
基于宽度学习的注塑产品质量预测方法
2022-05-31 06:19林江豪吴宗泽李嘉俊谢胜利
电子与信息学报 2022年5期
林江豪 吴宗泽 李嘉俊 谢胜利③
①(广东工业大学自动化学院 广州 510006)
②(广东外语外贸大学语言工程与计算实验室 广州 510006)
③(广东工业大学粤港澳离散制造智能化联合实验室 广州 510006)
1 引言
塑料制品具有质量轻、绝缘和耐腐蚀等优点,已广泛应用于航空航天、高铁、通信、新能源、物流和日常生活等多个领域。注塑产品的质量容易受注塑机工艺参数设定、模具状态等诸多因素的影响。产品质量预测可应用于实际注塑工业场景中的缺陷自动发现,及时停止缺陷产品生产,降低生产损失,因此要求模型结构简单、计算效率高,以满足快速的系统响应,实现产品缺陷的实时预警。同时,要求模型具有稳健性,确保缺陷预警的真实性,降低系统漏报、错报造成的生产损失。
常见的注塑产品质量缺陷有产品缩水、变形等多种。在现有的注塑产品质量预测研究中,主要选择如宽度、厚度和质量作为模型的预测目标,采用回归预测的方法来解决。传统的基于机器学习的方法主要有支持向量机(Support Vector Machines,SVM)[1]、最近邻算法(K-Nearest Neighbor,KNN)[2]、人工神经网络(Artificial Neural Network, ANN)[2–5]、轻量梯度提升机(Light Gradient Boosting Machine, LightGBM)[6,7]等。近年来以神经网络方法为主,Ogorodnyk等人[2]提出了采用多层感知机(MultiLayer Perceptron, MLP)来实现产品宽度和厚度的预测方法。文献[3,4]采用反向传播(Back Propagation, BP)网络来进行质量参数的建模。文献[5]结合径向基函数(Radial Basis Function,RBF)神经网络模型和多岛遗传算法(Multi-Island Genetic Algorithm MIGA)对注塑过程的最优参数寻找进行建模。文献[6,7]对LightGBM算法优化过程进行改进,实现更精准的注塑成型产品质量预测模型。传统机器学习的模型比较简洁,满足了实时计算的需求。然而,实际生产过程中,容易出现训练数据以外的离群点,属于典型的零样本或者小样本的问题,传统机器学习方法难以解决,表现出模型泛化能力不足的缺陷,而对离群点的预测是产品质量检测的核心。
随着基于深度学习的计算视觉技术发展,利用电荷耦合器件(Charged Coupled Device, CCD)图像传感器采集产品外观的多角度图像,基于深度神经网络模型构建缺陷分类器是可行的,主要以卷积神经网络(Convolutional Neural Networks, CNN)[8,9]或CNN与如门控循环单元(Gated Recurrent Unit, GRU)[10]的其他深度神经网络结合作为产品缺陷图像的特征提取器,进而训练分类器来进行注塑产品缺陷类别的自动分类。基于深度学习的方法虽然保证了准确率,但数据采集困难、特征提取复杂、不能针对生产场景灵活转变,并且大规模的参数学习,学习的时间成本非常高,属于典型的数据饥饿模型,需要大量的标注数据来进行模型训练才能获得稳定而有效的模型,然而在实际工业应用中获得大规模的缺陷标注数据显然是不现实的。
综合以上,现有基于机器学习和深度学习的注塑产品质量预测方法推动了注塑行业智能化和自动化,但模型仍存在泛化能力不足、灵活性不够、训练成本高等缺陷。文献[11]提出的宽度学习系统是基于随机向量函数链接网络的平行网络(Random Vector Functional Link Neural Networks,RVFLNN),已被证明具有通用的逼近能力[12]。文献[13]提出了采用最小p-Norm的方法优化参数矩阵W,在拟合sinc函数实验发现,在数据中的噪声分布不确定情况下,调节p值可以保持模型良好的鲁棒性。宽度学习具有结构简单、训练速度快、泛化性能好等优势。因此,本文以注塑产品质量的3维尺寸作为预测目标,提出一种基于宽度学习方法的注塑产品质量预测模型,主要创新工作可概括为以下3个方面:
(1)提出一种基于BLS的注塑产品尺寸预测方法,通过引入p范数提升宽度学习系统(Broad Learning System, BLS)模型应对异常数据和小样本数据的能力,提升模型的鲁棒性。
(2)介绍了一种基于相关系数矩阵的特征选择方法。对高频传感器数据、spc数据、注塑机台参数、产品质量数据进行预处理,利用相关系数进行特征筛选,并计算衍化特征,最后获得预测模型的输入特征。
(3)在注塑成型工艺品尺寸预测数据中进行实验,实验结果表明,本文所提方法确实能提高注塑产品尺寸预测的准确性。在实际的注塑产品缺陷自动发现中,能更好地预测小样本异常尺寸。
本文其余部分组织如下:首先,在第2节主要介绍特征筛选的方法和结果。然后,在第3节提出基于最小p范数的宽度学习在注塑产品尺寸预测中的建模方法。接着,在第4节中对实验结果进行分析。最后第5节对全文工作进行总结。
2 特征选择
2.1 数据来源
本文使用第4届工业大数据竞赛题目《注塑成型工艺的虚拟量测和调机优化》中任务A-虚拟量测的数据1)https://www.industrial-bigdata.com/Home,数据集提供了每个批次产品的生产过程数据,以及工艺参数的调机记录,并给出了每个模次生产的注塑产品的尺寸测量信息。数据的简单描述如下:
(1)传感器高频数据(data sensor):该数据来自于模温机及模具传感器采集的数据,单个模次时长为40~43 s,采样频率根据阶段有20 Hz和50 Hz两种,含有24个温度、压力等传感器数据,是连续的数据。
(2)成型机状态数据(data spc):该数据来自成型机机台,均为表征成型过程中的一些状态数据,数据维度为86维。每个模次记录1次数据,数据是离散的。
(3)机台工艺设定参数(data_set):注塑成型的81种工艺设定参数,这部分数据是在注塑机参数调整的时候产生,只在参数变化时记录,属于离散数据。
(4)产品测量尺寸(size data):每个模次产品的3维尺寸,记为size1, size2和size3。size1∈[299.85,300.15],size2∈[199.925,200.075] 和size3∈[199.925,200.075]分别是size1, size2和size3的合格范围。数据统计显示,异常数据占比非常低,高于上限的异常尺寸产品数量占比分别为2.73%, 11.86%和5.78%;低于下限的异常产品数量分别占比为0%, 2.01%和0.44%,属于典型的不平衡小样本数据,符合实际生产环境中数据的采集特点,模型计算结果更接近实际场景。
2.2 特征选择方法
为了对特征数据降维,采用基于斯皮尔曼(spearman)相关性系数矩阵的特征筛选方法2)https://github.com/chuangwang1991/VirtualMeasurement molding,如图1所示。对采集到的不同特征数据进行处理,包括数据清理、合并和衍化特征计算。具体处理的过程:首先删除data_sensor中存在空值和单一值的维度,计算每个模次中data_spc中传感器采集数据的平均值作为整个周期的值,作为模型的基础特征。将得到的基础特征分别与每个目标尺寸进行斯皮尔曼相关性系数分析得到相关矩阵,并利用训练集和测试集的数据分布差异,选择合适的基础特征。接着,删除data_set中的空值和单一值的维度,并计算衍化特征。随后,计算每个调机段中各个size的衍化特征。最后,将提取到的各类特征链接起来,作为总的特征提取结果。
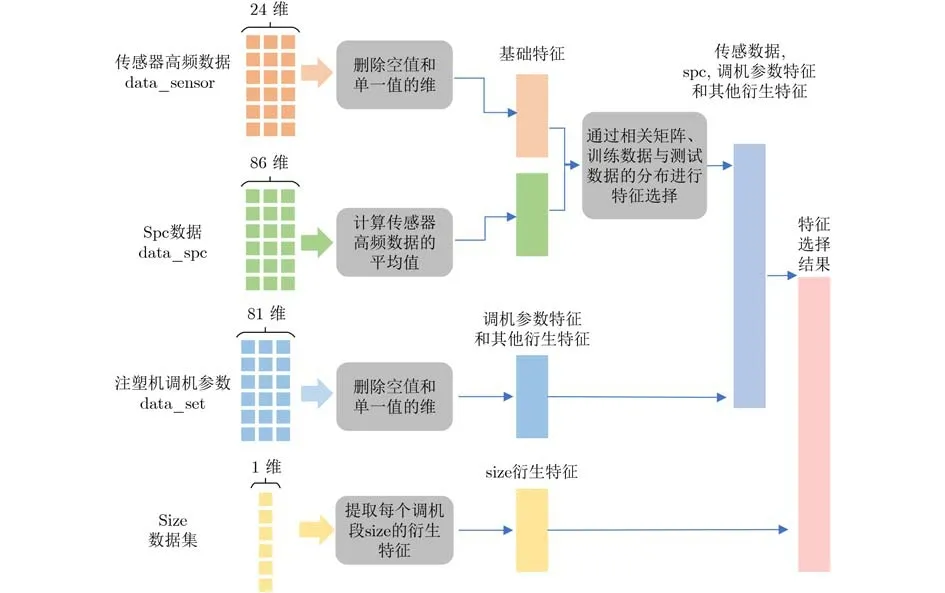
图1 特征提取过程
经过特征提取后,获得size1, size2, size3对应的模型特征如表1所示,其中“√”表示使用了该特征,“×”表示未使用该特征,最终的特征维数分别是21, 22和21,主要特征内容为时间、压力、温度和速度这4类参数。

表1 特征选择结果
3 基于最小p-范数宽度学习的注塑产品尺寸预测模型
3.1 基于BLS的注塑产品尺寸预测方法
注塑成型产品尺寸预测任务属于回归预测任务,对传感器高频数据、spc数据、机台工艺设定参数等数据进行特征提取,得到特征矩阵X,X经过BLS的特征层线性映射后,再通过增强层的非线性转换,最后将特征层和增强层的输出共同输入到输出层,得到BLS的预测结果。如图2所示,BLS简化了随机向量函数连接网络 (Random Vector Functional-Link Neural Network, RVFLNN)的网络结构,将增强节点和特征节点并列到同一层,主要优势有:(1)增加隐藏层节点的数量,真正实现将网络向宽度方向扩展;(2)输入数据经过特征映射和增强映射两次变换,增强了网络的特征提取能力。
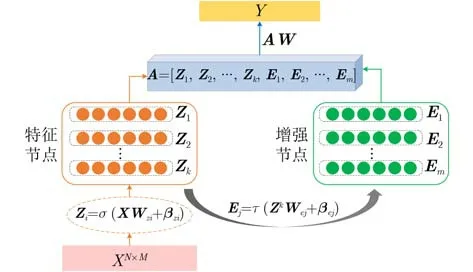
图2 宽度学习网络结构


3.2 基于最小p范数宽度学习的注塑成型工艺尺寸预测方法


表2 基于BLS的产品尺寸预测模型训练


4 实验结果与分析
4.1 基线模型
(1)支持向量机(SVM)[7]:能解决高维特征的回归问题;仅依靠支持向量来决定超平面,无需依赖全部数据;有多种核函数可以选择,从而可以更灵活地解决各种非线性的回归问题;在注塑成型质量预测的小样本数据中,具有更强的泛化能力。
(2) K近邻(KNN)[6]:通过找出一个样本的k个最近邻居,将这些邻居的某些属性的平均值赋给该样本,就可以得到该样本对应属性的值,模型比较简单,无需估计参数,重新训练代价低。
(3) 多层感知机(MLP)[6]:MLP是3层及以上的前馈神经网络,层与层之间是全连接,利用激活函数来对节点信息进行非线性激活,隐藏层的神经元数量是可设置的,可采用误差逆传播方法来进行优化。
4.2 评价标准
选用均方误差(Mean Squared Error, MSE)作为模型的评价标准,如式(16)所示,MSE是将所有预测结果与实际结果之间误差平方后求平均所得,常用于评估回归模型的性能。

表3 基于pN-BLS的产品尺寸预测模型训练

4.3 参数选择
4.3.1 SVM
对比了linear,rbf,poly和sigmoid 4种不同核函数在数据集上的表现,发现核函数poly在size1,size2, size3 3个尺寸的回归预测中,均可取得最小的MSE值。因此该文最终选择poly作为SVM的核函数,并设置核函数的度为3。
4.3.2 KNN
针对KNN模型,为了选择合适的最近邻数(nneighbors),通过设置n-neighbors从3~99,步进为2,实验结果发现n-neighbors对size1,size2,size3预测的MSE具有相同的趋势,随着n-neighbors逐步增加,MSE的值逐步变小,并趋向于稳定。相比而言,size1对n-neighbors更敏感,n-neighbors对size3的影响最小,根据实验记过,最终设置nneighbors=99。
4.3.3 MLP
设计包含输入层、隐藏层(N1) 、隐藏层(N2)、输出层共4层结构的MLP神经网络,采用tanh激活函数,设置alpha=1e-6。对隐藏层的最优节点数,采用网格搜索法来确定,设置每一个隐藏层的神经元数3~101,步进为2。实验结果发现N1<10时,对size1,size2和size3的预测影响都比较大,说明了第1个隐藏层神经元数需要尽量大一些,能更充分地学习输入层的信息。通过搜索,最终确定预测size1,size2和size3的最优N1和N2组合分别为(71,5),(83, 21),(43, 55)。
4.3.4 BLS
采用网格搜索法确定最优(q,k,r)组合,特征层的特征组数q和特征节点数k的搜索范围都是[2:1:1 1],增强层的节点数搜索范围设置为[3:2:101],设置正则化参数λ=2−30。实验结果表明,size2对 (q,k,r)的变化更为敏感,相比而言,size1和size3在r>20时,更为稳定。通过实验获得(q,k,r)对size1,size2和size3的最优组合分别是(8,10, 97),(10, 10, 95)和(9, 8, 93)。
4.4 实验结果
选择SVM, KNN, MLP, BLS和pN-BLS中p-norm值分别为0.1, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0时,模型的最优预测结果,如表4为size1, size2,size3对应的预测MSE值。从实验结果可以看出,相比SVM, KNN, MLP的预测结果,BLS和pN-BLS性能都有大幅度的提升,这说明了宽度学习方法可以有效地应用于注塑产品的质量预测。

表4 预测结果
对size1的预测,普通的BLS在q=8, k=10,r=97时取得最优的结果MSE=0.000548。在加入p进一步约束异常值的影响后,pN-BLS比BLS的效果普遍要好,当p=1.5, q=10, k=5, r=93时,最小的MSE=0.000187,相比BLS有较大幅度的性能提升。对size2的预测,当p=1.5, q=6, k=10,r=69时,pN-BLS预测的MSE=0.008483,取得最优效果;在q=10, k=10, r=95时的BLS预测的MSE=0.010706,比pN-BLS略差。对size3的预测,取p=1.5, q=10, k=2, r=89时pN-BLS的MSE=0.000178,而q=9, k=8, r=93时BLS预测结果的MSE=0.000385。综合以上,p=1.5时,pNBLS总能达到一个很小的MSE。本文提出方法的优势主要包括3个方面:(1)特征节点和增强节点能有效提取输入数据的特征。(2)BLS能有效通过岭回归求解违逆矩阵,防止回归模型过拟合。(3)p=范数的引入可有效提升BLS对抗复杂噪声的干扰能力,提高模型的稳定性。
4.5 预测时间的对比
理论上,只要设计合理的训练目标函数,模型的训练时间足够长,模型都可以达到收敛效果。现有的研究为了体现算法的计算优势,更多关注模型在训练时间训练上的优势,而不是预测时间。然而,在注塑产品缺陷检测应用中,预测时间代表了模型的响应速度,预测时间越短表示响应越及时,对工人及时发现缺陷产品,及时调整机器参数,降低生产损失有重要的价值。因此,本文更关注的是预测时间,选择每种模型中的最优参数,对比了不同模型在预测数据集上的时间表现,结果如表5所示,与其他传统学习方法相比,宽度学习方法在响应速度上有显著的优势,特别是pN-BLS (p = 1.5)预测速度具有明显的优势。主要原因是宽度学习的结构优势,通过矩阵计算的方法,能快速并行计算的大批量的输入数据并得到预测结果,也说明了宽度学习的方法在注塑产品缺陷检测中的应用具有响应速度快的优势。

表5 预测时间(s)
4.6 注塑产品缺陷发现应用
为了对比不同方法在实际的产品缺陷发现应用中的效果,本文设置SVM, KNN, MLP, BLS和pN-BLS的最优参数,预测结果如图3所示。
图3中,绿色的线表示真实的尺寸数据,蓝色的线表示预测结果。两条红色虚线之间的属于正常尺寸的注塑产品,两条红色以外的点表示尺寸不合格。红色的“●”是真实数据中的不合格尺寸,黑色的“●”点表示预测到的不合格尺寸。绿色的“●”和蓝色的“●”分别表示实际的合格尺寸和预测的合格尺寸。从中可以观察到,BLS和pNBLS都与真实尺寸的曲线更接近,对于异常值的发现更精准。观察发现不同模型对高于上限的不合格尺寸预测比较准确,对低于下限的尺寸预测要差一些。分析数据发现,大部分的不合格尺寸都是超过上限,如3个尺寸数据中,只有size2存在少量的低于下限尺寸的不合格样本。这种训练数据严重不平衡的现象,导致模型容易产生过拟合,影响了预测的准确性。图3中pN-BLS能更准确预测出部分低于下限的不合格尺寸,说明在引入p范数后,pN-BLS能有效降低异常值对模型的影响,这对实际注塑产品缺陷检测应用是非常有价值的。

图3 注塑产品异常尺寸预测结果
5 结论
注塑产品缺陷自动检测一直以来都是注塑工业智能化发展的关注点。本文提出基于最小p范数宽度学习方法的注塑产品尺寸预测方法。首先,对采集到传感器高频数据、成型机状态数据、机台工艺设定参数和产品的3维尺寸进行数据预处理,并计算了衍生特征,采用了相关系数矩阵进行特征筛选,获得3个尺寸对应的最优特征,实现对采集数据的特征选择与降维。接着,采用pN-BLS模型对注塑产品的3维尺寸分别进行回归预测,这种方法的输入特征与预测的目标尺寸之间是强相关的关系。最后,以SVM, KNN, MLP为基线模型,在第4届工业大数据创新竞赛-赛题二注塑成型工艺的虚拟量测数据中,评估了不同模型参数对尺寸预测的影响,选择最优效果的参数,进行模型的对比验证,包括预测的MSE和预测时间。具体的结果可总结如下:
(1)训练数据集和测试数据集均是8300组。在训练数据中训练并评估获得每种方法的最优参数后,对比不同方法预测MSE发现,BLS和pNBLS比SVM, KNN, MLP都有明显的优势。pN-BLS对size1, size2和size3的预测MSE分别是0.000187(p=1.5, q=10,k=5,r=93),0.008483 (p=1.5, q=6,k=10, r=69)和0.000178 (p=1.5, q =10, k=2,r=89),与其他方法相比均有显著的优势。说明了宽度学习方法可以有效应用到注塑产品尺寸回归预测中,p范数引入能优化BLS在回归预测任务中的应用,能约束异常数据对BLS的影响。同时,在模型预测响应方面,pN-BLS的响应速度最快。
(2)本研究还对比了不同方法在注塑产品质量自动检测方面的应用。结果发现,BLS和pNBLS的预测曲线与实际的尺寸曲线要比其他方法要更接近。但是相比BLS而言,pN-BLS能更好应对不平衡的训练数据的影响,对少样本的不合格尺寸的预测效果比BLS要好,也说明了引入p范数可提升模型的鲁棒性,这对注塑产品质量异常检测很有价值。
(3)通过特征筛选,最终选择17个基础特征,2个调机参数特征和4个衍生参数,其中8个不同位置温度传感器特征,6个不同压力传感器的特征。从特征选择结果来看,影响注塑成型产品质量最关键的参数是温度和压力。在注塑产品缺陷自动检测实际应用中,在其他注塑机上安装传感器采集数据时,可重点采集温度和压力参数,减少其他不必要的传感器,降低采集成本和数据处理成本。当注塑机出现产品缺陷时,也应该首先考虑温度和压力的设置问题,这对快速发现和解决生产问题是非常有价值的。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
China’s foreign Trade(2021年6期)2021-12-26
汽车与新动力(2017年3期)2017-06-29
中华奇石(2015年7期)2015-07-09
中华奇石(2015年5期)2015-07-09
人生十六七(2015年5期)2015-02-28
销售与市场·管理版(2009年21期)2009-09-03
