
BERT的图模型文本摘要生成方法研究
2022-06-15 15:52黄菲菲
现代信息科技 2022年2期
关键词:相似度



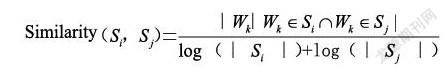

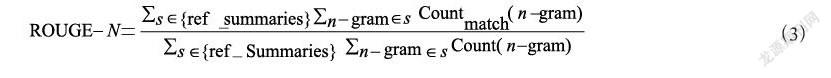

摘 要:基于图模型的TextRank方法形成的摘要不会脱离文档本身,但在抽取文本特征的时候,传统的词向量获取方法存在一词多义的问题,而基于BERT的词向量获取方式,充分挖掘了文本语义信息,缓解了一词多义问题。对不同词嵌入方法进行了实验对比,验证了BERT模型的有效性。基于词频统计的相似度计算方法也忽略了句子的语义信息,文中选择了向量形式的相似度的计算方法用于文本摘要生成。最后在TTNews数据集上做实验,效果有了明显的提升。
关键词:中文文本摘要;BERT;TextRank;相似度
中图分类号:TP 391 文献标识码:A文章编号:2096-4706(2022)02-0091-06
Abstract: The abstract formed by TextRank method based on graph model will not be separated from the document itself, but when extracting text features, the traditional word vector acquisition method has the problem of polysemy, while the word vector acquisition method based on BERT fully excavates the semantic information of the text and alleviates the problem of polysemy. The experimental comparison of different word embedding methods verifies the effectiveness of the BERT model. The similarity calculation method based on word frequency statistics also ignores the semantic information of sentences. In this paper, the similarity calculation method in vector form is selected for text abstract generation. Finally, the experiment on TTNews data set shows that the effect is obviously improved.
Keywords: abstract of Chinese text; BERT; TextRank; similarity
0 引 言
文本摘要作为自然语言处理领域的主要研究方向之一,它的主要任务是信息抽取。在这个互联网快速发展的时期,每天都能从网上看到大量的文本信息,比如新闻微博等。然而并不是所有的信息都是需要的,我们都只关注自己所关心的内容,如何从大量的文本里面抽取到关键信息以帮助人们快速获得自己想要的信息,是本篇论文主要讨论的问题。文本摘要的主要任务就是抽取关键信息,进而可以解决这一问题,文本摘要旨在帮助人们从大量的文本信息中快速找到自己关注的信息。如果把含有几千字的文章缩写成几百字,那么读者就可以很轻松地了解到文章的主旨,摘要分为“人工摘要”和“自动摘要”,人工摘要由读者自己阅读总结得到,可能需要花费读者大量的时间和精力,自动摘要是由机器得到的。
文本摘要可以分为抽取式摘要、生成式摘要[1]和混合式摘要。抽取式摘要可以简单概括为从原文档中抽取出一个或者多个句子拼接在一起构成摘要,这样得到的摘要不会脱离文档本身,既简单又实用。抽取式摘要主要思想是对文档的每句话打分,句子的重要程度就是根据分数的高低来判定的,按照分数的高低对每个句子排序,分数高的前几个句子被抽取出来形成摘要。生成式摘要和抽取式摘要不同,它重在提取每个句子的特征,获取文档的主要思想后,重新组织语言生成新的句子组成摘要。混合式摘要就是将上述两种方法结合在一起生成的摘要称为混合式摘要。
文本摘要又可以按照文档的其他形式划分,比如按照文档数量划分,分为单文档摘要和多文档摘要[2],这两者只是在文档数量上有所不同,单文档是指只针对一篇文档,多文档针对同一類型的多篇文档处理,最后生成的摘要包含了这些文档的主题信息。
1 相关工作
1.1 文本摘要研究现状
抽取式文本摘要简单实用,目前也出现了很多抽取式摘要生成方法,其中在工业方面应用的比较广泛,目前主要的技术方法有基于主题模型、基于图模型、特征评分、深度学习,等等。
1958年Luhn[3]提出了基于高频关键词给文章句子排序得到摘要的方法。Kupiec[4]等人采用了朴素贝叶斯分类器来计算一个句子是否为摘要句的概率。Aone[5]提出了TF-IDF[6]方法来计算某个句子成为摘要句子的概率。Conrog[7]等人运用马尔可夫模型来抽取摘要句子。
上述几种方法都是基于统计特征为基础的摘要方法。这几种方法得到的摘要的可读性不是很好,为了继续完善自动摘要提取方法,GunesErkan和Rad等人[8]提出了TextRank方法,这个算法计算每两个句子之间的相似度,计算每个句子占全文信息的比重,选择比重较高的前几个句子组成摘要。随着深度学习不断地发展,生成式摘要也逐渐得到了广泛的研究。2014年Google提出的序列到序列模型[9]最开始应用在翻译任务中;2015年Facebook公司的Rush等人[10]将深度学习的端到端的方法首次应用到摘要的生成任务中,得到了很好的效果;Chopra等人[11]用卷积神经网络编码原文信息,采用循环神经网络进行解码生成了更加连贯的摘要;Nallapati[12]等在编码阶段使用双向循环的神经网络,还对低频词进行了处理;2016年谷歌[13]发布的摘要模型采用了集束搜索(Beam-Search)来生成摘要,这种方法在编码和解码的部分采用的是循环神经网络,避免时间和空间的浪费;2018年谷歌发布BERT[14]模型,这个模型被多次应用在自然语言处理任务中,都取得了比较好的效果。
1.2 主要工作
在以往的NLP任务中,词向量的表示方法有One-Hot方法,可是One-Hot编码方式存在维度过高的缺点,计算量非常庞大。2013年Mikolov等人提出了基于分布式的词嵌入方式Word2Vec方法,这个方法网络结构简单,训练的中文语料比较少,不能提取句子的深层语义信息。2018年由Jacob Devlin等人研發出BERT[14]模型,BERT内部主要由Transformer[15]组成,该模型网络结构复杂,训练的中文语料比较多,充分提取文档的语义特征,缓解了一词多义问题。本文选用BERT模型,是因为BERT模型使用双向Transformer编码器,Transformer模型能够抽取句子的特征,得到的词向量会随着上下文语境的改变而动态变化,使句子的语义表达更准确,比如“苹果公司”和“吃个苹果”,“苹果”在第一个句子中代表的是一个品牌的名字,在第二句话中表示的是水果的意思,BERT在对苹果这个词进行编码的时候会根据其所在的上下文不同而改变编码的词向量,使其更符合所表达的含义。对于之前从未考虑过的词的位置信息影响语义的表达的问题,比如像“明天你去我家”和“明天我去你家”,意思完全不一样,BERT加入Position Embedding来保留位置信息,使相同的词在不同的位置的时候表达的语义信息更加准确。本文将其他词嵌入方法与BERT模型用于文本摘要做了实验对比,BERT相比较其他模型来说能达到比较好的效果。将微调后的BERT用来预处理文本,原始的BERT输出是针对Token的而不是句子,并且原始BERT的输入只有两个句子,不适合做文本摘要任务,所以,为了使它更加适合文本摘要任务,需要对BERT模型做一些修改。在每个句子句首加上[CLS]标签,每个句子的末尾都有一个[SEP]标签,[CLS]标签可以区分每一个句子,BERT可以输入多个句子,给句子进行编码构成特征向量,用于文本摘要任务。基于图模型的方法处理文本信息,通常以单词或者句子作为处理文本单元,在抽取式文本摘要中,主要以句子为文本单元进行处理,将句子作为顶点,2个相似的点用边连接起来构成图,利用图排序算法,比如TextRank算法对句子进行打分排序。这种方法依赖句子之间的相似度,主要进行任意句子之间的相似性计算和迭代计算,TextRank算法是基于PageRank算法改进而来。传统的TextRank模型在计算句子的相似度时用的是基于词频的统计方式,这种方法没有考虑到句子语义方面的信息,比如像“你美不”“你不美”这类的句子,没有考虑到他们的语义层面的信息,结果存在不必要性。本文用余弦相似度的计算方法代替了传统的词频统计方法,结果得到了明显的改善。本文研究内容主要有:
(1)基于BERT的句向量表示。通过word2vec或者glove方法抽取浅层的文本特征来对基本语义单元进行向量化表示,而后依据相应算法计算句子的权重,这种方法存在一词多义问题,抽取得到的摘要句精确度低,连贯性差。针对这一问题使用BERT对句子进行向量化表示,学习和开发深层次的语义特征,效果有明显改善。
(2)句子的相似度度量。用TextRank方法做抽取式摘要,计算每两个句子之间的相似度时,用的是基于词频的相似度度量方法,这种方法忽视了句子的上下文信息,针对这一问题本文对比了其他的相似度度量方法进行研究。
(3)关于TTNews的文本摘要生成。将本文的文本摘要生成方法用于TTNews数据集上,用其他方法和本文方法做了实验对比,运用ROUGE评价方法评测了摘要的质量。
2 研究方法
获取句子的向量形式,本文使用改进的BERT方法,原始的BERT输出是针对Token而不是句子,并且原始BERT的输入只有两个句子,不适合做文本摘要任务,所以,需要对BERT模型做一些修改。在每个句子句首加上[CLS]标签,使[CLS]标签可以区分每一个句子,同时BERT可以输入多个句子。使用BERT来获取句子的表示向量,借助BERT模型的强大表示能力,更好地捕捉句子的上下文信息。用TextRank算法对文本进行抽取处理,将文档中重要的句子抽取出来组合在一起,生成新的文本摘要。
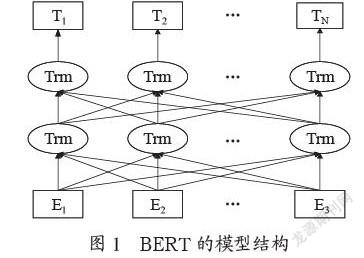
2.1 BERT的模型
图1为BERT的模型结构,BERT内部主要由多层Transformer构成。Transformer基本结构是Encoder-Decoder,Encoder表示编码器,Decoder表示解码器Transformer由这两者组合而成。
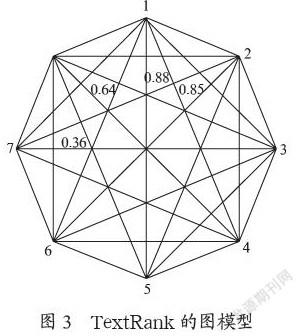
2.2 TextRank图模型
TextRank做文本摘要,针对单个文档首先根据标点符号进行句子分割,针对每个句子获得句子的向量表示,构建相似度矩阵,然后以句子为顶点,相似度作为边表示成图的形式,最后计算每个顶点的得分,把得分最高的前几个句子抽取出来构成文档的摘要,其流程图如图2所示。
具体流程为:
(1)将文档按照: , ? ! 。 ; “”等标点符号划分成一系列的句子。
(2)文本预处理,去除停用词,然后进行(jieba)分词,得到句子中词的词向量,对词向量求平均作为句子的向量表示。
(3)计算每两个句子之间的相似度值,然后以句子为顶点,相似度值作为边,将两个顶点连接构成图如图3所示。
(4)计算每个句子的得分值。
(5)最后按照分数高低排序,得分高的前几个句子抽取出来构成摘要。
TextRank图模型如图3所示,每个顶点代表的是文本中的句子,两个顶点连线上的数字为两个句子之间的相似度。
2.3 本文方法
摘要生成的流程图如图4所示,首先根据标点符号对文档进行句子分割,然后送入BERT模型,BERT模型首先对文档每个句子进行处理,在每个句子开头加[CLS]标签,句子的末尾加上[SEP]标签,句子表示成图4(TokenEmbedding+SegmentEmbedding+PositionEmbedding)的形式,BERT模型内部有多个Transformer层,经过这些Transformer层处理后输出每个句子的向量表示形式。然后求每两个句子之间的相似度值,构建相似度矩阵,以每个句子为顶点,句子之间的相似度作为边构建图模型,最后求每个句子的得分值,选取得分高的几个句子作为文档的摘要。
2.3.1 文本句向量表示
给定一篇文档D={S1,S2,S3,…,Sn}(其中n表示文档的第n个句子),BERT模型的句向量表示如图5所示。
原始的BERT输出是针对Token的而不是句子,由于原始BERT模型不适合文本摘要任务,所以,需要对模型做一些修改。在每個句子句首加上[CLS]标签,句子的末尾都有一个[SEP]标签,因此模型可以区分开每一个句子。
TokenEmbeddings:先得到每个词的词向量形式;
SegmentEmbeddings:根据i的奇偶性来决定这个句子的段嵌入为EA或者EB;
PositionEmbeddings:根据词在文档中的位置训练得到;
将上面三个向量相加TokenEmbedding+SegmentEmbedding+PositionEmbedding作为BERT模型的输入。即:
(1)将每个句子用向量表示出来保存在[CLS]中。
(2)经过BERT模型,得到每个句子的向量表示,这种向量表示包含句子的上下文信息,考虑到了句子语义层面的信息。
BERT模型与其他模型相比,可以充分挖掘词的上下文的信息,获得含有语义信息的向量表示形式,因此可以在一定程度上缓解多义词问题。
2.3.2 摘要句抽取
TextRank算法求句子的相似度,是基于词频的统计方式,忽视了句子之间的语义信息。计算公式为:
(Si,Sj表示第i个句子和第j个句子,wk表示第k个词)这种计算方法仅仅通过统计两个句子之间的公有词的个数来计算句子之间的相似度,没有考虑任何语义层面的信息。本文用BERT模型获取的句子的向量来计算相似度,因为BERT模型使用双向Transformer编码器,即让两个Transformer特征抽取器分别从左到右和从右到左扫描输入序列。BERT加入Position Embedding来保留位置信息,使相同的词在不同的位置的时候表达的语义信息更加准确。本文通过用余弦相似度的计算方法计算相似度,这个方法正是计算两个向量之间的方向关系,这样求得的句子之间的相似度更能表达两个句子之间的关系。
本文也考虑了用欧氏距离[16]来计算两个句子的相似度,可因为欧氏距离主要用来计算两个点之间的距离,和两个点之间的坐标信息有关,而语义层次的信息并不关心数值的大小,更多的是关注两个向量在方向上是否更加接近。基于此,余弦相似度的度量方法可以更有效地表示两个句子之间的相似度关系。
给定文档D,划分句子D={S1,S2,S3,…,Sn}。以句子为顶点,构建图G(V,E),其中V代表句子的集合,E是边的集合,句子之间的相似度作为构成图的边的权值。
式(2)中,WS(Vi)表示顶点i的得分,d的值为0.85。in(Vi)代表所有指向点i的点,Wji表示点j和点i之间的边的权值,out(Vj)表示所有从点j指向其他顶点的点,Wjk表示点j和点k的边的权值,WS(Vj)表示顶点j的得分。
根据式(2)得到每个句子的得分值,本文选取得分比较高的前三个句子作为文档的摘要。
3 实验分析
3.1 实验数据
文章提出的方法用在了TTNews corpus数据集上,取得分最高的前三句作为文本摘要,并与其他三个抽取式摘要方法做了对比。
3.2 实验环境及参数设置
实验环境:Pytorch 1.8.1,Tensorflow 1.9.0,Torchvision 0.8,Cuda 9.2。
实验使用的BERT-base模型共12层即12个encoder单元,隐藏层768维,12个attention,序列长度为128。
3.3 评价指标
文中用ROUGE[15]作为文本自动摘要的评价指标,Rouge方法比较本文生成的摘要与数据集给出的标准摘要的重叠单元,来评价模型生成摘要的质量。本实验用ROUGE-1、ROUGE-2、ROUGE-L这三个值作为评价指标对得出的摘要进行评价。
式(3)中n代表比较文本单元的长度,Countmatch代表的是同时出现在标准摘要和机器生成的摘要的文本的数目。
ROUGE-L表示的是标准摘要和本文生成的摘要的最长公共子序列的长度占标准摘要的比例。
3.4 实验结果与分析
实验进行了2000次迭代,文中介绍的抽取式摘要方法和其他抽取式摘要方法都在TTNews数据集上做了比较。从解决一词多义方面考虑,首先对word2vec、glove、BERT三种不同的词嵌入方法做了实验对比,结果如表1所示,从中可以看出相比较其他词向量表示方法,文中采用的方法效果更好。
对于不同的相似度计算方法,对比了TextRank原始的词频统计方式、欧氏距离相似度算法,以及文中用的余弦相似度算法,相似度比较结果如表2所示。从中可以看出,文中选用的余弦相似度计算方法判断两个句子之间的相似性精确度有了明显的提升。
最后,用文中提出的抽取式摘要方法与其他几个抽取式摘要方法做了实验对比,结果如表3所示。
Lead3方法:选取文章的前三个句子作为文章的摘要部分。这种方法虽然简单方便,但是存在信息覆盖不全,容易损失信息的缺点。
TextRank[17]方法:构建图模型,用算法为文档的每个句子按照得分排序。此方法经过本文方法的改进后,摘要信息的准确率得到了明显的提升。
TF-IDF方法[6]:根据每个句子中词语的TF-IDF值来计算句子的得分,句子的重要性根据词的重要性之和来估计,选取重要性高的几个句子作为摘要。这种方法句子的重要性主要通过“关键词”来衡量,得到的摘要存在片面,信息涵盖不全,不连贯等缺点。
從表3中可以看出本文提出的方法和其他几种方法相比,ROUGE-1、ROUGE-2、ROUGE-L的值都有所提升。说明本文提出的方法生成的摘要准确性和可读性有一定的保障。
4 结 论
文中主要介绍了一种对TextRank方法进行改进而得到的一个抽取式文本摘要方法,分别介绍了BERT的模型结构和TextRank处理文本的流程及原理,以及计算句子相似度的方法。因为近些年BERT模型在NLP领域处理文本的时候效果都比较好,所以选择了BERT模型来进行处理文本。文中首先对BERT进行改进,使它适用于处理多个句子,对多个句子进行向量表示。然后基于TextRank的思想对句子进行打分处理。就是将两种模型综合在一起使用,然后选择了合适的文本相似度度量方法,最后将得到的文本摘要同标准摘要进行对比分析。文中提出的方法虽然准确率得到了提升,但是得到的文本摘要还达不到非常好的效果,比如句子不够通顺、存在句子冗余等问题,文本摘要在自然语言处理领域还有待发展。
参考文献:
[1] MIHALCEA R,TARAU P. TextRank:Bringing Order into Texts [EB/OL].[2021-11-12].https://digital.library.unt.edu/ark:/67531/metadc30962/m1/1/.
[2] 胡侠,林晔,王灿,等.自动文本摘要技术综述 [J].情报杂志,2010,29(8):144-147.
[3] LUHNHP. The automatic creation of literature astracts [J].IBM Journal of Research and Development,1958,2(2):159-165.
[4] KUPIEC J,PEDERSEN J O,CHEN F. A trainable document summarizer [C]//18th annual international ACM SIGIR conference on Research and development in information retrieval.New York:Association for Computing Machinery,1995:68-73.
[5] AONE C,OKUROWSKI M E,GORLINSKY J,et al. A rainable summarizer with knowledge acquired from robust NLP techniques [M]//INDERJEET M,MARK M T.Advances in Automatic Text Summarization,Cambridge:The Mit Press,1999:71-80.
[6] SALTON G,BUCKLEY C.Term-weighting approaches in automatic text retrieval [J].Information Processing & Managem-ent,1988,24(5):513-523.
[7] CONROY J M,OLEARY D P. Text summarization via hidden Markov models [C]//SIGIR ‘01: Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval,New Orleans:Association for Computing Machinery,2001:406-407.
[8] ERKAN G,RADEV D R. LexRank:Graph-based Lexical Centrality as Salience in TextSummarization [J/OL].arXiv1109.2128[cs.CL].[2021-11-23].https://arxiv.org/abs/1109.2128.
[9] BAHDANAU D,CHO K,BENGIO Y. Neural Machine Translation by Jointly Learning to Align and Translate [J/OL].arXiv:1409.0473 [cs.CL].(2014-09-01).https://arxiv.org/abs/1409.0473,2014.
[10] RUSH A M,CHOPRA S,WESTON J. A Neural Attention Model for Abstractive Sentence Summarization [C]//Proceddings of the 2015Conference on Empirical Methods in Natural Language Processing.Lisbon:Association for Computational Linguistics,2015:379-389.
[11] CHOPRA S,AULI M,RUSH A M. Abstractive sentence summarization with attentive recurrent neural networks [C]//Proceddings of the Annual Conference of the North American Chapter of the Association for Computional Linguistics:Human Language Technologies.San Diego:Association for Computational Linguistics,2016:93-98.
[12] NALLAPATI R,ZHOU B W,SANTOS CND,et al. Abstractive Text Summarization Using Sequence-to-sequence RNNS and Beyond [C]//Proceddings of the 20thSIGNLL Conference on Computational Natural Language Learning.Berlin:Association for Computational Linguistics,2016:280-290.
[13] ABADI M,BARHAM P,CHEN J,et al. Tensor Flow:Asystem for large-scale machine learning [C]//The Processing of the 12th USENLX Symposium on Operating Systems Design and Implementation.Savannah:USENIX Association,2016:265-283.
[14] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2021-11-23].https://arxiv.org/abs/1810.04805v1.
[15] 王侃,曹开臣,徐畅,等.基于改进Transformer模型的文本摘要生成方法 [J].电讯技术,2019,59(10):1175-1181.
[16] Cjayz.文本相似度算法研究[EB/OL].[2021-11-23].https://www.docin.com/p-2221663292.html.
[17] MIHALCEA R,TARAU P. TextRank:Bringing Order into Texts [C]//Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing.Barcelona:Association for Computational Linguistics,2004:404-411.
作者簡介:黄菲菲(1995—),女,汉族,河南商丘人,硕士在读,研究方向:自然语言处理。
猜你喜欢
中国新通信(2016年22期)2017-01-13
计算技术与自动化(2016年4期)2017-01-11
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年13期)2016-06-29
电脑知识与技术(2016年7期)2016-05-19
科技视界(2016年10期)2016-04-26
现代经济信息(2016年3期)2016-03-24
电脑知识与技术(2016年2期)2016-03-22
