
基于强化学习的装甲救护车火线伤员收拢前接策略*
2022-04-27 09:04王建华吴杨霄李新伟
火力与指挥控制 2022年3期
王建华,吴杨霄,李新伟,齐 蕊,崔 澂
(陆军军医大学士官学校,石家庄 050081)
0 引言
随着新编制体制落地,新型合成旅作战指挥模式逐渐成形,与之相适应的合成旅卫勤保障力量亦需不断完善和加强。其中,合成营进攻战斗伤员收拢前接是保障时效救治原则的关键环节,其效率高低直接影响战现场急救的时效性。现阶段,我军依托卫生排及装甲救护车完成由火线至营救护站的伤员收拢前接任务,但伤员收拢前接策略大多凭借经验进行部署,在科学性、实时性和效能上还有待进一步论证和完善,因此,利用先进技术手段和数学方法研究智能化的装甲救护车伤员收拢前接策略模式,对于提升战术区卫勤保障能力具有重要意义。本文在建立伤员产生模型的基础上,综合考虑战场装甲救护车数量、营救护站到火线伤员集伤点距离、不同伤势伤员人数、装甲救护车搭载伤员数量、作战时间、阵地数量等复杂环境条件,建立基于深度强化学习的装甲救护车火线伤员收拢前接策略模型,并进行优化求解计算。通过与传统装甲救护车火线伤员收拢前接方法相比,该方法可以推演出更加优化的火线伤员收拢前接策略,能在一定程度上解决救治时间成本,为抢救伤员争取宝贵救治时间,提升装甲救护车利用效能。
1 问题描述及相关假设
1.1 问题简化及描述
在战术区真实战场环境下,伤员人数、伤员分布密集度、救护人员数量、救治技术、进攻通道状况、火力程度、天气等多种因素影响,装甲救护车的前出策略是一个非常复杂的运筹学问题,需要对每种影响因素进行定性定量描述,并分析其对优化目标的影响方式及影响程度,兼顾多种影响因素的精确模型建立难度较大,且求解很难得到最优解。因此,根据不同影响因素的主次关系,对该问题作以适当简化:
1)每个阵地伤员集伤点只有一个,即火线伤员已通过自救互救被集中到一个集伤点。
2)作战通路通畅、状况良好,装甲救护车能正常行驶。
3)不考虑伤员对作战能力的影响,所有伤员同等对待。
4)天气、火力程度、救护人员、指挥链条等相关救护条件正常,不影响装甲救护车执行前接伤员任务。
简化后,本文所考虑问题简要描述如下:已知不同伤势的伤员分布及数量多少,从1 个营救护站到n 个阵地,I 辆装甲救护车分多次前接M 名伤员。以3 个阵地为例,装甲救护车火线伤员收拢前接伤员流程如图1 所示。
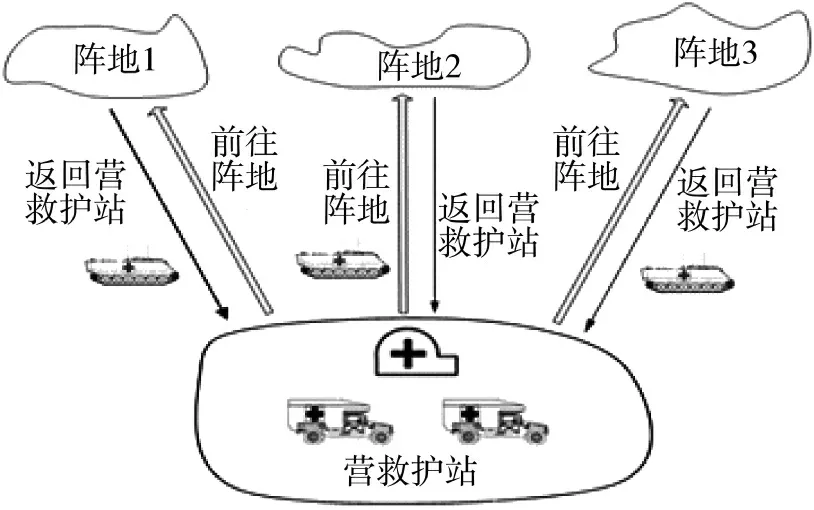
图1 装甲救护车火线伤员收拢前接伤员流程图
1.2 相关假设及符号说明
解决本文问题的相关假设如下:
1)每辆装甲救护车可以到多个不同阵地前接伤员。
2)装甲救护车到达某个阵地集伤点接上伤员原路返回至营救护站(即使在非满载的情况下,也不再到其他阵地集伤点前接伤员),即装甲救护车在伤员集伤点与营救护站之间往返一次后,可变更前接地点。
3)不考虑两车或多车相遇错车时间。
4)伤员等待时间:伤员受伤时刻起至上乘至装甲救护车的时间间隔。
2 模型建立
2.1 相关概念及数学表达

优化目标:I 辆装甲救护车前接完所有伤员时伤员的平均等待时间最少。
约束条件如下:
1)前接伤员的优先顺序依次是重伤员、中度伤员、轻伤员、危重伤员。

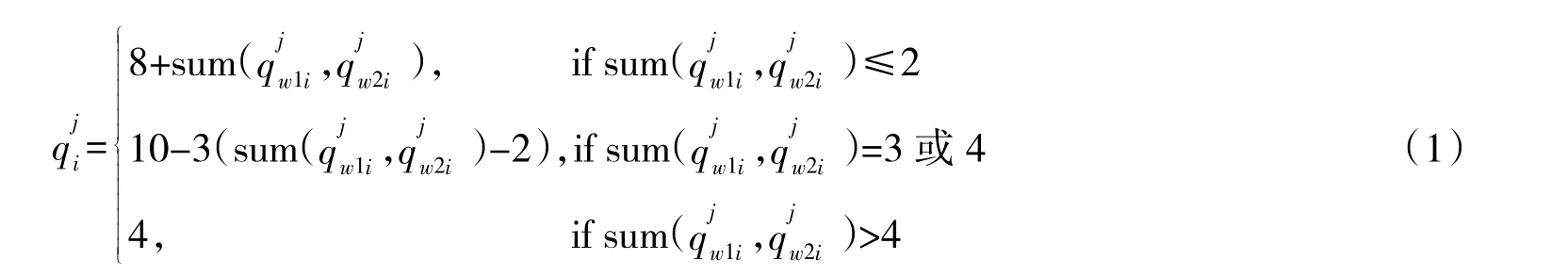
3)伤员登上装甲救护车按照先重后轻的顺序上乘。伤员下装甲救护车按照先坐后卧的顺序下车。
2.2 伤员产生模型

3)设第i 阵地重伤、中度伤、轻伤、危重伤的比例分别为x、x、x、x,且有x+x+x+x=1。则第i 个阵地各类伤员人数分别为:重伤伤员数量M=Mx、中度伤伤员数量M=Mx、轻伤伤员数量M=Mx、危重伤伤员数量M=Mx。
2.3 收拢前接模型
强化学习通过对价值函数实现对未来奖励的预测,进而指导选择不同的行为来影响环境。其中价值函数包括状态价值函数v(s)和动作价值函数q(s,a),表示如下:
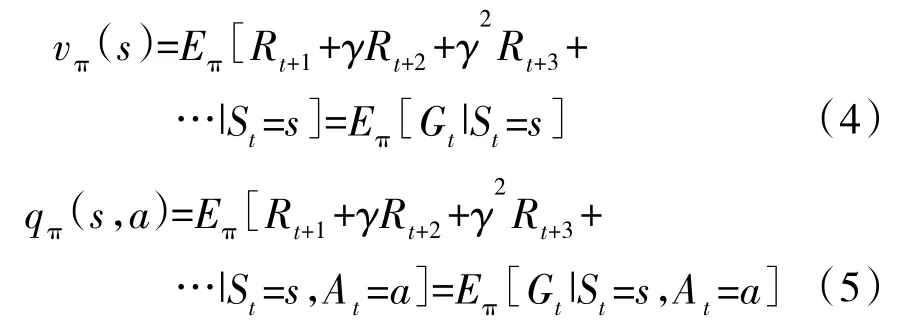
其中,S 为环境状态,是环境的私有呈现,包含了环境决定下一个时刻的奖励的基本信息,环境在t 时刻的状态为S;A 为个体行为,个体在t 时刻的行为用A表示;个体在状态S下,采取了行为A,所获得的奖励为R;π 为策略,是状态到行为的一个映射,也可称为在某个过程中的某一个状态s 采取行为a 的概率为:
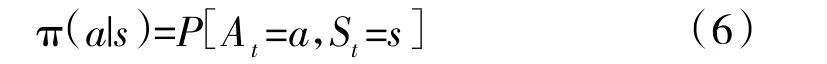
γ 为衰减因子,表示未来的奖励折算到当前的程度,由于未来的奖励具有不确定性,故引入衰减因子的概念,通常其范围为[0,1];G 为收获,即从当前时刻开始的累积奖励,其定义为:

设最优状态价值函数定义为在状态s 下采取最优策略的状态价值函数为:

最优动作价值函数为采取最优策略的动作价值函数为:

则可推导出贝尔曼最优方程为:

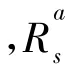

在解决本文所涉及问题时,在寻优过程中,考虑到伤员更新的时间间隔短、装甲救护车在路上所花费时间长,故仅考虑后续的一个状态参与当前状态价值的计算,另外,为了简化计算,设去各个阵地的状态转移概率都相同,则最优状态价值函数和最优行为价值函数改进为下式:

2.4 收拢前接算法设计
输入:伤员的状态S(即重伤,中度伤,轻伤,危重伤的人数),装甲救护车的动作A(即装甲救护车去哪个阵地前接伤员),前接每种伤势伤员的奖励R(利用不同伤势的奖励值体现救治优先顺序),前接策略π(奖励高的阵地优先派车),衰减因子γ。
输出:得出每个状态下的行为价值Q(即得到每个阵地的行为价值,按照行为价值高的优先派车)。
第1 步:根据当前的伤势分布状态S,根据前接策略π 排车去前接伤员,此时算出在当前状态下所有动作A 的即时奖励R。
第2 步:通过作出的行为A 进入下一个状态S′,根据下一个状态S′,利用贪婪法选择出状态S′下的最优动作a′,同时得出最优状态下的策略:
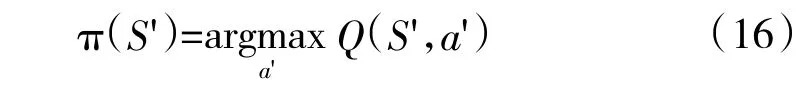
第3 步:利用下式计算当前状态S 的价值Q:
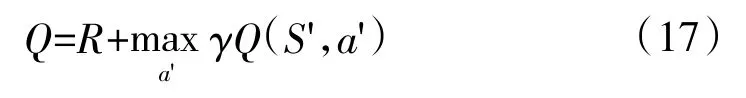
第4 步:比较在状态S 下各个行为A 的动作价值,利用贪婪法选择最优的行为作为实际的行动,同时进入下一个状态:
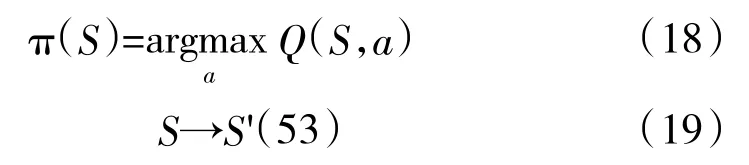
第5 步:循环上面步骤,直到前接完毕,算法结束。
3 算法实验及结果
3.1 实验基础数据
1)营救护站到伤员集伤点的距离区分近距离、中距离、远距离3 种情况。
2)伤员比例:0.1~0.6,以0.1 为间隔递增。
重伤、中度伤、轻伤、危重伤伤员占伤员总数的比例:0.25、0.35、0.35、0.05。
3)作战时间:0.5 h~7 h,以0.5 h 为间隔递增。
4)车辆数:1~20 辆。
5)上下车时间:重伤、危重伤员为30 s,中度伤、轻伤伤员为20 s。
6)车速为45 km/h。
7)合成营总人数:按一定数量计算。
3.2 实验条件
软件开发采用Matlab 2016a 编程,在CPU 为i5-7200、内存为8 G 的计算环境下进行实验验算。
3.3 相关参数设置
奖励R:不同伤势伤员的奖励值按照伤员的受伤程度、伤员的等待时间来进行设置。
衰减因子:γ=0.7。
3.4 算法比较对象:经验算法
根据各个阵地伤员伤势分布,按照重伤、中度伤、轻伤、危重伤优先救治顺序和伤员等待时间大于20 min、10 min~20 min(含)之间、10 min(含)以内优先顺序,进行救护车的调度和分配。定义伤员等待时间为伤员受伤时刻开始到上装甲救护车后的时间。即优先救治顺序为超过20 min 的重伤员、10 min~20 min(含)的重伤员、10 min(含)以内的重伤员,其次是中度伤、轻伤、危重伤的不同等待时间段内的伤员。在搭载不同伤势伤员时,如果车上座位允许,考虑搭载其他伤势种类伤员。
将本文算法与经验算法进行比较,在阵地数为2 伴随保障模式下不同情况两种算法的实验结果(部分),见下页表1。阵地数为3 跟进保障模式下不同情况两种算法的实验结果(部分),见表2。表中伤员平均等待时间为所有伤员等待时间的平均值,单位:min。其中伴随救护保障模式指装甲救护车部署在营救护站,接到命令后前出至火线前接伤员;跟进保障模式指装甲救护车跟进连战斗队,直接接受战斗队连长救护命令,在火线对伤员进行现场急救,而后将伤员后送至营救护站。

表1 阵地数为2 伴随保障模式下两种算法结果比较
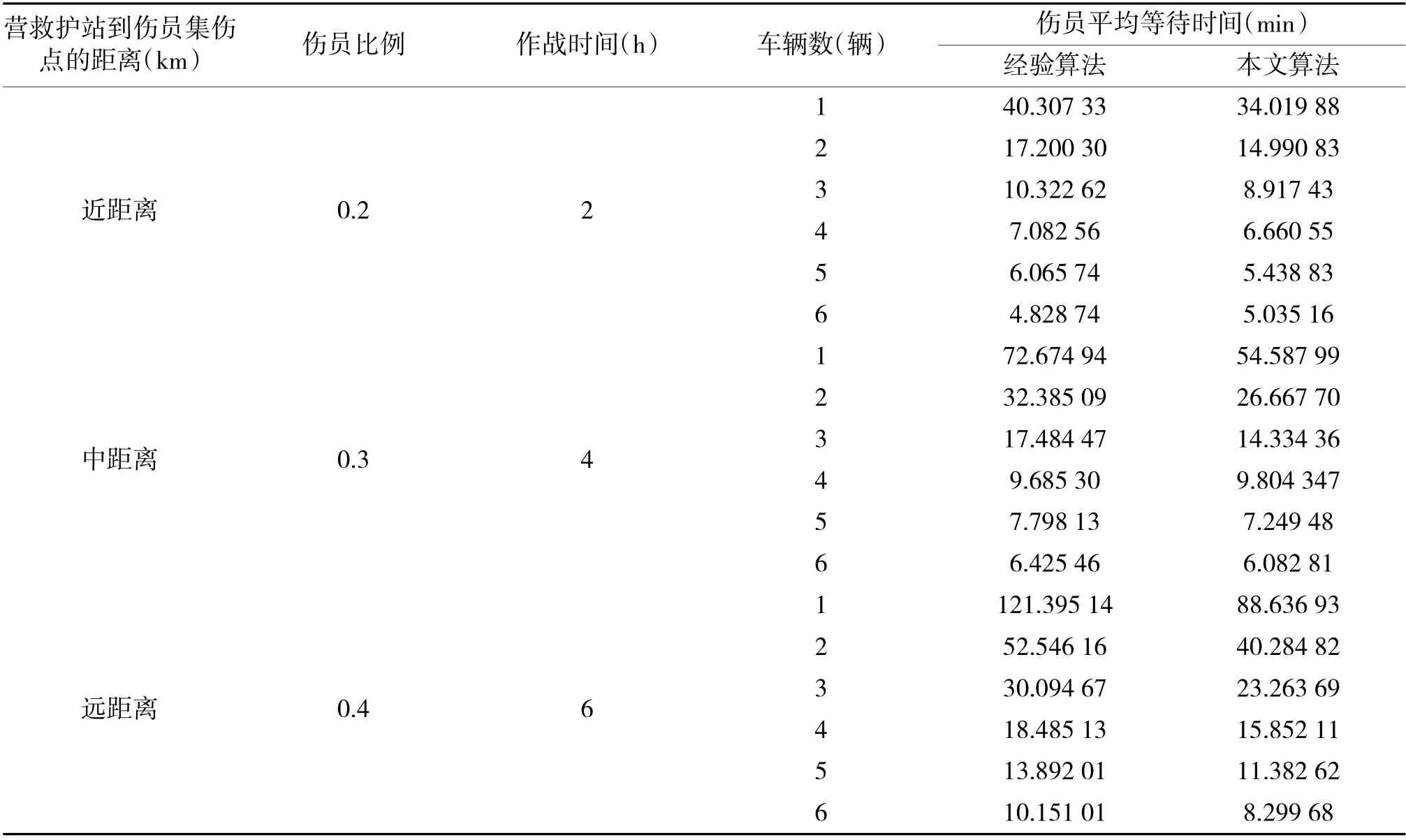
表2 阵地数为3 跟进保障模式下两种算法结果比较
实验中,按照两种不同的保障模式,根据不同阵地数、车辆数、伤员比例、作战时间,针对营救护站到伤员集伤点距离的3 种不同情况,不同距离情况下各作了3 840 次对比实验。综合分析所有实验数据,在3 种不同距离情况下,本文算法优于经验算法的分别占78.9%、77%、68.7%。程序运行一次的时间为0.2 s~50 s。
4 结论
本文以提高合成营卫生排装甲救护组战伤救治能力为根本出发点,将强化学习与装甲救护车的前接策略相结合,运用强化学习理论,综合考虑多种影响因素,构建了装甲救护车火线伤员收拢前接策略模型,测度了不同参数背景条件下不同策略效能,对比了多种情况下本文算法与经验算法的求解效果。实验结果表明,基于强化学习的装甲救护车火线伤员收拢前接策略模型,能够在较短时间内以大概率得到接近最优解的可行策略方案,可为装甲救护车火线伤员收拢前接提供辅助决策支持。
猜你喜欢
小哥白尼(军事科学)(2022年1期)2022-04-26
人大建设(2020年2期)2020-07-27
商业评论(2020年3期)2020-06-15
人人健康(2017年8期)2017-05-02
读者(2015年12期)2015-06-19
新媒体研究(2009年3期)2009-03-30
军事文摘(2009年8期)2009-03-29
军事文摘(2009年8期)2009-03-29
