
基于改进随机搜索算法的随机森林调参优化
2022-04-27 11:51刘紫亮居翔张永芳黄逸翠
网络安全技术与应用 2022年4期
◆刘紫亮 居翔 张永芳 黄逸翠
基于改进随机搜索算法的随机森林调参优化
◆刘紫亮 居翔 张永芳 黄逸翠
(南昌工程学院 江西 330096)
随机搜索法是对无约束力问题寻找最优解的一种算法。随机森林是一种集成算法,为了提高随机森林分类的准确率,需要对参数进行调参。随机森林可以通过网格搜索算法或学习曲线算法选取到合适的参数,但是训练时间过长,消耗资源过大。本文通过对随机搜索算法改进,利用改进的随机搜索算法优化随机森林调参。经过实验验证,改进的算法选取到的参数保证了随机森林分类准确率的同时,相较于通过学习曲线算法缩短了约百分之六十的调参时间。
随机搜索法;随机森林;参数优化;学习曲线
1 引言
集成学习(Emsemble Learning)是当前被广泛使用的一种机器学习算法,再机器学习领域都可以找到其身影。集成算法是在数据集上建立多个训练模型,构建多个相互独立或者相关的基评估器(Base Estimator)。集成算法会把所有基评估器的分类或回归结果进行整合运算,以提高分类或回归结果的准确性[1]。随机森林(Random Forest)就是集成学习算法的一种,随机森林算法[2]是由Leo Breiman在2001年提出,结合了袋装法(Bagging)和随机子空间理论,使得决策树过拟合的问题在随机森林上得到解决。文献[3]表明了随机森林算法在处理高纬度数据或是数据特征缺失的情况下依旧能维持较高的分类准确率。
随机森林的基评估器的数量代表决策树(DecisionTree)的数量。决策树可以是分类树或者回归树,对应的分别为随机森林分类器和随机森林回归器[4]。Paul At等提出一种改进的随机森林分类器,提出的方法能迭代地删除一些对随机森林不重要的特征,减少了特征参数的数量[5]。Yang等验证了一种基于边缘优化的剪枝算法,减小了调参的复杂性并提高了随机森林的性能[6]。想要提高随机森林的分类准确率,除了特征的选取,还需要对参数进行优化。刘凯提出了自适应特征选择参数优化算法SARFFS,该算法综合了粒子群算法和随机森林算法,提高了参数选择过程的效率[7]。温博文等通过改进网格搜索法,对随机森林的候选分类特征和决策树的数量参数进行优化,降低了泛化误差[8]。具体调参方面的研究还甚少,究其原因就是每个数据集所需要的参数有所不同。仅凭借经验进行调参,往往得不到最优的分类结果。若是以牺牲计算机的性能为代价,暴力地通过学习曲线法或者网格搜索法进行调参,虽然能够遍历所有参数,分析每个参数对随机森林的影响,但代价就是训练时间过长,消耗资源过大。
2 决策树与随机森林算法原理
2.1 决策树算法
一片森林是由多棵树构成,随机森林的树称之为决策树,一棵棵不同的决策树就形成了随机森林。式(1)中S为决策树的数量。

决策树算法的模型原理简单,在解决分类和回归问题上有很好的表现。决策树算法的原理是在一组有不同特征和分类标签的数据中,对特征进行分类判断训练,训练结束后形成一棵类似树的分类模型。构建决策树模型最重要的是找到最佳的分支节点和最佳分支方法,衡量“最佳”的指标叫做不纯度。分类树的不纯度选用信息熵或者基尼系数进行运算,分类决策树每次选择分支节点时,决策树会对剩余所有特征进行不纯度的计算,决策树会选择不纯度最低的特征进行分支,分支越多,决策树模型越复杂,树整体不纯度也越低。这种模型构建方法会导致决策树易拟合,训练集表现良好,测试集却不尽人意。
2.2 随机森林算法
随机森林算法引入了两个随机量应对决策树易过拟合的问题,分别是有放回的随机抽取样本数据和从特征中随机选择候选分类属性。随机森林的构建过程如图1所示。

图1 随机森林构建过程
RF在构建每一棵决策树的过程中,训练集是通过在大小为N的数据集中有放回的抽取N个训练样本,一个样本被抽取的概率为:





用泛化误差衡量随机森林的准确率。当泛化误差达到最低点时,分类的准确率最高。泛化误差受模型复杂度的影响,参数影响模型的复杂度,模型复杂度越高,泛化误差随之升高。相反,模型复杂度比最佳复杂度还低时,泛化程度也随之升高。泛化误差受到方差(var)与偏差(bias)和噪声的影响:

偏差反映的是预测值和真实值的差异,随机森林的偏差是所有决策树偏差的均值,模型越精确,偏差越低。方差反映的是每次输出结果与模型预测值的平均水平的误差,模型的稳定性与方差值成反比。方差与偏差不可能同时最低,调参的目的就是让方差和偏差相对最低,得到最低的泛化误差。
3 基于改进随机搜索算法优化随机森林调参
随机搜索法是一维搜索法,先确定一个大致的范围,然后随机对这个范围内的点进行比较,设定一个迭代次数的上限,如果在迭代次数的范围内找到最优值,则终止迭代,否则加大迭代次数,重新开始。随机搜索法的算法如下:
程序结束后可以通过观察最优解的稳定性判断迭代次数是否足够,稳定性不足,可以加大迭代上限。随机搜索法得到的最优解是全局最优解而非局部最优解,对低维的数据集搜索快速且效率高。
随机森林模型分类准确率取决于泛化误差的大小,而为了达到泛化误差的方差与偏差的平衡,让模型的效果达到最优,我们需要进行超参数的优化,也就是进行调参,随机森林可调节参数和参数重要性如表1所示。
表1 随机森林参数
参数对模型的影响影响等级 n_estimators基分类器数量不影响单棵决策树的复杂度,数量越大模型越稳定Level-1 max_depth最大深度越小,模型越简单Leval-2 min_samples_leaf越小模型越复杂Leval-3 min_samples_split越小模型越复杂Leval-3 max_features数量为总特征数的平方,降低时模型复杂度降低Leval-4 criterion选用gini系数Leval-5
为了降低调参的时间,提高训练的效率,本文提出了在学习曲线的基础上,利用改进的随机搜索法进行随机森林的调参。具体步骤如下(见图2):
(1)确定选取参数的上限与学习曲线的粗步长,在范围内进行步长L搜索,利用交叉验证的方法,得到每个点的分类准确率的均值,选取最优的分类准确率的粗最优点。
(2)在选取粗最优点后利用随机搜索法在粗最优点附近进行随机搜索,随机搜索的范围为。
(3)确定好迭代次数,对每一次迭代取到的随机点进行交叉验证,记录选取的参数和对应的分类准确率。程序结束后输出最优的参数和最优的分类准确率。判断分类准确率的稳定性,稳定性不足增大迭代次数,重新进行搜索。

图2 基于改进随机搜索算法优化随机森林调参流程图
通过学习曲线或者网格搜索的“暴力”搜索法,虽然能够探索到参数的边缘,但是代价就是训练模型的时间非常长,极大地浪费资源,通过改进的随机搜索改进的随机森林调参法能够避免对每个参数进行校验,节省资源的同时缩短调参时间。
4 实验
4.1 数据集和实验环境
本文数据集采用的是sklearn数据库中的6个数据集,开发环境为Jupyter Lab,使用的库和模块为Pandas、Matplotlib、Graphvi、SciP与Python。表2为数据集的描述。
表2 sklearn数据集
数据集样本数特征维数类别数 Wine124133 breast_cancer569302 Iris15043 Pima768822 Glass178133 Letter31752403
4.2 实验过程
本文以breast_cancer数据集为例基于改进随机搜索算法优化随机森林调参。breast_cancer是一个二分类数据集,两个类别分别是“良性”和“恶性”,具有30个特征维度。选用随机森林的基分类器(n_estimators)参数进行调参优化,设定基分类器上限为300,粗步长为30,交叉验证cv=10。
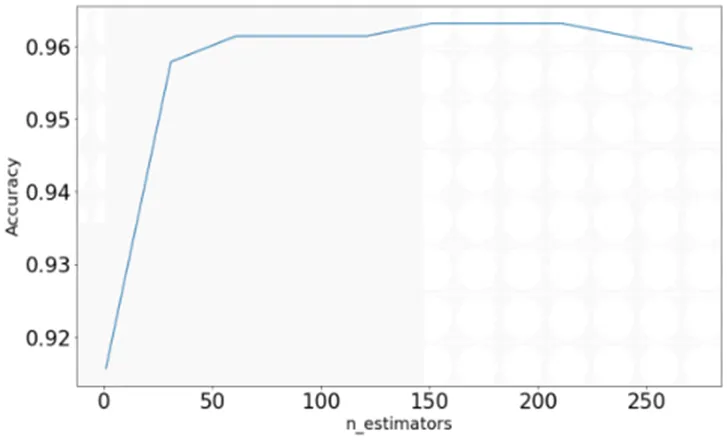
图3 粗步长搜索图
由图3可知,当基分类器的数量71时,随机森林的分类准确率最高,为0.963126。可以看出随机森林的准确率并不是随着基分类器的增大而一直增大,这是由于基分类器的数量越大,模型的复杂度会增加,方差增大使得总泛化误差也随之变大。由于开始选取的粗步长为30,接下来需要在(41,101)范围内,利用随机搜索法进行随机搜索,设定迭代次数上限为20,进行随机搜索。

图4 改进随机搜索法与学习曲线对比图
图4中折线与点状图分别为学习曲线与改进的随机搜索法搜索参数的分类准确率。由点状图可知,当基分类器参数取到75时,随机森林分类器的准确率最高,为0.9648809。由于参数的分类准确率趋于稳定,可以认定该点为最优点。由图4可知,基于改进的随机搜索法搜索到的参数最高的分类准确率与学习曲线取到的参数最高分类准确率相同,但两者在训练的时间上却相差很大,分别为20s与98s。为了验证本文提出的方法具有普遍性,对表2其余数据集也进行上述步骤,得到实验结果如表3所示。
表3 不同数据集实验结果比较
数据集学习曲线随机森林准确率学习曲线算法时间(s)随机搜索法随机森林准确率随机搜索法优化后时间(s) wine0.955360.95411 iris0.943480.94313 pima0.9381120.93632 glass0.946530.94618 Letter0.8985780.904120
通过表3可以看出,基于改进随机搜索法的随机森林调参相对于通过学习曲线调参,选取的参数保证了随机森林准确率的同时,缩短了约百分之六十的调参时间,数据集越大,节省时间的效果也越明显。在letter数据集上,由于样本数量的庞大,计算机未能通过学习曲线遍历所有的参数,分类准确率低于本文提出的方法。
5 结束语
本文提出的基于改进随机搜索法的随机森林调参优化,保证了搜索到的参数能提高随机森林分类的准确率,相较于学习曲线算法极大缩短了搜索合适参数的时间。但是本文参数选择有一定的随机性,在进行步长搜索时,最优的参数可能没有被搜索到,陷入了局部最优。
[1]于玲,吴铁军. 集成学习:Boosting算法综述[J]. 模式识别与人工智能,2004(01):52-59.
[2]Breiman L.Random forests[J] .Machine Learning,2001,45(1):5-32.
[3]方匡南,吴见彬,朱建平,等. 随机森林方法研究综述[J]. 统计与信息论坛,2011,26(003):32-38.
[4]Bonissone P,Cadenas J M,Garrido M C,et al. A fuzzy random forest[J]. International Journal of Approximate Reasoning, 2010.
[5]Paul A,Mukherjee D P,Das P,et al. Improved Random Forest for Classification[J]. IEEE Transactions on Image Processing,2018:4012-4024.
[6]Yang,WH,Luo,et al. Margin optimization based pruning for random forest[J]. NEUROCOMPUTING,2012(94):54-63.
[7]刘凯. 随机森林自适应特征选择和参数优化算法研究[D].长春工业大学,2018.
[8]温博文,董文瀚,解武杰,等. 基于改进网格搜索算法的随机森林参数优化[J]. 计算机工程与应用,2018.
[9]罗预欣,张兵,薛运强.基于变量分析和粒子群优化加权随机森林的交通事件检测方法[J].科学技术与工程,2021,21(14).
[10]余韦,余凤丽,吉晶,等.一种基于改进逻辑回归算法实现模型在线调参方法[J].通信技术,2020,53(08):1965-1969.
[11]陈晋音,熊晖,郑海斌.基于粒子群算法的支持向量机的参数优化[J].计算机科学,2018,45(06):197-203.
[12]Cai J,Xu K,Zhu Y,et al. Prediction and analysis of net ecosystem carbon exchange based on gradient boosting regression and random forest[J]. Applied Energy,2020,262:114566.
猜你喜欢
中华骨与关节外科杂志(2022年1期)2022-08-31
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
空间科学学报(2020年1期)2021-01-14
文苑·感悟(2019年12期)2019-12-23
文苑(2019年23期)2019-12-05
电子技术与软件工程(2019年18期)2019-11-18
读者·校园版(2019年17期)2019-08-13
电子制作(2018年16期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
