
基于生成对抗网络的个人信用风险评估研究
2022-06-26 07:02魏全
科教创新与实践 2022年14期
魏全
摘要:数据不平衡条件下的信用风险评估是一项重要但具有挑战性的任务,其表现为违约者类别的数量不够。本文提出了一种基于多源异构信用数据的不平衡生成对抗网络来缓解当前的类别不平衡信用评分问题。具体地说,本文设计了一个融合模块,将来自多个来源的异构信用数据整合到一个统一的潜在特征空间中。然后设计了一个基于生成对抗性网络(GAN)的平衡模块,为不平衡数据集的少数类生成新样本的潜在表示。最后将GAN的性能与多种传统的机器学习采样算法进行了比较,实验表明本文所提出的GAN在真实数据集上具有明显优于比较方法的性能。
关键词:信用风险评估;数据不平衡;生成对抗网络
1.引言
近年来,我国人民的收入和消费能力水平得到不断提升,消费场景不断丰富,人们的消费观念逐步升级,信贷消费已经成为消费的主要形式之一。越来越多的金融机构大力发展信贷业务,直接促进了我国个人信贷市场规模的持续扩大。日益增长的贷款需求及较高的不良贷款率促使着银行业金融机构在不断简化信贷审批流程的同時,要更加关注信贷资产风险的控制。
信用评分风险评估旨在自动判断是否应该批准或拒绝信用申请,以降低信用风险和减少不良贷款。由于其在银行和其他金融机构[1]的广泛应用,引起业界越来越多的关注。以往的大多数工作都采用了传统的机器学习方法,如支持向量机、决策树和逻辑回归方法来建立信用风险评估模型。受计算机视觉和自然语言处理领域深度学习成功的启发,最近的几项研究采用了深度学习算法,如卷积神经网络[2]和深度信念网络[3]的信用风险评估。
信用评分数据通常是结构化数据和半结构化数据的混合数据,称为多源异构数据,如用户档案数据和基于时间的用户行为数据。大多数研究只关注单一类型的数据,但没有融合这两种类型的数据来提取高级隐藏特征。一些研究[4]平等地对待各种数据,未能捕捉到用户支付行为随时间变化的动态,而另一些研究[5]只关注用户行为数据,而不是对信用评分任务至关重要的用户档案数据。这些传统的方法无法从这些多源异构信用数据中挖掘和融合丰富的潜在信息。在这种情况下,多源的集成异构数据被认为是信用评分的重要研究点之一。同时研究表明,普通采样方法重叠区域的样本在提高不平衡数据的分类性能方面发挥着更重要的作用。然而,如何有效地消除重叠区域中的多数类样本,同时避免因丢失原始分布而导致分类性能下降,仍然是一个悬而未决的问题。
2.文献综述
不平衡学习对于传统算法来说是一项具有挑战性的任务。研究人员意识到类别的不平衡确实会影响信用评估的分类,通过设计了上采样和下采样的方法去关注信用风险评估中的多数类和少数类,分析了采样技术对信用评分中类别不平衡问题的适用性[6, 7]。数据采样的方式有非常多种,值得一提的是,SMOTE算法[8]及在其基础上一些改进的方法[9]在信用风险评估中得到广泛应用并取得不错的效果,有效缓解了数据不均衡带来的偏差。
Shen[10]等人对SMOTE采样方法进行改进之后生成少数类样本,利用这种采样技术来处理不平衡的信用数据能够有效克服了SMOTE合成噪声样本的问题,提高信用风险评估模型在处理不平衡数据时的性能。Wang等[11]人改进并集成了过采样、欠采样和混合采样等多种采样方法以获得平衡的信用数据集。然而,这些算法共同的缺点是创造的少数类样本具有相同的特征性质,新样本与原始数据具有很高的重叠性,并不一定能为模型提供有效信息。
本研究考虑了上述所有的局限性,首先,整合来自多个来源的异构数据,其次提出了基于生成对抗网络,通过为少数类生成新的代表性样本来恢复数据集的平衡,以缓解信用评分任务中的类别不平衡问题。
3.数据来源及分析
本研究的数据集选取了中国某商业银行的个人信贷数据,包含了用户的基本信息和交易数据。数据集中正常样本个数有25141个,违约样本有6852个。其中个人基本信息数据中一些特征变量存在缺失严重的现象,必将导致特征信息损失严重,对其进行删除。交易数据中不存在缺失值,主要对交易时间进行了一系列时间特征的提取,并将字符型的类别特征,如交易方式、交易特征、一级交易代码进行独热编码的处理,以便后续进行特征构造。
4.商业银行客户信用风险评估
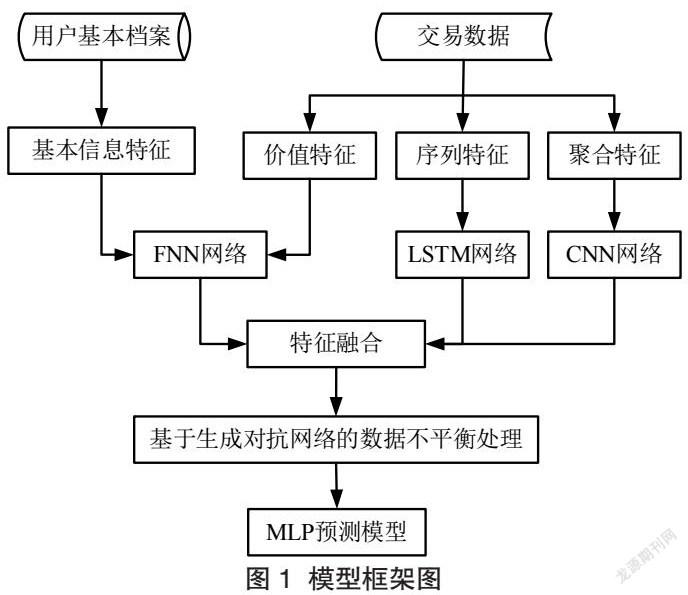
针对多源异构信用数据,本文对交易数据构造用户的静态和动态风险特征,并与个人基本信息进行融合,然后加入数据不平衡处理模块,提高模型预测的性能。具体的流程如图1所示。
4.1特征工程
(一)基于RFM模型的客户价值特征
交易数据中用户的每笔交易主要包含了三大维度特征:一是交易类型,如支出、收入、支付方式及交易对象等;二是交易时间,其中蕴含了用户消费的行为习惯;三是交易金额,能够反映了用户的消费能力和财富情况。借鉴RFM模型对客户价值衡量的思路,本文针对交易数据构造个人的用户价值特征。具体表示为:R反映个人最近的交易活跃度,如最近一次交易的时间;F代表一段时间内用户不同类型交易的次数,如:支付的次数、收入的次数,日均交易次等;M反映用户在一定时间内的不同交易类型的交易金额,如:日均收入、日均支出、周均支出等。
(二)个人交易行为的序列特征
单笔交易信息包含了时间、金额、交易方向等特征,由于特征的类型不同,无法采用相同的处理方式。针对不同类型的特征变量,本文将采用合适的方式进行处理。对于交易时间,我们提取每笔交易的时间特征,如年、月、周、日等,同时衍生为周末和工作日等特征;对于类别型特征,进行独热编码处理为稀疏矩阵;对于金额等数值型变量,直接进行输入。
本文选取在一定的时间段内拥有交易记录的用户样本,但是由于不同用户的交易笔数存在差异,假定用户在该段时间内的交易笔数为n,为了使得交易数据的序列向量表示能够变成统一的结构输入到神经网络中,需要对用户的交易记录数量进行统一。如果某用户交易记录数超过n,将选取最后的n笔交易作为输入.对于不足n笔交易的用户,我们将其交易序列前面补充0使其满足与其他样本向量的维度相同。
(三)交易数据的窗口聚合特征
单一的交易信息并不足以揭露出个人的信用风险,同时交易记录之间的时间间隔非常不规则,从分钟到天不等。这种时间间隔的不规则性导致很难提取交易时间序列的周期。因此我们考虑用户交易行为的一种更有效的方法是使用交易数据的聚合函数构造出一些特征。首先将用户在一段时间内的交易记录按照每周进行分组,然后计算这一段时间段内不同类型的交易数量、交易数量比例、交易金额、交易金额比例。为了在较长的过程中识别用户的行为模式,本文通过把用户的历史交易数据中按照每周的窗口进行聚合得到矩阵特征,其目标是根据用户的交易历史创建一个活动记录,揭示当前的交易行为与以往的不同程度。
4.2数据不平衡处理
生成式对抗网络(Generative adversarial network,GAN)是Goodfellow等人提出一种无监督算法,从刚提出就引起了许多研究人员的关注,继而在计算机视觉、自然语言处理、语音等领域取得了不俗的表现,并向其它一些领域逐渐延伸。生成式对抗网络不同于以往的生成模型预先假设生成样本服从某种分布,而是基于随机的噪声生成原始样本分布的新样本。GAN网络最大的创新是结合了生成网络和判别网络两部分,生成网络能够根据输入的随机噪声去构建映射函数生成新的样本,判别网络的能够将生成器的生成样本与真实样本进行比较,然后将结果反馈给生成器,直到最终生成的新样本近似服从真实样本的分布,两种网络是一种相互对抗优化的关系。
5.实验及分析
5.1分类评估指标
单一评价指标无法准确、全面、综合衡量模型的预测性能。考虑到评价标准在实际应用领域中的特点和局限性,为了更准确和全面地评价个人信用风险评估模型真实预测效果,本文采用了信用风险评估领域中四个主要的评价指标来综合评价模型的性能:准确率(Accuracy)、AUC(Area Under Curve)、F1值和KS(Kolmogorov-Smirnov)曲线。
5.2实验结果分析
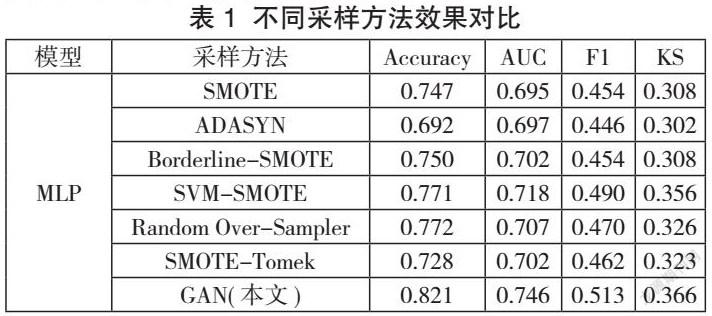
针对基于多源异构信用数据融合中的不平衡问题,本文提出的一种基于GAN的数据不平衡处理方法,其能够最大限度地学习原始数据中少数类样本地分布,从而生成接近真实分布地少数类样本。同时与现有机器学习主流采样方法,如SMOTE、ADASYN、Borderline-SMOTE、SVM-SMOTE、Random Over-Sampler、SMOTE-Tomek等进行对比,验证本文所提出的方法的性能,结果如表1所示。
从表1可以看出,在经过不同数据采样方法之后,传统的数据不平衡处理方法在四个评价指标上均低于本文的方法。Random Over-Sampler、SMOTE以及基于SMOTE的其它改進方法的评价指标虽然总体评价不错,但由于在信用风险评估对违约用户的错误分类要比预测正常用户有害得多,我们更关注模型识别具有违约风险用户的能力。
本文所提出的GAN模型优于所测试的传统采样方法。从本质看,基于GAN的数据生成方式主要是通过输入随机噪声,让生成器与判别器互相对抗优化去获得近似真实分布的数据,这样生成的数据因为与原始数据之间有着非常大的共性和显著性特征,数据质量更高。而对于传统的采样方法,都是在整体数据中的局部进行抽样,这样的结果就不如GAN稳定。本文所提出的GAN模型通过生成样本来平衡数据类可以学习到原始样本少数类足够的规律信息,更准确地识别具有违约风险的用户,这在信用风险评估场景中是十分有意义的。
参考文献:
[1] 顾洲一, 胡丽娟. 机器学习视角下商业银行客户信用风险评估研究[J]. 金融发展研究, 2022(01).
[2] Zhang X, Han Y, Xu W, et al. HOBA: A novel feature engineering methodology for credit card fraud detection with a deep learning architecture[J]. Information Sciences, 2021(03).
[3] 熊志斌, 吴维烨. 基于深度信念网络的信用评估研究[J]. 科研信息化技术与应用, 2019(03).
[4] Zhang Y, Wang D, Chen Y, et al. Credit risk assessment based on long short-term memory model[C].International conference on intelligent computing. 2017(02).
[5] 陈煜, 周继恩, 杜金泉. 基于交易数据的信用评估方法[J]. 计算机应用与软件, 2018(05)
[6] Crone S F, Finlay S. Instance sampling in credit scoring: An empirical study of sample size and balancing[J]. International Journal of Forecasting, 2012(01).
[7] Marqués A I, García V, Sánchez J S. On the suitability of resampling techniques for the class imbalance problem in credit scoring[J]. Journal of the Operational Research Society, 2013(07).
[8] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of artificial intelligence research, 2002(06).
[9] Wang L. Imbalanced credit risk prediction based on SMOTE and multi-kernel FCM improved by particle swarm optimization[J]. Applied Soft Computing, 2022(04).
[10] Shen F, Zhao X, Kou G, et al. A new deep learning ensemble credit risk evaluation model with an improved synthetic minority oversampling technique[J]. Applied Soft Computing, 2021(01).
[11] Wang D, Dong L, Wang R, et al. Targeted speech adversarial example generation with generative adversarial network[J]. IEEE Access, 2020(08).
