
基于字符区域感知的端到端车牌识别方法
2022-06-02 06:57范晓焓宿汉辰李斌阳
无线电工程 2022年6期
李 岩 ,舒 言 ,范晓焓 ,宿汉辰 ,李斌阳
(1.国际关系学院 网络空间安全学院, 北京 100191;2.哈尔滨工业大学 计算机科学与技术学院, 黑龙江 哈尔滨 150006)
0 引言
车牌识别是智能交通系统的重要组成部分,在收费控制、数字安全监控等诸多应用中发挥着重要作用。传统的车牌识别系统通常将任务分解为车牌区域检测(车牌定位)、字符分割和字符识别3个阶段[1-3],同时借助端到端训练技术[4-8],深度学习方法进一步提升了车牌检测与识别的整体性能。
尽管深度学习方法提升了车牌识别能力,但是大部分车牌识别系统在困难场景下依然无法兼顾识别精度与算法效率。这是因为大部分端到端车牌识别模型依然遵循车牌定位—识别这一框架[9-12]。基于此,本文提出了一种基于字符区域感知[13-14]的端到端车牌识别方法,有效平衡了复杂场景下车牌识别的精度与速度。该框架无需借助车牌区域检测即可实现对字符的识别。与现有方法不同,本文提出的方法直接提取单字符特征并进行分类,同时在网络结构设计阶段采用由特征金字塔增强模块和特征融合模块组成的低计算量分割头[15]弥补其在特征提取方面的精度缺陷,构建高效精准的车牌识别模型。
1 相关工作
1.1 车牌识别系统
传统的车牌识别系统通常分为车牌区域检测、字符分割和字符识别3个阶段。随着深度学习的发展,基于卷积神经网络的目标检测模型被广泛用于车牌识别,典型的有YOLO[16],R-CNN[17]和SSD[18]。大量车牌识别工作基于以上目标检测模型展开深入研究。Brillantes等[17]提出了一种基于Faster R-CNN[19]架构的车牌检测网络,使用特征金字塔网络(FPN)作为Faster R-CNN的探测器,进一步提升了检测速度。Wu等[18]在车牌检测阶段使用残差网络ResNet替代SSD中的VGG[20]网络,通过引入残差网络结构加深网络深度,提升模型学习能力。
在车牌识别阶段,Zhang等[4]在字符识别阶段将车牌视为二维信号,改善了传统因将车牌视为一维序列所导致的复杂环境下车牌识别能力下降的问题。Chang等[1]设计了一种由字符分类、拓扑排序和自组织识别3个步骤组成的字符识别方法,显著提升了识别的准确性。上述方法一定程度上提高了车牌自动识别能力,但却局限于传统三阶段框架,当受到复杂环境影响时系统整体性能会受到较大影响。
1.2 端到端车牌识别模型
深度学习中的端到端训练是提升车牌检测与识别整体性能的重要技术手段。Li等[7]第一次将车牌检测和识别集成到一个统一的端到端网络中,通过共享卷积特征层对检测和识别任务损失函数进行联合优化,提升系统效能。Chen等[10]设计了一种基于车牌关系挖掘的端到端车牌检测网络,先根据车牌中心与车辆偏移量估计车牌位置,再对车牌四边形框进行细化,最终聚合成车牌拼接区域,减少了车牌搜索面积,并提高了小尺寸车牌检测性能。Wang等[12]提出了基于级联网络的实时端到端车牌识别框架,使用级联卷积神经网络以及多任务卷积神经网络,将板块分类、边界框回归、车牌地标检测和板块颜色识别4个任务同时进行,极大地提高了训练速度。上述端到端车牌识别方法有效提升了车牌识别的精度,但受限于车牌定位—识别这一框架,计算开销较大,无法在车牌识别的速度和精度间取得较好的平衡。
本文提出的车牌识别框架如图1所示。
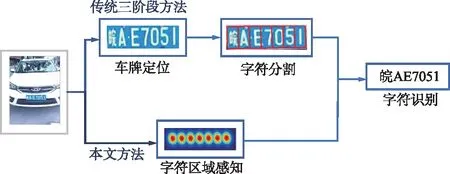
图1 本文提出的车牌识别框架Fig.1 The proposed license plate recognition framework
2 字符区域感知方法
2.1 方法框架
本文车牌识别网络体系结构如图2所示。对于输入的含有车牌的图像,首先利用预训练好的共享卷积层对车牌区域进行字符感知,从而生成正式训练时所需要的标签。在正式训练中,车牌区域的字符区域高斯热力图和字符联通高斯热力图将被预测,以检测车牌框。与此同时,字符定位的结果被用于在共享卷积层输出的特征图中,以提取感兴趣区域的特征向量。最后,2个并列的轻量卷积神经网络用于预测不同位置的车牌字符输出。值得注意的是,本文构建了一个统一模型,可以实现端到端训练。作为主干网络的共享卷积层架构的说明详见2.2节。
为了有效解决因相机视角剧烈变化导致识别精度降低的问题,本文提出了一种通过构造人造数据集模拟多角度车牌字符进行预训练的方法。同时针对车牌字符排列的特殊规律并参考车牌颜色的先验信息,进一步提升字符定位精度。由于车牌具有自然场景文本中没有的颜色以及字符规律等特性,在检测过程中加入对车牌的颜色以及字符排列特性的处理,成功降低了车牌中字符定位的难度。
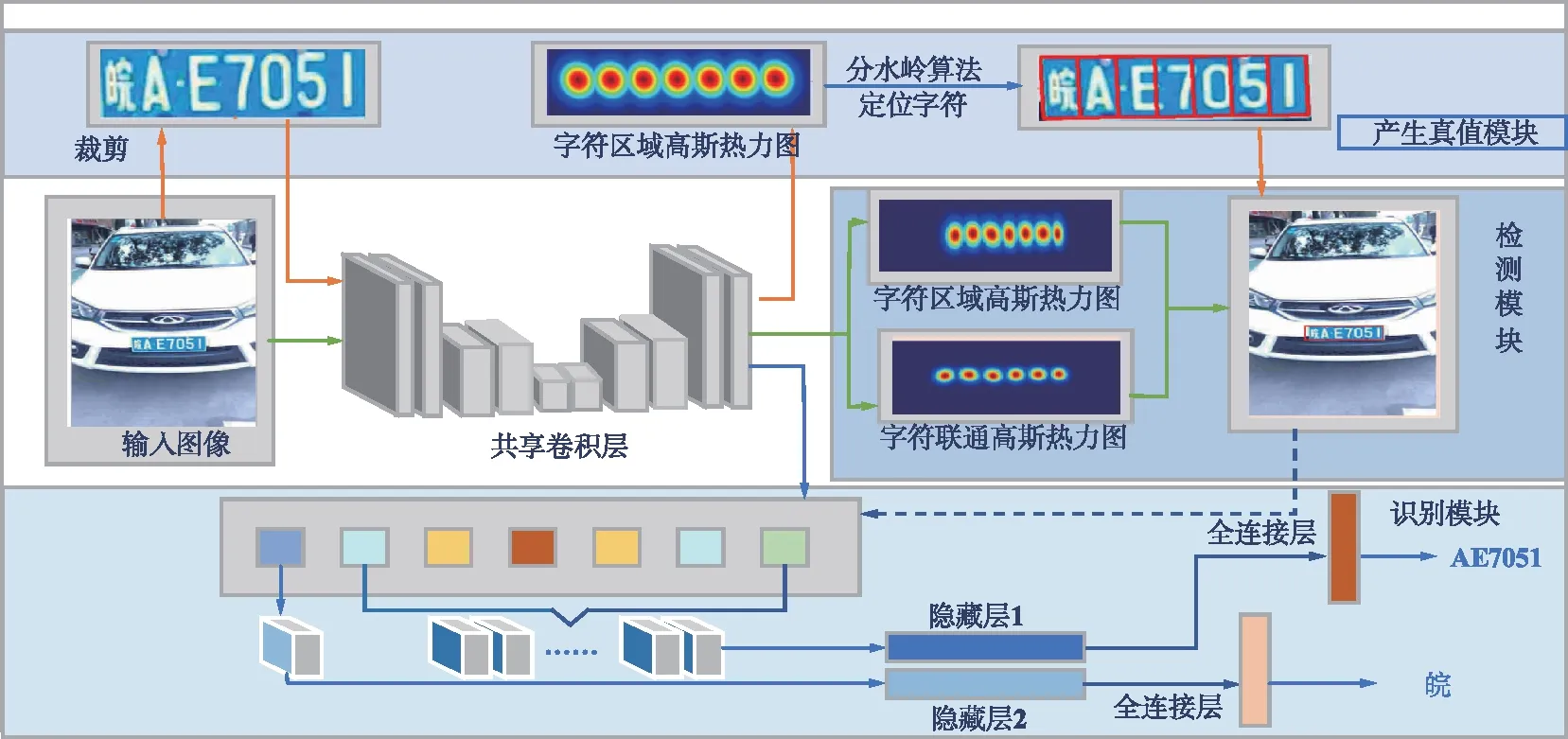
图2 车牌识别网络体系结构Fig.2 The architecture of license plate recognition network
2.2 主干网络架构
分割头对网络的增强示意图如图3所示。主干网络主要由特征金字塔增强模块(FPEM)和特征融合模块(FFM)组成。ResNet18[20]作为主干网络虽然计算量较小,但由于网络层数较低,模型学习能力有限。为了解决这一问题,使用FPEM和FFM弥补这一缺陷。FPEM呈级联结构且计算量小,可以连接在主干网络后面使不同尺寸的特征更深,从而更具表征能力。FPEM模块可以看成是一个轻量级的FPN,可以不停级联以达到不停增强特征的作用。而FFM模块用于融合不同尺度的特征,最后通过上采样将它们合并到一起。具体地,特征提取部分全部使用3×3大小的卷积核进行图像特征提取,并以一个平均池化层和含有1 000路Softmax的全连接层结束。使用1×1卷积将特征图通道数减少到128后得到缩小的特征金字塔,并用FPEM进行增强,每个FPEM产生一个增强的特征金字塔,最后由FFM将增强后的特征金字塔融合,通道数为512。实验结果表明,本文使用轻量级网络ResNet18配合由特征FPEM和FFM组合成的低计算分割头作为主干网络[15],在保证模型准确性的同时极大地提升了模型的推理速度。

图3 分割头对网络的增强示意Fig.3 The diagram of the segmentation head’s enhancement to the network
2.3 预训练&训练
为了进一步提高模型对车牌字符区域的感知能力,本文使用带有字符级标注的人造数据集进行预训练。与构造自然场景光学字符识别(OCR)人造数据集不同[13],本文根据真实车牌特性构造的人造数据集仅包含大写字母与数字的字符形式。由于车牌首位一般为代表地区的汉字,训练时只需将最前的字母前一位确定为该汉字位置即可。构造人造数据集时不仅需要模拟产生多种视角的车牌字符,同时应模拟与真实车牌相似的各类复杂场景,从而提升模型在各类复杂情况下的车牌字符区域感知能力。
模型预训练与训练流程如图2所示,绿线和蓝线流程分别揭示了检测模块和识别模块的训练流程。由卷积网络输出2个通道的字符区域高斯热力图和字符联通高斯热力图用于定位字符的边界框,包含16个通道的特征图用于识别模块。识别模块利用模型自动定位的每个车牌字符区域,输出车牌的内容信息,并根据车牌的字符数量和位置信息输出车牌的具体类型。值得注意的是,预训练阶段标签已由人造数据集提供;正式训练时由于缺少字符级别的标注,需要利用弱监督学习生成伪造标签,即红线所展示的流程。具体地,红线流程首先使用人造车牌数据集中的每张图片,裁剪出车牌区域,针对图像中每个文本实例经过共享卷积网络生成单个字符区域的高斯热力图,使用分水岭算法将高斯热力图与背景分开,并使用最小外接矩形框出每个车牌字符的位置,最后通过尺度变化的方式即可在原始图像中得到每个字符的边界框。
本文采取端到端训练方式,预训练阶段误差函数由检测端和识别端共同组成,其中检测端的误差函数可表示为:
(1)
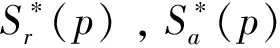
识别端的误差函数表示为:
(2)
式中,xi为预测出该字符类别的概率;ci为该字符类别在真实标签中的概率。对于第2个分类器,i为该字符类别;yi为预测出该字符类别的概率;di为该字符类别在真实标签中的概率。
总的误差函数表示为:
L=w1Ldet+w2Lrec,
(3)
式中,超参数取值w1=w2=1。
预训练结束后将输入真实车牌数据以弱监督学习方式进行正式训练。在此过程中, 通过预训练事先得到的模型已经具备预测字符级标注的能力。同时,为保证训练过程可靠性,在正式训练时建立真值评估机制,通过设置置信度对生成的真值进行评估、筛选和纠正。假设对于某车牌w,由模型分割出的字符框数量为l*(w),车牌字符真值数量为l(w),可得分割置信度为:
(4)
训练过程中设定该置信度最小阈值为0.7,如果置信度大于等于最小阈值,则使用模型产生的真值;相反,则启用矫正机制重新对字符进行分割。正式训练的误差函数在引入真值置信度后可修改为:
(5)
本文提出的模型可以通过不断学习原始图像中的字符提升识别能力。随着训练时间的增加,模型可以获得越来越多的正确车牌数据标签,从而提高车牌识别性能。
3 实验结果与分析
本文使用PyTorch 1.8版本,在Intel酷睿i5 CPU,单块GTX3090 GPU的平台上进行车牌识别模型的训练和评估。实验比较了几种优秀的车牌识别方法,同时进行了消融实验比较分析。
3.1 数据集与评价指标
本文在公开大型车牌数据集CCPD 2019[21]上与之前的工作[18-19]进行了对比实验。CCPD数据集是目前中国最大的公开可得的车牌数据集,收录近30万张彩色图片,每张图片分辨率为720 pixel×1 160 pixel,包含多种类型的车牌。其中“DB”为光线较暗或较亮车牌、“Challenge”为具有挑战性的车牌、“Blur”为模糊的车牌、“FN”为距离摄像头较远或较近的车牌、“Rotate”为小倾斜角度车牌(水平倾斜20°~50°,垂直倾斜-10°~10°)、“Tilt”为大倾斜角度车牌(水平倾斜15°~45°,垂直倾斜15°~45°)、“FPS”为帧率、“AP”为平均准确率,具体如表1所示。这些图片包含不同背景、不同拍摄角度、不同拍摄时间和不同光照等级的独立车牌图像,是现有公开车牌识别数据集中种类最为丰富、度最高的数据集,可以很好地验证本文提出方法的有效性。

表1 CCDP数据集检测结果
评价指标选取上,在车牌检测任务中本文使用目标检测中广泛使用的VOC评价标准[20]进行评估。具体地,对比每张图片检测出的结果和真实标签的交并比(IOU),如果IOU值超过了某个阈值,则将它划归到真阳(True Positive,TP)中,IOU值低于某个阈值,则将它划归到假阳(False Positive,FP)中。最终根据TP,FP计算准确率和召回率,然后据此计算平均准确率(Mean Average Precision,MAP)。车牌识别任务的评价指标与ICDAR2013场景文字识别的评价指标相同,即当某个文本识别的结果和真实标签一致时才算正样本,最终计算每个类别的平均准确率即为最终的MAP结果。
3.2 车牌识别结果比较
本文提出的模型同时在检测器和识别器中进行端到端联合训练。检测器采用了一种基于弱监督框架的学习方法进行训练,因此识别器只反向传播由正确分割的车牌在训练每个阶段产生的损失。此外,在训练过程中还应用了水平翻转、随机裁剪、仿射变换和颜色变化等数据增强技术。本文训练过程可以分为2个阶段:基于人造数据集的预训练阶段和基于真实数据的参数微调阶段。首先,利用人造数据对主干网络进行预训练初始化网络参数,直到损失值收敛;然后,在CCPD数据集上进行正式训练,正式训练阶段的损失函数引入真值置信度。
为了验证模型的有效性,本文选取了最具代表性的Faster R-CNN和SSD作为基线模型进行实验对比,定量结果如表1所示。实验结果表明,本文提出的车牌识别模型在车牌检测任务上远超基线模型,尤其在旋转和倾斜数据上显著地超过了基于目标检测的模型。而在车牌识别任务上,本文选取“ SSD+HC ”的模型[21]作为基线模型,定量结果如表2所示。

表2 CCPD数据识别结果
实验结果表明,本文提出的网络模型在车牌识别任务上具有明显优势。部分检测识别可视化结果如图4所示,可以看出,本文提出的模型可以成功检测并识别常规、倾斜角度及低分辨率图像中的车牌。

图4 车牌识别可视化结果Fig.4 The visualization results of license plate recognition
为了进一步验证本文轻量级主干网络中FPEM和FFM模块的必要性,采用消融实验进行验证。实验使用ResNet18作为基本骨架网络,具体结果如表3所示。实验结果表明,相比于传统的FPN,FPE和FFM结构,本文方法在保证模型准确率的前提下极大地降低了模型复杂度和推理时间;同时相较于不使用该模块又提升了模型准确率。因此相较于传统的CNN特征提取架构,本文采取的FPEM和FFM的结构能够更好地与主干网络架构相结合,在具有轻量级网络快速提取特征的基础上,增强了图像中不同尺度车牌区域特征表示能力,从而使其适合于各类富有挑战的车牌识别任务。

表3 本模型关于分割头的消融实验
4 结束语
本文的主要贡献包括两方面:① 提出了一种基于字符区域感知的车牌识别框架,将车牌识别问题转换为直接对车牌中每个字符进行定位并识别的问题,有效兼顾了复杂场景下车牌识别的精度与实时性需求;② 构造了人造车牌相关字符数据集并将其应用于车牌字符区域感知模型预训练过程,有效提升了模型对车牌字符区域的感知能力与识别精度。
未来的工作将会继续优化改进端到端车牌识别模型,如利用模型压缩剪枝等方法加快模型推理速度,使之可以更好地适应实际应用。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
动漫界·幼教365(中班)(2021年4期)2021-05-23
集美大学学报(自然科学版)(2021年2期)2021-04-29
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年11期)2019-07-04
小猕猴智力画刊(2017年5期)2017-05-25
