
混合采样与PSO优化的随机森林组合模型及应用
2022-05-07 02:24郑列,鲍佳
湖北工业大学学报 2022年2期
郑 列, 鲍 佳
(湖北工业大学理学院, 湖北 武汉 430068)
财务困境预测模型最初主要是Beaver[1]的单变量判别模型、Altman[2]的多变量判别分析模型和Ohlson[3]的Logistic模型等。随着机器学习和数据挖掘逐步运用到财务困境的预测中,Min等[4]对比多个模型发现支持向量机效果更优。黄衍[5]针对制造业上市公司研究了支持向量机、BP神经网络和随机森林模型,最后发现三者中随机森林最优,且在不平衡问题中基于投票阈值调整的随机森林模型相对更优。张娜[6]基于BP神经网络、决策树和支持向量机分别构建财务预警模型,设计集成Ada Boost_BP、Ada Boost_DT以及Ada Boost_SVM等3个财务预警分类器,结果发现Ada Boost_DT的效果最优。陈子之[7]针对地方政府债务,采用梯度提升树构建预警模型,发现该算法优于BP神经网络。史立新[8]研究上市公司财务预警时将xgboost与随机森林的组合模型、支持向量机、logistic回归模型、ANN模型对比,证明组合模型拥有更优的性能。
针对财务困境公司与财务正常公司占比差别大、数据不均衡的情况,研究者开始探究基于不均衡数据的财务困境预测问题。商志明[9]从非平衡角度出发集成Bagging、SMOTE和SVM构建SB-SVM预警模型;孟杰[10]基于不平衡数据样本对比分析Logistic回归等4类模型,结果表明随机森林集成学习的预测效果更好;李扬[11]应用加权正则化支持向量机构建的财务困境模型解决了非平衡数据问题和财务指标选择问题。现阶段对不均衡问题的研究大多从数据层和算法层展开。数据层主要是对数据进行过采样或欠采样处理,以SMOTE系列为代表,涵盖SMOTE[12]、Borderline-SMOTE[13]和Safe-level-SMOTE[14],算法层是基于代价敏感和集成学习。本文采用改进的SMOTE算法和随机欠采样组合的新混合采样对数据进行平衡处理,再对新训练集建立随机森林模型,并与Bagging、SVM和BP神经网络进行对比,采用粒子群算法对随机森林模型进行参数调优,以达到对财务困境的精准预测。
1 算法介绍
1.1 SMOTE算法
SMOTE算法主要是通过增加少数类样本量以达到两类间的平衡,一般基于k近邻和线性插值方法,在距离较近的两个少数类样本之间插入新样本。其插值公式为:
(1)

1.2 K-means算法思想
K-means算法主要基于相似性原则,将相似度较高的对象分至同一类。其一般以距离为评价指标,对象之间间距越小相似度越高。算法流程如下:
Step 1 在训练集x(1),x(2),…,x(m)中随机选择k个类簇中心为z1,z2,z3,…,zk∈Rn;


Step 4 迭代2和3直至所有的类簇中心没有变化为止。其中,k为事先给定的聚类数,Cj为重新划分好的类簇,zj为每轮猜测的类簇中心。
1.3 基于K-means的混合采样算法
混合采样是融合过采样和欠采样以达到正负样本平衡的方法。混合采样不会造成大量的负样本特征丢失,在数据处理中也不会产生过多的噪声,能够有效提升正样本和负样本的分类正确率。对于SMOTE算法目前存在的边界模糊和合成样本质量不高的问题,先基于K-means算法思想对SMOTE进行改进[17],再与随机欠采样结合形成混合采样。
首先,找到少数类样本中大部分类的中心,在创建“新增少数类”的过程中,尽可能使新产生的样本向中心靠近,从而解决SMOTE算法在新生成样本时易边缘化的问题。由新合成数据代替原始少数类数据后,其分布上的改变将有助于最终分类性能的提升。算法如下:
Step 1 找到少数类样本的中心;利用统计软件SPSS中的K-means算法,将少数类样本进行K-means聚类,在分类结果中选择数目最多的一类作为少数类样本的中心,去除聚类数目较少的类簇样本,只保留数目最多的一类,其中心记作Xc;
Step 2 基于以下规则,对保留的少数类数据处理,得到“新增少数类”
pj=x+rand(0,1)·(Xc-x),j=1,2,…,N
(2)
其中,pj为生成的新增少数类样本,rand(0,1)为区间(0,1)内的任一随机数,x为第一步中保留的数目最多的少数类;
Step 3 用“新增少数类”代替原始数据中的少数类,再将获得的数据代入SMOTE进行过采样,对多数类选择合适的比例采用随机欠采样处理,得到最终的实验样本。
2 混合采样与PSO优化的随机森林组合模型
2.1 随机森林
随机森林[18]是由多个决策树模型h(X,θk),k=1,2,…,K组合的分类模型。在给定自变量X和决策树k时,每个基分类器通过投票得到最佳分类,k轮训练后得到分类模型序列为{h1(X),h2(X),…,hk(X)},再用它们构造一个多分类模型系统,最终结果以多数投票为准,随机森林的分类结果
(3)
其中:hi(x)代表单个决策树模型的分类结果;Y为分类目标;I(·)为示性函数。
2.2 粒子群算法PSO
粒子群算法[19]主要是通过个体信息的迭代寻找群体空间中最优解。算法中的每个粒子表示一个候选解,粒子依据适应度值搜索空间内最优的粒子,其搜索流程见图1。

图 1 基于随机森林的粒子群算法参数优化流程
假设种群个数为n,种群表示为X=(X1,X2,…,XD),空间内第i个粒子的位置为Xi=(xi1,xi2,…,xiD),速度为Vi=(vi1,vi2,…,viD),第i个粒子所寻找的当前最佳位置为Pi=(pi1,pi2,…,piD),其为局部最优值。所有粒子所寻找到的当前最佳位置为Pg=(pg1,pg2,…,pgD),其为全局最优值。
2.3 混合采样与PSO优化的随机森林组合模型
针对数据不均衡问题,采用混合采样对数据处理以达到平衡状态,再利用分类效果好的随机森林模型进行分类预测,随机森林中的参数问题采用粒子群算法进行优化,具体步骤如下。
Step 1 在原始不平衡数据的基础上,随机抽取70%作为训练集,其余30%作为测试集拟作样本预测。利用改进的SMOTE技术扩增训练集少数类样本,随机欠采样技术获取训练集多数类样本,使两者数量相等,总数大致为原始数量的1/2左右。
Step 2 将数量相同的多数类和少数类样本放在一起形成新的平衡训练集,利用随机森林模型对测试集分类预测。
Step 3 对于随机森林中的模型参数,通过粒子群算法不断迭代选择最优参数,输出模型最终的分类结果。流程见图2。
2.4 预测效果评价准则
2.4.1传统评价指标对于均衡的数据集,常以整体的分类误差为评价标准,但对于不均衡的数据集,则以F-value和G-mean来评估。
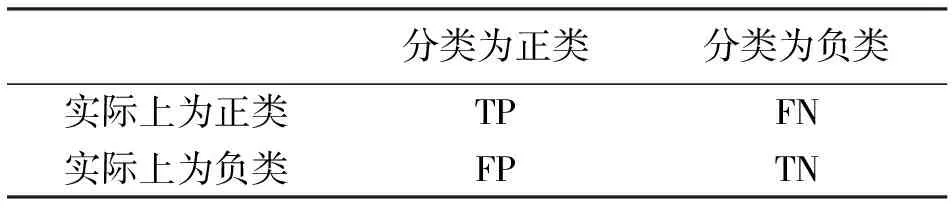
表1 分类结果
正类样本召回率
TPR=TP/(TP+FN)
(4)
负类样本召回率
TNR=TN/(TN+FP)
(5)
正类样本精确率
Precision=TP/(TP+FP)
(6)
F-value值
F=2·TPR·Precision/(TPR+Precision)
(7)
G-mean值
(8)
F-value值涵盖少数类样本的召回率和查准率信息,较为全面地反映了少数类样本的分类情况;G-mean值则包含了少数类和多数类样本的召回率信息。两类指标结合可综合反映模型的分类性能。
分类精度
(9)
AUC值[20]是ROC曲线与坐标轴围成的面积的大小。ROC曲线的横坐标为FPR,代表多数类样本中被预测错误的比率,即FPR=FP/(FP+TN);纵坐标为TPR,代表少数类样本中被正确预测的比率。AUC值越大表示ROC曲线越靠近左上方位置,模型分类效果越好。
2.4.2新评价指标考虑到分类模型的稳定性,本文在精确率、召回率和F-value评价指标的基础上,尝试以各类别样本量与样本总量之比代表样本的重要性,以各类别的分类效果与总体效果的差异代表分类效果的稳定性,引入谭章禄等人提出的三类评价指标平衡精确率(SP)、平衡召回率(SR)、平衡F-value(SF)[21]。

平衡精确率
(10)
其中,P1和P2分别代表第1和第2类的分类精确率,P代表总体样本分类精确率的宏平均。
平衡召回率
(11)
其中,R1和R2分别代表第1和第2类的分类召回率,R代表总体样本分类召回率的宏平均。
平衡F-value
(12)
其中,F1和F2分别代表第1和第2类的分类F-value,F代表总体样本分类F-value的宏平均。三类指标中的SP和SR分别衡量模型的查准率和查全率,SF是一种综合指标,指标值在[0,1]>内,其值越大表示模型性能越好。
3 实证分析
3.1 指标说明及数据预处理
为验证混合采样和粒子群算法优化的随机森林模型在财务困境预测中的效果,以巨潮资讯网2018—2019年中小板上市公司数据作为基础样本,将标注ST的公司数据作为正类样本,其余数据作为负类样本,以此为基础进行分析。指标说明[22]见表1。
对搜集到的数据进行Z-score标准化处理,消除指标量纲带来的影响[23],最终得到2006个样本,其中包含正样本142个,负样本1864个,不平衡率达到7.6%。从中随机抽取70%作为训练集,其余作为测试集以作样本预测。

表2 指标说明
针对不平衡数据,采用SMOTE算法与欠采样结合的旧混合采样和改进的SMOTE算法与欠采样结合的新混合采样分别进行处理。利用SMOTE时,直接对正样本进行过采样,对负样本按适当比例随机欠采样,使正负比接近1∶1,训练集数量接近600个,每轮重复100次计算指标平均值。利用改进的SMOTE时则在原始正类的基础上先创建“新正类”,用“新正类”代替原始正类之后,对“新数据集”进行同上的SMOTE过采样和随机欠采样处理,最终对比SMOTE系列和改进的SMOTE系列的分类情况。
3.2 模型结果与分析
在混合采样与PSO优化的随机森林组合模型中,参数部分给定种群个数初值n=20,迭代次数iters=50,学习因子c1=c2=1.5,速度限定横向和纵向移动的最大速度分别为4和2,权重ω=0.5,依据式(13)和(14)不断更新空间内的位置和速度[24],以达到适应度AUC最大:
(13)
(14)
其中,r1和r2是区间[0,1]内的随机数,针对参数ntree和mtry,范围分别限定在[100,500]和[1,17]内。
对不均衡数据集共构建包含对照组在内的10种模型:SMOTE+随机欠采样+Bagging(S_Bagging)、改进的SMOTE+随机欠采样+Bagging(KS_Bagging)、SMOTE+随机欠采样+SVM(S_SVM)、改进的SMOTE+随机欠采样+SVM(KS_SVM)、SMOTE+随机欠采样+BP神经网络(S_BP)、改进的SMOTE+随机欠采样+BP神经网络(KS_BP)、SMOTE+随机欠采样+随机森林(S_RF)、改进的SMOTE+随机欠采样+随机森林(KS_RF)、SMOTE+随机欠采样+粒子群算法优化的随机森林(S_PSO_RF)以及改进的SMOTE+随机欠采样+粒子群算法优化的随机森林(KS_PSO_RF)。将Accuracy、AUC、G-mean和F-value作为少数类分类性能的评价指标,绘制模型的结果对比情况如图3所示。

图 3 十大模型结果对比
图3中与由SMOTE和欠采样组成的旧混合采样处理过的数据相比,由改进的SMOTE算法和欠采样组成的新混合采样提高了Bagging、支持向量机、BP神经网络和随机森林模型对少数类的分类效果。4类模型在Accuracy、AUC、G-mean、F-value等指标上均有显著提升,大多数指标值经改进的SMOTE算法和欠采样处理后达到90%以上,其中随机森林的分类效果最优,经改进后大部分指标达95%以上。经观察,单独的Bagging、SVM、BP神经网络和随机森林发现模型的F-value都非常低,主要是由于这些模型自身对非均衡的分类问题敏感过度,从而导致少数类很难被正确预测,在经过改进的SMOTE和欠采样组成的新混合采样处理之后,整体的F-value都有很明显提高。
对比S_RF和S_PSO_RF可以发现,经过粒子群算法调参后,模型在目标AUC值提升的基础上,G-mean、F-value和整体Accuracy均有一定提升;对比KS_RF和KS_PSO_RF两类模型发现,除目标AUC值提升外,G-mean有小幅提升,Accuracy和F-value有微弱下降。由此表明,粒子群算法在样本数据质量不同的条件下调优效果不同,并且在提升目标AUC值的同时会提升G-mean,整个模型对少数类的辨认度也得到提高。从Accuracy、AUC、G-mean、F-value等4类指标整体来看,KS_PSO_RF模型在10种模型中的分类效果最优。
为深入研究改进的SMOTE算法及欠采样组成的新混合采样和粒子群算法对模型分类结果的影响,针对新混合采样和粒子群优化的随机森林组合模型,引入平衡精确率(SP)、平衡召回率(SR)、和平衡F-value(SF)等新指标对其进行评价。以SMOTE算法+随机欠采样+随机森林组合模型(S_RF)为对照组,基于Accuracy、AUC、G-mean、F-value值、SP、SR和SF等7类指标对改进的SMOTE+随机欠采样+随机森林(KS_RF)、SMOTE+随机欠采样+粒子群算法优化的随机森林(S_PSO_RF)和改进的SMOTE+随机欠采样+粒子群算法优化的随机森林(KS_PSO_RF)共4类模型进行指标层面的对比,以评价分类的精确性和稳定性。分别设定α=0(图4a和b)、α=1(图4c和d)和α=-1(图4e和f),基于3种调节系数绘制模型分类的2种代表情况如图4所示。
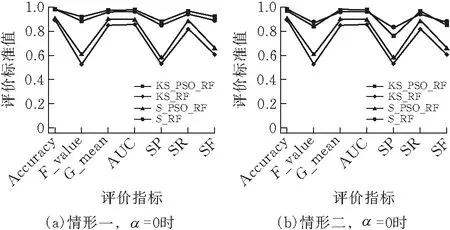
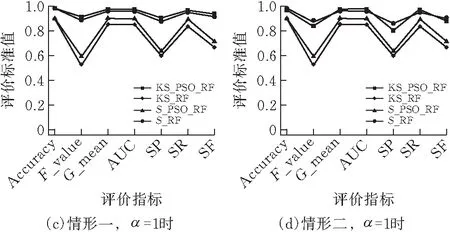

图 4 评价指标的评判结果
情形一 图4a、c和e代表SMOTE系列模型和改进的SMOTE系列模型两类经粒子群算法优化后,传统指标(Accuracy、AUC、G-mean、F-value)均有部分提升。
情形二 图4b、d和f代表SMOTE系列模型经粒子群算法优化后,传统指标(Accuracy、AUC、G-mean、F-value)均有部分提升,但改进的SMOTE系列模型仅AUC和G-mean提升,Accuracy和F-value均下降。
两类情形对比发现,情形二更能凸显粒子群算法的优化效果,粒子群算法基于适应度AUC值优化的目标,能使G-mean与AUC始终保持同向增长,表明多数类样本和少数类样本的召回率均得到提升,使得SR同步增长。
图4b、d和f都能展现出粒子群算法的优化效果,可以发现在不同模型下优化效果不同。在SMOTE系列模型中SP、SR、SF值均有提升,模型稳定性较高。在改进的SMOTE系列模型中,总体效果SP和SF下降,模型稳定性有微弱降低,但少数类的准确分类使得SR显著提升,特别是在图4f(α=-1)中,样本的数量分布对总体分类结果的影响被强化。同时,在图4中可以看出,相较于SMOTE算法和欠采样组合的旧混合采样,改进后的SMOTE算法与欠采样组合的新混合采样大幅提高了7类评价指标值。
4 结论
针对公司财务困境预测中常出现的数据不均衡问题,本文提出一种基于混合采样和随机森林的财务预警模型。首先利用基于K-means改进的SMOTE算法过采样增加少数类的样本数量,然后选择适当比例欠采样获得多数类样本以构建新的平衡数据集,在新的数据集上训练分类模型。对比由SMOTE算法和随机欠采样组合的旧混合采样和由改进的SMOTE算法和随机欠采样组合的新混合采样在不同模型中的表现,结果表明:在Bagging、SVM、BP神经网络以及随机森林模型中,新混合采样和随机森林的组合模型性能最佳;在组合模型的基础上,通过粒子群算法对模型参数进行优化,引入新指标SP、SR、SF对模型进行评价,本文提出的新混合采样和粒子群算法优化的随机森林模型(KS_PSO_RF)对少数类和整体都具有较好的分类性能。
猜你喜欢
现代装饰(2022年5期)2022-10-13
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
学苑创造·A版(2019年8期)2019-08-15
领导决策信息(2018年16期)2018-09-27
电子技术与软件工程(2018年12期)2018-02-25
人大建设(2017年10期)2018-01-23
分析化学(2018年12期)2018-01-22
数学学习与研究(2017年3期)2017-03-09
飞碟探索(2015年8期)2015-10-15
西南学林(2011年0期)2011-11-12
