
基于集成学习模型的糖尿病患病风险预测研究
2022-04-24 03:20王琦琪戴家佳崔熊卫
软件导刊 2022年4期
王琦琪,戴家佳,崔熊卫
(1.贵州大学数学与统计学院,贵州贵阳 550025;2.重庆医科大学附属第二医院,重庆 400010)
0 引言
据国际糖尿病联合会2019年报告显示,全球糖尿病患者数约为4.63亿,中国患病人数高达1.16亿,居世界第一。近年来,随着生活水平的提高,我国糖尿病患者数量不断增加,其防治已成为我国重要的公共卫生问题。糖尿病是继心脑血管疾病、恶性肿瘤之后第三大威胁人类健康的慢性病,糖尿病患者可能会出现严重并发症,如脑血管意外、视网膜脱落、肾脏损伤等,不仅给患者的生活带来严重影响,还给社会带来了沉重的经济负担。对于大多数糖尿病患者,如果及早发现并开始治疗,并发症将很容易控制,甚至可以避免发生。因此,进行早期糖尿病风险预测,对于降低糖尿病及其并发症的发病率、节约国家医疗资源具有重要意义。
1 相关研究
机器学习是重要的信息挖掘技术,目前已有很多国内外学者采用机器学习方法预测糖尿病患病风险。例如,Joshi等采用支持向量机(Support Vector Machine,SVM)、logistic回归、神经网络3种机器学习方法预测患者糖尿病患病风险,最后发现SVM的预测效果最好;Singh等运用朴素贝叶斯、随机森林(Random Forest,RF)和基于函数的多层感知器算法进行糖尿病患病风险建模,结果显示RF的预测准确率最高;Gill等将遗传算法和RF用于糖尿病的有效诊断和预测;Bassam等运用SVM预测2型糖尿病的患病风险;陈思含等结合多因素Logistic回归分析和具有集成学习框架的XGBoost算法,构建了2型糖尿病并发症预测模型;郭奕瑞等对社区居民进行流行病学调查,分别应用神经网络和Logistic回归建立2型糖尿病预测模型,应用受试者工作特征曲线评价预测模型的检验效能,结果显示神经网络模型较Logistic回归模型具有更好的预测效能;陈真诚等为实现糖尿病的早期筛查,利用邻近算法和神经网络两种方法进行分类,发现神经网络,能对糖尿病进行更好的分类和识别,起到早期筛查的作用。
通过梳理现有文献发现,较少学者采用集成学习模型对糖尿病进行分类预测。集成学习算法不是一种单独的机器学习算法,而是通过结合多个机器学习器完成学习任务,可以说是集百家之所长,具有较高的准确率。因此,本文以糖尿病患病风险预测作为分析视角,分别采用代表性集成学习算法RF、GBDT(Gradient Boosting Decision Tree)和XGBoost,以及已有文献研究证实分类效果较好的单一分类器模型SVM和BP(Back Propagation)神经网络建立5种分类预测模型,通过多种性能评价指标探讨预测糖尿病患病风险的最佳分类模型。
2 算法原理
2.1 SVM
SVM是一种有监督学习算法,可用于解决数据挖掘或模式识别领域中的数据分类问题。其基本思想是建立一个最优决策超平面,使得该平面两侧距平面最近的两类样本之间的距离最大化,从而使得该模型用于分类问题时能具有良好的泛化能力。SVM适用于样本较小、非线性及高维空间问题,可与其他机器学习算法联合使用。SVM通过引入拉格朗日常数解决凸二次优化问题,表示为:
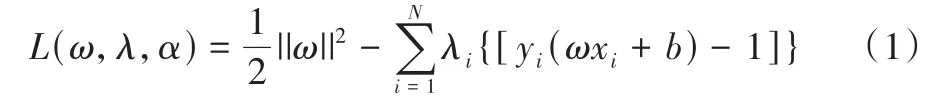
ω
||为正常超平面的范数,b
为常数,λ
为拉格朗日乘数,x
(i
=1,2,…n
)为线性可分的向量,y
为输出类。2.2 BP神经网络
人工神经网络是一种抽象的非线性信息处理系统,模拟大脑神经网络处理、记忆信息的方式。BP神经网络作为最基础的神经网络,由1个输入层、任意个隐含层和1个输出层构成,是一种通过误差反向传播算法训练的前馈性网络。BP神经网络的基本思想是整个学习过程由信号的正向传播和误差的反向传播两部分组成,当输出值与期望值之间的误差达到截止误差后,训练即停止;若输出值和期望值不一致,则进入误差的反向传播阶段。误差反向传播即将误差以某种形式分摊给各层的所有单元,从而获得误差信号作为修正各单元权值的依据。
2.3 RF
RF模型是在CART(Classification and Regression Tree)决策树模型的基础上衍生而来,结合了Bagging集成学习方法和随机子空间理论。作为一种监督学习算法,RF能克服单一分类预测模型的一些弊端,获得更高的分类预测准确率。其是通过集成学习将多棵决策树集成在一起的一种机器学习算法,比单个决策树性能更优。RF在样本和特征选取上具有随机性,这两个随机性的引入使其不容易陷入过拟合,具有很好的抗噪能力。
2.4 GBDT
GBDT是由Freidman提出的改进Boosting算法,其以CART决策树作为基分类器,将一系列CART基分类器串联起来得到集成模型。GBDT的基本思想是借鉴梯度下降法,根据当前模型损失函数的负梯度信息不断训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式整合到现有模型中。GBDT用于二分类的损失函数表示为:

2.5 XGBoost
XGBoost算法是一个优化的分布式梯度增强库,其以CART决策树作为基分类器,采用新增树形成的新函数拟合之前预测的残差,然后累加所有树的预测结果,得到最终预测结果。XGBoost的目标函数为:

n
为训练样本数量,k
为决策树数量,f
为基学习器。损失函数l
用于衡量真实分数与预测分数的差距。正则化项Ω包含两个部分,其中T
表示叶子节点数量,W
表示叶子节点分数;γ
和λ
表示惩罚力度,可控制叶子节点数量并限制节点分数,防止模型过分贴合训练数据而损失预测效果导致过拟合。3 数据来源与处理方法
3.1 资料来源
选取UCI机器学习库中(https://archive.ics.uci.edu)的糖尿病风险预测数据集,共包含520个样本,其中不患病人数200例,患病人数320例。如表1所示,Class用Y
表示,解释变量依次用X
(i
=1,2,…,16)表示。
Table1 Variable assignment表1 变量赋值
3.2 数据处理方法
将520个样本按照7∶3的比例分为训练集和测试集两部分。将患病赋值为1,未患病赋值为0,组间比较采用卡方检验。选取对糖尿病患病有显著影响的变量作为自变量输入建立预测模型,采用有结果标签的训练集对模型进行训练,然后对其各项参数和评价指标进行优化,利用网格搜索确定各模型最优参数,再采用测试数据对预测模型进行分类准确性的评价比较。采用Python对其进行数据分析。
4 实验结果与分析
4.1 数据资料分析
对16个变量进行分组描述,并进行差异性检验。如表2所示,Itching(X
),delayed healing(X
)两个变量对是否患糖尿病无显著性影响,因此在构建分类模型时,采用余下14个变量作为自变量输入。
Table2 Single factor analysis of diabetespre valence表2 糖尿病患病情况单因素分析
4.2 模型评价标准
在二分类预测模型评估指标中,混淆矩阵可用于判断分类器分类效能优劣,具体如表3所示。采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数和AUC 5个指标评价各模型性能。

Table3 Confusion matrix表3 混淆矩阵
(1)准确率(Accuracy,ACC)。该指标为预测结果和真实结果同为正例和同为反例占所有样本的比例,反映分类器对整个样本的判定能力,表示为:

(2)精确率(Precision)。该指标为预测正确的正例数占预测为正例总量的比例,表示为:

(3)召回率(Recall)。该指标为预测正确的正例数占真正正例数的比例,表示为:

(4)F1分数。该指标表示为精确率与召回率的调和平均值,表示为:

(5)AUC。该指标表示ROC曲线下的面积,取值在0.5~1之间;ROC曲线横轴表示负例分错的概率,纵轴表示正例分对的概率。AUC可以直观地评价分类器性能优劣,其值越大越好。
4.3 模型预测性能评价
基于SVM、BP神经网络、RF、GBDT、XGBoost算法建立预测模型,5种分类器的预测结果见表4,性能比较结果见表5。可以看出,XGBoost的区分度最好,AUC达到99.41%。从准确率、精确率、召回率和F1结果可以看出,XGBoost的预测准确率最高,达到97.44%,其精确率和召回率在5个模型中最佳。单个分类器SVM的预测准确率最差。在集成学习模型中,XGBoost的预测结果略优于GBDT,明显优于RF。总体而言,集成学习模型的预测性能比单个分类器有所提升,能够更为精确地进行糖尿病风险预测。
预测性能最好的XGBoost算法给出的变量重要性如图1所示。影响权重排名前十的因素依次为烦渴、多尿症、脱发、感到无力疲惫、体重突然减轻等。

Table 4 Prediction results of the five classifier test sets表4 5个分类器测试集预测结果

Table 5 Comparison of prediction performance of five classifiers表5 5个分类器预测性能比较
5 结语

Fig.1 Variable importance ranking图1 变量重要性排序
本研究使用UCI数据库,基于集成学习算法RF、GBDT和XGBoost建立糖尿病患病风险预测模型。就预测准确率而言,XGBoost(Accuracy=97.44%)略优于GBDT(Accuracy=96.79%),明显优于RF(Accuracy=94.23%)。与单一分类器SVM(Accuracy=93.59%)和BP神经网络(Accuracy=94.87%)相比,XGBoost的预测效果最好,而RF和BP神经网络的预测准确率仅相差0.64%。针对其他评价指标,XGBoost算法的精确率、召回率、F1值、AUC值均最高,分别达到99.02%、97.12%、98.06%、99.41%。集成学习算法是目前对结构化数据拟合效果最好的算法之一,本文研究结果也证实了这一点。
研究表明,糖尿病患者血糖升高导致血管内渗透压升高,使大脑产生口干欲饮的感觉。患者大量饮水后导致全身血流量增加,肾脏灌注压升高,从而导致尿量增加。此外,糖尿病患者存在胰岛素分泌不足或胰岛素抵抗等现象,机体细胞不能正常利用血糖供能,使患者产生饥饿感,促使其不断进食保证能量供应,且机体会通过分解脂肪、蛋白质等供能,因此患者体重减轻。本文建立的XGBoost模型分析影响因素权重排名前十的因素为烦渴、多尿症、脱发、无力、体重减轻等,与医学研究结论相符。
综上所述,本文通过集成学习算法构建的早期糖尿病患病风险预测模型可较为精确地分类出潜在患病人群,但仍有优化空间。未来可采用更大规模的数据集以及更准确的特征分类算法进行糖尿病患病风险预测,以帮助临床医生识别早期糖尿病患者,减少糖尿病并发症发生,提高患者生活质量,减轻社会负担。
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
上海工运(2020年8期)2020-12-14
科学(2020年3期)2020-11-26
中国交通信息化(2018年5期)2018-08-21
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
为了孩子(孕0~3岁)(2001年3期)2001-06-13
