
基于距离相关的超高维竞争风险数据特征筛选*
2022-04-20 01:27陈晓静陈晓林
曲阜师范大学学报(自然科学版) 2022年2期
高 静, 陈晓静, 陈晓林
(曲阜师范大学统计与数据科学学院,273165,山东省曲阜市)
0 引 言
随着社会经济和科学技术的发展与进步,社会卫生经济学、生物信息学、金融学等各个领域都出现了复杂的超高维数据.在超高维数据中,协变量维数p远远大于样本量n.特征筛选作为一种处理超高维数据的重要统计方法,近年来引起了研究学者们的广泛关注.Fan和Lv(2008)[1]在超高维线性模型下基于Pearson相关系数提出了一种确定性独立筛选方法(SIS),该方法能将协变量维数从超高维快速地降低到一个较小的范围.这样就可以方便地使用基于惩罚的变量选择方法对数据进行进一步分析.Fan和Lv(2008)[1]首次为这种降维方法建立了理论基础.受该工作的启发,许多统计学者对这类方法进行了研究.Fan和Song(2010)[2]在广义线性模型下提出了基于最大边际似然估计的确定性独立筛选方法,这实际上是SIS方法的一个拓展.Liu等(2014)[3]在变系数模型下提出了基于条件相关系数的特征筛选方法.Zhu等(2011)[4]提出了一种无模型的特征筛选方法,适用于许多常用的参数和半参数模型.在度量变量之间相关性的指标中,距离相关具有一些优良的性质,例如两个随机变量独立等价于它们的距离相关为零,它能度量变量之间非线性相关等.因此,它特别适合用来进行超高维数据的降维.Li等(2012)[5]首先在一般的完全数据下研究了基于距离相关的特征筛选.数值模拟显示,该方法明显改善了SIS方法的不足之处.Huang等(2014)[6]基于Pearson卡方检验提出了一种特征筛选方法.Pan等(2016)[7]基于期望差提出了一种成对准确独立筛选方法.Kong等(2019)[8]基于复合决定系数提出了一种筛选方法.Zhou等(2020)[9]基于累积差分提出了一种无模型向前筛选方法.
超高维生存数据是一类涉及生存时间的特殊类型的超高维数据.在这一类数据中,响应变量是研究个体的生存时间,例如病人从确诊某种疾病到死亡的时间,某人从失业到再就业的时间等等.在生物医学研究中,研究个体可能不仅会经历感兴趣疾病的死亡,还会经历其它不感兴趣疾病的死亡.例如,某研究关心病人从确诊到死于癌症的时间,但是病人还可能会死于心脏病、糖尿病等其它疾病.这种情况下,病人从确诊到死于癌症的时间是不一定能观测到的.在文献中,把关心的疾病导致的死亡称为感兴趣事件,其它疾病或原因造成的死亡称为竞争事件.这类涉及竞争事件的生存数据被称为竞争风险数据.不同于标准的生存数据,竞争风险数据中不仅会出现由于研究终止、研究个体退出研究等原因导致的感兴趣事件观测不到(即右删失),还会出现由于竞争事件的发生导致感兴趣事件观测不到.在分析竞争风险数据时,既不能删除右删失的数据,也不能简单地把竞争事件的发生认为是右删失.因此,超高维标准生存数据的特征筛选方法不能简单地用于超高维竞争风险数据.对于超高维竞争风险数据的特征筛选问题,文献中的研究还较少.Li等(2018)[10]在比例子分布风险(proportional subdistribution hazards,PSH)模型下提出了两阶段的方法,并证明了相应方法的确定性筛选性质.Chen等(2020)[11]把Zhu等(2011)[4]的方法推广到了超高维竞争风险数据,提出了一种无模型的特征筛选方法(CRSIRS).Li(2020)[12]基于相关秩提出了一种特征筛选方法(CRCRS).尽管这些方法具有很多优点,但需要注意的是Li等(2018)[10]是基于PSH模型这一特定模型的,在实际应用中,此类模型不一定成立.Chen等(2020)[11]和Li(2020)[12]提出的两种特征筛选方法所选取的筛选指标有一定的局限性,此时筛选指标等于零并不能说明协变量与响应变量的独立性,故不能准确探测两者之间的非线性关系.为了改进这些方法存在的不足,提出更加适合超高维竞争风险数据的特征筛选方法就显得尤为重要.
针对超高维竞争风险数据,在稀疏性假定下,本文提出了一种新的基于距离相关的特征筛选方法.该方法对于协变量、感兴趣事件时间、其他竞争事件时间都具有很好的稳健性.此外,该方法不需要预设某种特定的回归模型,可应用于协变量、感兴趣事件时间、其他竞争事件时间之间的各种线性、非线性关系.
1 方 法
记个体的生存时间为T,J为失效类型,J的取值为1和2,分别代表失效原因为感兴趣事件和其它竞争事件.在实际医学临床研究中,由于研究时间有限、受访者失访等原因,个体的生存时间往往被右删失了.记删失时间为C,则实际观测时间为Y=T∧C,删失指标为δ=I(T≤C).在这里,需要注意的是当生存时间T被C删失时,失效类型J也就未知了.记对感兴趣事件时间有潜在影响的协变量为x=(X1,X2,…,Xp)T,其中p是维数,对响应变量有重要影响的协变量的指标集合为
M={1≤k≤p:F1(y|x)依赖于Xk},
其中F1(y|x)为给定协变量x时感兴趣事件时间的条件累积发病率函数.我们的目的是把它估计出来.
对于竞争风险数据,不能直接利用Székely等(2007)[13]提出的距离相关来衡量协变量与感兴趣事件时间的相关程度.为了能使用距离相关度量协变量与感兴趣事件时间的相关性,我们通过它们的分布函数和累积发病率函数对它们进行变换.对每个协变量Xk,我们记其累积分布函数为Fk(xk)=Pr(Xk≤xk);对感兴趣事件时间,我们记其累积发病率函数为F1(y)=Pr(T≤y,J=1).为了度量每个协变量Xk和感兴趣事件时间的相关性,考虑Fk(Xk)和F1(T)的距离相关
其中dcov(Fk(Xk),F1(T)),dcov(Fk(Xk),Fk(Xk))和dcov(F1(T),F1(T))三者的定义类似,下面以dcov(Fk(Xk),F1(T))为例说明其表达式的具体形式,其余两者的表达式可以相应得出.令

下面考虑特征筛选指标的估计. 记{Yi,δi,δiJi,xi,i=1,…,n}为一个独立同分布样本.对协变量Xk,累积分布函数Fk(xk)的估计为
感兴趣事件时间累积发病率函数的估计为
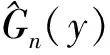

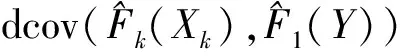
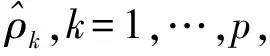
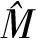
为了证明CRDC-SIS的大样本性质,我们给出下面的假设:
(A.1) 存在正常数τ和η,使得Pr(t≤T≤C)≥η,其中t∈(0,τ],τ是最大随访时间;sup{t:Pr(T>t)>0}≥sup{t:Pr(C>t)>0};函数G(y)具有一致有界的一阶导数.
(A.2) 存在正常数c1和κ∈(0,1/2),使得真正重要变量筛选指标的最小值满足
假设(A.1)在生存分析文献中很常见,可以保证Kaplan-Meier估计有良好的表现.许多文献中都采用了该假设,例如Zhou等(2017)[14]和Chen等(2020)[11].假设(A.2)要求筛选指标的最小值不能太小,即真正重要变量与响应变量之间的相关性不能太弱.
为了证明CRDC-SIS的确定性筛选性质,首先给出一个引理.记概率空间(Ω,Fz,Pr),其中Ω为样本空间,F为σ代数,Pr为概率.记
根据假设(A.1)和Zhou等(2017)[14]的引理1,可以得到
是几乎处处成立的.记上式成立的集合为Ω0,则Pr(Ω0)=1.以下的证明都是在Ω0上进行的.
引理1假设(A.1)下,对于任意ε∈(0,1),可得
该引理可由Li(2020)[12]的引理1得到.
在给出CRDC-SIS确定性筛选性质之前,再引入新的记号.记
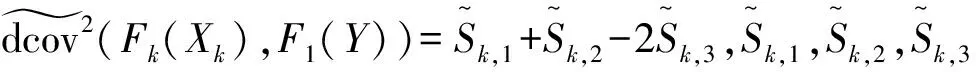
定理1假设(A.1)下,有
其中d1为一正常数.进一步地,假设(A.2)也成立,令vn=c1n-κ,可以得到
其中q是协变量中真正重要的变量的个数.
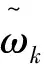
≜T1+T2.
对于T1,可以得到
又因为F1(Yi)-F1(Yj)|≤1,有
其中最后一个不等式由DKW不等式得到.
对于T2,可以得到
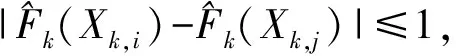
其中最后一个不等式由引理1得到. 因此
2exp(-nε2/c2)+2(n+1)exp(-nε2c3)=
其中c2=1/8,c3=1/32,d1=min{c2,c3}.
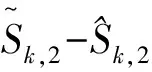
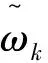
又根据Li等(2012)[5]的证明可知
最终得到
O{pexp(-d1n1-2κ)}.
因此可以得到
1-O{qexp(-d1n1-2κ)}.
定理证毕.
2 数值模拟
在本节,我们通过2个例子来检验CRDC-SIS的有限样本性质,并和CRSIRS[11]和CRCRS[12]2种筛选方法进行比较.对于协变量x=(X1,X2,…,Xp)T,我们假定x~N(0p×1,Σ=(ρ|i-j|)p×p),ρ=0.9.在模拟中,样本量n取为200,协变量维数p的取值为1000和3000,删失时间C服从(0,6)上的均匀分布.基于500次的数据重复,我们考虑下面的指标:真正重要变量被筛选出来的频率分别记为pk;全部重要变量都被筛选出的概率Pa.
例1假设感兴趣事件发生的概率为Pr(J=1)=0.7,竞争事件发生的概率为Pr(J=2)=1-Pr(J=1)=0.3.感兴趣事件时间和竞争事件时间分别为T1和T2,两者分别满足回归模型
log(T1)=0.8cos(X1+0.5X2+X3)+sin(X2)+cos(1.5X3)+ε1
和
log(T2)=0.8sin(1.5X1+0.25)+sin(X2X3)+0.5tan(X3)+ε2,
其中随机误差ε1和ε2服从标准正态分布.从模型中,可以看出,真正重要的变量为X1,X2和X3.在本例中,删失率大约为45%.例1的模拟结果列于表1.

表1 例1中pk和pa的模拟结果
根据表1,可以看出,在不同参数设定下,本文所提出的筛选方法将所有重要变量筛选出来的频率pa要明显大于CRSIRS[11]和CRCRS[12]2种方法.
例2本例中感兴趣事件和其他竞争事件发生的概率同例1.T1和T2分别满足的回归模型如下
log(T1)=2sin(2X1+X3)+0.5tan(X1X2)+1.5cos(X2)+1.5sin(X2+X3)+ε1
和
log(T2)=0.5sin(X1+0.15X2)+0.2sin(X1)+X3+0.15tan(X3)+ε2,
其中随机误差ε1和ε2服从标准正态分布.真正重要的变量为X1,X2和X3.在本例中,删失率大约为46%.例2的模拟结果列于表2.
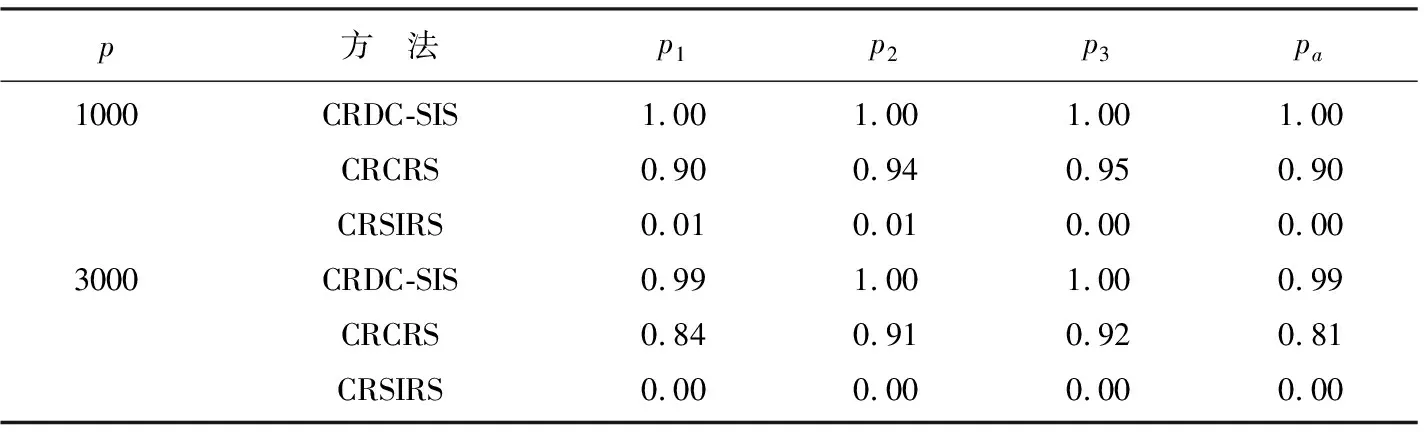
表2 例2中pk和pa的模拟结果
我们可以从表2中看出CRDC-SIS方法一致地优于另外2种方法.此外,根据表2发现,在非线性模型中,CRSIRS[11]方法将各个重要变量筛选出来的频率p1,p2和p3都非常小,在此情况下,将所有真正重要变量全部筛选出来的频率pa也很小.对于CRCRS[12]方法来说,虽然频率较CRSIRS[11]方法大,但其表现稍差于本文的筛选方法.因此,本文所提出的筛选方法对于本例的非线性模型也有很好的表现.
3 实例分析
本节将CRDC-SIS方法应用到膀胱癌数据集[15].该数据集包含301位病人的数据,其中响应变量数据分为3类:患者死于膀胱癌,即感兴趣事件;死于其他原因,即其他竞争事件;由于临床研究时间限制或者失访而产生的删失数据.除了生存时间,本数据集还包含1381个基因和5个临床变量.据了解,人体内某些基因会影响膀胱癌的发病几率.因此,我们拟利用本文提出的方法筛选出对膀胱癌有重要影响的协变量.首先,我们将CRDC-SIS、CRSIRS[11]和CRCRS[12]3种筛选方法应用到膀胱癌实例中,筛选出[n/log(n)]=52个基因. 3种方法共同筛选出了16个基因.这些基因是更有可能导致疾病发生的重要基因.
由于筛选出来的基因个数还较多,我们采用基于惩罚的变量选择方法进行进一步的降维.在竞争风险数据分析中,应用最广泛的回归模型是Fine和Gray(1999)[16]提出的PSH模型.借助R软件中的程序包crrp和cmprsk来实施基于PSH模型的变量选择方法.基于各种方法的变量选择结果列于表3,其中Est.和Se.分别表示回归系数估计和标准误差估计.回归系数估计越大,标准误差估计越小,则说明识别出的基因对于膀胱癌的影响越显著.
从下页表3看出,CRDC-SIS方法下,SEQ820、SEQ279、SEQ377和SEQ833在4种变量选择方法下都被识别出来.同时,SEQ820、SEQ279在CRCRS[12]方法下也被4种方法所选择,说明这两个基因极有可能是导致膀胱癌的关键原因.CRSIRS[11]方法下除ALASSO外,其余3种变量选择方法都将SEQ820选择出来,这进一步验证了SEQ820对于膀胱癌的重要影响.此外,在同一惩罚函数下,CRDC-SIS方法所确定的基因个数少于其余两种,根据回归系数的估计可知CRDC-SIS方法选出的基因更为显著.这进一步说明了本文所提方法的优越性.
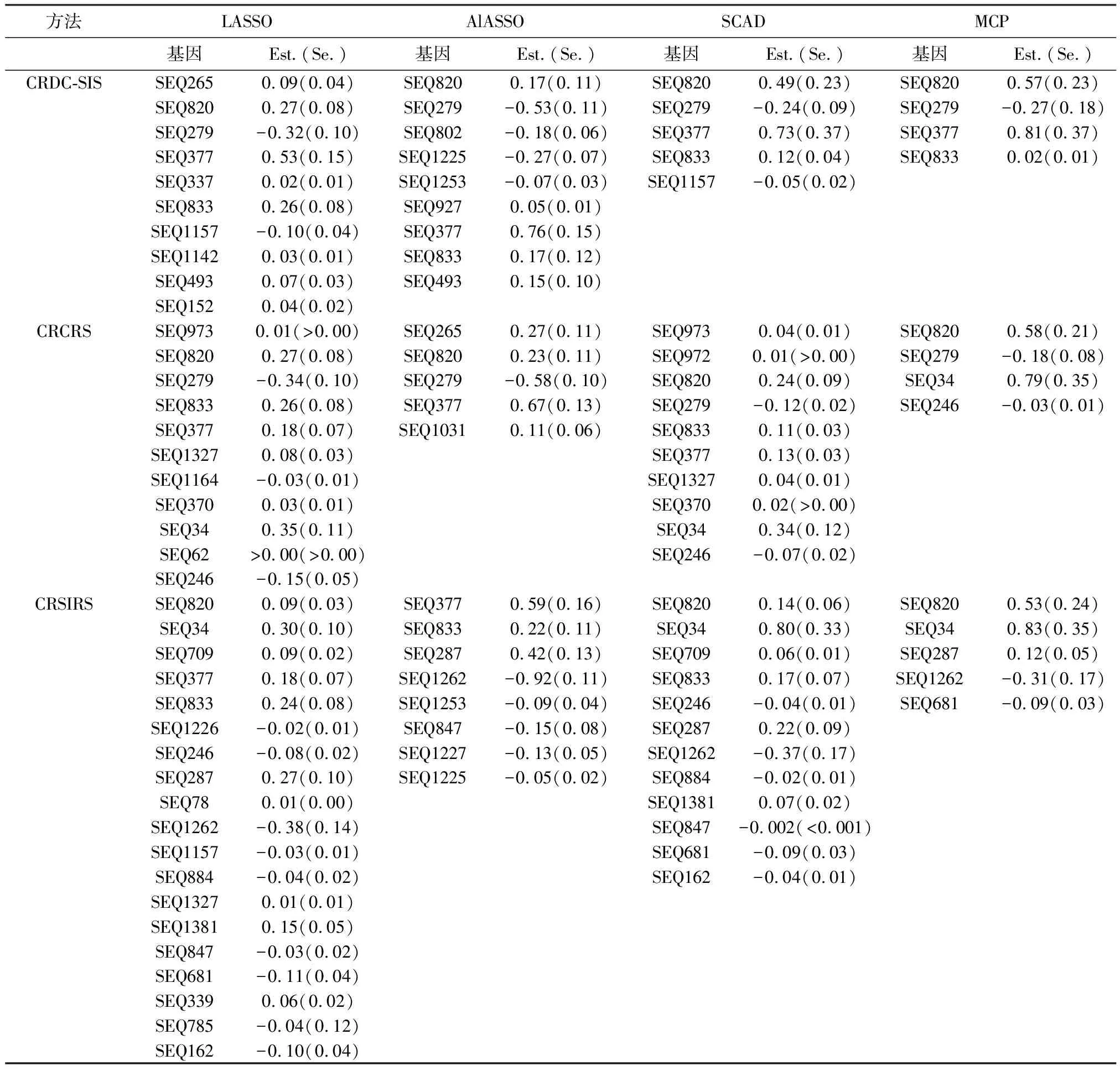
表3 不同惩罚的变量选择方法下的结果
4 结 论
基于Székely等(2007)[13]提出的距离相关,本文构建了一种适用于超高维竞争风险数据的特征筛选方法CRDC-SIS,从理论和数值模拟两方面对其进行了详细的研究.理论研究表明在很弱的假设下,CRDC-SIS具有确定性筛选性质.数值结果验证了本文方法的有限样本性质,并表明新提出的CRDC-SIS要优于文献中已经有的方法CRSIRS[11]和CRCRS[12].注意到本文的实际数据中包含5个临床变量,一般来说,这些变量都是对感兴趣事件的生存时间有重要影响的变量.在变量筛选的过程中,需要把这样的先验信息考虑进来.因此,超高维竞争风险数据的条件特征筛选是进一步要研究的方向.
猜你喜欢
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年1期)2022-02-28
思维与智慧·上半月(2021年8期)2021-08-06
实用肿瘤学杂志(2020年6期)2020-12-09
Drug Combination Therapy(2020年1期)2020-02-14
现代企业文化·综合版(2017年5期)2017-06-14
人生十六七(2015年26期)2015-08-22
小说月刊(2015年9期)2015-04-23
营销界(2015年22期)2015-02-28
博客天下(2009年12期)2009-08-21
