
基于多尺度密集特征融合的单图像翻译
2022-06-01 06:47李启航冯龙杨清王雨耿国华
光学精密工程 2022年10期
李启航,冯龙,杨清,王雨,耿国华*
基于多尺度密集特征融合的单图像翻译
李启航1,冯龙1,杨清1,王雨2,耿国华1*
(1.西北大学 信息科学与技术学院,陕西 西安 710127;2.西北大学 数学学院,陕西 西安 710127)
为了解决现有的单图像翻译模型生成的图像质量低、细节特征差的问题,本文提出了基于多尺度密集特征融合的单图像翻译模型。该模型首先借用多尺度金字塔结构思想,对原图像和目标图像进行下采样,得到不同尺寸的输入图像。然后在生成器中将不同尺寸的图像输入到密集特征模块进行风格特征提取,将提取到的风格特征从原图像迁移到目标图像中,通过与判别器不断的博弈对抗,生成所需要的翻译图像;最后,本文通过渐进式增长生成器训练的方式,在训练的每个阶段中不断增加密集特征模块,实现生成图像从全局风格到局部风格的迁移,生成所需要的翻译图像。本文在各种无监督图像到图像翻译任务上进行了广泛的实验,实验结果表明,与现有的方法相比,本文的方法训练时长缩短了75%,并且生成图像的SIFID值平均降低了22.18%。本文的模型可以更好地捕获源域和目标域之间分布的差异,提高图像翻译的质量。
单图像翻译;图像风格迁移;生成对抗网络;密集特征融合;多尺度结构
1 引 言
无监督图像到图像的翻译(Unsupervised Image-to-Image Translation, UI2I)旨在学习源图像域向目标图像域转换的映射函数,在改变源图像域风格特征的同时保持其几何形状不变。例如,马到斑马的转换,风景照到艺术画的转换等等。UI2I在医学图像[1]、超分辨率[2]、图像上色[3]、风格迁移[4-5]、图像遥感[6]等应用上具有出色表现,因此受到了机器学习和计算机视觉领域研究人员的广泛关注。
近年来,随着人工智能的兴起,生成对抗网络(Generative Adversarial Network, GAN)的出现推动了UI2I领域的进一步发展。GAN[7]由一个生成器和一个判别器组成,其本质是生成器和判别器的相互对抗与博弈。虽然GAN可以成功地用于生成视觉逼真的图像,但仍存在一些挑战。例如,在没有成对训练样本的UI2I任务中,GAN存在对抗损失无约束的问题,即源域和目标域之间可能存在多个映射,导致模型训练不稳定、图像翻译不能成功,这些问题限制了其实际的应用。针对这个问题,CycleGAN[8]、DiscoGAN[9]和DualGAN[10]引入了循环一致性损失,学习从目标域到源域的反向映射,并度量重建图像与输入图像是否相同。循环一致性损失能够确保翻译后的图像具有与目标域相似的纹理信息,且不会发生几何变化。
尽管CycleGAN等[8-10]方法成功地解决了在UI2I任务中损失无约束的问题,但是这些方法仍需要大量的未配对图像进行训练。在实际使用中收集大量的未配对图像难度较大,所以此方法不具有普适性。为了解决数据集的问题,One-Shot无监督学习通过使用源域和目标域的单幅图像实现风格的转换,在UI2I中得到了广泛的应用。最近提出的SinGAN[11]研究表明,因为图像信息驻留在构成图像补丁的内部统计信息中,所以可以仅从单个自然图像中提取大量信息。但它仅限于学习单个图像分布,不适合UI2I中一组图像之间的转换。而Lin等人[12]提出的TuiGAN,通过在同一尺度上使用循环一致性损失[8]来约束两幅图像之间的结构差异,实现了两幅未配对图像的翻译。然而,这种仅仅依靠连续改变感受野来提取两幅图像之间潜在关系的方案,并不能有效地在不同尺度上捕捉源域和目标域之间分布的差异,这通常伴随着大量噪声的产生,导致生成图像质量低,出现伪影、扭曲等不符合人类视觉的部分。所以现有的One-Shot方法在图像风格的提取中存在着特征提取不准确、风格转换不全面等问题。因此,如何在少样本条件下保证翻译图像几何形状不发生改变并实现风格的准确迁移是目前UI2I任务的最大挑战。
针对以上问题,本文提出了一种新的单图像翻译模型。该模型基于密集特征[13]的多尺度融合[14],同时引入渐进式增长生成器[15],通过端到端的并行训练方式将生成的图像从全局结构逐渐细化到局部细节,并在训练过程中不断进行密集特征模块的迭代增长,从而实现不同尺度上特征信息的细粒度提取。实验分析表明,在多个具有挑战性的图像翻译任务中,与最新的UI2I方法相比,本文的方法可以更好地保留图像细节,使生成图像的SIFID值[11]平均降低22.18%,同时减少75%模型训练时间。
2 本文方法
2.1 网络结构
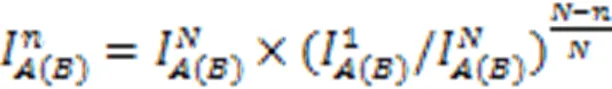
如图1所示,为了更精确地捕捉不同尺度的原图像和目标图像之间分布的差异,本文利用密集特征模块[13]来进行图像特征的提取和融合,加强了图像特征的复用,进而不断优化翻译图像的细节特征。其次,本文引入了渐进式增长生成器[15],在训练过程中不断添加新的密集特征模块来增加生成器的大小,同时共享上一阶段训练得到的权重,以端到端的方式并行训练,从而加速了模型的收敛速度。最后,本文通过对抗损失约束生成器生成与目标图像在视觉上相似的翻译图像,采用空间相关性损失[16]来有效地保持原图像与翻译图像场景结构的一致性,采用循环一致性损失[8]解决模式崩溃问题。
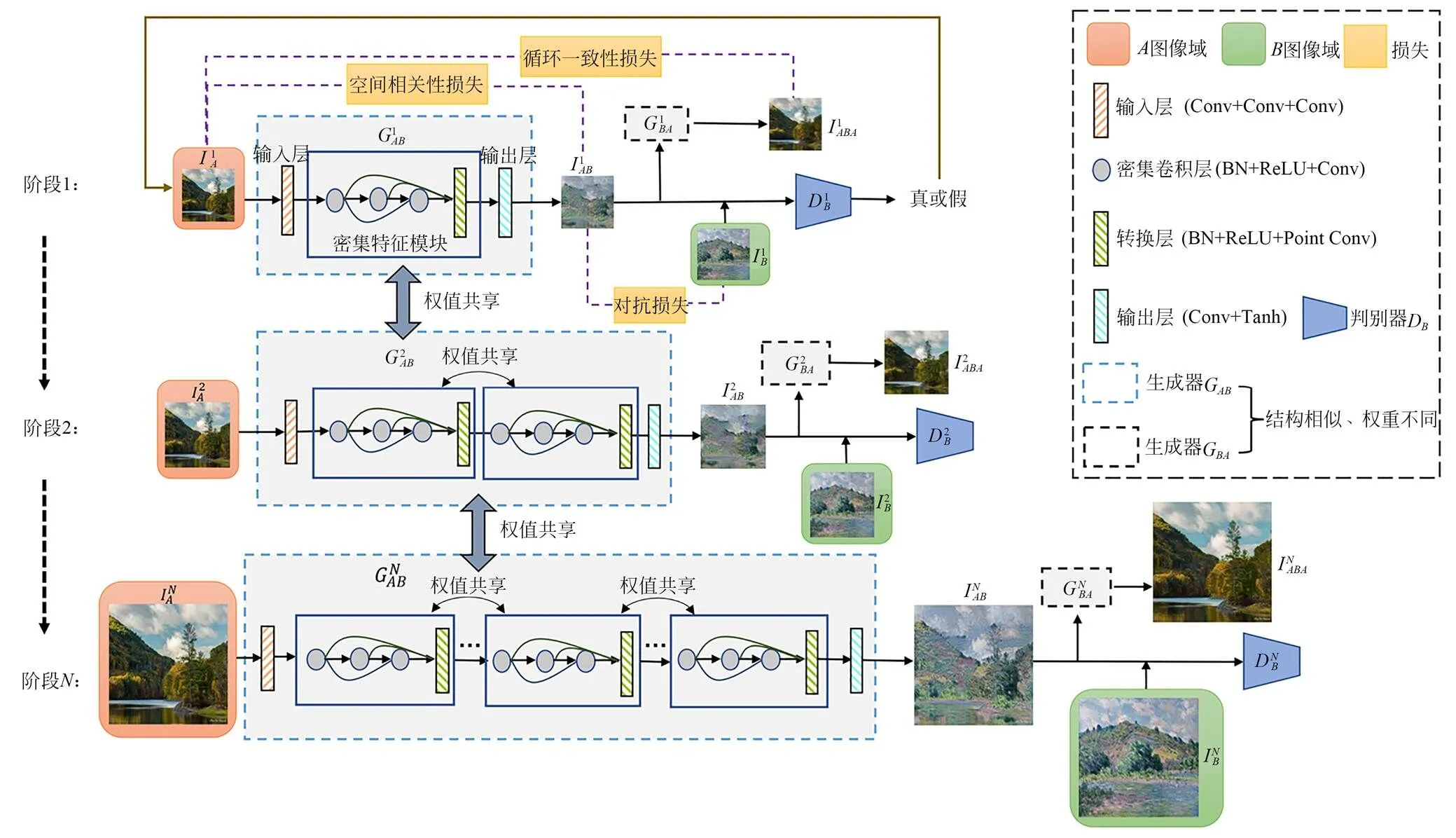
图1 A图像域转换到B图像域的网络结构
与传统UI2I方法不同的是,本文的方法仅需两幅未配对的图像即可完成各种UI2I任务且图像翻译质量高、模型训练速度快、能够保留更多的图像细节特征、生成更加真实的图像。
2.2 密集特征融合
研究表明[17],低维特征对于保持图像结构贡献较大,高维特征对于保持图像纹理和颜色非常重要。尽管高维特征拥有较为丰富的细节信息,但是其所包含的语义信息较为匮乏。并且在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显[18],从而导致低维特征不能得到有效地利用。
针对以上问题,本文基于DenseNet设计了一种密集特征融合模块。首先,采用三个3×3卷积从输入图像提取特征。其次,将各个阶段提取到的图像特征进行拼接融合,并利用这些特征将原图像的特征向量转换为目标图像的特征向量。同时为了避免拼接操作造成输出特征维度过大的问题,采用1×1卷积降低输出特征维度。最后通过一个3×3卷积输出翻译图像。整体过程如图2所示。

图2 特征提取及融合示意图
由图2可以看出,与DenseNet不同的是,本文针对单图像翻译任务设计的密集特征模块仅由三个卷积块及一个转换层组成,以防止网络的卷积层数过多导致训练过拟合。同时为了保证在多阶段训练过程中每阶段的图像尺度不变,本文去掉了DenseNet转换层中平均池化操作。最后,由于数据仅有两幅图像,能够提取的图像特征有限,因此本文将每一层输出的特征数设置为16。
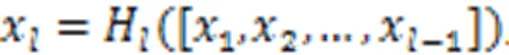
2.3 渐进式增长生成器
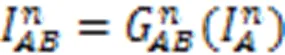
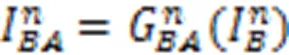
2.4 损失函数
本文一共使用了四种损失函数,分别为对抗损失、循环一致性损失、空间相关性损失、总变差损失。详细描述如下。
241总损失
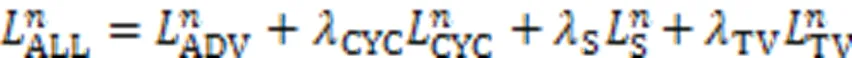
242对抗损失
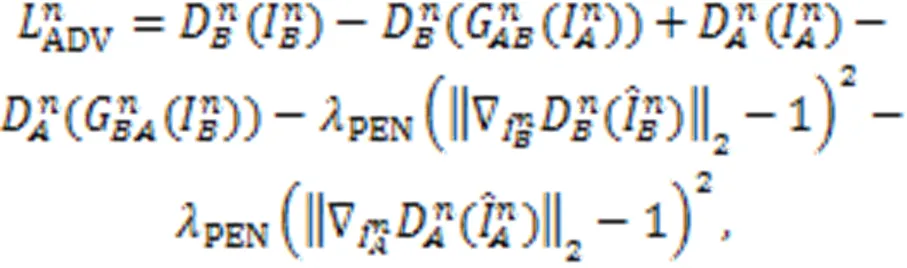
243循环一致性损失
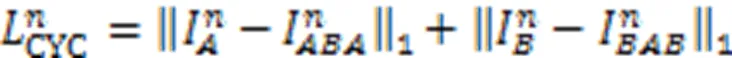
244空间相关性损失
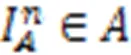
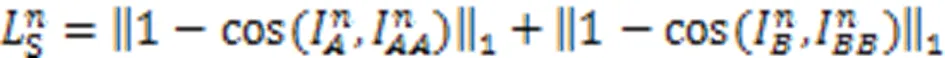
245总变差损失
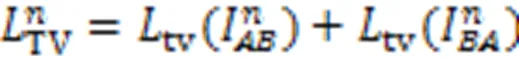
3 实验与结果分析
本文以CycleGAN、SinGAN、TuiGAN为基线,使用图像质量评价指标Single Image Fréchet Inception Distance (SIFID)在Monet2Photo、Horse2Zebra、GrumpifyCat数据集上,评估所提出的方法。SIFID[11]通过计算原图像和翻译图像深度特征之间的Fréchet Inception Distance (FID)[21]来评估翻译图像的质量,SIFID分数越低,两幅图像风格越相似,翻译图像质量越高。
3.1 实验细节
3.2 数据集
Monet2Photo数据集由1 193幅莫奈绘画和7 038张风景照片组成,该数据集由CycleGAN[8]发布。Horse2Zebra数据集包含1 067幅马图像、1 344幅斑马图像作为训练图像,120幅马图像、140幅斑马图像作为测试图像,该数据集在CycleGAN[8]中收集。GrumpifyCat数据集包含88幅蓝猫图像和214幅猫图像,该数据集在CUT[5]中收集。
3.3 实验分析
331实验结果
为确保实验结果准确,本文使用CycleGAN、SinGAN、TuiGAN的官方代码和默认配置训练。其中,CycleGAN使用源域和目标域完整的数据集训练,SinGAN使用源域仅有一幅图像训练,TuiGAN和本文使用源域和目标域都有一幅图像训练。
分别应用训练得到的CycleGAN、SinGAN、TuiGAN和本文的模型在3个具有挑战性的任务上进行图像翻译实验,这3个任务包括马↔斑马、风景↔莫奈画、蓝猫↔猫,部分实验结果如图3所示。图3中第一列是原图像,第二列是目标图像,第三列到第六列分别为CycleGAN、SinGAN、TuiGAN和本文的图像翻译结果。

图3 图像翻译实验结果比较
从实验结果对比可以发现,本文的方法总体上优于SinGAN和TuiGAN,在某些情况下甚至比使用完整数据集训练的CycleGAN效果更好。本文从以下三个实验结果进行详细分析对比:
(1)在马→斑马翻译任务上,CycleGAN生成的图像虽然具有斑马的纹理,但没有斑马的颜色特征。SinGAN仅改变了背景中草的颜色,无法学习斑马的整体风格特征。TuiGAN虽然捕捉到斑马的纹理特征及颜色特征,但其生成细节较差,如斑马头部和腹部条纹紊乱。本文方法生成的图像同时具有斑马的纹理特征和颜色特征,且纹理更加细致,生成的斑马条纹更加接近于目标图像。
(2)在莫奈画→风景翻译任务上,CycleGAN生成的图像结构完整、清晰、不含噪声,图像质量较高,而在生成图像的风格特征方面,由于其使用完整的数据集进行训练,因此生成图像的风格特征是目标图像域的整体风格特征,而不是目标图像的风格特征,例如目标图像的天空是浅蓝色、树木是棕色,生成图像的天空是蓝色、树木是绿色。SinGAN和TuiGAN虽然都传递了目标图像的整体颜色特征,但生成图像的空间结构发生了改变,如山的轮廓不完整。本文方法生成的图像能够准确地迁移目标图像的整体风格特征,且空间结构完整。
(3)在蓝猫→猫翻译任务上,由于该数据集较少,CycleGAN容易发生过拟合现象,导致训练不稳定,如生成的图像仅保留了目标图像的颜色特征,但空间结构发生了较大的变化,图像噪声过多。SinGAN在翻译结果上改变了原图像的全局颜色,不能传递高级语义信息,无法学习目标图像的风格特征。TuiGAN生成的图像虽然具有目标图像的整体风格特征,但图像伪影过多,图像质量较差。本文方法生成的图像具有目标图像的风格特征,同时几乎不存在伪影,图像质量高,能够取得更加逼真的风格迁移的效果。
332图像质量评估
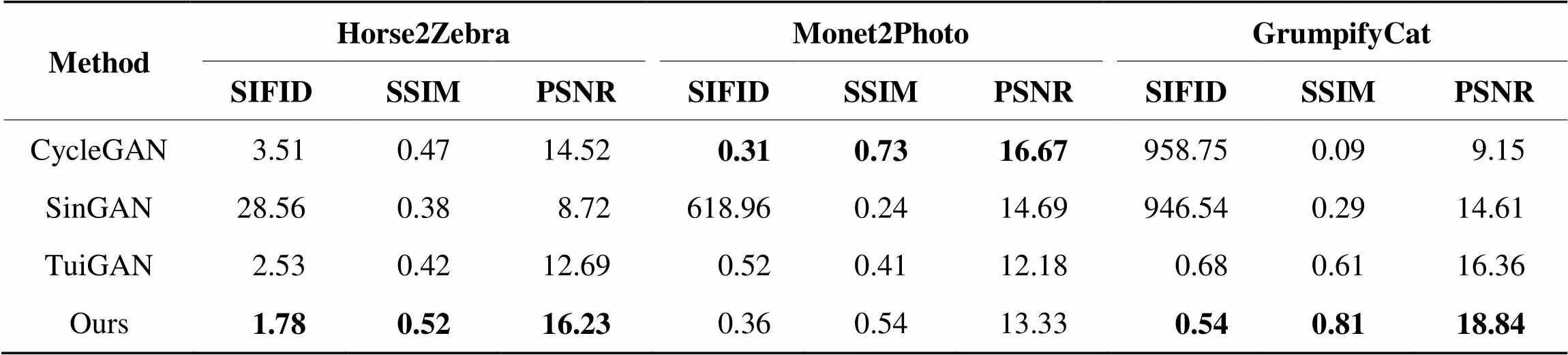
表1给出了用SIFID、SSIM、PSNR图像质量评价指标对CycleGAN、SinGAN、TuiGAN和本文所提出方法在3个翻译任务上结果的比较。
从表1可知,在风景↔莫奈画翻译任务上,CycleGAN的各项质量评价指标更好,这是由于CycleGAN使用的是完整的数据集训练,相比单图像翻译模型,其生成的翻译图像通常质量更高且风格迁移效果更好。
表1SIFID,SSIM和PSNR指标的实验
Tab.1 Experiment evaluation by SIFID, SSIM and PSNR
在马↔斑马和蓝猫↔猫这两个翻译任务上,本文的方法都取得了更好的SIFID、SSIM、PSNR评分,这说明本文的模型成功地捕捉了原图像和目标图像之间分布的差异,能够生成质量更高、结构更加完整、风格迁移效果更加逼真的翻译图像,在某些情况下甚至比使用完整数据集训练的CycleGAN效果更好。相比TuiGAN,本文模型在马↔斑马、风景↔莫奈画、蓝猫↔猫这三个翻译任务上,SIFID平均降低22.18%,SSIM平均提高28.33%,PSNR平均提高17.12%。
333模型参数评估
因CycleGAN需要使用完整的数据集训练,故不参与本节的模型参数评估。在评估实验中,按照SinGAN和TuiGAN官方代码的默认配置训练模型。图4给出了SinGAN、TuiGAN以及本文的模型参数总量和在马↔斑马翻译任务上的训练时长。
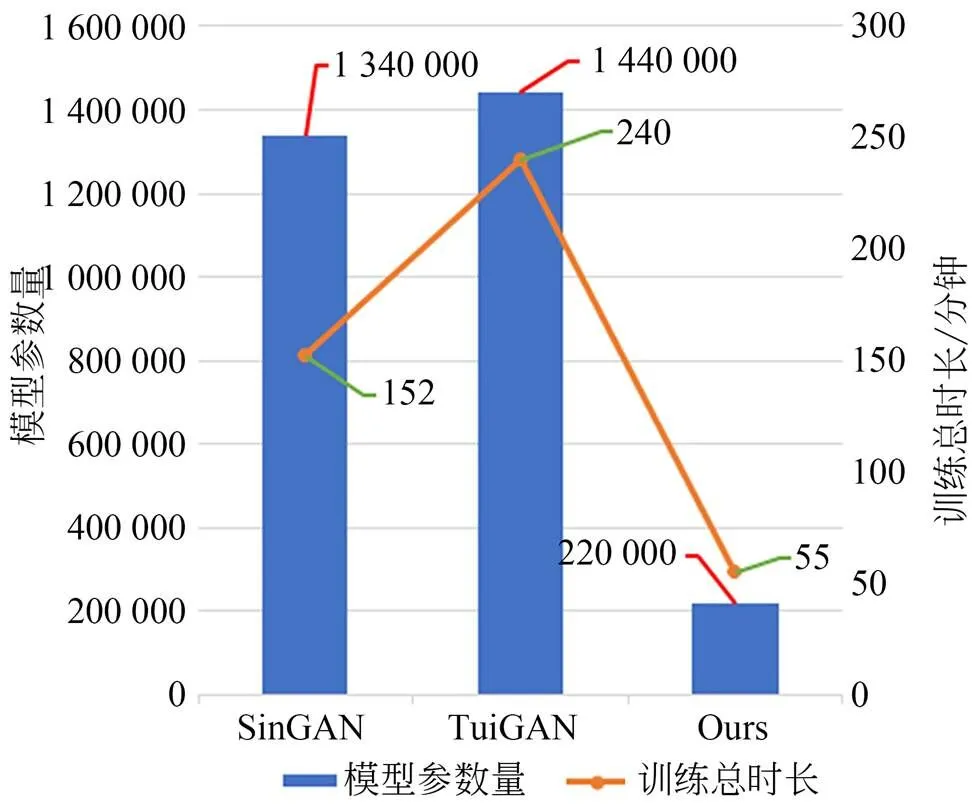
图4 模型参数及训练时长
由图3和图4可知,本文模型在马↔斑马翻译任务上取得了比SinGAN、TuiGAN更好的实验结果,并且参数量远远少于SinGAN和TuiGAN模型。此外,在训练模型时间上,本文模型较TuiGAN缩短了约3/4,这表明本文端到端的训练方式可以有效地加快模型收敛速度,结合密集特征模块的优点,大幅度地减少了模型的参数量。
334模型通用性评估
为了进一步验证本文的模型在单图像翻译任务上的通用性,本文展示了在三项对象转换任务上的结果,这三项任务是:狗对象互换、狐狸对象互换、猫对象互换。实验结果如图5所示。
从图5可以看出,本文的模型在许多情况下都具有良好的性能,可以生成内容真实、质量较高、风格迁移效果较好的翻译图像,这表明本文的模型在单图像翻译任务中具有一定的通用性。

图5 本文模型在对象转换任务上的实验结果
3.4 消融分析
为了验证本文所提出的方法在单图像翻译任务上的有效性,本文基于马↔斑马、风景↔莫奈画、蓝猫↔猫翻译任务共设置了5个消融实验。部分实验结果如图6所示。实验在本文模型的基础之上:(Ⅰ)剔除密集特征模块,改用ResNet模块;(Ⅱ)剔除渐进式增长生成器,同时不共享每阶段训练的权重;(Ⅲ)剔除空间相关性损失;(Ⅳ)剔除循环一致性损失;(Ⅴ)剔除总变差损失;(Ⅵ)本文方法。

图6 消融实验结果比较
从图6可以看出:(Ⅰ)用ResNet替换密集特征模块,各尺度的图像特征不能得到有效地利用,容易造成翻译图像出现伪影等不符合人类视觉的部分。(Ⅱ)若不渐进式增加生成器的大小,生成器不能更好地传递图像特征,同时训练时长增加。(Ⅲ)如果没有空间相关性损失,生成的结果会受到颜色和纹理不准确的影响。(Ⅳ)在没有循环一致性损失的情况下,本文的模型不能保证翻译图像的完整性。(Ⅴ)如果没有总变差损失,本文的模型可能会产生一些噪声,如生成结果中左侧部分的粉色。
如表2所示,通过计算本文模型不同变体的SIFID、SSIM、PSNR来评估消融实验结果。本文的完整模型仍然获得了最好的三项图像质量评价指标,这证明了本文所提出的方法在单图像翻译任务上的有效性。
表2SIFID,SSIM和PSNR指标的消融实验评估
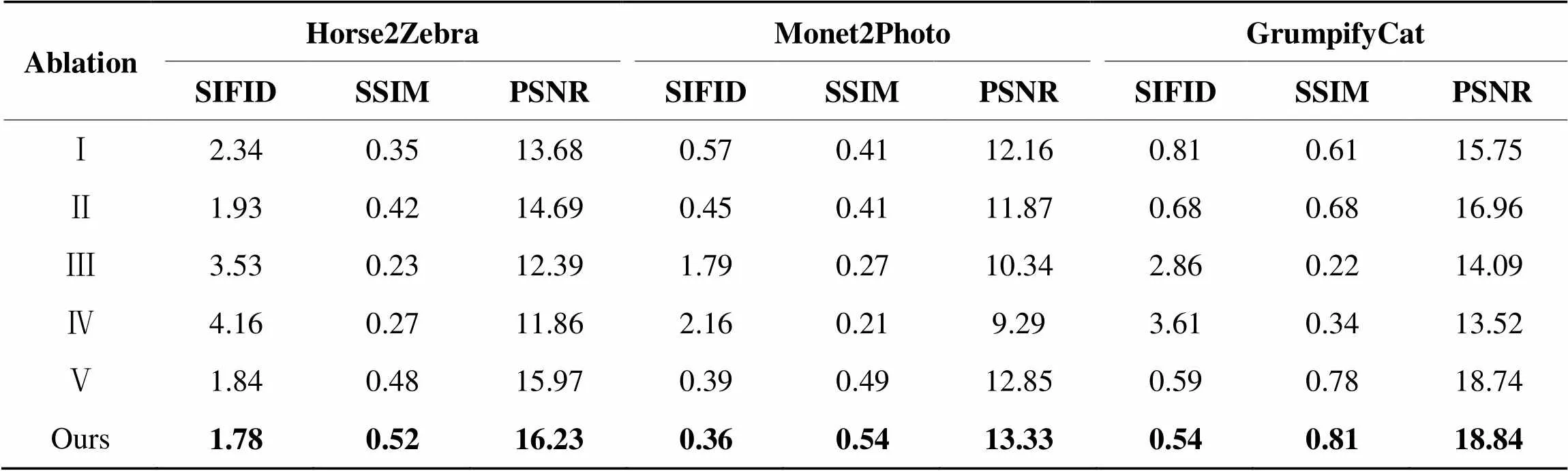
Tab.2 Ablation experiments evaluation by SIFID, SSIM and PSNR
4 结 论
本文提出了一种基于多尺度密集特征融合的单图像翻译模型,适用于仅有两幅未配对图像的数据集。该模型在循序递增的图像尺度上多阶段训练,首先学习图像的全局结构,再学习图像的纹理和风格特征。本文设计的密集特征模块在不同尺度的图像上进行特征提取和融合,加强了图像特征的复用,解决了梯度消失的问题,提高了图像翻译的质量。同时本文引入了渐进式增长生成器,使模型以端到端的方式训练,加速了网络的收敛,改善了融合不同尺度特征时直接维度拼接带来的信息损失。实验结果表明,在数据极其有限的图像翻译任务中,本文的方法能够生成细节更加丰富、内容更加逼真的高质量图像。在马↔斑马、风景↔莫奈画、蓝猫↔猫这三个翻译任务上,本文方法的图像质量评价指标相比TuiGAN都更好,SIFID平均降低了22.18%,SSIM平均提高了28.33%,PSNR平均提高了17.12%。此外,本文模型的训练时长较TuiGAN减少了约75%。
[1] 吕晓琪,吴凉,谷宇,等. 基于三维卷积神经网络的低剂量CT肺结节检测[J]. 光学精密工程, 2018, 26(5): 1211-1218.
LV X Q, WU L, GU Y,. Detection of low dose CT pulmonary nodules based on 3D convolution neural network[J]., 2018, 26(5): 1211-1218.(in Chinese)
[2] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]. 20162730,2016,,,IEEE, 2016: 1646-1654.
[3] ZHANG R, ISOLA P, EFROS A A. Colorful image colorization[C].2016, 2016: 649-666.
[4] 杜振龙,沈海洋,宋国美,等. 基于改进CycleGAN的图像风格迁移[J]. 光学精密工程, 2019, 27(8): 1836-1844.
DU Z L, SHEN H Y, SONG G M,. Image style transfer based on improved CycleGAN[J]., 2019, 27(8): 1836-1844.(in Chinese)
[5] PARK T, EFROS A A, ZHANG R,. Contrastive learning for unpaired image-to-image translation[C].2020, 2020: 319-345.
[6] 李宇,刘雪莹,张洪群,等. 基于卷积神经网络的光学遥感图像检索[J]. 光学精密工程, 2018, 26(1): 200-207.
LI Y, LIU X Y, ZHANG H Q,. Optical remote sensing image retrieval based on convolutional neural networks[J]., 2018, 26(1): 200-207.(in Chinese)
[7] GOODFELLOW I, POUGET A J, MIRZA M,. Generative adversarial nets[J]., 2014, 27.
[8] ZHU J Y, PARK T, ISOLA P,. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 20172229,2017,,IEEE, 2017: 2242-2251.
[9] KIM T, CHA M, KIM H,. Learning to discover cross-domain relations with generative adversarial networks[C]., 2017: 1857-1865..
[10] YI Z L, ZHANG H, TAN P,. DualGAN: unsupervised dual learning for image-to-image translation[C]. 20172229,2017,,IEEE, 2017: 2868-2876.
[11] SHAHAM T R, DEKEL T, MICHAELI T. SinGAN: learning a generative model from a single natural image[C]. 2019()272,2019,,(). IEEE, 2019: 4569-4579.
[12] LIN J X, PANG Y X, XIA Y C,. TuiGAN: learning versatile image-to-image translation with two unpaired images[C].2020, 2020: 18-35.
[13] HUANG G, LIU Z, MAATEN LVAN DER,. Densely connected convolutional networks[C]. 20172126,2017,,,IEEE, 2017: 2261-2269.
[14] KARRAS T, AILA, LAINE S,. Progressive growing of GANs for improved quality, stability, and variation[EB/OL].:: 1710.10196[cs.NE]. https://arxiv.org/abs/1710.10196
[15] HINZ T, FISHER M, WANG O,. Improved techniques for training single-image GANs[C]. 202138,2021,,,IEEE, 2021: 1299-1308.
[16] ZHENG C X, CHAM T J, CAI J F. The spatially-correlative loss for various image translation tasks[C]. 2021()2025,2021,,,IEEE, 2021: 16402-16412.
[17] LEE H Y, TSENG H Y, HUANG J B,. Diverse image-to-image translation via disentangled representations[C].2018, 2018: 35-51.
[18] HE K M, ZHANG X Y, REN S Q,. Deep residual learning for image recognition[C]. 20162730,2016,,,IEEE, 2016: 770-778.
[19] GULRAJANI I, AHMED F, ARJOVSKY M,. Improved training of wasserstein gans[J].:1704.00028, 2017.
[20] PUMAROLA A, AGUDO A,MARTINEZ A M,. GANimation: anatomically-aware facial animation from a single image[J].-::, 2018, 11214: 835-851.
[21] HEUSEL M, RAMSAUER H,UNTERTHINER T,. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[J]., 2017.
[22] NEWEY W K. Adaptive estimation of regression models via moment restrictions[J]., 1988, 38(3): 301-339.
[23] DEMIR U, UNAL G. Patch-based image inpainting with generative adversarial networks[EB/OL].:: 1803.07422[cs.CV]. https://arxiv.org/abs/1803.07422
Single-image translation based on multi-scale dense feature fusion
LI Qihang1,FENG Long1,YANG Qing1,WANG Yu2,GENG Guohua1*
(1,,’710127,;2,,’710127,),:1925995331
To solve the problems of low image quality and poor detail features generated by the existing single image translation models, a single image translation model based on multi-scale dense feature fusion is proposed in this paper. First, in this model, the idea of multi-scale pyramid structure is used to downsample the original and target images to obtain input images of different sizes. Then, in the generator, images of different sizes are input into the dense feature module for style feature extraction, which are transferred from the original image to the target image, and the required translation image is generated through continuous game confrontation with the discriminator. Finally, dense feature modules are added in each stage of training by means of incremental growth generator training, which realizes the migration of generated images from global to local styles, and generates the required translation images. Extensive experiments have been conducted on various unsupervised images to perform image translation tasks. The experimental results demonstrate that in contrast to the existing methods, the training time of this method is shortened by 80%, and the SIFID value of the generated image is reduced by 22.18%. Therefore, the model proposed in this paper can better capture the distribution difference between the source and target domains, and improve the quality of image translation.
single-image translation; image style transfer; GAN; dense feature fusion; multi-scale structure
TP391
A
10.37188/OPE.20223010.1217
1004-924X(2022)10-1217-11
2021-12-22;
2022-01-18.
国家自然科学基金资助项目(No.61731015);国家重点研发计划资助项目(No. 2019YFC1521103,No.2020YFC1523301);陕西省重点产业链资助项目(No.2019ZDLSF07-02);青海省重点研发计划资助项目(No.2020-SF-142)
李启航(1997),男,河南郑州人,西北大学信息科学与技术学院2020级硕士研究生在读,现主要从事计算机视觉、图像风格迁移方面的研究。Email: liqihang@stumail.nwu.edu.cn

耿国华(1955),女,山东莱西人,教授,博士生导师,1976 和1988 年于西北大学分别获得学士和硕士学位,主要从事虚拟现实、可视化技术、图像处理和智能信息处理等领域的理论及应用工程创新研究。E-mail: 1925995331@qq.com
猜你喜欢
四川工商学院学术新视野(2021年3期)2021-11-05
数学小灵通·3-4年级(2021年5期)2021-07-16
童话世界(2020年17期)2020-07-25
阅读(快乐英语中年级)(2019年5期)2019-09-10
今日农业(2019年15期)2019-01-03
幼儿画刊(2018年8期)2018-08-29
人间(2016年24期)2016-11-23
现代计算机(2016年11期)2016-02-28
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
