
基于FastDTW-LSH的shapelet筛选方法
2022-05-05 08:31张宏飞乔钢柱
中北大学学报(自然科学版) 2022年2期
张宏飞,乔钢柱,宿 荣
(中北大学 大数据学院,山西 太原 030051)
0 引 言
时间序列数据,按一定先后顺序排列而成,是一种随着时间变化而发生变化的数据,它反映了观测数据随着时间不断变化的趋势,这个趋势可能会具有混沌性、周期性、随机性等性质. 对于时间序列的分析大致有两类,一类是根据历史数据对未来数据进行预测分析,例如天气预测,空气质量预测,疫情预测[1-3]等; 另一类是对时间序列数据进行分类,例如心电图诊断分类,设备故障分类[4-5]等.
与传统数据分类不同的是,时间序列数据是一种强调时序顺序的数据,不同的属性次序可能会产生不同的特征提取结果,进而会影响最终的分类效果. 由于时间序列数据大多是高维海量数据,如果要全部处理,其计算开销巨大,耗时严重且夹杂了许多噪声. 鉴于此,Ye和Keogh[6]首先提出了shapelet的概念,根据不同时间序列之间略有差异的局部特征进行分类. Shapelet是时间序列中最具区别性的一组子序列,由一个或多个子序列组成,能明显区分出不同类别的序列. 如图 1 所示,Coffee两类数据在全局特征上保持高度相似性,仅在局部特征上表现出明显差异,即标注之处或可为Coffee数据的shapelets,在形状上能直观解释不同类别数据的差异. Shapelet的优势在于将研究目标从时间序列本身转换为研究其子序列,能够大大减少时间消耗,且shapelet在形状上可以直观解释分类结果和数据内部特征差异.

图 1 Coffee数据序列示意图Fig.1 Data sequence diagram of Coffee
Ye和Keogh提出的基于shapelet的时间序列分类和分析方法也被应用于时间序列数据挖掘的各个领域,但这种原始搜索shapelet方法的时间复杂度为O(n2m4),需要枚举所有候选子序列并比较其质量,时间开销太大,令研究难以为继. 于是,在基于候选空间搜索shapelet的研究领域,研究者们提出以下方法来降低计算开销.
在聚集近似方面,Rakthanmanon等[7]提出了一种基于符号聚集近似(SAX)的快速shapelet发现算法(Fast Shapelet,FS). 类似地,Fang等[8]也提出了一种基于分段聚合近似(PAA)的shapelet搜索方法来加快运行速度.
在降维方面,李祯盛等[9]提出了基于主成分分析(PCA)的shapelet搜寻方法(降维从而加快运算速度),但是降维的方法可能会丢失原始数据中的有用信息,影响分类准确率.
在硬件方面,Chang等[10]从硬件角度出发,并行计算shapelet从而提升了效率,但候选者空间消耗巨大,冗余无法解决.
在剪枝操作方面,He等[11]提出了先将序列符号化,将较低频率的序列列入候选空间; Wei等[12]提出了通过最大相似性和最小冗余度消除一部分相似shapelet; Ji等[13]提出了一种基于子类分裂方法,通过对训练实例采样找出局部最远偏移点,选择两个不相邻的偏移点之间的子序列作候选shapelets.
对序列是否被列入为候选空间,Renard等[14]提出了随机思想,但是通过随机函数方法得到的结果解释能力不强. Karlsson等[15]提出了shapelet随机森林的方法,通过随机选择的序列和shapelet构建决策树构成随机森林.
针对在筛选shapelet的过程中同时构建分类器,Lines等[16]提出了通过shapelet的转换,将shapelet转换到新的数据空间,使shapelet的发现过程和分类器构建各自独立,使用更加灵活. Grabocka等[17]第一次提出用目标函数求解shapelet(Learned Shapelet,LS),然而,由于不能学习随着时间轴弯曲的时间序列,又提出了基于DTW的学习shapelet方法,但是复杂度增加. 基于shapelet转换方法上的难题在于无法确定用于转换的shapelet的数量,原继东等[18]提出了剪枝和覆盖的shapelet转换方法来解决此问题,但是随着数据规模增大,时间复杂度难免增加. 鉴于此,丁智慧等[19]提出了基于LSH的shapelet转换方法(LSH shapelet transform, LSHST),采用解决高维海量数据问题的局部敏感哈希(LSH)方法在搜寻shapelet的过程中逐级过滤掉大量子序列,再通过文献[18]的shapelet覆盖方法再次筛选,以确定最终shapelet数量,最后进行shapelet转换,缩减了时间复杂度,保证了一定的分类准确率.
由于LSHST在逐级过滤过程中,仅是对同一哈希桶中的子序列进行随机筛选,可能会造成带有关键性信息和局部特征区分度更高的候选子序列被剔除,导致最终筛选出来的shapelets对分类结果有一定影响. 因此,本文提出基于局部敏感哈希的FastDTW-LSH-Shapelet筛选方法,对LSH映射后的各哈希桶中的子序列采用FastDTW距离[20]衡量子序列间的相似性,对其进行分类并挑选出各类中具有极大不相似性的子序列以供下一次映射,循环操作后,使用shapelet覆盖的方法确定最终shapelet数量并进行转换. 相比LSHST方法循环映射中的随机筛选,本文所提方法采用的分类后再筛选更具有公平性,而且在各数据集上都具有较好的分类结果.
1 相关公式与定义
定义1(时间序列):时间序列T={t1,t2,t3,…,tn}是一个长度为n的实值连续型数据序列.其中每个元素ti(1≤i≤n)按照时间的先后顺序采样排列.
定义2(动态时间规整,Dynamic Time Wraping,DTW)[20]:是为了解决传统欧式距离点对点计算要求序列等长的问题而提出的,可以对时间序列本身进行延伸和缩短,能实现不同长度时间序列距离的计算. 计算序列T={t1,t2,t3,…,tM}和T1={t11,t12,t13,…,t1N}之间DTW距离的步骤如下:
1) 计算两个序列各个点之间的距离矩阵(Distance Matrix,DM).
DM=(a(i,j))M×N,a(i,j)=(ti-t1j)2.
(1)
2) 寻找一条从矩阵左下角到右上角的规整路径,使得路径上的元素和最小.
W=(w1,w2,…,wk),
(2)
式中:wk=a(i,j),那么wk+1满足以下条件
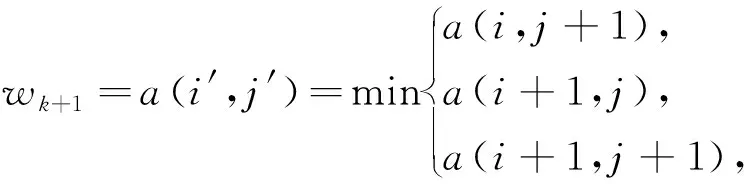
(3)
那么两条序列之间的DTW距离为

(4)
定义3(局部敏感哈希,LSH)[21]:局部敏感哈希的提出是用来解决高维海量数据的近似近邻搜索问题. 通过哈希函数对原始数据空间中的点进行哈希映射,映射到同一哈希桶中的数据被认为近似相似. 哈希函数H需要满足以下两个条件:
1) 如果d(x,y)≤d1,则h(x)=h(y)的概率至少为p1,即PrH[h(x)=h(y)]≥p1;
2) 如果d(x,y)≥d2,则h(x)=h(y)的概率至多为p2,即PrH[h(x)=h(y)]≤p2.
满足以上条件则认为H是(d1,d2,p1,p2)敏感的. 哈希函数定义为
(5)
式中:ω是窗口长度参数;ai是一个d维向量,每一维的值都满足标准正态分布;bi满足[0,ω]的均匀分布.
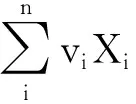
2 基于FastDTW-LSH的shapelet筛选方法
为了解决海量高维数据查询效率低的问题,局部敏感哈希利用哈希函数将近似相似的数据映射在同一哈希桶中,不相似的分别映射在其他桶中,保证同一哈希桶中数据近似相似,明显降低了计算复杂度和时间消耗. LSHST通过欧式敏感哈希函数将大规模的候选子序列映射到不同哈希桶中,随机筛选出每个哈希桶中具有代表性的集合并释放空间,然后再逐级过滤掉大规模的冗余序列,筛选出最终的shapelets.
图 2 为GunPoint数据集的原始序列和部分长度为20的子序列,这些子序列经过局部敏感哈希映射有极大概率会落在同一个哈希桶HashBucket1中,但是子序列Subseq2与其他两条相比,明显具有更多特征,形状上也更具区分度,更希望Subseq2参与下一次哈希映射,但随机挑选时,同一哈希桶中每一条子序列都容易被选中,很可能会遗漏掉Subseq2; 另一方面原始序列在产生子序列时为保证时序数据的时序性,是在原始序列上进行窗口为1的滑动,会产生有大量重叠部分且高度相似的候选子序列,而这些冗余无意义的候选序列无疑会增大计算开销和时间消耗. 因此,在逐级哈希的过程中使用FastDTW距离衡量序列相似性并剔除冗余序列,可以在减少计算开销、降低时间消耗的同时选择出更具有区分度的子序列来进行下一次哈希映射,提高最终shapelets集合的质量,提升分类精度.
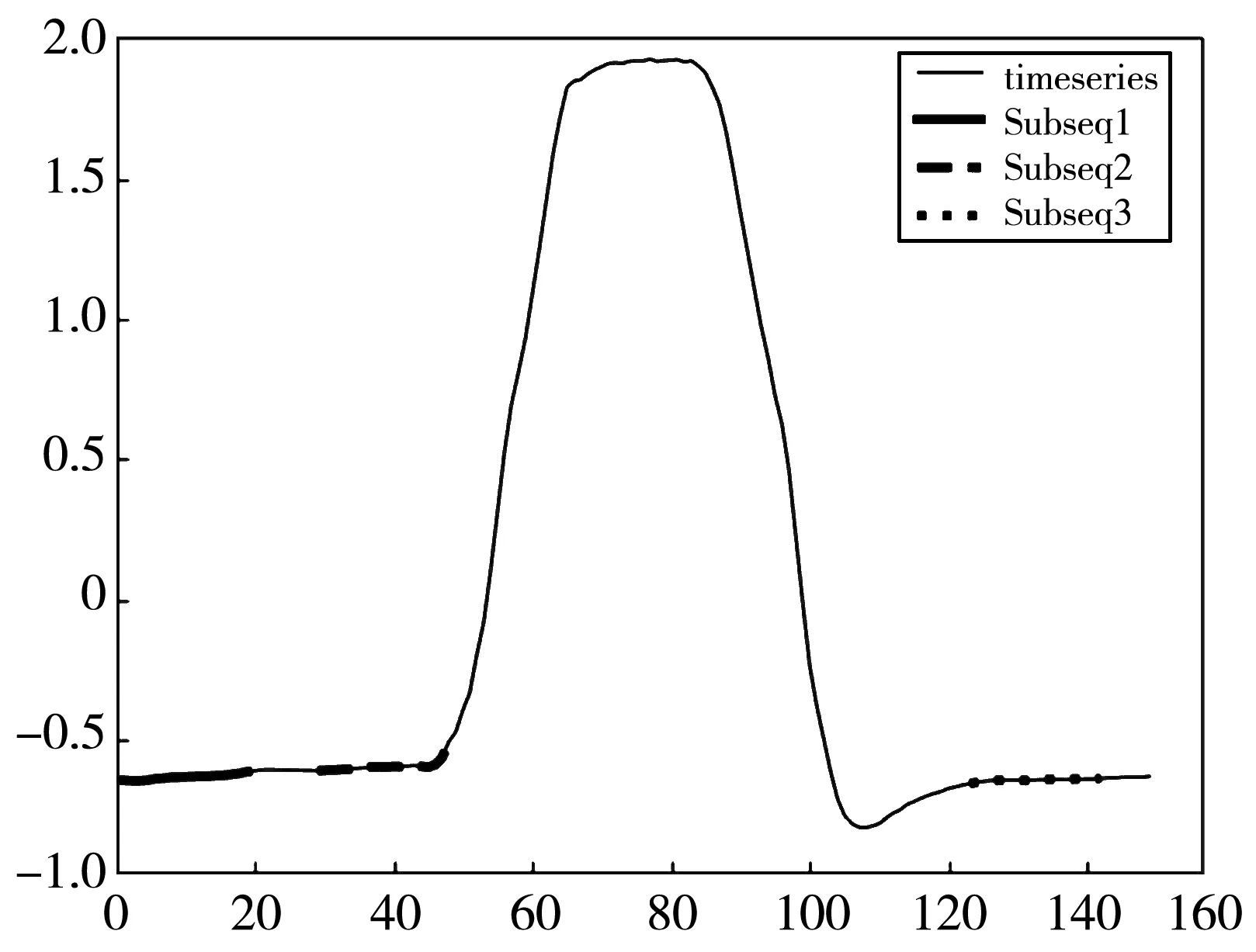
图 2 GunPoint数据序列示意图Fig.2 Data sequence diagram of GunPoint
2.1 LSH映射筛选子序列
由上述定义3可知,局部敏感哈希映射,即用满足以下两个条件的哈希函数将原始数据映射生成哈希表:
1) 相近的数据落在同一个哈希桶中的概率p1很高;
2) 不相近数据落在同一哈希桶中概率p2很低.
将序列引伸为向量数据,利用LSH映射筛选子序列的过程即将序列通过哈希函数映射生成哈希表,生成的哈希表中相似序列落在同一个哈希桶中的概率很大,不相似序列则落在不同哈希桶中. 在序列筛选过程中更多关注的是具有不同特征的序列而非具有高度相似性的序列,以便从不同哈希桶中挑选出更具有区分度的序列进行下次计算. 建立L个哈希表后,两条序列相似的概率是P=1-(1-pk)L,利用LSH映射的这种性质可以很快筛选出需要的待选序列,减少计算开销,提高时间效率.
2.2 FastDTW衡量筛选过程
经过LSH映射后,同一哈希桶中的序列只是保证了有一定概率相似而非完全相似. 以GunPoint数据集为例,长度为10的子序列经过LSH映射,随机选择HashTable1中的哈希桶并随机采样如图 3 所示. 由图 3 可见,落入同一哈希桶中的序列并非完全相似,HashBucket1中序列1,2,5,6在形状趋势变化上相似,而序列3和4则与之不同. 将前者划分为Class1,后者划分为Class2. 在随机筛选HashBucket1中的序列参与下一次映射计算时,Class1中的序列参选概率更大,会引起筛选过程中更具特征差异性的子序列被遗漏,导致候选空间的子序列质量不高,降低最终筛选的shapelets质量. 在HashBucket2中子序列集保持很大的相似性,在HashBucket3中子序列集明显出现聚集情况. 本文提出将哈希桶中的序列先分类再筛选,确保涵盖特征差异的子序列参与下一次哈希映射,提高最终筛选的shapelets质量.

(a) HashBucket1 采样序列
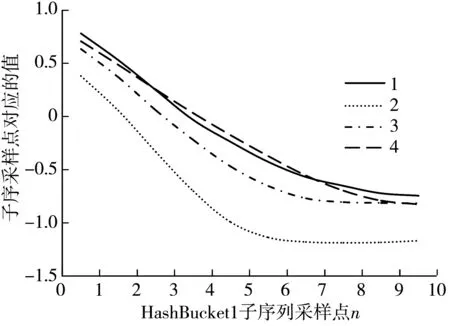
(b) HashBucket2 采样序列

(c) HashBucket3 采样序列图 3 不同哈希桶中的子序列Fig.3 Sub-sequences in different Hash Buckets
对于序列分类而言,欧式距离无法解决序列弯曲拉伸的情况. 如图 3 所示,HashBucket1中的序列1,5,6经过一定程度平移伸缩可认为其相似性很高,而欧式距离无法评判这种相似性,故而采用DTW距离作为度量标准. 由式(4)定义可知,计算两条序列DTW距离的时间复杂度是O(n2),计算开销太大. 经过LSH映射筛选后落在同一个哈希桶中的序列已经保持了极大的相似性,所以,对同一个哈希桶中的序列进行分类的目的是为了能够尽可能公平地筛选出具备更多特征和区分度更强的子序列参与下一次计算,因而不需要精确计算出序列间的DTW距离. 使用FastDTW方法来加快计算过程,通过限制空间和抽象的手段求出两条序列间一条近似最优的弯曲路径,且时间复杂度仅为O(n).
1) FastDTW计算步骤:
① 粗粒度化:原始序列粗粒度化收缩,收缩后各数据点为相邻数据点的平均值. 可进行多次收缩求出粗粒度化空间.
② 投影:在粗粒度化收缩后的空间计算DTW距离,得到粗粒度化空间下的动态规整路径.
③ 细粒度化:将上一步求到的规整路径细化到细粒度空间,再逐步细化到原始空间.
如表 1 所示,随机采样HashTable1中的哈希桶,计算子序列与各桶中首个子序列的FastDTW距离,从数值上可以看出同一哈希桶中的子序列只是近似相似而非完全相似. 采用FastDTW距离对各桶中的序列进行分类后,再随机筛选出子序列参与下一次LSH映射.

表 1 不同哈希桶中随机采样子序列间的FastDTW距离Tab.1 FastDTW distance between randomly sampled sub-sequences in different Hash Buckets
2) FastDTW分类筛选方法
FastDTW筛选流程如图 4 所示.
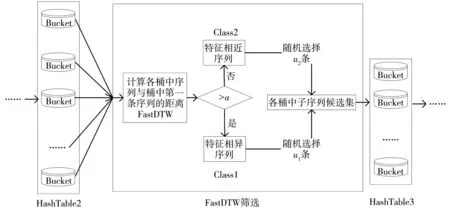
图 4 FastDTW筛选流程图
首先,计算哈希桶中的子序列与各桶中第一条序列的FastDTW距离. FastDTW大于阈值a的划分为特征相异的一类Class1,不大于阈值a的划分为特征相近的一类Class2; 在Class1,Class2中各随机选择u1,u2条序列.
其次,对哈希表中的每个哈希桶中的子序列重复上述操作,筛选出高质量的子序列候选集.
最后,删除此次哈希映射生成的哈希表,释放空间并进行下一次哈希映射.
2.3 FastDTW-LSH的shapelet筛选方法描述
FastDTW-LSH方法在筛选shapelets过程中对序列数据进行第一次LSH映射后,所有子序列被映射到HashTable1中,若此时对HashTable1中所有哈希桶的子序列进行FastDTW分类判别无疑增加了时间消耗. 由图 3 可以看出,即使映射在同一哈希桶中的子序列也存在明显类别差异. 为了增加随机筛选的公平性(即增加了同一哈希桶中不同类别的子序列参与映射的概率),同时为了避免庞大时间消耗,对HashTable1中各哈希桶随机筛选两条进行第2次哈希映射,在第2次LSH映射结束后再进行FastDTW分类筛选,将原本上千甚至上万条子序列的分类判别转变成对几十条子序列的分类,在较低的计算开销下筛选出更具代表性和特征差异性的子序列参与下一次映射,最终提高 shapelets的多样性和可解释性. 如图 5 所示,FastDTW-LSH的shapelets筛选方法具体流程如下:
第一步,定义shapelets候选序列的最小长度minlength和最大长度maxlength,并根据原始序列生成子序列; 设置哈希映射次数L,设置同一哈希桶中序列相似阈值a和筛选条数u1和u2.
第二步,利用LSH映射建立哈希表HashTable1,将子序列集合映射到各哈希桶中,在各哈希桶中随机筛选两条序列参与下一次映射并删除HashTable1释放空间.
第三步,利用LSH映射建立哈希表HashTable2,将HashTable1中筛选出来的子序列映射到各哈希桶中,根据FastDTW距离来筛选过滤各哈希桶中的子序列; 计算HashBucket1中所有序列与第一条序列的FastDTW距离,大于a的序列划分为Class1,其余归为Class2,分别在Class1和Class2中各筛选u1和u2条; 遍历HashTable2中所有哈希桶,挑出各桶中具有极大不相似性的子序列供下一次计算,并删除HashTable2,剔除冗余无意义的序列,释放空间.
第四步,重复上述操作,逐级筛选过滤至L次循环映射结束,得到具有明显特征区分的候选序列.

图 5 FastDTW-LSH筛选shapelets流程图
3 实验
针对shapelets筛选过程参数选择和FastDTW-LSH算法评估分别进行对比实验. 本文实验环境为Java,Python3.7,数据集选用UCR公开数据集,实验数据如表 2 所示,分别选用不同规模数据综合评估算法.

表 2 实验数据集Tab.2 Experimental dataset
3.1 参数选择
为了提高筛选shapelets的质量,本文方法在子序列筛选过程中引入参数L,a,u1和u2. 文献[19] 实验结果证明,哈希映射次数L和随机筛选参数u的最佳组合是L=50,u=1. 在此基础上,设计了子序列相似性阈值a,循环映射次数L和映射过程中的筛选子序列数量u1,u2等实验参数组合,分别在各数据集上进行算法分类精度和耗时实验,以便进行最优参数的选择.
3.1.1 子序列相似性阈值a
如图 2 和表 1 所示,针对GunPoint数据集长度为10的子序列,经过一次LSH映射后,随机采样HashTable1中的哈希桶并进行FastDTW距离计算,可以看到即使是映射到同一哈希桶中的子序列,其距离差异也很大,故针对后续筛选过程阈值a的选取应该由各桶中序列的相似性决定.由于样本均值反映的是样本集中趋势,而样本方差和标准差反映的是样本离散趋势,均值结合标准差反映的是样本偏离程度,故使用统计量μ,σ,μ+σ作为各哈希桶中分类筛选的阈值参数a,并进行多组实验选出最适合的统计量作为阈值参数.μ,σ分别表示样本均值和标准差,对于统计量定义如下:
aii=μii+σii,
式中:aii表示HashTablei中HashBucketi进行FastDTW分类筛选的阈值;μii表示HashTablei中HashBucketi序列间FastDTW距离的均值;σii表示HashTablei中HashBucketi各序列间FastDTW距离的标准差.
3.1.2L和u1,u2组合参数
参数L是循环映射次数,参数u1,u2是在对同一哈希桶中的子序列分类后各类参与下一次映射的子序列数量.在不大幅增加时间消耗的前提下,为了保证映射和筛选过程的公平性,使用u1,u2组合函数f.
不同统计量定义的参数阈值a和循环映射次数L都会影响最终shapelets的质量,进而影响FastDTW-LSH方法的分类效果. 为了探究参数的影响,分别在不同参数组合下对不同数据集进行实验,结果如图 6 所示.
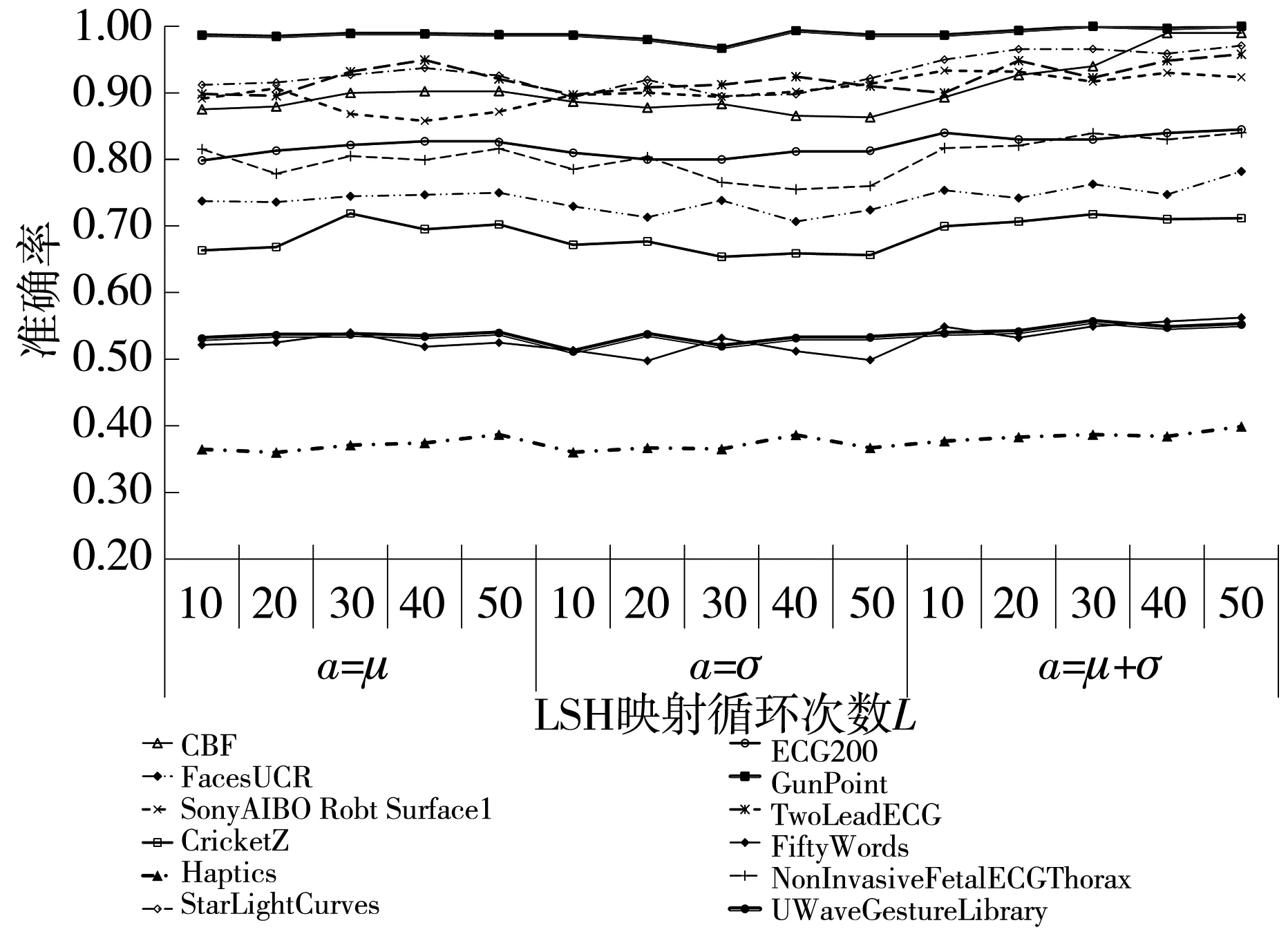
图 6 FastDTW-LSH方法精度在不同统计量下随L变化的曲线Fig.6 The curve of FastDTW-LSH algorithm accuracy with L under different statistics
由图 6 可以看到,在同一统计量定义的阈值下,FastDTW-LSH方法筛选出来的shapelets分类准确率总体随L变化的趋势不明显,在L=40后准确率基本保持稳定; 在不同统计量定义的阈值下,FastDTW-LSH方法筛选出来的shapelets分类准确率有所不同,在统计量μ+σ下的分类准确率比其他两个统计量下的更高,筛选出来的shapelets质量优于其他两个统计量下的筛选结果,因此,选用μ+σ作为阈值参数a的定义.
由于L=40后准确率曲线基本保持稳定,为了选取最佳的循环映射参数L,对各数据集进行了耗时实验,实验结果如图 7 所示.随着参数L的不断变化,算法耗时整体呈现减小趋势,L=55左右算法耗时基本保持稳定;L=60左右小数据集上耗时呈现一定上升趋势.所以,参数L的最佳值选取55.

(a) 小规模数据集
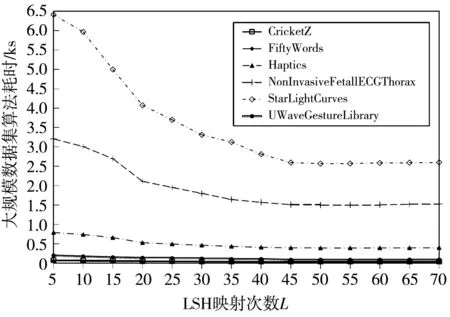
(b) 大规模数据集图 7 FastDTW-LSH方法耗时随L变化的曲线Fig.7 The curve of FastDTW-LSH algorithm time consuming with L
3.2 FastDTW-LSH算法评估
3.2.1 与LSHST算法对比
为了评价FastDTW-LSH方法较LSHST方法的优越性,结合不同分类器分别对表 2 所示12个数据集进行分类并计算平均分类精度,结果如表 3 所示. 由表 3 可以看到,在时间消耗上FastDTW-LSH方法相比LSHST有一定程度的增加,但是FastDTW-LSH方法结合分类器RandomForest,RotationForest,SVML的平均分类精度在8个数据集(见表 3)上的表现优于LSHST方法,尤其在CricketZ和FiftyWords数据集上分别最高提升了11.57%和9.16%.
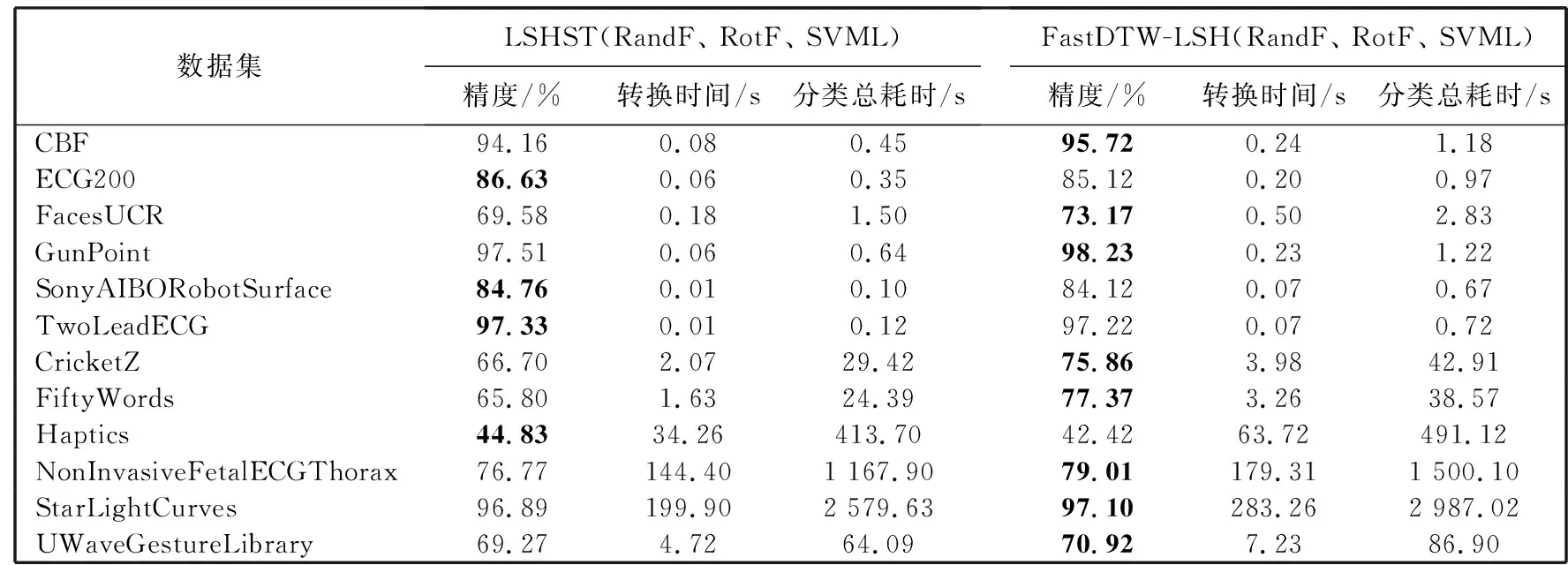
表 3 FastDTW-LSH与LSHST算法分类精度、shapelets转换耗时和分类总耗时比较Tab.3 Comparison of accuracy, shapelets time consuming and total time between FastDTW-LSH and LSHST algorithms
3.2.2 与经典分类算法对比
与经典分类算法FS[7]、LS[17]、COTE[22]进行比较,分析FastDTW-LSH算法分类结果的优越性. FastDTW-LSH方法结合3.2.1节实验中所提的分类器计算分类准确率和耗时,所得实验结果如表 4 所示. 可以看到,虽然FS方法利用SAX方法降低了时间消耗,但是一定程度上牺牲了分类精度; LS、COTE方法虽有较高的分类精度,但因时间消耗太大而不可取. 相比经典分类算法,本文方法FastDTW-LSH二者兼得,在有着远小于经典分类方法LS、COTE的时间消耗的同时,其分类精度在6个数据集(见表 4)上也表现出良好的优越性.
由表 4 可看出,FastDTW-LSH方法优先适用于高维海量序列数据,在降低时间消耗的同时,提升了分类准确率,即使对于较小数据集CBF、ECG200和GunPoint,本文方法相比其他方法也有较强的竞争优势.

表 4 FastDTW-LSH与经典分类算法分类精度、耗时比较Tab.4 Comparison of classification accuracy and time consuming between FastDTW-LSH and classic classifical algorithms
综上所述,FastDTW-LSH方法具有普适性,在保证一定时间消耗的同时可以提高shapelets筛选的质量,有卓越的分类效果.
4 结 论
本文提出一种基于FastDTW-LSH的shapelet筛选方法. 首先,采用局部敏感哈希利用空间投影的近似相似性快速将子序列映射到各个哈希桶中; 其次,通过FastDTW距离快速筛选出各桶中具有极大不相似性的子序列,以便作为下一次过滤的候选集,经过多次过滤筛选得到最终的shapelets; 最后,通过shapelets转换技术结合分类器进行分类.
与传统方法相比,该方法能够明显降低时间消耗,提高分类效率,在轴承故障诊断、网络故障诊断、电厂数据稳定性评价等序列数据分类方面具有极大应用前景. 在下一步的研究中,应侧重于优化局部敏感哈希函数,使用更适用于时间序列相似性判断的DTW距离来进行哈希映射,在进一步缩短耗时的同时明显提升分类精度.
猜你喜欢
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
现代英语(2021年18期)2021-11-22
计算机仿真(2021年6期)2021-11-17
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
智能计算机与应用(2020年4期)2020-08-31
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
