
复杂场景点云数据的6D位姿估计深度学习网络
2022-05-31 06:19陈海永李龙腾
电子与信息学报 2022年5期
陈海永 李龙腾 陈 鹏 孟 蕊
(河北工业大学 天津 300130)
1 引言
随着技术的进步,机器人在抓取、装配、包装、加工、物流分拣等方面得到日益广泛的应用。其中抓取装配操作是机器人最常见的应用场景,面临的一大挑战是复杂环境下对象的准确抓取问题。在传统的结构化环境中,通过预先由人工寻找示教点编入程序,再按固定程序运行的方式,虽然可达到很高的精度与成功率,但由于缺少环境感知与交互,难以在非结构化或半结构化等复杂场景下完成精密抓取装配作业。
可靠的机器人抓取装配系统,需要准确地获得目标在场景点云中的位置和姿态,即6D位姿。现有的方法,主要分为类别级识别和实例级识别。类别级姿态估计是指,同类物体拥有不同外形或是在有某类下新的物体加入的情况下也能完成物体识别与姿态估计任务;实例级识别则反之,每类物体需要有固定的外形形状,如CAD模型等。而工业零件大都为具有标准生产模型的刚性物体,几乎无类内的变化,降低了识别难度,但工业场景中的大多数零件有弱纹理、颜色相近或相同的特点, 在这种情况下,RGB颜色信息变得不再可靠。因此,为了提高识别的可靠性,本文从仅包含3D几何信息的点云入手,从物体的边缘信息、几何关系中挖掘物体6D位姿;另外待抓取物体因为经常在杂乱的场景中,物体间相互遮挡和堆叠不可避免,这对基于视觉引导的机器人抓取等任务仍带来较大困难[1]。
目前,基于传统算法的姿态估计大都采用人工设计的3D几何描述子如FPFH (Fast Point Feature Histograms)[2],SHOT (Signature of Histograms of OrienTations)[3]等,从点云中提取目标局部特征,进而在场景点云特征中,将提取到的特征与模板预提取特征进行查询匹配,来获得物体的6D位姿,但是这些方法需要待识别的物体有丰富的几何信息。Drost等人[4]将点对特征(Point Pair Feature, PPF)描述子与投票方案有效结合,来解决物体6D位姿估计。这是点云物体识别最成功的方法之一,许多学者也提出了它的改进型如文献[5,6]。该方法成功应用到了工业机器人抓取任务中,如文献[7–9]。但这类方法受限于每类物体模板的数量,且其单纯通过阈值判断物体的姿态估计结果,在堆叠杂乱场景中并不稳定。
近年来,由于深度卷积神经网络拥有强大的特征提取能力,传统的人工设计的点云特征描述子逐渐被学习型的描述子取代。Lyu等人[10]提出了将点云对应映射为2D图片,进而进行训练识别的方法,这种方式往往造成点云物体的几何信息丢失,在PointNet这一开创性3维特征提取网络被提出之后,研究人员开始探索适用于各种 3D 应用场景的PointNet变体。对于3D对象的物体检测和位姿估计任务,VoxelNet[11]和 Frustrum-PointNets[12]设计了类似PointNet 的结构实现了3D目标检测任务。
对于一些复杂场景,点云数据的预先分割具有重要意义,是场景理解中关键步骤。复杂场景点云分割研究始终围绕点云的特点,致力于寻找高效、鲁棒、普适的分割方法。Pham等人[13]提出了基于PointNet[14]的语义图和点特征相似矩阵,通过添加一个提出对象实例的过程来扩展语义分割框架,并通过多值条件随机场实现了语义与实例的相互约束与划分。Gao等人[15]提出了一种基于点云深度网络回归物体6D位姿估计的网络CloudPose,利用两个分离的网络分别回归平移向量与旋转向量,达到仅从无序点云中回归物体6D位姿的目的。
本文提出的位姿估计方法与CloudPose比较相近,其直接通过高维特征回归预测。不同的是,本文在其基础上融合了输入点云的多尺度特征,针对物体识别中遇到的存在弱纹理、对称等问题的识别效果进行了提升。
为了解决上述的分割依赖和弱纹理、散乱摆放干扰问题,本文提出一种仅使用点云中的3D几何信息,对目标物体进行6D位姿估计的深度学习网络,解决弱纹理、部分堆叠干扰等复杂场景下的物体识别问题。主要的贡献包括:(1) 提出了一种实例级散乱堆叠零件快速批量生成仿真数据集的方法,解决了难以获取大量带标注点云数据的问题;(2)提出了一种新颖的基于点云坐标数据的实例分割方法,解决了工业场景下弱纹理工件难以识别的问题;(3) 提出了一个改进的物体6D位姿估计网络,为复杂场景下机器人抓取装配任务提供6维姿态信息。
2 数据集生成
深度学习是数据驱动的方法,需要大量的数据做训练,使网络学习到足够稳健的特征[16]。但是,在面向如图1的工业抓取装配任务时,所用到的点云数据是3维的,物体位姿标签难以人工标注,特别是在较复杂且有一定遮挡的场景中。因此,缺乏3维标签样本是目前6D位姿估计深度学习模型构建的难题之一。

图1 机器人抓取装配系统
为此,本文利用文献[17]提出的Blensor仿真软件,快速批量生成工业零件在抓取平面上各种位姿下的表面点云。Blensor是在开源3维图形图像软件Blender基础上二次开发而来的,具有多种传感器类别,与文献[18]使用Blensor中的Kinect虚拟3维相机获取RGB-D数据作为样本不同,本文选择其中的ToF虚拟3维相机进行仿真,且仅获取点云数据而无颜色信息。借助Blender里的物理引擎渲染,可以模拟刚体的自由下落、碰撞效果等,将生成物体从平面上方某一位置自由落体掉落至抓取平面,得到精确的刚体变换。
数据集生成的具体步骤图2所示,每一步的具体操作流程如下:
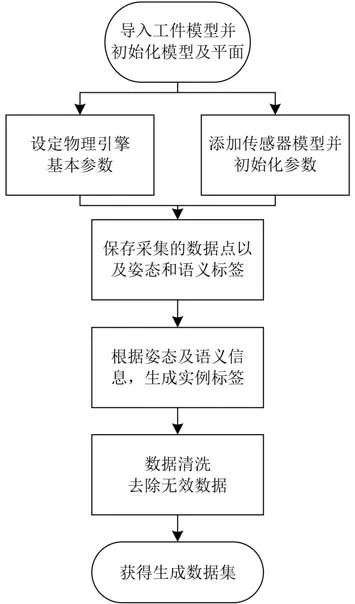
图2 数据集生成流程图
(1) 随机导入4~7个可重复的零件的CAD网格模型,并在预设的抓取平面上方,随机产生各模型的6自由度位姿,用于初始化零件的位态,待拍摄平面为长宽均为256 mm的正方形区域,并在四周设置了碰撞挡板,防止物体从平面掉落导致穿模而无法获取准确数据。
(2) 为仿真场景中模型加入物理引擎,设定对应刚体碰撞参数,动态参数。保留零件在重力作用下,工件自由落体的最后状态,以模拟工件在平面上的散乱、有堆叠的摆放。
(3) 添加传感器模型。设定传感器分辨率、焦距等。以提高数据集与实际传感器采集数据的相似程度。
(4) 保存传感器坐标系下场景内的表面点云作为数据集样本及各零件的6自由度姿态信息与点级语义信息,作为数据集标签。
(5) 进一步地,针对每个场景下有多个同类工件的点云,依据语义信息,将该类工件分离出来,并将点云模型通过6自由度姿态信息变换到实际位置,使用KNN(K近邻点算法)算法,获取变换后的每个点云模型在原场景中临近的1个或多个点,并提取为单个实例,从而获得整个场景点云的准确实例标签。
(6) 最后,针对严重遮挡,或因碰撞、穿模而无法在场景点云中有效呈现物体的标签,予以去除。严重遮挡判定阈值为所有生成物体表面点云统计均值的30%,以保证识别抓取的可靠性。
本文所涉及的数据集有7类物体,其中,主要的待抓取工件为物体A, B, C,此外,为了提高模型在面对对称物体,大小尺寸不同的物体时的鲁棒性,本文通过载入若干包含单轴对称、360°对称等干扰物体到场景中,7类物体的 CAD模型中,物体最大长度在90~220 mm,如图3(a)所示,由上述得到的场景点云,如图3(b)所示。
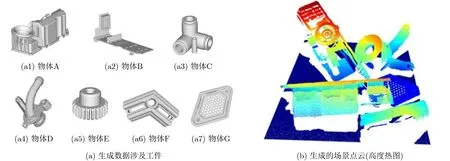
图3 工件CAD模型图及仿真场景点云样本示例
3 物体6D位姿估计深度学习网络
为了解决3D物体识别与位姿估计场景下,前景点与背景点之间、不同物体间的点会出现互相影响的问题,本文设计了6D位姿估计深度学习网络,利用实例分割网络将点云的前景点和背景点解耦,进而实例聚类,生成统一的点云切片,送入后续网络进行位姿估计。其结构主要包括点云实例分割模块、实例聚类生成模块、切片点云的6D位姿估计模块3个部分,其基本结构如图4所示。
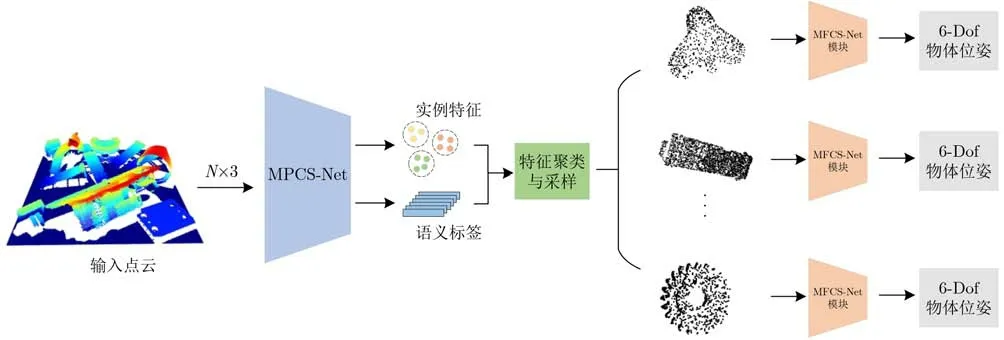
图4 网络整体架构图
3.1 点云语义及实例
预先将每个物体实例分割出来,会使得最终的位姿估计结果对噪声、自遮挡等影响因素的鲁棒性更好,从而获得一个更好的结果。对于点云分割方法,JSIS3D[13]认为目标语义与目标实例是相互依赖的关系,即在实例预测中所提取到的边缘与形状信息能够辅助该点的语义类别预测,文中提出了一个两阶段的分割网络结构,首先,面对室内场景数据集,JSIS3D使用滑动窗口结构,在每个滑窗中,利用MT-PNet对输入点云进行语义类别及实例特征的提取,并将特征输出为两个分支:语义分割结果以及实例嵌入特征,进而送入后续的MV-CRF网络进行实例预测。
但该网络在面对本文涉及的数据集,即工业抓取装配场景时,也存在一定的问题,首先,滑窗会将被检测物体进行切分,容易导致部分滑窗中被识别物体的点数丢失过多,且不同于室内场景,工件的抓取场景的实际尺寸不会过大,不需要滑动窗口结构;另外,在利用PointNet骨干网络提取点级特征时,将获得的高维特征向量通过最大池化操作,形成一个全局特征,这样会使得场景中每个工件的点与点之间的形状特征没有被网络学习到,使得最终分割精度有所降低。
本文基于MTP-Net,将仅能学习划窗内部全局特征的点云分割网络,修改为学习局部与全局特征的分割网络,相比于原结构,强化了网络对场景下各类非规则工件的外观及形状特征的学习能力,并针对实例分割部分进行了调整,提升了实例特征输出的维度,并将其命名为多尺度联合分割网络(Multiscale Point Cloud Segmentation Net,MPCS-Net),其网络结构如图5所示。

图5 MPCS-Net 网络图
MPCS-Net网络输入为仅有3维坐标的点云,通过FPS采样(最远点采样)进行输入点云数据的预处理,将原始点云下采样至N个点,相比于原网络使用的PointNet骨干网络,本文通过PointNet++作为骨干网络进行特征提取,提升了对局部特征的识别能力,在特征提取过程中,不断采样特征点,提取高维特征,其前4层采样点数分别为[4096,512, 128, 16],并通过多层感知机(Multi-Layer Perceptron, MLP)在SA(Set Abstraction)与FP(Feature Propagation)层提取多维度特征,其中,SA层用于点云的采样、点组合、组合点处的局部特征提取任务,而FP层则用于将多尺度的特征进行传递,最终输出每个点的预测特征,最终输出N×128维的特征向量,并分成了两个不同分支,对点云数据中逐点进行语义标签预测与实例特征生成,相比于原网络将语义与实例损失函数直接求和的方式,本文改进的点云分割模块的损失函数,由两个分支的损失函数加权求和而成

3.2 特征聚类与采样
针对点云分割网络输出的实例特征,进行特征聚类,生成实例点云,并将聚类后的实例点云的点数统一控制在M个点,结合语义标签送入下一环节,其流程图如图6所示。
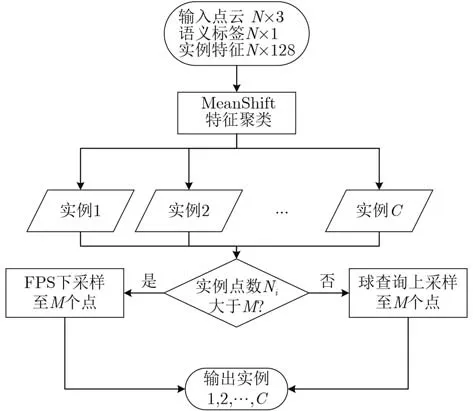
图6 特征聚类与采样模块流程图
首先,对于送入的N×128的高维特征,使用MeanShift算法进行特征聚类,生成逐点实例预测,在评估时,会出现虽预测的是同一个实例,但是预测编号不一致,导致评估为错误的数据关联问题,受到文献[20]启发,引入KM(Kuhn-Munkras)算法,按照点数的接近程度设定其初始匹配权重,其目的在于使得点数越相近的两组点拥有越高的连接权重,从而使得同一实例的预测标签与真实标签数值相同。在聚类生成实例后,由于每个实例的点个数都不相同,需将其采样至统一值,送入后续网络,这里采用PointNet++中提出的最远点采样(Farthest Point Sampling, FPS)与球查询方法,其中若实例的点数大于M,使用FPS采样法,相比于其他点云采样方式,该方法可以更好地覆盖空间中的所有点,尽可能地保留源点云的特征,便于后续的网络分析,而实例的点数小于M时, 则使用球查询的方法,将点云围绕中心点划分成 N个球形区域,将预测实例的点与输入的原始点云合并,并在每个预测点的查询半径内查找距离最近的原始点,循环查找直至找到M个点,将查找到的原始点集作为实例送入后续进行分析。
3.3 切片点云数据的6D位姿估计
在6D物体位姿估计任务中,输入的物体表面点云处于拍摄相机的相机坐标系下,其目的是找到待估计物体从物体坐标系变换到相机坐标系的变换关系,即旋转和平移参数,从而进行后续的处理,如机械臂抓取等,而平移与旋转彼此相对独立,其中,平移参数一般以3×1的平移向量T表示,代表了物体变换时沿着3个坐标轴的位移,旋转指定了围绕3个坐标轴的旋转,本文在网络中采用了旋转向量的输出方式。
受到文献[15]启发,本文提出了一种基于切片点云数据,多尺度特征融合的位姿估计回归方法,将其命名为多层特征姿态估计网(Multi-layer Feature Pose Estimation Net, MFPE-Net)其输入数据维度为M×(3+k),其中k为物体种类的总数,在输入中以One-Hot形式存在,并通过两个分支分别对旋转与平移向量进行回归,网络基本结构如图7所示。

图7 MFPE-Net结构图
其中,姿态特征提取模块基于改进的Point-Net结构,将输入点云通过MLP(多层感知机)提取特征后,将多个维度的特征拼接起来获得512维度的多层次特征,实现网络对物体多层特征的学习感知,进而通过全连接层将特征维度升至1024维,送入池化层后获取全局特征,进而通过尺寸为[512,256, 3]的MLP回归物体的旋转或平移向量。
在网络的优化环节,参考了文献[21],引入了RAdam (Rectified Adam)优化器,RAdam是一种可以根据方差的散度动态地开闭自适应学习速率的优化器,使得网络在训练时具有更好的鲁棒性与学习率的动态调整性能,从而获取更好的训练结果,模块基本结构如图8所示。
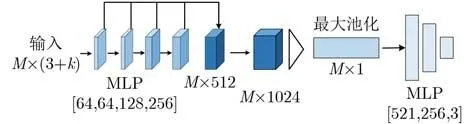
图8 姿态特征提取模块结构图

4 实验及分析
本文在训练时采用分别训练、统一测试的方法,在点云语义与实例分割网络、位姿估计网络的训练中,均采用生成数据集中得到的准确标签,以使得两个网络获得更好的训练效果,而在测试环节,位姿估计网络的输入为点云分割网络输出特征进行特征聚类与采样后生成的点云切片。
4.1 点云分割网络
本文在所提出的网络上,对图3(a)所示的5类物体,以及其他2类干扰物体,共7类物体进行训练和测试,其基本配置如表1所示。
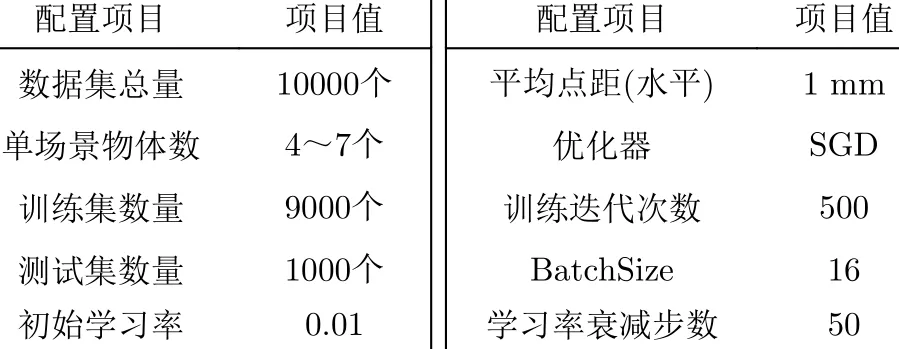
表1 训练基本配置表
训练使用的计算机配置是酷睿i9-9820X CPU、32 GB内存,单张NVIDIA GeForce RTX 2080ti显卡,经过特征聚类的点云实例分割的效果图如图9所示。
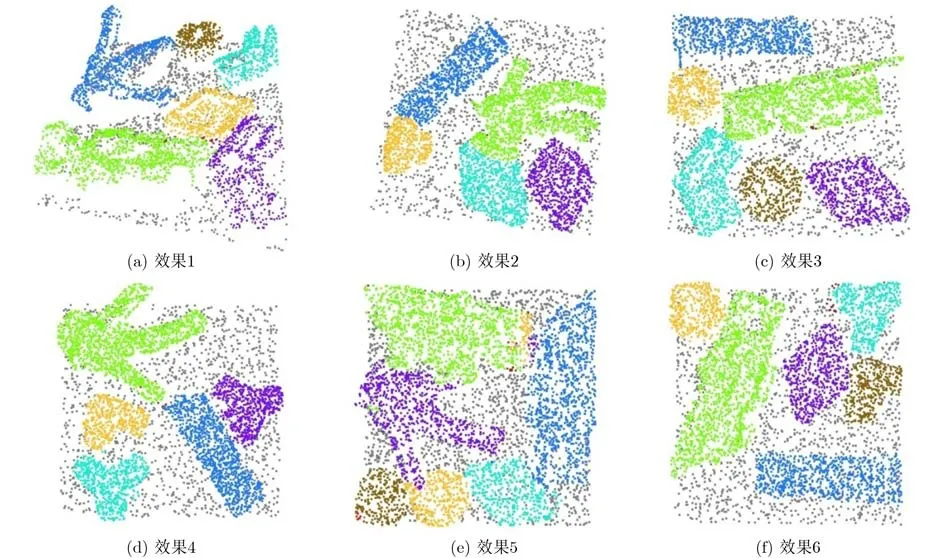
图9 点云实例分割网络效果图
表2展示了本文提出的多尺度点云分割网络的语义分割部分与PointNet++, MT-PNet, MV-CRF的语义分割精度结果,而表3展示了本文提出网络的实例分割部分与MT-PNet, MV-CRF的实例分割的精度对比,可以看到,针对工业抓取数据集,本文提出方法的误差明显较小,平均94%以上的实例分割精度使得输出实例足够完整,可以满足后续的位姿估计网络对输入数据的要求。

表2 语义分割精度(%)和平均时间(s)

表3 实例分割精度(%)和平均时间(s)
在单个场景点云的识别时间对比上,本文骨干网络采用了CUDA版本的PointNet++,故在精度提升明显的情况下,仅有略小的时间增加。在实例分割部分,运行在CPU的实例特征聚类算法占据了大部分的运算时间。总体来说,本文提出的分割网络,每次运算时间根据场景内物体数量的不同会有浮动,每个场景内,出现4~7个不同种类、不同大小的物体时,运算时间在3.5~7 s内浮动。
进行实例特征聚类时,需采用无需输入总体聚类数量的方法,本文在常见的无需聚类数量的方法中进行了测试,包括已经选用的MeanShift算法,以及基于密度聚类的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法,以及基于层次凝聚的HAC(Hierarchical Agglomerative Clustering)聚类算法,具体结果如表4所示。
由表4,在使用DBSCAN方法时,需要指定聚类半径和最小聚类点数,因本文涉及的物体存在大小尺度不一的情况,故在设定一个聚类半径后,很难适配大小不同的工件,存在一定聚类误差而基于层次凝聚的HAC算法在实际使用时,存在计算时间偏长、计算结果较差的问题,故不采用。

表4 不同实例聚类方法精度(%)
最终确定使用MeanShift算法,该方法对于其中涉及的窗口半径r的比较鲁棒,r在一定范围内聚类表现均良好,能够保证每类工件均保持较好的分割结果。
在实例特征进行特征聚类过程中,会出现聚类实例数量多于实际实例数量的情况,会导致在最终的准确率评判环节,因序号不对应导致的比对错误情况,最终会出现较大误差,经实验验证,引入的KM算法会在这种情况下将预测正确的点簇的实例序号与真实序号对应,不会因某一实例的预测不准影响后续的预测评估过程。
对预测实例进行可视化评估时,发现会小概率出现将某一物体中的一部分预测成多类的情况,如图10所示,这也是导致聚类实例的数量与实际实例数量不符的主要原因,此类问题也会导致实例聚类输出的错误结果影响后续姿态估计网络的判断流程。

图10 实例预测出现错误情况图
本文采用的解决办法是对每一组输出点簇进行数量判断,对于数量过于小的点簇,不进行查询以及后续的保存处理,避免这类小概率错误的分割结果影响后续的位姿估计任务。
此外,在实例特征聚类阶段,本文网络直接输出的高维特征已经具有一定程度的聚类效果,通过PCA降维方法将原有的高维特征降维至3维数据,并进行特征可视化后,其结果如图11所示。

图11 高维实例特征降维结果
4.2 点云位姿估计网络
在4.1节输出的结果上,进行特征聚类与采样后,送入本阶段网络进行姿态估计,由于每个场景内的物体为随机产生,故每次生成数据的每类物体总数量并不固定,均在8000个左右,在进行数据清洗后,同样按照9:1的比例进行训练集与测试集的划分,其测试结果如图12所示,图中显示为将未进行采样的模型经过解算位姿变换后与未经采样的场景。

图12 待抓取物体位姿估计效果
对于物体位姿估计常用的评价指标是平均点对距离,即将3D模型点云分别做真实位姿和预测位姿的刚体变换后点对的平均欧氏距离。由于对称物体真实位姿变换与预测位姿变换后的3D模型点云之间点对的对应关系不确定,因此区分非对称物体和对称物体,平均点对距离的计算也相应分为了针对非对称物体的AD[23]和针对对称物体的AD-S,具体如式(9, 10, 11)所示


6D位姿估计的预测质量评估,通常表示为平均点对距离误差(AD/AD-S)小于各物体对应模型直径d的10%的度量上准确率,本文采用的精配准方法均为迭代最近点法(Iterative Closest Point,ICP),本文将所提出的方法与其他3种做比较:分别是FPFH+RANSAC+ICP[2], PPF+3D-Hough+ICP[4]和CloudPose+ICP[15]方法。其中前两种是在传统的基于人工描述子的配准方法中常见的识别方案,第3种是基于直接在点云数据上使用深度学习方法进行位姿估计。为了全面比较本文提出网络的性能,在输入数据形式上4种方法也有不同,FPFH+RANSAC+ICP和CloudPose+ICP是在已经在真实标签下分割好的点云块上进行识别,并且已知该点云块对应的语义,而PPF+3D-Hough+ICP和本文提出的网络均在整个场景点云上做出多个物体的位姿估计。
如表5所示,是上述几种方法的6D位姿估计准确率,可以看到,相比其他方法,本文提出方法的误差明显较小,在更多的物体上获得了最优的识别精度(非对称与对称物体分别采用AD和AD-S进行比较),从结果上看,本文提出的网络效果更加稳定。通过实验观察发现,基于人工设计特征的传统方法,由于点云配准方法的描述子对点云法线估计的计算依赖性较强,当场景点云中物体法线与模型点云法线有较大差异时,配准错误的情况会经常出现。
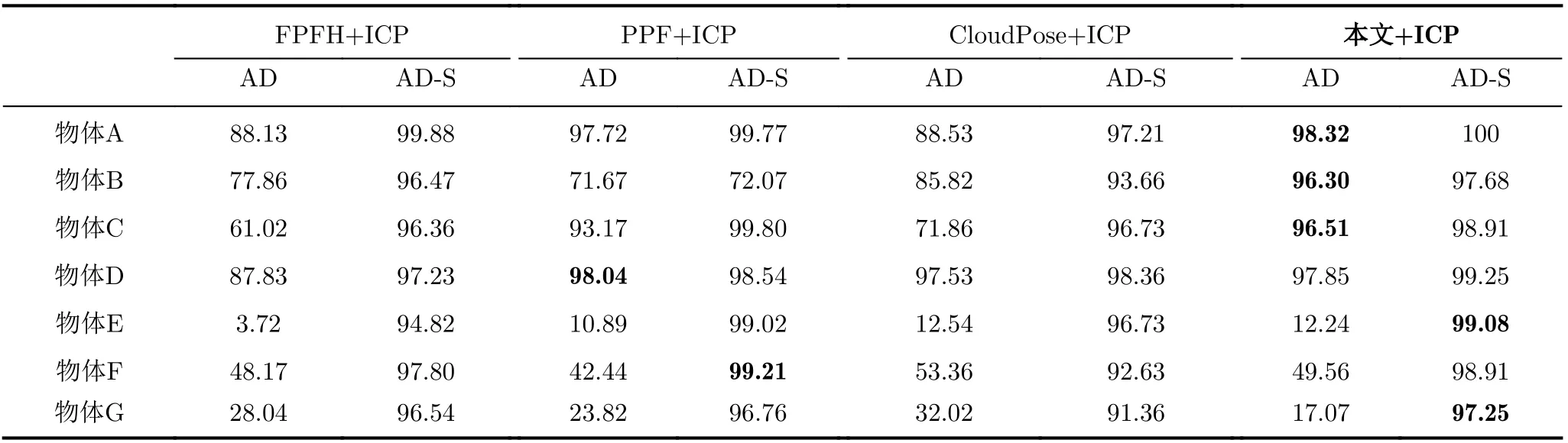
表5 姿态估计精度(%)
物体A、物体D是尺寸最大的两类物体,在场景点云中有更多的点能够描述,而且表面几何特征也较丰富,因此在不同度量下几种方法的识别误差都比较小。
物体B主体为片状结构,存在大量局部特征的错误地关联在了其他含平面的干扰物体上的情况,而且传统粗配准的体素下采样方式没有将空洞和边缘特征很好利用到,自身片状正反面易混淆,因而出现表现较多的误识别情况,本文采用的方法会将物体B完整分割出来,避免以上情况的发生。
物体C在几何上不具有对称性,但是前两种方法均出现ADS指标明显高于AD指标的情况,说明在特征上物体上有局部特征难以准确区分的位置,造成点对相关性配对错误,容易以60°的错误旋转或者是镜像式的错误旋转进行预测,从而影响估计位姿估计结果,如图13(a)(b)所示,而本文提出的物体6D位姿估计网络,通过多层特征融合,加强了网络对物体细节特征的识别能力,降低了上述识别错误情况的发生。
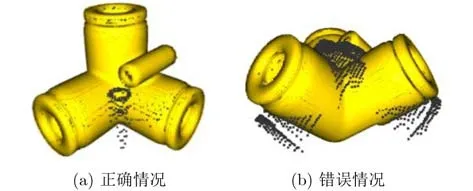
图13 物体C配准的情况
且从表5也可看出,针对非对称物体A, B, C,D,本文提出的网络识别精度(AD)均为最优或者处于领先位置,针对对称结构的物体E, F, G,本文提出的网络也具有很高的识别率(AD-S),证明了本文提出的方法的有效性,更加适配有高精度识别抓取需求的场景。
如表6所示,针对对比的几种方法进行了时效性的测试,其中,传统方法FPFH, PPF的输入为完整场景点云,在保证精度的前提下,完成下采样后的场景点云数量为300000,模板点云数量为30000,所列出时间为在场景点云中完成单个工件的识别任务的所需时间,且PPF算法未计入线下离线建模的时间;而CloudPose其原始输入即为分割后的点云切片,故使用MPCS-Net作为场景点云的分割网络,而本文提出的网络时效参数则是MPCSNet与MFPE-Net的总体时间,对于场景中出现的多个物体,所列时间为分割网络以及姿态估计网络的时间总和,平摊至每个点云实例后的运算时间;可以看出,本文所提出的网络大幅度优于传统方法,在与CloudPose方法进行对比时,因网络复杂度相近,故时效基本一致。

表6 单个实例识别时间(s)
5 结束语
本文针对现有的基于点云的位姿估计方法存在的不足,提出了一种基于深度学习的复杂点云场景下的6D位姿估计方法。通过物理引擎生成模拟数据集的方法解决了大体量点云数据集获取困难的问题,以纯几何点云坐标直接将完整场景点云作为输入,通过点云的语义与实例分割部分,可以提取输入点云的局部与全局特征,提升了网络对场景的理解能力,并通过多层特征融合的位姿估计网络输出准确姿态,在一定程度上解决了物体的堆叠和自遮挡问题,且针对各种对称物体具有鲁棒性,经过模拟真实场景的数据集的实验验证,本文提出的方法在整体精度和稳定性上具有明显优势,具有更高的鲁棒性,由于数据在预处理时剔除了遮挡过于严重的部分,本文提出的网络只解决了轻度遮挡以及物体自遮挡的情况,因此在解决严重遮挡的问题上仍具有提升空间,下一步工作将结合真实数据构建的数据集,以提升本网络的实用价值及鲁棒性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国惯性技术学报(2020年4期)2020-12-14
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
开放教育研究(2020年2期)2020-03-31
电子技术与软件工程(2019年6期)2019-04-26
科技与创新(2018年12期)2018-06-22
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
