
无监督图像翻译的个性化手写汉字生成方法
2022-04-21 05:21陈金宇邹国良郑宗生王振华
计算机工程与应用 2022年8期
卢 鹏,陈金宇,邹国良,万 莹,郑宗生,王振华
上海海洋大学 信息学院,上海 201306
如今,机器学习技术已经被广泛地用于汉字的识别和分类的问题上,但是很少有人研究汉字生成的问题。对于汉字生成的研究主要旨在解决快速构建个人手写字体库以及快速设计新的个性化风格汉字时,减少人员手写量巨大的问题。对于个性化英语字体的生成,只需要涉及到26个字母。而中文有超过80 000个字符,对于生成个性化的手写汉字来说,至少要涉及到3 000个最常用的汉字[1]。因此,生成个性化手写汉字比生成其他语言更具有挑战性。为了满足生成个性化手写汉字的需求,需要一种能够基于相对较少的训练汉字数据集自动生成具有个性化手写风格汉字的方法。
手写汉字的生成没有像数字、英文那样被广泛研究,但是仍然有一些针对手写汉字生成的方法。前期,汉字生成模型的研究主要注重笔画和汉字组件的拆分和重构。将标准字体和目标字体分解成若干组件,利用汉字部件拼接来生成汉字。StrokeBank[2]使用了半监督算法,将汉字分解成一个组件树。这种方法只关注汉字的局部结构,不关注汉字的整体风格,需要为每个新生成的汉字调整笔画的形状、大小和位置。因此,在缩放拼接后,会导致汉字笔画的一致性产生失真,需要人工干预保证提取结果的正确性,对于个性化手写汉字的快速生成并不可行。
FlexiFont[3]系统是将照相机中拍摄的汉字图像生成个人字体库。首先,FlexiFont将用户的手写汉字照片进行分割,然后对每个汉字图像进行去噪、矢量化和归一化的处理,最后将其存储在TrueType文件中。EasyFont[4]是基于样式学习可以构建手写汉字的系统。该系统包含有效的笔划提取算法,该算法从受过训练的字体骨架流形来构建最合适的参考数据,然后通过非刚性点集配准的方法,在目标汉字和参考汉字之间建立对应关系。同时,该系统可以学习和恢复用户的整体手写风格和具体的手写行为。
Zhang等人[5]使用递归神经网络(recurrent neural network,RNN)进行端到端在线手写汉字生成的工作,将笔尖移动(x、y坐标)和笔状态(向下或向上)自动存储为可变长度的顺序数据。该模型对英文手写的识别和生成非常有效,对汉字轮廓的描述不够理想,训练时间漫长。Tian[6]使用了传统的卷积神经网络(convolutional neural networks,CNN)结构,设计了一种“Rewrite”的网络结构,能够生成较标准的字体,但是对于转化风格跨度较大的汉字有很大的缺陷。还有研究者[7]使用“U-Net”[8]基本模型并添加独热编码实现汉字风格的转换。
相比之下,使用有监督图像翻译原理的汉字风格迁移模型zi2zi[9]来生成汉字,会更注重汉字的整体结构特征。Zi2zi利用成对的汉字图像作为训练数据来转换字体风格,并添加了多种字体的类别嵌入,使该模型通过一次训练就将原始汉字转换为几种不同的字体。然而,在数据集采集的过程中,要求用户写出大量的成对汉字是不切实际的,工程量非常大,需要消耗很多的时间和精力。所以,对于快速生成个性化手写汉字的问题,使用非成对的汉字数据集更合适。
本文以无监督图像翻译模型CycleGAN[10]为基础,提出一种结合注意力机制和自适应归一化的无监督个性化手写汉字图像生成方法,本文的主要工作如下:
(1)改进生成器,引入了注意力机制和自适应归一化层。注意力机制是为了在汉字风格转化的过程中提升汉字图像中有用的特征,抑制对当前任务用处不大的特征。自适应归一化层是为了指导残差块对生成汉字的样式进行加强。通过这两种方法,生成器提高了生成手写汉字图像的质量。
(2)改进判别器,利用输入数据一半为真一半为假的先验知识,结合最小二乘法损失函数,从一定程度上解决了训练过程中模型的不稳定。同时,改善了当生成器优化良好时,判别器无法判别真伪的问题。
1 基本原理
1.1 图像翻译
图像翻译(image-to-image translation)[11]是一类将源图像域作为输入转化为目标图像作为输出的计算机视觉处理任务,主要应用于图像风格转换[12]、图片复原等领域。具体的应用包括:虚拟换衣[13]、姿势转换[14]等。生成对抗网络(generative adversarial networks,GANs)[15]作为当前图像翻译任务的主流模型,通过生成器和判别器之间的零和博弈,提高判别器鉴别真伪的能力,指导生成器学习真实的数据分布从而生成逼真图像。
根据训练数据集中源图像和输出图像的对应关系,图像翻译分为有监督和无监督两种[16]。有监督图像翻译需要一一配对的训练图像集,一般都是基于条件生成对抗网络(conditional generative adversarial networks,CGANs)[17]为基础结构改进的。Pix2pix[11]就是典型的有监督图像翻译的方法,它在保持图像结构一致性的情况下完成有标注的成对图像数据间的风格转换工作。而无监督图像翻译方法不需要使用大量配对的训练数据集,训练集中的源图像和输出图像不必拥有明确的对应关系,就能够较好地建立不同图像域之间相互映射关系。CycleGAN、DualGAN[18]以及DiscoGAN[19],它们都是利用循环一致性作为约束条件来保留图像内容结构信息。而UNIT[20]利用共享中间层的网络权重,在生成器中的编码器结构提取不同图像域共享的低维潜在向量后,使用对应的解码器结构建立低维潜在向量与各个图像域的映射关系,完成无监督图像翻译。
当前的无监督图像存在一定的缺点,使它无法生成高质量的图片。首先,无监督的图像翻译训练数据中没有配对的目标图像,翻译过程中目标图像域信息定位不准确,存在无关图像域信息改变。所以在翻译效果、生成图像质量以及模型训练方面存在不足。其次,当前生成对抗网络博弈对抗过程中,生成器要尽可能地生成能骗过判别器的高质量图片,而判别器要尽可能把真实样本分为正例,生成样本分为负例。因此就会存在无法平衡生成器和判别器的缺点。当判别器训练的足够好时,生成器就会完全学不动;当生成器训练得足够好时,判别器就无法判别生成的伪图像的真伪。这些缺点都阻碍了无监督图像翻译模型生成更高质量的图片。
1.2 注意力机制
注意力机制(attention mechanism)[21]应用于递归神经网络和长期短期记忆(long short-term memory,LSTM)中,以解决机器翻译和自然语言处理方面的任务。之后被逐渐应用在计算机视觉中。注意力机制被分为两种[22],一种是柔性注意力(soft attention),它通过强化学习,使用基于梯度下降的方法,利用目标函数或者相应的优化函数来进行,学习完成后直接可以通过网络生成。另一种则是硬性注意力(hard attention),将更多的注意力放在点上。
在计算机视觉中,注意力机制实际上是为了模仿人类观察物品的方式。当人们在观察一张图片的时候,除了从整体把握一幅图片之外,也会更加关注图片的某些局部特征。因此,注意力机制其实包含两个部分,首先,注意力机制需要决定哪个部分需要更加关注;其次,从关键的部分进行特征提取,得到重要的信息。Fu等人[23]提出了循环注意力卷积神经网络(recurrent attention convolutional neural network,RA-CNN),该模型递归地分析图片中的局部信息,从局部的信息中提取必要的特征。Vaswani等人[24]提出的自注意力机制,计算的是同一张图片中不同位置之间的注意力分配,从而提取该图片的特征。自注意力机制在生成对抗网路中解决了卷积神经网络的局部视野域问题,使得每个位置都可以获得全局的视野域。
1.3 图像归一化
在深度学习中,归一化用来解决梯度爆炸和梯度消失的问题。最常用的图像归一化方法有:批归一化[25](batch normalization,BN),层归一化[26](layer normalization,LN),实例归一化[27](instance normalization,IN),组归一化[28](group normalization,GN)等。不同的归一化操作之间的区别是归一化的维度不同,导致操作后的效果不同。
批归一化逐渐变成构建深度神经网络的基本要素,它把每层神经网络任意神经元的输入值分布强行拉回到均值为0方差为1的标准正态分布。批归一化是在同一个批量中,将所有样本的同一层特征图抽出来计算特征统计量。层归一化和组归一化都是批归一化的变体,主要是为了减少批归一化对固有的最小批量的依赖关系。实例归一化是通过调整每个实例的特征统计量来规范图像样式,一般用于样式转换和图像翻译之类的图像生成任务。之后,有研究者提出了批实例归一化[29](batch-instance normalization,BIN)。这种归一化结合了批归一化和实例归一化的优点,考虑到某些样式在判别任务中起着至关重要的作用,BIN会保留维护有用的样式,同时选择性地规范不必要的样式。所以,BIN可以适应不同的图像任务。
2 个性化手写汉字生成模型
2.1 模型总体结构
本文设计的模型是基于CycleGAN网络结构,它无需使用一一配对的训练数据集,就能够完成无监督的图像翻译任务。在此基础上,设计了汉字样式风格迁移的网络模型,将现有印刷字体到个性化手写汉字样式映射过程的问题公式化。
模型整体结构如图1所示。X与Y分别代表两组不同样式的汉字图像集合,模型的主要结构是由两个生成式对抗网络组合而成。第一组生成式对抗网络是生成器G与鉴别器Dy,G尽可能地生成能骗过判别器Dy的图像,Dy用于判断伪图像是否属于图像域Y;第二组反向的生成器F与鉴别器Dx也具有相同的过程。在判别器网络中使用了PatchGAN[10],它将输入的真实图像或生成图像划分为N×N的多个区域,分别对每个区域进行真伪判断。
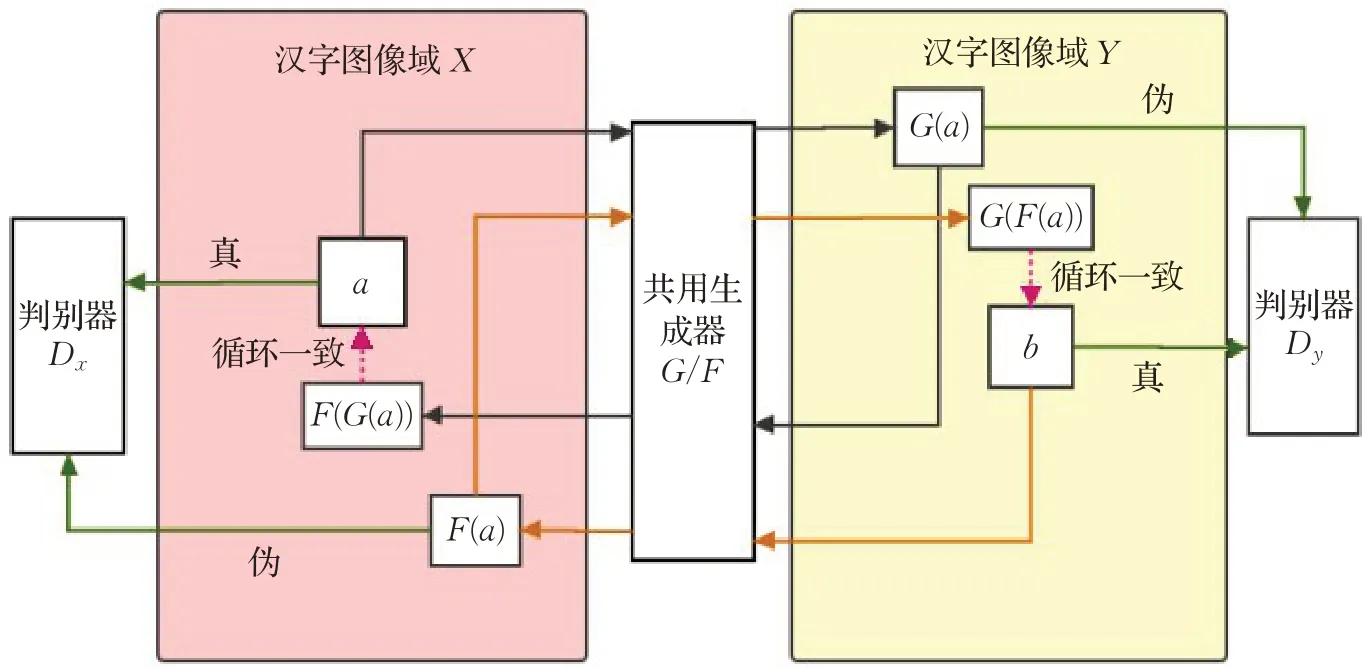
图1 模型整体结构图Fig.1 Network architectures
生成器G和F能够分别产生很多与目标域X和Y具有相同特征分布的输出。所以,仅使用生成对抗损失并不能保证所学习的函数能够将单个的输入x i映射到所需的输出yi。为了进一步缩小可能映射函数的空间,在转换图像域的过程中,保留循环一致性[30]对生成结果的影响,减少了无关图像域的变化,指导整体模型建立图像域之间映射关系,完成无监督汉字图像风格迁移。对于X域中的每个源图像x,要保证x→G(x)→F(G(x))→x,G(x)能通过生成器F得到重构图像,并且F(G(x))≈x。对于Y域中的每个源图像y,保证:y→F(y)→G(F(x))→y。
2.2 生成器结构
为了在汉字图像域转换过程中提高生成汉字图像真实性,获取高质量的个性化手写汉字图像,本文的生成器引入了注意力机制和自适应归一化层。本文的生成器由三部分组成,分别为:由卷积神经网络组成的下采样区域,由残差块[31]、注意力机制和自适应归一化层组成的中间区域以及上采样区域。模型的具体结构如图2所示。
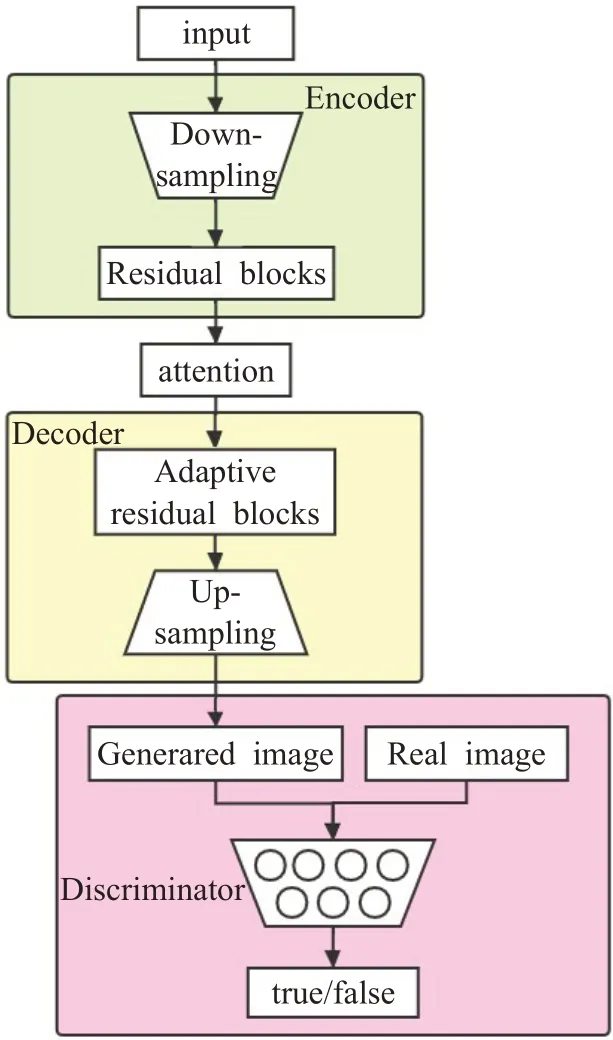
图2 模型总体结构Fig.2 Model structure
2.2.1注意力机制
仅凭借每一层的卷积操作,只能在局部感受野上进行特征融合,无法充分开发通道之间的相关性。添加的注意力机制关注了通道之间的相关性,通过有效的学习方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制用处不大的特征。所以,在生成器的残差块之后,用SENet[32]模型方法的注意力机制去挖掘通过下采样过程后仍然存在的隐式的全局的特征。具体注意力机制块结构如图3所示。
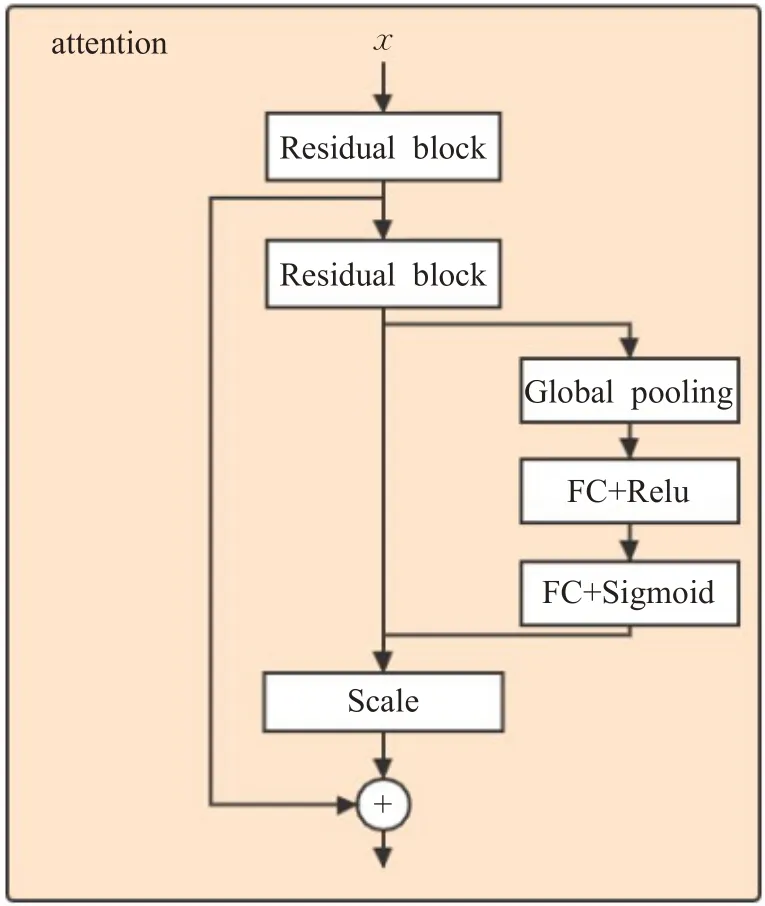
图3 注意力机制块Fig.3 Attention mechanism block

对于一个空间尺寸大小为H×W的输出U,首先会对其顺着空间维度来进行特征压缩,即将H×W×C压缩成1×1×C,尺寸大小压缩成一维,这个一维参数某种程度上代表了之前特征通道上全局的分布,使得靠近输入的层可以获得全局的信息以及相关性,其中z∈ℝC:
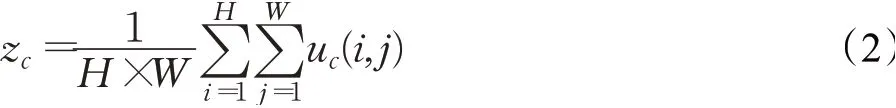
得到了全局描述特征,接着是抓取通道之间的关系,学习各个通道之间的非线性关系。它是一个类似于门的机制。通过参数W来为每个特征通道生成权重,即对每一个通道的重要性进行预测,得到不同通道的重要性大小之后在作用到之前对应的通道上:
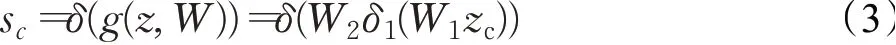
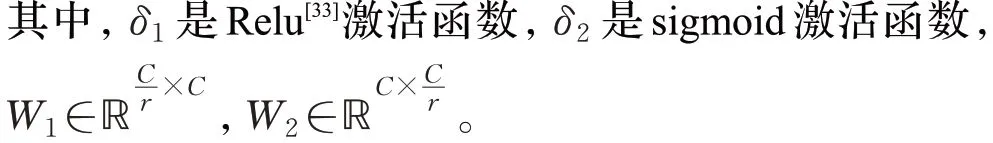
最后,通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征uc的重标定:

通过这样的注意力机制结构,提取到了隐藏在特征通道中重要的特征和图像信息。
2.2.2自适应标准化层
每个特征图所携带的信息可以分为两个部分:内容和形状。在汉字图像的提取上,实例标准化可以规范每个汉字图像的样式,保持每个图像实例之间的独立性。尽管它有助于减少不良的样式变化,但是却产生了通道之间的不相关性,可能会导致信息的丢失。层标准化针对单个汉字图像训练样本的所有维度做归一化,将同一个样本中的特征处理到同一区间中。
本文使用了一种自适应标准化层,结合了实例标准化和层标准化,用它们共同指导后续的残差块进行工作,能灵活地针对每种样式的学习都有一组不同的参数。自适应标准化层的体系结构示例如图4所示。这种自适应标准化层既考虑了汉字图像样式,又考虑了特征通道的相关性,灵活控制汉字图像形状与纹理的变化。实例标准化和层标准化如公式(5)、(6)计算,x∈ℝH×W×C,h、w表示为空间位置,c为通道索引:
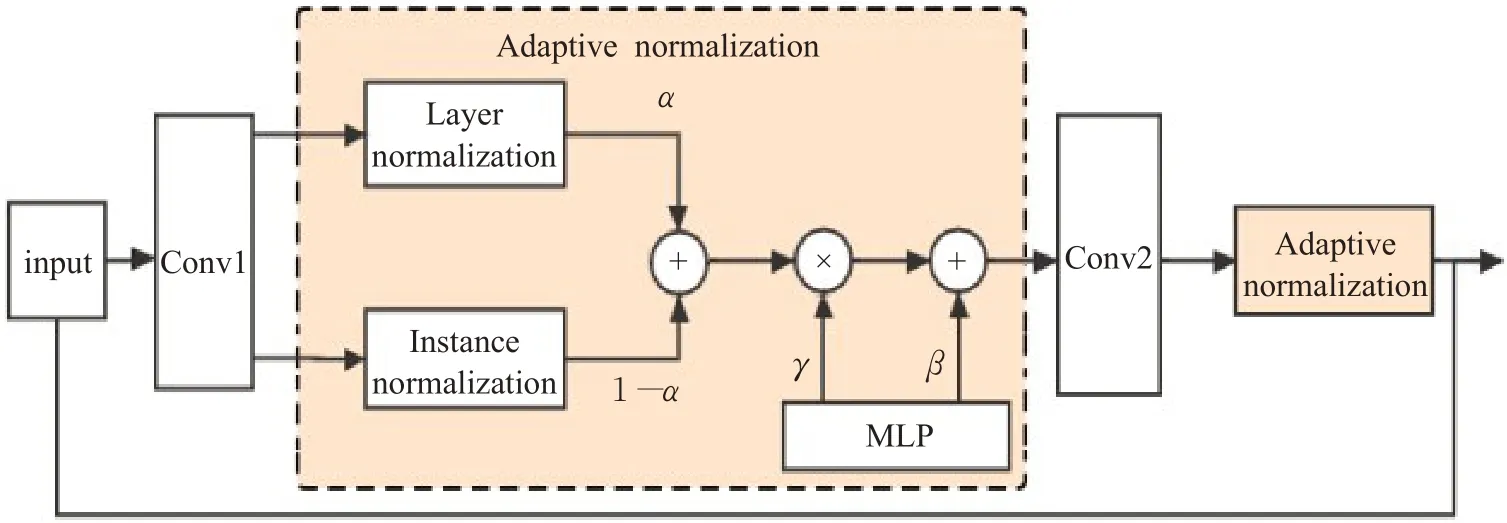
图4 自适应标准化层Fig.4 Adaptive normalization layer
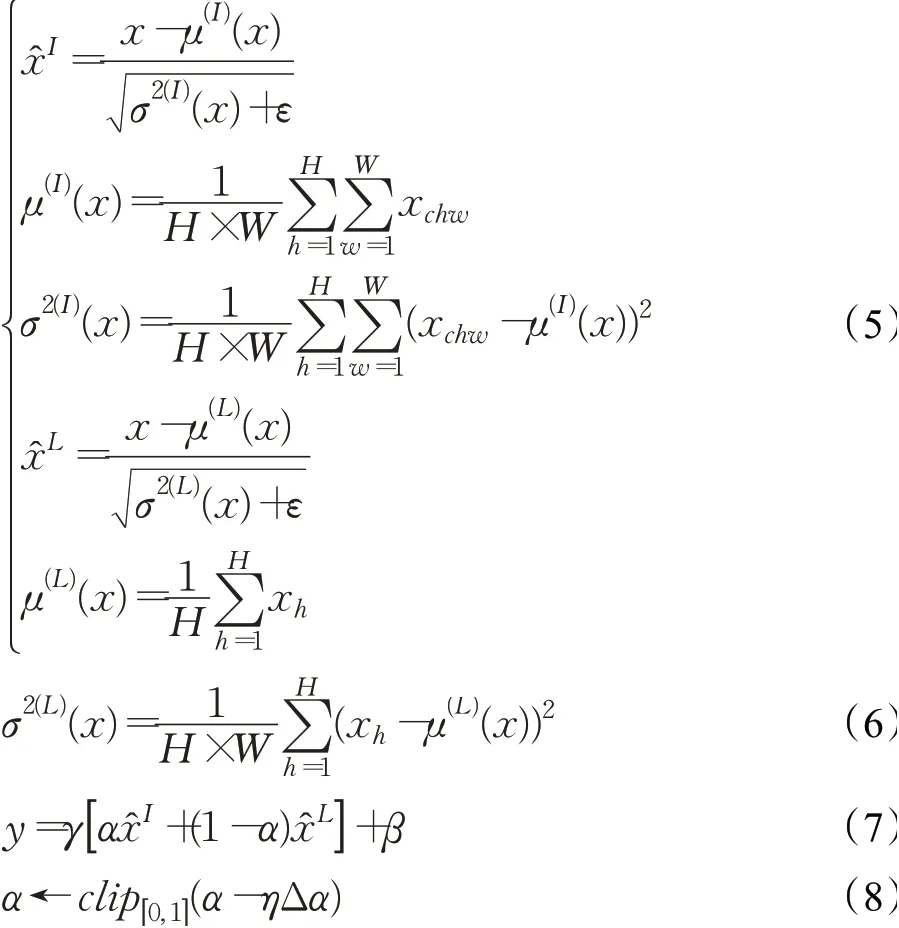
在公式(7)和(8)中,γ和β是多层感知机(multi-layer perceptron,MLP)生成的参数,η是学习速率,Δα表示参数更新向量。通过在参数更新步骤中施加限制,α被限制在[0,1]之间,它决定是维持还是放弃每个通道的样式变化。如果样式对当前任务很重要,则将增加至1。如果该任务不需要样式或干扰了当前的任务,则对应的将接近0。
通过自适应标准化层之后,使用最近邻插值的上采样和卷积层组成的编码器来进行图像的生成。当卷积核大小不能被步长整除时,使用转置卷积会产生不均匀的重叠现象。多层转置卷积的堆叠使用,不均匀的重叠部分就会层层传递,造成生成的图片带有明显的棋盘状伪影,从而影响图片的质量。因此,使用最近邻插值的上采样避免了产生图片伪影,从而生成高质量的图片。
2.3 损失函数
定义pdata(x)表示图像域X的样本分布,pdata(y)表示图像域Y的样本分布,以生成器G和判别器DY为例,使用真实图像y和生成图像G(x)对DY进行训练,并将DY对G(x)的判定结果反馈给G来指导其训练,生成对抗损失[10]为:

原始的生成对抗损失使用的是Sigmoid函数。Sigmoid函数只会关注样本的真假,会迅速忽略样本到决策边界的距离,不会惩罚远离决策边界的样本。本文借用了最小二乘生成对抗损失[34],对处于判别成真的但是远离真实样本的假样本进行惩罚,把远离决策边界的假样本拖进决策边界,从而提高生成图片的质量。
本文在此基础上,还借鉴了相对鉴别生成对抗损失[35]。在没使用相对鉴别生成对抗损失之前,对于图像域X来说,当经过生成器G训练之后生成的假样本G(x)足够真实的时候,判别器DY对真实图像x和伪图像G(x)的判别值是近似的。判别器DY不知道输入中一半是真实数据一半是假数据,就会判别所有DY(G(x))≈DY(y)≈1。但实际情况并不是如此。因此,需要让判别器DY知道输入数据一半为真一半为假的先验知识,将绝对真假变成相对真假。于是将DY(y)改成(DY(y)-DY(G(x))),DY(G(x))改成(DY(G(x))-DY(y))从而改进最小二乘为基础的生成对抗损失函数:

作用于图像域Y,生成器F生成图像的F(y),判别器DX对真实图像y和伪图像F(y)进行判别。将DX对F(y)的判定结果反馈给F来指导网络进行训练也是如此。
为了保证减少了无关图像域的变化,还继承了循环一致性。在循环一致性中,使用L1函数:
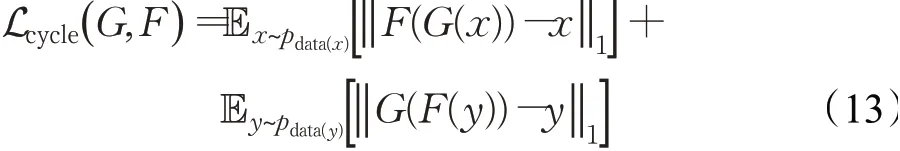
因此,该模型总目标函数为:

其中λ为循环一致性损失相对于对抗损失的权重比例超参数。本文的模型旨在解决:
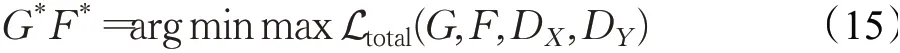
3 实验结果及分析
3.1 实验数据
本文借用了CASIA-HWDB数据集[36]以及《兰亭序》书法作为数据集,通过使用原始的CycleGAN以及改进后融合了注意力机制和自适应归一化层的模型进行了对比实验,验证了本文方法的有效性。数据集具体说明如下:
(1)CASIA-HWDB数据集:CASIA-HWDB数据集是由中国科学院自动化研究所的国家模式识别国家实验室建立的离线中文手写数据库。如今,它被用于中文手写字符识别任务中。该数据集是由1 020位作家使用Anoto笔在纸上制作的孤立字符和手写文本的样本。本文使用来自CASIA-HWDB的HWDB1.1数据集,其中包括来自300个人书写的汉字的文件。每个文件包含由一位作者书写3 755个孤立的灰度汉字图像及其相应的标签。将这些孤立的汉字图像调整为256×256像素大小。除了调整大小外,不执行其他数据预处理。为了生成手写汉字,使用HWDB1.1数据集中的文件HW011(1011-c.gnt)作为目标汉字样式,使用魏碑字体作为源样式。
(2)兰亭序书法数据集:中国书法是一种美学上令人愉悦的书写形式,在中国文化中占有很高的地位。王羲之被认为是中国历史上最伟大的中国书法家之一。本文借用了王羲之一生中最著名的书法作品《兰亭序》作为数据集。它是由324个半草书风格的汉字组成,其中的每个汉字都被扫描并分割开,使用中值滤波将它们进一步二值化和去噪。最后,将这些汉字填充为正方形并调整为256×256像素大小,所得的数据集称为兰亭书法数据集。同样使用魏碑字体作为源样式。
3.2 实验环境及细节
本文实验运行环境为Ubuntu 16.04 LTS,使用的处理器为Intel Xeon E5-2678 v3 CPU@2.50 GHz,GPU为NVIDIA GeForce GTX 1080Ti。开发框架是在python 3.7.4,Tensorflow1.14.0上进行。
输入图像和输出图像尺寸设置为256×256的像素大小,没有使用其他预处理方法处理汉字数据集(例如裁切和翻转),并将图片转化成TFRecord格式进行读取操作。在网络结构中,使用实例归一化。在生成器网络中,残差块数量为8,其中包括4个由自适应归一化层指导的残差块;判别器PatchGAN的判别区域设置为70×70。对于所有实验,正则化强度设置为10,采用Adam[37]算法对训练过程中的梯度下降进行优化,指数衰减率beta1设定为0.5。前100个迭代中,学习率设置为0.000 2,之后线性衰减为0。
3.3 评价指标
使用生成对抗网络所生成的图像,其质量是一个非常主观的概念。不够清晰的图片和线条清晰但“非常奇怪”的图片都应该属于低质量的图片,但是计算机很难识别这样的问题,所以缺乏客观的评估标准。需要一个可计算的定量指标来衡量生成手写汉字方法的性能。
使用互补的评估指标:内容准确性和风格差异性,来衡量和比较本文方法与原始CycleGAN的性能。在CASIA-HWDB数据集上,两种评估都基于预先训练的基于GoogLeNet的手写汉字分类模型网络。
(1)内容准确性。本文使用经过预训练的GoogLeNet模型来评估生成的手写汉字的内容质量。使用CASIAHWDB1.0-1.2手写字符数据库训练的,其中包括HW011。预训练的GoogLeNet达到了汉字分类较高准确性。从理论上来说,如果通过网络生成的汉字足够真实,那么经过预训练的GoogLeNet可以对生成的汉字进行正确的分类。在此任务中,生成的汉字是从源样式中可用的汉字图像生成的,如果生成的汉字可以通过预训练的模型准确分类,则在某种程度上表明该方法在生成汉字的内容上具有较高的准确性。
表1显示了本文方法在以HW011手写汉字和魏碑为基准的GoogLeNetTop-1和Top-5的分类准确性。Top-1正确率指的是与实际结果一致的排名最高的类别的准确率,Top-5正确率指的是包含实际结果的前5个类别的准确率。较高的准确率表明以GoogLeNet分类准确性作为内容上的判断指标是可靠的。但是,分类的准确性仅从内容方面衡量了生成汉字的质量,而忽略了生成汉字的样式是否与原本数据集中的样式相似。因此,GoogLeNet在生成的手写汉字上的识别精度被称为内容准确性。
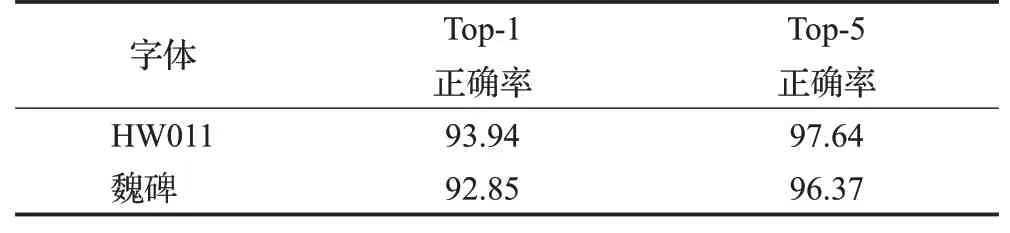
表1 以两种字体为基准的GoogLeNet分类准确性Table 1 GoogLeNet classification accuracy based on two fonts %
(2)样式差异性。为了测量源图像字体和目标图像字体之间样式的差异性,借用了风格损失[38]的方法。对于图像风格损失,一般会将提取到的特征转换为Gram矩阵,用Gram矩阵来表示图像风格。其中卷积层的输出为表示是l层的第i行第j个特征向量化后的内积:


因此,样式差异定义为目标汉字样式和生成汉字样式之间的均方根差。在本文中,使用GoogLeNet中的Inception模块3的输入作为层来计算样式差异。运行了两个基准实验,以大致了解汉字样式差异的范围。
①样式差异的最小值。HW011中的所有汉字均由同一人书写,因此具有相同的书写风格。将其随机且均等分割成两个子集。这两个子集之间样式差异的均方根误差就是样式差异的最小值,样式差异的下限为516.53。
②样式差异的最大值。HW011和魏碑是两种完全不同的字体样式。它们之间的差异是源字体和目标字体之间的样式差异,代表了样式中最可能出现的差异。因此,HW011和魏碑之间的样式丢失的均方根误差为样式差异的最大值。样式差异的上限为3 023.82。
3.4 效果评估
3.4.1兰亭序书法数据集
在此实验中,使用魏碑作为源字体,兰亭序书法作为目标字体,从中选取的汉字图片不是一一匹配的。图5显示了兰亭序书法数据集中前四个汉字的真实图像,对应的魏碑风格以及通过两种不同方法生成的汉字。

图5 汉字“永和九年”Fig.5 Chinese characters“Yong He Jiunian”
可以看出,本文方法和CycleGAN都抓住了王羲之整体的书写风格,并产生了合理的输出。但是,用本文的方法产生的结果要略胜于CycleGAN。通过本文的方法,生成的汉字更加清晰,并且笔画丢失的情况更少。在细节方面,使用本文方法生成的汉字在笔锋上与兰亭序数据集中真实字体的风格更加相似。但是本文的方法和CycleGAN生成的汉字都无法学习到王羲之书法的某些风格。比如:“和”字撇和捺在兰亭序数据集中简化成一个笔画,这个是它们都无法学习到的特征。
图6的这些汉字不在原始的兰亭书法数据集中,但也是带有王羲之风格的中国书法,并且表现出令人满意的质量和风格。

图6 汉字“睦”“唑”Fig.6 Chinese characters“Mu”and“Zuo”
3.4.2 CASIA-HWDB数据集
在此实验中,本文使用魏碑作为源字体,HW011中的手写汉字作为目标字体,从中选取的汉字图片是不匹配的。在实际应用中,本模型基于用户少量的手写汉字样本,生成带有其个人风格的手写汉字字库。因此,此实验的目标是保证有较高内容准确性和样式差异性的基础上,使用尽量小的训练集来训练模型。
为了验证本模型在不同规模数据集上的效果,从HW011汉字数据集中随机挑选了300张、400张和500张分成三组,每组进行十次实验,每组实验随机选取不同的数据集作为训练集。表2展现了选取300张、400张和500张HW011数据集分成三组,每组进行十次实验,每组随机选择不同的数据集作为训练集,使用CycleGAN和本文方法产生的内容准确性和样式差异性。由实验结果可知,当训练集规模较小(300张)时,本文方法与CycleGAN的内容准确性和样式差异性相近,样式差异性的波动较大,结果不稳定。随着训练集规模的增加(400张、500张时),本文方法生成的汉字效果显著提高,明显优于CycleGAN,内容准确率始终在80%以上,生成汉字的样式差异性逐渐稳定。同时,在本文3.3节中提及,样式差异性的取值范围在516.53和3 023.82之间,实验结果表明,本文方法所生成的汉字在样式差异性上也明显优于CycleGAN。
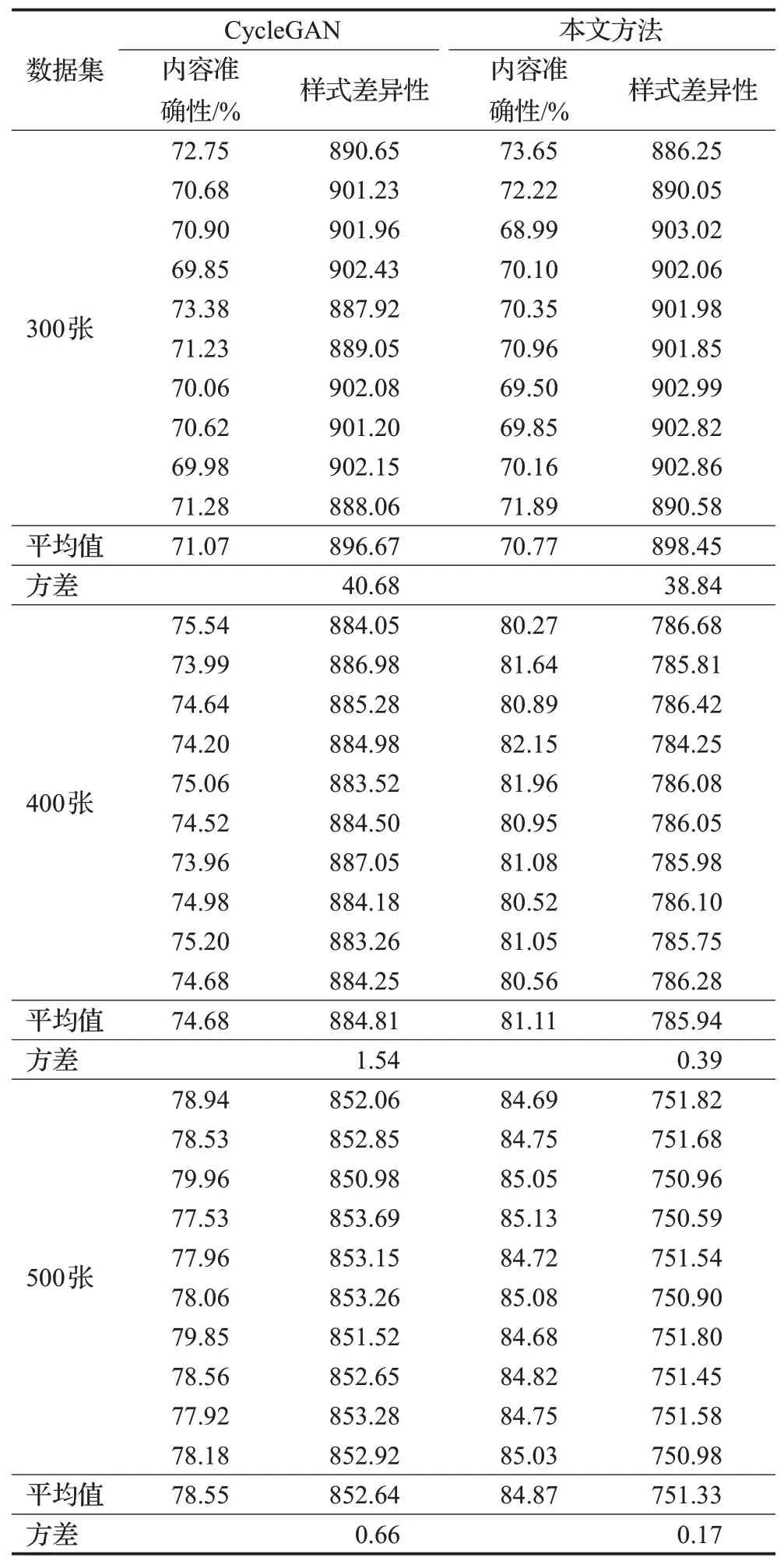
表2 两种方法在三组数量不同数据集上的实验结果Table 2 Experimental results of two methods on three different data sets
综上,在较小规模的训练集下,本文方法也能取得很好的效果,并且随着训练集的增加,内容准确性不断提升,样式差异性不断缩小。图7和图8为结果展示。

图7 汉字“固”“你”Fig.7 Chinese characters“Gu”and“Ni”

图8 汉字词语“和谐”Fig.8 Chinese word”Hexie”
4 结语
本文使用内容和结构都不匹配的汉字数据集,将现有的标准打印字体通过图像翻译原理转换成个性化手写汉字。提出了一种结合注意力机制和自适应标准化层的无监督汉字图像翻译模型来解决这个问题,并且能够减少汉字数据集采集所花费的时间和精力。使用注意力机制提高了生成汉字图像的质量,添加的自适应标准化层不仅加强了特征通道之间的相关性,而且能够加强个性化汉字的风格样式。通过告知判别器先验知识从而加强了它的判别能力。与原始CycleGAN进行了比较,在CASIA-HWDB数据集和兰亭序书法数据集上进行了评估,利用汉字生成性能的评价指标,即内容准确性和风格差异性,定量评估生成手写汉字的质量。实验结果证明了本文方法的有效性。
但本文仍存在较大提升空间,对其局限性及未来工作归纳如下:
(1)本文方法虽然提升了汉字图像翻译的质量,但是依然无法完全避免无关信息的改变。如何在汉字图像翻译过程中只改变目标图像域,将有助于提升图像翻译效果。
(2)本文方法仅适用于单个汉字图像域的翻译任务,在同时建立多个汉字图像域之间映射关系时需要针对每对图像域进行训练,不能完成端对端的图像翻译。改进整体模型结构和损失函数以适应多图像域翻译将是下一步的研究工作。
猜你喜欢
天然气与石油(2022年4期)2022-09-21
故事作文·低年级(2021年12期)2021-12-21
天然气与石油(2021年5期)2021-11-06
天然气与石油(2021年1期)2021-03-08
作文成功之路·小学版(2020年7期)2020-08-24
娃娃乐园·综合智能(2020年2期)2020-03-12
电子制作(2018年18期)2018-11-14
课堂内外(初中版)(2015年9期)2015-09-10
小雪花·成长指南(2014年10期)2014-10-31
党建文汇·上(2014年8期)2014-10-27
