
基于EM算法的高斯混合模型在鸢尾花数据集的应用
2022-04-27 11:51吴婷
网络安全技术与应用 2022年4期
◆吴婷
基于EM算法的高斯混合模型在鸢尾花数据集的应用
◆吴婷
(保山学院 云南 678000)
高斯混合模型是一种含隐变量的概率图模型,其参数通常由EM算法迭代训练得到。本文在简单推导高斯混合模型的EM算法后,将使用高斯混合模型对鸢尾花(iris)数据集进行分类判别。同时,针对EM算法受初始值影响大的问题,使用了K均值聚类算法作为其初始值的估计方法。在得到K均值聚类算法和EM算法的分类判别结果后,对比两种算法的判别准确率,以此说明在初始值合适的条件下,基于EM算法的高斯混合模型具有较高的准确率。最后文章分析指出了当前EM算法的两个局限性:易受初始值影响和维度灾难。
高斯混合模型;EM算法;鸢尾花数据集;K均值聚类
在实际问题中,传统的单一模型已经无法满足准确性和合理性的要求,有限混合分布的提出为大量随机现象建立统计模型提供了数学基础。混合模型是分析复杂现象的一个极其重要的工具,如图像分割技术和股票市场的数据分析,它几乎涵盖了金融、经济、生物、医学、计算机科学及工程领域等的各个学科[1]。EM算法是一种基于极大似然估计的迭代算法,用于对混合模型的参数估计。近年,国内外研究者对EM算法作了大量研究。王凯南,金立左对传统EM算法稳定性低,易陷入局部极小值,在迭代过程中加入基于模型熵的分裂和合并策略进行改进。冯杭,王胜兵[2]针对离散-连续型混合分布参数估计问题,给出EM算法的估计和求解。Haojun Sun,Shengrui Wang[3]设计了一种计算高斯混合模型中重复率的算法,使用该算法能消除数据集中不同类的混淆问题。
1 基于EM算法的高斯混合模型
1.1 高斯混合模型
高斯混合模型(Gaussian Mixture Model,GMM)是由多个高斯分布组成的模型,其总体密度函数为多个高斯密度函数的加权组合[3]。它既是一种基于概率的聚类模型,也是一种含隐变量的概率图模型。假设样本x是从K个高斯分布中的一个分布生成的,但是无法观测到具体由哪个分布生成。我们引入一个隐变量z∈{1,...,K}来表示样本x来自哪个高斯分布,z服从多项分布:

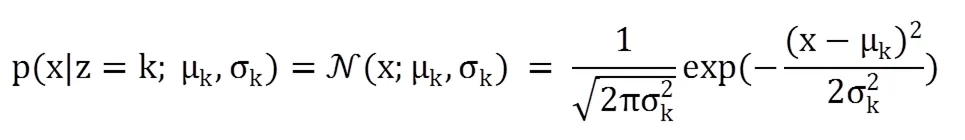

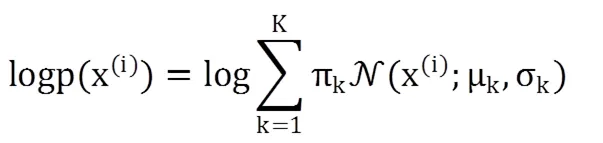
从高斯混合模型中生成一个样本x需要两步:
(1)首先从多项式分布中p(z;π)随机选取一个高斯分布;
(2)假定选中了第k个高斯分布(z=k),再从高斯分布中选取一个样本x。
1.2 EM算法

EM算法每次迭代包含两个步骤:

(2)M步:最大化ELBO(证据下界),将参数估计问题转换为优化问题,求出下次迭代的参数。根据拉格朗日求解后,可得



1.3 K均值聚类
K均值聚类算法(K-means Clustering Algorithm,Kmeans)[6]是一种迭代求解的聚类分析算法,其步骤为,先预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
2 鸢尾花数据集
2.1 数据来源
数据使用了来自R语言中base包里面的iris数据集[7]。iris数据集也称鸢尾花卉数据集,是一类多重变量分析的数据集,也是常用的分类实验数据集,由Fisher于1936收集整理。iris数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性,分别为:花萼长度(Sepal.Length),花萼宽度(Sepal.Width),花瓣长度(Petal.Length),花瓣宽度(Petal.Width)。可通过4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类(Species)中的哪一类。
鸢尾花数据集是一个开放数据集,为解决分类判别问题,已有其他算法的尝试,如:KNN、决策树、逻辑回归(线性回归)、朴素贝叶斯、SVM、随机森林、PCA、Kmeans、Boosting等。目前还没有使用过高斯混合模型来解决鸢尾花划分的问题。
2.2 密度分布图
按种类(Species)不同,分别绘制4个影响变量的密度图,由图1可知,花瓣的长度和宽度对花种类的影响较为明显,不同种类有明显的分布结构区分。而从整体分布上,4个属性大体也服从正态分布,故使用高斯混合模型来表示。

图1 不同种类在不同影响变量上的密度图
3 实验
3.1 实验环境
实验环境为macOS 11.6操作系统,使用R语言4.1.1版本。使用到的R包:ggplot2包和mixtools包。
3.2 实验方法


图2 对数似然值与迭代次数
3.3 实验结果
针对分类结果,需要使用一些分类器的评价指标来对模型优劣进行评价。如果是二分类问题,那么有多种评价指标可以选择,如准确率、召回率、F1、ROC等。但由于本次研究的是三分类问题,那么采用准确率来判断分类的优劣。
(1)K均值聚类的判别结果
由表1可知,K均值聚类判别准确率为89.33%,接近90,判别的准确率不错,但K均值聚类容易陷入局部最优。针对iris数据集,对setosa类别判别更为准确,versicolor和virginica的分类容易混淆。
表1 K均值聚类的判别结果
真实值预测值setosaversicolorvirginica setosa5000 versicolor0482 virginica01436
(2)基于EM算法的高斯混合模型的判别结果
由表2可知,使用K均值聚类结果作为初始值后的EM算法判别准确率为96.67%,判别准确率相比仅使用K均值聚类提高了6个百分点。针对iris数据集,对versicolor和virginica的分类判别更为准确。
表2 基于EM算法的高斯混合模型的判别结果
真实值预测值setosaversicolorvirginica setosa5000 versicolor0455 virginica0050
4 结束语
从实验结果上看,基于EM算法的高斯混合模型在鸢尾花数据集的无监督判别有较好的适用性和准确率。但目前EM算法还存在自身的一些局限性有待解决。一是模型分类结果受初始值的影响较大,目前尚未有公认最有效的初始值确定方法,常用方法是使用聚类的结果来作初始值。二是不适用于高维数据,当数据维度变高时,极易出现相关变量导致奇异矩阵的出现,导致无法进行估计;同时,高维数据还会导致待估计的参数个数呈幂增长,EM算法求解运行效率较低。今后可以针对这两个问题,提出进一步的解决优化方案。
[1]冯杭,王胜兵. 基于EM算法的离散-连续型混合分布参数估计[J]. 统计与决策,2019:85-88.
[2]王凯南,金立左. 基于高斯混合模型的EM算法改进与优化[J]. 工业控制计算机,2017:115-116+118.
[3]Sun H,Wang S. Measuring the component overlapping in the Gaussian mixture model[J]. Data mining and knowledge discovery,2011,23(3):479-502.
[4]Dempster A P,Laird N M,Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society:Series B(Methodological),1977,39(1):1-22.
[5]邱锡鹏. 神经网络与深度学习[M]. 北京:机械工业出版社,2020.04.
[6]Wang L,Ma J W. An Efficient Greedy EM Algorithm for Gaussian Mixture for Adaptive Model Selection Using the Kurtosis and Skewness Criterion[C]//Advanced Materials Research. Trans Tech Publications Ltd,2012,452:1501-1506.
[7]周志华. 机器学习[M]. 北京:清华大学出版社,2016.01.
[8]Fisher,R. A.(1936) The use of multiple measurements in taxonomic problems.Annals of Eugenics,7,Part II,179-188.
猜你喜欢
幼儿100(2021年37期)2021-12-23
小学生必读(低年级版)(2020年4期)2020-06-28
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
百科探秘·航空航天(2019年5期)2019-06-06
散文诗(2017年18期)2018-01-31
中国水运(2017年9期)2017-09-15
现代电子技术(2017年11期)2017-06-12
湖南大学学报·自然科学版(2017年4期)2017-05-18
计算机应用与软件(2017年4期)2017-04-24
