
基于改进原型网络的P300脑电信号检测①
2022-05-10 12:11施翔宇潘家辉
计算机系统应用 2022年3期
施翔宇,潘家辉
1(华南理工大学 自动化科学与工程学院 脑机接口与脑信息处理研究中心,广州 510640)
2(华南师范大学 软件学院,佛山 528225)
1 引言
脑机接口是直接建立大脑和外部设备交流的渠道,而不需要人的任何肌肉活动.在不同的大脑信号中,脑电信号具有相对较高的时间分辨率,有非侵入性、成本低等特点,适用于实现脑机接口系统.脑电信号中的P300 事件相关电位是构建拼写系统中常用的脑电信号之一.以往对P300 分类的工作主要利用传统机器学习算法,如支持向量机和线性判别分析.Rakotomamonjy等[1]使用支持向量机,字符预测的平均准确率达到96.5%,在2004年的脑机接口竞赛数据集II 中名列前茅.Bostanov 等[2]在脑机接口竞赛中使用基于Bagging的线性判别分析获得与支持向量机相当的结果.近十年来,深度学习在解决计算机视觉和自然语言处理等现实问题中取得了很大的进展,但是在脑电信号检测的应用还处于起步阶段.Cecotti 等[3]提出了一个4 层卷积神经网络(convolutional neural networks,CNN),在数据集上获得了的97%平均预测准确率.Liu 等[4]在CNN 中引入批归一化(batch normalization,BN)[5]缓解过拟合,字符预测的平均准确率达98%.
意识障碍(disorders of consciousness,DOCs)是脑损伤的后遗症,包括昏迷、植物状态、最小意识状态和闭锁综合征等4 种状态.处于植物状态的患者不能表达可理解的语言,也不能自发地睁开眼睛服从口头命令[6-8],而最小意识状态的特点是可以通过行为反应,表现出不一致但可重现的意识迹象[9].闭锁综合征患者以构音不全和四肢瘫痪为特征,但是能保持基本的认知功能[8].处于不同状态的意识障碍患者有不同的意识水平,因此,准确的意识水平检测是诊断和治疗意识障碍患者的关键.目前,评估意识障碍患者意识状态最常用的方法是行为评分法,如JFK 昏迷恢复量表修订版[10,11].然而,这种基于行为的评估方法误诊率高达37%-43%[12,13].因此,探索非行为、客观的方法来检测意识障碍患者的意识水平具有重要意义.近年来,一些研究显示了脑机接口技术在检测意识障碍患者意识水平方面的潜力,Pan 等[14]使用结合P300和SSVEPs的视觉混合脑机接口检测8 名意识障碍患者的意识,其中的3 名患者显示了命令-跟随行为.然而,意识障碍患者的认知能力普遍低于健康受试者,并且容易出现疲劳、注意力不集中等问题,难以完成长时间的实验,如何在实验时间短、数据数量少的情况下,准确分析出意识障碍患者的意识水平仍然是当前面临的挑战.一种可行的改进方向是优化分类算法,使其在样本数量少的情况下训练出好的模型.
在样本数量较少的情况下,深度学习算法在训练过程中容易出现过拟合现象,常见的解决方案有数据增强和正则化.而近年来的主流方案是使用元学习技术,利用已有的先验知识解决新的问题,而不需要大量的训练样本,从而解决了小样本带来的过拟合问题.元学习技术可大致分为3 类:学习微调、基于循环神经网络的记忆和度量学习.2015年Lake 等[15]在“Science”发表文章,提出了贝叶斯程序学习框架,实现单样本学习,Vinyals 等[16]提出的匹配网络和Snell 等[17]提出的原型网络,使用基于度量的方法实现了小样本学习.所谓度量就是比较两个样本的相关性,借助最近邻的思想完成分类,在某一个投影空间中,距离越近的样本越相似,即认为可以将其分为同一类别.
针对上述问题,本文结合原型网络思想,使用卷积神经网络提取脑电信号的特征,并使用度量方法,实现小样本情况下P300 信号的分类和识别,以及在样本数量较少的情况下的意识障碍检测.
2 P300 检测算法
2.1 数据预处理
P300 事件相关电位发生于刺激开始后大约300 ms,在EEG 中对应为正电压偏转.为检测P300 波形,需要使用时间窗对原始数据进行截取,并使用带通滤波器滤波以及对数据进行下采样抑制噪声干扰,提高信噪比.
2.2 网络架构
本章使用原型网络思想,结合卷积神经网络和度量方法,提出一种适用于P300 信号检测的改进原型网络,以第三届BCI 大赛的数据集II为例,每个电极通道样本的采样点数为78,使用所有的64 个电极通道,即输入样本维度为64×78.原型网络的流程图如图1所示,将支持集的每一个样本输入训练后的嵌入网络,生成一个编码表示,通过求和后平均生成每一个分类在嵌入空间的原型表示,对于查询样本输入同样的嵌入网络,得到其在嵌入空间的向量表示后,计算查询点与每一个类别原型的距离,距离最近的类别即为该查询点的类别.图2描述了嵌入网络的整体结构,嵌入网络使用卷积神经网络,由6 层组成,使用L0-L5表示.每层的第1 列表示该层的编号,第2 列表示该层的内部结构.例如,L1层是用于空间特征提取的一维卷积层.第3 列表示该层的输入和输出的维度.例如,L4层为全连接层,将360 维向量转换为128 维向量.第4 列表示该层的参数数量.
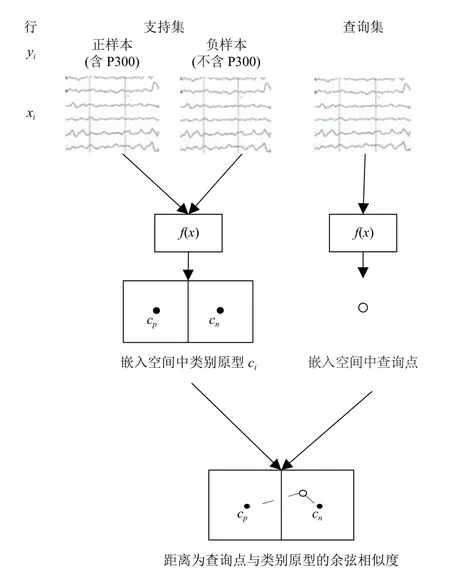
图1 原型网络流程图

图2 卷积神经网络结构概述
L0层:
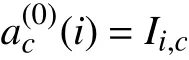
该层是输入层,数据经过预处理后作为输入,样本维度为[Nt×Nc],电极通道数Nc为64,时间维度Nt为78.其中,Ii,c表示第c个通道的第i时刻元素值,1≤c≤64,1≤i≤78.
L1层:
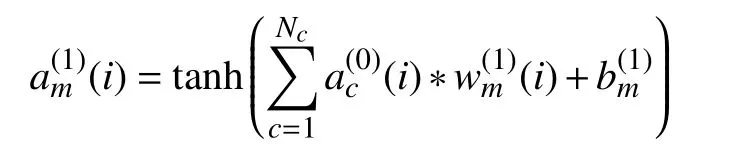
该层是卷积层,进行空间滤波和非线性激活.其中,w(m1)(i) 表示L1层第m个卷积核的权 重,b(m1)表示第m个卷积核的偏置.在该层学习了20 个维度为[1×1×64]卷 积核,即1≤m≤Ns,Ns=20表示卷积核个数,卷积步长设置为[1,1].激活函数使用tanh 函数.经过每个滤波器之后的输出a(m1)是一个维度为[78×1]的张量,故1≤i≤78.L1层 所有滤波器参数个数为20×(1×1×64+1)=1300.
L2层:

该层为卷积层、BN层及池化层.一维卷积层用于时域滤波,其中,w(n2)表示L2层第n个卷积核的权重,b(n2)表示第n个卷积核的偏置.在该层学习了20 个维度为[20×6×1]的卷积核,即1≤n≤20,卷积步长设置为2,因此时间维度下采样为Nt=37.经过每个卷积核a(n1)之后的输出g(n2)都是一个[37×1]的张量.激活函数选择 tanh 函数,在使用tanh 函数激活之前执行批归一化,以避免分布偏移,避免梯度消失和过拟合,加快网络的训练和收敛速度.池化层选用最大池化对时域进行下采样,经过池化层后,a(n2)尺寸为[18×1].L2层所有滤波器参数为2 0×(20×6×1+1)=2420.
L3层:
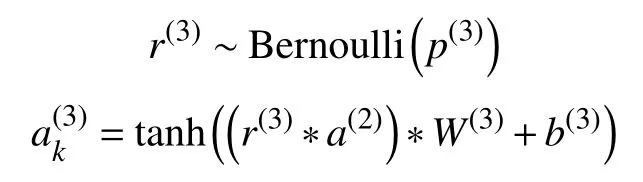
该层为Flatten 层和全连接层.使用Flatten 层,将输入张量由多维转换成一维的形式,达到从卷积层到全连接层的过渡的目的.为防止过拟合,该层引入Dropout,提升模型的泛化能力[18].全连接层则是把特征向量进行全连接处理,激活函数使用tanh 函数.其中,p(3)为第3 层神经元的Dropout 丢失率,Bernoulli 函数是以概率p(3)随机生成一个由0和1 组成的向量,从而使得这个向量与输入映射进行逐元素的乘积.L3层卷积核的权重为W(3),偏置为b(3).Flatten 操作之后,张量的尺寸由 [20×18×1]转 换为[360×1],最后经过全连接层,张量尺寸为[128×1].L3层参数个数为(360+1)×128=46208.
L4层:
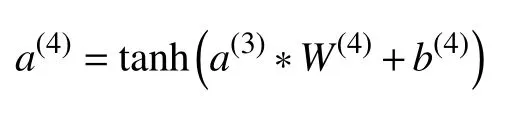
该层为全连接层,作用是输出样本特征.其中,W(4)表示L4层的权重,b(4)表示L4层的偏置.激活函数使用tanh 函数.经过该全连接层,张量尺寸为[32×1],L4层的输出a(4)表示输入样本的特征.L4层参数个数为(128+1)×32=4 128.
L5层:
该层是输出层.将训练集中所有的正样本P=[X1,X2,···,Xn]作为网络输入,其中n表示训练集中所有的正样本数.对每个正样本的特征a(4)取均值,表示正样本的原型Vp:
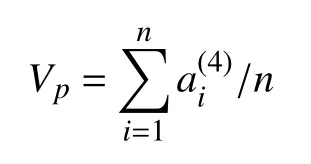
将单个样本X作为同一个网络的输入,特征为Vx=a(4),计算单个样本特征与正样本原型的余弦相似性:

输出结果为余弦相似性 cos ∈[-1,1],结果越接近1 表示两者相似程度越高,表示该输入样本越接近正样本的类别.因此,单个样本的P300 检测结果被定义为:
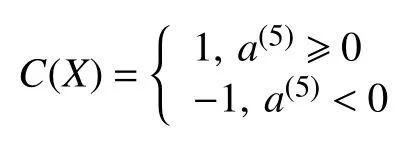
其中,X是待分类的样本,C是输出类别.
2.3 正则化技术
2.3.1 批归一化
批归一化用于减少神经网络训练过程中内部协变量偏移.由于tanh 激活函数是S 型饱和非线性激活函数,当 |z|很大或者很小时,g(z)的梯度趋于0,当网络有多层时,数据的分布可能进入激活函数的饱和区域,大大降低网络的训练速度.在我们的网络中,进入激活函数之前,使用对特征进行批归一化,可以有效地避免饱和问题,保证更快的训练速度.

算法1.批归一化算法M={x1,x2,···,xm}xi 1≤i≤m输入:最小批中训练样本数量为m,即输入的最小批,其中为最小批的一个训练样本,;ˆxi=BN{xi}输出:.(1)计算最小批中所有样本特征均值:µM←1 m m∑i=1xi(2)计算最小批中所有样本特征方差:σ2M 1 m m∑i=1(xi-µM)2←(3)归一化每一个样本的特征:︿xi xi-µM σM2+ò←其中,ò是一个用于保持数值稳定的常量.
2.3.2 Dropout
Dropout 算法可以使每个神经元学习到更多的随机特征,目前已经解决了许多的语音和图像识别任务中的难题.Dropout的基本原理是在前向传播的训练阶段,将某一层的Dropout 率设置为p,则该层中的每个神经元都有1-p的概率不工作.而在测试阶段,保留所有神经元,使其正常工作.设置适当的p值可以帮助神经元学习更明显更普遍的特征,避免网络过拟合.
2.4 损失函数
如前文所述,将所有正样本P输入网络,L4层输出为正样本的原型Vp,单个训练样本X作为同一个网络的输入,L4层输出特征Vx,单个训练样本特征与正样本原型的余弦相似性为网络的输出值a(5)=cos(P,X).
正样本标签y=1,负样本标签为y=-1,则单个样本损失函数表达式为:
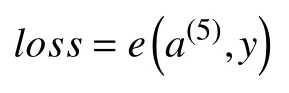
其中,e表示误差函数,本方法中e使用均方误差损失函数:
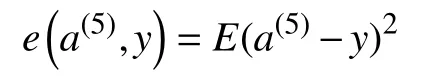
2.5 训练设置
本文网络使用Adam 作为优化器,初始学习率设置为10-3,在第5和第10 个Epoch 后分别将学习率设置为原来的1 /10,如文献[19]中建议,优化器的其他参数分别为β1=0.9,β2=0.999,ò=10-8.Dropout 率设置为0.5,随机梯度下降的批大小设置为50.
3 实验分析
实验分别以第三届国际BCI 竞赛数据集II、正常人和意识障碍患者照片识别数据作为实验数据.分别用于验证该网络对P300 拼写系统中经典数据集的检测效果、验证该网络对于小样本数据的检测效果以及对意识障碍患者的小样本数据进行分析.
3.1 数据集
3.1.1 第三届BCI 大赛的数据集II
第三届BCI 大赛的数据集II 中记录的是两名受试者的完整脑电信号.该数据集采用Oddball 范式下的BCI 2000 系统采集.在实验中,显示器上显示了一个6 行6 列的矩阵,矩阵中的字符为[a-Z],[1-9]和[_].受试者的任务是按顺序注视矩阵中的一个字符.该矩阵的6 行6 列以5.7 Hz的频率随机闪烁.要选择的字符由一行和一列决定.因此,12 行或列的闪烁中有2 个会诱发受试者的P300 响应.一个字符的拼写实验共有15 轮,1 轮闪烁中每行每列各随机闪烁1 次,共闪烁12 次.因此需要检测30 个P300 响应.
两个受试者的脑电信号从标准10-20 系统的64 个通道采集[20].该信号经过0.1-60 Hz的带通滤波,以240 Hz的采样频率进行采样.训练集由85 个字符的实验组成,正样本(含P300) 数量为85×2×15=2 550,负样本(不含P300)数量为8 5×10×15=12750.测试集由100 个字符的实验组成,正样本数量为3 000,负样本数量为15 000.每个受试者的样本数量如表1.

表1 受试者A、B的训练集和测试集样本数
每个样本使用刺激发生后0-650 ms的时间窗进行采样,采样频率为120 Hz,并通过0.1-20 Hz的8 阶带通巴特沃斯滤波器对脑电信号进行滤波.即每个通道样本的采样点数为78,当使用所有通道时,电极通道数为64,输入样本维度为6 4×78.
P300 拼写器是6 行6 列的矩阵,在一次字符拼写实验中,共有15 轮闪烁,即n=15.在1 轮闪烁中每行每列各随机闪烁1 次,共闪烁12 次,即1≤i≤12.使用得分向量S(i)计算1 次实验15 轮闪烁中,每一行和列分别检测出P300的累计概率:
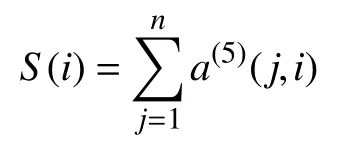
其中,a(5)(j,i)表示第j轮闪烁中第i行或列的网络输出结果,得分向量中行和列最大值的索引交叉点即为预测字符.

其中,x表示字符矩阵中的行中最大值的索引,y表示字符矩阵中的列中最大值的索引.
3.1.2 照片识别数据
照片识别数据由一个命令遵循实验采集,该实验的目的是判断受试者能否遵循指导语,看向指定的照片,通过分析实验过程中受试者的脑电信号,检测意识障碍患者的意识状态.在实验过程中,使用NuAmps 设备采集受试者的脑电数据,受试者在保持清醒的情况下戴上电极帽,脑电信号的参考电极放置在右侧乳突,地电极位于“Fpz”位置,且各电极阻抗保持在5 kΩ以下,采样率为250 Hz.一块显示屏放置于受试者前方约0.5 m 处,并调整到最佳视角.
命令遵循实验具体过程如下:在显示屏上出现两张照片,一张为受试者照片,一张为陌生人的照片,分别随机出现在屏幕的左右两侧,受试者根据指导语看向自己的照片或陌生人的照片.两张照片随机闪烁,每次闪烁持续200 ms,连续两次出现的间隔为800 ms,闪烁的出现符合Oddball 范式,可以诱发脑电信号中相关的P300 电位.两张照片各闪烁一次被定义为一轮闪烁,持续2 000 ms,在一次实验中,两张图片各闪烁8 次,即有8 轮闪烁.
共有15 名受试者参与该实验,其中5 名健康受试者,10 名意识障碍患者.实验前一周采用昏迷恢复量表(CRS-R)对所有意识障碍患者的意识状态进行评估.每位受试者进行了20 次实验.将这20 次实验数据随机分为10 个训练集,和10 个测试集,则每个受试者的训练集和测试集中正样本的数量均为8×1×10=80,负样本的数量也为8×1×10=80.每个受试者的样本数量如表2所示.

表2 每位受试者的训练集和测试集样本数
使用每次闪烁发生后0-600 ms的时间窗进行截取,每个样本共有 250×0.6=150个样本点,使用刺激前100 ms的基线校正后通过0.1-20 Hz的8 阶带通巴特沃斯滤波器对信号进行滤波.并以5的速率对所有数据进行下采样,即每个样本通道的采样点数为150÷5=30个.当使用所有通道时,电极通道数为30,输入样本维度为3 0×30.
在一次照片识别实验中,共有8 轮,即n=8.1 轮闪烁中两张照片各随机闪烁1 次,共闪烁2 次,即1≤i≤2.使用得分向量S(i)计算1 次实验8 轮闪烁,左右两张照片闪烁分别检测出P300的概率.
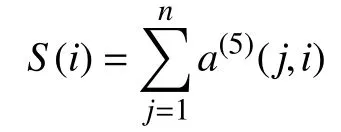
其中,a(5)(j,i)表示第j轮闪烁中第i张照片的网络输出结果,得分向量中的最大值为预测目标:

其中,t表示概率最大值的索引.
应用于照片识别数据的网络结构略有不同,L0层输入样本维度为[Nt×Nc],电极通道数Nc为12,时间维度Nt为30.L1层 卷积核维度为[1×1×12],经过每个滤波器之后的输出a(m1)是一个维度为[30×1]的张量.L2层卷积核的维度为[20×4×1],经过每个卷积核a(n1)之后的输出g(n2)都是一个[13×1]的张量,经过池化层后,a(n2)尺寸为[7×1].L3层,Flatten 操作之后,张量的尺寸由[20×7×1]转 换为[140×1].其余结构均与前文一致.
3.2 性能评价指标
本文模型首先检测每次闪烁出现后脑电信号中的P300 波形,并根据检测出P300 波形的次数预测字符/照片.因此可以用P300 波形识别率和字符/照片识别准确率两个方面来衡量我们的模型.
3.2.1 P300 波形识别率
P300 波形检测问题可以看作二分类问题,波形的识别率(recognition rate,Reco)定义为:
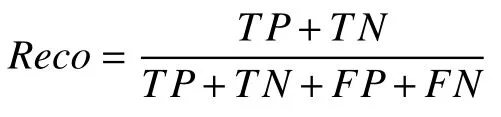
其中,真阳性(TP)表示实际为正样本,识别结果为正的样本数量;真阴性(TN)表示实际为负样本,识别结果为负的样本数量;假阳性(FP)表示实际为负样本,识别结果为正的样本数量;假阴性(FN)表示实际为正样本,识别结果为负的样本数量[21].
其他广泛使用的结果度量指标包括召回率(Recall)、精确率(Precision)以及二者的调和平均数F-measure:

3.2.2 字符/照片识别准确率
将字符识别测试数据作为模型的输入,输出为预测字符,即检测到P300 次数最多的行和列的交点,字符识别准确率定义为预测正确的字符数与所有测试字符的比例.
将照片识别测试数据作为模型的输入,输出为预测照片,即检测到P300 次数最多的目标,照片识别准确率定义为预测正确的照片数与所有测试照片数的比例.
3.3 实验结果
3.3.1 第三届国际BCI 竞赛数据集II 结果
本文模型与Cecotti 等人[3]经典的CNN 模型(CNN-1,MCNN-1)进行了比较.P300的分类结果如表3所示.对于受试者A和B,本方法的P300 识别率和精确率以及F-measure均高于其他两个方法.受试者A的识别率分别提高0.022和0.036,受试者B的识别率分别提高0.007和0.030.在精确率方面,受试者A和受试者B的数据使用本方法分析,相比CNN-1 分别提高了0.018和0.010,与MCNN-1 相比分别提高了0.027和0.034.而比较另一个重要的评价指标Fmeasure,本方法对于受试者A的结果,相比CNN-1和MCNN-1 分别提高0.009和0.016,对于受试者B,分别提高0.004和0.010.通过比较上述性能评价指标,可以认为本文方法在该字符拼写数据集中,对P300 波形有较好的分类性能.
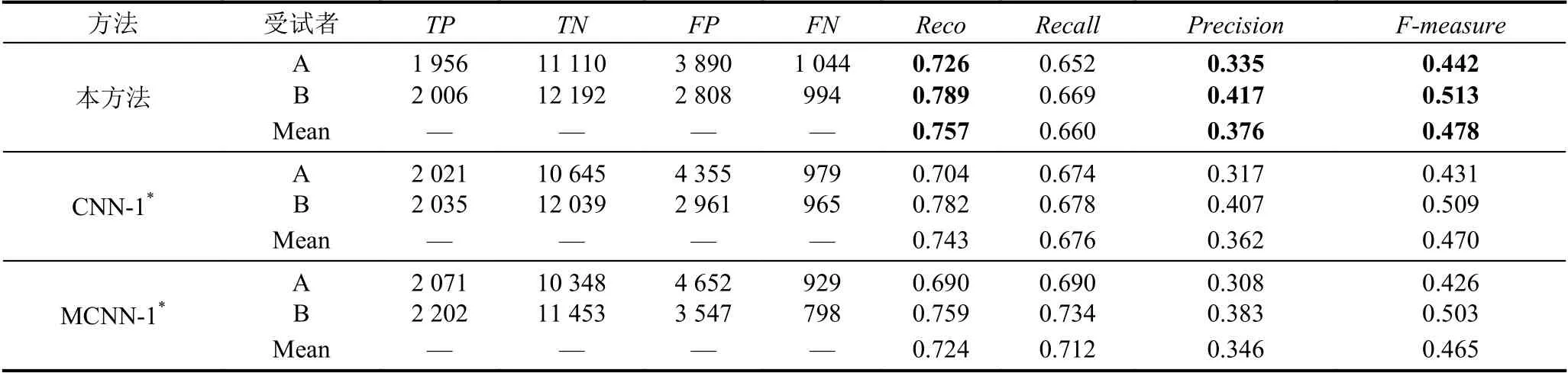
表3 P300 检测结果
使用平均字符识别准确率作为识别准确率的指标,同样与CNN-1,MCNN-1 模型进行比较.结果如表4所示,可以看出本方法在字符实验中对受试者A和B的字符识别准确率在不同闪烁轮次均与其他两个方法相近,大多数的字符都能在10 个闪烁轮次内被正确识别.综合两种性能评价指标,说明本方法可以有效应用于P300 信号检测与基于P300的拼写系统的应用.

表4 脑电竞赛数据集:不同方法字符识别率 (%)
3.3.2 照片识别数据结果
使用本文模型分别对5 名健康受试者和10 名意识障碍患者的照片识别数据进行离线分析.每位受试者有20 次的照片识别实验数据,随机选取其中10 次实验数据作为训练集,其余10 次实验数据作为测试集.表5总结了健康受试者的离线实验准确率,所有的5 名健康受试者均能正确完成照片识别实验,且在目标照片的第5 次闪烁之后准确率均达到了100%,即10 次照片识别任务均正确完成.验证了该方法适用于样本数量较少的脑电数据分类任务,同时表明该命令遵循实验可以有效地检测受试者的意识状态水平与命令遵循能力.
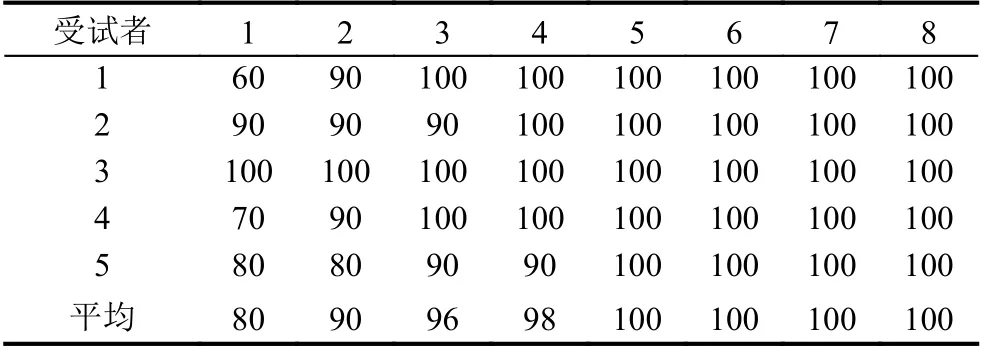
表5 健康受试者在照片闪烁多次后的识别准确率(%)
表6是意识障碍患者的离线实验准确率,10 名意识障碍患者的数据中有5 名受试者在目标闪烁8 次之后,准确率达到了70%及以上,即10 次识别任务中,识别正确的个数达到了7 个及以上.准确率高于脑机接口系统64%的随机水平,可以认为是显著的[22],表明该受试者拥有较高的理解认知能力和意识水平,具备命令遵循的能力.虽然其余5 名受试者的离线分析准确率低于64%,但是不能将这些结果作为受试者没有意识、不能遵循命令的依据,因为完成该实验需要受试者拥有注视能力及其他认知能力,任何一种能力的缺失都有导致实验准确率低下的可能性.

表6 意识障碍患者在照片闪烁多次后的识别准确率(%)
将实验离线分析结果与实验前后两次临床CRS-R行为量表评估结果对比,实验准确率高于64%的5 名意识障碍患者中,有3 名患者在实验结束的一段时间后,患者有较好的意识恢复情况,行为量表评估得分相比实验前有明显的提高.5 名实验准确率低于64%的意识障碍患者中有4 名的意识状态则没有明显变化.表明该方法对意识障碍患者的意识状态检测结果与临床评估结果匹配程度较高,具有较高的有效性.此外,在3 名有较好意识恢复情况的患者中,其中一名患者实验前的临床CRS-R 行为量表评估结果为植物状态,在第2 次评估中有较好的意识恢复情况,说明该检测方法相比于临床行为量表评估方法有更高的敏感性.
4 结论与展望
本文提出了一种适用于P300 信号检测的改进原型网络.该模型基于原型网络思想,使用卷积神经网络提取P300 信号样本的特征均值作为原型,结合度量方法余弦相似度,实现P300 信号的分类和识别.该模型在第三届BCI 竞赛数据集II 上取得了良好的结果,此外,在对样本数较少的照片识别数据分析中,该模型对意识障碍患者意识水平的检测结果与临床行为量表评估结果相近,并且该模型有更高的敏感性,可以有效地解决临床行为量表评估可能出现的误诊情况.在机器学习和神经科学领域,由于不同个体差异很大,个体间的P300 信号检测仍然是一个具有挑战性的问题,进一步的工作是研究小样本学习模型,实现不同个体间P300 信号的小样本识别,并选择最合适的模型应用于在线的脑机接口系统,实现对意识障碍患者的在线意识状态检测.
猜你喜欢
中国心血管杂志(2022年2期)2022-11-25
中国心血管杂志(2022年4期)2022-11-25
世界最新医学信息文摘(2022年43期)2022-11-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
