
基于改进SSD算法的限位器检测方法
2022-06-15 03:32张凤
现代信息科技 2022年2期
关键词:卡尔曼滤波
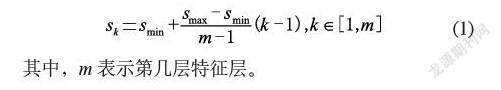




摘 要:自动泊车系统已经成为高级辅助驾驶系统(ADAS)中的一项重要功能,车辆在泊车过程中时常会出现泊車不到位、与相邻车位中的车辆发生剐蹭等事故。为提升自动泊车的精准性,文章提出了一种实时检测限位器的改进算法SSD-L,通过定位限位器的位置,对车辆的泊车位置进行修正。该方法对原先的SSD网络结构进行精简和改进,并使用卡尔曼滤波增加识别的稳定性。在实际泊车场景中的测试结果表明,SSD-L算法检测限位器的平均精度(mAP)较高,为95%。
关键词:限位器检测;SSD;卡尔曼滤波;ADAS
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2022)02-0174-04
Abstract: Automatic parking system has become an important function of advanced driver assistance system (ADAS). In the process of parking, there are often accidents such as vehicle not parking in place and rubbing with vehicles in adjacent parking spaces. In order to improve the accuracy of automatic parking, an improved algorithm SSD-L for real-time detection of the limiter is proposed, which modifies the parking position of the vehicle by locating the position of the limiter. This method simplifies and improves the original SSD network structure, and uses Kalman filter to increase the stability of recognition. The test results in the actual parking scene show that SSD-L algorithm has a high average accuracy (mAP) of 95% for limiter.
Keywords: limiter detection; SSD; Kalman filter; ADAS
0 引 言
随着汽车智能驾驶辅助技术的不断发展,自动泊车技术成为汽车辅助驾驶系统的关键技术之一,为了提高泊车过程中车位位置的定位精度,本文通过识别车位限位器来修正车辆在车位中的停车位置。将目标检测技术作为实现ADAS(Advanced Driver Assistance System)的基础,可以通过传感器准确地感知车辆周围的环境信息,并根据传感器系统的信息对限位器进行实时检测,并将检测结果传给决策层和控制层,及时采取相应的决策来控制车辆的停车位置,提升了汽车行驶过程的安全性和准确性,减少了财产损失。
目前,ADAS还是以视觉感知的方式来实现目标检测为主,雷达传感器作为辅助功能。随着基于深度学习网络的方法在ADAS目标检测方面的广泛应用,目标检测的效果不断提升,ADAS的实现等级也随之提高,安全性能也不断地提高。ADAS对使用的目标检测算法提出了严格的要求,主要体现在高准确率、实时检测、高鲁棒性方面,为此,国内外学者、高校研究院、工业界工程师做了大量的研究工作。
基于深度学习的目标检测算法,在目标检测的精度和鲁棒性方面都比传统的目标检测方法有了显著的提高。传统的目标检测算法是通过手工设计特征,而基于深度学习的目标检测方法则是通过卷积运算来学习各个层级的特征,与手工设计的特征相比,可以学习到更加丰富的特征,也具有了很强的表征能力。从ADAS的市场来看,工业界常用的基于深度学习的目标检测算法主要有:YOLOv3[1]和SSD[2]。基于回归的目标检测算法则去掉了耗时的目标区域的生成过程,而是按照预先设定好的方法去生成默认框,这样做使得检测速度得到了有效的提升,同时又可以保证检测的实时性。而SSD算法相比于YOLOv3算法加入了Faster R-CNN[3]的Anchor机制,这样做既能保证算法的实时性,又可以拥有较高的检测准确率。
本文对自动泊车场景下的限位器特点进行分析,限位器的种类主要分为分离式和长杆型两种,位于车位的中间靠后的位置,从标注的数据集来看,限位器不存在小目标检测问题,也没有遮挡问题,所以为了降低特征提取的计算量和模型的复杂度,将SSD算法模型中的浅层特征提取层删除,对SSD网络的主干部分进行改进,以此提出了一种适合的限位器检测的模型SSD-L,在限位器数据集和实际交通场景中进行SSD-L算法精度的验证。
1 SSD-L目标检测算法
1.1 原始SSD网络结构
原始SSD网络是使用VGG-16[4]作为主干网络,相比于轻量化网络VGG-16的网络结构比较深,模型参数量也比较大,SSD采用了多尺度特征检测的原理,第一个特征预测层输出的特征矩阵大小为38×38,用于检测小目标。
在不同的特征层上,Proir Box(区域候选框,类似于Anchor)的尺寸大小是不一样的,最低层的尺寸大小为0.2,最高层的尺寸大小为0.95,其他层的计算公式为:
1.2 SSD-L改进网络
车载ADAS系统对目标检测的实时性提出了较高的要求,为了提高系统检测的实时性,本文采用轻量化模型MobileNetV2[5]作为基础特征提取层,减少了模型的参数量,改进后的SSD-L的网络结构如图1所示,总共有5层特征图,去掉了原始SSD中的38×38大小的特征图,卷积层Conv4_b的特征图输入大小为19×19,用于检测小目标,1×1层特征图用于检测大目标,中间层的特征图分别用于预测目标的边框偏移以及得分,使用非极大值抑制(Non-Maximum-Suppression, NMS)[6]算法,将检测框按照得分高低进行排序,保留得分最高的框,同时删除与该框的重叠面积大于一定阈值的其他的检测框,就得到了最终的检测结果。
輕量级网络模型的复杂度和性能在一定程度上是有限的,当检测单帧图像上的目标时,得到的检测结果可能会出现以下问题:目标漏检、目标误检、难以检出小目标、较低的鲁棒性(无法很好地适应遮挡、大雾、雨天、夜间黑暗、反光、逆光等复杂场景)。上述问题使得目标信息极为不稳定,为后续算法的使用带来极大挑战,且误差不断向后传播,严重影响整体功能的效果。本文对检测框使用卡尔曼滤波器[7],可以实现物体检测框的高稳定性,能有效克服目标丢失误检、包围盒抖动等问题,在时序视频流上表现优越。
2 损失函数改进
2.1 原始SSD损失函数
原始SSD网络在训练过程中对目标类别和目标位置进行回归,它的目标损失函数分为两部分:定位损失(loc)与置信度损失(conf),其表达式为:
式(2)中:N表示区域候选框与真实框的匹配个数,如果N等于0则设置Loss的大小为0,x表示区域候选框与不同类别的真实框的匹配结果,如果匹配x等于1,如果不匹配则x等于0,c表示预测物体类别的置信度,l表示预测框位置的偏移信息,g表示真实边框和区域候选框的偏移量,α表示位置损失权重参数,其值通常设为1。
实际目标检测回归任务中,原始SSD算法的位置损失函数采用Smooth-L1[8],对区域候选框(p)的中心坐标(cx,cy)、宽(w)、高(h)的偏移量进行回归,按以下公式:
3 实验与结果
3.1 数据预处理
本文使用含有ADAS功能的车辆采集车位限位器,将采集的图片统一缩放到分辨率为640×480,并按照模型评估的规则制成LIMITER数据集,LIMITER数据集按照一定比例拆分成训练集和测试集,其中训练集包含100 000张图片,测试集包含20 000张图片,另外,正样本中的标注框按照一定的偏移制作10 000张负样本。该数据集主要包含日常中常见的分离式和长杆型两类车位限位器。模型在训练过程中,对训练集采用与原始SSD相同的数据增强方法,使得数据集数量达到一定的量级,还可以提高模型的泛化能力。
3.2 模型训练
本文目标检测网络训练所使用的预训练网络模型是基于VGG-16网络,预训练的网络参数是通过在PASCAL VOC 2007[10]数据集和COCO[11]数据集上对VGG-16网络进行训练得到。接下来使用预训练的网络参数对改进的SSD-L网络结构进行fine-tuning,fine-tuning过程中采用随机梯度下降法[12](Stochastic Gradient Descent, SGD)寻找目标函数的最优解,网络输入大小320×320,并根据LIMITER数据集标注框的大小,重新设计Proir Box的大小,训练采用的batch_size为64,总训练次数为210 000。
3.3 实验结果及分析
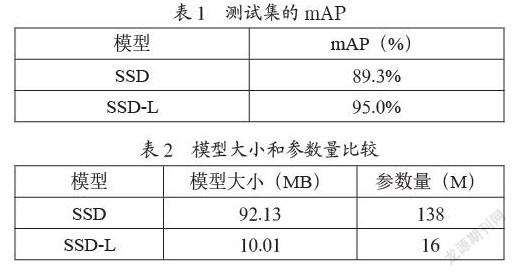
分别训练原始SSD网络(使用Smooth-L1损失函数),和改进型SSD_L网络(使用CIOU损失函数),两个模型在测试集上的检测性能如表1所示。可以看出,mAP从89.3%、提高到了95.0%,检测性能提高了约6.7%。从表2可以看出,SSD-L模型的大小减少了9倍,相应的参数量也大约减少了9倍,模型的计算量大大减少,满足了算法对实时性的要求。
从图2中两种限位器的检测结果可以得出,SSD-L对两种车位限位器的检测准确率能达到95%以上,很好地满足了ADAS对检测的高准确率需求。
4 结 论
本文通过重新设计SSD的网络结构,使用MobileNetV2作为主干网络,使其轻量化并降低了模型的复杂度,去掉了多余的区域候选框和目标预测层,比原始的SSD网络具有更少的参数量,预测速度也更快。使用CIOU损失函数,提高了模型对重叠目标的检测准确率,并使用卡尔曼滤波,进一步提高检测的准确度,SSD-L模型在工况良好的情况下,检测的准确率可以达到95%,在雨雪、阴天、夜晚等工况不好的情况下,其检测准确率还有待验证,这也是下一步需要进行优化的方向。
参考文献:
[1] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].[2021-11-08].https://arxiv.org/abs/1804.02767.
[2] LIU W,ANGUELOV D,ERHAN D,et al. SSD:Single Shot MultiBox Detector [C]//Computer Vision–ECCV 2016.Amsterdam:Springer,2016:21-37.
[3] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[4] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].[2021-12-03].https://arxiv.org/abs/1409.1556.
[5] SANDLER M,HOWARD A,ZHU M L,et al. MobileNetV2:Inverted Residuals and Linear Bottlenecks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4510-4520.
[6] NEUBECK A,GOOL L V. Efficient Non-Maximum Suppression [C]//18th International Conference on Pattern Recognition(ICPR06).Hong Kong:IEEE,2006:850-855.
[7] KALMAN R E. A New Approach To Linear Filtering and Prediction Problems [EB/OL].1960:35-45.[2021-11-23].https://ieeexplore.ieee.org/document/5311910.
[8] GIRSHICK R. Fast R-CNN [J/OL].arXiv:1504.08083 [cs.CV].[2021-11-23].https://arxiv.org/abs/1504.08083.
[9] ZHENG Z H,WANG P,LIU W,et al. Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression [J/OL].arXiv:1911.08287 [cs.CV].[2021-11-20].https://arxiv.org/abs/1911.08287v1.
[10] EVERINGHAM M,ESLAMI S M A,GOOL L V,et al. The Pascal Visual Object Classes Challenge:A Retrospective [J].International Journal of Computer Vision,2015,111(1):98-136.
[11] LIN T Y,MAIRE M,BELONGIE S,et al. Microsoft COCO:Common Objects in Context [J/OL].arXiv:1405.0312 [cs.CV].[2021-11-20].https://arxiv.org/abs/1405.0312.
[12] KETKAR N. Stochastic Gradient Descent [M]//KETKAR N. Deep Learning with Python.[S.I.]:Apress,2014:113-132.
作者簡介:张凤(1991—),女,汉族,山东临沂人,讲师,硕士研究生,研究方向:图像处理。
猜你喜欢
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
电脑知识与技术(2016年27期)2016-12-15
软件导刊(2016年9期)2016-11-07
科技视界(2016年14期)2016-06-08
电脑知识与技术(2016年2期)2016-03-22
科技视界(2016年5期)2016-02-22
物联网技术(2015年11期)2015-11-26
现代电子技术(2015年15期)2015-08-14
光学仪器(2015年1期)2015-07-30
