
面向大数据存储的主动与被动相结合的性能评测方法体系结构与实现*
2022-04-21 04:43刘世缘李云春杨海龙
计算机工程与科学 2022年4期
刘世缘,李云春,,陈 晨,杨海龙
(1.北京航空航天大学计算机学院,北京 100191;2.北京航空航天大学网络空间安全学院,北京 100191)
1 引言
大数据技术广泛应用于搜索、社交、金融、医疗和能源等诸多领域,当前,全球数据量飞速增长,根据国际权威机构Statista的统计和预测,预计到2035年,全球数据产生量预计达到2 142 ZB。以往应用程序可以使用传统数据库对数据进行存储,但使用传统数据库的存储方式已很难满足大数据应用的需求[1],因此研究人员设计了一些可以解决大数据存储问题的系统和解决方案。例如,Hadoop分布式文件系统HDFS(Hadoop Distributed File System)[2]、GlusterFS[3]和Ceph[4]等。大数据应用从这些分布式文件系统中读写数据,从而实现对大量数据的分析处理,这也表明分布式文件系统的存储性能会直接影响大数据应用程序的性能,使得分布式文件系统处于十分重要的位置。通过对分布式文件系统进行性能评测,可以指导大数据开发人员分析及定位大数据应用性能瓶颈,提高数据利用率。因此,对分布式文件系统进行性能分析和评测,进而优化分布式存储以及大数据应用的性能,具有重要的研究和应用意义。
分布式文件系统通常利用多个节点来提高系统的吞吐量,保证系统的高可用,实现数据容错,这增加了对分布式文件系统进行性能评测及分析的难度。在以往的工作中,通常使用基准测试的方式来对不同大数据框架进行性能评测[5],或者采用插桩并分析轨迹(trace)文件的方式对分布式文件系统进行性能分析。这2种方法采用的分析角度不同,并没有形成合理的评测体系来评价大数据分布式存储系统。同时,以往的性能评测方法仅针对分布式文件系统本身进行测试分析,而大数据应用与大数据基准测试程序对分布式文件系统的使用模式并不相同。
针对上述背景及存在的问题,本文提出一种主动测试与被动测试相结合的大数据存储系统性能评测体系结构。在主动性能评测方面,对大数据存储系统主动发起性能测试,分析大数据存储系统的基准性能指标,从应用层、分布式文件系统层和基础IO层得出大数据存储系统的基准性能。在被动性能评测方面,通过分析运行在大数据存储系统之上的大数据应用,分析大数据应用程序低效的原因,并根据大数据应用程序不同的低效表现,从低效任务、低效算子和低效函数3个层次对运行在大数据存储系统之上的大数据应用的性能瓶颈进行分析。本文依据提出的大数据存储系统性能评测方法体系结构对HDFS进行了性能评测分析,从不同层次给出了分析结果。
2 相关工作
对大数据存储系统进行性能分析在业界有着广泛的研究,但国内对大数据存储系统的性能分析主要停留在应用配置层面和资源监控层面,缺少对存储系统的多层次、全面的性能分析方法。文献[6]认为Hadoop的应用程序性能主要由4个因素决定:Hadoop执行的应用程序、应用程序的输入、Hadoop集群的资源和Hadoop的配置参数,其中,应用程序无法进行自动优化,数据输入也无法优化,Hadoop的集群资源无法改变,只有Hadoop配置是可以优化的,所以作者只考虑了Hadoop配置的影响。文献[7]对Spark低效算子进行了研究,虽然通过插桩方式得到了Spark算子粒度的性能信息,但并未分析低效算子产生的原因。
而大多数的国外研究则是对存储系统进行细粒度的分析,例如面向性能事件的插桩工具,Magpie[8]和Dapper[9]都需要对源代码修改并进行预插桩后得到性能轨迹数据。XRay[10]是Google提出的一个函数调用轨迹分析系统,可以输出循环计数、时间戳和足够的元数据。另外,文献[5,11]对大数据系统的基准测试进行了较为详细的综述,但均为大数据框架具体的性能指标的采集及评测。文献[12]虽然对现有的基准测试工具的特点进行了对比分析,但仍未提出对大数据存储系统进行性能评测的体系。
上述研究虽然对具体的性能评测方式给予了详尽的分析,但仍缺少对大数据存储系统性能评测体系的研究。为此,本文面向大数据存储系统,在细粒度的性能分析基础上,构建了一种多层次的主动与被动相结合的大数据存储系统性能评测体系结构,来对大数据存储系统进行多角度的测试,为基于大数据存储系统的大数据应用开发人员提供全面的性能评测方案与指导。
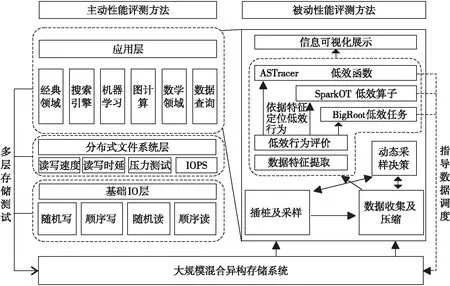
Figure 1 A storage system evaluation architecture with active & passive performance evaluation methods for big data applications
3 大数据存储系统性能评测方法体系结构
为了针对大数据存储系统形成系统的评测方法及评测理论,本文提出了主动测试与被动测试相结合的、面向大数据应用特性的存储系统性能评测体系结构,如图 1所示。
在主动性能评测方法方面,本文可以在应用层、分布式文件系统层和基础IO层对大数据存储系统进行多层次的性能基准测试,为测试人员提供全面、统一的基准测试程序。通过多层次主动评测方法,对大数据存储系统主动发起性能测试,可以了解大数据存储系统的基本性能信息。本文对应用层的经典领域、搜索引擎、机器学习、图计算、数学领域和数据查询共6个领域,超过20个应用进行大数据存储系统的性能测试。在分布式文件系统层,本文集成了开源测试工具,形成统一的程序入口和输出报告。在基础IO层,可以针对具体的存储设备进行随机写、顺序写、随机读和顺序读测试。
在被动性能评测方法方面,本文关注大数据存储系统的重要性能指标[12],并将系统性能指标依据特征划分为4类,即离散特征、数值特征、资源特征和时间特征。应用在存储系统上运行时会产生轨迹(trace)文件,利用合适的分析方法分析轨迹文件可以定位程序的性能瓶颈。本文利用课题组前期工作ASTracer[13]中的自适应采样模块对分布式存储系统进行动态采样率的采样。对采集到的轨迹文件进行数据特征的提取,并定义低效行为,对采集到的任务信息、算子信息、函数信息通过前期工作中的BigRoot[14]、SparkOT[15]和ASTracer[13]分别进行低效任务、低效算子和低效函数定位。
3.1 主动性能评测方法
为了对大数据存储系统进行完整的性能评测,形成完整的性能评测方法体系结构,在本文提出的主动性能评测方法中,需要实现如表 1所示的多层次、多领域的性能测试。
目前业界存在多种多样的性能评测软件,但一些大数据基准测试程序集的测试程序分类不够准确,缺少统一的配置方式,测试结果获取困难,本文对目前广泛使用的基准测试程序进行整合开发。在本文提出的主动性能评测方法中,需要提供多层次的测试方法选择、测试程序配置、测试数据生成和测试结果分析方法。具体需要实现的方法有:
(1) 列出基准测试程序及其相关说明。可以通过程序直接获取应用列表、应用领域对应的基准测试程序列表,以及每个测试程序的功能描述。
(2) 提供测试数据生成和任务运行的配置参数输入功能。根据所选的测试程序,给出测试程序数据生成和任务运行的输入配置参数的帮助。
(3) 测试数据生成。提供基准测试数据生成入口,为相应的测试功能生成所需测试数据。
(4) 测试结果分析。获取任务原始信息并进行处理,提供任务运行过程中的信息以及测试结果。

Table 1 Evaluation layers and fields of active performance evaluation method
多层次多领域的主动性能评测可以为大数据存储系统提供全面的性能指标,在应用层,应用领域的选择能够反映大数据系统基准测试程序集的应用方向,提供大数据应用在不同领域的性能表现,对于大数据Spark程序,可以统计Spark程序的运行时间,以及在当前存储系统上运行时系统IO、CPU、内存等性能变化轨迹,存储系统的读写速率、IOPS等性能参数。在分布式文件系统层,提供当前运行的大数据存储系统负载能力以及吞吐量、操作延迟等性能指标。在基础IO层,提供所用硬件设备的物理性能指标。
通过使用主动性能评测方法,可以为大数据存储系统提供基准的性能测试参数,以及通用应用在大数据存储系统上的性能表现。
3.2 被动性能评测方法
本文提出的基于被动测量的大数据存储系统性能评测方法BDSProf主要包括大数据程序低效任务评测技术、大数据程序低效算子评测技术和大数据程序低效函数评测技术。
被动性能测评方法的核心思想是利用ASTracer[13]中的自适应采样模块对分布式存储系统进行采样率动态变化的采样,收集大数据程序在存储系统上运行时产生的trace文件,对采集到的trace文件进行数据特征提取,并定义低效行为。最终可以分别进行低效任务、低效算子和低效函数定位。
3.2.1 大数据程序低效任务评测技术
Spark将一个阶段划分为多个任务,如果某些任务慢于同一阶段中的其他任务,整个应用程序的执行会因这些任务(也称为慢任务)而变慢。这些慢任务会显著影响整个应用程序的执行速度。但是,传统的性能监控工具如Ganglia[16]和Nagios[17],虽然仍然是大型分布式计算系统所采用的主要性能检测工具,然而其粗粒度的系统运行数据展示无法为具体应用的分析提供所需的细粒度事件信息,不能有效地挖掘慢任务背后的原因并进行有针对性的改进。
低效任务评测技术着眼于应用层面分析,采集被广泛采用的系统特征,包括CPU、IO和网络流量等资源占用特征以及数据局部性、读写数据量、混洗读写数据量、JVM(Java Virtual Machine)垃圾收集时间、任务序列化和反序列化时间等应用特征。评测过程使用Linux采样工具收集系统资源占用信息,采样工具会在Spark启动时,自动开始采样,记录采样开始时间戳,每秒钟搜集一次系统资源占用信息,写入日志,当Spark应用程序结束运行时,调度器在集群各个节点上终止采样进程,然后聚合集群各个节点的采样日志,通过和Spark任务执行时间进行对比,就可以得到任务运行时的资源占用情况。应用特征则是从Spark日志文件中抽取,反映了慢任务产生的内部原因,如数据倾斜、数据局部性、JVM垃圾搜集、任务序列化和反序列化、数据本地性等。运用数学统计的方法,从以上特征中,找出根原因影响程序运行的规律,从而可反向推算根原因出现的时刻。
(1)数据特征提取。
采用Linux采样工具收集系统信息,包括iostat、mpstat和sar。利用式(1)~式(3)分别计算系统资源占用特征[14]:
(1)
(2)
(3)
其中,user_timet是指t时间内用户占用的 CPU 时间,total_timet是指t时间内总的CPU时间,IO_timet是指t时间内IO占用的时间,bytes_sendt是指t时间内网卡发送的数据量,bytes_receivedt是指t时间内网卡接收的数据量。
(2)根原因分析方法。
特征分为4类,包括离散特征、数值特征、资源特征和时间特征,本文针对不同的特征提出了不同的分析方法。资源特征包括CPU、IO和网络特征,属于数值特征的一个特例,由于需要排除应用自身造成的假阳性(FP),所以要有特殊的约束条件。时间特征包括任务序列化和反序列时间、垃圾搜集时间,也是数值特征的一个特例,需要排除该特征虽然有波动但是相比于任务执行时间可以忽略不计的情况。对于数值特征,当满足式(4)中的全部条件时,则认为它是根原因特征。对于资源占用特征,使用边缘检测(Edge Detection)[14]的方法来过滤由任务本身导致的高资源占用率的情况。从数学的角度来讲,如果任务满足式(5)中的全部条件,那么就认为高资源占用率是由任务本身引起的。数据本地性是本文唯一考虑的离散特征。如果局部性值为2并且满足式(6)中的条件,则将局部性作为根原因[14]。
F>global_quantileλq,
F>mean(Fpeer)λq
(4)


(5)
(6)

3.2.2 大数据程序低效算子评测技术
该技术对Standalone模式下运行的Spark大数据应用程序的性能数据进行采集,使用采集到的数据分析性能瓶颈,最终通过可视化展示的形式向Spark大数据程序开发人员提供程序运行时的各层系统性能轨迹、程序运行时事件、Straggler瓶颈任务的检测分析,以及性能热点算子的检测分析服务。
在Spark的图依赖关系中,如果一个弹性分布式数据集RDD(Resilient Distributed Dataset)的分区依赖于父RDD的多个分区,Spark混洗数据之前需要等待父RDD所有分区完成计算,Spark据此将应用程序划分成多个阶段。但是,如果一个RDD只依赖父RDD的一个分区,就无需等待别的分区完成计算,而本文主要分析这种情况下算子的低效行为。这种算子粒度的低效行为比应用粒度的低效任务更为复杂,低效算子不仅要考虑算子相对于其他算子执行时间的长短,还要考虑算子自身的执行时间和算子所在任务的执行时间。
(1)低效算子定义及评价。
为了定位低效算子,本文为每个算子赋予一个低效算子评分,然后将低效评分较高的算子作为低效算子。本文采用算子评分OG(Operator Grade)的方法[18]来对Spark框架中的低效算子进行定位,在计算出每个算子相应的算子评分之后,从中选择评分较高的算子作为低效算子,并进行后续的优化处理。本文主要考虑以下几个评分原则:
① 算子实例的执行时间差异很大,执行时间较长的算子实例应该分配较高的分数。
② 在关键流水线优化后,其他算子流水线有可能会成为新的关键流水线,因此,应该为执行时间较长的算子流水线中的算子实例分配较高的分数。
③ 算子实例的优化潜力也应该被考虑在内,一般来说,相比于同阶算子执行时间更长的算子实例具有更多优化潜力,应该被分配较高的分数。
为了满足第1个原则,本文使低效评分IS(Inefficiency Score)与算子实例的执行时间成正比。为了满足第2个和第3个原则,本文使用流水线因子[18]PF(Pipeline Factor)为每个算子流水线分配一个合理的评分。PF使用式(7)计算:
(7)
其中,i代表第i条算子流水线,j代表第j个片段,ni代表第i条算子流水线内的片段数量,N表示关键算子流水线可以划分的阶段数量,Sj表示第j个片段的流水线执行时间。
为了满足第3个原则,本文使用SS(Straggler Scale)作为IS的一个因子。SS是当前算子实例的执行时间除以同阶算子实例执行时间的中位数,这个因子代表算子的优化潜力。把上述因素组合在一起后,利用式(8)可推导出IS[18]。
ISij=PFi×spanij×SSij=
(8)
其中,spanij是指第i条算子流水线中第j个片段的执行时间,Medianj表示第j个流水线片段的平均执行时间。
3.2.3 大数据程序低效函数评测技术
大数据程序低效函数评测技术重点分析分布式文件系统内部的低效行为,这些性能信息在应用层面和框架层面的性能分析中都无法获取,但是分布式文件系统对所有的大数据系统都是至关重要的,这是大数据应用程序区别于高性能程序的一个重要特点。
分布式文件系统的性能和应用层面、框架层面的性能息息相关,应用层面的数据倾斜和框架层面的Hadoop函数都和分布式文件系统性能紧密相关。
对HDFS进行性能分析必须还原每一个IO请求的函数调用树,否则便无法分析HDFS消耗在各个函数的延迟,也无法定位造成性能瓶颈的高延迟函数。基于单节点的动态插桩技术无法满足分布式文件系统的动态插桩需求,只能采用静态插桩的方式对分布式文件系统插桩(直接修改源代码并进行编译)。
在获取性能日志文件之后,首先需要利用父子关系将日志还原成多个调用树结构,这些树结构规模十分庞大,不便于分析,因此需要采用一种同构树压缩的算法进行大规模压缩。在进行压缩之后,还可以对压缩节点的数据进行规约,比如只保留函数执行时间的均值、方差、极值和分位点等统计信息。经过压缩后不仅数据规模大幅下降,同时也方便抽取典型IO模式以及每种IO模式下的性能瓶颈。
实际HDFS任务运行过程中,有一些调用树会频繁出现,将其全部采样既无必要,又消耗了大量计算和存储资源,有时记录trace消耗的时间会严重影响任务本身的运行时间,另外过大的trace文件对于后续分析也会造成极大负担。与以往的工作不同,本文的采样器都是以调用树为决策的基本对象,而不是全局或单个函数调用。但是,考虑到采样对应用性能的影响,采样器设计不能过于复杂。本文使用根节点近似代替调用树。
针对全局采样率容易造成调用树遗漏的问题,本文使用的方法是根据调用树出现次数调整采样率[19]。该方法主要考虑到不同的调用树出现次数差异较大,尤其是在迭代多次的工作负载中,即使是用了较小的数据量,但由于频繁的迭代计算,不同调用树出现次数相差甚至5~6个数量级。对这类函数的采样会造成trace文件过大,也会对任务性能造成影响。
(1)核心采样器。
① bump采样器。bump 采样器使用bump函数作为采样概率生成器,使用bump函数的原因是,这一类函数存在一个突变点,当变量超过一定值后数值会发生突变,利用该属性,可以把函数调用的执行次数作为变量,设定参数λ的值,可以保证函数在执行指定次数之前有较大的概率被采样到,但超过阈值之后,函数被采样的概率会急剧下降,在保证了函数最低采样的同时,也能防止一些执行次数过多的函数被大量采样。本文中使用的bump函数如式(9)所示:
(9)
其中,t1表示函数执行次数,λ为超参数。
② 令牌桶采样器。该方法的特点在于,不再使用采样率的概念,而是用桶中是否有剩余的令牌来决定是否采样,同时灵活性较高,可以通过设置参数满足不同环境的采样需求。这种方法带来的效果是,频繁出现的调用会被压制,而罕见的调用几乎总是被采样到,尤其是当某一函数调用短时间内高并发式出现时,该采样器可以有效压缩采样。
(2)采样调优。
本文采用了参数自动调优机制,利用模拟退火算法对采样器的参数设置进行自动搜索,从而获取最优的参数设置。模拟退火算法首先设置一个随机的初始解x,并计算目标函数f(x),如式(10)所示:
(10)
其中,entropy(x)表示采样结果的信息熵,代表着trace文件包含的信息量,信息熵越大,获取的信息越多;dist(x)表示采样后的结果和全采样结果的相似度,这里用欧氏距离来表示,欧氏距离越小相似度越高。本文还加入了如式(11)所示的约束:
0.1×Sp0.1≤S≤Sp0.1
(11)
其中,Sp0.1表示使用0.1概率采样到的结果大小,S表示调参后动态采样器采样到的trace文件大小。即在保证较好的压缩trace文件大小的同时又不会因为文件太小而丢失太多信息。
4 实验及结果分析
4.1 实验环境设置
本文实验环境如表 2所示,使用R2220-D08服务器组成集群,通过测试终端登录到集群进行实验。
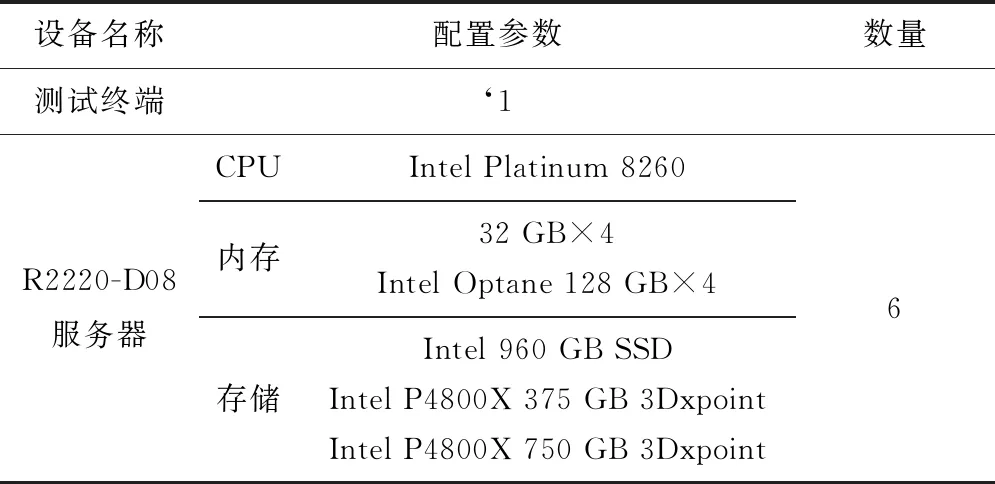
Table 2 Experimental environment configuration
4.2 主动评测性能评测实验
4.2.1 应用层性能评测实验
应用层性能评测以数学领域的Bayes应用为例。运行Bayes应用后,可以在结果文件中得到应用运行过程中的数据吞吐量情况以及不同节点吞吐量情况,如表 3所示。

Table 3 Active performance evaluation results of Bayes application at application layer
主动性能评测记录程序运行过程中的CPU、内存、磁盘和网络使用情况,图 2是截取的与读写相关的性能指标,纵轴表示吞吐量,横轴表示时间,可以观察到程序运行期间读写随时间变化的情况,由于程序运行过程中会提前准备数据,所以写操作发生在前,读操作发生在后。
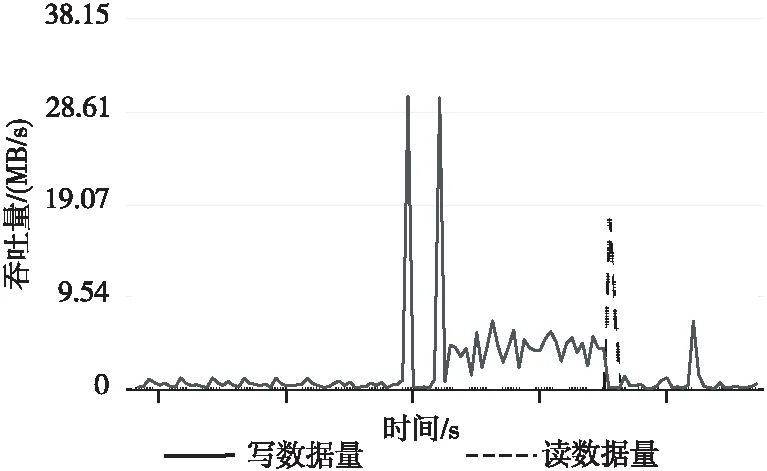
Figure 2 Active performance evaluation partial results of Bayes application at application layer
4.2.2 分布式文件系统层性能评测实验
分布式文件系统层性能评测以Dfsioe测试为例。表 4展示了使用分布式文件系统层Dfsioe应用对大数据存储系统进行主动性能评测的结果。

Table 4 Active performance evaluation results of Dfsioe test at distributed file system layer
在分布式文件系统层进行主动性能评测同样会记录CPU、内存、磁盘和网络使用情况,本文中仅截取与读写相关的性能指标进行展示,如图 3所示,展示了读写速率随时间的变化情况,以及每秒读写次数的变化情况。
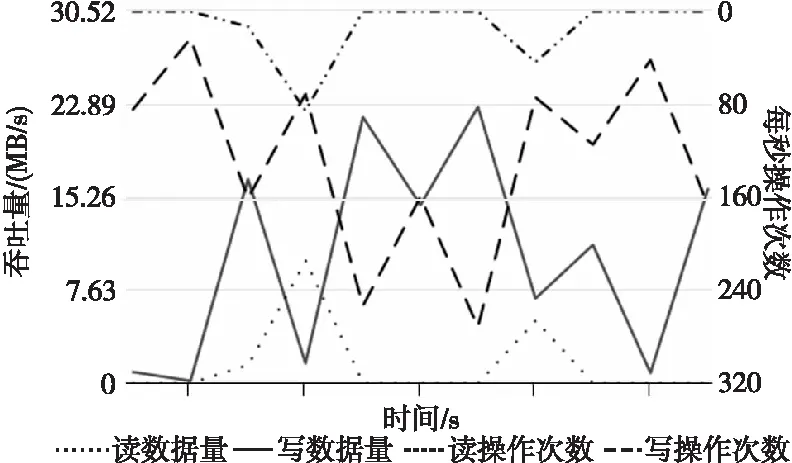
Figure 3 Active performance evaluation partial results of Dfsioe test at distributed file system layer
4.2.3 基础IO层性能评测实验
基础IO层性能评测以Iozone测试为例。在文件块大小为128 MB的情况下,写速率、重复写速率、读速率和重复读速率如表 5所示。基础IO层测试直接在本地完成,可以测试本地文件系统和本地磁盘的性能。
4.3 被动测试性能评测实验
4.3.1 大数据低效任务评测实验
实验使用Bayes应用作为工作负载,从图 4可

Table 5 Active performance evaluation results of Iozone test in the basic IO layer
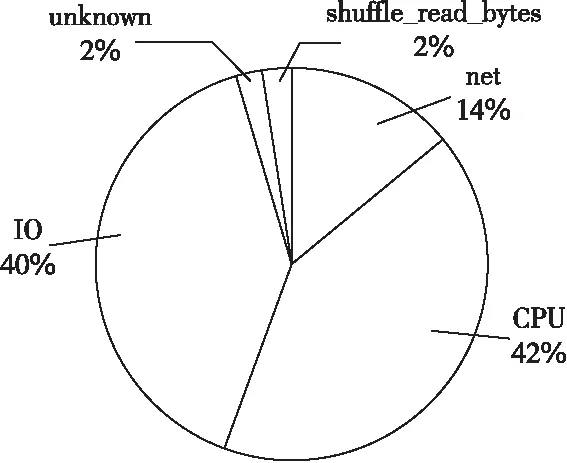
Figure 4 Percentage of inefficiency causes

Figure 5 Analysis results of inefficient tasks
知Bayes的应用特征为IO和CPU占用较大,符合Bayes实际的应用特征。
图5详细展示了Spark运行Bayes应用程序时CPU、IO的资源利用率、慢任务及慢任务产生的根原因。
图5中横轴表示任务执行时间,左侧的纵轴表示资源利用率(百分比),右边的纵轴表示通过将慢任务的持续时间除以阶段持续时间中位数计算出的慢任务因子。图5中水平的黑色部分表示标注了慢任务的时间跨度、慢任务因子(任务执行时间和同阶段所有任务执行时间中位数的比例)及其根原因。图5中同时还展示了未确定根原因的慢任务。图5上方的黑色横线表示注入不同类型异常的开始时间和持续时间。
4.3.2 大数据低效算子评测实验
实验使用Nweight应用作为工作负载,图 6显示了Spark运行Nweight应用程序时每一个导致数据倾斜的任务事件,并得到Straggler在不同task上的分布。

Figure 6 Analysis results of Spark inefficient operator
本实验先用IS定位低效算子,再采用聚类的方法对低效算子的JVM特征进行聚类,通过分析聚类中心的特征大小,就可以判定哪些特征和低效算子相关性较强。
本实验将定性和定量分析不同工作负载下低效算子分布情况。由于工作负载的算子出现的次数较多,因此实验只采取一些有代表性的阶段进行分析并总结出典型的低效算子模式。
4.3.3 大数据程序低效函数评测实验
本实验选用了Hibench中的Kmeans负载来验证ASTracer对其中异常函数的识别能力。对于函数DFSInputStream#writeChunk来说,本实验中观察该函数到75%分位点的执行时间都小于0.1 ms,但是该函数的最大执行时间达到200 ms,这表示工作负载中存在着严重的数据不平衡。
对于Kmeans的机器学习算法要求多轮迭代,表 6展示了Kmeans的采样函数信息,可以看到函数调用次数越多,且不同函数的执行时间不平衡,因此数据倾斜的问题对这样的工作负载有着明显的性能影响。
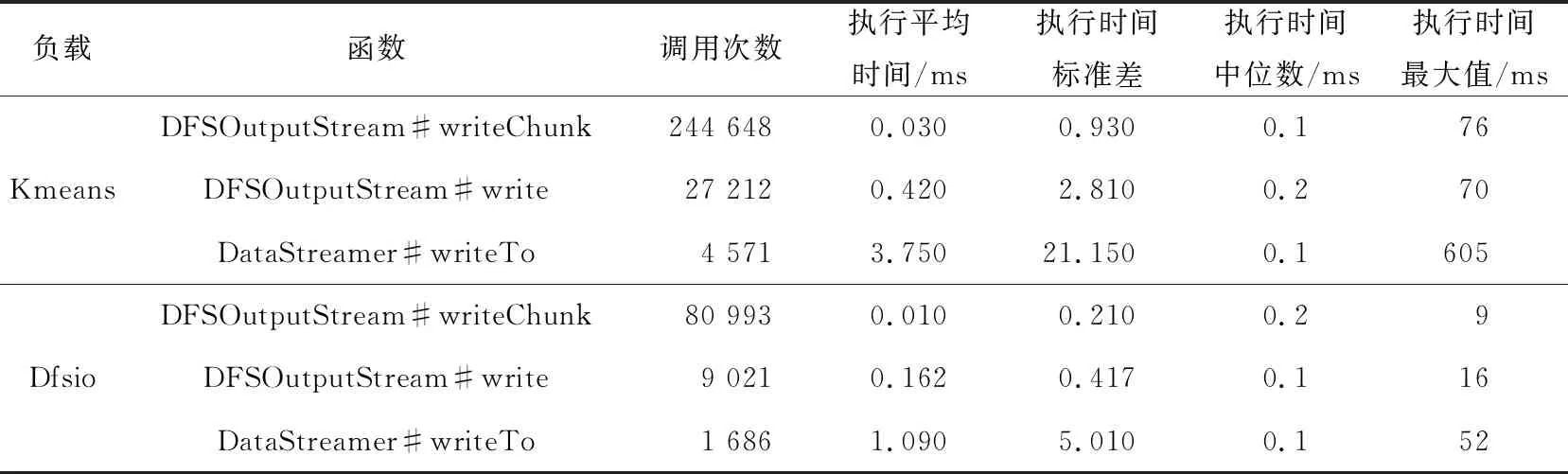
Table 6 Kmeans and Dfsio sampling functions
5 结束语
在数据量与日俱增的情况下,大数据的存储处于核心位置,通过对大数据存储系统性能的评测能够指导实际开发人员分析大数据应用的性能瓶颈,为此,本文基于业界当前工作进展与课题组前期工作提出了面向大数据存储系统的主动与被动测试相结合的评测理论体系,并依据本文所提出的理论体系针对主动测试与被动测试实现了评测工具,给出了当前进行大数据存储系统性能评测的问题分析与评测原理,本文所开发的工具源码已开源至木兰社区[20]。实验结果表明,本文所提出的方法与工具能够提供全面的性能指标,并为大数据存储系统提供多层次的性能评测及分析,具有较强的实用意义。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
煤气与热力(2021年10期)2021-12-02
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
哈尔滨轴承(2020年2期)2020-11-06
校园英语·上旬(2020年1期)2020-05-09
发明与创新·大科技(2019年12期)2019-03-17
卷宗(2017年16期)2017-08-30
弹箭与制导学报(2015年1期)2015-03-11
客车技术与研究(2014年5期)2014-02-28
