
知识角色迁移视域下图书情报学研究方法识别
2022-06-18 17:43李佳莲
快乐学习报·教师周刊 2022年22期
摘要:想要完善并健全建设领域学科方法库,那么就需要识别图书情报领域中的研究方法。因此需要对现有的研究方法进行探究分析,并且从各项数据中获取相应的难点内容,本文依靠图书情报学以及计算机学之间知识的流通特性,提出知识角色迁移规律,并对数据进行批量标注,同时也需要应用深度学习模型。经研究证明此法值得进行推广和应用,可以从大规模文本中识别图书情报学的研究方法。
关键词:知识角色迁移;图书情报学;研究方法识别
引言:从我国目前图书情报领域的发展状况来看,照比之前现有的方法识别研究已经取得了一定的进步,而且在实际进行的过程中通常会应用NLP以及深度学习技术。当前我国现存的识别模型可以在学习文本中词汇、语法以及语义等特征的同时,识别抽取研究方法实体。图书情报学是一项较为复杂的学科,而且其研究方法多种多样,除了文献计量法、引文网络法等常见的图书情报学方法,还会融合其他学科的技术方法。
一、研究方法实体识别概述
研究方法识别换一种说法就是信息抽取问题,简单来说就是在图书或者是文本之中抽取描述方法的词语或者是语句。从形式上来讲,与它相近的任务还包括研究任务识别、理论术语抽取以及知识元抽取等,最开始研究这个话题时主要是应用基于规则的方法。当前我国科学技术手段以及信息技术手段也在不断地优化和完善,因此用于研究方法识别的技术也更加成熟,当前机器学习以及NLP技术照比之前也更加完善,而且目前大部分的研究主要以将信息抽取转化为机器可解的标签判定问题为主,现阶段,在实际进行研究方法识别工作的过程中通常会应用多类别分类或者是序列标注的方法,进而得到文本中包含的方法类实体。
现阶段我国研究人员对于图书情报学研究方法识别也进行了大量的研究,并不断进行探究和分析,从目前的研究成果来看,在图书情报学之中方法实体识别已经取得了很大的进步。而且目前统计学以及相关技术也更加完善,因此目前主要以机器学习为主,逐渐取代了模块学习的地位。以机器學习为主进行实体识别其效果更加明显,也更加优质,但是其在使用的过程中也存在一定的弊端,在实际应用的过程中,主要是依靠大规模以及高质量的训练样本。但是受到跨学科的特性以及学科知识内容交叉的影响,在图书情报学之中研究方法来源更加广泛,各类型之间也存在一定的差异性,目前现有的方法语料库主要是应用人工标准的形式完成数据的集构建,但是其成本较高,文本主体类型较为单一,并且在数据体量方面也存在一定的局限性。因此研究人员需要针对这一问题进一步进行探究和分析,进而实现自建研究方法识别模型的训练拟合,推动图书情报学的发展和进步[1]。
二、知识角色迁移的显现机理
知识迁移在迁移学领域中的重要内容,也是其理论基础,知识迁移主要是将源领域中学习到的知识更好地应用到目标领域之中,进而帮助目标问题进行求解。而图书情报学是一种教学复杂且繁琐的学科,其融合交叉了多种学科内容,比如说自然科学、技术科学以及社会科学,在其发展进步的过程中,需要不断地融合吸收其知识内容。随着我国经济社会的不断进步,越来越多的研究人员投身至科学技术以及信息技术领域的研究之中,而且也取得了很大的进步,并且也在不断地进行完善和优化,科学技术手段以及信息技术手段也在不断地创新,而实际进行工作的过程中不难发现,计算机领域与图书情报领域之间的知识角色迁移也愈加明显,研究人员在实际对图书情报学进行研究探究的过程中,通常会应用到大量的计算机算法、模型、工具以及计算机系统。我国研究学者张瑞等对于图书情报学中的知识角色迁移也进行了大量的研究,并且对图书情报学中的知识流入特点进行进一步分析,并明确指出在众多学科之中,相对而言计算机学科输出图书情报学中知识内容最多。而且以作者发文角度为出发点,也可以看出计算机学科与图书情报学科之间存在紧密的关联性。
总体来看,学科之间的交叉学习以及一个学科的交叉特性一般都会在研究方法之中展现出来。其实现阶段知识产生知识内容的主要方式还是跨学科合作以及多学科知识交叉,对于图书情报学之中,主要是以计算机学科为主不断对其进行影响和渗透,在图书情报领域之中为了解决出现的各种研究问题,通常会应用计算机学科之中的各种算法、模型以及工具等[2]。
三、研究思路概述
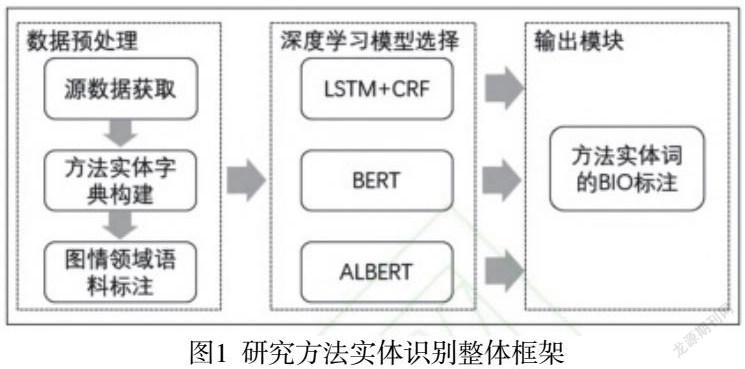
目前在图书情报学之中较为突出的一个问题就是研究方法自动识别问题,因此以计算机学科向图书情报学进行知识角色迁移规律为基础,建立一种基于弱监督学习的神经网络模型,并且在此过程中,研究人员以及相关工作人员需要进行大量标准样本的训练拟合,这样做的目的是更有效地实现高精准度以及鲁棒的图书情报性研究方法识别,进而促进其发展和进步,整体框架如图1所示。
图1研究方法实体识别整体框架
从图1中不难看出,可以将整体框架分为三个流程:(1)数据获取以及预处理:首先,工作人员可以利用信息网络技术收集获取源数据;其次应用字典并结合bootstrapping自学习策略,进而获取图书情报学中文本中的方法字典集;最后,需要对图书情报领域中文本数据进行一定的匹配,在这一过程中通常会应用计算机学科中的算法以及模型等实体,而且受到计算机学科向图书情报学领域知识角色迁移规律的影响,将出现在图书情报文献中的计算机算法或者是模型当作其研究识别方法,这样才能获取图书情报学领域中关于方法实体的标注数据。(2)深度学习模型选择:再次过程中选择利用三种较为先进且应用较为广泛的神经网络模型,即LSTM+CRF、BERT、ALBERT,然后工作人员利用实验检测方法实体识别的效果。(3)方法实体识别:应用通过训练拟合之后的模型完成学术文本中研究方法的识别。
结语:综上所述,本文对研究方法实体识别进行详细说明,并且对知识角色迁移的显现机理进行进一步探究,同时详细解释了其研究思路,并且研究方法实体识别的整体框架进行探究和分析。从中不难发现,计算机学科与图书情报学领域之间存在大量的知识角色迁移,而且其学科知识内容教学较为明显,同时在进行图书情报学中研究方法识别的过程中,通常会应用到计算领域的算法和模型,因此在今后的发展之中值得被进一步研究分析。
参考文献:
[1]李鹏程,程齐凯.知识角色迁移视域下图书情报学研究方法识别[J].情报杂志:1-7.
[2]孙琳,孙向荣.知识转移视角下中国图书情报学六种合著关系探析[J].内蒙古科技与经济,2021(11):134-137139.
作者简介:李佳莲;1985.8;女;汉族;四川省眉山市;大学本科;讲师;研究方向:图书情报;单位:四川工商学院图书馆。
