
基于节点引力与鱼记忆的社区检测算法
2022-05-14 03:28孙福禄王宇嘉刘子怡
计算机工程 2022年5期
孙福禄,王宇嘉,刘子怡
(上海工程技术大学电子电气工程学院,上海 201620)
0 概述
在现实世界中,许多事物之间的关系可用复杂网络表示。复杂网络又分为重叠社区和非重叠社区,若节点只属于一个社区,称该社区为非重叠社区;反之则称为重叠社区。目前的研究主要集中在非重叠社区检测,而真实社交网络中的社区通常是互相重叠的[1],例如个体可能会同时属于学校和社区,且其在网络中也可能会同时存在于多个兴趣小组中。因此,重叠社区的研究对于复杂网络的结构分析具有重要意义[2]。
近年来,研究者发现,重叠社区与现实世界网络的实际社区结构较为贴近,更具有研究意义,一些优秀的思想和方法被相继提出。2004 年,NEWMAN等提出经典的基于分裂思想的社团检测算法[3]。2005 年,PALLA 等提出基于派系过滤思想的重叠社区发现算法[4]。之后,研究者围绕派系过滤提出了多种不同的方法,如FARKAS 等提出针对加权网络的社区划分算法[5],KUMPULA 等提出快速的派系过滤算法[6]。2007 年,RAGHAVAN 等提出了著名的标签传播算法[7]。其后,研究者又提出了一些新的基于标签传播的改进算法,如SHANG 等提出了一种基于循环搜索核心节点并根据节点的相似度进行标签传播的方法[8],文献[9-10]提出了基于节点重要性进行社区检测的标签传播方法,WANG 等提出了一种改进随机策略[11],提高了标签传播算法的稳定性,但这些算法都只是解决了非重叠社区的划分问题。为了将标签传播算法应用到重叠社区检测中,STEVE 等提出了基于标签隶属度的重叠社区检测算 法[12](Community Οverlap Propagation Algorithm,CΟPRA),XIE 等提出了一种基于speaker 和listener的标签传播算法[13],SUN 等提出了一种基于优势标记传播 的网络 重叠社 区检测算法[14],MA 等 在CΟPRA 的基础上提出了一种采用PageRank 和节点聚类系数的标签传播重叠社区检测算法[15]。这些算法都保持了标签传播算法可应用于大规模复杂网络重叠社区检测的优点,然而,并没有解决LPA 随机性强、准确性差的问题,不能有效提高社区划分质量。
本文提出一种基于节点引力和鱼记忆的社区检测算法。通过节点质量计算节点信息熵,并将信息熵融入k-shell 算法中进行节点排序,同时根据节点与标签间的引力,使用鱼记忆节点标签存储策略实现标签更新,从而解决标签传播随机性造成社区划分不稳定的问题,提高社区检测的准确性。
1 基于节点引力与鱼记忆的标签传播算法
当前的标签传播算法有近似线性的时间复杂度,但稳定性较差,即多次运行算法的社区发现结果差异很大。有效解决节点更新的随机性及标签选择的不确定性,可以增强社区检测的稳定性,提高社区检测质量。本文提出的算法通过节点间的相互关系和节点标签间的吸引力,解决节点排序与标签传播更新两个重要步骤的随机性与不确定性问题。
1.1 相关定义
设定图G=(V,Ε)为复杂网络,V=(ν1,ν2,…,νn)为图的节点集,Ε表示图的边集,本文仅对无向图结构进行研究。各节点在图G中的度用ki表示,如图1所示,则V=(ν1,ν2,…,ν9),节点ν1的度k=3。
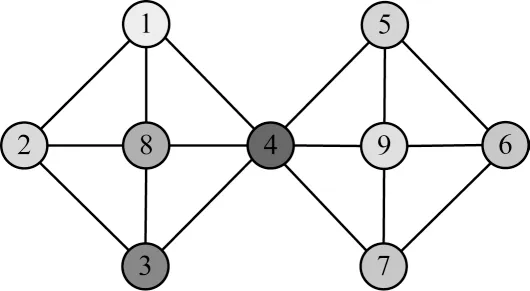
图1 简单图结构Fig.1 Simple graph structure
定义1如果图G中的节点u满足:

则称N(νi)为νi的邻居节点集,ui为νi的邻居节点。在简单结构图G中,有N(ν1)={ν2,ν4,ν8}。
定义2(节点质量)对于G=(V,Ε),节点质量表示节点在图中各点的质量大小,即重要程度。
一个节点可能是潜在的社区中心,即该节点具有以下特征:它与更多的邻居节点连接,并且这些邻居节点紧密地相互连接。一个节点与其邻居节点连接得越紧密,这个节点与其邻居节点形成的三角形就越多,这意味着如果一个节点具有较大的度,并且与其邻居节点形成更多的三角形,那么该节点质量越好,成为社区中心的可能性越大。因此,本文采用三角形数量及节点的度来表示节点质量,定义为:
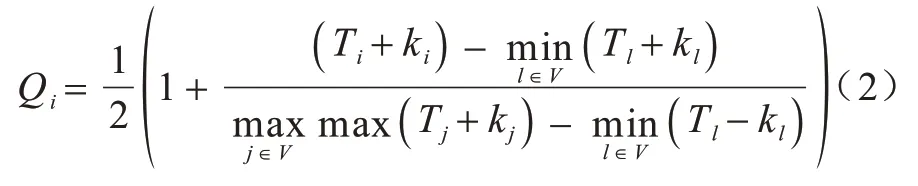
其中:Ti表示节点i所属三角形的数量。
定义3(节点信息熵)节点信息熵表示节点获取邻居节点信息时消耗的能量,定义为:

信息熵由节点质量计算得到,用以表示该节点质量的强弱,即节点在图中的中心度。
定义4(节点相似度)节点相似度反映了两个相邻节点之间的连接强度。
常用的相似度计算方法是用Katz 函数[16]进行相似度度量,然而它不能有效区分两个节点之间的程度差异对节点相似性的影响。此外,该算法计算复杂度很高。受Jaccard 函数[17]的启发,本文提出一个基于Jaccard 函数的相似性函数,如式(4)所示:

其中:α为相似度系数,α=0.2~1;Str为节点t、r之间的节点相似度;Dij为节点i到j最优路径上的所有节点。
定义5(节点引力)节点j对i的引力大小定义为:

在标签传播过程中,不同邻居节点间的引力大小是不同的,也就导致不同节点间的信息影响程度不同。本文用节点的信息熵Ε及相似度S来表示节点引力,并通过节点引力计算节点对不同节点标签的引力大小,使得节点更新变得更加合理。Ε越大,S越大,节点对标签的引力就越大。
定义6(节点记忆)模拟鱼的记忆存储特征,构建一个节点记忆集合:
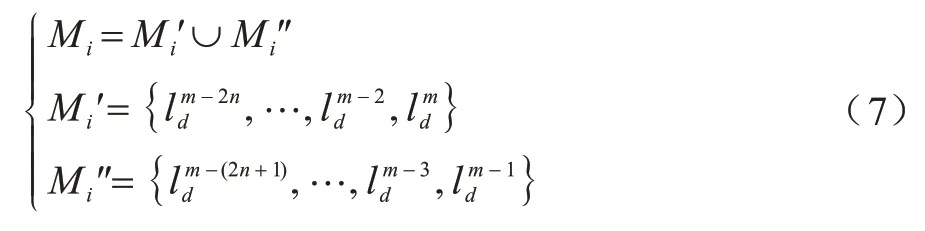
其中:ld为每一次迭代节点i中的支配标签;m为当前迭代次数。在标签传播中,复杂网络节点极易造成标签震荡(即两个标签交替支配节点),使得网络形成二分图结构,严重时会导致无法检测出社团。根据鱼记忆特征,每个记忆存储保存最近n次迭代的记忆,Mi出现n次记忆相同时,则视为节点标签出现记忆振荡,需要做进一步处理。鱼记忆的存储策略既解决了标签振荡,可保持算法的准确性,又减少了计算成本及内存的损耗。
1.2 标签更新策略
本文借鉴文献[12]的设计思想,使用g(c,u)来表示节点u对标签的引力。引力足够大时才能将标签吸引到节点,迭代结束时,通过引力大小来生成节点的标签集,从而检测到重叠社区。
为了降低标签传播的复杂性,只传播具有最大归属系数的优势标签[14],同时避免随机更新节点标签带来的社区检测不稳定性,将节点熵融入k-shell算法[18]对节点进行排序,节点标签将根据排序进行标签更新。笔者认为,节点k值越高、信息熵越大,节点成为潜在社区中心的概率越大。因此,按升序对节点进行排序,可以使潜在社区中心的标签传播得足够远,以占据社区中心,然后社区可以获得与其他社区边界区域中的节点,从而检测到更准确的社区结构。
在每一次迭代的开始,首先更新标签及节点间引力大小,具体更新策略如下:
1)根据节点的k值,对节点u∈V进行分壳处理,将相同k值的节点分在同一壳内。
2)计算各节点信息熵,在每一k壳中进行升序排序,然后进行总体升序排序。
3)对于节点,在迭代开始更新标签时,节点只接收各邻居节点引力最大的标签,并形成邻居节点标签集:

其中:lj→i=(cj,gj);cj为节点j中受节点i引力最强的标签;gj为该标签受节点i引力的大小。根据节点排序获取邻居节点的支配标签集Li(若是第一次迭代则获取初始标签),能够保证所获取标签对节点的支配性,降低标签的随机性。
4)基于G和Li计算并更新节点i对标签cj的引力大小:
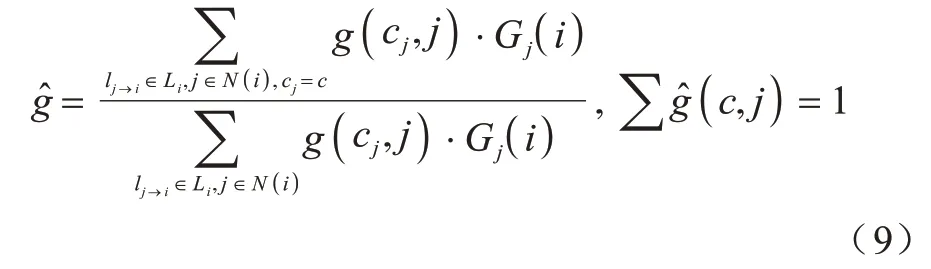

7)将ld存储在标签记忆Mi中,更新Mi,当Mi内出现标签记忆波纹,即该节点标签只保存为ld将不再改变,且节点引力gd(c,j)=1。
CDA-GM 算法伪代码如算法1 所示。
算法1CDA-GM


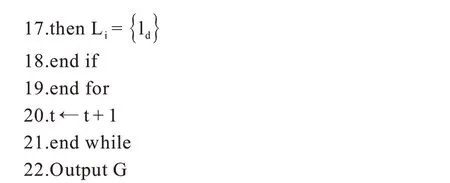
CDA-GM 算法的简单图应用如图2 所示。
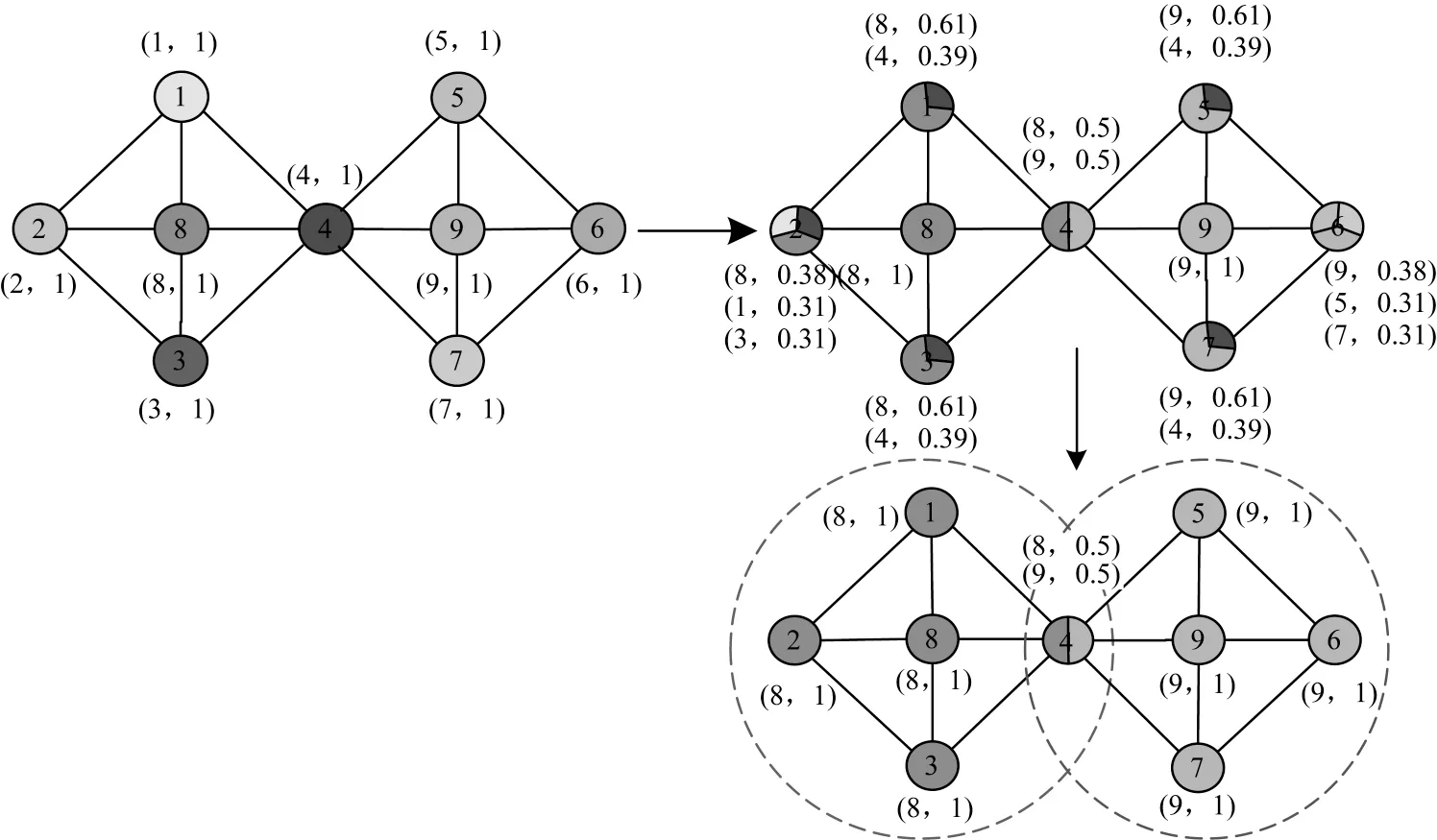
图2 CDA-GM 的简单图应用Fig.2 Application of CDA-GM algorithm in simple graph
首先根据式(3)计算出的Εi进行排序,初始化标签及标签引力g=1,更新顺序为2→6→1→3→5→7 →8 →9 →4,然后依据CDA-GM 的更新策略进行节点更新。
1.3 时间复杂度分析
一个具有n个节点的图结构,在CDA-GM 的第一阶段,时间复杂度分析如下:
1)Εi的时间复杂度:节点度数和三角形数量的时间复杂度分别为Ο(k)和Ο(k2),即计算Εi的时间复杂度为Ο(n(k2+k)m),m为相连节点数。
2)Sij的时间复杂度近似为Ο(knm+kn)。
3)利用Εi进行排序的时间复杂度约为Ο(2n)。
在CDA-GM 的第二阶段,标签迭代更新T次的时间复杂度为Ο(knT)。因此,算法总的时间复杂度为Ο(n(k2+k)m+kn(m+1) +2n+knT)。对于大型网络n≫m≫k,T,总时间复杂度为Ο(nm+αn),其中,α为常数。由上述可知,CDA-GM 各阶段时间复杂度都趋近于线性,更适用于稀疏大规模网络。
2 实验结果与分析
为验证CDA-GM 算法的性能,本文在真实数据集和人工数据集上进行社区检测实验,并与其他算法的社区检测结果进行对比。
人工数据集由LFR 人工基准发生器[19]生成,采用标准化互信息(NMI)指标[20]进行对比评价。真实网络大多情况下是不知其社区划分的,因此,采用当前主流的拓展模块度EQ[21]函数进行评价。
为更直观地验证CDA-GM 的实现效果,分别选取CΟPRA[12]、SPLA[13]、DLPA[14]、CΟPRAPC[15]算法进行对比。将CΟPRA、SLPA、DLPA 的参数分别设置为ν=2~9,r=0.1~0.5,in=1~8,使得各算法在指定的参数范围内获得最优评价指标。算法各运行20 次,并取最大值的平均值进行对比,减小算法随机性对结果的影响。
2.1 实验数据集
2.1.1 LFR 基准网络
LFR 基准网络由LANCICHINETTI 等[19]提 出,具有真实世界的网络特性,且社区可调模块度呈幂律分布。LFR 各参数意义如表1 所示,其中混合参数μ是衡量算法稳定性的重要指标,表示社区的模糊度,μ的值越大,则表示网络连边越多,社区结构越不清晰,社区检测的难度越大。重叠社区的LFR 基准网络参数设置如表2 所示。

表1 LFR 基准网络参数说明Table 1 LFR benchmark network parameters description
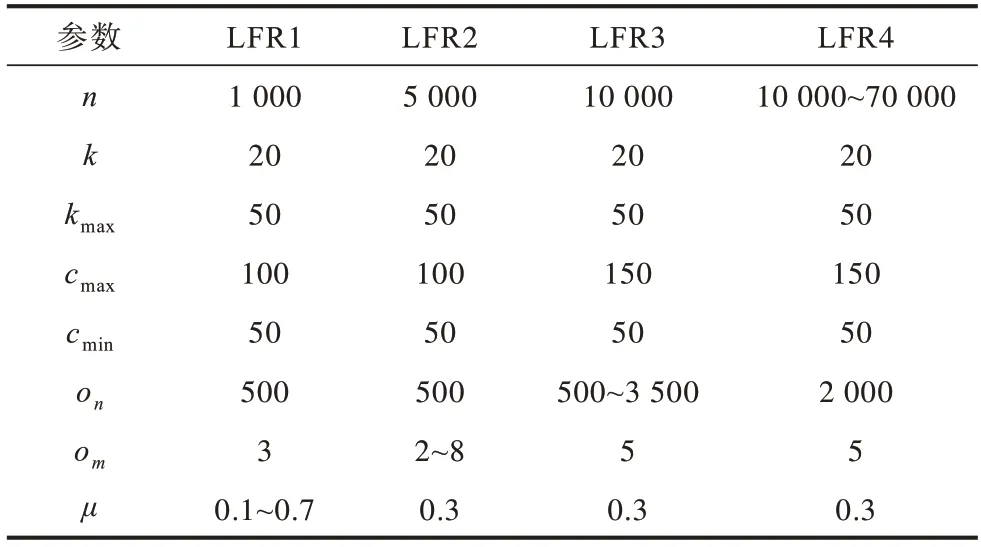
表2 LFR 基准网络参数设置Table 2 LFR benchmark network parameters setting
2.1.2 真实世界网络
实验用到的真实数据集有小数据集Karate、Dolphins和Football,以及大数据集Facebook、Ca-HepPh和Email-Enron。其中:小数据集来自于http://wwwpersonal.umich.edu/~mejn/netdata/;大数据集 来自于http://snap.stanford.edu/data/。具体数据参数如表3所示。
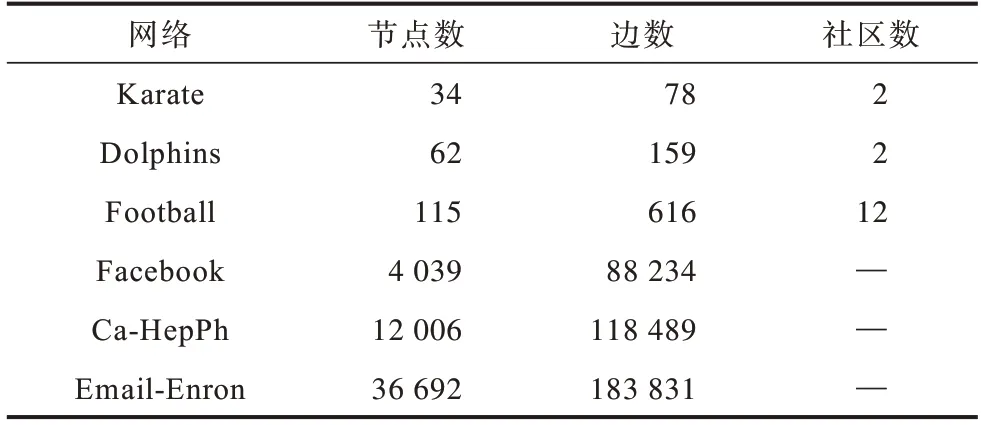
表3 真实网络相关参数Table 3 Related parameters of the real network
2.2 评价指标
2.2.1 标准化互信息
标准化互信息(Normalized Mutual Information,NMI)指标[20]用于评价已知网络结构的社区检测。因为NMI 被用于比较各算法所获取的社区划分与基准网络社区结构间的相似程度,所以只能被用于已知社区结构的网络。NMI 指标定义如下:
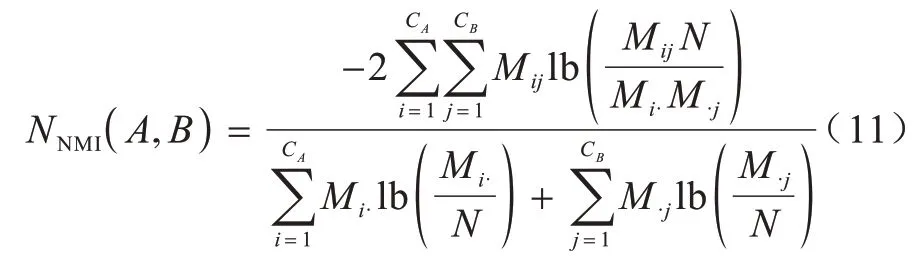
其中,A、B分别是原有网络社区结构以及算法检测结果;Mi·表示网络A中第i社区的节点数量;M·j为网络B中第j社区的节点数;Mij表示两个网络之间的接近程度。NMI 在[0,1]之间的值越高,代表算法检测出的社区结构越好。
2.2.2 社区模块度
对于未知社区结构的真实网络,算法划分结果往往采用社区模块度(即Q 指标)[22]作为划分社区结构质量的评价指标。与文献[22]提出的模块度指标不同,因为本文研究的对象是重叠社区,所以采用的是重叠模块度QE指标[21],定义如下:
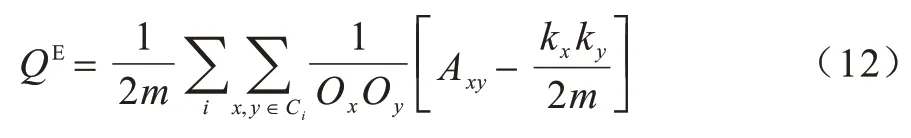
其中:m为网络边数总和;Ci为最终网络结构的第i社区;各节点x、y的归属社区数为Οx、Οy;Axy为x、y节点间的邻居矩阵元素。
2.3 算法参数分析
2.3.1 相似度参数分析
本文分别在LFR1 与真实世界网络上进行对相似度参数α的实验分析,CDA-GM 基于相似度参数不同值在LFR 人工网络中的NMI 值如图3 所示,真实世界网络中相似度参数的取值如图4 所示。
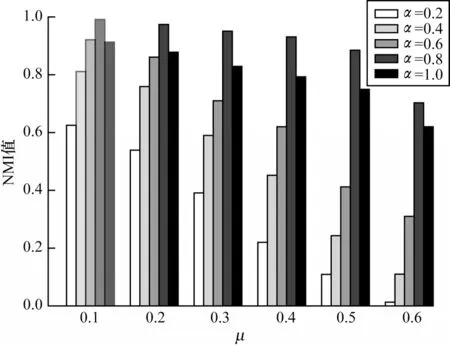
图3 各α 值下LFR1 网络NMI 值Fig.3 NMI value of LFR1 network under each α value

图4 各α 值下真实世界网络QE 值Fig.4 QE value of real world network under each α value
由图3、图4 可以看出:当α=0.8 时,CDA-GM 的表现明显优于其他参数取值;当网络结构变模糊时,α=0.8 仍能保持一个较好的稳定性及准确性;α=1虽然也能在结构模糊时保持一定的稳定性,但准确性上却差了一些。
2.3.2 记忆存储参数分析
为分析记忆存储参数,将相似度参数设为0.8,在人工网络LFR1 中对是否引入鱼记忆存储及记忆存储个数进行实验对比分析。CDA-GM 引入鱼记忆存储方法前后及不同记忆存储个数在LFR1 人工网络中的性能表现如图5 所示。
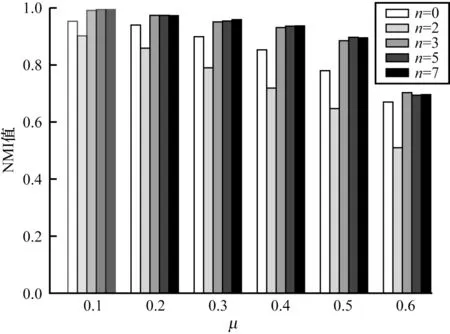
图5 各n 值 下LFR1 网络的NMI 值Fig.5 NMI value of LFR1 network under each n value
在图5 中,n=0 为没有引入鱼记忆存储策略的CDA-GM 算法。可以看出:当n=0 和n=2 时,社 区划分结果始终不如n>2 的社区划分结果,且在网络结构越模糊时表现越明显;当n=2 时,各节点只保存两次迭代,而标签交替出现两次的情况易发生,导致节点的标签多样性严重下降,干扰了检测准确性,社区划分结果反而下降;当n>2 时,NMI 值明显大于没有引入记忆存储的NMI 值,说明引入n>2 的记忆存储后社区划分结果更贴近原有的社区划分,将网络信息进行了更为完整准确的保存。同时由图5 可以看出:n>3 与n=3 的社区划分结果基本相同。因此,在保证算法计算复杂度及内存占用耗费较低的前提下,本文选择n=3,即将存储次数为3 的标签记忆引入CDA-GM 中。
2.4 LFR 人工网络实验结果分析
CDA-GM 及其他4 种比较算法在基准网络LFR1、LFR2 和LFR3 中的NMI 评价结果如图6 所示。
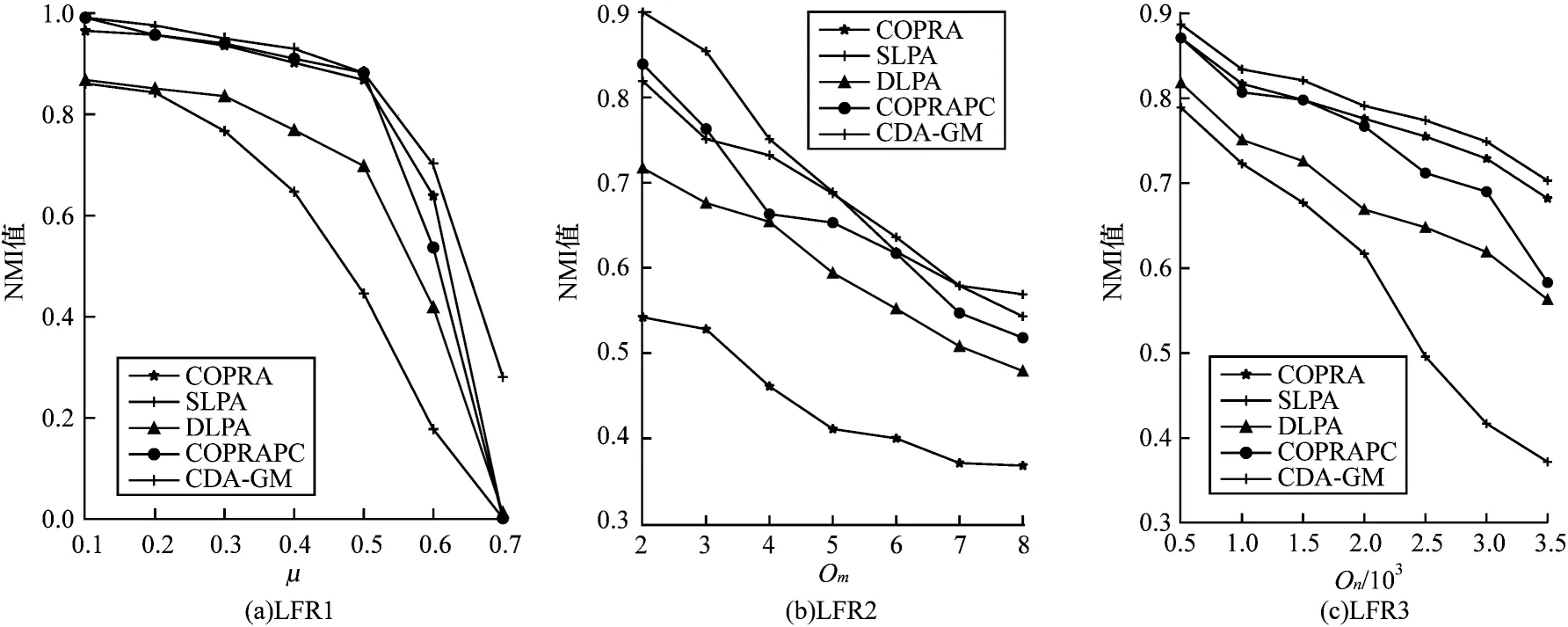
图6 各算法在3 种LFR 基准网络上的实验结果Fig.6 Experimental result of each algorithm on three LFR benchmark networks
在图6(a)中,调整μ值大小,其余参数固定。可以看出:当μ=0.7时,其他算法已经基本检测不出社区结果,CDA-GM 的NMI 值依然 能保持在0.2 以 上,且 当μ<0.7时,CDA-GM 也始终能获得比其他算法更好的NMI值,说明CDA-GM 在模糊图上的社区划分能力更强。
在图6(b)中,调整Οm值大小,其余参数固定。可以看出:在不同Οm值下,CDA-GM 具有良好适应性。由于CDA-GM 的标签引力设置,节点最多只能拥有3 个标签,因此,当Οm≥4 时,CDA-GM 的NMI值下降较快。但相比于其他算法,CDA-GM 仍能保持一个较优的NMI 值,说明在结构复杂的网络中,CDA-GM 仍能获得较好的社区划分结果。
在图6(c)中,调整Οn的值,控制其他参数不变。可以看出:随着Οn值增大,社区检测的难度逐渐增大。当Οn=3 500 时,除了SLPA 能保持一个较好的适应性,CDA-GM 仍能拥有最高的NMI 值,即使是在较多重叠节点的网络中,CDA-GM 仍能获得较好的社区划分结果。
本文选取LFR3 中Οn=2 000 的基准网络,将各算法在较复杂网络上进行社区检测稳定性对比,结果如图7 所示。可以看出:CDA-GM 的稳定性明显优于CΟPRA、SLPA 和DLPA;CΟPRAPC 的稳定性较好,但极值相差较大。
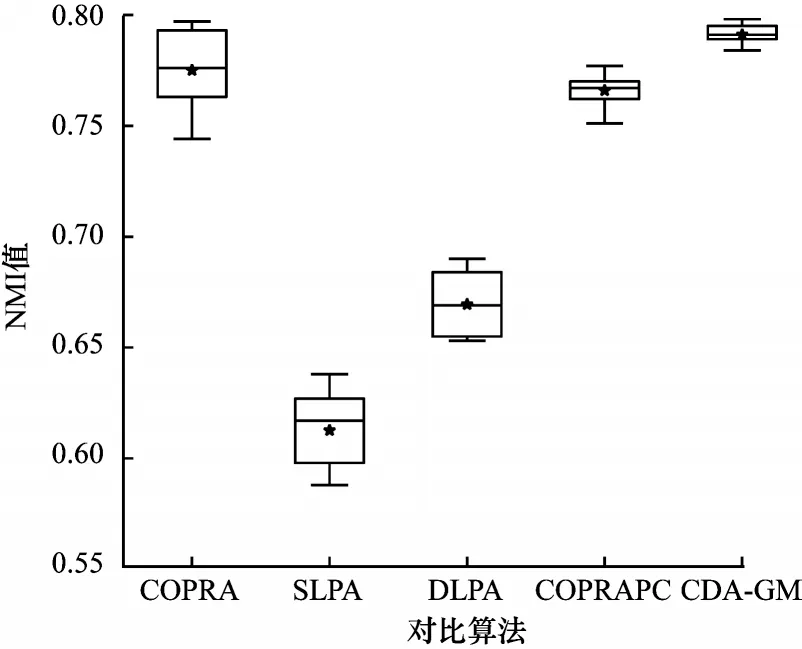
图7 各算法稳定性对比Fig.7 Stability comparison of each algorithm
图8 显示了各算法在LFR4 人工网络上的时间耗费。可以看出:DLPA 所用的时长最短,SLPA 与CΟPRA 相当,这是因为DLPA 的时间复杂度为Ο(Tm),其中m是网络中的边数;而CΟPRA 与SLPA的时间复杂度分别为其中,T为迭代次数,ν为社区数量。图8 中因LFR4 网络结构较为简单,当社区规模增大时,边的数量相比于节点数较小,DLPA 算法时间耗费也就较小。而CΟPRAPC 的时间复杂度为Ο((m+n)/c),其中,c为聚类系数,CDA-GM 与CΟPRAPC 的时间耗费相比于基线方法略高,但与其他4 种算法相比,CDA-GM 获得了较好的准确度和稳定性,这表明CDA-GM 在保持一个接近线性时间复杂度的前提下,大幅提高了标签传播算法的社区检测能力。
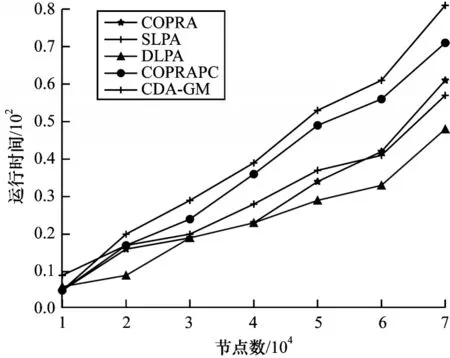
图8 LFR4 网络数据集上的运行时间Fig.8 Running time on LFR4 data sets
算法划分的社区与原有社区的相似程度,也经常用于辅助评价社区检测结果。表4 为各算法在LFR1 上获取的社区数量,其中,Nreal为数据集中的原有网络数量。可以看出,CDA-GM 能够获得较好的社区划分结果,与原有社区较为接近,而CΟPRA、CΟPRAPC 在μ=0.4 时,已经无法检测社区。

表4 各算法划分社区数Table 4 Number of divided communities of each algorithm
2.5 真实世界网络实验结果分析
将5 种算法分别应用到真实世界数据中,对比经过20 次重复实验取得的平均值以及标准差值如表5、表6 所示,其中,最优值以粗体显示,CΟPRA、SLPA 及DLPA 算法调整参数取最优结果。
表5 各算法值对比Table 5 Comparison of value of each algorithm

表5 各算法值对比Table 5 Comparison of value of each algorithm
表6 各算法值对比Table 6 Comparison of value of each algorithm
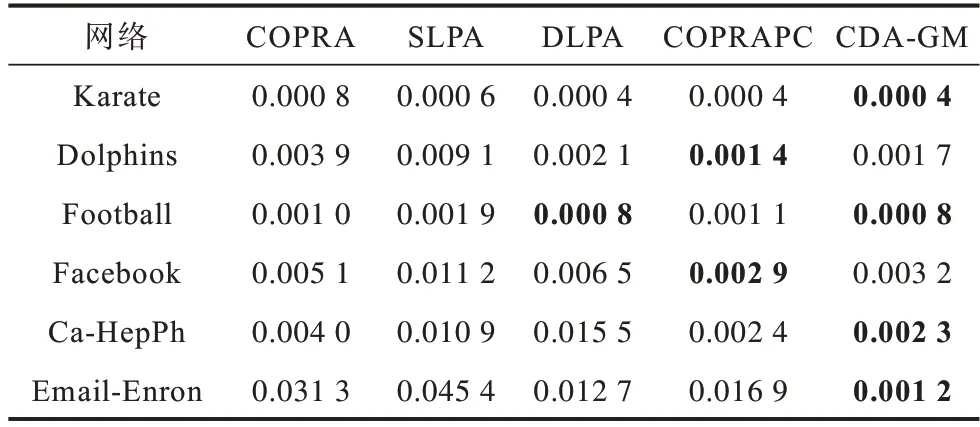
表6 各算法值对比Table 6 Comparison of value of each algorithm
3 结束语
为提高社区检测的准确性和稳定性,本文提出一种基于节点引力与鱼记忆的社区检测算法CDA-GM。使用融入节点信息熵的k-shell 排序策略,同时利用节点间的引力选择标签。在此基础上,引入鱼记忆的节点标签存储策略避免出现标签震荡。实验结果表明,该算法在LFR 人工基准网络和真实世界网络中能获得较好且稳定的NMI 值和社区模块度,检测性 能优于CΟPRA、SLPA、DLPA 和CΟPRAPC 算法。在后续研究中,拟将本文算法结合时间参数应用到动态的社区检测中,进一步提高算法的实用性。
猜你喜欢
当代陕西(2020年15期)2021-01-07
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
中国惯性技术学报(2019年6期)2019-03-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19
火控雷达技术(2016年3期)2016-02-06
Coco薇(2015年11期)2015-11-09
第二课堂(课外活动版)(2015年4期)2015-10-21
