
基于非负矩阵分解的群组推荐算法*
2022-05-27 02:05贾俊杰姚叶旺陈旺虎
计算机工程与科学 2022年5期
贾俊杰,姚叶旺,陈旺虎
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
网络信息的爆炸增长,导致人们在选择心仪的商品或服务时极易陷入“信息过载”的窘境。推荐系统作为缓解信息过载问题的重要手段,得到广大学者的研究[1]。该技术通过对用户大量历史行为数据进行深度挖掘,分析出不同用户的偏好与需求,实现向用户精准推送[2]。传统的个性化推荐系统采用协同过滤[3]和矩阵分解[4]等手段,在单个用户的预测评分和推荐方面取得巨大成功,被广泛应用于电子商务、音乐和新闻等领域。
随着交通工具和媒介技术的不断革新,人们之间的交往变得越来越简单、频繁,用户的消费或娱乐行为也越来越倾向于以群组的形式进行,如旅游、聚餐等。多人参与便会产生分歧和冲突,群组更是如此,针对同样的商品,群组内的不同成员往往有不同的意见与喜好。在此情况下,传统的个性化推荐系统无法解决群体内部的偏好冲突问题,群组推荐系统[5]便应运而生。
群组推荐系统的目标是向多用户组成的群组进行推荐,其核心是提取并融合组内不同成员之间的偏好,最大程度地缓解偏好冲突,建立群组模型。目前主流的融合策略有均值策略AVG(AVeraGe strategy)[6]、最小痛苦策略LM(Least Misery strategy)[7]、最开心策略MP(Most Pleasure strategy)[8]、最受尊敬者策略[9]、痛苦避免均值策略[10]和基于以上传统策略的加权结合方法[11,12]等。但是,传统策略往往存在各种弊端,如均值策略仅仅把组内各成员的评分均值作为群组评分进行偏好建模,虽然执行简单,但忽视了成员的贡献度,群组偏好易被贡献度较低的成员扰乱;最小痛苦策略和最开心策略简单选取组内的最低或最高评分作为群组评分,忽视了组内大部分人的喜好,容易带来不公平性问题;最受尊敬者策略以某一成员偏好代表整体,有失偏颇;痛苦避免均值策略通过对超过痛苦阈值的评分求取均值建立群组模型,可以在一定程度上避免恶意评分的干扰,但痛苦阈值的选取需视情况而定,且该策略没有考虑群体成员的整体偏差。
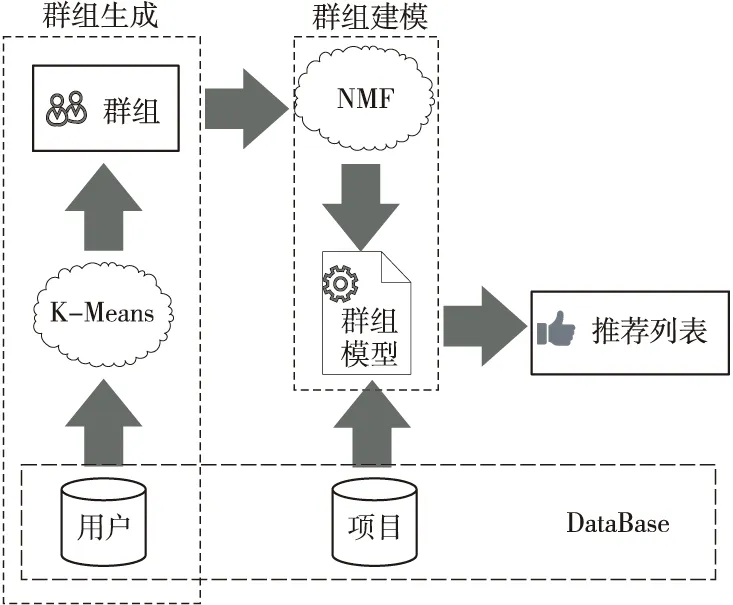
本文在此基础上,提出一种基于非负矩阵分解的群组推荐算法GRBNMF(a Group Recommendation algorithm Based on Non-negative Matrix Factorization)。通过K-Means聚类发现群组,对群组内用户评分矩阵,利用非负矩阵分解得到用户矩阵和项目矩阵。计算项目矩阵中各项目在不同隐含类别下的隶属度和用户矩阵中各成员在不同隐含类别上的专业度,并结合隶属度和专业度得到各成员针对不同项目评分的贡献度,依据成员贡献度对成员偏好加权融合得到群组偏好,由此产生群组推荐列表。相比于传统融合策略,本文算法根据群组中专家成员对整个群组偏好的影响,降低了普通成员对融合结果的干扰。
本文主要贡献如下:
(1)提出了一种群组偏好建模方法,该方法从群组成员对隐含项目类别的专业度出发,通过非负矩阵分解获取组内成员在每个项目上的贡献度,以此为依据构建群组偏好模型;
(2)提出了一种基于非负矩阵分解的群组推荐算法,该算法可以避免非专家成员对融合结果的干扰,解决了一般的群组推荐问题。
2 相关工作
近年来,有许多学者对群组推荐系统进行了深入研究,这些工作的重心基本都是围绕在群组成员的偏好融合方面。
在偏好融合的过程中,根据群组建模发生的时间不同,可将偏好融合分为模型融合和推荐融合,如图1所示。

Figure 1 Schematic diagram of two aggregation methods图1 2种融合方法示意图
模型融合先对成员偏好进行融合构建群组偏好模型,可根据群组模型生成推荐列表;推荐融合是先对群组成员进行个性化推荐,再融合成员个人的推荐结果得到群组推荐结果。2种融合方法的优劣不能一概而论,但其缺点都较为明显,模型融合易受评分稀疏性的影响,推荐融合则忽略了群组之间的交互,因为个人行为易受群体影响[13]。
在融合策略方面的研究中,陈君同等[11]针对旅游组推荐提出一种满意度平衡策略,该策略在融合过程中结合均值策略和最小痛苦策略,提升了群体成员的推荐满意度。陶永才等[12]提出一种混合融合策略,在分歧阈值的两侧分别采用最受尊敬者策略和均值策略完成偏好融合,但阈值的选取往往需视情况而定。针对组内成员的评分预测,郑伟等[14]认为在同一群组中用户的未知偏好会受到组内其他成员的影响,基于此提出了一种偏好预测算法,但该算法时间复杂度较高。Wang等[15]结合信任社交网络对群体成员的偏好进行修正,但通常情况下信任度难以获取,因此该方法并不易于实施。
自从矩阵分解模型在Netflix Prize大赛上一鸣惊人之后[16],人们纷纷展开了将矩阵分解应用于推荐系统的研究。到目前为止,矩阵分解模型已经在个性化推荐系统上取得傲人成绩,但将其应用于群组推荐的算法却寥若晨星。王海艳等[17]受潜在因子模型与状态空间模型启发,提出一种基于动态卷积概率矩阵分解的群组推荐方法,该方法在潜在因子模型下可以充分挖掘用户与服务的隐含关系,帮助生成潜在群组,提高推荐质量。王刚等[18]将群组成员间的关系加入联合概率矩阵分解,提高了群组推荐的准确率。Ortega等[19]在传统矩阵分解基础上,通过计算群组成员对项目的评分数量和评分一致性为候选项目添加权重,再通过融合项目权重进行组推荐。Zhang等[20]在考虑了项目的自然属性以及用户兴趣会随时间发生动态变化的基础上,提出一种按项目加权的矩阵分解模型,通过将该模型与时效函数相结合,提升了群组推荐系统的查全率与查准率。由此可见,矩阵分解模型在群组推荐系统上依然可以发挥其独特的优势[17-20]。但是,传统矩阵分解因为受到初始值和更新方法的显著影响,无法保证获得一个稳定的解,因此也无法建立一个稳定且唯一的群组偏好模型[21]。在Lee等[22]提出非负矩阵分解模型之后,因该模型实现上的简便性,分解形式和分解结果的可解释性,在计算机视觉和数据挖掘等方面得到广泛应用。Wang等[21]利用可分离非负矩阵分解在全局空间上挖掘群组成员的贡献度,并依据成员贡献度对成员评分进行加权融合建立群组偏好模型。该方法在一定程度上缓解了组内矛盾,但其在偏好融合过程中对用户知识背景和项目固有属性(即隐含类别)之间的关系欠缺考虑。
基于以上研究启发,本文考虑从隐含项目类别入手,利用非负矩阵分解分析成员专业度,尝试缓解非专业成员对融合结果的影响,以期建立准确率更高的群组偏好模型,实现高效的群组推荐。
3 相关技术
3.1 非负矩阵分解
矩阵分解将高维用户项目评分矩阵Rm×n分解为2个低维用户矩阵Um×k和项目矩阵Vk×n,其中用户矩阵表示用户对k个隐含项目类别的偏好程度,项目矩阵表示项目在k个隐含项目类别上的隶属程度。通过2个特征矩阵相乘完成对原评分矩阵的拟合,并在拟合过程中对特征矩阵进行不断更新。矩阵分解可以表示如式(1)所示:
Rm×n≈Um×kVk×n
(1)
其中,Rm×n表示原用户项目评分矩阵;Um×k表示用户特征矩阵;Vk×n表示项目特征矩阵;m和n分别表示用户和项目的数量,k为隐含项目类别数量。
非负矩阵分解NMF(Non-negative Matrix Factorization)在矩阵分解的基础上对特征矩阵加上非负的约束条件,即同时要求:U和V中元素不小于0。
这种非负性的约束会导致相应描述在一定程度上的稀疏性,但稀疏性的表述已被证明是介于完全分布式和单一活跃分量的描述间的一种有效数据描述形式,并且这种稀疏性的描述能使对数据的解释变得方便(少量活跃的分量使数据的组成方式变得清晰)与合理(在评分中不可能存在负值)[23]。
为使式(1)最大程度地逼近原评分矩阵,建立的目标函数如式(2)所示:
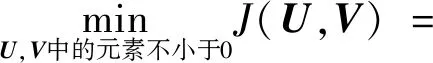
(2)
其中,ri,j表示原评分矩阵中的元素值,β为正则项系数。
根据Lee等[24]提出的乘性迭代规则求解目标函数,最终得到的迭代式如式(3)和式(4)所示:
(3)
(4)
3.2 群组推荐系统
当前,群组推荐系统还没有统一的形式化定义,本文从群组推荐的一般步骤出发对其进行简单阐述。
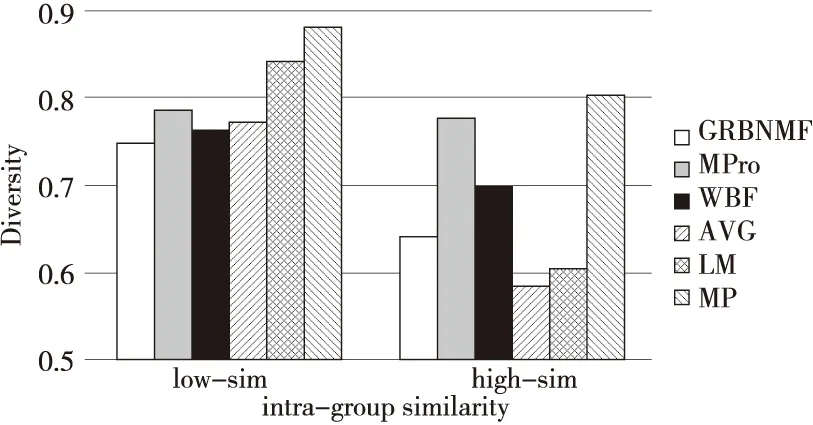
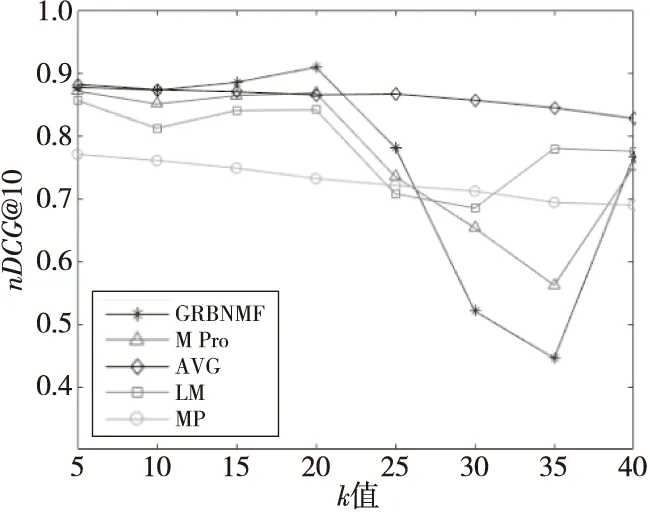
定义1群组G是由若干有偏好意愿的用户组成的集合,G={ui|0 定义2群组偏好profileG,i=∑uu∈Gωu,iprofileu,i,其中profileG,i表示群组G对项目ii的偏好,通常以评分表示;profileu,i表示成员uu对项目ii的偏好;ωu,i是群组G中成员uu在项目ii上的权重,不同的权重可以代表不同的偏好融合策略。如ωu,i≡1/|G|时,上式可以表示均值策略;而当评分最低的成员权重为1,其他成员权重为0时,上式可以表示最小痛苦策略。 定义3Top-N组推荐:群组推荐系统一般将候选项目集中前N个偏好得分最高的项目推荐给群组,候选项目集一般为未被所有成员消费的项目集合。对于给定的群组G,可从候选项目集I中得到一个群组推荐列表IG,如式(5)所示: |IG|=N,∀ii,ij∈I, s.t.profileG,i≥profileG,j,ii∈IG,ij∉IG (5) 且IG中的项目按照群组偏好降序排列。 在群组推荐系统中,推荐结果的好坏不仅依赖于偏好融合策略的设计,而且在很大程度上受到组内相似度的影响。一般而言,组内相似度越高,群组的偏好冲突就越小,对推荐结果的整体满意度也就越高。而相对地,组内相似度越低,说明组内成员的兴趣爱好大相径庭,正所谓众口难调,在此情况下,群组对推荐结果的满意度往往也比较低。因此,发现内部更为相似的群组对提高推荐结果的满意度有着至关重要的作用。 K-Means聚类算法因其实现简单、收敛速度快的优势,成为最常用的聚类算法之一。本文根据文献[25],以用户评分向量之间的Pearson相关系数为度量,采用K-Means对评分数据集中的用户进行多次聚类,生成大小不一的多个群组。Pearson相关系数的计算公式如式(6)所示: sim(uu,uv)= (6) 通常,评分数据集中用户数量远少于项目数量,因此一般的评分数据集往往稀疏度都非常高,同时Pearson相关系数的计算非常依赖共同评分项。为缓解评分稀疏对用户聚类结果的影响,在对用户聚类之前先对项目聚类,使相似项目位于同一个簇中。之后,计算用户对每个项目簇的评分均值作为用户的评分向量,减少用户的空白评分,使Pearson相关系数的计算更加准确。最后,对用户进行聚类产生群组。由于一个用户可以属于多个群组,反复执行聚类过程产生大量群组。假设原评分数据如表1所示。 Table 1 Rating table表1 评分表 先对表1中项目进行聚类,假设项目聚类结果为S1={i1,i2,i3,i4,i5}和S2={i6,i7,i8,i9,i10}。然后对各项目簇的评分取均值可实现用户评分向量的降维,如用户u1降维后的评分向量就是[3.2,1.4]。在此基础上对用户聚类,假设表1产生G1={u1,u2,u3,u4}和G2={u5,u6,u7,u8}2个群组。算法的具体描述如算法1所示。 算法1群组发现算法 输入:评分矩阵Rm×n,项目种类p,群组数量q。 输出:q个群组。 步骤1K-Means(items);//items为R中的所有项目 步骤2 Foruuinusers://users为R中的所有用户 步骤3ru=[avg(rcluster1),avg(rcluster2),…,avg(rclusterp)];/*clusterp为项目聚类后第p个项目簇*/ 步骤4 EndFor; 步骤5K-Means(users);//对降维后的用户进行聚类 步骤6 Returnqgroups。 在实际生活中,一个项目通常具有多个属性,如一部电影,它可以属于某个年代,也可以属于某几种类型。在群组决策的过程中,针对不同的项目属性,成员之间的话语权往往各不相同。一般情况下,对于项目所涉属性具有较多专业背景知识的成员话语权更高,在决策过程中的贡献度也更高,决策结果也常倾向于此。通常,用户专业程度与其兴趣度成正比,而用户兴趣度常以用户特征矩阵中的偏好值表示。 本文算法通过分析群组成员对隐含项目类别的专业程度,使偏好融合的结果倾向于更为专业的成员。通过预测评分矩阵对原评分矩阵中的空值填充得到填充评分矩阵,针对成员专业背景知识对群组偏好的影响,通过项目矩阵计算项目在各隐含项目类别下的隶属度,并结合各成员在用户矩阵计算得到的各隐含类别上的专业度,形成成员在各项目上进行偏好融合的贡献度,根据成员贡献度对成员偏好加权融合得到群组偏好。 通过表1所得群组G1={u1,u2,u3,u4}作为示例进行演示,利用NMF建立群组偏好模型的步骤如下所示: 步骤1填充评分矩阵。 对于一个给定群组G,设其评分矩阵为RG∈R|G|×n,如式(7)所示: (7) 其中,|G|表示群组规模,n表示项目数量,ri,j表示成员ui对项目ij的评分。 对RG进行非负矩阵分解得到用户矩阵UG∈R|G|×k和项目矩阵VG∈Rk×n,分别如式(8)和式(9)所示: (8) (9) 其中,k为隐含项目类别数量,且k≤|G|≼n;ui,x表示成员ui对隐含项目类别x的偏好值;ix,j表示项目ij在隐含类别x上的属性值。 则对群组G1有: (10) 设k=2,对RG 1分解可得(四舍五入保留2位小数): (11) (12) (13) (14) 经上述步骤可得G1的填充评分矩阵RFG 1如式(15)所示: (15) 步骤2计算项目隶属度和成员专业度。 通过项目矩阵可计算项目ij在隐含项目类别x下的隶属度iweight(j,x),如式(16)所示: (16) 上述矩阵VG1中,i1在2个隐含项目类别下的值分别为2.28和0.16,计算得到总属性值为2.44,之后可得iweight(1,1)=2.28/2.44=0.93,iweight(1,2)=0.07。 项目的属性权重面向的是隐含项目类别,与之不同是,成员专业度的权值计算面向的是群组。因此,可通过用户矩阵得到成员ui对于隐含项目类别x在群组G中的专业度uweight(i,x),如式(17)所示: (17) 例如,在矩阵UG1中,4位成员在隐含项目类别1上的总偏好值为1.84+0.17+1.24+2.55=5.8,可计算得到uweight(1,1)=1.84/5.8=0.32。 步骤3得出成员贡献度矩阵。 以上可得项目隶属度矩阵VW∈Rk×n和成员专业度矩阵UW∈R|G|×k分别如式(18)和式(19)所示: (18) (19) 在矩阵VW中,每一列表示项目在不同隐含类别(属性)下的隶属度;在矩阵UW中,每一行表示群组成员对于不同隐含项目类别在群组中的专业度。因此,通过UW和VW2个矩阵点积可得群组成员对于不同项目在群组中所占权重,以此表示各成员在不同项目上偏好融合时的贡献度,即: UIW=UW·VW= (20) 其中,weight(i,j)表示群组G中成员ui对于项目ij在偏好融合时的贡献度。 对群组G1,通过步骤3可得项目隶属度矩阵VWG1和成员专业度矩阵UWG1,分别如式(21)和式(22)所示: VWG1= (21) (22) 通过式(21)和式(22)中2个矩阵可得成员贡献度矩阵(四舍五入保留2位小数),如式(23)所示: UIWG1= (23) 步骤4群组偏好。 此时,将G中所有成员对项目ij填充后的评分与其贡献度相乘的结果进行累加,得到群组G对项目ij的评分rG,j,即群组偏好,如式(24)所示: (24) 如计算群组G1对项目i1的评分,如式(25)所示: rG1,1=0.31×5+0.06×0.82+ 0.22×4+0.41×5=4.53 (25) 根据式(24),在计算G对候选项目评分的过程中即可建立群组偏好模型。 通过上述方法完成群组建模之后,便可在群组偏好中选取前N个评分最高的项目进行推荐。本文所提GRBNMF算法的框架图如图2所示。 Figure 2 Framework diagram of GRBNMF algorithm图2 GRBNMF算法框架图 在第1阶段,通过K-Means算法对用户聚类发现潜在群组;在第2阶段中,采用NMF模型对群组评分矩阵进行分解,从成员知识背景和项目固有属性之间的关系出发,获得了群组成员对不同项目的贡献度,依据成员贡献度构建了群组偏好模型;在第3阶段,通过群组模型生成了Top-N推荐列表。 本文算法(GRBNMF)的具体描述如算法2所示。 算法2GRBNMF算法 输入:群组G的评分矩阵RG,隐含项目类别数量k,候选项目集I,推荐数量N。 输出:Top-N推荐列表。 步骤1NMF(RG); 步骤2RFG←U·V;//对RG中的空值赋值 步骤3UW←U,VW←V; 步骤4UIW=UW·VW; 步骤5 ForiiinI: 步骤6rG,i=∑uu∈Gweight(u,i)·rfu,i; 步骤7 Endfor; 步骤8sortedrG,iby descending order; 步骤9selectNhighest items; 步骤10ReturnTop-Nlist。 本文使用MovieLens公开电影评分数据集进行实验验证,它分为多个版本,本文实验所使用的ML-100K数据集信息如表2所示,其它的信息还包含每个电影的标签、每个用户的职业、年龄、邮编等个人信息。本文在实验中将数据集按照8∶2的比例分为训练集和测试集,将算法在训练集上进行训练,训练完成之后在测试集上进行验证。 Table 2 ML-100K data set information表2 ML-100K数据集信息 (1)推荐准确率。 归一化折损累计增益nDCG(normalized Discounted Cumulative Gain)是评价推荐系统的常用指标,被广泛用于衡量群组推荐的准确率。每个用户的nDCG的计算如式(26)和式(27)所示: (26) (27) 其中,DCG@N表示用户对推荐列表中N个项目的真实评分与其在列表中相对位置的满意程度,reli表示用户对推荐列表中排名第i的项目的评分。IDCG@N是最好情况下的DCG@N的值,即推荐列表对于用户个人而言是按照评分降序进行排列的。 nDCG@N由DCG@N和IDCG@N的比值得来,其取值在0~1,且nDCG@N越大,说明用户对推荐列表的满意度越高,推荐效果越好。实验中计算群组内每个成员的nDCG@N的值,以均值表示群组的nDCG@N值。 (2)推荐列表多样性。 推荐列表的多样性是指推荐列表内的项目在种类或类型上彼此不同,多样性越高,说明推荐列表的质量越高,推荐效果越好。本文使用Jaccard距离来计算推荐列表多样性,具体如式(28)和式(29)所示: (28) (29) 其中,distanceJac(ij,il)表示两者之间Jaccard距离,ijgenre表示项目ij包含的类型。 群组推荐的结果受群组特征的影响,群组特征主要包括群组规模(group size)和组内相似度(intra-group similarity)[26]。群组规模表示组内成员个数,组内相似度指群组中任意2个用户相似度的最小值[26]。本文首先从群组特征的2个方面出发,针对均值策略AVG[6]、最小痛苦策略LM[7]、最开心策略MP[8]以及Ortega等[19]提出的WBF(Weighted Before Factorization)算法,验证本文GRBNMF算法的可行性。 同时,为探究项目隶属度和成员专业度对本文算法的影响,在对比实验中设置基于成员专业度MPro(Member Professional degree)的方法,该方法忽略项目的多元属性,并将其归为隶属度最大的一类,针对该类别下成员专业度进行偏好融合生成群组推荐列表。忽略成员专业度的偏好融合方法即为均值策略。 此外,在研究不同算法在不同群组规模下的推荐性能时,针对群组的产生方式,设置2类由不同方法发现的群组,即本文群组发现算法产生的群组(group size-Simi)和随机产生的群组(group size-Rand),以评估群组发现算法对群组推荐效果的影响情况。 最后,因为本文算法基于非负矩阵分解,所以在验证算法在不同群组特征下的可行性之后,探究不同k值对算法的影响也是非常必要的。 5.3.1 群组规模 为研究不同算法在不同群组规模下的推荐性能和群组发现算法对推荐效果的影响,从由群组发现算法产生的群组和随机产生的群组中随机选择不同规模的群组进行实验。选取群组规模从5开始,间隔为5,直到30为止。实验中推荐列表长度N取10,正则项系数β为0.005,矩阵分解最大迭代次数设置为1 000,k值随群组规模改变,但所有算法都是基于同一个分解结果,因此并不影响。 (1)推荐准确率。 根据图3得到的实验结果,横向来看,在由群组发现算法产生的群组中,本文算法除了在群组规模为10和30时推荐准确率略低之外,在其他情况下均明显高于其他对比算法。尤其在群组规模为20时,本文算法推荐准确率较均值策略提高6%,较最小痛苦策略则提高了9.2%。在由随机产生的群组中,本文算法在推荐准确率方面普遍优于其他算法,这是因为随机产生的群组组内相似度普遍较低,内部偏好冲突较大,而本文算法通过选取专家成员缓解了内部冲突,使推荐准确率保持在较为稳定的水平。而推荐准确率总体呈现一种先上升后下降的趋势,这是因为在选择群组规模时没有考虑组内相似度。从纵向观察可知,推荐准确率受组内相似度的影响较大,这也从侧面表明群组推荐的效果受群组发现算法的影响显著。 Figure 3 Accuracy rate under different group sizes图3 不同群组规模下的推荐准确率 (2)推荐列表多样性。 推荐列表多样性通常与准确率负相关,从图4的实验结果可以看出,本文算法在准确率明显高于其他算法的情况下,多样性常介于其他算法之间。在群组规模为15时,本文算法在准确率高于其他算法的情况下,多样性也高于其他算法。这是因为本文算法能够充分分析成员偏好及其贡献度,使得每位成员喜欢的项目都有可能被推荐。在群组规模为10时,本文算法在牺牲较低准确度的情况下,换来了多样性的极大提升。 Figure 4 Diversity under different group sizes图4 不同群组规模下的推荐多样性 结合图3和图4来看,本文算法能够在不同的群组规模下发挥较好的推荐性能。最开心策略在上述实验中表现较差,这是因为在选择不同的群组规模时无法保证组内相似度的一致性,而组内相似度也会对推荐结果造成一定的影响。 5.3.2 组内相似度 为了探究组内相似度对推荐结果的影响并从多方面衡量本文算法的优劣性,设置相似度阈值为0.4,将相似度低于此阈值的群组设为低相似度群组,高于的则记为高相似度群组,群组规模固定为12,其余参数与上文一致,进行如下对比实验。 (1)推荐准确率。 从图5的实验结果可看出,本文算法无论在高相似度群组还是在低相似度群组中都有着较高的推荐准确率。尤其在组内相似度较低时,本文算法的推荐准确率高于基于成员专业度的算法10%,高于WBF 7%,高于均值策略和最小痛苦策略13%和25%,有着较为稳定的发挥。这是因为本文算法从隐含项目类别对群组成员的知识背景进行了详细分析,使得群组模型在专家成员的影响之下更为准确。总体来看,推荐准确率与组内相似度之间呈现一种正相关,组内相似度越高,推荐准确率就越高。 Figure 5 Accuracy rate under different intra-group similarities图5 不同组内相似度下的推荐准确率 另外,结合图5和图3b来看,即使是在图5的低相似度群组中,推荐列表准确率依旧显著高于图3b中群组的推荐列表准确率。这说明由群组发现算法得到的即便是低相似度群组,其组内相似度依旧显著高于随机产生的群组,这也从侧面反映了本文群组发现算法对潜在群组的挖掘能力。 (2)推荐列表多样性。 从图6的实验结果来看,本文算法在组内相似度较低时,推荐列表多样性是最低的,相较于基于成员专业度的算法、WBF方法、均值策略和最小痛苦策略分别低了5.3%,2.6%,2.7%和12%,但这些与准确率的提升相比显得微不足道。在组内相似度较高时,本文算法的推荐列表多样性介于其他算法之间,且表现较好。 Figure 6 Diversity under different intra-group similarities图6 不同组内相似度下的推荐多样性 总结图5和图6的实验结果可以看出,本文算法在组内相似度低和高时都可以发挥出色的推荐性能。 5.3.3k值 非负矩阵分解模型要求k的取值要小于或等于矩阵维度,因此,为了更好地观察k值对本文算法的影响,选取规模较大的群组进行多次实验。在实验中选择群组规模为50的10个群组,获取每个群组在对应k值下的推荐准确率,以均值表示不同算法在该k值下的推荐准确率。由于WBF基于传统矩阵分解,所以不在本次实验范围之内。推荐数量N取10,非负矩阵分解参数与上文保持一致,实验结果如图7所示。 Figure 7 Accuracy rate under different k values图7 不同k值下的推荐准确率 从实验结果中可以看到,本文算法受k值影响较大,这是因为如果k值选取不当,会使成员贡献度计算失真,进而使群组模型偏差较大,降低推荐质量。从图7中可以看到,均值策略几乎不受k值影响,这是因为均值策略将所有成员贡献度视为一致,从而摆脱了参数k的影响,其曲线略微波动是因为在不同的k值下得到的预测评分不同。但可以看到的是,在k值为[5,20]时,本文算法推荐准确率呈上升趋势且高于其他算法,尤其在k值为20时,准确率大幅高于其他算法,这是因为候选项目类别约为20种。因而可得,当k值较为准确时,本文算法可以展现出色的推荐性能。 本文提出了一种基于非负矩阵分解的群组推荐算法,该算法从成员知识背景和项目固有属性之间的关系出发,利用非负矩阵分解深入分析了群组中各成员在偏好融合时的贡献度,建立了更加准确的群组偏好模型。之后,依据群组偏好模型产生了推荐列表。在MovieLens数据集上的实验结果表明了本文算法的有效性。 尽管本文利用非负矩阵分解可以有效分析成员贡献度,提高推荐性能,但通过矩阵分解得到的预测评分无法体现群组成员之间的交互和影响,如何将成员之间的交互加入矩阵分解模型,进一步提高群组推荐的准确率,将会是下一步研究目标。4 GRBNMF算法步骤与示例
4.1 群组发现
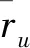

4.2 群组偏好建模

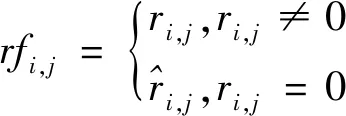

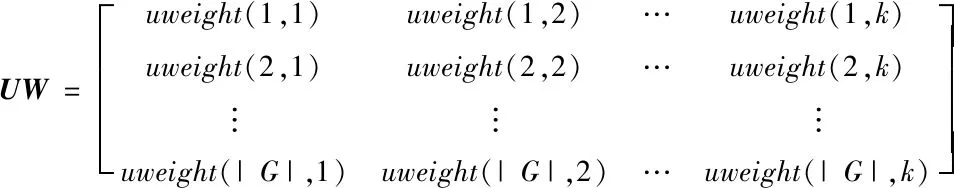



4.3 群组推荐
5 实验与结果分析
5.1 数据集介绍

5.2 评价指标
5.3 实验设置与结果分析



6 结束语
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
课程教育研究(2020年7期)2020-04-21
网络安全技术与应用(2019年5期)2019-06-05
考试周刊(2016年80期)2016-10-24
现代教育科学·中学教师(2015年2期)2015-10-21
现代教育科学·中学教师(2015年3期)2015-10-21
