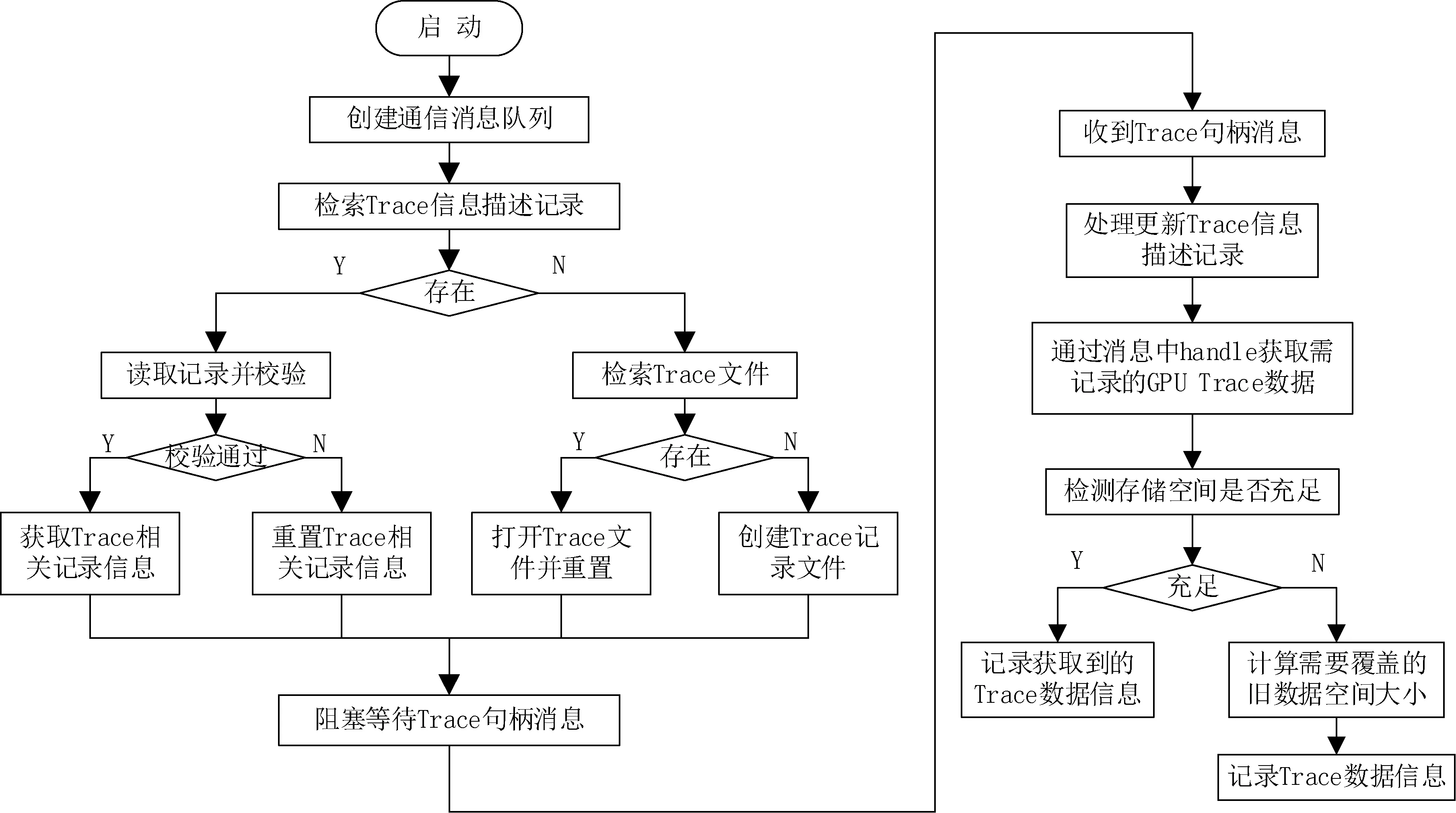
图1 模块server程序运行流程
为了确保记录的实时性,GPU Trace功能模块在内存中开辟了一块存储空间用以记录GPU运行信息。该存储空间由GPU Trace目录和GPU Trace记录数据两部分组成。GPU Trace目录部分,主要用于记录存储空间的内存地址、当前GPU Trace记录序号、存储空间使用情况等信息。GPU Trace记录数据部分,除了GPU运行数据记录之外,每一条Trace记录的Record Head还记录着Trace的序号、长度、是由哪个模块申请,以及执行Trace记录操作的时间和代码的位置。GPU Trace记录数据部分采用循环的形式进行存储,当存储空间不足或耗尽时,新的GPU的运行记录信息将会覆盖最早的记录信息。
3 GPU Trace模块实现
在设备运行过程中,各个需要记录GPU运行信息的软件功能模块,通过调用GPU Trace模块中client端的GPU Trace函数向server端发送带有Trace数据句柄的消息。该函数主要代码如下:
cudaIpcGetMemHandle(&handle, (void *)devPtr);
msg.gpu_msg.handle=handle;
msg.gpu_msg.length=size;memcpy(msg.gpu_msg.module_tag, module_tag, 10);
snprintf(msg.gpu_msg.file, 20, "%s", filename(file));
msg.gpu_msg.line=line;msg_send(&msg, server_mbox, MSG_MY_MBOX);
GPU Trace模块server端在接收到带有Trace数据句柄的消息后,通过调用Fetch_GPU_Data函数获得需 要记录的GPU数据。然后将GPU数据与client端发送过来的Record Head信息,一同存储到在内存中开辟的GPU Trace存储空间中的GPU Trace记录数据部分。Fetch_GPU_Data函数的主要代码如下:
cudaIpcOpenMemHandle ( devPtr, Handle, cudaIpcMemLazyEnablePeerAccess);
cudaMemcpy ( buff, devPtr, length, cudaMemcpyDeviceToHost);
cudaIpcCloseMemHandle(devPtr);
4 结语
本文基于CUDA编程接口,设计了一款GPU Trace模块,实现了在GPU+CPU平台架构中CPU侧对GPU运行数据的获取和记录。该GPU Trace模块为在采用GPU+CPU平台架构的现代无线接入网设备中,跟踪调试GPU的运行信息提供了一种实时高效的技术手段。
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
电脑爱好者(2019年17期)2019-10-30
电脑知识与技术(2016年33期)2017-03-21
软件导刊(2016年9期)2016-11-07
通信电源技术(2016年5期)2016-03-22
石油知识(2016年2期)2016-02-28
自动化仪表(2015年11期)2015-04-01
