
基于Apriori算法的图书馆用户行为模式分析研究
2022-06-15 15:31刘璐璐陈志飚黄勇熊章远
现代信息科技 2022年2期
刘璐璐?陈志飚?黄勇?熊章远

摘 要:以某高校图书馆信息管理系统用户数据为研究对象,对图书馆用户借阅行为进行研究。充分利用业务系统海量数据优势,使用K-means算法对用户数据进行聚簇,将用户群体细分形成相似群,然后构造用户行为指标体系,再选用Apriori关联规则算法,根据借阅行为数据特点构造用户行为分析模型,同时在聚类群体数据的基础上进一步深入挖掘,最后得到用户行为规则和模式。研究结论可为图书馆合理丰富馆藏、图书采编、书架摆放、业务系统流程优化等提供参考。
关键词:图书馆;用户行为;关联规则;数据挖掘;Apriori算法
中图法分类号:TP391;G252 文献标识码:A文章编号:2096-4706(2022)02-0009-04
Abstract: Taking the user data of the information management system of a university library as the research object, this paper studies the borrowing behavior of library users. Make full use of the massive data advantages of the business system, cluster the user data by using the K-means algorithm, subdivide the user group into similar groups, and then construct the user behavior index system, and then select the Apriori association rule algorithm to construct the user behavior analysis model according to the characteristics of borrowing behavior data. At the same time, further mining is carried out on the basis of clustering group data, Finally, the user behavior rules and patterns are obtained. The research conclusion can provide reference for the library to reasonably enrich the collection, book collection and editing, bookshelf placement, business system process optimization and so on.
Keywords: library; user behavior; association rule; data mining; Apriori algorithm
0 引 言
大數据技术的不断成熟,掀起了新时代信息化发展又一波高潮,高校图书馆数字化智能化发展与研究也逐渐成为时下研究热点。随着高校图书信息管理系统的用户数据的不断积累,如用户的专业、课程、学科、年级、查询关键词等信息,为图书馆用户行为的研究提供了难得的一手实验数据。目前,这些海量的数据除了用于记录图书的借阅信息之外,大多仅用于统计日常业务数据,而数据的真正价值往往被图书管理者忽略。
图书馆用户在专业课程学习或进行科研活动过程中,往往需要到图书馆借阅图书、期刊等书籍,跨学科或专业等交叉式学习研究已成为常态,用户的这些借阅行为往往会存在一定的行为特征,用户群体之间存在共性,借阅书目之间存在关联[1]。一般来说,图书建设管理方可以根据用户的专业或者研究方向等信息,利用自身图书管理经验来判定用户借阅图书类别需求[2]。但客观来说,很多用户行为之中隐藏的关联性很难凭借图书管理人员的常识或经验去获取。本文利用图书馆信息系统产生的借阅数据,通过数据挖掘技术来进行深度挖掘,借此发现这种“隐藏的关联性”,以推动高校图书馆的服务工作向智能化方向迈进。
如何根据用户的个人信息(如专业、课程、年级等)、借阅记录(如借阅时间、频度、学科等)、查询关键词记录等数据,发现不同用户的借阅行为是否有关联?不同的专业与书目之间是否存在关联?用户的借阅图书种类会出现什么样的趋势?用户的借阅习惯存在什么样的规律?挖掘出这些数据之间规律,有利于合理配置图书资源和提高资源利用率,合理分布图书馆馆藏书籍,为师生用户主动提供个性化的服务。
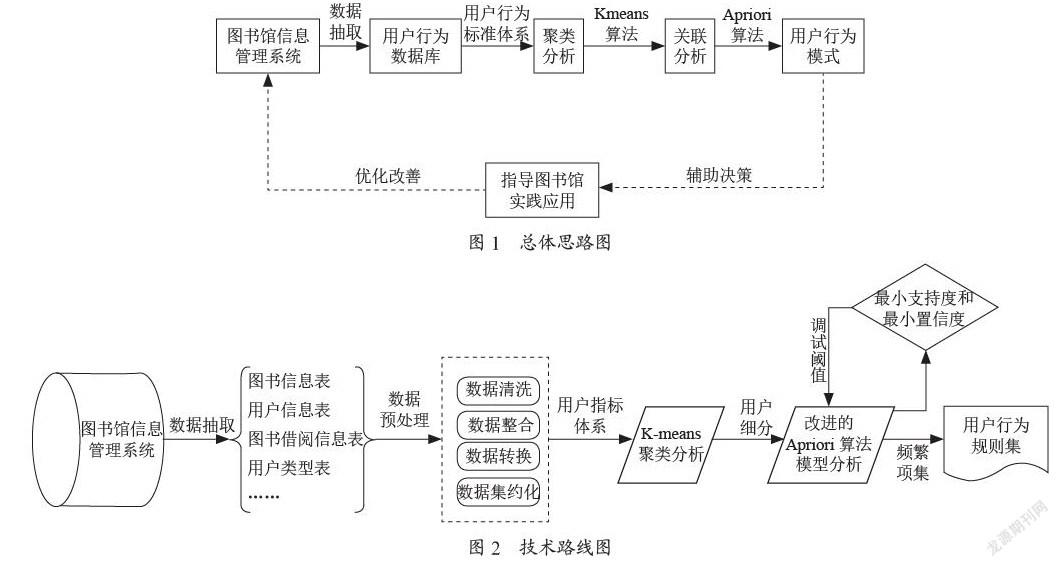
1 总体思路
传统的图书馆用户数据分析是基于数据统计的基础上,实现数据的检索、分类等功能[3]。图书馆数据库中大量借阅数据,通过数据挖掘可以很好地反映出用户的需求,找出用户借阅图书之间存在的关联规则、不同学科图书之间存在的关联规则、不同专业用户借阅图书的规律等等[4,5]。
如图1所示。本文通过利用高校图书馆信息管理系统,对从用户查询、采编、流通、借阅、图书订购、用户信息数据中抽取学生、教师等用户信息建立用户行为数据库。通过数据清洗、转换、集约化处理等预处理过程,建立用户借阅记录、兴趣和习惯等维度的数据标准体系。通过聚类分析将用户标记分类,使用Apriori关联规则分析用户行为关联规则和规律,识别分析出发现用户特征与他们借阅行为的规律性,最后论述用户的隐形需求、行为习惯以及未来的借阅趋势,最终从真正意义上实现个性化信息服务的目的,为高校图书馆用户服务、科学丰富馆藏,图书采编行为,书架摆放设置,图书信息系统业务流程优化等提供实践参考。E5787314-7492-4389-B566-4A8809DEA7D0
2 用户行为分析模型
图书馆用户借阅行为模式研究主要包括四大过程数据抽取、数据预处理、聚类分析、关联规则分析,最后形成用户行为规则集,如图2所示。
2.1 收集用户基础数据
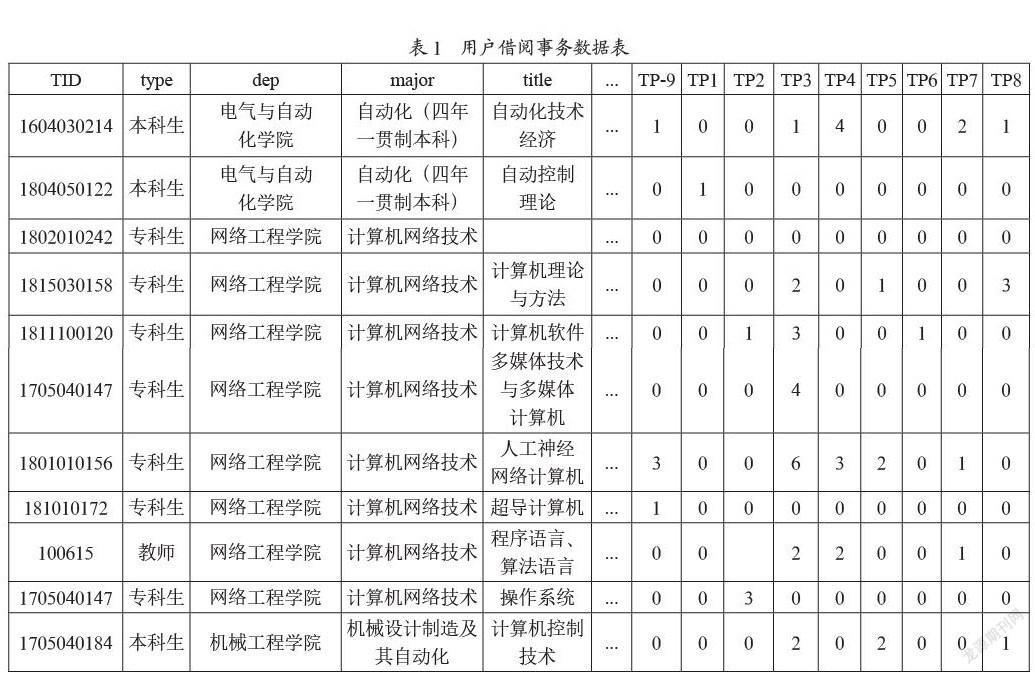
本文通过某高校图书馆信息管理系统数据库抽取2019年到2020年为期一学年的数据,主要包括用户基本信息(学号、年级、专业、学科课程等字段)和借阅图书信息(题名、索书号、中国图书馆分类号、作者、出版等字段),通过这些数据来描述用户的借阅行为。本文研究获得的未经处理的原始数据有用户基础信息18 565条记录,借阅图书信息595 153条记录。
2.2 数据预处理
清洗收集到的数据中既有噪声数据、空缺数据、分散数据[6];整合归并不同数据源的数据文件;使用如采用分箱、聚类和回归等方法对数据进行规格化处理。
我们将数据表中每一行记录定义为一个事务,包含一个唯一的标识TID(学号或教师号)和用户的基础信息(用户类型、学院、专业、图书名称、图书分类等)和借阅图书信息,其中为了分析用户基础信息和图书借阅信息之间的关联,为更好地开展实验,本文根据中图法对所借阅图书进行分类,以此来整合归并用户借阅图书信息。实验中,取到第四类,如分类号为TP3的图书,按照中图法分类,就是计算技术、计算机技术类图书。然后将每一用户借阅的书目放在同一个项集中,若该用户借阅了该类书目,则通过借阅数量来进行标记。其处理结果如表1所示(部分代表数据),每条借阅记录中包含着诸如以下几个信息:用户号(TID)、用户类型(type)、用户所在院系(dep)、用户专业(major)、用户借阅图书名称(title)及用户对每本书的借阅情况(books)。
2.3 用户群体聚类分析
利用用户借阅事务数据表,使用K-means聚类算法用户进行细分生成用户相似群。本文对用户借阅各类书目的次数聚类,将用户分成行为具备共性聚簇,在各簇之间用户借阅书目的类型和数量构成比较接近,表现为对用户借阅数量上不同,以及用户借阅频率的高低。在实际K-means聚类过程中,通过对K值的不断调整,最终将K值确定为5,即将用户细分为5个大类。用户群体聚类分析结果如图3所示。
在本次聚类分析中,用户群体总计为11 305个用户。从图中聚类结果可以看出,用户最多的为类1,占比52.5%,有5 935个用户,该年度借阅图书数量4.7本;聚类2中用户数为3 742,占比33.10%,该年度借阅数量为12.3本;聚类3中用户数为1 587,占比14.04%,该年度借阅数量为22.4本,聚类4中用户数为36,占比0.32%,该年度借阅数量为42.6本。可以到聚类1、聚类2、聚类3、聚类4包括绝大分用户,占比99.9%,表现为绝大部用户年度借阅书目在4.7~42.6本,该校图书总体利用率较低。聚类5中用户数为5,属于极个别情况,实际上由于方差太大,为52.04%,说明该类用户的借阅行为在数据上体现为比较离散,不具备普适性。
2.4 用户行为模式分析
传统的用户行为属性研究都是将全部信息作为产生规则的数据源或是主观性的根据用户的自身属性特征(用户所在院系,性别等因素)对用户进行分类,以每个类中的借阅信息作为产生规则的数据源,然后对每位用户实行关联[7]。本文利用Apriori关联规则算法,根据借阅行为数据特点构造用户行为分析模型,同时在聚类群体数据的基础上用户类型、专业、学科等基础信息等与书目之间进一步深入挖掘,最后得到用户行为规则和模式。如在数据挖掘过程中,发现大部分用户借阅了“人工智能”的同时也借阅“统计学”这本书,我们认为这两本书存在一定关联,可以作为用户借阅行为模式。图4是本文构建的用户借阅行为模式关联规则挖掘的模型。在此基础找出有效的借阅规则,然后根据用户的借阅兴趣,向用户推荐可能会感兴趣的图书。
本文进行的用户行为模式分析,主要包括两个部分,一是利用用户借阅图书信息进行关联规则分析,二是在上文聚类出的5类相似群内容进一步进行关联规则挖掘。
2.5 结果分析
在用户行为模式反复挖掘过程中,我们调试试验参数,最后将最小支持度设置为52%,最小的置信度设置为60%,最后共生成126条关联规则,部分结果如表2所示。如首条关联规则显示,借阅H和B类书目的用户去借阅I类书目的概率为99.361%,借阅H、B、I类书目的事项的概率为65.199,其他关联规则可类比解释。在聚类出的5类相似群内容进一步进行关联规则挖掘,去掉一部分无效的关联规则,我们发现了24条关联规则。这些关联规则可以作为用户的行为规律和模式,可为图书馆合理丰富馆藏、图书采编、书架摆放、业务系统流程优化等提供参考。
3 结 论
本文利用用户图书借阅行为数据,使用K-means算法对用户进行聚簇形成相似群,然后选用Apriori关联规则算法,并根据借阅行为数据特点构造用户行为分析模型,同时在聚类数据的基础上进一步深入挖掘,最后得到用户行为规则和模式。目前的图书馆管理系统大多缺乏数据挖掘功能,本文研究有利于图书馆建设管理方全面掌握用户的阅读习惯和行为模式,通过对用户的阅读规律进行分析,可为图书馆合理丰富馆藏、图书采编、书架摆放、业务系统流程优化等提供参考,积极向用户提供更加个性化的服务。
参考文献:
[1] 李宝.基于用户画像的高校图书馆个性化资源推荐服务设计 [J].新世纪图书馆,2021(4):68-75.
[2] 陈东华.计算机技术进行图书分类的问题探讨 [J].中外企业家,2019(29):124.
[3] 乔鑫鑫.信息化技术在图书管理中的应用 [J].电子技术与软件工程,2021(2):235-236.
[4] 张媛玲.互联网时代的图书管理信息化建设探索 [J].汉字文化,2018(17):119-120.
[5] MAURI M,ELLI T,CAVIGLIA G,et al. Rawgraphs:a visualisation platform to create open outputs [C]//CHItaly17:Proceedings of the 12th Biannual Conference on Italian SIGCHI Chapter.Cagliari:Association for Computing Machinery,2017:1-5.
[6] 姜云龍.基于数据挖掘的高校大学生读者阅读趋向研究 [D].东北师范大学,2016.
[7] 李文华.基于Apriori关联分析与协同过滤的图书推荐算法 [J].电脑知识与技术,2017,13(33):32-33+35.
作者简介:刘璐璐(1991—)女,汉族,安徽宿州人,馆员,硕士研究生,研究方向:计算机。E5787314-7492-4389-B566-4A8809DEA7D0
猜你喜欢
广西教育·C版(2016年11期)2017-01-16
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
湖南师范大学社会科学学报(2016年5期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
科技视界(2016年5期)2016-02-22
