
基于多模型融合的警情要素提取
2022-04-24 03:21龚艳汪玉梁昌明黄林钰乐汉徐圣婴王本强
软件导刊 2022年4期
龚艳,汪玉,梁昌明,黄林钰,乐汉,徐圣婴,王本强
(1.上海市公安局科技处,上海 200042;2.上海德拓信息技术股份有限公司,上海 200030)
0 引言
命名实体识别(Named Entity Recognition,NER)又称为要素提取,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,简而言之就是识别自然文本中实体指称的边界和类别,在自动文本摘要、机器翻译、信息检索、问题回答等不同自然语言的应用中具有至关重要的作用。
目前,公安系统已经初步建立了能覆盖业务场景和满足使用需求的应用系统体系,并在实际使用过程中积累了大量案件数据。这些数据和现有公安数据、社会数据在公安日常工作中起着至关重要的作用,如在警情统计分析中需进行同时间、同地点等更细腻的要素统计分析;分析同一案件人员的串联关系,用于警情串并案;对于重点人员、重点车辆等要素进行预警分析等。因此,随着各类警务活动的深入开展,建立一个高精度、高覆盖率的警情要素提取模型迫在眉睫。
1 相关研究
近年来,神经网络与传统机器学习相结合的方法在端到端NER系统中的应用越来越广泛。例如,文献[5]提出基于词向量+条件随机场(Conditional Random Fields,CRF)的NER方法;文献[6-7]提出基于双向长短时记忆神经网络(Bi-directional Long Short-Term Memory,BiLSTM)+卷积神经网络(Convolutional Neural Networks,CNN)的实体提取模型;文献[8-9]提出基于BiLSTM+CRF的NER方法;文献[10]提出基于BiLSTM+CNN+CRF的序列标注方法。然而,但上述方法均存在未引入预训练知识且抽取内容单一等问题。
为此,本文提出多模型融合警情要素提取方法,主要由两部分组成。对于人名、地名、机构名等无明显规律的要 素,采 用BERT(Bidirectional Encoder Representations from Transformers)+BiLSTM+CRF方法。该法相较传统深度学习方法提取的上下文语义信息更加丰富准确,同时很好地解决了一词多义的问题;对于时间、车牌号等具有一定规律的数据,采用模式识别方法搜集要素规律,制定相关规则,抽取出符合该规则的要素类型。最后结合两种方法,抽取出人名、地点、机构名、丢失物品、金额、身份证号、手机号、银行卡号、时间、IMEI、MAC、车牌号、性别、文化程度、血型、民族16种要素,以满足实际业务需求。
2 算法简介
2.1 BERT+BiLSTM+CRF
采用BERT+BiLSTM+CRF模型对人名、地点、机构名、丢失物品、金额5类要素进行抽取,该模型由BERT字向量表征层、BiLSTM双向编码层、CRF解码层组成。首先采用BERT对文本中的每个字进行向量表征,利用上下文信息使每个字不仅包含其本身的语义信息,还能包含上下文的语义信息;然后通过BiLSTM进行更深层次的编码;最后利用CRF进行解码及序列标注,从而得到每个字所对应的类别。
BERT+BiLSTM+CRF模型架构如图1所示,其中Text
为输入文本,每个字映射为Tok
1、Tok
2…TokN
对应数字。利用BERT层将数字映射为对应的字向量E
、E
…E
,融合句子上下文信息,将字向量表征为T
、T
…T
;然后利用BiLSTM层进一步学习句子的序列信息,得到P
、P
…P
;最后利用CRF进行解码,得到每个字所对应的类别Tag
、Tag
…Tag
。2.1.1 BERT预训练语言模型
近年来,预训练语言模型逐渐成为自然语言处理领域的一大热点,被广泛应用于自然语言推理、命名实体识别、知识问答等领域。传统语言模型仅从统计的角度考虑,没有考虑上下文信息,难以解决一词多义问题。随着神经网络的发展,近年来出现了ELMO(Embedding from Language Models)、GPT(Improving Language Understanding by Generative Pre-Training)等优秀的语言模型,均取得了不错效果。Devlin等提出的BERT预训练语言模型更是一举拿下自然语言处理领域的14个冠军,成为近年来领先的预训练语言模型。

Fig.1 Structure of BERT+BiLSTM+CRF model图1 BERT+BiLSTM+CRF模型架构
采用BERT模型作为字向量表征层,结构如图2所示。其中,P
、P
……P
为位置编码,用于存储每个字对应的位置信息;E
为句子编码,用于区分上下句;t
、t
……t
为字向量,用于储存字信息;加入特殊符号[CLS],用于后续分类任务。将3个部分的信息相加融合形成E
、E
……E
,作为输入向量,再经过BERT模型将字向量表征为T
、T
……T
。
Fig.2 Structure of BERT model图2 BERT模型结构
BERT的特征提取采用Transformer(Attention is All You Need)的编码部分,该部分由多个编码层(Encoder)堆叠而成。每个编码层由自注意力机制(Self-attention)和前馈神经网络(Feed-forward)两部分构成,结构如图3所示。
编码层中的主要部分为Self-attention层,具体结构如图4所示。每个字都有Q(Query)、K(Key)、V(Value)3个向量,分别由其对应的字向量与w
、w
、w
3个矩阵相乘得到,表示为:
Fig.3 Structure of Encoder in the Transformer图3 Transformer中的Encoder结构

x
为每个字经过映射对应的字向量,维度为512×768;w
、w
、w
为初始化后的学习矩阵,维度为768×64。
Fig.4 Structure of self-attention图4 Self-attention结构
在自编码中,单个词的Attention值计算结果如图4中公式所示。采用字a对应的K
向量与字a所对应的Q
向量点乘,产生对应的score值,再利用Softmax对score进行归一化,表示为: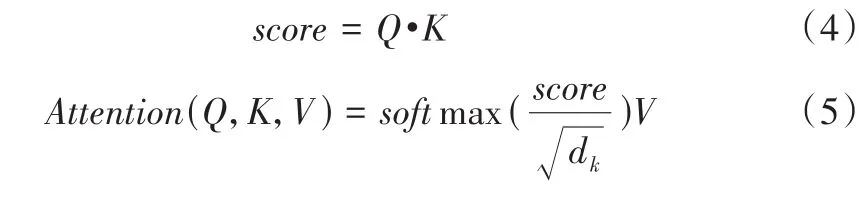
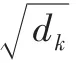
此外,为提取更深层的语义信息,Transformer中使用了多头注意力机制(Multi-Headed-Attention),即重复式(4)、式(5)计算,再将结果进行拼接,表示为:
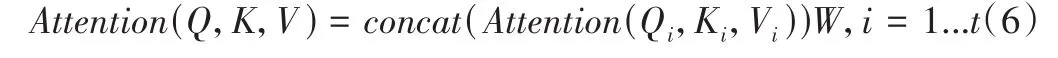
t
为Multi-Headed个数。为防止模型退化,Transformer中借鉴了残差结构,将上一层参数与这一层参数相加融合。同时,为加速模型的学习速度,引入批归一化(Normalize)方法,将参数缩放至类正态分布。
2.1.2 BiLSTM层
采用长短时记忆神经网络(Long Short-Term Memory,LSTM)层进行更深层次的编码。LSTM是循环神经网络的一种,由于其能够储存序列信息,在序列标注任务中应用广泛。LSTM的结构如图5所示。

Fig.5 Structure of LSTM algorithm图5 LSTM结构
LSTM主要由遗忘门、学习门、记忆门和使用门组成,同时利用长时记忆C和短时记忆h作为记忆单元。对于第t
个输入来说,h
、C
的更新方式为:

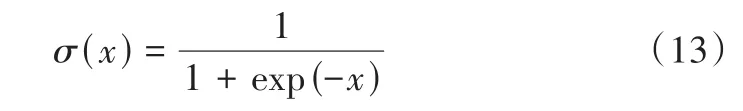
τ
为tanh激活函数,用于拟合模型非线性能力,表示为:
为缓解LSTM产生的长时依赖问题,本文模型采用双向LSTM模型BiLSTM,即正向逆向各进行一次LSTM,再将两者信息进行拼接融合。
2.1.3 CRF层
CRF是经典无向图之一,其核心思想为给定一组输入序列条件下另一组输出序列的条件概率分布模型,最常见的形式为线性链(Linear Chain),结构如图6所示。该模型假设马尔可夫随机场中只有X和Y两个变量,X一般是给定的,而Y是X给定条件下模型的输出。
在线性CRF中,特征函数分为两类:第一类是定义在Y节点上的节点特征函数,该函数只与当前节点有关,表示为:

第二类是定义在Y上下文的局部特征函数,该函数只与当前节点的上一个节点有关,表示为:

Fig.6 Structureof CRF图6 CRF结构

无论是节点特征函数还是局部特征函数,它们的取值只能是0或1,分别表示满足特征条件或不满足特征条件。此外,可以为每个特征函数赋予一个权值,用于表达对该特征函数的信任度,从而得到线性CRF的参数化形式:

以上公式中涉及的参数均采用梯度下降法求解。为减少计算量,采用维特比算法求得局部最优解。
2.2 模式识别
采用模式识别方式抽取身份证号、手机号、银行卡号、时间、IMEI、MAC、车牌号、性别、文化程度、血型、民族11种要素。模式识别的原理是通过搜集要素规律制定相关规则,抽取出符合该规则的要素类型。例如,身份证号的固定长度为18位,由地址码、出生日期码、顺序码和校验码组成,其中前6位为地址码,第7-14位为出生日期码,第15-17位为顺序码,第18位为校验码。再如关于时间的规律比较杂乱且多,分为5个部分进行分析:①标准时间,如2020-11-11 23:59:59、2020/11/11;②数字中文混合,如2020年十一月11日;③年、月、周、天,如上周日、周日下午、明天、上月末、去年十月一号;④节日,如端午节、圣诞节、春节;⑤时间段,如近3天、10月11日到11月11日。
3 实验方法与结果分析
3.1 模型参数设置
遵循BERT+BiLSTM+CRF模型训练规则,数据采用BIOES编码方式,其中B代表每个类别的起始字,I代表中间字,E代表结束字,S代表单个字,O代表无关字。
BERT层采用Google中文预训练语言模型参数作为初始参数,并在此基础上进行微调(Fine-tuning)。模型包含12个Encoder层,每个隐藏层有768个参数,12个Multi-Headed;BiLSTM层中,神经元个数为256,向上堆叠2层;CRF层中输出21个类别。
选取Adam优化器,训练30批次,每个批次大小为256,初始学习率为1×10,并在每个Epoch结束后衰减5%。同时,为了防止过拟合,在训练过程中随机丢弃10%的参数。
3.2 评估标准
模型采取精确率(Precision)、召回率(Recall)、F1值作为评估标准。
精确率用于评估抽取出来要素的准确性,表示为:

召回率用于评估要素抽取的全面性,表示为:

F1用于评估模型整体效果,表示为:
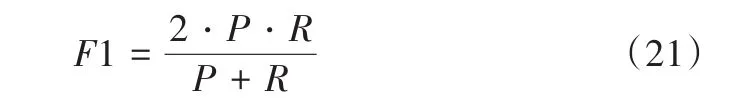
3.3 数据集
本文使用的数据集由8万篇警情构成,警情字数范围为50~100个。为保证测试公平性,采用十折交叉法验证。识别实体包括人名、地名、机构名、丢失物品、金额、身份证号、手机号、银行卡号、时间、IMEI、MAC、车牌号、性别、文化程度、血型、民族。
3.4 结果分析
对人名、地名、机构名、丢失物品、金额进行命名实体识别,比较Word2vec+CRF、BiLSTM、BiLSTM+CRF、BiLSTM+CNN+CRF、BERT+BiLSTM+CRF模型的性能,结果见表1。可以看出,BERT+BiLSTM+CRF在精确率、召回率、F1值上均比其他模型提升3%以上。
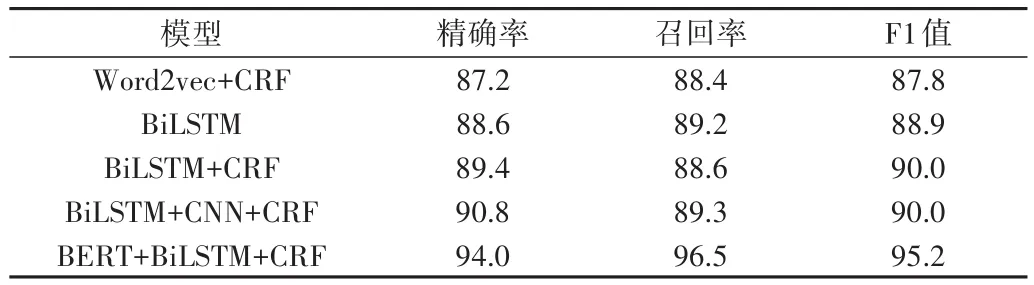
Table1 Results of named entity recognition of each model表1 命名实体识别效果比较 (%)
比较各批次下BERT+BiLSTM+CRF模型在测试集中的性能(见表2),1个批次时,测试集的F1值即达到94.0%,在20个批次左右F1值达到95.2%,后续训练无明显提升。
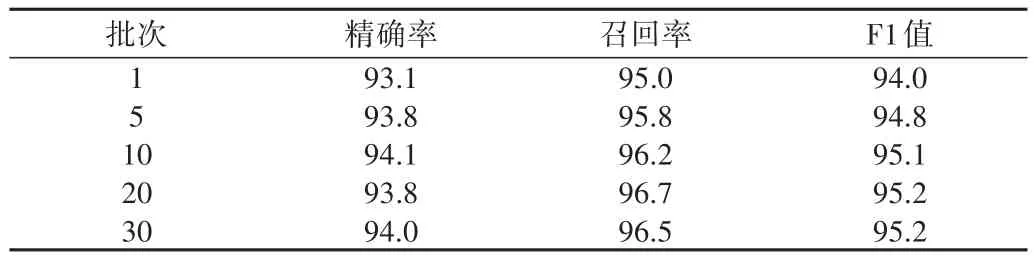
Table2 Effect of BERT+BiLSTM+CRF model in different batches of test dataset表2 BERT+BiLSTM+CRF模型在不同批次下的测试集效果(%)
30个训练批次完成后,BERT+BiLSTM+CRF模型对各个实体的抽取效果见表3。对于人名、地名、机构名、金额的抽取,F1值均能达到95%以上;丢失物品的不规律性过强,很多描述模棱两可,对模型理解造成较大干扰,导致其F1值仅在78%左右。
比较模式识别模型对不同实体的抽取效果(见表4),发现除时间外,其余要素召回率均超过95%,F1值均超过93%。

Table3 Effect of BERT+BiLSTM+CRF model in different entities表3 BERT+BiLSTM+CRF模型对不同实体的抽取效果 (%)
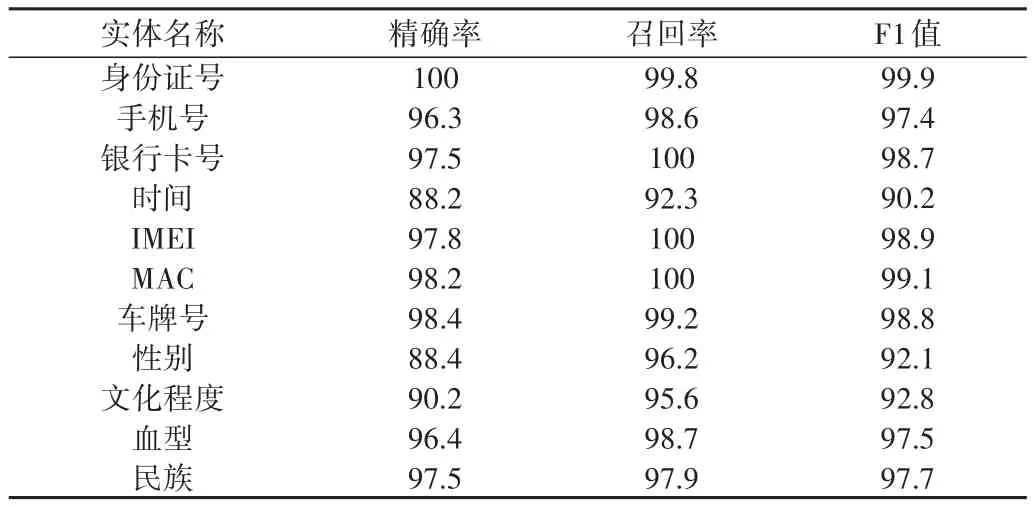
Table4 Effect of pattern recognition model in different entities表4 模式识别模型对不同实体的抽取效果 (%)
比较模式识别和表1中5种深度学习方法对身份证号、手机号、银行卡号、时间、IMEI、MAC、车牌号、性别、文化程度、血型、民族要素的抽取效果(见表5),可以看出,模式识别的评价指标相较其他方法均提升超过1%。

Table5 Results comparison of named entity recognition based on pattern recognition and deep learning methods表5 模式识别与深度学习方法效果比较 (%)
4 结语
基于多模型融合的要素提取方法旨在解决警情中日益增长的不同种类要素提取需求,为此,本文建立了抽取词义关键信息的BERT+BiLSTM+CRF模型,以及抽取符合一定规则要素的模式识别模型。实验结果表明,该模型具有较高的准确率,且能够满足不同种类的要素提取需求。后续计划将BERT+BiLSTM+CRF模型与模式识别模型融合起来,形成端到端的一体化模型,并继续探索新类型的警情要素提取方法。
猜你喜欢
数学年刊A辑(中文版)(2020年1期)2020-05-19
黑龙江科学(2020年5期)2020-04-13
邢台学院学报(2018年4期)2018-12-14
数码设计(2017年14期)2017-11-15
派出所工作(2017年9期)2017-05-30
派出所工作(2017年9期)2017-05-30
派出所工作(2017年9期)2017-05-30
电子测试(2017年23期)2017-04-04
智能系统学报(2017年5期)2017-01-22
智能系统学报(2015年3期)2015-01-29
