
结合代价敏感与集成算法的个人信用评估模型
2022-04-24 03:21张怡罗康洋谢晓金
软件导刊 2022年4期
张怡,罗康洋,谢晓金
(1.上海工程技术大学数理与统计学院,上海 201620;2.华东师范大学数据科学与工程学院,上海 200062)
0 引言
随着贷款消费的不断发展,个人信用评估已成为银行等金融机构密切关注的热点。截至2019年9月底,国民贷款消费达到13.34万亿元,同比增长17.4%。2019年底突然爆发的新冠肺炎疫情给全球经济增长带来严重冲击,社会秩序面临巨大挑战。面对较多的不确定性,迫切需要加强金融风险监测评估,关注金融风险边际变化,积极稳妥防范化解金融风险。目前中小微企业遭受不同程度的冲击,不少雇员面临降薪甚至失业的风险,贷款偿还能力大大削弱,金融风险压力凸现。因此,对个人信用风险进行评估以便及时采取有效的规避措施,降低信用风险带来的金融危机隐患显得尤为重要。
个人信用评估是通过挖掘个人信用的指标数据与失信状态之间的关联关系构建模型,从而评估个人的信用风险。文献[2-6]介绍了目前国内外主要的个人信用评估模型,包括专家评分模型、统计评分模型和机器学习模型;严鸿和等从知识工程的基本思想出发,分析了专家评分过程中的非线性规划模型,用以确定权系数;文献[4]针对数据集特征变量进行主成分分析,使降维后的变量无相关性,再对其进行稀疏贝叶斯分类,得出PCA-SBL具有更高的分类性能的结论;Ma等针对个人信用评估问题,在随机森林、LightGBM和支持向量机3个分类器上进行加权投票组合,获得了良好的分类精度;Shen等提出一种集成优化模型用于个人信用风险评估。针对个人信用数据类不平衡问题,基于代价敏感的改进算法应运而生。文献[7]介绍了基于集成随机森林(RF)、GBDT算法和XGBoost三种算法建立的个人信用评估模型,并依据相关多元评价指标对个人信用评估进行对比研究;文献[8]介绍了基于代价敏感的改进算法。
以上方法都未研究离散型和连续型并存使算法运行性能降低的问题,以及不平衡数据导致模型的整体预测性能不高问题。为此,本文提出一种结合代价敏感和集成算法的分类模型,改进了大样本不平衡数据的分类性能,有效解决了离散型和连续型数据并存的问题,提高了个人信用评估效果。
1 相关理论
1.1 集成型特征选择算法
特征选择指从全部特征出发,选择符合一定评价条件的最佳特征子集,从而降低特征维度,减少模型拟合训练的复杂性。本文利用特征分箱将连续型数据离散化,借助去不平衡思想设计集成型特征选择算法,将每个特征的信息价值(Information Value,IV)、互信息、信息增益和基尼指数累加后进行排序,筛选出最优子集,从而对类不平衡和属性杂糅的个人信用数据进行有效的特征选择。
1.1.1 基于IV的特征选择
在监督学习中WOE(Weight of evidence,WOE)是自变量的一种编码形式。假设p
(p
)是第i
箱中少(多)数类样本占所有少(多)数类样本的比例,则第i
箱的WOE值为:
B
和G
分别为第i
箱中累积失信用户和累积信用良好用户的数量,B
和G
分别为所有失信用户和所有信用良好用户的数量。IV指信息数据的价值,即:

IV常用于对不同特征的预测能力进行评估,IV越大,则该特征的预测准确度越高。但当IV大于0.5时,有过拟合的风险。
基于IV的特征选择步骤为:1使用Best-KS分箱将连续型数据离散化;2对离散化后的数据进行WOE编码;3结合每个分箱及其对应的WOE计算IV,并将其作为特征选择的指标之一。文献[12]介绍了针对连续型特征的分箱操作,包括等频、等距和Best-KS最优分箱。等频和等距分箱在不平衡数据中存在易偏向多数类的局限,因此本文采用Best-KS最优分箱算法。
1.1.2 基于互信息的特征选择
信息熵是消除不确定性所需信息量的度量,在图像处理、人工智能、数据挖掘等领域应用广泛。对于任意的特征变量X
,信息熵为:
p
=P
(X
=x
),i
=1,2,...,N
,下同。互信息本质是两个随机变量统计相关性的测度,通常用于特征和类别之间的测度。对于任意的特征变量X
和类别Y
,互信息为:
p
=P
(Y
=y
),p
=P
(X
=x
,Y
=y
),i
=1,2,...,N
,j
=1,2,...,M
。I
(X
;Y
)越大,特征X
的分类能力越强,反之,其分类能力越弱。在不平衡数据问题中,基于互信息的特征选择容易倾向于多数类。1.1.3 基于信息增益率的特征选择
信息增益率是互信息与特征信息熵之比。在分类判别中,其信息增益率为:

I
(X
,Y
)越大,其分类能力越强,反之,则分类能力越弱。信息增益率可以克服互信息偏向取值较多一方的弊端,但是其不足之处在于可能存在偏向取值较少一方的隐患。1.1.4 基于基尼指数的特征选择
基尼指数是随机检测样本被错分的最大概率,旨在刻画特征的不纯度,其定义如下:

Gini
(X
)越小,则特征的不纯度越低,特征越好。基尼指数在一定程度上可以规避互信息和信息增益率的两种偏向误差,从而最小化错误率。1.2 基于代价敏感的异质集成分类模型
传统的分类模型在分布均衡的数据集上呈现出较好的分类性能,但在不平衡数据集中,由于多数类样本远大于少数类样本,故容易倾向于多数类而忽略少数类的贡献。在不平衡数据问题中,人们更多地关注少数类的影响。因此,从算法层面建立少数类和多数类之间的错分矩阵,构建基于代价敏感的分类模型具有实际意义。
1.2.1 代价敏感
代价敏感指在二分类问题上将一类样本误分为另一类样本所产生的损失,可有效规避重采样技术中可能造成多数类中重要信息丢失或少数类过拟合现象的缺陷。假设n
和n
分别表示少数类样本和多数类样本数量,则少数类和多数类的错分代价分别为: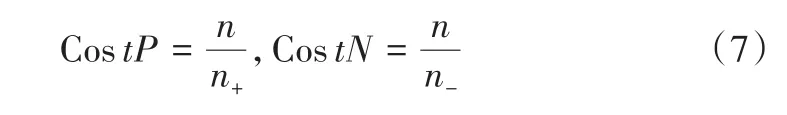
tP
远大于CostN
。1.2.2 异质集成分类模型
(1)Bagging集成算法。根据算法属性是否一致,集成模型划分为同质集成模型和异质集成模型。将基学习器之间依赖关系分为强依赖关系和弱依赖关系。强依赖关系的代表算法是Boosting系列算法,而弱依赖关系的代表算法是Bagging、随机森林等算法。对于噪声较大的数据集,随机森林容易陷入过拟合。本文基于Bagging思想构建集成模型,其算法流程如图1所示。
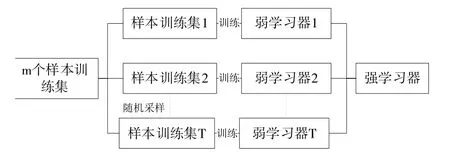
Fig.1 Bagging algorithm flow图1 Bagging算法流程
(2)基于L1和弹性网逻辑回归的基模型。通常借助正则化思想来降低二元逻辑回归模型的过拟合风险,即在基于极大似然估计得到的损失函数中加入正则项。常用的正则化包括L1正则化、L2正则化和弹性网正则化,对应的损失函数分别为:
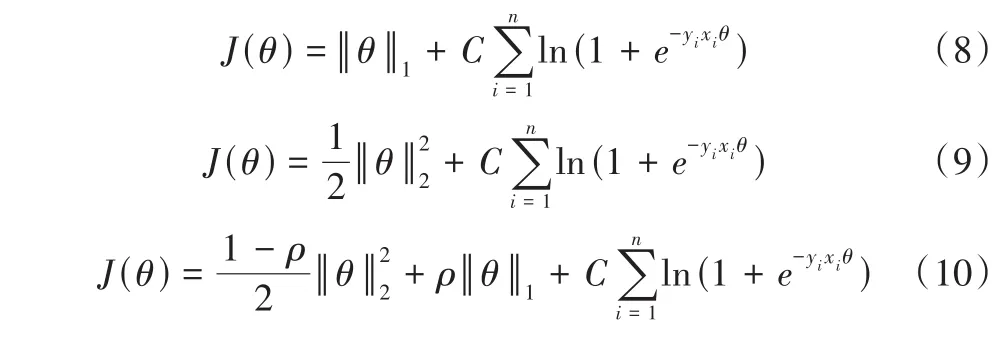
C
为惩罚项系数,ρ
为常数系数,θ
为目标变量y
和输入特征x
的关系矩阵。由式(8)—式(10)可知,L1—逻辑回归和弹性网-逻辑回归相比L2—逻辑回归,既可降低传统逻辑回归模型的过拟合风险,又能对特征全集进行筛选以简化模型。综上,本文将逻辑回归模型(包含文献介绍了:L1—逻辑回归和弹性网—逻辑回归)、贝叶斯模型、决策树模型和神经网络模型作为基模型构建异质集成模型,有助于规避单一基模型分类性能的偶然性,提高模型的泛化能力。
1.3 动态加权投票策略
集成模型的投票策略包括相对多数投票法、绝对多数投票法和加权投票法,本文对加权投票法进行改进以实现动态选取满足精度条件的弱学习器。主要思想为:在正式投票之前,自动过滤预测精度低于随机猜想的弱学习器,并将剩余的弱学习器利用式(11)进行加权投票,以确定最终的分类结果:



1.4 模型建立
本文通过集成IV、互信息、信息增益率和基尼指数的特征选择算法生成最优特征子集,并以L1—逻辑回归、弹性网—逻辑回归、贝叶斯、决策树和神经网络作为基模型构建个人信用评估分类模型,如图2所示。

Fig.2 Personal credit assessment classification model combining cost sensitive and integrated algorithm图2 结合代价敏感和集成算法的个人信用评估分类模型
2 实证分析
2.1 数据描述与预处理
本文数据来自Kaggle官网的Give Me Some Credit数据集,主要描述个人消费类信用卡贷款数据。由表1可知,该数据集有离散型和连续型数据并存特点。其中,失信客户(少数类)和信用良好客户(多数类)分别为10 026个和139 975个,属于不平衡数据集。
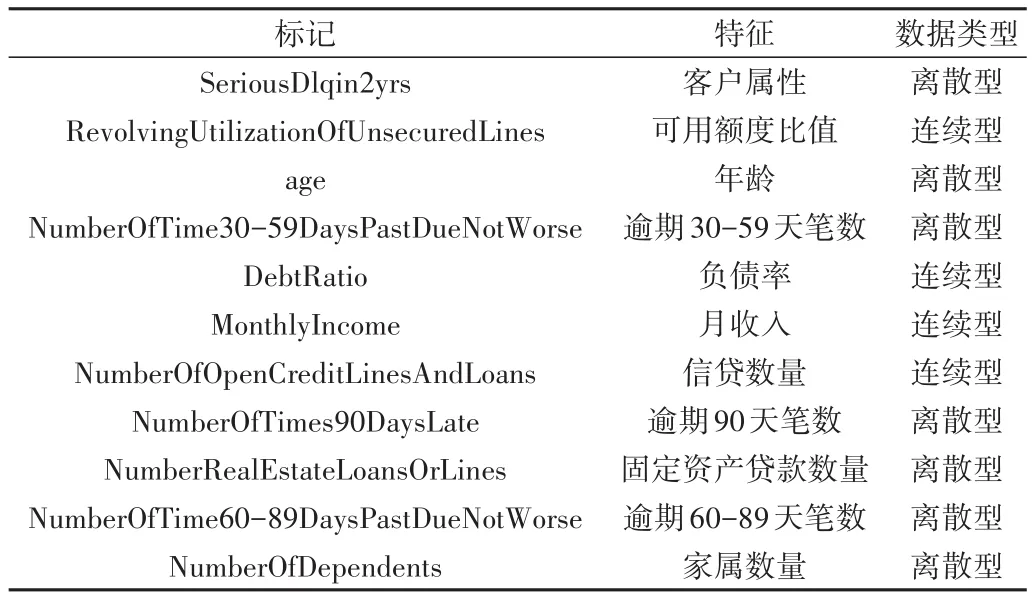
Table 1 Feature attribute description表1 特征属性描述
在预处理数据时,首先计算各自变量的缺失比,小于5%者删除对应样本,大于5%者使用均值插补法补全,得到少数类和多数类样本分别为8 357个和111 912个;其次,为了消除不同量纲对特征的影响,采用极大极小归一化法对数据进行标准化处理;最后,将数据集按8:2划分为训练集和测试集。
2.2 实验设置
采用原始特征集、基于mRMR特征选择算法以及集成型特征选择方法构建个人信用评估分类模型,对比其使用性能来验证本文集成模型的有效性,具体通过python代码编程实现。
2.2.1 异质集成分类模型
mRMR是常见的特征选择算法之一,它同时考虑了特征间的冗余性以及特征与目标变量的相关性,即选择与目标类别相关性最大、特征之间冗余性最小的特征子集。
假设特征集S
中的第i
个特征用f
表示,则S
与类别c
之间最大相关最小冗余的度量方法如下: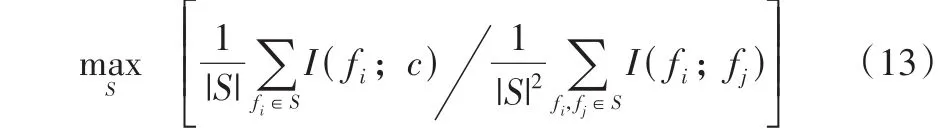
I
(f
,c
)和I
(f
,f
)分别表示特征f
与类别c
和特征f
之间的相关性度量。2.2.2 参数设置
为克服误分类造成的代价敏感问题,多次调参后引入类权重参数class_weight。若迭代次数太少会导致模型不收敛,故设置max_iter=10 000。更多参数设置见表2。

Table 2 Integrated classification model parameter settings表2 集成分类模型参数设置
2.2.3 性能评价指标
在个人信用评估研究中,金融机构更加关注的是少数类样本的预测准确度。在不平衡数据问题中,对少数类和多数类的整体分类精度是衡量模型优劣的重要标志。下面基于混淆矩阵构建评价模型性能指标,如表3所示。

Table 3 Confusion matrix表3 混淆矩阵
其中,TP表示少数类样本预测正确的数量,FN表示少数类样本预测错误的数量,FP表示多数类样本预测错误的数量,TN表示多数类样本预测正确的数量。少数类样本召回率rr
、多数类样本召回率rr
、少数类样本查准率pr
、综合分类预测能力G-means和少数类分类精确度Fvalue的定义分别表示如下:
考虑到少数类和多数类样本的总体预测性能,Gmeans值越大说明模型综合分类的预测性越强,可整体反应模型对不平衡数据的分类性能。F-value考虑了少数类样本的召回率和查准率,能全面反映少数类样本的分类精度,其值越大表明模型对于少数类样本的识别能力越强。
2.3 个人信用数据集实验结果与分析
在原始特征集中基于mRMR特征选择算法和基于集成型特征选择算法筛选出的特征子集见表4。从表4可以看出,无论从特征之间相关性、冗余性还是重要性角度,表4中的7个特征都与个人信用评估密切相关。

Table4 mRMR feature subset and integrated feature subset表4 mRMR特征子集与集成型特征子集

续表
分别将两组特征子集的对应数据作为集成模型的输入,预测结果如表5所示。

Table 5 Integrated model and prediction results based on mRMR model and existing literatures表5 集成型模型与基于mRMR模型和已有文献预测结果 (%)
由表5可知,本文模型和基于mRMR特征选择构建的模型评价指标均优于基于原始特征全集模型评价指标。事实上,相比基于原始特征全集构建的模型,本文模型的G-means和F-value分别提升8%和18%,而基于mRMR特征选择算法构建模型的性能均提升1%,可见本文模型的分类效果较mRMR特征选择算法模型有大幅提高。此外,与文献[23]的实证结果相比,rr
降低了11.94%,rr
增加了15.43%,G-Means、F-value和AUC的性能分别提升10.76%、21.07%和0.64%。rr
的增加是以牺牲多数类样本的正确预测为代价,这表明代价敏感算法和集成特征选择算法的结合有效降低了多数类的影响,增强了少数类的重要性,从而提升了不平衡数据整体的分类效果,但AUC指标提升较小。3 结语
本文提出一种结合代价敏感和集成算法的异质集成个人信用评估分类模型。首先借助Best-KS分箱将连续型数据离散化;然后利用IV、互信息、信息增益率和基尼指数集成特征选择算法;接着基于代价敏感构建L1逻辑回归、弹性网逻辑回归、贝叶斯、决策树和神经网络基模型;最后通过G-means赋权,实现动态加权投票策略。实证结果表明,本文模型的预测性能优于基于原始特征集以及利用mRMR特征选择后构建的个人信用评估分类模型,具有一定的鲁棒性。
利用本文模型将二分类问题推广至多分类问题方案以进一步提高模型分类性能是未来的研究方向。
猜你喜欢
法大研究生(2020年2期)2020-01-19
海峡姐妹(2017年12期)2018-01-31
当代贵州(2017年10期)2017-05-26
作文与考试·初中版(2017年12期)2017-04-19
电子制作(2017年23期)2017-02-02
汽车与安全(2016年5期)2016-12-01
西北工业大学学报(2015年4期)2016-01-19
中学生(2015年12期)2015-03-01
振动工程学报(2014年4期)2014-03-01
计算机工程(2014年6期)2014-02-28
