
工控协议逆向分析技术研究与挑战
2022-05-09 05:03付安民季宇凯王占丰
计算机研究与发展 2022年5期
黄 涛 付安民 季宇凯 毛 安 王占丰 胡 超
1(南京理工大学计算机科学与工程学院 南京 210094) 2(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004) 3(南京莱克贝尔信息技术有限公司 南京 210007) 4(解放军陆军工程大学指挥控制工程学院 南京 210007)
随着工业数字化、网络化、智能化的快速发展,工业互联网已经成为国家先进制造的重要基础设施,其安全问题也逐渐受到重视,尤其是工业控制系统(industrial control system, ICS)安全已成为实施制造强国和网络强国战略的重要保障[1-2].然而,日益频发的ICS安全事件表明ICS已经存在大量安全漏洞和隐患[3-5],如2017年乌克兰、俄罗斯等多国的银行、电力、通信系统均遭受Petya勒索病毒袭击,2019年委内瑞拉遭受电网攻击,2021年伊朗国家铁路系统遭受网络入侵等.ICS通过专有的工业控制协议(简称“工控协议”)实现各组件间的通信,进而控制工控网络内的各种工控设备.然而,由于商业性和安全性等原因[6],大多数工控设备厂商都不提供公开协议文档,造成ICS中存在大量私有、非标准的工控协议[7],为ICS的网络行为管理、模糊测试[8]、入侵检测[9-11]带来了巨大挑战.
协议逆向工程(protocol reverse engineering, PRE)是指在不依赖协议描述的情况下,通过对协议实体的网络输入/输出、系统行为和指令执行流程进行监控和分析,提取协议语法、语义和同步信息,从而推断出未知协议的消息格式和状态机模型的过程[12].最初的PRE技术完全基于人工分析的方式进行,需要耗费大量时间和精力.而后由于PRE在网络入侵检测、深度数据包分析、模糊测试等领域应用效果显著,逐渐引发众多学者研究,PRE技术也因此得到迅速发展,由最初的“人工分析”过渡到目前的“自动化分析”,并逐渐发展成2个分支[12-13]:1)基于程序执行的协议逆向分析技术,通过监视协议实体对消息的处理过程以及各消息片段的使用方式,获取协议的结构及字段语义,比如2007年Caballero等人提出Polyglot[14],基于动态污点技术完成对协议消息的字段划分;2)基于报文序列的协议逆向分析技术,通过对网络内的目标报文流量进行分析,获取协议的结构及字段语义,并且随着自然语言处理、机器学习等人工智能技术的不断成熟,这类协议逆向分析技术也得到了迅速发展[15],不仅研究对象从文本协议扩展到二进制协议,而且方法类型也不断丰富,比如基于序列比对的Discoverer[16],NetZob[17],MSA-HMM[18]等方法,基于概率模型的Biprominer[19],ProGraph[20],HsMM[21]等方法,基于频繁集的AutoReEngine[22],SPREA[23],HIERARCHICAL CSP[24]方法,以及基于语义分析的FieldHunter[25],WASp[26]等方法.此外,协议逆向分析方法也从最初的字段划分和结构识别逐渐向语义推断、状态机重构拓展,如PETX[27],ReverX[28],BFS[29]等方法.然而,相比于互联网系统,ICS对工控设备的操作精度和响应速度通常要求更高,但那些底层工控设备的计算性能却相对有限,难以处理较为复杂的工控指令和数据[1,3].因此,为了保证ICS的实时性和稳定性,工控协议通常采用二进制编码,并且功能相对固定,结构也比较简洁,甚至只通过一个或几个比特来表示相应功能,导致目前大多数针对互联网协议的逆向分析方法无法直接适用于工控协议[12,30],但工控协议的这些特征也为其逆向分析提供了一定依据.
结合工控协议的共性特征,近几年不断有学者基于互联网协议逆向分析技术,提出针对工控协议的逆向分析方法.一方面,部分学者基于程序执行对工控协议进行逆向分析,比如2018年魏骁等人[30]和Chen等人[31]分别都借助污点分析技术,实现对工控协议的字段划分和结构识别,并具有较高的识别准确度,但由于这类方法对ICS的稳定性影响和可控性要求都比较高,且实施和分析难度也较大,目前该方向的研究仍相对较少.另一方面,部分学者基于报文序列对工控协议进行逆向分析,主要分为2类方法:1)主要针对互联网协议逆向分析技术进行改进或重新设计,以实现工控协议的自动化逆向分析.比如Wu等人[32]通过pair-HMM方法对序列比对算法进行改进,以完善相邻字段的对比,提高工控协议格式提取的效率和准确度;Wang等人[33]针对基于N-gram模型的协议逆向分析方法进行改进,提出V-gram模型将协议字段识别精度提高到“半字节”.然而,这类方法虽然都能够实现工控协议格式的自动化提取,但只有较少方法能够进一步完成工控协议字段的语义推断.2)借助专家的先验知识,对现有公开工控协议的关键字段特征进行分析,归纳出相应字段的“启发式规则”,以提前实现对部分关键字段的识别,比如MSERA[34],IPART[35],IPRFW[36]等方法.这类人机协同型方法不仅能够进一步提高工控协议格式提取的效率和准确度,而且还有利于工控协议字段的语义推断.
综上所述,本文将系统性研究和分析目前工控协议的逆向分析技术,主要将其分为两大类:基于程序执行的分析技术和基于报文序列的分析技术.再重点根据“人机参与程度”将基于报文序列的方法分为全自动型方法和人机协同型方法.本文具体包括4部分内容:
1) 重点针对2种典型工控协议Modbus和DNP3的结构特征进行详细分析,进而归纳工控协议的共性特征;
2) 阐述基于程序执行和基于报文序列这2种工控协议逆向分析框架的基本流程与特点,并从多个角度全面讨论各自框架中互联网协议逆向分析方法和工控协议逆向分析方法的区别;
3) 分别针对基于程序执行和基于报文序列的工控协议逆向分析方法展开深入剖析,并重点从人机协同程度和协议格式提取方式这2个角度,对基于报文序列的工控协议逆向分析方法进行分类讨论与对比分析;
4) 讨论和分析目前各种工控协议逆向分析方法的特点和不足,并进一步分析和展望工控协议逆向分析技术的未来可能发展方向.
1 工控协议分析及其特征
相比于互联网协议,虽然工控协议目前仍没有统一的设计规范,但基于ICS的高精度、高实时性和高可靠性的要求,以及底层工控设备相对有限的计算性能,通常工控协议的结构更加简明,功能更加固定[35-36].因此,针对工控协议的典型特征进行分析和归纳,将非常有助于工控协议的逆向研究[37].
1.1 典型工控协议分析
目前比较常见的公开工控协议主要包括:工控标准协议Modbus、工业以太网协议Ethemet/IP、输配电通信协议IEC104/IEC61850系列协议簇、分布式网络协议DNP3和开放式实时以太网协议EtherCAT[38]等.本节将重点针对Modbus[39]和DNP3[40]这2种经典工控协议的结构特征进行分析.
1) Modbus
Modbus是1979年Modicon公司为可编程逻辑控制器(PLC)通信而提出的一种开放串行通信协议,由于其在工业网络中易于部署和扩展,目前被广泛采用,并成为工业领域通信协议的业界标准[39].
Modbus协议是一种基于主/从架构的协议,用于Modbus节点之间带有发送请求和读取响应类型的消息通信,在一个数据链路上通常只能处理247个地址,限制了可以连接到主控站点的从机数量(Modbus/TCP除外).Modbus信息都以“帧”的方式传输,每个信息帧有确定的起始点和结束点,便于接收设备识别,但目前几乎所有的Modbus实现都是官方标准的变体,它们在开始/结束标志、校验模式和格式等方面都存在一定差异,也进而导致不同供应商的设备之间可能无法正确通信[41].目前常见的Modbus协议变体主要包括3种:Modbus RTU,Modbus ASCII和Modbus/TCP.其中,Modbus/TCP基于TCP/IP开发,工业设备通过以太网进行数据交互,其数据帧格式与RTU非常类似,并去掉其中的校验码,因此此处仅重点介绍Modbus的RTU和ASCII协议.
① Modbus RTU
Modbus RTU是一种采用二进制编码的Modbus实现方式,结构相对紧凑.在RTU模式下,整个信息帧必须作为一个连续的流传输,并且不同的消息帧之间至少需要相隔传输3.5 B所需要的空闲时间,如果小于该时间,接收设备会将此消息作为前一信息帧的延续.Modbus RTU采用CRC校验码,以保证消息传输的可靠性.如图1所示,在格式方面,Modbus RTU信息帧主要包括4个字段:设备地址、功能码、数据和CRC校验字段.

Fig. 1 Modbus RTU protocol structure图1 Modbus RTU协议结构
其中,起始位和结束位分别表示3.5 B以上的消息间隔时间;设备地址表示从机地址,即需要对该消息进行回应的从机,其他非该地址的从机可以不回应;功能码表示具体操作,比如“06”代表“写操作”;数据代表需要操作的具体数据;CRC检验用于检验该消息在传输过程中是否出错,主要根据前3个字段计算相应的CRC检验码.
② Modbus ASCII
Modbus ASCII是一种人类可读的、冗长的表示方式.由于国内工业控制中很少采用ASCII码作为标准,因此Modus ASCII在国内的工控领域运用很少.在Modbus ASCII模式下,每个字节都被拆分成2个ASCII字符即2 B进行发送,因此其发送量是RTU模式的2倍.Modbus ASCII消息帧通过特定字符判定起始位置,以英文冒号“:”(0x3A)表示开始,以“回车”(0x0D)和“换行”(0x0A)表示结束,各占1 B和2 B .最后采用LRC检验,保证消息传输的可靠性,Modbus ASCII的详细结构如图2所示.其中,数据数量表示后续数据字段中的字节个数,其他字段含义和RTU模式类似.
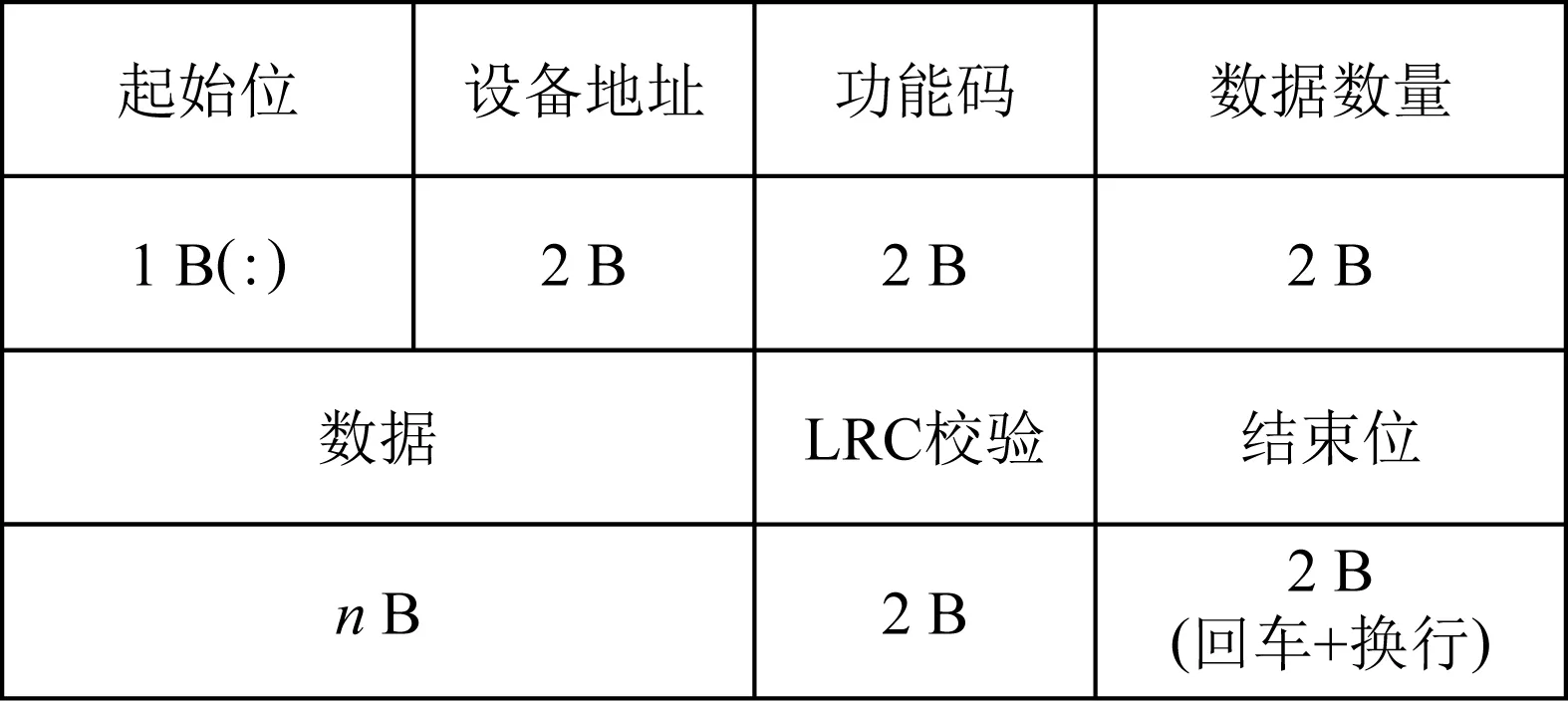
Fig. 2 Modbus ASCII protocol structure图2 Modbus ASCII协议结构
2) DNP3
DNP3协议是一种分布式网络协议,解决了SCADA行业中协议混杂、没有公认标准的问题.SCADA可以通过该协议与主站、RTU及IED进行通信,针对电磁干扰、元件老化等恶劣环境具有一定可靠性,并通过CRC校验保证数据的准确性.目前DNP3协议已被广泛应用于各类ICS中,如电力、水处理等行业[40].
DNP3协议完全基于TCP/IP,并具有类似OSI的协议栈结构[42],主要包括数据链路层、传输控制层和应用层,且各层数据单元的结构特征基本类似.因此,此处仅以数据链路层的数据单元为例,分析DNP3协议报文的结构特征,如图3所示.

Fig. 3 Data unit structure of data link layer in DNP3 protocol图3 DNP3协议中数据链路层的数据单元结构
其中,起始位表明数据开始的起始字节,固定为0x05 0x64;控制字段代表该消息的控制信息,精确到1 b,其详细结构如图4所示.
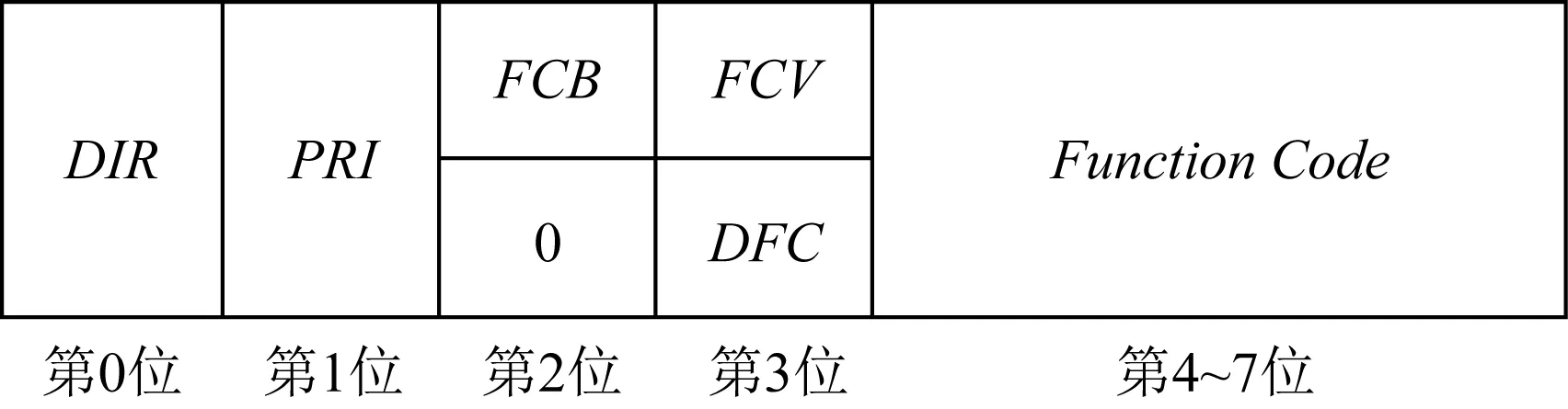
Fig. 4 DNP3 control field structure图4 DNP3控制字段结构
第0位:方向(direction,DIR).表示发送的方向.
第1位:源发标志位(primary,PRI).表示发送设备是主设备还是从设备,其中1表示主设备,0表示从设备.
第2位:帧的计数位(frame count bit,FCB).用于纠错,如果是response则为保留位.
第3位:帧计数有效位(frame count valid,FCV).表示FCB是否有效.如果FCB=0,表示FCB未开启;如果是response则为数据流控制位(data flow control,DFC),表示数据链路层是否发生缓冲区溢出.
第4~7位:功能码(FunctionCode).根据主从设备,代表不同含义.比如,对于主设备,0代表链路重置;但对于从设备,0代表同意.
1.2 工控协议特征
通过对Modbus RTU, Modbus ASCII和DNP3等典型工控协议的结构特征进行分析可知,目前这些工控协议虽然还没有统一的设计规范,但在编码、结构、周期性等方面都存在一些共性特征[43],主要包括7方面:
1) 二进制编码.为保证ICS的高实时性和可用性,工控协议通常不加密,大多数都采用二进制编码,少量采用ASCII进行编码.
2) 结构简明.即使部分工控协议存在协议栈的多层结构,如DNP3,S7Comm协议等,但每一层协议的数据报文结构都较为简明,功能相对固定,长度比较短,总体呈现一种扁平化的结构,只包含头部和数据,并且各字段之间没有额外的关键字或分隔符.
3) 字段精度较细.工控协议字段的划分颗粒度通常较细,虽然字段长度通常为一个字节的整数倍,但字段内的功能划分可能会精确到比特级,比如DNP3的控制字段.

Fig. 5 Framework of industrial control protocol reverse based on taint analysis图5 基于污点分析的工控协议逆向框架
4) 周期性强.工控协议报文传输通常都具有较强的周期性,特别是交互信息和控制信息,并且同类型协议报文在长度和格式方面存在相似性.
5) 起始标志明显.工控协议数据帧具有明显的起始标志,通常采用时间间隔或者标志位等方式.
6) 差错校验.为了保证数据帧传输的正确率,大多数工控协议都存在差错校验字段,通常采用CRC或者LRC校验.但部分基于TCP/IP以太网的工控协议通常会采用TCP/IP和链路层校验机制来校验分组交换的准确性,如Modbus/TCP.
7) 状态机简单.ICS中通常是主机发送命令,从机响应并执行命令,通信模式较为简单,因此,工控协议一般只有简单的状态机.
针对工控协议的这些共性特征,一方面,可以基于互联网协议的逆向分析方法,进一步改进或重新设计针对工控协议的自动化逆向分析方法;另一方面,也可以通过专家分析,归纳工控协议各种特征字段的启发式规则,以进一步提高工控协议的逆向分析效果和准确性.
2 工控协议逆向分析框架
工控协议逆向分析技术作为近几年协议逆向技术在工控领域的具体应用[44],几乎没有经历最初的基于人工分析的阶段,目前主要分为2种方式:基于程序执行和基于报文序列的工控协议逆向分析技术[15,45].
2.1 基于程序执行的分析框架
工控程序执行期间,协议报文中不同字段通常会被各自的函数调用,并且相同函数通常也只调用相同字段的数据.因此,基于程序执行的工控协议逆向分析技术可以通过跟踪并分析目标工控协议程序执行期间函数堆栈、指令序列、数据、寄存器等信息的变化情况,完成工控协议的字段划分和语义推断[46],而工控协议的结构简明、周期性强等特征也更加有利于这类方法的实施.
目前针对工控协议程序的分析主要借助污点分析思想实现,并分为静态污点分析和动态污点分析,它们的区别主要在于是否需要运行程序.前者可以不运行程序,仅需要对程序源代码进行分析[47];而后者需要运行程序,通过调试、代码注入等方式[48]对目标程序进行分析[49].但是由于工控程序源代码通常较难获取等原因,目前大多数都是借助动态污点分析实现对工控程序函数、指令和数据的跟踪与分析[50],主要分为目标监控、目标跟踪与分析和协议推断3个阶段[51],如图5所示.首先,确定可监控的目标协议程序,将其二进制程序或协议报文作为监控目标;然后,通过动态污点分析方法与插桩技术跟踪并记录目标程序运行期间的函数、指令和字段数据的执行轨迹;最后,结合它们之间的“共现”情况,比如,某些协议数据字节在哪些函数中出现或者某些函数的二进制指令调用过哪些协议字节,进而推断出工控协议字段的边界,并结合工控协议字段的特征,进一步完成工控协议报文的格式提取、语义推断及状态机重构.

Table 1 Comparison of Different Types of PRE Methods Based on Program Execution
然而,这类基于程序执行的分析技术要么需要获取工控执行程序的源代码,要么需要对工控程序进行反复运行与调试.因此,相比于互联网系统,对具有高可靠性、高稳定性和高实时性等要求的ICS来说,运用这类分析方法通常都难以实现.表1分别从5个角度将其与同类型的互联网协议逆向分析技术进行对比.
1) 在协议程序获取难度方面.由于部分基于程序执行的方法需要对执行程序的二进制源代码进行分析,因此相比于互联网应用程序,ICS的程序执行文件不仅更加难以获取,而且各种二进制程序文件格式也不统一,还需要做进一步兼容.
2) 在目标程序可控程度方面.由于目前互联网协议早已在各种轻量级且相对灵活的应用程序上成熟运行,而工控协议主要应用于中大型且较为专业的ICS中,因此,相比于互联网系统,这些ICS更加难以控制.
3) 在对系统稳定性的影响方面.相比于互联网应用程序,ICS通常要求更高的可靠性、稳定性和实时性,因此针对目标程序的反复调试更容易对工控程序的稳定性等造成影响.
4) 在执行过程监控难度方面.相比于ICS,不仅互联网设备的软硬件支持比较完善,而且针对互联网程序执行过程监控的工具和手段也更加全面、成熟,所以互联网程序的执行过程更易于监控.
5) 在指令序列分析难度方面.相比于互联网协议,工控协议具有结构简明、周期性强、状态机简单等特点,所以工控协议指令序列更易于分析.
综合以上对比分析可以明显看出,相比于互联网协议,虽然基于程序执行的工控协议逆向分析方法能够准确监控指令执行过程中函数与数据调用以及内存变化等情况,且具有较高的识别精度与准确度,但是该类方法通常需要获取工控程序源代码或反复调试程序,比较难以实施.因此,目前针对该方向的研究并不是很多,该类方法主要应用于一些小型的轻量级ICS.
2.2 基于报文序列的分析框架
基于报文序列的工控协议逆向分析技术主要针对工控协议通信实体间的网络报文流量进行分析,重点结合工控协议的特征,通过序列比对、聚类等算法完成协议的格式提取等操作.由于这类方法仅需要收集和分析实体间的通信流量,不仅易于实施,而且对目标系统的稳定性等影响都比较小,因此成为目前研究较多的方法.
该类技术的框架流程基本类似于互联网协议逆向分析技术[52],但为了更好地适用于工控协议,部分学者将工控协议的共性特征引入到原有的互联网协议逆向分析框架,改进或重新设计了工控协议逆向分析的部分环节(如格式提取),形成一种“全自动型”的工控协议逆向分析技术,具有较高的自动性和通用性.而另一部分学者基于公开工控协议中各种关键字段的特征,归纳出相应的“启发式规则”,并通过“人工干预”的方式提前识别私有工控协议中的部分关键字段,以进一步提高后续逆向分析环节的效率和准确率,进而形成一种“人机协同型”的工控协议逆向分析技术.但值得注意的是,这2类技术都将研究重心集中在工控协议的“格式提取”阶段,特别是关键字段的划分,因为该阶段的准确性直接关系到后续“语义推断”和“状态机重构”的准确性[53].
基于报文序列的工控协议逆向分析技术主要包括输入预处理、格式提取、语义推断和状态机重构4个阶段[15],其中,格式提取可以进一步分为字段划分和结构识别.具体框架流程如图6所示.
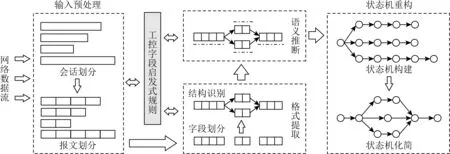
Fig. 6 Framework of industrial control protocol reverse based on packet sequence图6 基于报文序列的工控协议逆向框架
第1阶段是输入预处理.首先根据目标协议实体特征对网络流量数据进行过滤,将其划分为不同的会话;然后再结合工控协议的基本特征(如报文长度、报文相似度等),对目标报文序列进行初步聚类,得到多组报文序列集合.
第2阶段是格式提取.主要包括字段划分和结构识别2个步骤.首先针对每组同类型的报文序列集合,结合工控协议关键字段的特征,使用序列比对、统计分析、概率模型、深度学习等算法,完成工控特征字段的划分;再重点通过各种聚类算法,完成工控协议的结构识别.
第3阶段是语义推断.针对每个聚类中同一种协议结构,结合工控协议各种关键字段的特征(如位置、长度、数值、熵等)和上下文信息,推断相应字段的语义.因此该阶段通常要求对工控协议的应用背景和设计规范等先验知识具有一定的了解,但目前工控协议领域仍缺少统一的设计规范,并且各工控厂家很少公开各自的协议文档,导致没有足够的先验知识,使得语义推断仍然是工控协议逆向分析的难点.
第4阶段是状态机重构.消息数据帧中通常存在一些能够反映消息状态的状态字段,根据不同消息的状态字段取值和各类消息之间的顺序,初步完成状态机构建,随后再进一步完成状态机化简.但是一方面由于该阶段比较依赖格式提取和语义推断的结果,另一方面由于大多数工控协议只有简单的状态机,因此目前针对工控协议状态机重构的研究也比较少.
基于报文序列的协议逆向分析技术通常对报文样本的覆盖率和协议规范等先验知识具有一定的要求,因此,对于稳定性较高且缺少协议设计先验知识的ICS来说,针对工控协议进行逆向分析仍具有一定难度.表2分别从5个角度将其与同类型互联网的协议逆向分析技术进行对比.
1) 在报文样本覆盖率方面,ICS通常具有较高的稳定性和可靠性,因此一些特殊的异常流量通常较难收集,如系统故障或重启等指令信息,并且人为触发的代价比较大.而互联网系统往往对程序的稳定性与可靠性要求较低,通过人为触发等方式可以收集到更加全面的报文样本,具有比工控协议更高的样本覆盖率,更加有助于协议逆向分析.
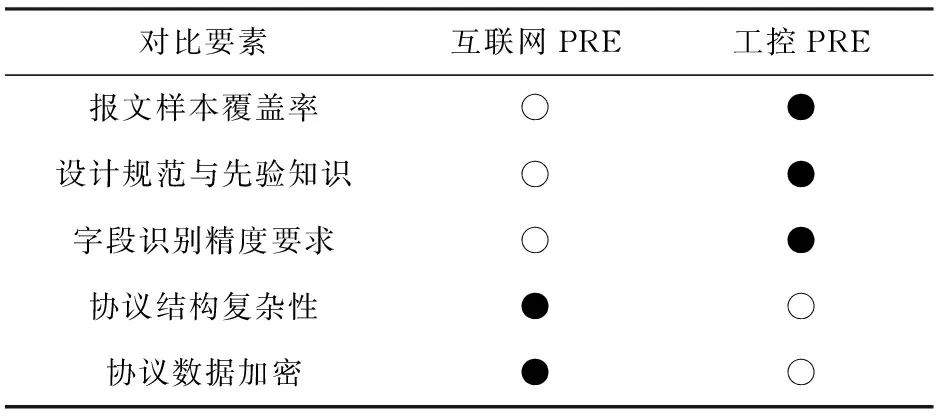
Table 2 Comparison of Different Types of PRE Methods Based on Packet Sequence
2) 在协议规范和先验知识方面,目前互联网协议已经具有统一的协议规范和标准,并且大多数互联网协议也都是公开的,如IP,TCP等协议,为互联网协议逆向分析提供了较多的先验知识.而目前各工控设备厂商基于安全性和商业性等考虑,大多数都自行设计各自的工控协议,不仅没有统一的工控协议规范,而且也不对外公开,导致工控协议的先验知识相对较少,远不如互联网协议.
3) 在字段识别精度要求方面,大多数互联网协议(含二进制协议)的字段精度为字节,一个字段通常需要使用多个字节表示.然而,由于工控硬件和网络等性能通常都相对有限,而ICS又具有较高的实时性等要求,导致工控协议的字段划分需要更加精细,通常为1个或几个比特,这为工控协议逆向分析提出了更高的识别精度要求.
4) 在协议结构复杂性方面,由于工控设备通常只需要高效地完成各自指定的操作,功能相对单一,且重复性较高,因此,相比于互联网协议,大部分工控协议都具有结构简明、周期性强和状态机简单等特点,非常有利于其逆向分析.
5) 在协议数据加密方面,相比于开放的互联网环境,工控网络通常比较封闭,所以基于安全性考虑,目前很多互联网协议都存在加密现象,但针对工控协议的加密现象仍比较少,这比较有利于工控协议的逆向分析.
综合以上对比分析可以明显看出,在样本覆盖率、协议规范与先验知识和字段识别精度方面,互联网协议的逆向分析都比较有优势,而工控协议的逆向分析仅在协议结构复杂性和协议数据加密方面具有一定优势.因此,目前大多数基于报文序列的工控协议逆向分析方法都主要结合工控协议的结构特征进行设计.
此外,表3重点针对工控协议的不同类型协议逆向分析技术进行对比,结果表明:仅在识别精度与准确度方面,基于程序执行的工控协议逆向分析技术具有较好的性能;在方法实施难度、对系统影响和自动化程度方面,基于报文序列的工控协议逆向分析技术都具有明显的优势.
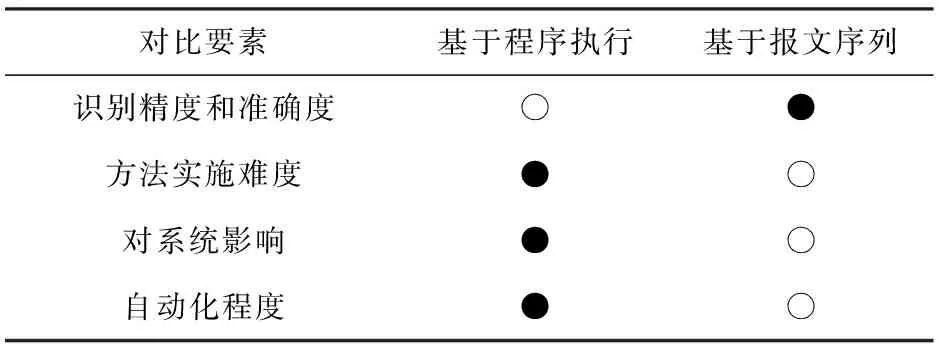
Table 3 Comparison of Different Types of PRE Methods for Industrial Control Protocols
2.3 小 结
本节重点阐述了基于程序执行和基于报文序列这2类工控协议逆向分析框架的基本流程与特点,并从多个角度将工控协议逆向分析技术与同类型的互联网协议逆向分析技术进行对比分析,总结各自的优势和劣势.其次,本节针对工控协议逆向分析技术,进一步剖析基于程序执行和基于报文序列这2类分析技术的优势和劣势.可以明显看出基于报文序列的逆向分析技术更加易于实施,且对ICS影响较小.因此目前针对该类技术的研究比较多,并旨在进一步提高对工控协议的识别精度和准确度.
3 基于程序执行的工控协议逆向
根据第2节的分析,基于程序执行的工控协议逆向分析技术通过跟踪并分析目标工控程序执行期间指令序列、数据、寄存器等信息的变化情况,实现工控协议的格式提取和语义推断,并且此类大多数方法都是借助污点分析的思想,如Polyglot[14],AutoFormat[54],Prospex[55]等.
2018年魏骁等人[30]提出了一种基于静态二进制分析的工控协议解析方法,将污点分析思想应用于静态二进制分析过程[47,56],主要包括数据预处理、交叉引用分析、协议帧重构和语义提取4个阶段:1)读取IDA Pro反汇编后的汇编代码,并通过代码交叉引用和源于动态污点的数据交叉引用剔除与通信过程无关的函数;2)调用IDC函数,获取交叉引用信息和函数间的依赖关系,并推断函数类型;3)基于前一阶段推断结果,判断函数代码特征,完成对目标协议帧的重构与分类,形成记录初步字段结构和常量字段值的帧结构;4)针对各协议帧字段的特征,如校验域字段通常伴随大量移位运算,完成协议帧的语义信息提取.
2018年Chen等人[31]重点根据“相同协议字段的字节在内存中通常具有相同传播轨迹”的原理,提出一种自动识别工控协议字段边界的方法——AutoBoundary,借助动态污点分析的思想[49],对受污染的数据进行跟踪,并建立对应的内存传播(memory propagation, MP)树,以记录每个消息字节在传播过程中的内存变化轨迹,再引入分支贡献以量化MP树中不同长度分支的权重,对相同分支进行合并以压缩MP树,提高后续字段边界识别的效率.然后Chen等人结合分支中各节点的属性,通过基于节点的序列对齐算法计算不同MP树中各个分支间的相似度和各个MP树之间的相似度,以相邻2字节为对象,对所有消息字节进行聚类,划分为不同集群,而集群之间就是协议字段边界.
总体而言,目前基于程序执行的工控协议逆向分析技术仍然主要借助污点分析的思想对工控协议程序执行过程进行监控,重点分析程序执行过程中指令函数、字段数据和内存的变化情况,通过它们的共现、依赖等关系,不断推测工控协议字段的结构和语义,实现对工控协议的逆向分析.由于这类方法能够对工控程序的执行过程进行精确监控,所以通常都具有较高的准确性,并且相比于互联网协议,工控协议结构简明、周期性强和状态机简单等特点,也能进一步提高这类分析方法的分析效果.根据污点分析原理不同,目前这类方法主要分为基于静态污点分析和基于动态污点分析2种类型.其中,基于静态污点分析的方法[30]需要获取工控程序的源代码,仅以只读方式访问程序二进制文件,在保证不破坏ICS稳定性的前提下获取工控协议的语义,并具有针对性强、通用性好等特点,但对于安全性要求较高的工控程序来说,获取工控程序的二进制文件具有很大难度;而基于动态污点分析的方法[31]虽然不需要程序源代码,但对样本覆盖率具有较高要求,特别是一些异常样本(如重启、崩溃等),所以需要反复调试程序,这对ICS的稳定性和可靠性具有较大影响,因此只能适用于一些对稳定性和可靠性要求较低的小型ICS.因此,基于程序执行的工控协议逆向分析技术虽然具有较高的准确性,但实施条件通常较为严苛,特别是对于安全性、稳定性和可靠性要求较高的ICS,导致目前该方向的研究仍比较少.
4 基于报文序列的全自动型工控协议逆向
相比于基于程序执行的逆向分析技术,基于报文序列的逆向分析技术更易于实施,且对ICS的影响较小.因此部分学者将工控协议的共性特征引入现有的互联网协议逆向分析框架,并重点对“格式提取”环节进行改进或重新设计,使其更加适用于工控协议,形成一种全自动型的分析技术,完全通过机器或者仅通过少量的人工协助,完成对工控协议的逆向分析[57].本节主要根据格式提取方式的不同将其分为4类[15]:基于序列比对的方法、基于频繁集的方法、基于概率模型的方法和基于深度学习的方法.
4.1 基于序列比对的方法
针对工控领域中的无人机专用飞行控制协议,2017年Ji等人[58]重点结合飞行控制协议的结构特征和高实时性要求,定制了一种自动化逆向方法.首先,针对飞行控制协议结构简明,且关键字段和动态字段长度固定等特征,分别按照报文长度和相似度距离对消息进行聚类;然后,结合无人机的高实时性要求,以及动作执行与命令间隔时间基本一致的原理,通过各命令集群的累计误差分析飞行控制指令含义;再次,通过序列比对算法提取命令的结构格式,并推断各字段的语义;最后,通过校验字段通常位于报文末尾的特征,对比特级的校验字段位置进行推断,并提出一种校验值生成矩阵的方法,以验证所推断的校验字段的正确性.但是该方法存在一定缺陷,即在推断无人机飞行控制命令的含义时,要求终端无人机必须实时可见且完全可控,而该要求在一般中大型ICS中较难实现,因此本方法仅适用于完全可控的小规模ICS.
2019年Wu等人[32]发现工控协议每个字段不仅具有明显的字段边界和多样性特征,而且各自还彼此联系,该特性非常适用于隐马尔可夫(hidden Markov model, HMM)模型[59].因此,他们提出了一种基于pair-HMM的工控协议逆向分析方法,在格式提取阶段,通过pair-HMM对序列比对算法进行改进,以提高工控协议相邻字段间的比对效果,构造工控协议的格式模板,最后再合并高相似度的格式模板,生成更简洁的消息格式.此外,该方法完全兼容文本和二进制型的工控协议.
综上所述,文献[58]重点结合目标协议的结构特征,针对性地按照报文长度和相似度距离进行聚类,并结合目标协议的目标完全可控且行动与命令都易于捕捉的场景特征推断指令含义.该方法在针对指定的工控协议进行逆向分析方面具有较高的准确性,对校验字段的识别精度甚至达到比特级,但是其泛化能力较弱,通用性差.而文献[32]完全基于工控协议的共性特征,通过pair-HMM对序列比对算法进行改进,完善相邻字段的对比,以提高工控协议格式提取的效率和准确度,且具有较强的通用性,但精度方面未能达到比特级.
4.2 基于频繁集的方法
2016年Ji等人[60]提出一种无人机通信协议的关键字提取框架,通过多模式匹配算法提取数据帧中的频繁序列,并对具有类似频繁序列的数据帧进行聚类,且为提高识别精度,利用改进的AC算法[61-62]识别8位频繁序列;其次采用FP-Growth算法[63]分析频繁序列之间的潜在关系,重点基于支持度和置信度扫描频繁序列,获取其特征集合并构建条件FP树,以表示频繁序列之间的联系;最后利用关联规则完成无人机通信协议的关键词提取.
2020年Shim等人[64]提出了一个用于推导Modbus/TCP,Ethernet/IP等工控协议结构的方法.该方法考虑到消息的传输方向,包括请求消息和响应消息,采集并提取同一功能多次执行后的消息流量;再结合工控协议消息长度和消息相似性方面的特点,通过mean-shift算法对工控协议消息进行聚类,并使用连续序列模式算法提取相同类型消息的公共子串,获得每种类型消息的结构,进而推导各类型消息的执行顺序.
综上所述,文献[60]仅将重心放在工控协议的关键字提取上,而文献[64]不仅完成了完整的格式提取,并且在其会话分析阶段完成了对各类型消息执行顺序的推导,已初步涉及状态机重构,只是文献[64]并未对该阶段工作进行详细介绍.
4.3 基于概率模型的方法
2020年Wang等人[33]考虑到工控协议字段长度可能小于1 B,提出了一种基于Variable-gram(V-gram)的XGBoost工控协议逆向分析方法,以V-gram作为XGBoost模型的输入,实现对S7等工控协议的逆向分析[65].该方法首先通过渐进式多序列比对算法对原始消息进行聚类,先将字段比对精度预设为半字节,并标记各字段的位置信息;再不断合并相邻字段,实现消息序列的可变域和固定域分离,进而生成V-gram,以解决二进制特征识别中半字节型关键字识别效率低下的问题;最后,将V-gram作为XGBoost模型的输入,利用XGBoost模型提取S7等工控协议的特征词,并对数据包状态进行分类和标记,实现FSM模型的构建.但是,该方法对捕获消息的数量和多样性比较敏感.
2021年Ye等人[66]提出一种概率性的网络协议逆向方法——NETPLIER,将关键词识别问题表述为一个概率推理问题[67].首先,通过多重序列对齐算法将客户端与服务器端的消息划分成字段列表,并为每个候选字段引入一个随机变量来表示该字段成为关键字的概率;其次,基于每个候选字段对所有消息进行聚类,重点计算各集群的消息相似性约束、远程耦合约束、结构一致性约束、维度约束等,具体约束定义如表4所示,越符合这些约束,则表示该候选字段成为关键字段的概率就越大,最终选择概率最高的字段作为关键字;最后,基于所选择的关键字对消息进行聚类,进一步完成格式提取、语义推断和状态机重构.

Table 4 Constraint Definition
NETPLIER方法深度挖掘关键字背后的各种约束关系,以概率量化约束关系的强弱,进而判定该字段是否为关键字.此外,该方法能够兼容文本和二进制协议,且性能都优于或不差于各自方向的典型优秀算法.然而,NETPLIER方法在一定程度上也非常依赖真实的标记数据,如果没有这些正确标记的真实样本数据,也就无法准确判定聚类后的样本种类是否满足各种约束关系,也就无法通过约束力判断相应关键字的正确性.
综上所述,这2种基于概率模型的工控协议逆向分析方法都实现了完整的格式提取、语义推断和状态机重构等步骤.但是它们的实现原理却完全不同.文献[33]的方法与传统基于N-gram的协议逆向分析方法基本类似,如FieldHunter[25], IPART[35]和ProDecoder[68]等,都是通过相邻字节之间的共现概率完成关键字提取,但文献[33]将N-gram改进为V-gram,将字段识别精度由字节级提升到半字节级,再利用XGBoost模型提取工控协议特征词.而文献[66]以概率量化关键字背后的各种约束关系,并通过各类约束关系的强弱确定该字段是否为真正的关键字段,进而实现关键字的准确识别,为协议逆向分析的研究提供了一种新颖的思路.
4.4 基于深度学习的方法
随着深度学习技术的不断成熟[69],部分学者将其引入到工控协议逆向分析领域.2020年Zhao等人[70]针对目前私有工控协议格式分析方法存在“通用性较弱、协议字段特征分析主观性较强”等问题,提出了一种基于长短期记忆-全卷积神经网络(long short-term memory fully convolutional neural network, LSTM-FCN)的工控协议逆向分析方法,基于时序特性对Modbus, S7Comm等工控协议字段进行识别,具有较高的通用性,更避免了人为主观因素的影响.
该方法首先将捕获的公共和私有工控协议数据按捕获时间排序,对同一字段的数据进行合并、排序,形成各字段的时间序列数据,其中,采用“数据编码”方法以避免数值特征对时间序列数据时序特征的影响;然后采用LSTM-FCN模型[71]对各字段时间序列数据的分类结果和格式特征进行不断学习,该模型主要包括2部分:全卷积神经网络(fully convolutional neural network, FCN)和长短期记忆(long short-term memory, LSTM),它们同时对输入数据进行处理,并将各自输出拼接到Softmax以完成分类,模型结构如图7所示;最后根据公共工控协议的格式特征,对已分类的私有工控协议字段分类结果进行融合,得到最终的格式信息.

Fig. 7 Structure of LSTM-FCN model图7 LSTM-FCN模型架构
该方法重点结合工控协议字段的时序特性,通过深度学习的方法实现字段识别,为目前的工控协议逆向分析提供了一种新思路.
4.5 小 结
本节针对基于报文序列的全自动型工控协议逆向分析技术进行分析.目前大多数该类方法都结合工控协议的共性特征,对互联网协议逆向分析技术的格式提取环节进行改进.如文献[32]通过pair-HMM对序列比对算法进行改进;文献[33]将N-gram改进为V-gram以提高工控协议字段的识别精度.但同时,也有部分学者另辟蹊径,深入挖掘工控协议的其他内在特性,重新设计相应的逆向分析环节.比如文献[66]挖掘关键字和多种集群约束之间的内在联系,构建约束概率计算模型;文献[70]挖掘工控协议报文的时序特性,针对该特性引入深度学习领域的LSTM-FCN模型予以解决.这些都为全自动型工控协议逆向技术研究提供了更多新思路.
这些全自动型的工控协议逆向分析方法通常都具有较高的执行效率和更强的通用性,但同时也比较依赖协议报文样本的覆盖率.此外,由于目前工控协议仍没有完全统一的设计规范,因此在没有人工协助的情况下,这类方法通常都难以完成后续工控字段的语义推断与状态机重构.
5 基于报文序列的人机协同型工控协议逆向
基于报文序列的全自动型工控协议逆向分析技术主要结合工控协议的共性特征,完全通过机器或者少量的人工协助实现对工控协议的自动化逆向分析.而另一部分学者结合已知工控协议中各种关键字段的特征,归纳出相应的启发式规则,并在格式提取阶段通过人工干预的方式提前识别私有工控协议中的部分关键字段,以进一步提高后续逆向分析环节的效率和准确率,进而形成一种人机协同型的工控协议逆向分析技术[72].本节依然根据格式提取方式将其分为4类:基于序列比对的方法、基于频繁集的方法、基于语义的方法和基于数理特征的方法.
5.1 基于序列比对的方法
2021年Wang等人[34]认为“流水线式”的传统协议逆向方法无法将后面阶段识别的有效信息反馈到前面阶段,限制了工控协议逆向的准确性,因此,提出一种多阶段集成逆向分析法——MSERA,以完成OMRON_FINS,BACnet和Heidenhain等多种工控协议的逆向分析.该方法首先通过工控协议中各种特征字段的启发式规则,提前对各种特征字段的范围和语义进行预挖掘,如协议标识符、序列号、位置标识符等,并且提出语义优先级解决部分字段的语义重叠问题;然后将所推断的结果代入后续的逆向环节,通过序列比对算法和DBSCAN聚类算法[73]将高相似度分组划分为同一类别,并根据字段的动态变化特征,将同一类别中的数据包划分为字段;最后,对无法通过预挖掘得到的字段语义进行重新分析.此外,MSERA方法还通过字段校正方法对一些异常字段进行了修正.
MSERA方法通过“启发式识别+机器识别+修正”的方式,确实能够提高工控协议逆向的准确度,但是当连续多个字段的内容没有改变时,MSERA也很难区分出这些字段,这也是基于报文序列的协议逆向分析技术无法克服的固有困难.
5.2 基于频繁集的方法
2014年Zhang等人[74]认为如果部分子序列连续出现的频率比较高,并且其后续字节具有很高的可变性,则该子序列很可能是一个关键字段,因此提出了Prowork方法,使用投票专家(voting expert, VE)算法[75]推断关键字边界,并根据其属性(如长度、偏移量和频率)对候选关键字段进行识别.其中,如图8所示,VE算法在连续序列上使用窗口滑动,并通过决策规则C(x)在每个步骤中选出最可能的单词边界,用于分割没有分隔符的文本,因此非常适用于二进制协议的字段划分.

Fig. 8 VE algorithm illustration图8 VE算法说明
然而,2020年Wang等人[35]认为Proword方法只考虑到消息的本地信息而非全局信息,并且Proword未能推断协议的完整格式,因此,针对这一缺陷提出了IPART方法,结合工控协议的特点将VE算法改进为全局投票专家(global voting expert, GVE)算法,以实现Modbus,IEC104等工控协议的逆向分析.如图9所示,IPART方法首先通过GVE算法将原始报文分解为一系列字段,每个字段都具有边界和类型2种属性,并对一些错误候选边界进行重定位,以提高边界的查找精度;其次,选择一定范围内(如消息开始部分)的候选字段作为公共字段,结合各类型字段的特征,采用相应的启发式规则推断这些公共字段的类型,如长度字段、功能码、序列ID等;再次,根据工控协议中具有相同功能的消息通常具有相同的格式的现象,将具有相同方向和功能码的消息聚类到同一个集群中;最后,推断每个子集群的格式,并对这些结果进行组合,得到一个协议的完整格式.
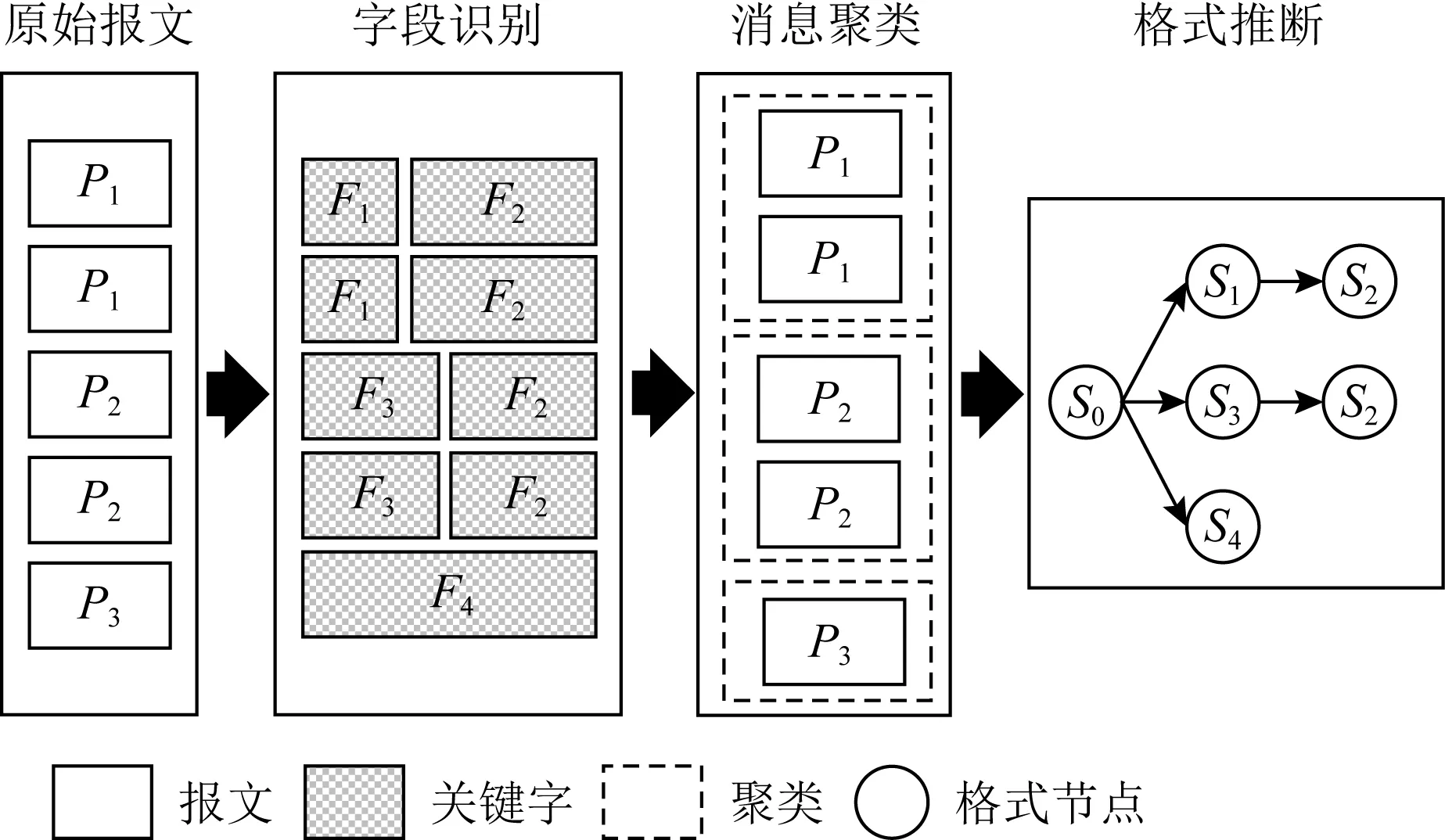
Fig. 9 The overview of IPART图9 IPART的概述
2020年Jiang等人[76]和2021年Liu等人[36]均提出一种基于数据驱动的方法——IPRFW,以推断Modbus,IEC104,Ethernet/IP等多种工控协议的字段边界和类型.该方法首先将每条消息中每个位置的数据都提取到相应的集合;其次计算每个集合的熵(entropy)E(s):

(1)
其中,s代表集合,i代表集合中的元素,n代表集合大小.计算2个相邻字段的熵距离D(X,Y):
(2)
其中,I(X)和I(Y)分别是变量X和Y的熵.再次,基于熵距离提出熵距离聚类(entropy distance cluster, EDC)算法,不断将熵距离最小的相邻字段进行递归合并,直至满足终止条件,进而推断字段边界.最后,结合工控协议各类特征字段的启发式规则,推断相应的特征字段,如常量字段、长度字段和功能代码字段等.
综上所述,虽然IPART和IPRFW的核心思想都是通过查找频繁集以准确定位工控字段的边界.但是它们的查找方式存在一定差别.IPART是根据多个连续字节的共现频率来推断字段边界,侧重于前后字段在统计意义上的相关性.而IPRFW是依赖某个固定位置上各数据的出现频率,并进一步通过相邻字段的编辑距离进行不断合并,以推断字段边界.此外,IPART推断长度可变字段的能力相对有限,因为变量字段的投票通常很小,很可能被IPART过滤掉,而且IPART主要通过功能代码对消息聚类,因此该方法仍然不够成熟.
5.3 基于语义的方法
2018年Ládi等人[77]针对Modbus和MQTT这2种常见的工控协议[78],提出了一种基于图的工控协议逆向分析方法.首先通过启发式规则逐步推断工控协议字段的类型和语义[79-80],初步构建无环连通图(树),再重点对无环连通图中存在的冗余问题进行优化,比如合并多个可变长度的字段和分支,替换有问题的枚举类型节点,最终完成无环连通图构建.该方法完全通过各工控协议字段的启发式规则以识别字段语义,因此对样本完备性具有较高要求,需要通信双方可控,并重复调用尽可能多的不同选项和不同功能组合,以便收集到足够且完整的协议网络流量.因此,该方法仅适用于范围较小且类型有限的工控协议的逆向分析.
5.4 基于数理特征的方法
目前大多数工控协议逆向分析方法都重点针对工控协议的结构简明、字段精度较细和周期性强等特征进行设计,基本没有考虑到部分工控协议的多层结构以及报文碎片化或重传导致的报文混乱等现象对工控协议逆向分析的影响,如S7Comm协议等.为避免这些负面影响,2017年Chang等人[81]提出一种自动化协议逆向工具,针对公开工控协议典型字段的恒定数理特征进行分析,如熵值、唯一值个数和增加趋势等,归纳相应的启发式规则,并将之作为私有工控协议字段的决策标准.框架流程如图10所示,主要分为5个步骤:会话分割、报文预处理、会话内分析、会话间分析和服务器-客户端分析.其中后面4个步骤是一个迭代循环过程.

Fig. 10 Packet field inference process图10 报文字段推断过程
该方法首先将网络流量分割成多个会话;其次,在第一次循环中,优先排除掉较小的数据包(可能表示简单的确认)和较大的数据包(可能表示分片),再通过碎片整理获得更多组织良好的数据包,进而发现一些更可靠的过滤和组装规则;再次,结合各类特征字段的决策标准,如熵、唯一值的个数、增加趋势等,完成各类字段的推断,比如在会话内分析阶段,检查会话中是否在固定位置字节上有变量值,如CRC、时间戳和序列ID等,而在随后的会话间分析阶段,随着固定值字节的特征变得更加具体,可以继续提取协议ID、会话ID、网络地址等字段;最后,检查和比较字段与响应标志相关或仅在响应报文中找到的值,以推断代表服务器—客户端关系的字段,并在每一次循环结束后,继续利用计算的信息重新开始分析,以获取更加精确的结果.
5.5 小 结
经过本节对基于报文序列的人机协同型工控协议逆向分析技术的分析,虽然目前该类大多数方法都是通过启发式规则对私有工控协议的特征字段进行人工预挖掘,但是它们对人工干预的节点选择仍存在一定区别.如果将格式提取细分为字段划分和结构识别2个子阶段,那么文献[34]、文献[77]和文献[81]等方法是在字段划分前就执行特征字段的预挖掘,而文献[35]、文献[36]和文献[76]等方法是在字段划分后再执行特征字段的预挖掘.通常来讲,人工干预越早,依赖的信息就越少,对专家的经验知识和启发式规则的要求就越高,但也更能促进后续的逆向环节,反之亦然.不过也有部分学者发现了工控协议通信过程中出现的一些其他现象,如分层结构和包碎片化、重传等,并深入研究能够克服这些负面影响的协议逆向分析方法.
这类人机协同型的工控协议逆向分析方法主要通过启发式规则完成工控协议特征字段的预挖掘,不仅能够进一步提高工控协议格式提取和后续分析环节的效率和准确度,而且非常有助于工控协议的字段语义推断.但同时该方法也比较依赖专家对工控协议设计规范的了解程度.此外,这类方法通常泛化能力也相对较弱,由于专家人工分析存在一定的片面性和局限性,导致这些启发式规则可能仅适用于部分领域的工控协议,甚至仅适用于指定工控协议.
6 讨 论
6.1 方法对比分析
相比于互联网协议,工控协议虽然没有统一的设计规范和大量的先验知识,导致大多数互联网协议逆向分析方法无法完全适用,但它们具有结构简明、周期性强等共性特征,为工控协议的逆向分析提供了更多依据.
结合工控协议的共性特征,目前基于程序执行的工控协议逆向分析技术主要借助污点分析的思想,对工控程序执行期间的函数、指令和数据的轨迹进行跟踪与分析,能够达到较高的识别精度和准确度,但是该方法不仅对ICS的稳定性影响较大,而且在工控领域难以实施,导致目前针对该类方法的研究仍比较少.而基于报文序列的工控协议逆向分析方法仅需要对捕获的网络流量进行分析,虽然识别精度和准确度不如基于程序执行的工控协议逆向分析方法,但是它易于实施且对ICS的影响比较小,自动化程度也相对较高,因此成为目前研究较多的方向.本文重点按照人机参与程度的不同将其分为全自动型和人机协同型,再按照格式提取方式的不同,继续分为基于序列比对的方法、基于频繁集的方法和基于概率模型的方法等.其中,表5重点对基于报文序列的工控协议逆向分析方法,从多个维度进行对比分析与总结,主要包括时间、分析粒度、字段划分、结构识别、语义推断、状态机重构等.
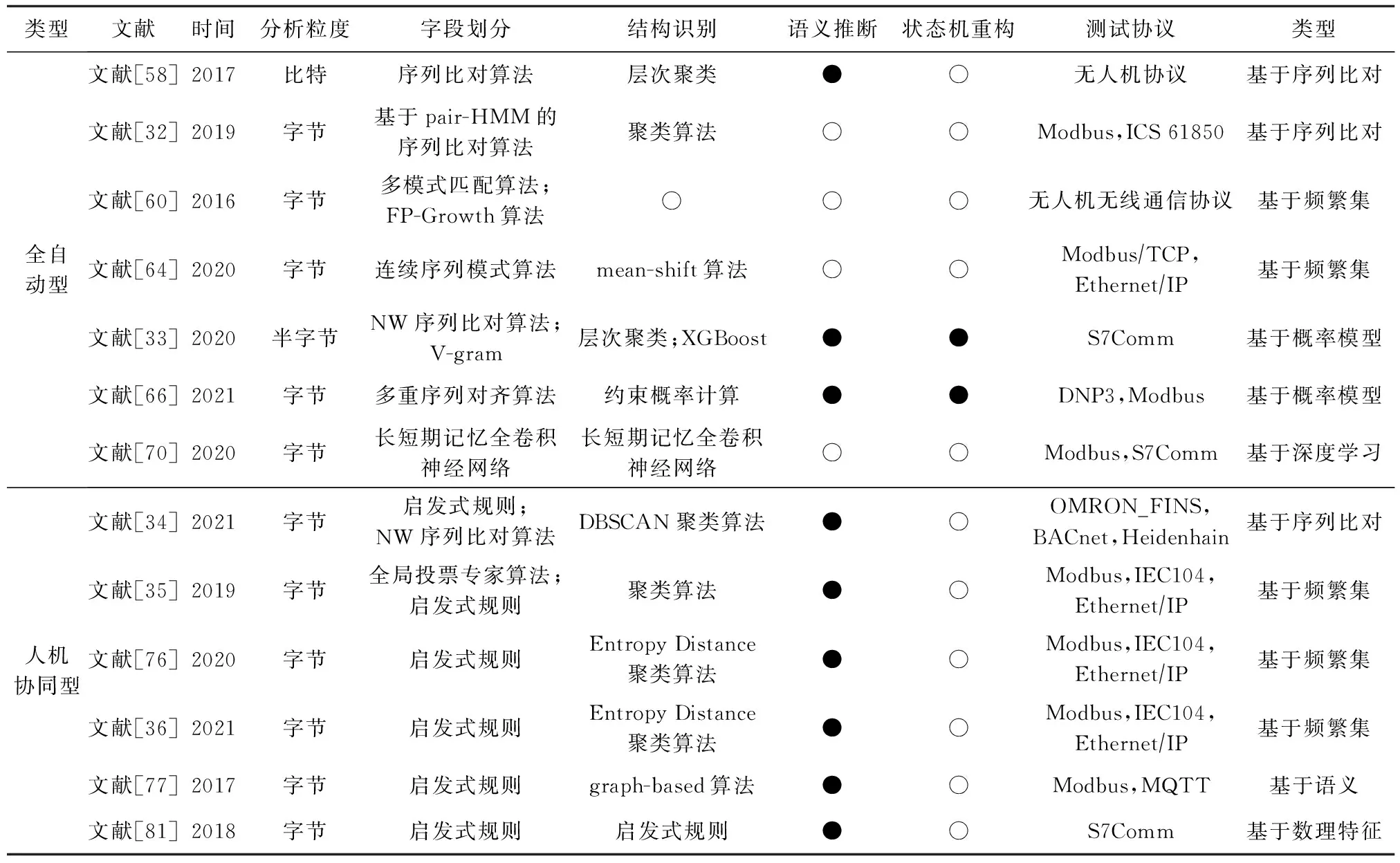
Table 5 Comparison of Industrial Control Protocol Reverse Methods
1) 从时间角度.目前针对工控协议的逆向分析研究主要是从2016年才开始,并主要集中在2019—2021年期间,说明随着工业互联网的兴起,该领域的安全研究正在逐渐受到重视.
2) 从分析粒度角度.目前基于启发式规则的人机协同型工控协议逆向分析方法对工控字段的识别精度只能做到字节级,但有少量全自动型工控协议逆向分析方法能够精确到半字节,甚至比特级,如文献[33]和文献[58].因此,目前基于报文序列的工控协议逆向分析技术对工控字段的识别精度仍存在较大不足,但是这也确实是该类型方法的难点.
3) 从字段划分角度.全自动型工控协议逆向分析方法主要通过改进的序列比对算法、多模式匹配算法、FP-Growth算法、连续序列模式算法、V-gram等多种方法完成对特征字段的提取,而所有的人机协同型工控协议逆向分析方法都是基于启发式规则完成协议字段的提取,仅部分方法会使用其他算法进行补充,如文献[34]的NW序列比对算法和文献[35]的全局投票专家算法等.
4) 从结构识别角度.这2类方法基本都是通过各种聚类算法完成格式识别,仅部分方法采用其他算法或模型进行辅助,如文献[77]的graph-based算法、文献[33]的XGBoost模型、文献[66]的约束概率计算模型等.
5) 从语义推断角度.仅有少数全自动型工控协议逆向分析方法能够完成语义推断,但是所有的人机协同型工控协议逆向分析方法都能够完成语义推断,说明工控协议特征字段的启发式规则不仅有助于提高格式提取的效率和准确度,还能够进一步促进工控协议字段的语义推断.
6) 从状态机重构角度.仅有少数全自动型工控协议逆向分析方法能够实现状态机重构,但是所有的人机协同型工控协议逆向分析方法都没有完成.因此,目前针对工控协议状态机重构的研究仍比较少.
综合来看,目前的工控协议逆向分析方法仍是将工控协议的格式提取(包括字段划分和结构识别)作为核心工作,因为只有准确地提取工控协议的格式才能够为后续逆向过程提供更高的性能保障.而仅有部分工控协议逆向分析方法能够完成语义推断,而能够完成状态机重构的方法更少.
6.2 未来研究方向
通过6.1节对工控协议逆向分析方法的总结可知,目前针对工控协议的逆向分析研究仍处于起步阶段,但随着近几年工业互联网的兴起,该方向已逐渐引起众多学者重视,因此我们认为未来针对工控协议的逆向分析研究可以从5方面展开.
1) 改善基于程序执行的方法实施难度
基于程序执行的工控协议逆向分析方法能够对工控程序执行期间的函数、指令和数据进行跟踪,因此具有较高的识别精度和准确度.但是因为其较难实施,且对ICS影响较大,目前针对这类分析技术的研究仍较少.因此如何寻找新的工具或者方法以改善基于程序执行的工控协议逆向分析方法的实施难度及对ICS的影响,将是一个非常值得研究的方向.
2) 提高工控协议格式提取的准确度
目前,不论是基于程序执行还是基于报文序列的工控协议逆向分析方法都将研究重心集中在格式提取上,主要包括字段划分和结构识别2部分,因为只有准确地提取协议格式,才能够保证后续环节的准确度.因此,可以继续针对该方向进行研究.一方面可以结合工控协议的特征,继续寻找其他能够进一步提高格式提取效率和准确性的新方法;另一方面也可以进一步深挖工控协议的内在属性,如文献[66]中的关键字和集群约束之间的内在联系,以及文献[70]中的报文时序特性等,进而完成工控协议的格式提取.此外,文献[69]基于深度学习完成工控协议的逆向分析,也是未来非常值得研究的一个方向.
3) 研究语义推断和状态机重构的方法
目前,大多数工控协议逆向分析方法都仅针对格式提取技术进行研究,能够深入到语义推断,甚至状态机重构阶段的方法少之又少.但是目前很多基于工控协议逆向分析的应用都非常依赖这2个环节的实现,如入侵检测、模糊测试[82]等.因此,针对工控协议语义推断和状态机重构的研究也是未来非常值得考虑的一个方向.
4) 研究针对工控协议其他特征的逆向分析技术
目前工控协议逆向分析方法通常都针对工控协议的结构简明、字段精度较细、周期性等特性进行设计,但随着工控设备、软件和网络等性能的不断提升,ICS对系统的实时性、可靠性、稳定性和功能性等需求也在逐渐提高.因此,工控协议的设计已经逐渐趋向复杂,导致出现一些新的现象,如文献[81]中研究的多层结构、报文碎片或重传等现象,这些现象为工控协议的逆向分析带来一些障碍.因此,针对工控协议的这些复杂特征进行研究也是非常值得思考的.
5) 研究工控加密协议逆向分析技术
基于商业性和安全性的考虑,大多数设备厂家都选择不对外公开自己的工控协议规范,同时,由于原先工控设备的计算性能较低,无法再额外负担对工控协议的加密与解密工作,因此目前大多数工控协议都未加密.但随着针对工控协议逆向分析技术的研究越来越多,这类非加密工控协议的安全性已经逐渐受到冲击[83].因此,结合工控设备性能的快速提升,目前已经有部分学者提出针对工控协议进行加密,以工控设备的“计算性能”换取必要的“安全性”[84].针对这类加密型工控协议的逆向研究势必也会成为未来的重点研究方向.
6.3 应用领域
工控协议逆向分析技术可以对未知工控协议进行分析,并获取协议规范和格式,目前可以被广泛应用于入侵检测、Fuzzing测试、协议重用等领域.
1) 入侵检测
由于ICS的硬件、网络等资源都相对有限,但又具有较高的实时性和可靠性要求,因此目前大多数工控协议为了提高通信效率,很少考虑一些非必要的安全需求,如安全认证和数据加密等,特别是一些早期设计的工控协议,都存在诸多安全性问题.将工控协议逆向分析技术应用于入侵检测系统,可以分析出ICS系统中的未知协议通信模型,包括协议格式、字段语义及取值范围和状态机信息等,一方面可以与恶意代码协议特征库进行比对,另一方面还可以基于这些信息进一步构造事件通信模型与服务模型,对各层协议进行深度检测,并根据数据包生成相应的事件,以检测ICS的入侵和异常行为,包括DoS、命令注入、未授权访问、缓冲区溢出等,最终进一步提高入侵检测系统的检测准确率.
2) Fuzzing测试
Fuzzing测试又称为模糊测试,通过自动或半自动生成大量非预期的测试数据作为目标测试程序的输入,并监测程序运行是否发生非预期结果,如输出错误、执行异常或内存泄漏等.将工控协议逆向分析技术与Fuzzing测试相结合,可以对目标ICS进行测试.通过工控协议逆向分析技术对目标ICS的通信协议进行逆向分析,可以得到工控协议的格式、字段语义和状态机等信息,进而构建未知工控协议模型.基于该模型生成的大量测试数据,不仅针对性较强,还具有较高的执行路径覆盖率,将这些测试数据作为Fuzzing系统的输入,对目标ICS进行测试,不仅能够发现更多潜在的异常点,还能够提高触发漏洞的概率.
3) 协议重用
随着工业的不断升级和技术发展,经常需要对一些早期开发的ICS进行更新,但相比于互联网应用,这些ICS的规模通常更大,并且各ICS子系统之间的关联性和依赖性也更强,重新开发不仅代价太大,而且对现有业务影响巨大,因此通常采用跨平台移植和重用,为此需要深入了解各ICS子系统之间的通信机制.通过工控协议逆向分析技术,可以提取各ICS子系统之间未知通信协议的格式与状态机模型,以及消息输入、输出之间的约束关系,基于这些信息可以实现对未知协议的重用,并进一步完成对现有ICS的升级与更新.
7 结束语
随着工业互联网近几年的迅速兴起,ICS的安全问题日益凸显,而工控协议逆向分析为其提供了良好的解决思路.虽然目前针对互联网协议的逆向分析技术具有很好的借鉴意义,但是由于工控协议特有的共性特征导致那些针对互联网协议的逆向分析方法无法适用于工控协议的逆向分析,因此本文重点对工控协议逆向分析的研究现状进行了详细阐述与总结,并提出这些工控协议逆向分析方法存在的不足和未来的研究方向,希望能够为更多从事这方面的同行学者提供一点帮助,以共同推进工控协议逆向分析技术的发展.
作者贡献声明:黄涛负责搜集、整理目前工业界和学术界的工控协议逆向研究工作,以及文章整体架构设计、撰写和修改;付安民负责全文结构设计与指导,以及各章节内容撰写思路;季宇凯负责工控协议逆向框架和未来研究热点的整理;毛安负责典型工控协议特征的分析、整理与总结;王占丰负责基于报文序列的工控协议逆向分类思路的指导;胡超负责工控协议逆向应用的整理以及全文总结.
猜你喜欢
汽车电器(2022年9期)2022-11-07
电子技术与软件工程(2022年11期)2022-09-09
软件导刊(2022年3期)2022-03-25
电脑爱好者(2021年23期)2021-12-08
科学家(2021年24期)2021-04-25
中国电子报(2019年75期)2019-01-16
中国经济周刊(2016年9期)2016-03-09
中国信息化周报(2015年17期)2015-06-01
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
